一、写在前面
之前在「人在途中」系列中,分享了一些工具链使用过程中的经验与踩坑笔记。这一篇想做一个补充:不讲算法、不讲优化,只讲基础但极其影响效率的使用方式。
因为我觉得很多问题不是能力问题,而是使用方式的问题。
古人说得很直接:
工欲善其事,必先利其器。
希望这篇文章帮你把"器"用顺。
二、工具链发布包到底包含什么(必须搞清楚)
这是很多人第一步就忽略的点,但其实是根本问题。
每次工具链发布,本质上是一个**完整的软件套件(Toolchain Suite)**,通常包含:
- Docker 镜像:提供工具链使用和运行的基本环境,方便快速部署。为适应不用用户的使用需求,docker 内的组件比较多,可用户模型量化和模型训练、部署编译等,该镜像即为 GPU 镜像,但是也有不少的伙伴因为工作分工等不同,不需要模型训练等环境,为了减少模型体积,移除不必要的组件,官方也提供了轻量的 CPU 版本镜像。两个镜像客户课按需取用,如果开始不知道自己将来的动作,推荐直接安装 GPU 版本即可。
- OE 包:该包为示例包,提供了工具链基本使用流程 PTQ/QAT/部署等方面的开发示例,配套 docker 的-v 参数挂载后,可以在 docker 环境中快速使用这些示例
- 文档(docs):指导大家在工具两使用过程中的基本使用流程和基本功能、工具、配置方法、模型约束和工具链 API 的的说明。
- 文档:release_note 变动说明和使用须知.pdf
👉 本质理解:
工具链 ≠ 一个工具,而是一整套工具和链路(环境-示例-指导手册, 模型生产-模型量化-模型部署)
如果你只会用其中一部分,你的效率一定上不去。
三、拿到发布包,如何最快"跑起来"
不要一上来就研究算子支持、精度问题,这是典型误区。
正确顺序是:
Step 1:先看文档(重点:环境部署)
不要全看,重点看:
- 环境要求
- docker 使用方式
- 示例入口
Step 2:把环境跑起来(优先 docker)
只要环境没问题,后面一切都好说。
Step 3:按顺序走一遍链路(非常关键)
建议顺序:
- PTQ 快速入门
- QAT 快速入门
- UCP / 示例工程
- 完整推理流程
👉 目标不是理解细节,而是:
把整条链路"打通一遍"
核心原则
先跑通,再优化;先整体,再细节
四、环境部署:为什么强烈建议 Docker
如果你是新手,这里我给你一个非常明确的结论:
不要犹豫,直接用 Docker
原因很现实:
优点(都是踩坑总结)
- 环境隔离
- 不受宿主机污染
- 不怕依赖冲突
- 多版本共存
- J5 / J6 / X5 可以同时存在
- 不用反复重装
- 可快速恢复
- 环境搞坏了 → 直接删容器重建
- 可并行使用
- 多个容器互不影响
什么时候不建议 Docker?
只在两种情况下:
- 原始工程本身就在 Docker 中(避免套娃)
- 需要强依赖宿主机硬件能力(如某些加速)
五、不要用 run_docker.sh 脚本,直接手动构建容器
OE 包里提供的 run 脚本有个-rm 参数:
容器退出就销毁,其中如果有什么配置也一并消失了
这在实际开发中非常不好。
推荐方式
👉 手动 docker run,长期复用容器
如下为构建容器时的完整模板,可供参考例如(J6 GPU):
Plain
docker run -dit --gpus all --shm-size="15g" \
-v $HOME/work/docker-data/AiToolchain/j6:/data \
-v $HOME/work/docker-data/AiToolchain/dataset:/data_set \
--privileged=true \
--name j6-3500 --hostname=j6-3500 \
openexplorer/ai_toolchain_ubuntu_22_j6_gpu:v3.5.0_rc3这些命令在附件中已经整理得很全
六、Docker 挂载(-v)设计:这是效率关键点
这一点是经验价值最高的部分之一。
推荐目录结构(非常建议照做)
Plain
docker-data/
├── AiToolchain/
│ ├── j5/
│ ├── j6/
│ ├── x5/
│ └── dataset/
├── common/挂载策略
Plain
-v /xxx/j6:/data
-v /xxx/dataset:/dataset
-v /xxx/common:/common这样设计的好处
- 命令统一
- 每次构建新的容器只换 image 和 name
- 跨版本复用
- 不同 OE 版本共享数据,可以在新的版本中查看和使用不同版本 OE 包内的情况。
- 数据集统一管理
- 数据集是共用的,不重复复制
- 模型可迁移
- 老版本模型直接复用
一个细节(很多人会踩坑)
容器默认路径是 /open_explorer
但你现在挂载在 /data
👉 解决方案:
Plain
rm -rf /open_explorer
ln -s /data/horizon_j6_open_explorer_vxxx /open_explorer👉 本质:恢复原有使用习惯
七、建议增加一个 Common 挂载目录(强烈推荐)
Plain
-v /xxx/common:/common用途
可以放:
- SSH key(复用宿主机权限)
- 常用脚本
- DSP 安装包
- debug 工具
- 内部工具
👉 价值:
不同容器共享"工作资产",而不是每个容器重新配置
八、远程调试
你附件里已经给出了完整流程,这里提炼核心:
容器内使用 HOST 的 pub_key
Plain
mkdir ~/.ssh
cp /common/ssh/* ~/.sshVSCode Remote 连接
vscode 中安装"Dev Containers"后,先通过 ssh 与服务器建立连接下(如下),然后通过开发容器便可以查看和新构建的容器环境了。 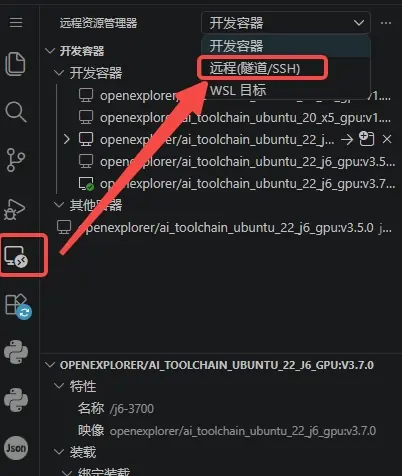
👉 一旦打通:
你就不再是在"容器里干活",而是在"IDE 里干活"
效率提升是质变。
配置本地的 pub key 到
细心的用户可能发现,windows 使用 ssh 连接远程服务器,每次都要输入密码,非常麻烦,这里提供一组命令解决该问题。
核心步骤:
- 生成 key 直接在 VSCODE 控制台(实际就是 PowerShell)执行:b)
Plain
ssh-keygen -t rsa -C 'xxxx@xxx.com'输入命令后, 回车两次,直到命令结束,会在 ~/。ssh 目录下生成 RSA 密钥对(私钥 id_rsa、公钥 id_rsa.pu
- 将公钥添加到远程服务器并配置 authorized_keys
Plain
function ssh-copy-id([string]$userAtMachine, $args){
$publicKey = "$ENV:USERPROFILE" + "/.ssh/id_rsa.pub"
if (!(Test-Path "$publicKey")){
Write-Error "ERROR: failed to open ID file '$publicKey': No such file"
} else {
& cat "$publicKey" | ssh $args $userAtMachine "umask 077; test -d .ssh || mkdir .ssh ; cat >> .ssh/authorized_keys || exit 1"
}
}
ssh-copy-id -p 22 root@server_ip
- 注意:ssh-copy-id -p 22 root@server_ip 中的 server_ip,端口(22),用户名(root)需要与自己的环境一致。
这样处理后,再次登录同一个服务器的 ssh 和 docker,都不会要求输入密码了。
九、一些额外但很实用的习惯
不要在容器里乱改环境
改了就不可复现
每个版本单独容器
不要混用
所有重要操作脚本化
比如:
Plain
sh build_env.sh
sh run_ptq.sh数据与代码分离
避免污染
十、总结(核心就三句话)
- 先跑通整条链路,而不是盯着一个点
- 环境稳定比什么都重要(Docker 优先)
- 目录结构和挂载设计决定你的效率上限
结尾
这篇内容不复杂,但都是实战里反复验证过的经验。
如果你刚开始用工具链,这些能帮你少走很多弯路;
如果你已经在用,建议对照看看有没有可以优化的地方。