
子图(Subgraphs)
什么是子图?
什么是子图?一句话概括:子图可以作为另一张主图内部的某一个节点。我们结合画图辅助理解,回顾常规流程图结构:一张标准流程图包含 START 起始节点、若干中间业务节点、END 结束节点,节点之间依靠连线配置流转方向,支持串行、路由、并行各类逻辑。而子图的设计思路就是,原图里任意单个节点,都能够被一整张完整的流程图替换,这张用来替换节点的独立流程图,就叫做子图,原来的大图称作主图。


**替换后的执行逻辑为:**主图流转走到原本被替换的节点位置时,不会直接执行单个函数,而是完整进入子图的 START 节点,顺着子图内部节点链路全部执行完毕、走到子图 END 后,再回到主图继续向后运行。
基于这个特性,子图拥有两大工程优势:第一,支持模块化独立开发与单元测试 ,开发阶段可以单独编写、调试子图逻辑,验证无误后再嵌入主图;第二,代码逻辑复用,通用业务逻辑只需要封装成一份子图,多个不同主图都可以重复引用调用,不用重复编写代码。
所以其实在 LangGraph 中,子图是另一个图中的一个节点,可以独立开发测试,也可以被多个主图复用。子图可用于:
- 模块化开发:不同团队可以独立开发不同部分
- 代码复用:相同逻辑的图只需开发一次
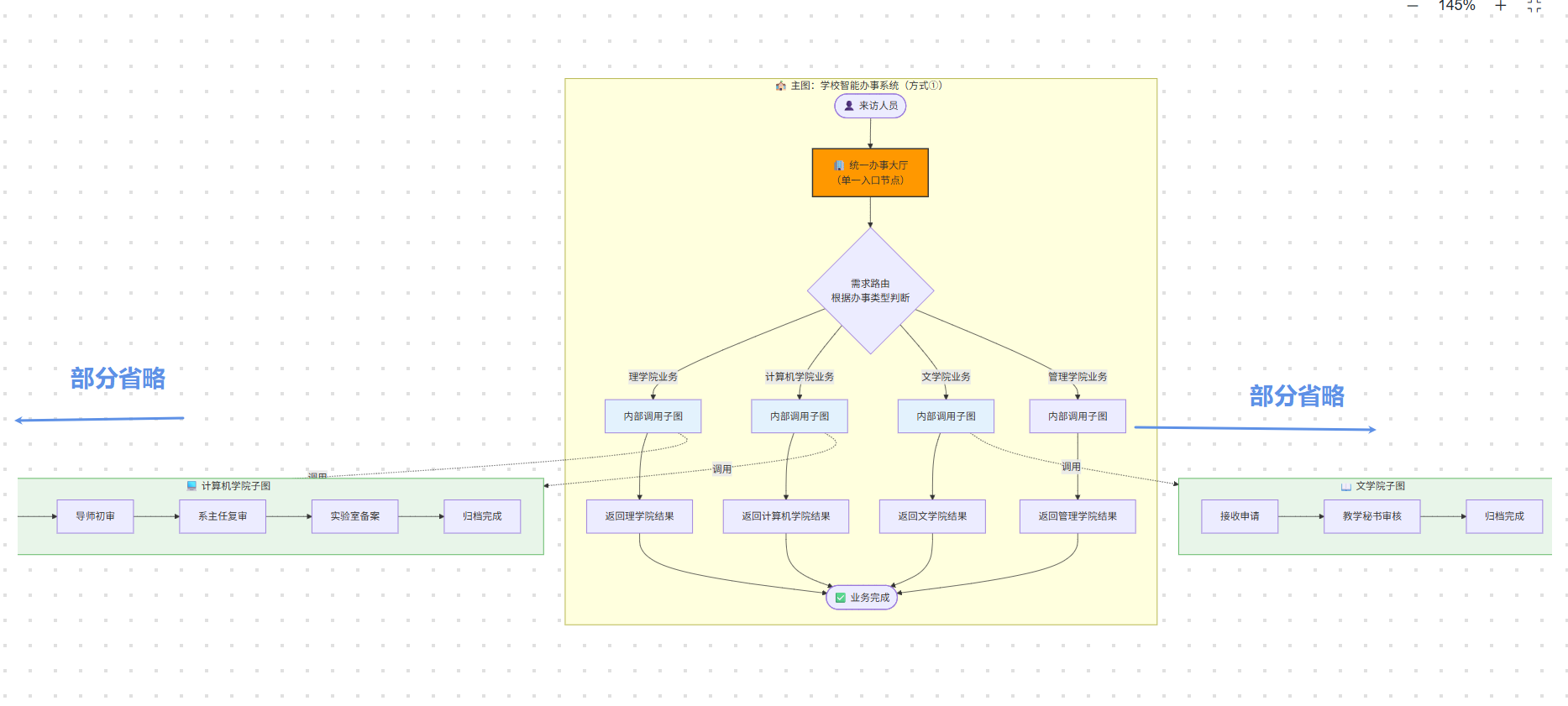
我们用校园办事系统举例具象理解:学校整体智能办事系统是主图,来访人员需要根据办事需求,被路由至理学院、计算机学院、文学院、管理学院、医学院等不同院系办理业务。
每个院系内部的审批流程、步骤、路由规则各不相同,我们就可以把每个院系完整的办事流程各自封装成一张独立子图。
落地有两种业务架构:
**第一种:**学校只设立统一办事大厅(主图单个节点),用户统一进入大厅后,由大厅内部逻辑按需调度、调用对应院系子图完成业务;
**第二种:**学校办事大厅内直接开设各个院系专属办事窗口,各个院系子图直接作为大厅内独立节点,用户可以直接进入对应院系窗口办理业务。
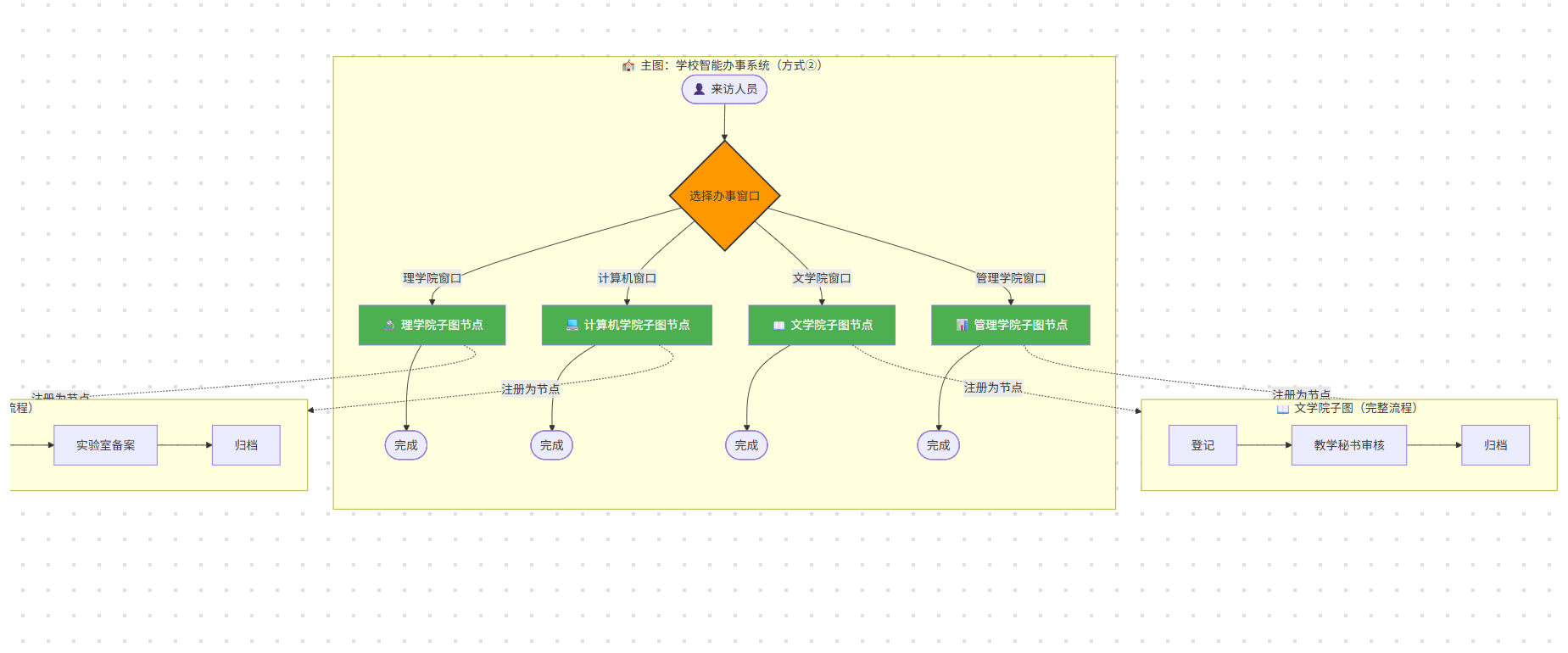
现实中两种架构都合理,对应 LangGraph 里子图的两种使用方式:
①在主图某个节点内部手动调用子图;
②直接把子图注册成主图的普通节点。下面结合两段示例代码,分别拆解两种实现。
使用子图的两种方式
方式一:从节点调用子图(不同状态模式)
核心特点:主图和子图可以定义完全不一样的 State 状态结构,字段互不共用,数据需要手动转换传递 。
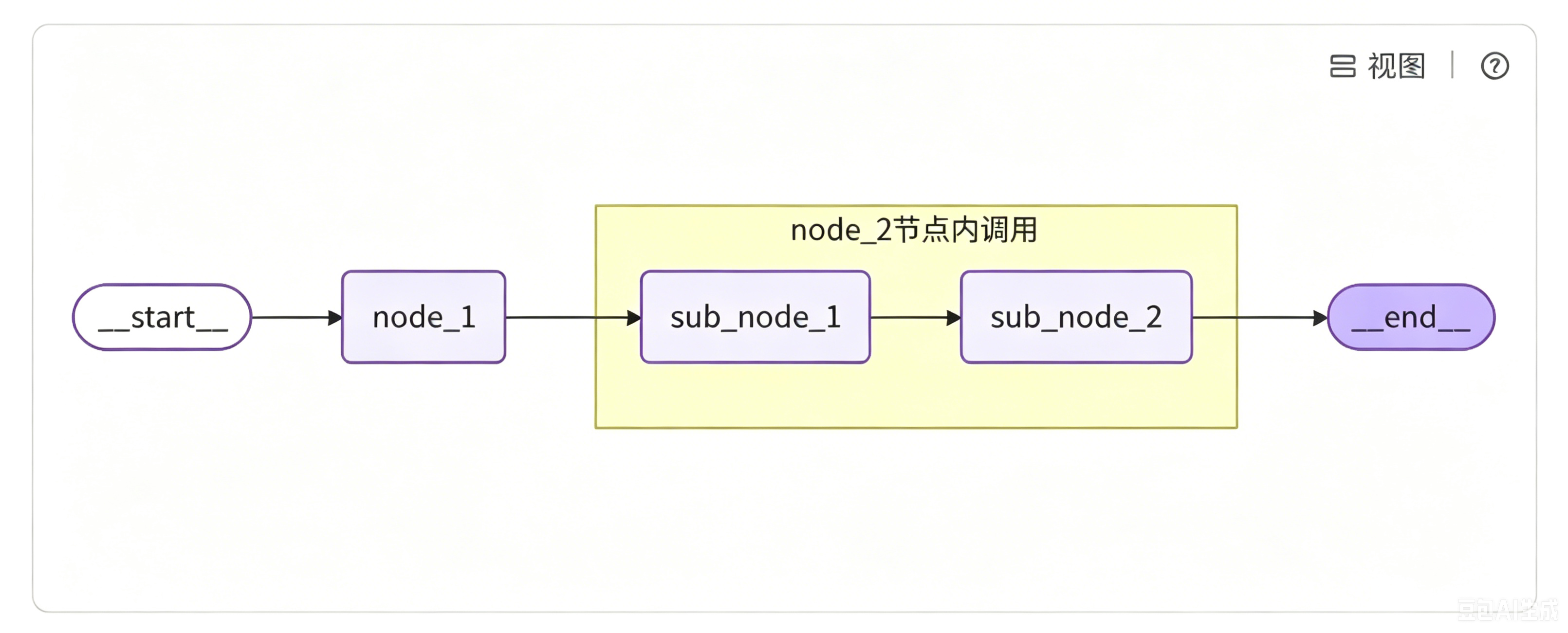
编写顺序为先定义、编译子图,再编写主图。
定义子图 :自定义子图专属状态SubState,包含sub_1、sub_2两个私有字段 ;创建两个子图节点,sub_node_1固定赋值sub_1字段,sub_node_2接收入参sub_2,拼接sub_1的值作为最终结果;
配置子图节点流转链路,最后调用.compile()编译生成可调用的子图实例,子图必须编译完成后才能被外部调用。
python
# 1. 定义子图
class SubState(TypedDict):
# 注意,这些键都不与父图状态共享
sub_1: str
sub_2: str
def sub_node_1(state: SubState):
return {"sub_1": "sub_1"}
def sub_node_2(state: SubState):
return {"sub_2": state["sub_2"] + state["sub_1"]}
sub_builder = StateGraph(SubState)
sub_builder.add_node(sub_node_1)
sub_builder.add_node(sub_node_2)
sub_builder.add_edge(START, "sub_node_1")
sub_builder.add_edge("sub_node_1", "sub_node_2")
subgraph = sub_builder.compile()我们可以先单独执行subgraph.invoke()自测子图运行效果,传入sub_2的入参,查看字段拼接结果。
python
print(subgraph.invoke({
"sub_1": "XXX",
"sub_2": "I am SUB_2 + "
}))
# 输出结果
{'sub_1': 'sub_1', 'sub_2': 'I am SUB_2 + sub_1'}定义主图 :主图状态ParentState仅包含parent一个字段,设计两个主图节点:node_1给入参字符串拼接前缀hi、更新parent;node_2内部通过subgraph.invoke({"sub_2": state["parent"]})手动调用子图,拿到子图执行完成后的全量返回字典,提取字典里sub_2的值,覆盖更新主图的parent字段。
这里是关键: 因为主、子状态隔离,子图内部状态无法自动同步到主图,想要把子图结果给到主图,必须手动提取返回值、赋值给主图状态字段 。
python
# 2. 定义主图
class ParentState(TypedDict):
parent: str
def node_1(state: ParentState):
return {"parent": "hi! " + state["parent"]}
def node_2(state: ParentState):
# 将状态转换为子图状态
response = subgraph.invoke({"sub_2": state["parent"]})
# 将响应转换回父状态
return {"parent": response["sub_2"]}
builder = StateGraph(ParentState)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
graph = builder.compile()执行主图invoke,传入初始parent参数,即可观察数据流转:原始入参经过node_1拼接hi后,作为入参传给子图,子图运算完成后结果回写主图parent。
python
print(graph.invoke({"parent": "parent"}))
# 输出结果 【可以看出没有追加,而是覆盖,这里的覆盖也是由主图更新的结果】
{'parent': 'hi! parentsub_1'}如果使用.stream()流式查看节点变更,默认只会打印主图各个节点的状态更新,看不到子图内部节点执行日志;
python
for chunk in graph.stream({"parent": "parent"}):
print(chunk)
# 输出结果:
{'node_1': {'parent': 'hi! parent'}}
{'node_2': {'parent': 'hi! parentsub_1'}}想要流式输出包含子图全流程,需要在 stream 入参配置subgraphs=True(默认subgraphs=False)。开启后打印的元组第一个元素会标注当前执行层级,子图节点会标注父节点来源(即主图中调用它的node_2),完整展示主、子图每一步状态变更。
python
for chunk in graph.stream({"parent": "parent"}, subgraphs=True):
print(chunk)
# 输出结果:
# ========== 流式输出结果逐行注释 ==========
# 第1行:主图 node_1 执行完成
# 空元组 () 表示在主图层级(没有子图路径)
# node_1 返回了 {'parent': 'hi! parent'}
(
(), # 路径:主图顶层
{'node_1': {'parent': 'hi! parent'}} # 节点名 → 返回值
)
# 第2行:子图内部 sub_node_1 执行完成
# 元组 ('node_2:b558ccdf-...',) 表示:
# - 当前在子图 node_2 内部
# - b558ccdf-6b86-c286-2a1d-9771c9a27dd9 是子图实例的ID(支持同一子图多次调用)
# sub_node_1 返回了 {'sub_1': 'sub_1'}
(
('node_2:b558ccdf-6b86-c286-2a1d-9771c9a27dd9',), # 路径:主图.node_2
{'sub_node_1': {'sub_1': 'sub_1'}} # 子图内部节点名 → 返回值
)
# 第3行:子图内部 sub_node_2 执行完成
# 同样在子图 node_2 内部
# sub_node_2 返回了 {'sub_2': 'hi! parentsub_1'}
# 注意:'hi! parentsub_1' 拼接了父节点传来的 'hi! parent' 和 sub_1 返回的 'sub_1'
(
('node_2:b558ccdf-6b86-c286-2a1d-9771c9a27dd9',),
{'sub_node_2': {'sub_2': 'hi! parentsub_1'}}
)
# 第4行:主图 node_2 执行完成
# 路径回到主图顶层
# node_2 返回了 {'parent': 'hi! parentsub_1'}
# 这个结果聚合了子图内部的计算结果
(
(),
{'node_2': {'parent': 'hi! parentsub_1'}}
)该方式总结: 子图是被主图某个节点通过代码主动调用,主、子状态完全隔离,跨层数据依赖手动转换赋值,后续主图其他节点想要使用子图数据,只能从已经同步到主状态的字段取值。
完整代码:
python
from typing_extensions import TypedDict
from langgraph.graph.state import StateGraph, START
# 1. 定义子图
class SubState(TypedDict):
# 注意,这些键都不与父图状态共享
sub_1: str
sub_2: str
def sub_node_1(state: SubState):
return {"sub_1": "sub_1"}
def sub_node_2(state: SubState):
return {"sub_2": state["sub_2"] + state["sub_1"]}
sub_builder = StateGraph(SubState)
sub_builder.add_node(sub_node_1)
sub_builder.add_node(sub_node_2)
sub_builder.add_edge(START, "sub_node_1")
sub_builder.add_edge("sub_node_1", "sub_node_2")
subgraph = sub_builder.compile()
# 2. 定义主图
class ParentState(TypedDict):
parent: str
def node_1(state: ParentState):
return {"parent": "hi! " + state["parent"]}
def node_2(state: ParentState):
# 将状态转换为子图状态
response = subgraph.invoke({"sub_2": state["parent"]})
# 将响应转换回父状态
return {"parent": response["sub_2"]}
builder = StateGraph(ParentState)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
graph = builder.compile()
# 要在流式输出中包含子图的输出,可以在父图的.stream() 方法中设置 subgraphs=True。
# subgraphs默认为False
for chunk in graph.stream({"parent": "parent"}, subgraphs=True):
print(chunk)输出结果:
python
((), {'node_1': {'parent': 'hi! parent'}})
(('node_2:60e75a5e-41d7-8ec4-915d-afb8f8f62c1c',), {'sub_node_1': {'sub_1': 'sub_1'}})
(('node_2:60e75a5e-41d7-8ec4-915d-afb8f8f62c1c',), {'sub_node_2': {'sub_2': 'hi! parentsub_1'}})
((), {'node_2': {'parent': 'hi! parentsub_1'}})扩展:定义主图、子图、孙子图进行调用。 上述代码中,要在流式输出中包含子图的输出,可以在父图的.stream()方法中设置subgraphs=True。这将从父图和任何子图流式传输输出。
方式二:将子图作为节点(共享状态模式)
这种方式可以将图添加为另一个图中的节点,如下所示:
python
# 子图和主图使用相同的状态结构
# 子图 = 创建子图()
# 直接把子图作为节点加入主图
# 主图.add_node("子图节点", 子图)其特点是:子图和主图共享部分状态。
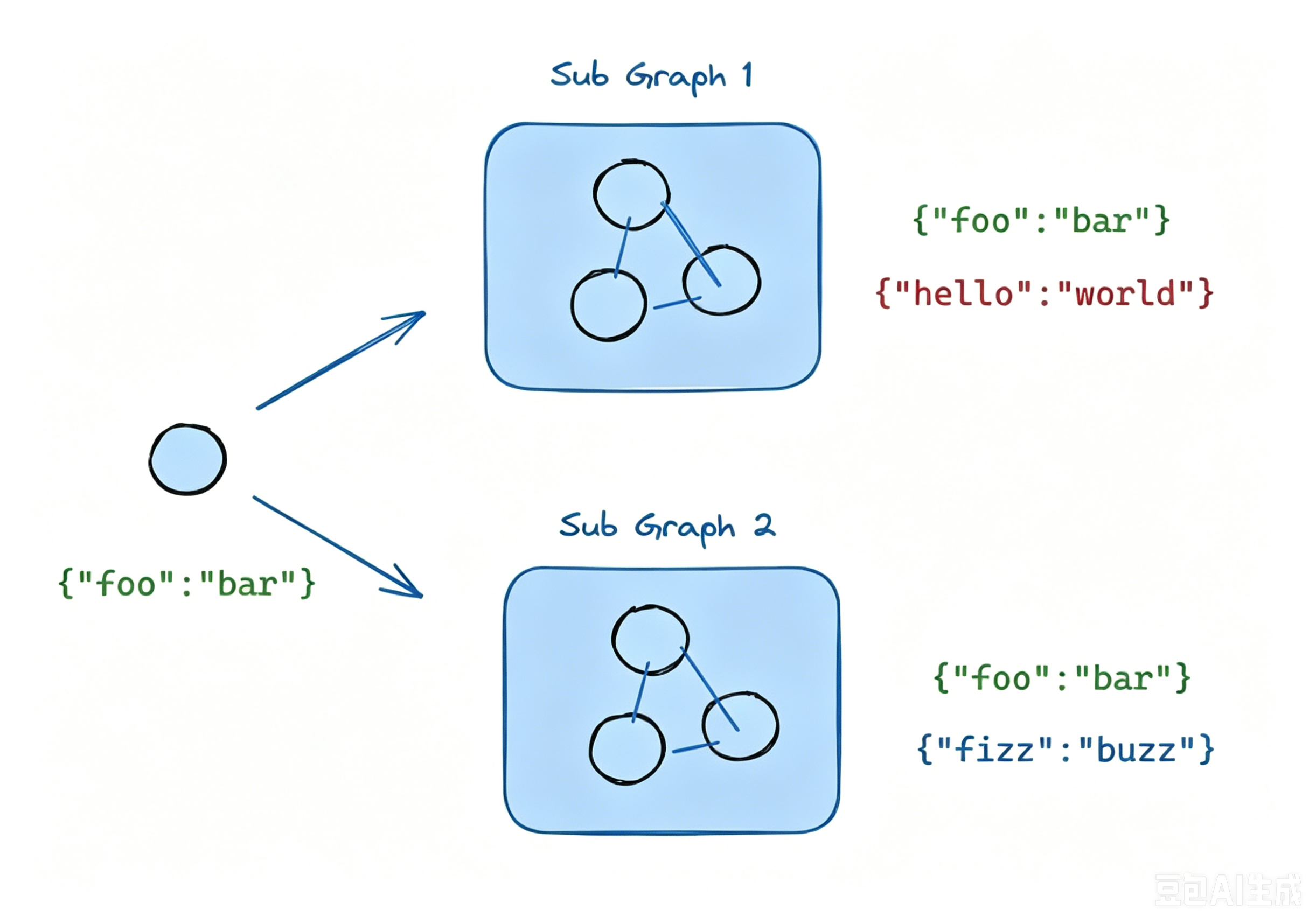
核心特点:主图和子图共用同名的状态字段,子图修改共享字段后,主图状态同步自动变更,私有字段相互隔离 。
同样先编写并编译子图: 子图状态SubState中,parent字段和主图状态字段同名(用于共享数据),sub为子图私有字段;sub_node_1初始化私有字段sub,sub_node_2读取共享字段parent,拼接私有sub后重新回写parent字段。
python
# 1. 定义子图
class SubState(TypedDict):
parent: str # 共享父状态
sub: str # Sub私有
def sub_node_1(state: SubState):
return {"sub": "sub"}
def sub_node_2(state: SubState):
return {"parent": state["parent"] + state["sub"]}
sub_builder = StateGraph(SubState)
sub_builder.add_node(sub_node_1)
sub_builder.add_node(sub_node_2)
sub_builder.add_edge(START, "sub_node_1")
sub_builder.add_edge("sub_node_1", "sub_node_2")
subgraph = sub_builder.compile()单独测试子图invoke,传入parent入参,验证字段拼接逻辑。
python
print(subgraph.invoke({
"parent": "parent",
"sub": "sub"
}))
# 输出结果:
{'parent': 'parentsub', 'sub': 'sub'}再编写主图: 主图状态只保留parent字段,node_1节点给入参拼接hi并更新parent;构建主图链路时,不再在函数内部调用子图,而是直接通过builder.add_node("node2", subgraph),把已经编译好的子图实例直接注册成主图名为node2的普通节点;配置流转:START→node1→node2→END。
python
# 2. 定义主图
class ParentState(TypedDict):
parent: str
def node_1(state: ParentState):
return {"parent": "hi! " + state["parent"]}
builder = StateGraph(ParentState)
builder.add_node("sub_1", subgraph) # 【重点关注】
builder.add_node("node_1", node_1)
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "sub_1")
graph = builder.compile()执行逻辑推演:传入初始值小明,node1执行后parent变为hi小明;流转进入作为节点的子图,子图直接读取共享字段parent=hi小明,内部完成运算后,修改共享parent的值;由于字段共享,子图对parent的修改会自动同步到主图全局状态,子图私有字段sub不会暴露到主图。运行代码后最终主图返回的parent就是拼接完成后的结果,验证了状态共享特性。
该方式使用.stream()同样默认只打印主图节点更新,添加subgraphs=True后,子图内部节点的状态变更也会一并流式输出。
python
for chunk in graph.stream({"parent": "小明"}, subgraphs=True):
print(chunk)
# 输出结果:
((), {'node_1': {'parent': 'hi! 小明'}})
(('sub_1:9152750b-b20b-0490-d11a-7853f2fa5c73',), {'sub_node_1': {'sub': 'sub'}})
(('sub_1:9152750b-b20b-0490-d11a-7853f2fa5c73',), {'sub_node_2': {'parent': 'hi! 小明sub'}})
((), {'sub_1': {'parent': 'hi! 小明sub'}})该方式总结:子图直接挂载为主图节点,同名状态自动共享,无需手动做数据转换,子图私有字段对外不可见,开发写法更简洁。
python
from typing_extensions import TypedDict
from langgraph.graph.state import StateGraph, START
# 1. 定义子图
class SubState(TypedDict):
parent: str # 共享父状态
sub: str # Sub私有
def sub_node_1(state: SubState):
return {"sub": "sub"}
def sub_node_2(state: SubState):
return {"parent": state["parent"] + state["sub"]}
sub_builder = StateGraph(SubState)
sub_builder.add_node(sub_node_1)
sub_builder.add_node(sub_node_2)
sub_builder.add_edge(START, "sub_node_1")
sub_builder.add_edge("sub_node_1", "sub_node_2")
subgraph = sub_builder.compile()
# 2. 定义主图
class ParentState(TypedDict):
parent: str
def node_1(state: ParentState):
return {"parent": "hi! " + state["parent"]}
builder = StateGraph(ParentState)
builder.add_node("sub_1", subgraph)
builder.add_node("node_1", node_1)
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "sub_1")
graph = builder.compile()
for chunk in graph.stream({"parent": "小明"}):
print(chunk)输出结果:
python
{'node_1': {'parent': 'hi! parent'}}
{'sub_1': {'parent': 'hi! parentsub'}}为子图添加短期记忆
如果包含子图,则只需在编译父图时提供checkpointer。LangGraph 会自动将checkpoint传播到子图。
python
from langgraph.graph import START, StateGraph
from langgraph.checkpoint.memory import InMemorySaver
from typing import TypedDict
class State(TypedDict):
foo: str
# 子图
def subgraph_node_1(state: State):
return {"foo": state["foo"] + "|bar"}
subgraph_builder = StateGraph(State)
subgraph_builder.add_node(subgraph_node_1)
subgraph_builder.add_edge(START, "subgraph_node_1")
subgraph = subgraph_builder.compile()
# 主图
builder = StateGraph(State)
builder.add_node("node_1", subgraph)
builder.add_edge(START, "node_1")
checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)所以如果项目需要开启状态记忆、断点续跑,只需要在编译顶层主图时传入 checkpointer 存储器 即可,LangGraph 会自动把检查点配置向下传播到所有嵌套子图,子图编译时不需要重复配置 checkpointer,框架内部自动完成记忆同步,大幅简化多嵌套子图的记忆配置成本。
**注意:**子图不局限于只有主、子两层关系,一张子图内部还可以继续嵌入其他子图,形成多级嵌套(父图→子图→孙图→曾孙图)。层级是相对概念:某张图在一个链路里是被调用的子图,在另一个链路中也可以作为主图调用其他流程图,图与图之间支持任意互相引用,这也是模块化大型 Agent 工作流的核心基础。
引入子图的核心目的就是工程模块化、逻辑复用,复杂业务拆分成多个独立子模块,不同团队分开开发调试,通用逻辑封装复用;两种接入方式按需选型:需要数据自主转换、状态隔离选「节点内手动调用子图」;需要字段自动共享、简化编码选「子图直接注册为主图节点」。
在子图中使用中断
实际上在子图 中我们还可以去使用之前学习过的中断功能,这个中断就是我们之前讲过的人机交互逻辑。在子图中使用中断,本质就是在子图的节点内部调用interrupt这个方法,调用interrupt之后,整个工作流就会临时暂停;后续在程序外部,我们依靠Command完成工作流的恢复,这套中断 + 恢复的逻辑可以完整沿用在子图场景中。
基本用法
在子图中,同样可以使用中断。且添加短期记忆后,可以检查图状态(检查点)。但要注意,只有当子图中断时,才能查看子图状态;恢复后,将无法访问子图形态状态。
恢复时的注意事项
之前讲过,当节点恢复执行时,发起中断的节点会从头再跑一遍。因此,对于中断前的代码,会多重复执行!
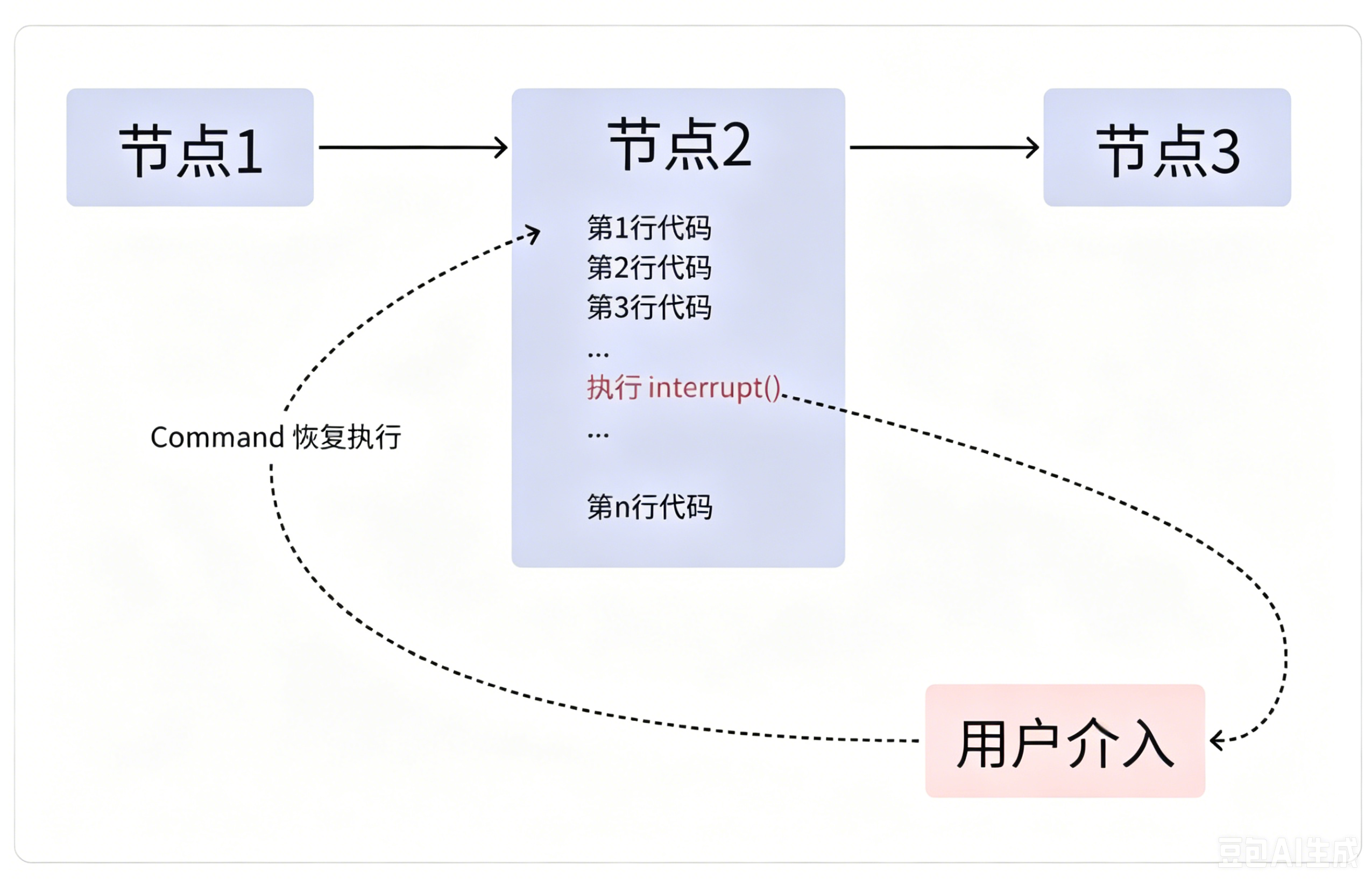
而在子图场景下,子图的不同调用方式有不同的执行结果:
子图使用中断的基础用法和普通节点一致,但有一处关键区别 :结合此前讲到的子图两种调用方式,「主图节点内部手动调用子图」「直接把子图注册成主图普通节点」 ,两种模式在中断恢复阶段的执行表现完全不同。因此下面学习重点,就是对比两种调用方案下,子图触发中断后恢复运行的差异化现象。
将子图作为节点时
首先看第一种场景:直接将子图添加为主图节点(状态共享模式)。
python
from langgraph.graph import START, StateGraph
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import interrupt, Command
from typing_extensions import TypedDict
# ============================================================================
# 1. 定义共享状态结构
# ============================================================================
class State(TypedDict):
"""主图和子图共享的状态结构"""
foo: str # 一个字符串字段,用于演示数据传递
# ============================================================================
# 2. 构建子图
# ============================================================================
def subgraph_node_1(state: State):
"""子图的第一个节点 - 普通执行节点"""
print("sub_node_1") # 控制台输出,表示该节点被执行
return {} # 不修改状态,返回空字典
def subgraph_node_2(state: State):
"""子图的第二个节点 - 包含中断的节点
关键点:
- interrupt() 会暂停整个图(主图+子图)的执行
- interrupt() 的参数会作为"中断提示"返回给调用方
- 恢复执行时通过 Command(resume=...) 传入的值会作为 interrupt() 的返回值
"""
print("sub_node_2")
# interrupt("输入值:") 会做两件事:
# 1. 立即暂停当前图的执行
# 2. 将字符串 "输入值:" 作为中断信息返回
# 3. 等待外部调用 Command(resume=...) 恢复
value = interrupt("输入值:") # 这里会暂停!等待用户输入
# 恢复执行后,value 就是 Command(resume=...) 中传入的值
# 更新状态:将新输入的值拼接到原来的 foo 后面
return {"foo": state["foo"] + value}
# 创建子图构建器
subgraph_builder = StateGraph(State)
# 添加子图节点
subgraph_builder.add_node(subgraph_node_1) # 节点1:普通执行
subgraph_builder.add_node(subgraph_node_2) # 节点2:包含中断
# 定义子图的边(执行顺序)
subgraph_builder.add_edge(START, "subgraph_node_1") # 开始 → 节点1
subgraph_builder.add_edge("subgraph_node_1", "subgraph_node_2") # 节点1 → 节点2
# 编译子图(子图不需要 checkpointer?实际如果需要子图独立断点续传也需要)
# 但这里子图的中断会通过主图传播,主图有 checkpointer 就足够了
subgraph = subgraph_builder.compile()
# ============================================================================
# 3. 构建主图
# ============================================================================
builder = StateGraph(State)
# 关键:将整个子图作为一个节点添加到主图中
# 这意味着主图的 "node_1" 节点就是完整的子图
builder.add_node("node_1", subgraph)
# 定义主图的边:开始 → 子图节点
builder.add_edge(START, "node_1")
# 创建 checkpointer(内存存储,用于保存中断状态)
# 有了 checkpointer,图可以在中断后恢复执行
checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)
# 配置 thread_id(用于区分不同的会话/线程)
# 同一个 thread_id 可以恢复之前的执行状态
config = {"configurable": {"thread_id": "1"}}
# ============================================================================
# 4. 执行流程演示
# ============================================================================
# ----------------------------------------------------------------------------
# 4.1 第一次调用:会触发中断
# ----------------------------------------------------------------------------
graph.invoke({"foo": "哈哈"}, config)
# ----------------------------------------------------------------------------
# 4.2 获取当前状态(仅在中断时有效)
# ----------------------------------------------------------------------------
parent_state = graph.get_state(config)
# 说明:获取主图的状态快照,此时子图处于中断状态
# ----------------------------------------------------------------------------
# 4.3 访问子图内部状态(只能在中断期间访问)
# ----------------------------------------------------------------------------
# 【重要】只能在子图被中断时才可访问子图状态
# 一旦恢复了图,将无法访问子图状态
#
# 代码解析:
# graph.get_state(config, subgraphs=True) - 获取包含子图的状态
# .tasks[0] - 当前正在执行的任务(即被中断的任务)
# .state - 该任务的状态(即子图的当前状态)
#
subgraph_state = graph.get_state(config, subgraphs=True).tasks[0].state
print(subgraph_state)
# ----------------------------------------------------------------------------
# 4.4 恢复执行:传入中断所需的值
# ----------------------------------------------------------------------------
# Command(resume="bar") 的作用:
# 1. 告诉中断的 interrupt() 以 "bar" 作为返回值继续执行
# 2. 图会从上次中断的位置继续运行
#
# 执行流程回顾:
# - 第一次调用:foo="" → 进入子图 → sub_node_1 → sub_node_2 → interrupt("输入值:")
# - 恢复调用:Command(resume="bar") → interrupt() 返回 "bar" → state["foo"] + "bar" = "" + "bar" = "bar"
# - 最终状态:{"foo": "bar"}
#
print(graph.invoke(Command(resume="bar"), config))-
代码里子图与主图共用同一份
State状态定义,状态内的foo字段父子图共享; -
主图编译环节采用第二种子图接入方式,不通过主图节点代码手动调用子图,而是直接把编译完毕的子图挂载成主图的单个节点。
-
子图内部一共配置两个节点,流转链路:
START → sub_node_1 → sub_node_2 → END。 -
sub_node_1内部仅做日志打印,用来标识当前节点被执行; -
sub_node_2除打印日志外,核心逻辑是调用interrupt方法,在子图节点内部触发流程中断。
从流程图结构来看: 整张子图被封装成主图里唯一的node1节点,主图链路简化为START → node1(子图整体) → END。我们最终运行时启动的是主图,传入初始化参数,给共享字段foo赋值""。
想要正常启用中断功能,主图编译时必须注入checkpointer检查点存储器,同时调用.invoke()执行的时候,需要在config配置项里填写唯一的thread_id线程编号,这是开启断点续跑、中断恢复的前置配置,也是之前线程持久化模块讲过的必备内容。
子图在sub_node_2触发中断时,等同于主图在node1节点位置整体暂停。中断触发后程序会阻塞,等待外部传入恢复值,拿到Command携带的返回值后,把新值和原始foo的历史数据拼接,重新覆盖更新foo字段,字段更新完成后子图全流程收尾,主图随之执行结束。
执行首轮.invoke(),程序正常走完sub_node_1打印日志,运行至sub_node_2触发中断,控制台生成携带提示信息"输入入值:"的Interrupt中断对象。
此时调用Command(resume="bar", config=config)执行流程恢复,观察打印日志:恢复后只有sub_node_2的日志重复输出一遍。 原因是此前的知识点:中断恢复时,触发中断的节点会从头完整重跑一次,中断之前已经执行完毕的节点不会重复运行。
所以本场景里只有发起中断的sub_node_2二次执行,sub_node_1不再重复运行,该执行现象符合框架设计逻辑。【将子图作为节点时的效果示例】
补充回顾中断底层机制:每次触发中断会在框架内部的中断记录表新增记录,完成一次 resume 恢复后,对应中断条目被标记为已完成,节点再次运行时不会重复触发中断,我们只需记住这个底层规则即可。
结果如下:
python
sub_node_1
sub_node_2
StateSnapshot(
values={'foo': ''},
next=('subgraph_node_2',),
config={...},
metadata={...},
parent_config={...},
tasks=(
PregelTask(
id='4afcaec2-1fd1-7bfc-cab9-dcd3f1b6980d',
name='subgraph_node_2',
path=('__pregel_pull', 'subgraph_node_2'),
error=None,
interrupts=(
Interrupt(
value='输入值:',
id='f62f6bce645a53af213c432eee562e49'
),
),
state=None,
result=None
),
),
)
interrupts=(Interrupt(value='输入值:',id='f62f6bce645a53af213c432eee562e49'),)
sub_node_2
{'foo': 'bar'}节点内调用子图时
接下来切换第二种场景:在主图的节点函数内部手动调用子图(状态隔离模式)。
重新编写一版主图逻辑,依旧沿用原来的State类型定义,主图仅保留一个node1节点,节点内部先打印node1的执行日志,再通过subgraph.invoke()手动调用已经编译好的子图,把子图运行所需的入参{"foo": state["foo"]}传入,接收子图运行结束返回的结果字典result,最后提取result["foo"],赋值覆盖主图自身的foo字段。
主图流转链路:START → node1 → END,不再将子图直接注册为主图节点。
python
from langgraph.graph import START, StateGraph
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import interrupt, Command
from typing_extensions import TypedDict
class State(TypedDict):
foo: str
# 子图
def subgraph_node_1(state: State):
print("sub_node_1")
return {}
def subgraph_node_2(state: State):
print("sub_node_2")
value = interrupt("输入值:")
return {"foo": state["foo"] + value}
subgraph_builder = StateGraph(State)
subgraph_builder.add_node(subgraph_node_1)
subgraph_builder.add_node(subgraph_node_2)
subgraph_builder.add_edge(START, "subgraph_node_1")
subgraph_builder.add_edge("subgraph_node_1", "subgraph_node_2")
subgraph = subgraph_builder.compile()
# 主图
def node_1(state: State):
print("node_1")
response = subgraph.invoke({"foo": state["foo"]})
return {"foo": response["foo"]}
builder = StateGraph(State)
builder.add_node("node_1", node_1)
builder.add_edge(START, "node_1")
graph = builder.compile(checkpointer=InMemorySaver())
config = {"configurable": {"thread_id": "1"}}
graph.invoke({"foo": ""}, config)
print(graph.invoke(Command(resume="bar"), config))这里着重区分两种模式的状态差异: 即便主图和子图的状态类同名、字段都叫foo,但在「节点内手动调用子图」模式下,父子图的foo字段互相独立、数值完全隔离 ,类比之前学院办事系统举例:两个独立的业务流程,状态字段命名一致,但各自的数据互不干扰,子图内部修改foo不会同步到主图,想要同步数据只能手动提取子图返回值、赋值给主图状态,这也是本场景中result["foo"]回写主图foo的代码意义。而第一种把子图作为主图节点的模式,所有子图同属一份主图全局状态,同名字段天然共享修改。
保持子图代码完全不变,依旧在sub_node_2里使用interrupt触发中断,配置相同的checkpointer与thread_id,首次执行主图:程序先走主图node1打印日志,在node1内部触发子图调用,依次打印sub_node_1、sub_node_2,随后在sub_node_2触发流程中断,同样生成输入值的中断提示。
继续使用Command(resume="bar", config=config)恢复运行,此时出现和第一种场景不一样的日志:除了触发中断的sub_node_2重复打印日志,主图中调用子图的node1节点也完整重新执行了一遍 。【节点内调用子图时的效果示例】
打印结果:
python
sub_node_1
sub_node_2
node_1 # 主图节点重新执行
sub_node_1
sub_node_2 # 子图节点重新执行
{'foo': 'bar'}可以看到不仅是调用中断的子节点重新执行,就连调用子图的主图节点也会被重新调用!
由此总结核心区别:
-
子图直接作为主图节点:子图中断恢复,仅触发中断的子图节点重跑,主图节点不会重复执行;
-
主图节点内部手动调用子图:子图中断恢复,不仅子图里触发中断的节点重跑,调用子图的上层主图节点也会整体重新执行。
这个结论是子图搭配中断开发的重点,如果开发时忽略该特性,node1中包含写入数据库、接口请求等幂等性较差的代码,恢复流程时重复执行就会产生脏数据、重复请求等 BUG。以上就是子图内部使用中断的关键注意事项。