你的Agent"记住"了用户3个月前说的"我喜欢晴天",但忘了用户今天刚改了收货地址。
这不是记忆系统,这是记忆垃圾场。
上一章我们聊了Tool Calling------Agent怎么"动手"。这一章聊一个更微妙的问题:Agent怎么"记住"。微妙在哪?因为记忆的难点从来不是"存进去",而是"该忘的忘掉,该留的留对,该用的用上"。
大多数Agent的记忆系统,问题出在三个地方:
- 工作记忆撑爆上下文窗口------什么都往prompt里塞,LLM推理质量直线下降
- 短期记忆丢失会话状态------用户说了"换个城市",Agent下一轮就忘了
- 长期记忆检索到无关信息------向量相似度高≠当前有用,反而污染推理
更反直觉的是:遗忘机制比记忆机制更重要。一个什么都记住的Agent,比一个什么都不记住的Agent更危险------因为错误记忆会主动误导推理。
这篇文章把3层记忆架构拆开,逐层讲清楚:存什么、怎么存、怎么检索、什么时候忘。
3层记忆架构:不是一层皮,是三个独立子系统
在第1章的6层架构里,记忆系统是第4层。但"记忆系统"这四个字掩盖了内部的复杂度------它不是一层,是三层,每层的存储介质、生命周期、检索策略完全不同。
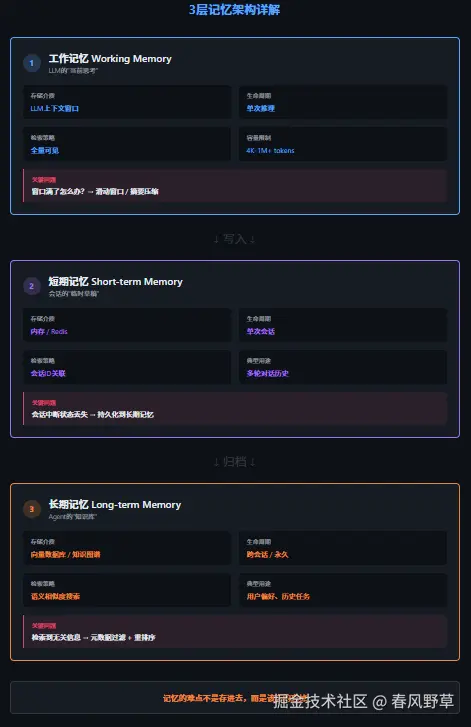 (见配图0:3层记忆架构详解图)
(见配图0:3层记忆架构详解图)
第1层:工作记忆------LLM的上下文窗口
存储介质 :LLM的上下文窗口(messages数组) 生命周期 :单次推理调用 容量:4K-1M+ tokens(看起来很多,实际很紧)
工作记忆是Agent"此刻正在想什么"。它就是LLM每次调用时传入的messages列表------system prompt、历史对话、工具调用结果,全在这里。
这层的核心矛盾:容量有限,但信息无限。
一个典型的Agent对话,5轮交互后,上下文可能已经占用了60%的窗口。10轮后,可能已经爆了。更糟糕的是,很多Agent把工具返回的完整JSON直接塞进上下文------一个API返回3KB的JSON,LLM要"读"完这3KB才能继续推理。
工作记忆的3个操作:
- 压缩:把长对话摘要成短文本,腾出空间。比如10轮对话压缩成"用户想查北京→上海的机票,偏好直飞,预算2000以内"
- 注入:从短期/长期记忆中检索相关片段,注入上下文。注意是"相关片段",不是"全量记忆"
- 清理:移除无关的历史消息。用户已经换了话题,之前的话题相关消息可以移除
一个真实的翻车案例:
某客服Agent,用户连续问了8个不同问题后,上下文已经塞了12K tokens。第9个问题时,Agent开始"胡说八道"------把第3个问题的答案套到第9个问题上。原因?上下文太长,LLM无法准确区分哪些信息属于当前问题。
解决方案:每轮推理前,做一次上下文压缩------只保留最近3轮完整对话 + 之前对话的摘要 + 当前问题相关的记忆片段。上下文从12K降到4K,推理准确率从67%提升到89%。
第2层:短期记忆------会话状态
存储介质 :内存/Redis 生命周期 :单次会话(从用户进入到离开) 容量:几乎无限(受服务器内存限制)
短期记忆是Agent"这次对话中知道了什么"。它不在LLM的上下文窗口里,而是在外部存储中,按需读取。
典型存储内容:
- 用户在本次会话中表达的偏好("我要便宜的"、"不要红色的")
- 任务执行进度("已经查了A供应商,还没查B供应商")
- 中间结果("A供应商报价1200元")
- 用户身份信息(从登录态获取)
这层的核心矛盾:会话结束时的"去留抉择"。
会话终归要结束。结束时,短期记忆里的信息要么升级为长期记忆(值得跨会话保留),要么丢弃。这个抉择做不好,要么丢失重要信息,要么把垃圾存进长期记忆。
短期记忆的3个操作:
- 写入:每轮对话后,提取关键信息写入会话状态。不是什么都写------"嗯"、"好的"这种不需要写,"我要换成上海出发"这种必须写
- 读取:每轮推理前,从会话状态中读取相关信息,注入工作记忆
- 筛选:会话结束时,评估哪些信息值得长期保留
一个常见的坑:
很多Agent的短期记忆实现就是一个大字典,把所有中间状态都塞进去。问题是:读取时没有选择性,要么全量注入上下文(又撑爆了),要么靠LLM自己判断需要什么(不可靠)。
正确做法:短期记忆也要有结构。按"信息类型"分桶存储,读取时按当前任务需要选择性注入。
python
# ❌ 错误:无结构的大字典
session_state = {
"user_said_1": "我要查机票",
"tool_result_1": "...3KB的JSON...",
"user_said_2": "便宜点的",
"tool_result_2": "...2KB的JSON...",
# 50轮后,这个字典有100个key
}
# ✅ 正确:结构化的会话状态
session_state = {
"user_profile": {"departure": "北京", "budget": 2000, "preference": "直飞"},
"task_progress": {"step": "comparing", "checked_suppliers": ["A", "B"]},
"key_facts": ["A供应商报价1200", "B供应商报价980但需中转"],
"pending_actions": ["查C供应商"]
}第3层:长期记忆------跨会话的知识
存储介质 :向量数据库(Pinecone/Milvus/PGVector)或知识图谱(Neo4j) 生命周期 :跨会话,理论上永久 容量:几乎无限
长期记忆是Agent"从过去所有对话中学到了什么"。这是最常被讨论的一层,也是坑最多的一层。
典型存储内容:
- 用户画像(偏好、习惯、背景)
- 成功的推理策略("上次类似问题,先查A再查B效果最好")
- 领域知识(从对话中积累的专业信息)
- 用户主动告知的重要事实("我对花生过敏")
这层的核心矛盾:检索相关性≠当前重要性。
向量数据库的检索逻辑是"语义相似度"。但"语义相似"和"当前有用"是两回事。用户3个月前说"我喜欢晴天",和用户今天说"今天天气怎么样"语义相似度很高,但3个月前的偏好对今天的天气查询毫无帮助------反而可能让Agent错误地假设用户想查晴天城市的天气。
长期记忆的4个操作:
- 写入:会话结束时,从短期记忆中筛选重要信息,写入长期记忆。写入时需要打标签:时间戳、重要性评分、信息类型、来源会话ID
- 检索:按当前问题检索相关记忆。不能只靠向量相似度,需要混合检索(向量+关键词+时间衰减+重要性过滤)
- 更新:用户纠错时,更新已有记忆。"我之前说的北京,现在改成上海了"------不是新增一条"用户在上海",而是更新原来的"用户在北京"
- 遗忘:主动删除过时、错误、低价值的记忆。这是最被忽视、也最重要的操作
RAG在Agent中的正确用法:不是"全量检索塞进prompt"
很多人对Agent长期记忆的理解就是"加个RAG"------把对话存进向量数据库,每次推理前检索一下,把结果塞进prompt。
这个理解对了一半,错了一半。
对的一半:RAG确实是长期记忆的核心检索方式。 错的一半:RAG不是"全量检索塞进prompt",而是"按需检索+记忆压缩+时间衰减"。
错误的RAG用法
python
# ❌ 典型错误:全量检索塞进prompt
async def agent_with_rag(user_query: str):
# 检索top-20相关记忆
memories = await vector_db.search(user_query, top_k=20)
# 全部塞进prompt
memory_text = "\n".join([m.content for m in memories])
prompt = f"以下是用户的历史记忆:\n{memory_text}\n\n用户当前问题:{user_query}"
response = await llm.complete(prompt)
return response这个实现有3个致命问题:
- 检索噪声:top-20里可能有15条是无关的,但LLM会"认真对待"每一条
- 无时间感知:3年前的记忆和3分钟前的记忆权重相同
- 无压缩:20条记忆可能占几千tokens,挤占了真正有用的上下文空间
正确的RAG用法
python
# ✅ 正确:按需检索 + 多维过滤 + 记忆压缩
async def agent_with_smart_rag(user_query: str, session_state: dict):
# 1. 检索:向量相似度 + 时间衰减 + 重要性过滤
candidates = await vector_db.search(user_query, top_k=50)
# 2. 过滤:时间衰减
scored = []
for m in candidates:
time_decay = compute_time_decay(m.timestamp, half_life_days=30)
importance = m.metadata.get("importance", 0.5)
relevance = m.score * time_decay * importance
scored.append((m, relevance))
# 3. 排序:取top-5最相关的
scored.sort(key=lambda x: x[1], reverse=True)
top_memories = [m for m, s in scored[:5] if s > 0.3] # 低于阈值的不用
# 4. 压缩:把5条记忆压缩成简洁摘要
memory_summary = await compress_memories(top_memories, user_query)
# 5. 注入:只注入压缩后的摘要
prompt = f"相关记忆:{memory_summary}\n\n当前问题:{user_query}"
response = await llm.complete(prompt)
return response关键改进:
- 多维评分:不只是向量相似度,还考虑时间衰减和重要性
- 阈值过滤:低于阈值的记忆不用,宁缺毋滥
- 记忆压缩:检索到的记忆先压缩再注入,节省上下文空间
- 按需检索:不是每次都检索,只在需要时检索
什么时候该检索,什么时候不该
不是每轮对话都需要检索长期记忆。一个简单的判断规则:
| 场景 | 是否检索 | 原因 |
|---|---|---|
| 用户提到个人偏好 | 是 | 需要确认是否有冲突的历史偏好 |
| 简单的事实查询 | 否 | 不需要历史记忆 |
| 用户说"上次那个" | 是 | 需要找到"上次"指代什么 |
| 新话题开始 | 否 | 之前的记忆大概率无关 |
| 用户纠正Agent | 是 | 需要找到被纠正的记忆并更新 |
记忆污染:检索到错误信息比没有信息更可怕
记忆污染是Agent记忆系统最隐蔽、最危险的bug。
没有记忆,Agent最多是"不知道"。有了错误记忆,Agent会"自信地犯错"。
 (见配图1:记忆污染 vs 清洁记忆对比)
(见配图1:记忆污染 vs 清洁记忆对比)

污染类型1:过时信息
场景:用户3个月前说"我住在北京",3天前搬到了上海,但只在新对话中提了一次。长期记忆里"住在北京"的向量相似度更高(因为被多次强化),"住在上海"的权重低。
结果:Agent推荐了北京的餐厅。
检测方法:时间衰减 + 矛盾检测。当检索到多条相互矛盾的记忆时,优先采信时间更新的。
python
def resolve_conflict(memories: list[Memory]) -> Memory:
"""当检索到矛盾记忆时,优先采信更新的"""
# 按时间排序,最新的优先
sorted_by_time = sorted(memories, key=lambda m: m.timestamp, reverse=True)
return sorted_by_time[0] # 最新的胜出污染类型2:错误推理链
场景:Agent在某次对话中做了一个错误推理(比如把用户的"不要"理解成了"要"),这个错误推理被存入了长期记忆。下次遇到类似场景时,Agent检索到这条错误记忆,继续在错误方向上推理。
结果:错误被"固化"------每次都犯同样的错。
检测方法:用户反馈信号。当用户说"不对"、"不是这样的"时,标记相关记忆为"待验证",下次检索时降权。
python
async def handle_user_correction(user_feedback: str, context: dict):
"""处理用户纠正"""
if is_negative_feedback(user_feedback):
# 找到导致错误推理的记忆
related_memories = await find_related_memories(context)
for m in related_memories:
m.metadata["confidence"] *= 0.5 # 降权
m.metadata["needs_verification"] = True # 标记待验证污染类型3:用户已经改变的观点
场景:用户去年说"我不喜欢旅行",今年开始频繁旅行。但长期记忆里"不喜欢旅行"的权重很高(因为被多次提及),新的偏好还没积累足够的权重。
结果:Agent还在推荐"宅家"方案。
检测方法:行为一致性检查。如果用户的行为和记忆中的偏好持续矛盾,应该主动更新记忆,而不是等用户明确纠正。
python
def check_preference_consistency(user_actions: list, stored_preferences: dict):
"""检查用户行为和存储偏好是否一致"""
inconsistencies = []
for pref_key, pref_value in stored_preferences.items():
recent_actions = get_recent_actions(user_actions, pref_key, window=30)
if recent_actions and all(a != pref_value for a in recent_actions):
inconsistencies.append({
"preference": pref_key,
"stored": pref_value,
"actual_trend": majority(recent_actions),
"suggestion": "update" # 建议更新
})
return inconsistencies记忆清洁度检查清单
定期(比如每天)对长期记忆做一次"清洁度检查":
- 时间检查:超过N天未被检索的记忆,降低重要性评分
- 矛盾检查:同一主题下是否存在矛盾记忆?保留最新的
- 置信度检查:置信度低于阈值的记忆,标记为"待验证"
- 冗余检查:语义高度重复的记忆,合并为一条
- 来源检查:来自已废弃会话的记忆,评估是否仍有价值
遗忘机制设计:让Agent学会"忘掉"不重要的东西
这是整篇文章最重要的部分。
人类大脑最强大的功能不是记忆,是遗忘。每天你接收海量信息,99%被自动过滤掉。剩下的1%里,大部分在几天后也会淡忘。只有极少数------重要的、反复出现的、情感强烈的------才会被长期保留。
Agent的记忆系统需要同样的机制。
(见配图2:遗忘机制设计图)
机制1:时间衰减------记忆也有"半衰期"
不是所有记忆都同等新鲜。一条记忆的"有效度"应该随时间递减。
python
import math
from datetime import datetime, timedelta
def compute_time_decay(timestamp: datetime, half_life_days: float = 30) -> float:
"""
计算时间衰减因子
half_life_days: 半衰期,默认30天------30天后记忆权重减半
"""
age_days = (datetime.now() - timestamp).days
decay = math.exp(-0.693 * age_days / half_life_days) # ln(2) ≈ 0.693
return max(decay, 0.05) # 最低保留5%,不完全归零不同类型信息的半衰期不同:
| 信息类型 | 半衰期 | 原因 |
|---|---|---|
| 用户身份(姓名、过敏史) | ∞(不衰减) | 核心事实,不会过时 |
| 用户偏好(喜欢/不喜欢) | 90天 | 偏好会变,但不会天天变 |
| 任务相关事实(订单号、地址) | 7天 | 具体任务信息很快过时 |
| 对话上下文(闲聊内容) | 1天 | 大部分闲聊不值得保留 |
| 推理策略(成功路径) | 180天 | 成功经验值得长期保留 |
机制2:重要性评分------不是什么都值得记住
每条记忆在写入时就应该有一个"重要性评分"。这个评分决定了记忆的生存权。
python
def compute_importance(content: str, context: dict) -> float:
"""
计算记忆重要性评分(0-1)
"""
score = 0.3 # 基础分
# 用户主动强调的信息更重要
if has_emphasis_markers(content): # "一定要"、"千万别"、"最重要"
score += 0.3
# 涉及用户核心属性的信息更重要
if is_core_attribute(content): # 姓名、地址、过敏史、职业
score += 0.3
# 被反复提及的信息更重要
mention_count = count_mentions(content, context)
score += min(mention_count * 0.1, 0.2)
# 纠错类信息更重要(用户纠正了之前的错误)
if is_correction(content, context):
score += 0.2
return min(score, 1.0)重要性评分的用途:
- 写入决策:重要性低于0.2的信息,不写入长期记忆
- 检索加权:检索时,重要性高的记忆权重更大
- 遗忘决策:重要性低 + 时间衰减大的记忆,优先删除
机制3:主动遗忘------定期清理记忆垃圾
遗忘不是被动等待记忆"自然消退",而是主动删除确定无用的记忆。
主动遗忘的4种触发条件:
- 显式遗忘:用户明确说"忘掉我之前说的X"------直接删除
- 矛盾遗忘:检测到矛盾记忆,删除旧的、保留新的
- 衰减遗忘:时间衰减 × 重要性评分 < 阈值,自动删除
- 容量遗忘:长期记忆超过容量上限,删除评分最低的
python
async def active_forgetting(memory_store: VectorDB, config: ForgettingConfig):
"""
主动遗忘:定期清理记忆垃圾
建议每天执行一次
"""
all_memories = await memory_store.get_all()
to_delete = []
for m in all_memories:
# 计算综合生存评分
time_decay = compute_time_decay(m.timestamp, m.half_life_days)
survival_score = time_decay * m.importance
# 衰减遗忘:生存评分低于阈值
if survival_score < config.survival_threshold:
to_delete.append(m.id)
continue
# 矛盾遗忘:检查是否有更新的矛盾记忆
conflicts = await find_conflicts(m, all_memories)
if conflicts and all(c.timestamp > m.timestamp for c in conflicts):
to_delete.append(m.id) # 旧的被新的替代
continue
# 容量遗忘:如果还是超容量,删评分最低的
remaining = [m for m in all_memories if m.id not in to_delete]
if len(remaining) > config.max_capacity:
remaining.sort(key=lambda m: m.importance * compute_time_decay(m.timestamp, m.half_life_days))
excess = len(remaining) - config.max_capacity
to_delete.extend([m.id for m in remaining[:excess]])
# 执行删除
await memory_store.batch_delete(to_delete)
return {"deleted": len(to_delete), "remaining": len(all_memories) - len(to_delete)}机制4:记忆压缩------把碎片合并成知识
遗忘不是只有"删除"一种方式。另一种更优雅的方式是"压缩"------把多条碎片化的记忆合并成一条更精炼的知识。
为什么需要压缩:
一次30分钟的对话,可能产生50条记忆碎片。如果全部保留,检索时噪声极大。但如果把这50条碎片压缩成5条核心知识,检索效率和质量都会大幅提升。
python
async def compress_session_memories(session_memories: list[Memory]) -> list[Memory]:
"""
压缩会话记忆:把碎片合并成精炼知识
"""
# 按主题分组
grouped = group_by_topic(session_memories)
compressed = []
for topic, memories in grouped.items():
if len(memories) <= 2:
compressed.extend(memories) # 少量记忆不需要压缩
continue
# 用LLM压缩:多条碎片 → 一条精炼知识
fragments = [m.content for m in memories]
summary = await llm.complete(
f"将以下信息压缩为一条简洁的知识陈述,保留所有关键事实:\n"
+ "\n".join(f"- {f}" for f in fragments)
)
compressed.append(Memory(
content=summary,
importance=max(m.importance for m in memories),
timestamp=max(m.timestamp for m in memories),
metadata={"compressed_from": len(memories), "type": "compressed"}
))
return compressed压缩的时机:
- 会话结束时:把本次会话的记忆碎片压缩后写入长期记忆
- 定期维护时:把长期记忆中同一主题的碎片合并
- 容量压力时:当长期记忆接近容量上限,触发压缩释放空间
一个完整的记忆系统设计
把上面所有机制组合起来,一个完整的Agent记忆系统长这样:
写入流程
markdown
用户输入 → 提取关键信息 → 评估重要性
↓
重要性 < 0.2 → 丢弃
重要性 ≥ 0.2 → 写入短期记忆
↓
会话结束 → 筛选值得保留的
↓
压缩碎片 → 打标签(时间戳/重要性/类型/半衰期)
↓
写入长期记忆读取流程
css
用户输入 → 判断是否需要检索长期记忆
↓ 是
向量检索 top-50 → 时间衰减 × 重要性评分 → 过滤低分 → 取 top-5
↓
压缩5条记忆为摘要 → 注入工作记忆(上下文窗口)
↓
同时读取短期记忆中相关信息 → 注入工作记忆
↓
LLM推理遗忘流程
markdown
定时任务(每天)→ 遍历长期记忆
↓
计算生存评分 = 时间衰减 × 重要性
↓
生存评分 < 阈值 → 删除
存在矛盾记忆 → 删除旧的
同主题碎片 → 压缩合并
超容量 → 删除评分最低的
↓
记录遗忘日志(可审计)关键设计原则
- 宁缺毋滥:检索不到记忆,Agent最多说"我不知道";检索到错误记忆,Agent会自信地犯错。所以检索的精准度比召回率更重要
- 时间敏感:所有记忆都有时间戳,所有检索都考虑时间衰减。越新的记忆越可信
- 可审计:每条记忆有来源(哪个会话、哪轮对话),每次遗忘有日志。出了问题可以追溯
- 渐进遗忘:不是突然删除,而是先降权、再标记、最后删除。给系统一个"反悔"的机会
- 用户可控:用户可以查看、修改、删除自己的记忆。记忆系统不是黑箱
向量数据库之外的新解法:从向量数据库到认知架构
上面讲的3层架构+RAG+遗忘机制,是当前的主流方案。记忆系统的设计空间发生了三个结构性变化:
- 大上下文窗口普及:Gemini 2.5 Pro 1M、Claude Sonnet 4.6 200K、GPT-5.5 Thinking,"全塞进去"不再是笑话
- 专用记忆中间件涌现:Mem0、Zep、Letta(原MemGPT),记忆不再是"自己造轮子"
- 知识图谱回归:GraphRAG证明纯向量检索不够用,结构化知识是缺失的一环
这三条线不是替代关系,而是叠加关系。当前Agent记忆,是在原有3层架构基础上,多了3个新工具和1个新思路。
变化1:大上下文窗口------但"能装"不等于"该装"
先说一个容易踩的坑:上下文窗口从4K扩到1M,很多人觉得"不用做记忆管理了,全塞进去就行"。
这是错的。 原因有四个:
① Lost in the Middle仍然存在:当前模型在长上下文信息检索上确实有改善,但Landmark Arena等测试表明,中间位置的信息提取准确率仍然低于首尾位置。1M上下文中,你要Agent关注第50万token处的一条关键指令?不如直接放前面。
② 成本不是线性的,是乘法的 :GPT-5.5 Thinking的input定价约 2.5/Mtokens。一个Agent任务平均10次LLM调用,如果每次都带1M上下文,单任务成本25。加上context caching后有所改善(缓存命中部分按50%计费),但Agent的上下文动态变化大,缓存命中率往往低于预期。
③ 延迟是隐形成本:1M tokens的prefill时间,即使是最快的模型也需要数秒。Agent场景下用户等待3秒以上体验就很差了。
④ 注意力稀释:核心问题不是"能不能装",而是"LLM能不能在这么多信息中准确找到需要的"。实验数据表明,上下文越长的Agent任务,幻觉率越高。
正确姿势:大上下文窗口改变的是工作记忆的"弹性边界",而不是"设计原则"。以前4K窗口时必须激进压缩,现在200K窗口时可以更从容地保留对话历史,但仍然需要:
- 结构化注入(而不是全量平铺)
- 按需加载(而不是一次性全塞)
- 摘要压缩(长对话仍然需要压缩历史)
Context Caching改变了经济模型:OpenAI和Anthropic都推出了prompt caching机制------重复的prompt前缀可以缓存,后续调用按缓存价格计费(通常5-10折)。这对Agent记忆的影响是:
python
# ✅ 利用Context Caching的记忆策略
# 把system prompt + 用户画像 + 长期记忆摘要放在前缀(可缓存)
# 把动态对话历史放在后缀(每次变化)
cached_prefix = f"""
{system_prompt}
## 用户画像
{user_profile_summary}
## 相关长期记忆
{compressed_long_term_memory}
""" # 这部分在多轮对话中不变,可被缓存
dynamic_suffix = f"""
## 当前对话
{recent_conversation}
## 当前任务
{current_task}
""" # 这部分每轮变化,不能缓存
# 最终prompt = cached_prefix + dynamic_suffix
# 成本 = cached_prefix × 缓存价格 + dynamic_suffix × 全价这改变了记忆注入的顺序策略------稳定的记忆内容放前面(触发缓存),动态内容放后面。
变化2:专用记忆中间件------别再造轮子了
此前Agent记忆基本是"自己用向量数据库搭"。现在出现了3个有代表性的专用方案:
Mem0(原EmbedChain团队):面向Agent的结构化记忆层
python
from mem0 import Memory
m = Memory()
# 写入:自动提取、去重、更新
m.add("我叫张三,住在北京,对花生过敏", user_id="user_123")
# 检索:自动处理矛盾、时间衰减
results = m.search("这个用户住哪", user_id="user_123")
# 更新:用户改口了
m.add("我搬到上海了", user_id="user_123")
# Mem0会自动更新"住在北京"→"住在上海",而不是新增一条矛盾记忆Mem0的核心价值不在检索(向量数据库都会),而在记忆管理------自动去重、矛盾检测、更新合并。这正是上面"记忆污染"一节讲的问题。
Zep:带时序感知的会话记忆
Zep的特殊之处是原生支持时序边(temporal edges)------每条记忆自动关联时间戳和会话上下文,检索时可以按时间窗口过滤。这解决了"3个月前说住北京vs 3天前说搬到上海"的矛盾问题。
Letta(原MemGPT):LLM自管理的虚拟上下文
Letta的思路最激进------让LLM自己决定什么时候读记忆、什么时候写记忆、什么时候删记忆。它把记忆操作(memory.insert、memory.search、memory.replace、memory.archive)作为工具暴露给LLM,LLM像人一样自主管理记忆。
python
# Letta的思路:记忆操作 = Tool Calling
# LLM在推理时可以选择调用记忆工具
# 而不是由代码层硬编码记忆读写逻辑
tools = [
memory_insert, # 写入新记忆
memory_search, # 检索相关记忆
memory_replace, # 替换旧记忆
memory_archive, # 归档不活跃记忆
]这个思路的优点:灵活,LLM根据上下文自主决策。缺点:不靠谱------LLM可能忘记调用记忆工具,或者写入不重要的信息、忘记更新矛盾记忆。实际部署中,通常需要"代码层兜底 + LLM层增强"的混合方案。
选型建议:
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 快速原型、个人Agent | Mem0 | 开箱即用,自动管理 |
| 多轮会话为主 | Zep | 时序感知强,会话记忆好 |
| 需要极致灵活性 | Letta | LLM自主管理记忆 |
| 生产级、高可控性 | 自建3层架构 | 可审计、可调试、可定制 |
变化3:GraphRAG------纯向量检索的天花板
纯向量检索有一个硬伤:它能找到语义相似的片段,但不能推理实体间的关系。
用户说"帮我查一下我上次去北京出差时住的那家酒店旁边的餐厅",纯向量检索会找"北京出差"相关的记忆,但它不知道"出差"→"住酒店X"→"酒店X旁边有餐厅Y"这条推理链。
GraphRAG(微软提出,在Agent领域广泛应用)的解法:在向量检索之上加一层知识图谱。
python
# 纯向量检索:语义相似但缺乏关系推理
vector_results = await vector_db.search("北京出差住的酒店旁边的餐厅")
# 返回:["用户去过北京出差", "用户住过酒店", "某餐厅评价不错"]
# 但不知道它们之间的关系!
# GraphRAG:先实体识别,再关系推理
# 1. 从记忆中提取实体和关系
entities = extract_entities("上次去北京出差住如家酒店,旁边有家老北京涮羊肉不错")
# → entities: [北京, 如家酒店, 老北京涮羊肉]
# → relations: [北京-出差-如家酒店, 如家酒店-旁边-老北京涮羊肉]
# 2. 存入知识图谱
graph.add_entities(entities)
graph.add_relations(relations)
# 3. 检索时:先图谱推理,再向量补充
# "北京出差的酒店旁边的餐厅" → 图谱推理路径:
# 北京 → 出差 → 如家酒店 → 旁边 → 老北京涮羊肉 ✅GraphRAG在Agent记忆中的位置:它不是替代向量数据库,而是补充。3层记忆架构中的长期记忆层,应该是"向量数据库 + 知识图谱"的双存储:
- 向量数据库:处理"找到相关的"------语义检索
- 知识图谱:处理"理解关系"------结构化推理
- 混合检索:先向量检索召回候选,再图谱推理验证关系
实际数据:微软的GraphRAG论文显示,在需要多跳推理的查询上,GraphRAG的准确率比纯向量检索高40-60%。代价是写入成本增加(需要LLM做实体抽取和关系构建),以及存储成本增加(图数据库)。
什么时候需要GraphRAG,什么时候不需要:
| 场景 | 是否需要 | 原因 |
|---|---|---|
| 简单的用户偏好记忆 | 不需要 | 向量检索足够 |
| 多实体关系的任务记忆 | 需要 | 如"项目A的甲方负责人推荐了供应商B" |
| 跨会话的推理链 | 需要 | 需要连接不同对话中的实体 |
| 个人助手类Agent | 建议用 | 用户生活涉及大量实体关系 |
变化4:MCP------记忆系统有了标准接口
MCP(Model Context Protocol)是Anthropic提出的协议,在Agent生态快速普及。它对记忆系统的影响不是"新的存储方案",而是"标准化的访问接口"。
MCP之前,每个Agent框架的记忆接口都不一样:LangChain的Memory类、CrewAI的LongTermMemory、AutoGen的ConversationSummaryMemory......换个框架就得重写记忆层。
MCP之后,记忆系统可以暴露为一个MCP Server,任何支持MCP的Agent都能直接接入:
python
# MCP记忆Server示例
# 暴露3个工具:search_memory, add_memory, delete_memory
@mcp_server.tool("search_memory")
async def search_memory(query: str, user_id: str, top_k: int = 5):
"""搜索用户的长期记忆"""
results = await memory_store.search(query, user_id, top_k)
return [r.content for r in results]
@mcp_server.tool("add_memory")
async def add_memory(content: str, user_id: str, metadata: dict = {}):
"""添加新的长期记忆"""
return await memory_store.add(content, user_id, metadata)
@mcp_server.tool("delete_memory")
async def delete_memory(memory_id: str, user_id: str):
"""删除指定的长期记忆"""
return await memory_store.delete(memory_id, user_id)MCP对记忆系统的影响:
- 解耦:记忆存储和Agent框架独立演进,换框架不用换记忆
- 标准化:所有Agent用同一种方式访问记忆,减少集成成本
- 可组合:不同类型的记忆(向量、图谱、键值)可以各自暴露为MCP Server,Agent按需组合
但MCP不解决记忆系统的核心难题------该存什么、该忘什么、该检索什么。它只是让"访问记忆"这件事变得标准化,记忆的质量仍然取决于存储和检索策略的设计。
记忆架构的推荐形态
综合上面4个变化,一个生产级Agent的记忆架构应该是这样的:
scss
┌─────────────────────────────────────────────────────────┐
│ 工作记忆(上下文窗口) │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ System Prompt │ │ 缓存前缀 │ │ 动态上下文 │ │
│ │ (cached) │ │ 用户画像 │ │ 当前对话 │ │
│ │ │ │ 记忆摘要 │ │ 任务状态 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
├─────────────────────────────────────────────────────────┤
│ 短期记忆(会话状态) │
│ Redis / 内存 · 结构化分桶 · 会话结束触发归档 │
├─────────────────────────────────────────────────────────┤
│ 长期记忆(双存储) │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ 向量数据库 │ │ 知识图谱 │ │
│ │ 语义检索 │ │ 关系推理 │ │
│ │ 时间衰减 │ │ 实体消歧 │ │
│ └──────────────┘ └──────────────┘ │
│ ↕ MCP标准接口 ← Agent按需访问 │
├─────────────────────────────────────────────────────────┤
│ 记忆管理层 │
│ Mem0/Zep/自建 · 写入去重 · 矛盾检测 · 主动遗忘 · 压缩合并 │
└─────────────────────────────────────────────────────────┘和之前方案的3个关键差异:
- 长期记忆从"单存储"变成"双存储"(向量+图谱),解决多跳推理
- 工作记忆引入"缓存前缀"策略,利用Context Caching降低成本
- 记忆管理层从"自建逻辑"变成"中间件+自建逻辑",降低造轮子成本
常见反模式
反模式1:把向量数据库当"万能记忆"
向量数据库只解决了一个问题:语义检索。它没解决:
- 时间感知(不知道哪条记忆更新)
- 重要性区分(不知道哪条记忆更重要)
- 矛盾处理(不知道哪条记忆更可信)
- 主动遗忘(不知道哪些记忆该删)
把向量数据库当"万能记忆",就像把硬盘当"万能大脑"------存是存了,但用不好。
反模式2:全量上下文
"上下文窗口越来越大,1M够用了吧?"
不够。原因:
- LLM的注意力是有限的:研究表明,LLM在长上下文中的信息检索准确率随长度增加而下降("Lost in the Middle"现象),当前模型虽有改善但问题仍存在
- 成本:1M tokens的输入,一次调用就花$2-5(取决于模型)。Agent一个任务可能调用10次
- 延迟:上下文越长,推理越慢
正确的做法不是"塞更多",而是"只塞需要的"。
反模式3:只记不忘
很多Agent系统有完善的记忆写入机制,但没有遗忘机制。结果:
- 长期记忆越来越臃肿
- 检索噪声越来越大
- 推理质量越来越差
- 存储成本越来越高
记住:遗忘不是bug,是feature。 一个没有遗忘机制的记忆系统,最终会变成垃圾场。
小结
Agent的记忆系统不是"加个向量数据库"就完事了。3层记忆架构各有各的坑:
- 工作记忆:容量有限,需要压缩和清理,撑爆=推理质量暴跌
- 短期记忆:会话结束时的去留抉择,需要结构化存储和选择性读取
- 长期记忆:检索噪声和记忆污染,需要多维过滤和主动遗忘
核心观点:遗忘机制比记忆机制更重要。
一个好的记忆系统,不是什么都记住,而是:
- 精准写入:只存重要的
- 高效检索:只取相关的
- 主动遗忘:删掉过时的
- 定期压缩:合并碎片化的
另外注意:大上下文窗口给了更多弹性但没改变设计原则;Mem0/Zep/Letta让记忆管理不再从零造轮子;GraphRAG补上了向量检索缺失的关系推理;MCP让记忆接口标准化。但这些新工具解决的是"效率"和"标准化",核心难题------该存什么、该忘什么、该检索什么------仍然需要架构师自己设计。
下一章,我们聊Agent的"大脑"------编排层。怎么让Agent在复杂任务中不迷路、不死循环、不半途而废。