2026台北GTC大会期间,英伟达发布了Cosmos 3一款基于突破性Transformer混合架构的物理AI世界模型。Cosmos3 的关键不是生成更炫的视频,而是把文本、图像、视频、音频和动作轨迹放进同一个模型里,让 AI 能理解物理世界、预测未来状态,并生成可用于训练和评估的世界样本。

从视频生成到物理世界模型
过去一年,多模态模型给人的第一印象往往是"看图说话"或"文生视频"。但机器人、自动驾驶和智能工厂真正需要的能力,远不止把画面生成得更清楚。一个机器人要抓取桌面物体,必须判断物体位置、手臂轨迹、接触关系和失败风险;一辆车进入复杂路口,必须理解行人、车辆、信号灯和未来几秒的运动变化。Physical AI 面对的是连续变化的物理世界,模型需要同时处理观察、理解、预测和动作后果。
Cosmos3 正是沿着这个方向设计的。它不是把视频生成当作终点,而是把视频、声音、图像、语言和动作都视为世界状态的一部分。换句话说,它希望 AI 不只是"看见世界",还能够在模型内部模拟世界如何继续演化,并把这些模拟结果用于训练、评估和决策。
Cosmos3的核心:Omnimodal World Model
Cosmos3 最大的关键词是 omnimodal。它支持 text、image、video、audio、action 等模态,不只是把多种输入塞进一个模型,而是把世界理解、世界生成、未来预测和动作生成放进同一套框架。对于真实世界里的智能体来说,视觉、声音和动作从来不是孤立信号:一个杯子被推倒,会同时带来画面变化、声音变化、空间关系变化,也会影响下一步动作是否可行。
这也是 Cosmos3 相比普通视频生成模型更值得注意的地方。它关心的不只是"生成一段看起来合理的视频",而是让模型理解场景里的对象、关系、运动和因果。自动驾驶中的长尾场景、机器人操作中的失败案例、智能空间里的异常事件,都很难靠真实采集无限扩充。一个开放的 omni world model,可以为这些场景生成更丰富的训练样本,也可以帮助系统提前推演风险。
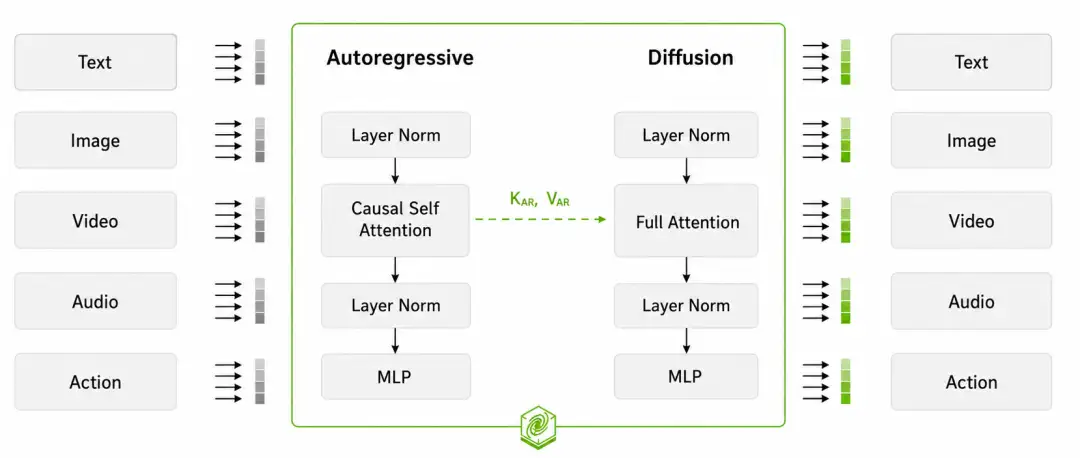
MoT 架构:为什么理解和生成要放在一起
架构上,Cosmos3 使用 Mixture-of-Transformers。可以把它理解成两个互补的分支:Autoregressive Transformer 更擅长处理离散 token、语言、推理和动作逻辑;Diffusion Transformer 更适合图像、视频、音频、动作轨迹等连续信号生成。前者偏"理解和推理",后者偏"生成和模拟"。
这种组合的意义在于,Physical AI 的任务本来就是闭环的:先观察环境,再理解状态,再预测未来,再选择动作,最后根据反馈修正策略。如果理解模型、视频模型和动作模型各自独立,系统就很容易在信息传递时丢失语义和因果。Cosmos3 试图把这些能力压到一个统一模型中,让世界模拟不只是视觉生成,而是和推理、动作、声音共同发生。
Cosmos3-Nano:16B 级别的开放入口
Cosmos3-Nano模型卡约为 15.75B 参数,通常可按 16B 规格描述,架构标注为 cosmos3_omni。它支持多模态输入输出,覆盖文本、图像、视频、音频和动作等信息。相比 64B/65B 级别的 Cosmos3-Super,Nano 更像是让研究者和开发者理解 Cosmos3 能力边界的开放入口。
数据口径上,官方模型卡采用 1.3B data points,覆盖图像、视频、音频、文本和动作等物理 AI 数据。这一点很关键,因为 Cosmos3 的能力不是靠单一模态堆出来的,而是通过跨模态数据学习物体、运动、声音和动作之间的关系。它的目标不是成为单一任务模型,而是成为能支撑机器人、自动驾驶和工业智能的世界模型底座。
从模型定位看,Nano 的意义不是替代更大的 Super,而是让社区先看到 Cosmos3 的统一范式:同一个模型既能理解场景,也能生成世界状态,还能围绕动作进行推理。对一篇模型推文来说,这比单纯比较参数规模更重要,因为 Cosmos3 真正想表达的是"世界模型可以成为 Physical AI 的共同语言"。
能力场景:机器人、自动驾驶与未来预测
Cosmos3 的应用想象主要集中在 Physical AI 的高成本数据场景。机器人可以利用模型生成或预测操作过程,用来评估抓取、移动、避障等动作是否合理;自动驾驶可以生成夜间、施工、紧急车辆、复杂交通参与者等长尾场景,补足真实采集覆盖不到的样本;未来预测则可以基于当前观察,推演接下来几秒的视频变化和动作结果。
这些能力背后的共同点,是"生成"不再只是内容生产,而是成为训练和评估的一部分。对机器人来说,模型生成的是可能发生的操作过程;对自动驾驶来说,模型生成的是难以高频采集的危险或罕见场景;对智能空间来说,模型生成的是系统需要提前理解和处理的世界状态。
这也解释了为什么 NVIDIA 会把 Cosmos3 放在 Physical AI 语境里介绍。现实世界的数据往往昂贵、稀缺,而且充满低频高风险事件;世界模型如果能提供可控的合成样本和未来预测,就能帮助模型在真实部署前看到更多可能发生的状态。它不是替代现实,而是扩展训练和验证的想象空间。

推理能力:不只是生成,还要解释为什么
Cosmos3 之所以被 NVIDIA 称为面向 Physical AI reasoning and action 的 omni-model,是因为它不仅要生成结果,还要理解为什么会发生这些结果。在自动驾驶场景中,模型需要判断道路参与者、交通状态、潜在危险和下一步行为;在机器人场景中,模型需要理解物体是否可抓取、轨迹是否安全、动作是否可能导致碰撞。
这种推理能力决定了 Cosmos3 和普通生成模型的差别。一个看起来真实的视频不一定对策略训练有用,真正有价值的是能保留物理关系、动作逻辑和风险信息的世界样本。Cosmos3 试图把场景理解、因果判断和动作推演统一起来,让模型输出更接近 Physical AI 系统真正需要的训练信号。

仍然需要冷静看待的边界
当然,Cosmos3 不应该被理解成物理世界建模难题已经消失。长视频一致性、高分辨率复杂场景里的细节稳定性、复杂接触物理、声音与视觉对齐、动作轨迹和真实执行之间的误差,仍然需要大量验证。尤其在安全敏感任务里,生成结果不能直接等同于真实世界测试,模型预测也不能替代仿真、评估和工程冗余。
更合理的判断是,Cosmos3 提供了一个开放的统一入口,让 Physical AI 从"单点模型拼接"逐步走向"围绕世界模型构建数据和评估闭环"。它的价值不在于一次性解决所有问题,而在于把理解、生成、模拟和动作放到同一条技术路线上。
结语
如果说大语言模型让 AI 学会了处理文本世界,那么 Cosmos3 代表的是另一条更接近现实的路线:让 AI 学会理解并模拟物理世界。它未必会像消费级文生视频模型那样一夜刷屏,但对机器人、自动驾驶和工业智能来说,这类模型可能会成为下一代 Physical AI 基础设施的一部分。Cosmos3 的意义正在于此:它把多模态生成推进到世界建模,把"看见世界"推进到"推演世界"
社区地址
OpenCSG社区:
https://opencsg.com/models/nvidia/Cosmos3-Super
https://opencsg.com/models/nvidia/Cosmos3-Nano
huggingface社区:
https://huggingface.co/nvidia/Cosmos3-Nano
https://huggingface.co/nvidia/Cosmos3-Super
关于OpenCSG
OpenCSG是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续生态,AgenticOps是人工智能领域的一种AI原生方法论,由OpenCSG(开放传神)提出。AgenticOps是Agentic AI的最佳落地实践也是方法论。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的 一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。