VibeLoop 系列:Spring Boot × Redis 面试深度系列
贯穿案例「VibeLoop」为虚拟的轻量级内容互动平台,仅用于技术演示,并非真实存在的产品。
上期速递:【Redis】分布式锁从青铜到王者
本文覆盖 RDB/AOF 持久化原理、主从复制、哨兵集群、Cluster 分片、VibeLoop 生产部署、8 道面试题、必背速查表。
目录
- 开篇场景:凌晨三点的宕机电话
- 理论速览:持久化与高可用的四层金字塔
- RDB:定时快照的得与失
- AOF:命令日志的取舍
- [RDB vs AOF 选型决策树](#RDB vs AOF 选型决策树)
- 主从复制:读流量分流
- 哨兵集群:自动故障转移
- Cluster:数据分片与横向扩展
- [VibeLoop 生产部署方案](#VibeLoop 生产部署方案)
- [面试八连问 + 详解](#面试八连问 + 详解)
- 必背速查表
开篇场景:凌晨三点的宕机电话
20xx年 6 月 12 日,凌晨 3:17。
VibeLoop 运维群里炸了------"首页打不开了!"值班的张伟被电话叫醒,打开监控一看,Redis 进程没了。服务器半夜自动装了 Windows 安全补丁然后重启了。
他火速重启 Redis。RDB 文件在,数据恢复到了凌晨 3:00 的快照状态。用户登录 Session 没丢,但最近 17 分钟的热门帖子点赞数、实时评论、最新关注关系------全没了。
早上老板开会:"恢复速度还行,但整整 17 分钟的数据说没就没,下次能不能做到一点不丢?"
张伟把 appendonly yes 加上了。AOF 开启后,每条写命令都记到日志里。一个月后,AOF 文件涨到了 8GB,重启恢复要 4 分钟------老板又来问了:"Redis 不是号称微秒级响应吗?怎么重启越来越慢?"
加上运维组反馈:读流量越来越大了,Redis 单机 CPU 经常飙到 90%。张伟翻了翻 Redis 官方文档,发现后面还有一大串东西------主从复制、哨兵集群、Cluster 分片。
今天这篇文章,就沿着张伟踩过的坑,把 Redis 持久化到高可用这条路走通。
理论速览:持久化与高可用的四层金字塔
Redis 的单机高性能架构像一辆赛车:跑得快,但不出事还好,出一次事就致命。持久化和高可用就是给这辆赛车装上安全带 + 备用引擎 + 副驾驶 + 车队。
| 层级 | 能力 | 解决的问题 | 对应技术 |
|---|---|---|---|
| L1 持久化 | 重启不丢数据 | 进程崩溃/宕机 | RDB / AOF / 混合 |
| L2 主从复制 | 读流量分流 + 数据冗余 | 单机读瓶颈 | PSYNC 全量/增量 |
| L3 哨兵集群 | 自动故障转移 | 主节点宕机无人值守 | Sentinel Raft |
| L4 Cluster | 数据分片 + 横向扩展 | 单机写瓶颈 / 内存天花板 | 哈希槽 16384 |
类比:L1 就像是给赛车装了行车记录仪(出事了能回溯);L2 是加了副驾驶(能帮你分担);L3 是自动驾驶切换(司机晕了副驾自动接手);L4 是组建车队(一辆车装不下,分到多辆车上跑)。
今晚张伟的事故,每一层都能帮上忙。
RDB:定时快照的得与失
类比:拍照 vs 录像
如果把 Redis 数据比作一个大家庭的全家福------
RDB 是定时拍照:每隔一段时间喊大家"别动!看镜头!"拍一张。优点是照片体积小、拿出来就能看。缺点也很明显------两张照片之间发生的事,照片里没有。
AOF 是全程录像:从开机到关机一直录。丢了任何一秒都能回看。但录像文件越来越大,看一遍要快进很久。
fork + Copy-On-Write:不阻塞的快照是怎么做到的
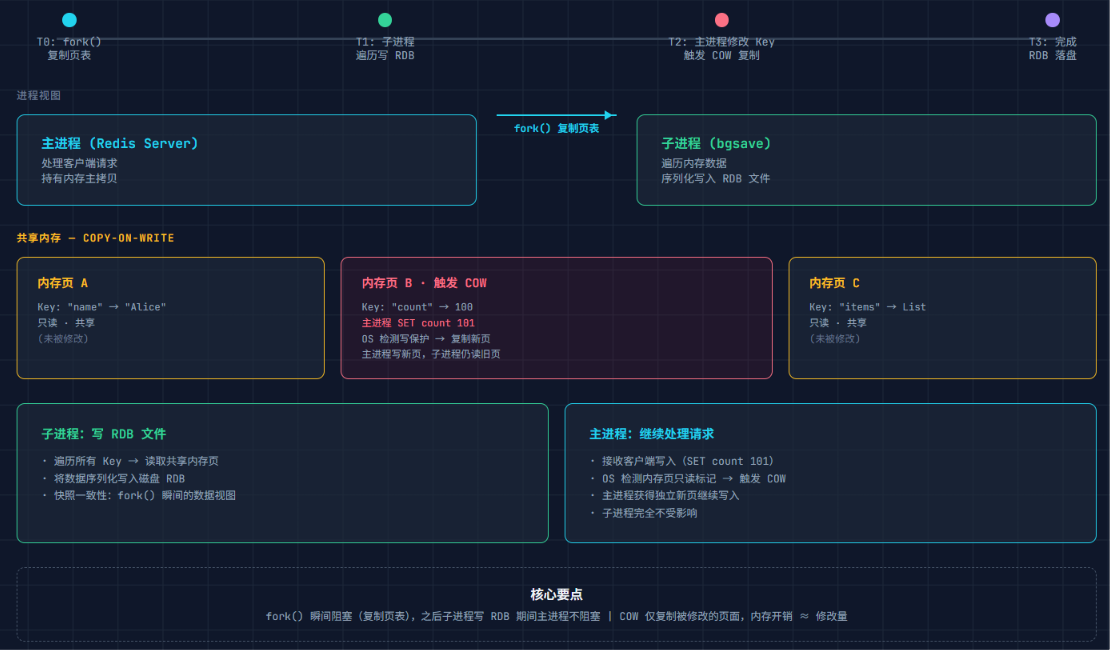
RDB 的核心命令是 bgsave(后台保存)。这里最容易混淆的点是:Redis 是单线程的,bgsave 会不会卡住主线程?
不会。bgsave 做了三件事:
-
fork() 子进程 :Linux
fork()会创建一个和父进程一模一样的子进程。此时父子进程共享同一块物理内存,但操作系统并不真的拷贝数据------只是把页表标记为"只读"。 -
子进程写 RDB 文件:子进程遍历内存中的键值对,逐个序列化写入磁盘。
-
Copy-On-Write(写时复制) :关键在这里。子进程写 RDB 期间,主进程还在处理客户端请求。当主进程要修改某个 key 时,操作系统发现这块内存是"只读"的,就会把要修改的那一页内存复制一份给主进程,子进程继续用原来的那页。只复制被修改的页,不是整个内存。
主进程: 修改 key-A → OS 检测到共享页 → 复制 key-A 所在页 → 主进程在新页上修改
子进程: 继续读原来的 key-A 页 → 写入 RDB 文件(内容是 fork 时刻的快照)
内存消耗估算:如果 fork 时有 10GB 内存,fork 期间修改了其中 2GB 的数据,COW 会产生约 2GB 额外内存开销------这在生产环境中必须留出余量。
save 自动触发条件
redis.conf 中默认的三条触发规则:
conf
save 900 1 # 900 秒内至少 1 次修改 → 触发 bgsave
save 300 10 # 300 秒内至少 10 次修改
save 60 10000 # 60 秒内至少 10000 次修改三条规则是"或"关系------满足任意一条就触发。可以注释掉所有 save 行来禁用自动 RDB。
RDB 优缺点速查
| 维度 | RDB |
|---|---|
| 数据恢复完整性 | 只能恢复到最近一次快照,丢失窗口 = 两次 save 间隔 |
| 恢复速度 | 快,二进制文件直接加载到内存 |
| 文件体积 | 小,紧凑压缩的二进制格式 |
| fork 开销 | 大内存实例 fork 耗时可能几百毫秒,COW 额外占内存 |
| 适用场景 | 对数据完整性要求一般、需要快速冷备的场景 |
AOF:命令日志的取舍
三种同步策略
AOF 记录的是每一条写命令 (以 Redis 协议格式追加)。关键参数 appendfsync:
| 策略 | 行为 | 数据安全 | 性能影响 |
|---|---|---|---|
always |
每条写命令都 fsync 到磁盘 | 最高,最多丢 1 条命令 | 性能最低(磁盘瓶颈) |
everysec |
每秒 fsync 一次(独立线程) | 较高,最多丢 1 秒数据 | 性能损耗可接受 |
no |
不主动 fsync,靠操作系统刷盘 | 最低,可能丢 30 秒数据 | 几乎无损耗 |
张伟选了 everysec------这是 99% 场景下的最优解。always 把 Redis 的 QPS 直接拉到机械硬盘级别,no 等于没开。
AOF 重写:给录像文件做剪辑
AOF 文件会无限增长。比如你对同一个 key 反复 INCR 了 100 万次,AOF 里有 100 万条 INCR 命令。重写就是把这些命令合并成一条 SET key 1000000。
bgrewriteaof 流程:
-
主进程 fork 子进程
-
子进程扫描内存中的所有 key,生成当前数据状态的最小命令集写入新 AOF 文件
-
期间主进程的新写入同时记录到 AOF 重写缓冲区
-
子进程完成后,父进程把缓冲区的命令追加到新文件末尾
-
原子地
rename新文件覆盖旧文件fork → 子进程写新AOF → 父进程积累增量 → 追加重写缓冲 → rename 替换
↑ ↑
COW 共享内存 主进程正常处理请求
AOF 触发条件
conf
auto-aof-rewrite-percentage 100 # AOF 文件增长了 100% 后触发重写
auto-aof-rewrite-min-size 64mb # 且 AOF 文件至少 64MBAOF 优缺点速查
| 维度 | AOF |
|---|---|
| 数据恢复完整性 | 高(everysec 最多丢 1 秒) |
| 恢复速度 | 慢,需要逐条执行命令重建数据 |
| 文件体积 | 大,是 RDB 的数倍(重写后可压缩) |
| fork 开销 | 重写时也需要 fork,同样有 COW |
| 适用场景 | 对数据安全性要求高的场景 |
RDB vs AOF 选型决策树
数据能接受丢失几分钟?
├─ 能 → 只用 RDB(最省资源)
│ └─ 实例内存超过 50GB?→ 关闭自动 save,改手动定时 bgsave
├─ 不能 → 开启 AOF(everysec)
│ └─ 还要考虑恢复速度?
│ ├─ 恢复速度重要 → RDB + AOF 同时开(生产最常见)
│ └─ 恢复速度无所谓 → 纯 AOF
└─ Redis 4.0+?→ 开混合持久化(aof-use-rdb-preamble yes)
RDB 做前缀(快速加载)+ AOF 做增量(完整数据)
兼顾了恢复速度和数据完整性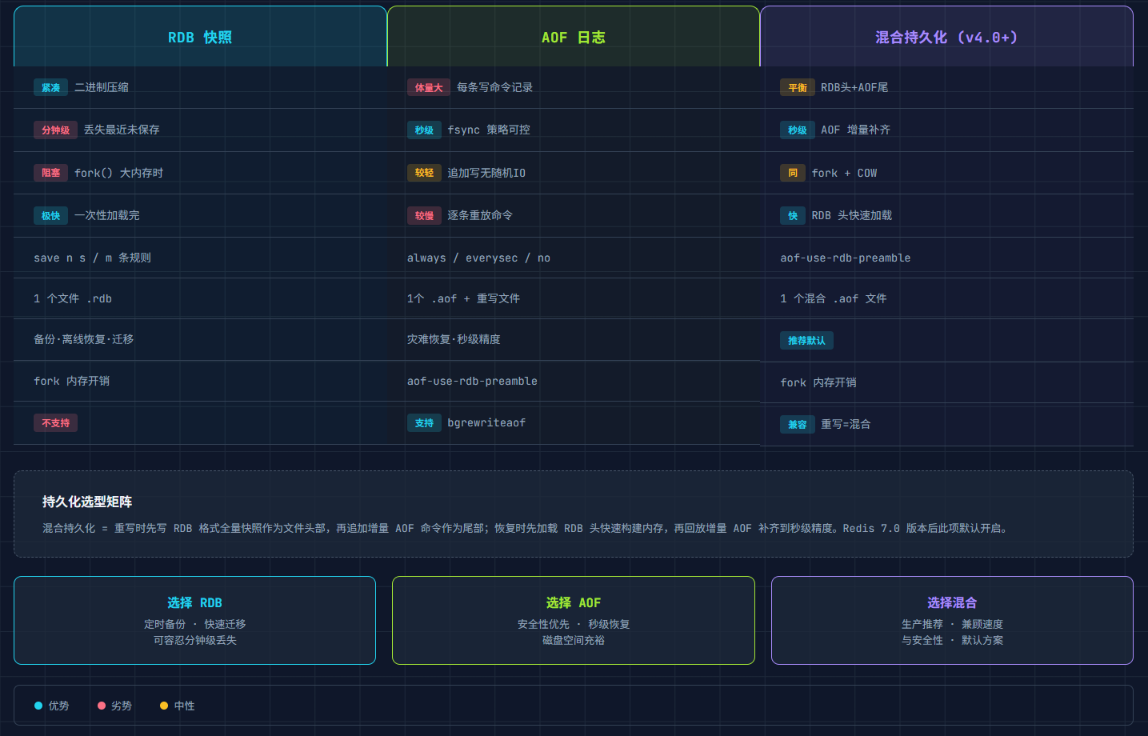
VibeLoop 的选择:混合持久化。RDB 前缀保证重启恢复速度快(老板能接受),AOF 增量保证数据不丢(用户不投诉)。
主从复制:读流量分流
为什么需要主从
张伟的单机 Redis 读 QPS 到了 8 万,CPU 90%。VibeLoop 的 Feed 流、帖子详情、用户主页全是读------读写比例约 9:1。加一个从节点,读流量分过去一半,主节点立刻降到 45%。
PSYNC:增量同步 vs 全量同步
主从复制的核心是 PSYNC 命令。从节点连接主节点后,发 PSYNC <replid> <offset>:
从节点: PSYNC ? -1 → 首次连接,全量同步
主节点: +FULLRESYNC <replid> <offset>
→ 主节点 bgsave 生成 RDB → 发送给从节点
→ 从节点清空旧数据 → 加载 RDB
→ 主节点把 RDB 生成期间的新写命令通过 replication buffer 发给从节点
→ 从节点追完 buffer → 进入命令传播阶段
从节点: PSYNC <replid> <offset> → 断线重连,增量同步
主节点: +CONTINUE
→ offset 还在复制积压缓冲区范围内 → 只需补发断线期间的命令
→ offset 不在范围内 → 退化为全量同步复制积压缓冲区(replication backlog) 是一个固定大小的环形缓冲区,默认 1MB。如果断线期间积压的命令超过了 1MB,只能触发全量同步------这就是为什么生产环境中 repl-backlog-size 要调大(建议 64MB+)。
从节点处理过期 Key
从节点不会主动删除过期 key 。主节点删除 key 时会在命令流中发一条 DEL,从节点同步执行。
主从复制的局限
主从解决了读扩展问题,但没有解决:
- 主节点挂了,需要手动把从节点提升为主(改配置 + 改应用连接地址)
- 写流量仍然只能走主节点
这两个问题分别交给哨兵和 Cluster。
哨兵集群:自动故障转移
张伟的第二件事故
开篇事故两个月后。张伟给 Redis 配了主从:1 主 3 从,读压力解决了。某个周六下午,主节点所在服务器磁盘满了,Redis 进程 OOM 被杀。
张伟在超市买菜,手机报警响了。他远程连进去,手动把从节点 slaveof no one 提为主节点,改了应用配置,重启了所有服务------整个流程 25 分钟。老板说:"下次能不能自动处理?"
哨兵就是干这事的。
主观下线 vs 客观下线
哨兵节点定期 PING 主节点。如果一个哨兵在 down-after-milliseconds(默认 30s)内没收到响应,标记为 SDOWN(主观下线)。
一个哨兵判断 SDOWN 不可靠------可能是它自己和主节点之间的网络断了。需要多个哨兵达成共识,这就是 ODOWN(客观下线):
哨兵1 → PING 主节点 → 超时 → SDOWN → 询问其他哨兵
哨兵2 → 回复:我也连不上主节点
哨兵3 → 回复:我也连不上
→ 票数 >= quorum(配置的法定人数)→ ODOWN → 开始故障转移哨兵领导者选举:Raft 协议
ODOWN 触发后,不是所有哨兵一起动手------需要选出一个 Leader 来执行故障转移。这个过程用 Raft 协议变体:
- 发现 ODOWN 的哨兵发起投票请求(
SENTINEL is-master-down-by-addr) - 每个哨兵在一个纪元(epoch)内只能投一票
- 得票数 >=
max(quorum, N/2+1)的当选 Leader - Leader 负责选新主节点 + 通知其他哨兵 + 更新客户端
选新主节点的逻辑
Leader 从所有从节点中按优先级排序:
1. 过滤掉 SDOWN / ODOWN / 断线超过 5s 的从节点
2. 按 slave-priority 升序(数字越小越优先)
3. 同优先级按复制偏移量降序(数据最新的优先)
4. 偏移量相同按 runid 字典序(唯一确定一个)类比 :哨兵选举就像班级选班长------需要超半数投票才算当选。如果平票就重新投。落选者自动变成副班长(普通哨兵),继续参与下一轮。如果多个哨兵同时发起选举(split vote),大家随机等待不同时间重试,避免活锁。
故障转移完整时序
SDOWN → 询问其他哨兵 → ODOWN → Raft 选举 Leader
→ Leader 选最优从节点 → SLAVEOF NO ONE 提主
→ 其他从节点 SLAVEOF 新主 → 更新哨兵监控目标
→ 发布 +switch-master 通知客户端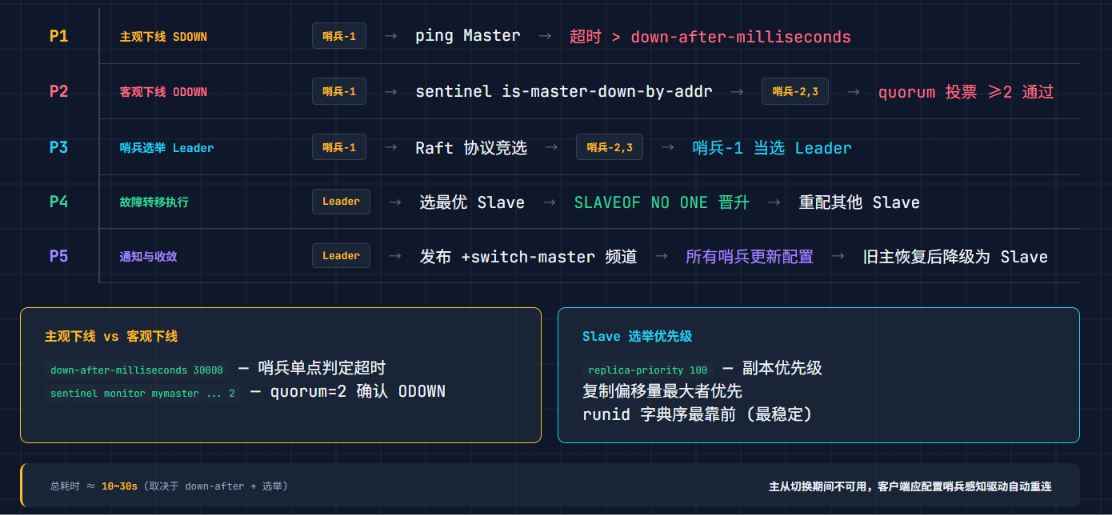
Cluster:数据分片与横向扩展
为什么还需要 Cluster
哨兵解决了高可用,没解决"数据太多存不下"和"写 QPS 太高扛不住"。VibeLoop 日活从 10 万涨到 100 万后,单机 Redis 内存飙到 58GB(物理内存只有 64GB),写 QPS 接近 4 万。
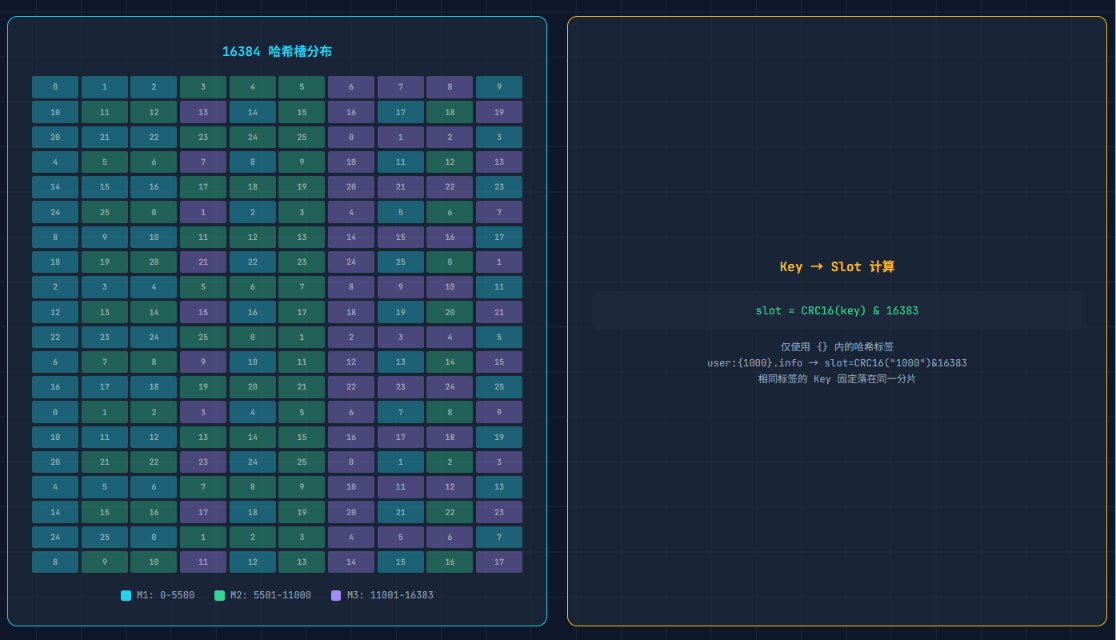
Cluster 把数据切成 16384 个槽,分到多台机器上。每个节点负责一部分槽,数据自动分散。
哈希槽:CRC16 % 16384
java
// key 对应的槽号计算
int slot = CRC16.crc16(key.getBytes()) % 16384;和一致性哈希的区别:Cluster 不维护哈希环,维护的是槽-节点映射表。扩容时人工指定槽迁移------哪些槽从节点 A 迁移到节点 B。
类比 :一致性哈希像环形跑道接力 ------新增选手只需交接相邻的那一棒,其他选手的跑道路线完全不受影响。哈希槽则是一整排储物柜(16384 个格子),每个节点管一段连续的柜子。扩容就是把一部分柜子移到新节点去管,迁移期间新旧节点共同服务被迁移的柜子。
Gossip 协议:节点间怎么通信
Cluster 没有中心节点,每个节点都通过 Gossip 协议和其他节点交换信息:
| 消息类型 | 用途 |
|---|---|
PING |
定期发送,携带自身状态 + 已知的其他节点信息 |
PONG |
对 PING 的回复 + 回应 MEET 握手 |
MEET |
邀请新节点加入集群 |
FAIL |
广播某个节点已下线 |
UPDATE |
通知槽配置变更 |
每个节点定期随机选几个其他节点发 PING,通过"病毒式传播"让集群状态最终一致。
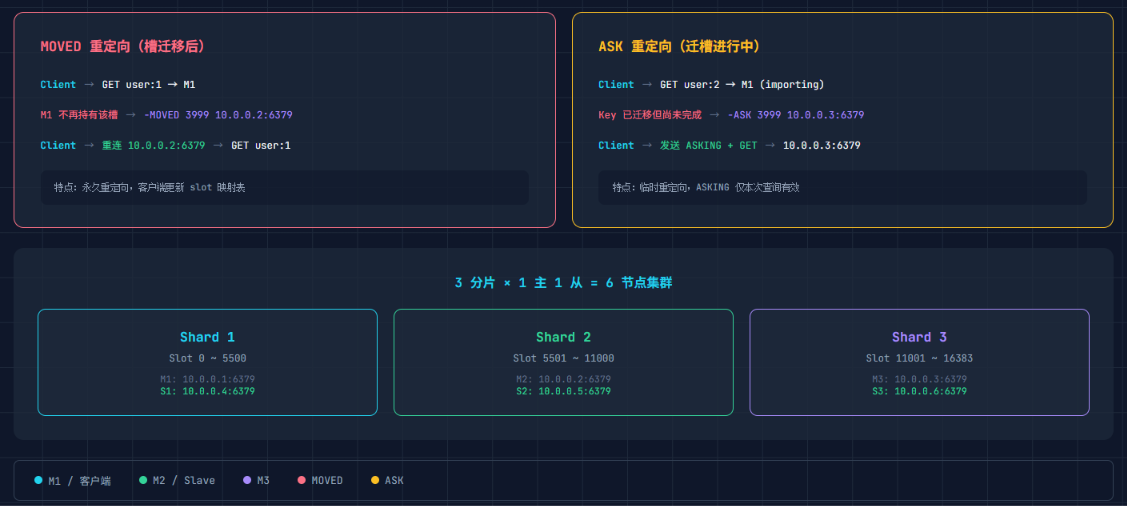
请求重定向:MOVED vs ASK
客户端随便连集群中任意一个节点发请求。如果该 key 的槽不在这台机器上:
客户端: GET post:10001
节点A: -MOVED 8462 192.168.1.103:6379 // 槽 8462 在 103 上,去那找
客户端: → 连接 192.168.1.103:6379 → GET post:10001 → 成功如果是槽正在迁移中:
客户端: GET post:10001
节点A: -ASK 8462 192.168.1.104:6379 // 槽正在迁,试试去 104 查
客户端: → ASKING → GET post:10001 → 成功(这次临时重定向)关键区别 :MOVED 是永久重定向(客户端应更新槽映射表),ASK 是临时重定向(槽还在迁移中,下次可能回到原节点)。
扩容流程
1. 新节点 CLUSTER MEET 加入集群
2. CLUSTER SETSLOT <slot> IMPORTING <source_node> // 目标节点标记槽为"正在迁入"
3. CLUSTER SETSLOT <slot> MIGRATING <target_node> // 源节点标记槽为"正在迁出"
4. MIGRATE 逐 key 迁移数据
5. CLUSTER SETSLOT <slot> NODE <target> // 完成迁移生产环境一般用
redis-cli --cluster reshard自动化执行,但理解底层命令对排查迁移卡住问题很重要。
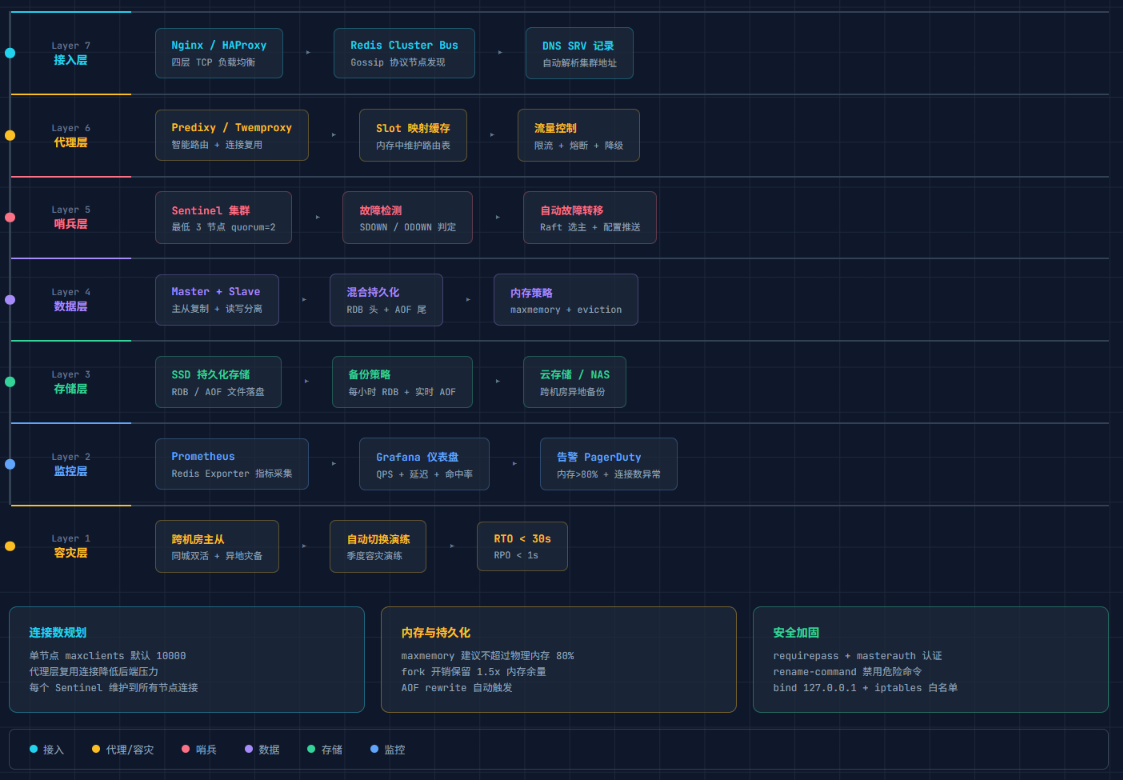
VibeLoop 生产部署方案
从单机 Redis 到 Cluster,VibeLoop 经历了三次架构升级:
| 阶段 | 架构 | 痛点 | 升级原因 |
|---|---|---|---|
| 初创期 | 单机 Redis + RDB | 半夜宕机丢 17 分钟数据 | 数据安全 |
| 成长期 | 主从 + 混合持久化 | 主节点挂了手动切 25 分钟 | 高可用 |
| 爆发期 | 6 节点 Cluster | 单机内存 58GB 接近天花板 | 横向扩展 |
最终生产配置:
conf
# 持久化:混合模式
save 900 1
save 300 10
save 60 10000
appendonly yes
appendfsync everysec
aof-use-rdb-preamble yes
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 128mb
# 主从复制
repl-backlog-size 64mb
repl-diskless-sync yes # 无盘复制,不落 RDB 文件直接网络传输
# 哨兵
sentinel monitor mymaster 192.168.1.101 6379 2
sentinel down-after-milliseconds mymaster 10000
sentinel parallel-syncs mymaster 1
# Cluster
cluster-enabled yes
cluster-node-timeout 5000部署拓扑:3 主 3 从,每对主从跨机架部署(避免单机架断电全挂)。哨兵 3 节点部署在独立机器上。
面试八连问 + 详解
Q1:RDB 的 bgsave 会阻塞主线程吗?为什么?
答:不会。bgsave 通过 fork() 创建子进程来执行磁盘写入,主线程继续处理请求。fork() 本身是阻塞的(复制页表),大内存实例可能耗时几十到几百毫秒。fork 之后父子进程通过 COW 共享内存,主进程修改数据时才触发页面复制。所以fork 瞬间有短暂阻塞,写 RDB 期间不阻塞。
Q2:AOF 重写期间,重写缓冲区会不会无限增长?
答:不会。如果 AOF 重写期间父进程累积的重写缓冲超过了限制,Redis 会限流------暂停接收客户端请求直到子进程完成。生产环境中应确保有足够的写入余量,避免触发限流。
Q3:混合持久化比纯 AOF 好在哪?
答:Redis 4.0 引入。RDB 做文件头(加载快),AOF 做文件尾(数据完整)。恢复时先加载 RDB 部分(二进制直接 rdbLoad),再回放尾部 AOF------恢复速度接近纯 RDB,数据完整性达到 AOF 级别。解决了"纯 RDB 丢数据"和"纯 AOF 恢复慢"的 tradeoff。
Q4:主从切换期间会发生什么?客户端会丢请求吗?
答:主节点故障到哨兵完成切换之间(通常 10-30s),写请求会失败。读请求如果连的是从节点不受影响。客户端应实现重试 + 退避 逻辑,或使用哨兵/Cluster 感知的客户端(如 Lettuce 的 RedisURI 配置哨兵地址)自动感知切换。
Q5:哨兵集群为什么必须是奇数个?
答:Raft 选举需要超半数投票(N/2+1)。3 个哨兵允许挂 1 个(2/3 > 1/2);4 个哨兵也只允许挂 1 个(需要 3 票),没有比 3 个更可靠却多费一台机器。所以实践中哨兵集群都是 3、5、7 个。
Q6:Cluster 的 16384 个槽为什么是这个数字?不能更多吗?
答:16384 = 2^14。设计考量:① 心跳消息中携带槽位图,16384 位 = 2KB,网络开销合理;② 每个节点维护 16384 个槽的映射,内存开销小;③ 实际生产集群很少有超过 1000 个节点的,16384 个槽足够均匀分配。理论上可以改,但不建议------16384 是编译期常量。
Q7:Cluster 模式下,Lua 脚本和事务怎么处理跨槽 key?
答:Cluster 要求 Lua 脚本中涉及的所有 key 必须在同一个槽。使用 hash tag :把 key 写成 {user:100}:profile 和 {user:100}:posts,CRC16 只计算 {} 内的部分------保证它们落在同一个槽。MULTI/EXEC 事务同理。没有 hash tag 的跨槽操作直接报 CROSSSLOT 错误。
Q8:集群扩容期间,正在迁移的槽被写入了怎么办?
答:槽迁移期间,源节点和目标节点短暂共存。写请求到源节点:先查 key 是否已被迁移(lookupKey),已迁移则返回 -ASK 重定向。读请求到目标节点:ASKING 命令告知目标节点"暂时接管这个槽的请求"。迁移完成后,源节点的槽绑定解除,所有请求正常走目标节点。
必背速查表
| 概念 | 一句话 | 面试关键词 |
|---|---|---|
| RDB bgsave | fork 子进程 + COW,不阻塞主线程 | fork / COW / save 触发条件 |
| RDB 丢失窗口 | 两次 bgsave 之间数据不在磁盘上 | save 60 10000 |
| AOF 三策略 | always/everysec/no,everysec 是平衡点 | fsync / 最多丢 1 秒 |
| AOF 重写 | 扫描内存生成最小命令集,解决文件膨胀 | bgrewriteaof / 重写缓冲 |
| 混合持久化 | RDB 头 + AOF 尾,恢复快数据又完整 | aof-use-rdb-preamble / Redis 4.0 |
| PSYNC | replid + offset 实现断线增量同步 | +CONTINUE / +FULLRESYNC |
| 复制积压缓冲 | 环形 buffer,太小退化为全量同步 | repl-backlog-size 64MB |
| SDOWN/ODOWN | 主观下线 / 客观下线(多数哨兵确认) | down-after-milliseconds / quorum |
| 哨兵选举 | Raft 协议选 Leader 执行故障转移 | epoch / N/2+1 投票 |
| 哈希槽 | crc16 % 16384,数据分布靠槽不分 ring | slot / hash tag {...} |
| MOVED vs ASK | 永久重定向 vs 临时重定向(迁移中) | -MOVED / -ASK / ASKING |
| Gossip 协议 | 去中心化节点状态传播 | PING/PONG/MEET/FAIL |
这是Redis系列的最后一期,若有问题欢迎交流指正,若有帮助麻烦各位支持支持