计算机组成原理 | Cache 映射方式大乱斗:全相联、直接、组相联到底怎么选?
摘要/导语:
嗨!上两期我们搞定了 Cache 的存在意义和局部性原理,后台很多同学私信问:"既然 Cache 这么好用,那主存里的数据到底是怎么'搬'进 Cache 的?"
这个问题直指核心------Cache-主存映射方式。是随便放?还是按规矩放?不同的放法直接决定了系统的速度和成本。全相联、直接映射、组相联,这三个名词是不是听得头大?
今天这篇推文就是专门为大家准备的"避坑指南"。我们将彻底拆解这三种映射方式的底层逻辑、地址结构差异以及各自的优缺点。文末还附带了经典的地址拆分计算题和 408 真题解析,帮你打通任督二脉,期末复习必备!
🚀 正文内容
🧩 第一部分:Cache 里到底存了什么?
在讲怎么"放"之前,我们先看看 Cache 这一行行的小格子里到底装了啥。它不仅仅是数据的搬运工,还自带了"身份证"系统。
每一行 Cache 存储的信息包含三部分:
- 有效位 (Valid Bit):0 或 1。相当于一个开关,告诉 CPU "这行数据是有效的,还是空的/过期的"。刚开机时全是 0。
- 标记 (Tag) :这是最关键的身份信息!它用于指明这一行数据对应的是主存中的哪一块。注意敲黑板:不同的映射方式,这个 Tag 的长度是不一样的,这也是考试最爱挖坑的地方。
- 整块数据:从主存搬运过来的实际内容。
🔗 第二部分:三种映射方式大比拼
当 CPU 想要访问数据时,主存块如何放入 Cache?这就涉及到了三种经典的策略。我们可以用"停车"来打比方,这样最好理解。
1. 全相联映射 (Fully Associative Mapping)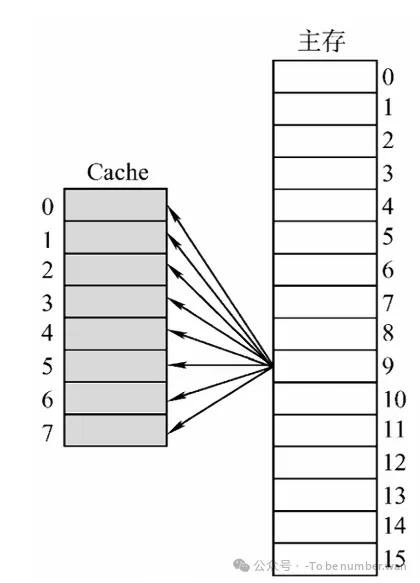
- 规则 :主存块可以放到 Cache 的任意位置。
- 比喻:就像去一个巨大的露天停车场,只要有个空位,你想停哪就停哪,非常自由。
- 地址结构 :
主存地址 = 标记 (整个主存块号) + 块内地址- 因为没有固定的位置限制,所以 Tag 必须包含完整的主存块号,以便在任何地方都能找到它。
- 优缺点 :
- ✅ 优点:空间利用率最高,冲突概率最低,命中率理论上最高。
- ❌ 缺点 :查找"标记"最慢! 因为数据可能在任何一行,CPU 必须把 Cache 里所有的 Tag 都拿出来比对一遍(并行比较器电路复杂且昂贵)。
2. 直接映射 (Direct Mapping)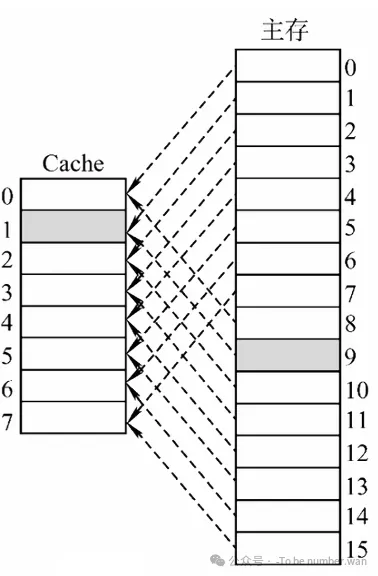
- 规则 :主存块只能放到特定的某个 Cache 行 。
- 公式:
Cache 行号 = 主存块号 % Cache 总行数
- 公式:
- 比喻:就像学校分配宿舍,学号尾号是 01 的只能住 1 号床,尾号 02 的只能住 2 号床。哪怕 1 号床空着,你也得去挤 2 号床(如果 2 号床有人,就得把原来的人踢走,这叫替换)。
- 地址结构 :
主存地址 = 标记 (主存块号前几位) + 行号 (主存块号末几位) + 块内地址- 这里的"行号"其实就是索引(Index),直接告诉你去第几行找。
- 优缺点 :
- ✅ 优点 :速度最快! 不需要复杂的比较电路,根据地址直接定位到某一行,只对比这一个 Tag 就行。硬件最简单,成本最低。
- ❌ 缺点:Cache 空间利用不充分,容易发生"抖动"(Thrashing)。如果程序频繁访问两个映射到同一行的块,命中率会极低。
3. 组相联映射 (Set Associative Mapping)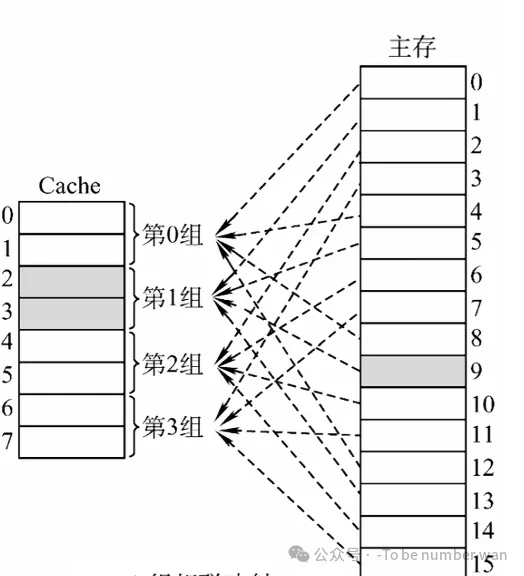
- 规则 :这是前两者的折中方案。把 Cache 分成若干个组 (Set) ,组内采用全相联,组间采用直接映射。
- 公式:
组号 = 主存块号 % 总组数 - 术语:n 路组相联 = 每个组里有 n 个 Cache 行。
- 公式:
- 比喻:还是分宿舍,但是这次是按班级分。你是 1 班的,只能去 1 班的那几间宿舍(组),但在 1 班的这几间宿舍里,你可以随便挑空床位睡(组内全相联)。
- 地址结构 :
主存地址 = 标记 (主存块号前几位) + 组号 (主存块号末几位) + 块内地址- 注意:这里的中间部分是"组号",不是"行号"了!
- 优缺点 :
- ✅ 优点:综合效果较好。既避免了全相联的复杂电路,又缓解了直接映射的冲突问题。现在的 CPU 几乎都用这种方式(比如 8 路组相联)。
💡 第三部分:核心考点与避坑指南
这里总结了大家最容易混淆的几个点,做题时请时刻提醒自己:
-
Tag 的长度怎么算?
- 全相联:Tag 最长 = 主存块号位数。
- 直接映射:Tag 最短 = 主存块号位数 - Cache 行号位数。
- 组相联:Tag 长度 = 主存块号位数 - 组号位数。
- 记忆技巧:限制越死(直接映射),需要的身份信息(Tag)就越短;越自由(全相联),需要的身份信息就越长。
-
"块内地址"是谁决定的?
- 无论哪种映射,块内地址(Offset)的位数永远只取决于 Cache 块的大小 (也就是主存块大小)。比如块大小是 64B,那块内地址就是 6 位 (26=642^6=6426=64)。这点千万别被映射方式带偏了!
-
关于"命中"的判断流程
- 直接映射:拿地址中的"行号"去 Cache 找对应行 -> 检查有效位是否为 1 -> 检查 Tag 是否相等 -> 相等则命中。
- 组相联:拿地址中的"组号"去 Cache 找对应组 -> 在该组内所有行中并行查找 -> 检查有效位和 Tag -> 有匹配则命中。
📝 第四部分:实战演练(408 & 期末真题风格)
光说不练假把式,来看一道经典的计算题,这也是 408 选择题的高频考法。
【例题】
假设某计算机主存容量为 4MB,Cache 容量为 16KB,每块大小为 64B。若采用 4 路组相联映射,请问主存地址的结构是怎样的?(即 Tag、组号、块内地址各占多少位?)
【解题思路】
-
先算块内地址(Offset):
- 块大小 = 64B = 262^626 B
- 所以,块内地址 = 6 位。
-
再算 Cache 的组数:
- Cache 总行数 = Cache 容量 / 块大小 = 16KB / 64B = 214/26=28=2562^{14} / 2^6 = 2^8 = 256214/26=28=256 行。
- 因为是 4 路组相联(每组 4 行),所以:
- 总组数 = 总行数 / 路数 = 256 / 4 = 64 组 = 262^626 组。
- 所以,组号(Index) = 6 位。
-
最后算 Tag:
- 主存容量 = 4MB = 2222^{22}222 B,说明主存地址总长 22 位。
- Tag = 总位数 - 组号位数 - 块内地址位数
- Tag = 22 - 6 - 6 = 10 位。
【最终答案】
主存地址结构为:Tag (10位) + 组号 (6位) + 块内地址 (6位)。
【408 真题改编·易错点分析】
题目 :在上述系统中,如果主存地址为
0x123456(十六进制),该地址对应的数据如果在 Cache 中,它一定在哪个组?
【解析】
这道题其实不需要看 Tag,只需要看中间的组号。
- 将
0x123456转为二进制(或者直接看十六进制的位权)。 - 低 6 位是块内地址(对应十六进制最后 1.5 位,稍微有点麻烦,建议转二进制)。
0x123456=0001 0010 0011 0100 0101 0110- 去掉最后 6 位(块内地址):
...0100 01(这是组号部分) -> 实际上是取中间 6 位。 - 中间 6 位(组号):
00 0101-> 即十进制的 5。 - 结论 :该数据如果命中,一定在 第 5 组。
🎓 总结
- 全相联:自由但慢,Tag 最长。
- 直接映射:快但容易冲突,Tag 最短,靠"行号"定位。
- 组相联:折中方案,靠"组号"定位,组内随便放。
希望这篇文章能帮你彻底搞定 Cache 映射!👇