久等啦,最近实在是有点忙,好久没更新,今天带新的干货来啦~
最近在 Github 上看到一个给 Hermes-Agent 专门做的记忆升级系统 memory-os,三天648星,这个增速还是相当可观的。
Memory-os 本身是为了 hermes-Agent 量身打造的,对于其他类型的智能体,比如 Claude code、Clacky 等并不能开箱即用。但是 memory-os 的 7层设计理念是框架无关的,尤其是最后一层的发现机制,对任何做Agent的人都值得借鉴。
Hermes本身有一套记忆系统,Memory-os 是在此基础上进行升级和调整,与 Hermes 原生记忆架构设计对照如下:
| Hermes原生 | Memory OS新增/改造 | |
|---|---|---|
| Workspace | MEMORY.md(memory工具写入)+ USER.md(用户录入) |
新增 CREATIVE.md,把Icarus的输出从MEMORY.md挪走,解决双Writer冲突 |
| Sessions | state.db存会话 + session_search工具 |
新增FTS5全文索引 + Icarus自动注入,原来Agent得自己调session_search,现在相关历史自动找上门 |
| Facts | 没有 | 整层全新,memory_store.db、信任评分、fact_feedback反馈循环、矛盾检测 |
| Fabric | Icarus插件上游版(esaradev/icarus-plugin),只能注入fabric,用text[:500]截断 |
大改Icarus fork,LLM提取替代截断、多源注入(Qdrant+sessions+facts)、CREATIVE.md隔离、社交闭合检测、反引号清洗、系统注入过滤 |
| Qdrant | 没有 | 整层全新,Qdrant混合检索、4级降级、衰减扫描、语义去重 |
| Wiki | 没有 | 整层全新,双管线Wiki策展+持续摄入 |
| Ground Truth | SOUL.md + rulebook.md,3级权威层级(终端输出>官方文档>训练知识) |
改了SOUL.md和rulebook.md,层级从3级扩到4级,注入记忆插为第2级 |
为什么需要增强 Hermes 的记忆系统?
这些痛点不是Hermes独有的,几乎所有Agent框架都有:
- 记忆存了,但Agent不去查,已经教过的东西白教
- 上下文注入了,但Agent当没看见,系统提示里明明有,但是没有遵守,没有执行
- 会话间有断层,昨天聊的架构决策,今天全忘了(需主动提示Agent查历史记忆)
- 记忆只增不减,时间长了记忆太多,没有衰减和归档机制,有用的信号被淹没
- 知识散落各处,结构化事实、聊天记录、项目文档各管各的,没有组织
Memory-os 要做的就是解决上面这些问题(当然目标是这样的啦),要让 Agent 从 "有记忆" 变为 "用记忆"。
7层架构全貌
Memory-os 按 生命周期 和 访问模式,把整个 Agent 记忆分为7层。
| 层 | 名字 | 存什么 | 干什么 | 来源 |
|---|---|---|---|---|
| Layer 1 | Workspace | 用户画像、偏好、创意状态 | 每轮都在,Agent随时能看见"你是谁" | Hermes原生 + Memory OS新增CREATIVE.md |
| Layer 2 | Sessions | 全部聊天记录 | 能翻历史,回顾"之前说了什么" | Hermes原生存储 + Memory OS加搜索注入 |
| Layer 3 | Structured Facts | 结构化事实+信任评分 | 知道哪些信息靠谱,哪些过时 | Memory OS全新 |
| Layer 4 | Fabric | 跨会话结构化笔记 | 聊天记录是流水账,这层存提炼后的经验卡片 | Hermes原生Icarus + Memory OS大改 |
| Layer 5 | Qdrant | 向量化知识库 | 前四层靠精确匹配或关键词,这层补语义搜索 | Memory OS全新 |
| Layer 6 | LLM Wiki | 自策展知识库 | 向量库只管搜到,Wiki管组织,从信息到知识 | Memory OS全新 |
| Layer 7 | Ground Truth | 身份文档中的权威层级 | 前6层保证记忆在提示词里,这层保证Agent用 | Hermes原生3级 + Memory OS扩为4级 |
其中 Layer 7 比较特殊,它不是一个物理存储层,而是偏向 概念层。这一层的目标不是管理记忆存储,而是管理 Agent 对注入的记忆内容的态度,该不该信?该不该用?这个问题比记忆如何存储和获取都重要,放在后面讲。
7层架构的完整协作流程,可以参考下面的小例子直观理解下:
markdown
信息产生(对话中)
│
├→ Layer 2 立即落盘:聊天记录存入SQLite(Hermes原生自动完成)
├→ Layer 1 实时更新:用户偏好写入MEMORY.md,创意状态写入CREATIVE.md(Memory OS)
│
▼ 会话结束
│
├→ Layer 3 结构化提取:Icarus调用LLM从对话中提取事实,存入fact_store(Memory OS)
├→ Layer 4 经验卡片:Icarus提取决策/方案/注意事项,写成Fabric条目(Memory OS改造)
│
▼ 定时任务(每小时/每天/每周)
│
├→ Layer 6 知识策展:Wiki Agent从raw/提取概念/实体/对比,生成 Wiki 页面(Memory OS)
├→ Layer 5 向量化:Wiki 文件经SHA-256 diff检测,嵌入后 upsert 到 Qdrant(Memory OS)
│
▼ 用户发来新消息
│
├→ Icarus pre_llm_call 钩子触发(Memory OS改造)
├→ 并行查询4个源:Fabric / Qdrant / Sessions / Facts
├→ 各自设阈值过滤,去重,组装进系统提示
│
▼ Agent推理
│
└→ Layer 7 生效:SOUL.md中的4级权威层级告诉Agent
注入的记忆是Ground Truth,不要假装没看见(Memory OS)Layer 1 Workspace:常驻记忆,永远可见
来源 :Hermes原生有 MEMORY.md 和 USER.md,Memory OS 新增了 CREATIVE.md。
三个文件都在 Hermes 目录下,每轮对话都注入系统提示,属于全局记忆,Agent不需要搜索就能看见。
| 文件 | 谁来写 | 存什么 | 来源 |
|---|---|---|---|
| MEMORY.md | memory工具,用§分隔符追加条目 |
Agent的持久记忆:环境事实、工具特性、项目约定 | Hermes原生 |
| USER.md | 用户手写 | 静态用户画像:你是谁、偏好、工作流 | Hermes原生 |
| CREATIVE.md | Icarus插件 | Agent的创意状态:学习心得、开放问题、循环计数 | Memory OS新增 |
CREATIVE.md 其实有点像是一个 bug fix。在 Hermes 原生记忆系统中, MEMORY.md 会同时被 memory 工具和 Icarus 插件修改,容易导致内容的覆盖。 CREATIVE.md 单独拆出来以后,memory 工具只修改 MEMORY.md,Icarus 插件只修改 CREATIVE.md,互不干扰。
Layer 2 Sessions:聊天记录+自动搜索注入
来源 :Hermes 原生有 session 存储(state.db + session_search工具),Memory-os加了 FTS5 全文索引和 Icarus 自动注入。
Hermes 原生就对所有的对话记录有着不错的管理,不论是存储还是搜索。但是原生框架的对话搜索是交给模型自己决策的,需要搜索的时候模型会调用 session_search 工具进行搜索。如果模型觉得不需要搜索,那么就不会调用工具,此时的对话记忆也就不会生效。
Memory-os 的做法是让 Icarus 在 pre_llm_call 阶段自动查相关历史,注入系统提示。即使 Agent 不搜,相关对话记忆也会自己找上门。
这是 Memory-os 反复用到的一个设计思想,不要等Agent主动调工具,在它思考之前就把相关信息喂过去。 后面Layer 3、4、5的注入都是同一个思路。
特别注意 ,Lay2 用到的搜索方法 FTS5 是 关键词搜索,不是语义搜索,用英文措辞搜索可能搜不到中文表达的同一个意思。所以后面还会有 Layer 5(Qdrant向量搜索)来补上语义搜索的缺口。
Layer 3 Structured Facts:结构化事实+信任评分
来源:全部由 memory-os 构建,Hermes 原生没有结构化事实存储。
Fact Store 存的不是原始文本,而是结构化后的事实数据。每个事实有类别(用户偏好/项目信息/工具/通用)、实体标签、信任评分、被检索次数、被标记有用次数。
聊天记录是流水账,废话多,信息密度低。比如上次对话提到过 "用pnpm不用npm",但这个信息会混在几百行对话里,噪声太大。Layer 3 把关键事实单独提出来,结构化存储,搜索时直接按实体或关键词命中,不用遍历全部记忆。
Layer 3 层有一个很不错的设计 ,就是关于信息的 信任评分。有时候我们会遇到一件事前后矛盾,比如以前可能让模型用React开发,但是过了一段时间以后,需要用Vue开发了。当 Agent 在做开发检索的时候,React这条信息和Vue这条信息同时被检索出来,到底哪个是对的?信任评分就是用于解决这类问题。
初始的时候,所有的信息评分都是0.5。后续基于每次信息的检索,会记录该信息的被检索次数 retrieved,以及检索到被标记为有用的次数 helpful。那么一段时间后,这条信息的 信任评分=0.5+helpful/retrieved。
这个信任评分机制其实还有个问题,作者的原话如下:
When you retrieve a fact via probe, search, or reason and reference it in your response, you MUST call fact_feedback in the same turn. Without feedback, trust_score is ornamental and fact quality degrades silently.
也就是说,模型必须要保证每次检索到信息后,要持续调用工具反馈信息的有用程度。如果长时间不反馈,则 helpful/retrieved≈0,那么信任评分的机制就失效了。
Memory-os 里信任评分这个问题其实也没完全解决。但它确实说明一件事,任何需要持续反馈才能生效的机制,如果反馈没有自动化,最终都会退化成摆设。

Layer 4 Fabric:跨会话经验卡片
来源:Hermes原有Icarus插件,Memory-os 改版很多,基本把原来的方式替换掉了。
Hermes 原生会在会话结束时从对话中提取笔记存为 Fabric 条目。提取方式是粗暴截断text[:500],前500字符,剩下的扔掉。本质上 Hermes 对于跨会话的信息没有做精细化设计,只是粗暴的把其他会话的信息截取一部分拿过来,让 Agent 知道之前对话的落点在哪里就行了。
Memory-os 修改后的方案是,每个会话结束时 Icarus 用 LLM 从对话中提取结构化笔记(而非暴力截断),存为Markdown + YAML frontmatter:
yaml
---
id: "29914be5"
type: "resolution"
summary: "Fixed MEMORY.md corruption from dual-writer conflict"
training_value: "high"
status: "completed"
---
## Context
...
## Action/Decision
...
## Outcome
...Hermes 原生的方式相当于今天上班的时候,把昨天的会议主题给你看了一下,顺带给你看了会议记录的前500个字。如果会议记录很长,其实你获得的信息并不完全,但是你能大体知道昨天干了点啥,这就是原来的设计理念。
Memory-os 修改后,相当于今天上班的时候,把昨天的会议总结给你看了。总结内容里面要干的事情都列清楚了,可能不是很详细,但是每一个点都在,基本能够比较完整的还原昨天的会议信息。
Layer 5+6:wiki 生成 + wiki 检索
来源:两层全新,且互为上下游------Layer 6 是 wiki 生产层,Layer 5 是 wiki 检索层。
从数据处理流程来看,其实 Layer 6 是先于 Layer 5 的,先生成信息再进行检索。但是从 Agent 使用的角度看,Layer 5 是实实在在的信息检索层,Layer 6 则偏向更下面的数据基座,甚至 Layer 6 对于 Agent 而言是无感的。
前面的4层解决了 Agent 的工作记忆,做过哪些事、用户提过哪些要求等等。但是更庞杂的信息,比如用户之前构建的技术规范,需求文档,或者项目的架构设计,这些实实在在的大产出,并不是简单放在记忆里就能解决的。Layer 5 + Layer 6 的组合,就是用来解决这一类问题。
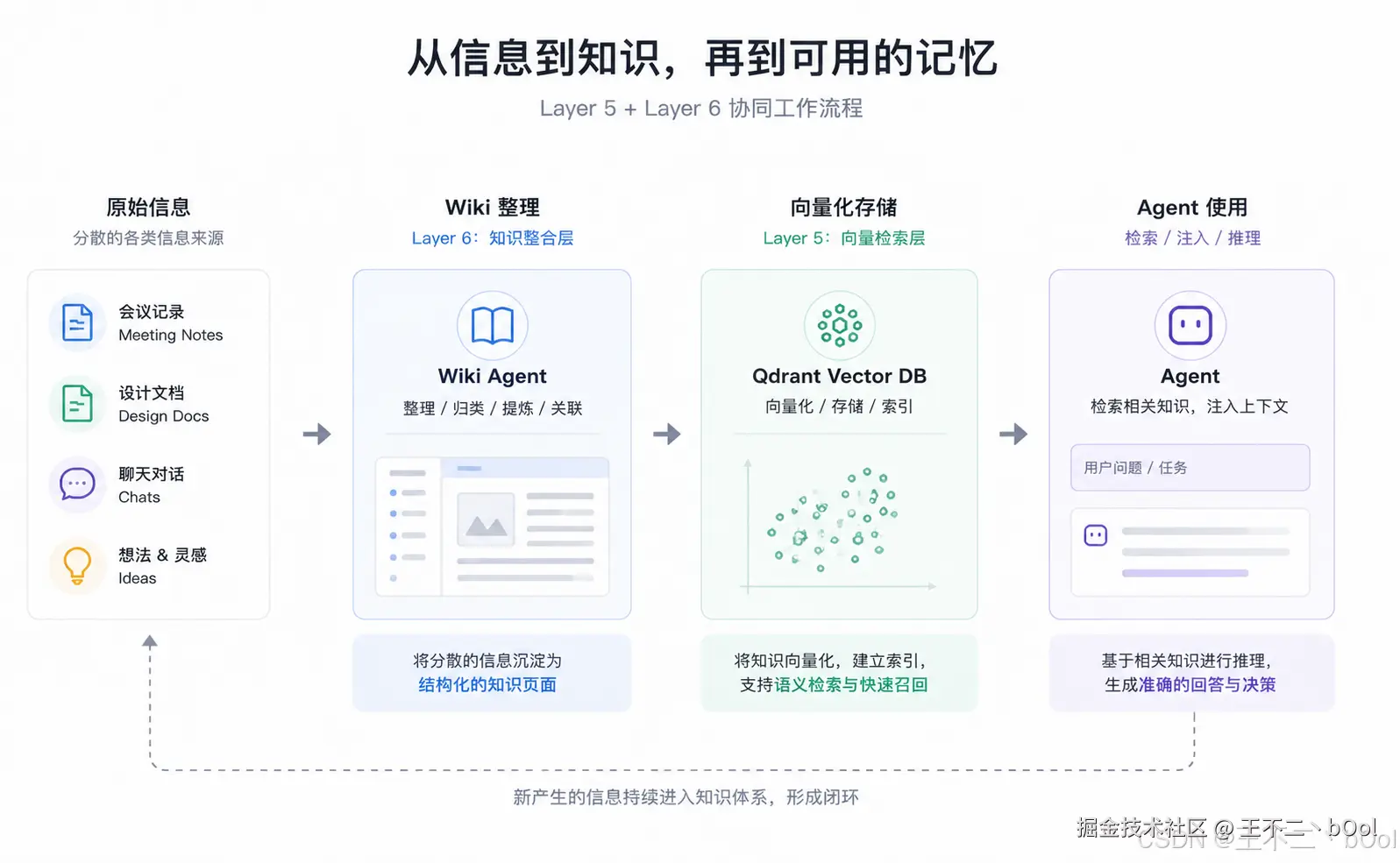
首先来看看 Layer 6 如何生成 wiki
Layer 6 生成内容的时机由两条定时任务控制,Wiki Agent 和 Vault Curator。Wiki Agent 每周两次调度,周一/周四凌晨3点。Vault Curator 每周一次(周末)。
Wiki Agent 是策展管线,处理流程如下:
markdown
1. 看全貌:读 SCHEMA.md + index.md + log.md,搞清已有页面、标签分类、最近动作
2. 扫新文件:遍历 raw/ 目录下未处理的文档
3. 策展:对每个文件自主判断------值不值得建页?建 concept / entity / comparison 哪种?
生成 markdown 写入对应目录,带上 YAML frontmatter、wikilink、回链 sourceVault Curator 是补充管线,不管新文件,只处理已有页面:
Phase 1:补全缺失的 frontmatter 字段
Phase 2:添加语义 wikilink(发现该连没连的页面)
Phase 3:更新 index.md 总目录然后看看 Layer 5 如何使用 wiki
Layer 5 的信息向量化,同样来源于定时任务,每一个小时做一次信息的向量化。每个内容通过调 Qwen3-Embedding-8B 生成4096维Dense向量,同时调 FastEmbed 的 BM25 生成稀疏向量(稠密+稀疏双检索)。
Layer 5 层的 wiki 向量化:
markdown
1. 扫描变更:遍历所有 .md,SHA-256 比对状态文件,只处理新增/修改的文件
2. 入队 Redis:ARQ Worker 从队列取 job
3. 双向量嵌入:Dense(Qwen3-Embedding-8B,4096维)+ Sparse(FastEmbed BM25)
4. 去重写入 Qdrant:cosine ≥ 0.92 的近重复点合并 payload,< 0.92 直接 upsertLayer 5 层的信息检索和降级策略:
perl
Level 1 混合检索(Dense向量 + BM25稀疏 → RRF融合排序)
↓ 检索失败
Level 2 仅Dense向量检索
↓ Qdrant整个挂了
Level 3 词法搜索(直接 grep wiki 目录下的 .md 文件)
↓ vault目录都不存在
Level 4 SQLite 关键词搜索(搜 lineage 表)
↓ 全挂
不注入,fail-open,Agent照样干活所以本质上,Layer 5 + Layer 6 其实就是给 Agent 补充了一个 RAG 知识库。
Layer 7 Ground Truth Hierarchy:相信相信的力量
来源:Hermes 原生有3级权威层级,Memory-os 扩为4级。
到这一层,Agent 已经拥有了完整的一套记忆系统,包括记忆检索、wiki检索等等,但是如果给到 Agent 的信息 Agent 不用,那就白搭了。所以 Layer 7 的目的,就是保证给到 Agent 的信息,Agent 必须奉为真理去应用。
Layer 7 的核心部分,其实就是下面两段prompt:
less
2. **Injected memory --- [qdrant], [fabric], [sessions], [facts]** --- Ground
truth for documented knowledge and prior decisions. These are delivered
by the `pre_llm_call` hook before every turn and represent what has
already been built, decided, or documented. When injected memory
contradicts your assumptions or training knowledge, injected memory wins.
Never treat a question as novel when the answer is already in your prompt.
csharp
## Context injection convention
When context is injected into the system prompt, it is labeled by source:
- [fabric] --- from Icarus fabric recall
- [qdrant] --- from Qdrant semantic search
- [sessions] --- from session history FTS5
- [facts] --- from holographic fact store
Injected memory takes priority level 2 in Ground Truth. This means: you
already know this. Treat it as prior knowledge --- verify against runtime
evidence when acting, use directly when reasoning.这两段其实做的是一件事,就是告诉 Agent,所有给你注入的信息,都是绝对真实可靠的,是属于 Agent 自身掌握的信息,放心大胆的用。
Memory-os 7 层记忆总结
回过头来再总结一下7层记忆架构都做了哪些:
-
Layer 1 :解决 Agent 对用户身份、长期偏好和当前工作状态的基础认知问题,是全局常驻的核心记忆层,在 Hermes 原生两个 MD 文件基础上新增 CREATIVE.md,解决了双写入冲突。
-
Layer 2 :解决会话间上下文断层和 Agent 不会主动查历史的问题,是原始对话的自动召回层,在 Hermes 原生会话存储基础上增加 FTS5 索引和预注入钩子,实现相关历史主动找上门。
-
Layer 3 :解决聊天记录信息密度低、新旧事实矛盾的问题,是经过提纯的可信事实底座,为 Memory-os 全新设计的一层,专门沉淀结构化、带信任评分的关键信息。
-
Layer 4 :解决跨会话经验无法有效复用的问题,是原始对话到结构化知识的中间转化层,彻底重构了 Hermes 原生粗暴截断的提取逻辑,用 LLM 生成标准化经验卡片。
-
Layer 5+6 :解决 Agent 无法处理海量长周期项目知识的问题,是完整的自研 RAG 闭环,为 Memory-os 全新增加的两层,实现知识自动策展、向量化和多级容灾检索。
-
Layer 7 :解决记忆存了、查了但 Agent 就是不用的终极痛点,是整个记忆系统的规则保障层,在 Hermes 原生 3 级权威体系基础上扩容为 4 级,强制模型优先采信注入的记忆。