目录
[Workflow 模式总览](#Workflow 模式总览)
[模式 1:Prompt Chain(提示链)](#模式 1:Prompt Chain(提示链))
[模式 2:Routing(路由)](#模式 2:Routing(路由))
[模式 3:Parallelization(并行化)](#模式 3:Parallelization(并行化))
[形式 A:分段并行(Sectioning)](#形式 A:分段并行(Sectioning))
[形式 B:投票并行(Voting)](#形式 B:投票并行(Voting))
[模式 4:Orchestrator-Workers(编排者-工作者)](#模式 4:Orchestrator-Workers(编排者-工作者))
[模式 5:Evaluator-Optimizer(评估者-优化者)](#模式 5:Evaluator-Optimizer(评估者-优化者))
这是本课程的核心章节------掌握这五种模式,你就掌握了长任务拆解的全部基础范式
Workflow 模式总览
以下五种模式来自 Anthropic 工程实践,是目前业界共识的长任务拆解基础范式。
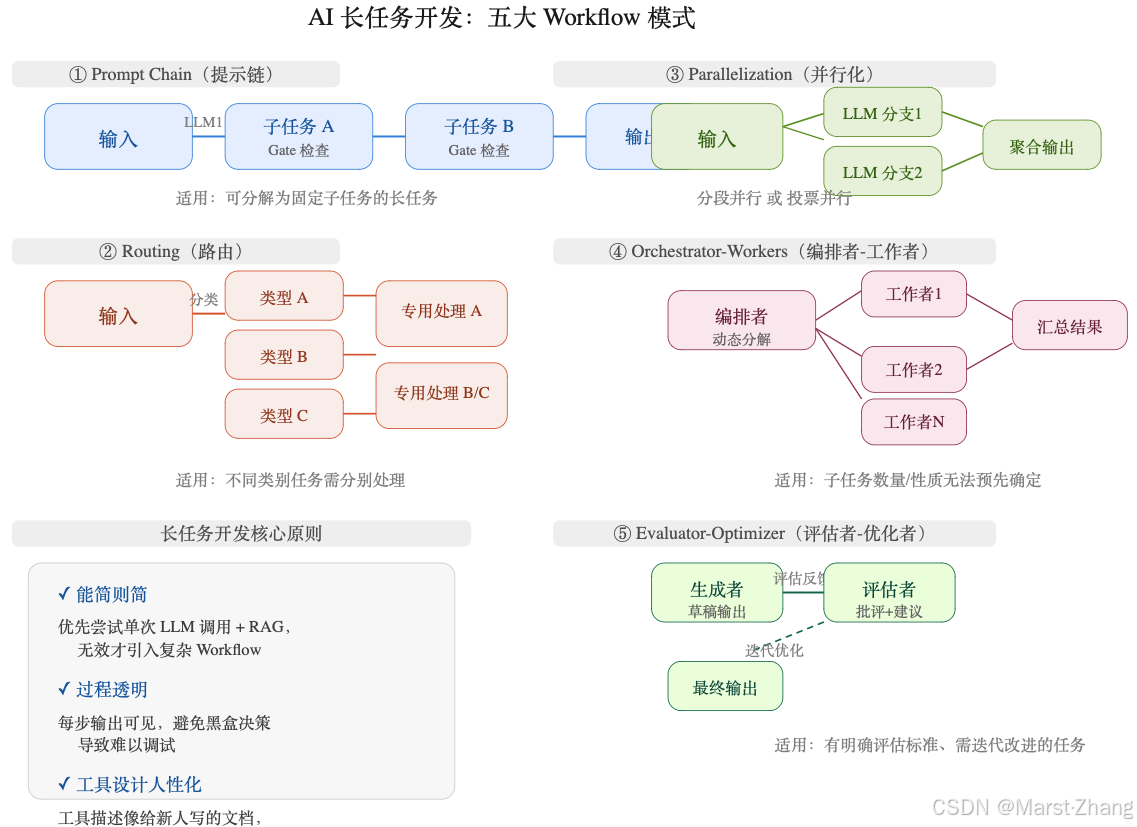
图 1:五大 Workflow 模式总览------复杂度从左到右递增,仅在前一种不够用时才考虑更复杂的
模式 1:Prompt Chain(提示链)
核心思想 :将长任务分解为一系列顺序执行的子任务 ,每个 LLM 调用只处理前一步的输出,每步之后都有一个 Gate(检查点) 验证输出质量。
输入 → LLM1:子任务 A → Gate 检查 → LLM2:子任务 B → Gate 检查 → LLM3:子任务 C → Gate 检查 → 输出
适用场景:
- 任务能干净地分解为固定子步骤
- 每步输出可以独立验证
- 错误传播代价高,不能容忍中间步骤出错
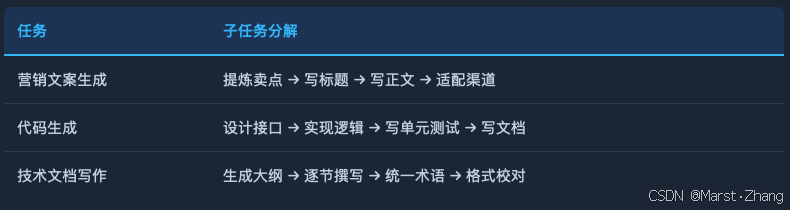
典型案例
核心要点:Gate(检查点)是 Prompt Chain 的灵魂!没有 Gate 的链式调用 = "把错误一步步放大"。Gate 的实现可以是:规则校验、LLM 评估器、自动化测试或人工审核。
模式 2:Routing(路由)
核心思想 :先对输入分类,再路由到专门的处理流程。
输入 → [分类器 LLM] → 类型 A 处理器 / 类型 B 处理器 / 类型 C 处理器
成本优化价值 :路由是成本优化的重要手段 。将简单问题路由到小模型,复杂问题路由到大模型,实测可降低 30--50% 成本。
python
def routing_workflow(user_input):
task_type = classify_with_llm(user_input, model="gpt-4o-mini")
if task_type == "code_generation":
return handle_code(user_input, model="gpt-4o")
elif task_type == "simple_qa":
return handle_qa(user_input, model="gpt-4o-mini")模式 3:Parallelization(并行化)
核心思想 :多个独立子任务同时执行,最后聚合结果。
形式 A:分段并行(Sectioning)
将任务拆分为独立部分,分别处理,最后合并。例:10 章文档分 3 组并行翻译。
形式 B:投票并行(Voting)
同一任务执行多次(不同 temperature),取最优结果或多数表决。例:代码审查执行 3 次取交集。
成本注意 :并行化会成倍增加 token 消耗,只在质量提升明显超过成本增加时使用。
模式 4:Orchestrator-Workers(编排者-工作者)
核心思想 :由一个编排者 LLM 动态分解任务,分配给多个工作者 LLM 执行,最后汇总。
与并行化的关键区别 :子任务不是预先定义的,而是编排者根据输入动态决定的。
用户任务 → [编排者 LLM:动态分解] → 工作者1 / 工作者2 / 工作者N → [编排者汇总] → 输出
适用场景:
- 无法预测需要修改多少个文件(代码重构典型)
- 需要从多个来源动态收集信息
- 子任务数量不固定
推荐框架:微软 AutoGen(原生支持)或 LangGraph(动态图)。
模式 5:Evaluator-Optimizer(评估者-优化者)
核心思想 :一个 LLM 生成结果 ,另一个 LLM 评估并提供反馈,形成迭代优化闭环。
任务 → [生成者:草稿] → [评估者:批评+建议] → [生成者:改进] → ... → 最终输出
终止条件设计(否则可能无限循环):
python
max_iterations = 5
for i in range(max_iterations):
draft = generator_llm(task, prev_feedback)
evaluation = evaluator_llm(draft, criteria)
if evaluation["passed"]:
return draft
if i == max_iterations - 1:
return draft
prev_feedback = evaluation["suggestions"]五种模式对比总结
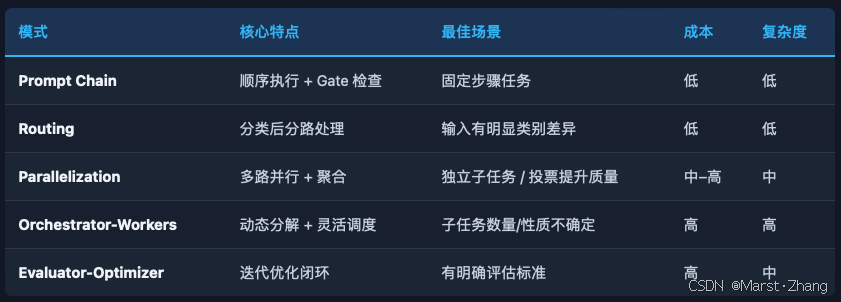
选型建议:从上到下选,只在更简单模式不够用时才考虑更复杂的模式。这是 Anthropic 和 AWS 的共同建议。
本章要点
五大 Workflow 模式是长任务拆解的基础范式------Prompt Chain 适合固定步骤任务,Routing 适合分类处理,Parallelization 适合并行加速,Orchestrator-Workers 适合动态调度,Evaluator-Optimizer 适合迭代优化。选型原则:从简单开始,只在必要时增加复杂度。