参考:Pytorch框架与经典卷积神经网络与实战哔哩哔哩bilibili
一、课程先导
1.1全连接网络 VS CNN卷积网络
原始数据:100×33×33×1,代表 100 张33×33 像素的单通道灰度图
全连接神经网络必须将图像展平为一维向量,会破坏图像空间结构信息。
全连接网络运算过程:
-
输入有 3 个神经元 :
x1, x2, x3 -
输出有 2 个神经元 :
y1, y2
那么:全连接层的参数 = 输入个数 × 输出个数 + 输出个数 = 权重数 + 偏置数
y1 = w11*x1 + w12*x2 + w13*x3 + b1
y2 = w21*x1 + w22*x2 + w23*x3 + b2参数
1.2卷积运算过程
卷积运算过程:在图像上滑动,执行卷积核相乘求和运算,得到特征图的一个像素值
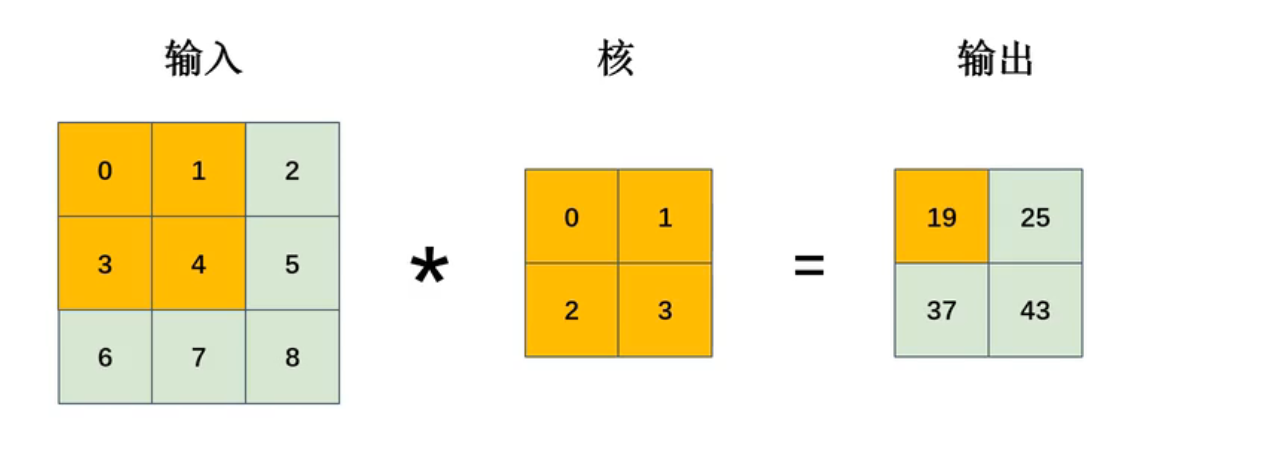
卷积核本质是特征模板,乘加运算表示局部区域和模板的匹配程度:
-
区域像素均匀 → 结果趋近 0 → 无特征
-
区域存在明暗突变 → 结果数值大 → 匹配到边缘、线条、角点
参数:
步幅:卷积核每次滑动的像素距离,步幅越大,特征图尺寸压缩越明显。
填充:在输入图像 / 特征图四周补充一圈像素(通常补 0)。
相互配合可以防止每次卷积运算后的特征图变小,同时能保留图像边缘信息。
输出特征图计算公式:
IH = 输入高度,IW = 输入宽度
K = 卷积核尺寸,P = 填充数,S = 步幅
输出高度:OH = \left\lfloor \frac{IH + 2P - K}{S} \right\rfloor + 1
输出宽度:OW = \left\lfloor \frac{IW + 2P - K}{S} \right\rfloor + 1
如果是正方形:边长=(输入边长+两倍填充层数,减去卷积核边长)除以步幅向下取整,再额外加一。
如果是长方形:高=(输入高+两倍填充层数,减去卷积核高)除以步幅向下取整,再额外加一。
:宽同理;
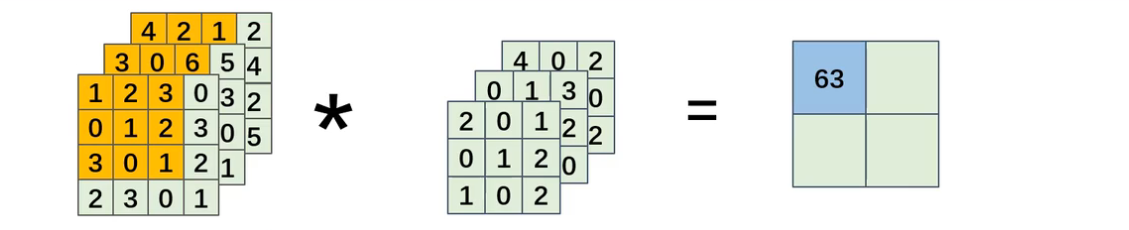
1.3多通道卷积
对于多通道数据的卷积运算需要使用多个不同卷积核,就能得到对应数量的输出通道
1.4池化
池化一般紧跟卷积层之后,但是只是一种操作,不属于模型的有效层数,也不包含可学习参数,优点如下:
-
缩小特征图尺寸,降低计算开销
-
提取关键特征,弱化无用细节
-
获得「平移不变性」同一个特征在图片里稍微挪一点点位置,网络依然能识别出来。
池化后的面积公式与卷积计算相同
最大池化(Max Pooling)
取池化窗口内最大像素值作为输出,优先保留纹理、边缘等显著特征,使用最广泛。
平均池化(Average Pooling),侧重保留整体区域特征,弱化细节。
池化同样设置池化核大小、步幅,也会改变特征图尺寸。
1.5卷积神经网络整体结构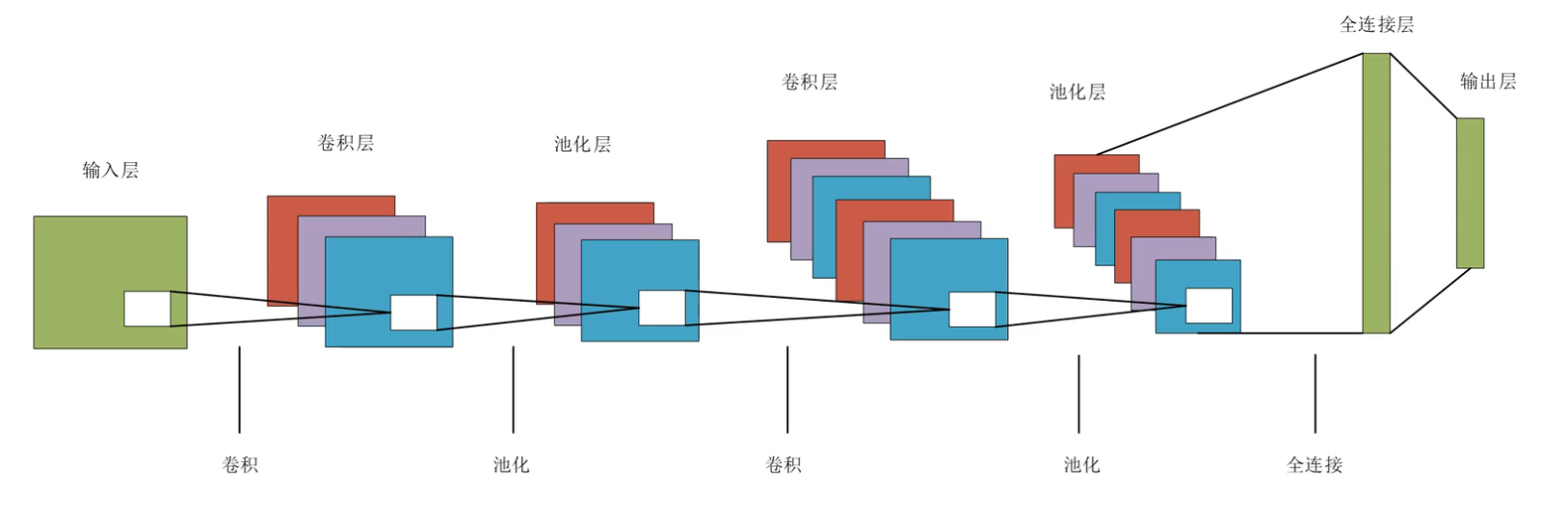
- 前向传播
输入数据→经过(w、b)运算→算出预测值→和真实标签对比,算出损失 Loss。
损失:数值用来判断模型好坏;解析式用来反向求梯度。
- 反向传播 BP
从损失值开始,链式求导,算出每一层权重w、偏置b的梯度(偏导)
梯度含义:这个参数往哪个方向微调,损失会变小。
✅BP 只出「修改方案(梯度数值)」,全程不改动 w 和 b 本身。
- SGD 随机梯度下降(执行修改)
拿到 BP 算好的梯度,套公式:w_{新}=w_{旧}-\eta\times梯度
实实在在替换原来的权重 w、b,参数被更新。
二、Pytorch开发环境搭建
2.1安装
安装并配置好 PyCharm、Anaconda、PyTorch、CUDA、其他库
python==3.8
Pytorch==1.10.1
Cudatookit==11.3.1
Cudnn==8.2
torchsummary==1.5.1
numpy==1.23.2
pandas==1.3.4
matplotlib==3.5.0
sklearn==0.0安装PyCharm :PyCharm,您需要的唯一 Python IDE,直接安装到D盘,其中四个选项全部勾选(创建快捷方式、添加到 PATH 等)
安装Anaconda :Download Success | Anaconda,直接安装,其中四个选项全部勾选(添加到 PATH、注册 Python 等)
创建虚拟环境(隔离项目依赖)
完成后,在开始菜单搜索:Anaconda Prompt
#创建名为 pytorch 的环境,Python 3.8
conda create -n pytorch python==3.8 安装完成后输入
# 查看所有环境
conda env list
# 进入 pytorch 环境
conda activate pytorch成功后命令行前面会出现 (pytorch)。
查看显卡支持的 CUDA 版本
在系统命令行/cmd输入
nvidia-smi 可以观察到使用得到cuda版本是12.2,版本可以低于12.2
可以观察到使用得到cuda版本是12.2,版本可以低于12.2
安装 PyTorch + CUDA + 其他库
pytorch历史版本查询:Previous PyTorch Versions
选择:
-
CUDA 11.3(兼容你的 12.2)
-
Conda 安装
在 Anaconda Prompt(已激活 pytorch)输入对应命令:
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=11.3 -c pytorch完成后安装常用工具包,继续输入
# 模型结构可视化工具
pip install torchsummary==1.5.1
# sklearn 机器学习库
pip install sklearn==0.0 -i https://pypi.mirrors.ustc.edu.cn/simple/国内源:
-
中科大源:-i Verifying - USTC Mirrors
-
清华源:-iSimple Index
2.2配置
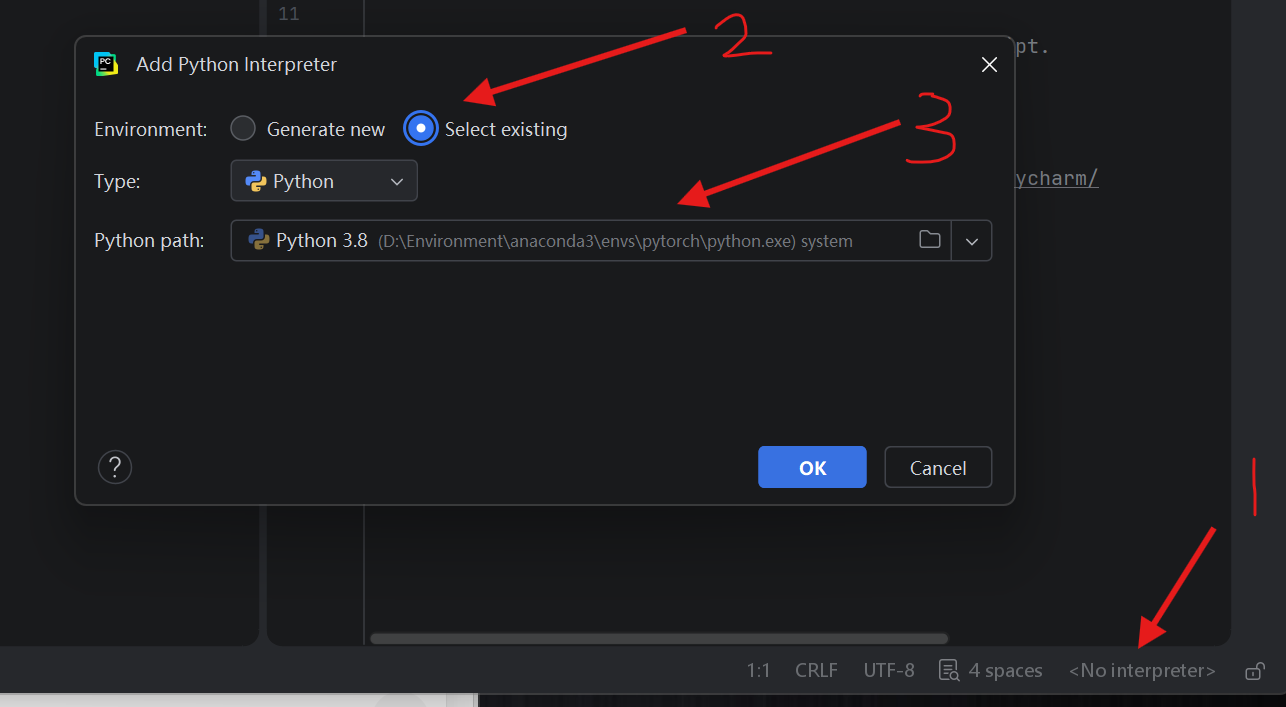
在 PyCharm 中配置 Conda 虚拟环境
桌面新建空白文件夹test→右键在pycharm中打开
点击左下角新建环境→导入本地环境→选择之前建立的pytorch虚拟环境
把main文件替换为下面代码
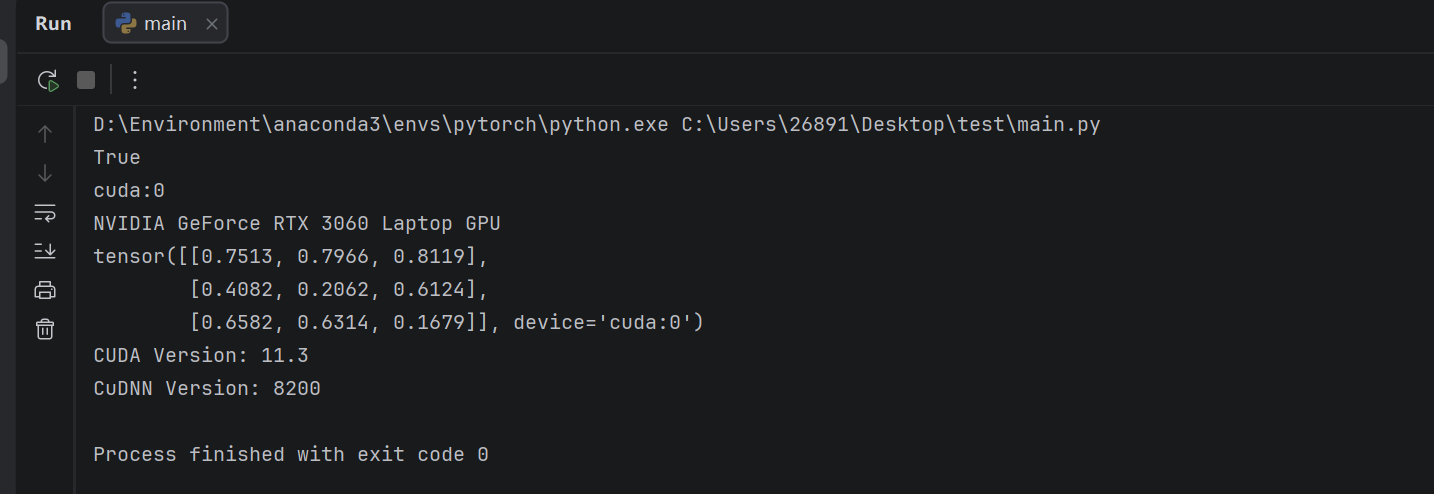
import torch
flag = torch.cuda.is_available()
print(flag) # 返回true为安装成功
ngpu = 1
# Decide which device we want to run on
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
print(device)
print(torch.cuda.get_device_name(0))
print(torch.rand(3, 3).cuda())
# Check CUDA version
cuda_version = torch.version.cuda
print("CUDA Version:", cuda_version)
# Check CuDNN version
cudnn_version = torch.backends.cudnn.version()
print("CuDNN Version:", cudnn_version)得到输出:
三、LeNet与AlexNet原理与实战
对于不同的深度学习模型,训练代码 和 测试代码 结构几乎一模一样!需要重点学习
3.1Lenet-5网络
1989年被提出,研究目的:手写数字识别
深度学习训练中,最耗时的两个部分:数据处理 + 网络模型前向传播与反向传播。
Lenet-5整体结构如下:两个卷积层+三个全连接层
输入 → 卷积 → 池化 → 卷积 → 池化 → 全连接 → 全连接 → 全连接 → 输出使用了sigmoid函数作为激活函数
参数详解:见1.2的输出层运算公式
注意:这里的卷积核用来提取不同特征,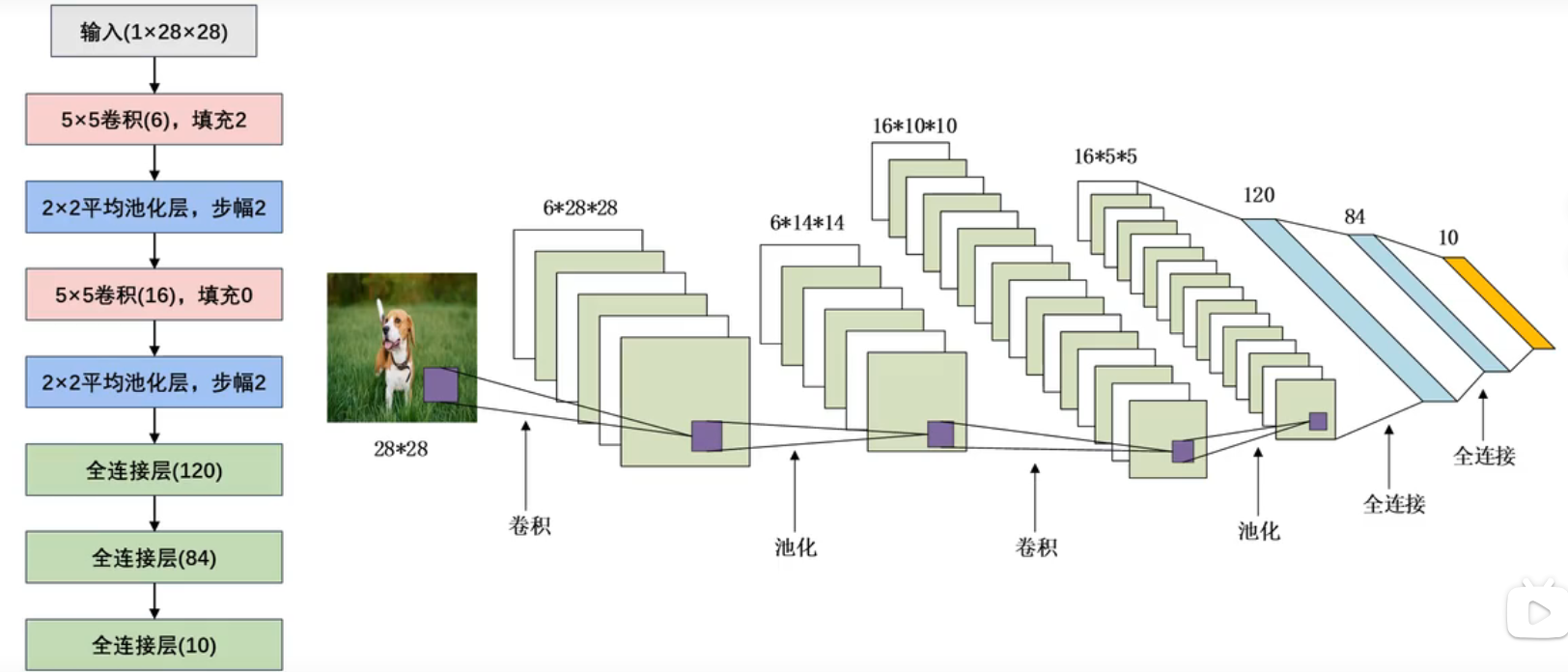
卷积→尽量使通道变多
池化→尽量使特征图变大
3.2AlexNet网络
在AlexNet网络提出前,卷积神经网络往往被其他机器学习方法超越
2012年,AlexNet网络拿到 ImageNet 大赛
2015年,ResNet网络拿到 ImageNet 大赛
李飞飞:造出海量数据,让 CNN 练得动,创办 ImageNet 大赛
吴恩达:把 AI 带出实验室、全民开课普及
何恺明:ResNet 打通深层网络上限,现代 CNN 基石
从结构来看,AlexNet网络是由五个卷积层,两个全连接层隐藏层,一个全连接输出层,使用了ReLU激活函数,使用最大池化
隐藏全连接层共计9216×4096个参数,容易过拟合,采用神经元失活Dropout操作
-
首先随机(临时)删掉网络中一部分的隐藏神经元
-
然后把输入 x 通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。
-
一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
-
下一轮重新随机删神经元,循环。
3.3图像增强
图像翻转、图像裁剪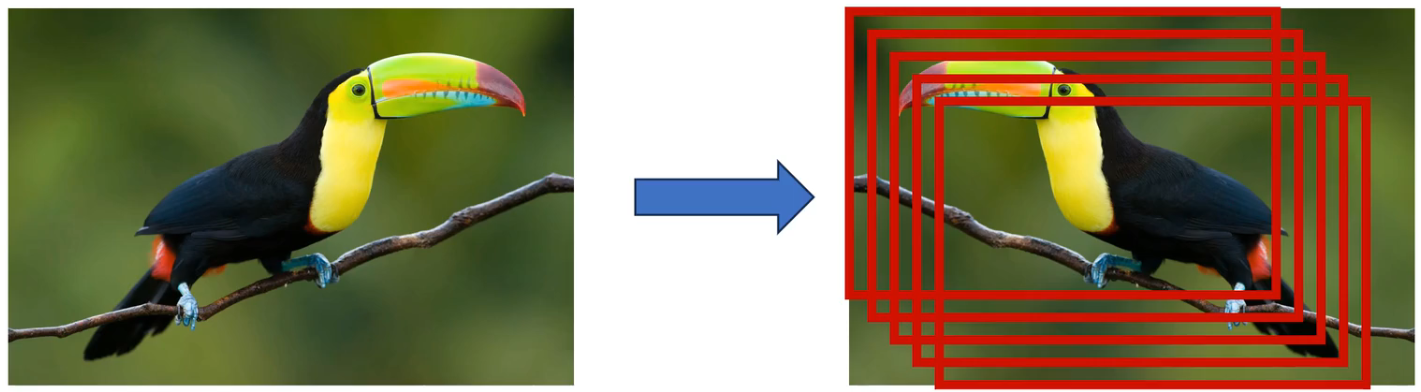
PCA(随机色彩扰动)
但这些只是补充,最主要的还是原始数据要足够
四、LeNet代码实战
4.1项目结构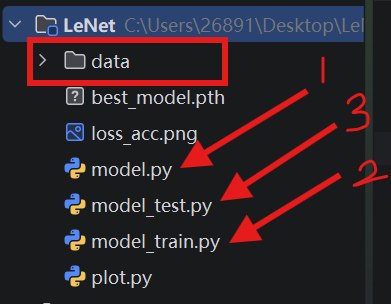
-
model.py 定义 LeNet 神经网络类:卷积层、池化层、全连接层、forward 前向传播
-
model_train.py 加载数据集 → 训练模型 → 保存最优模型
best_model.pth。 -
model_test.py 加载训练好的模型,测试准确率。
4.2模型定义
先介绍一下导入的库/函数
-
import torch导入 PyTorch 核心库,提供张量创建、GPU/CPU 设备管理、基础运算等核心功能 -
from torch import nn导入 PyTorch 神经网络模块,是构建模型的核心工具包,包括:卷积、池化、激活函数等操作
接着创建 PyTorch 模型类(必须继承父类模板nn.Module)
class LeNet(nn.Module):
def __init__(self):定义网络有哪些层(这个命名是构造函数名,创建对象时自动调用)
super(LeNet,self).__init__()
卷积 self.c1=nn.Conv2d(输入通道数,输出通道数=卷积核个数,卷积核大小,步幅,填充)
激活 self.sig = nn.Sigmoid()
池化 self.s2=nn.AvgPool2d(池化核大小,步幅)
展平 self.flatten = nn.Flatten()
全连接self.f5 = nn.Linear(输入特征维度,本层神经元数量)
def forward(self, x):定义数据经过的层的顺序(PyTorch 强制规定的前向传播函数名)
使用x参数来表示数据的流动,定义数据训练过程
x = self.sig(self.c1(x))
x = self.s2(x)
...
return x
最后我们可以通过主函数测试参数是否正确
if __name__ == "__main__":
model = LeNet().to(device)实例化模型 print(summary(model,(1,28,28)))通过输入假数据来测试参数是否正确
4.3模型训练
这里主要分为数据划分函数 +训练与验证函数
数据划分函数如下
def train_val_data_process():
准备数据集train_data = FashionMNIST(下载位置,用于训练,放缩图片为28×28)
划分train_data,val_data =Data.random_split(数据集,划分比例)
分批次训练
train_dataloader = Data.DataLoader(dataset=train_data,要分批次的数据集
batch_size=32, 每次训练多少
shuffle=True, 打乱顺序
num_workers=2) 进程数量分批次验证代码同上
返回分好批次的数据return train_dataloader,val_dataloader
训练与验证函数如下
def train_model_process(model,train_dataloader,val_dataloader,num_epochs):
参数:训练模型,划分好批次的训练集、验证集,训练轮次
-
训练前准备工作
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")optimizer = 学习方法,用来更新参数criterion = 损失函数model =model.to(device)best_model_wts =copy.deepcopy(model.state_dict())最优模型的容器参数:最高精度,训练与验证的损失值列表、精度列表
-
循环20轮次
for epoch in range(num_epochs):-
训练与验证 准备该批次训练前的参数:训练与验证的损失值、精度、数量
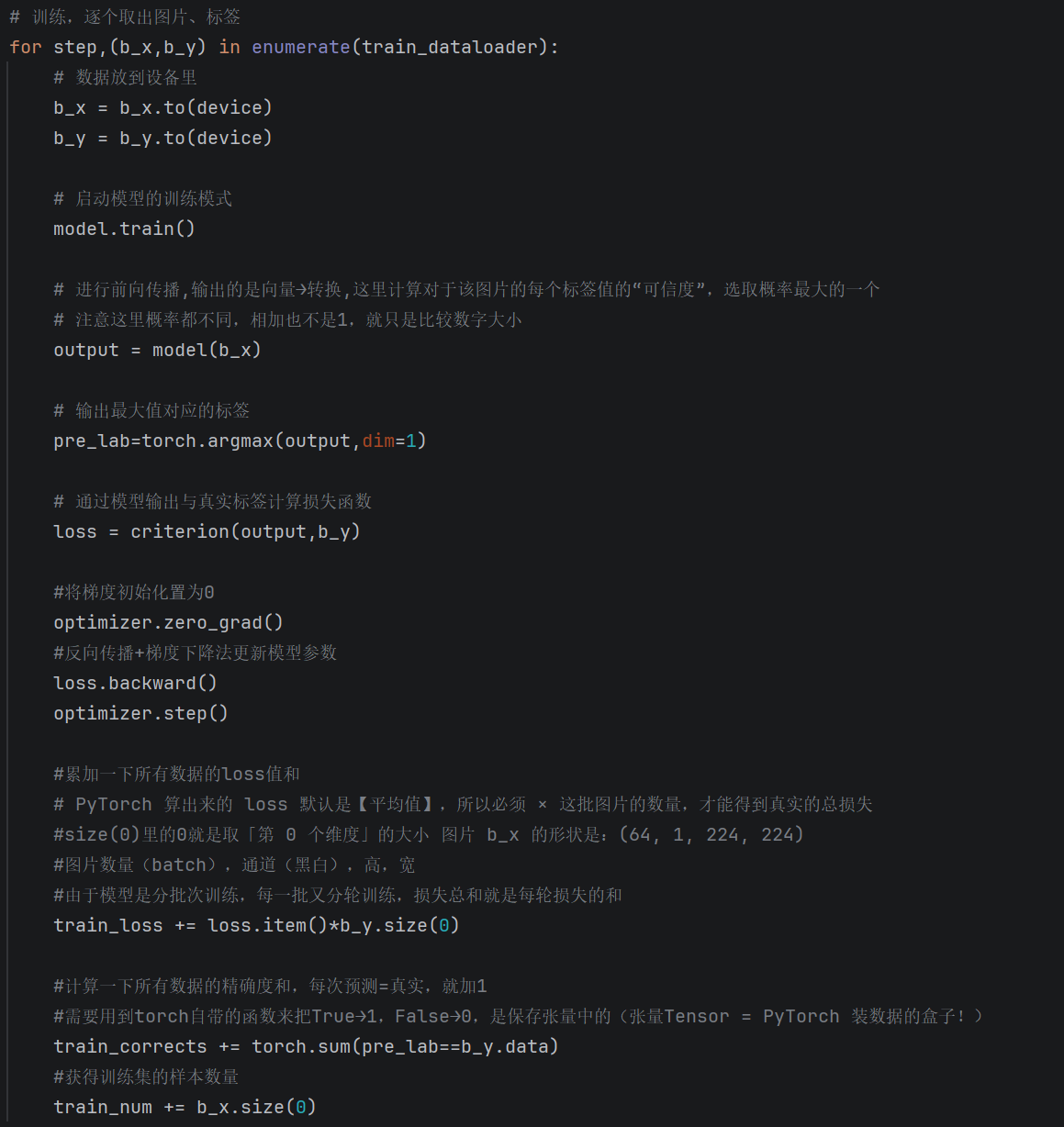
-
记录结果+保存最优模型
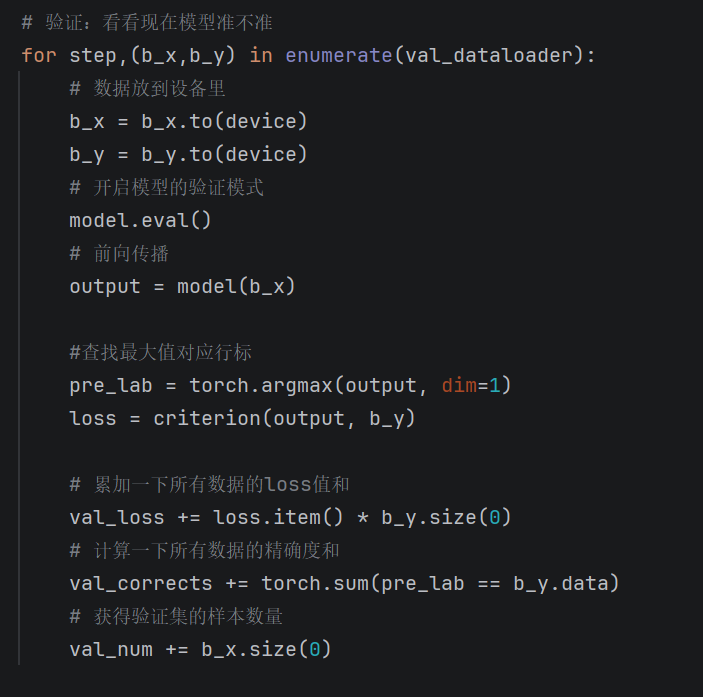
-
当该批次训练与验证结束后,计算本轮平均损失、平均准确率并存进列表
if判断来保存验证集准确率最高的模型权重
当20轮次for循环结束后,全程最优模型保存为best_model.pth文件
torch.save(best_model_wts,"./best_model.pth")
把全轮数据保存为dataframe格式并返回,后续可以绘图
定义训练主函数
if __name__ == '__main__':
LeNet = LeNet()实例化
调用数据划分函数,训练函数
4.4模型测试
模型测试阶段也分为两部分:数据划分函数 +测试函数
数据划分函数类似上述,不在复述
测试函数如下
def test_model_process(model,test_dataloader):
-
测试前准备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model =model.to(device)参数:测试精度,测试数量 -
测试代码如下
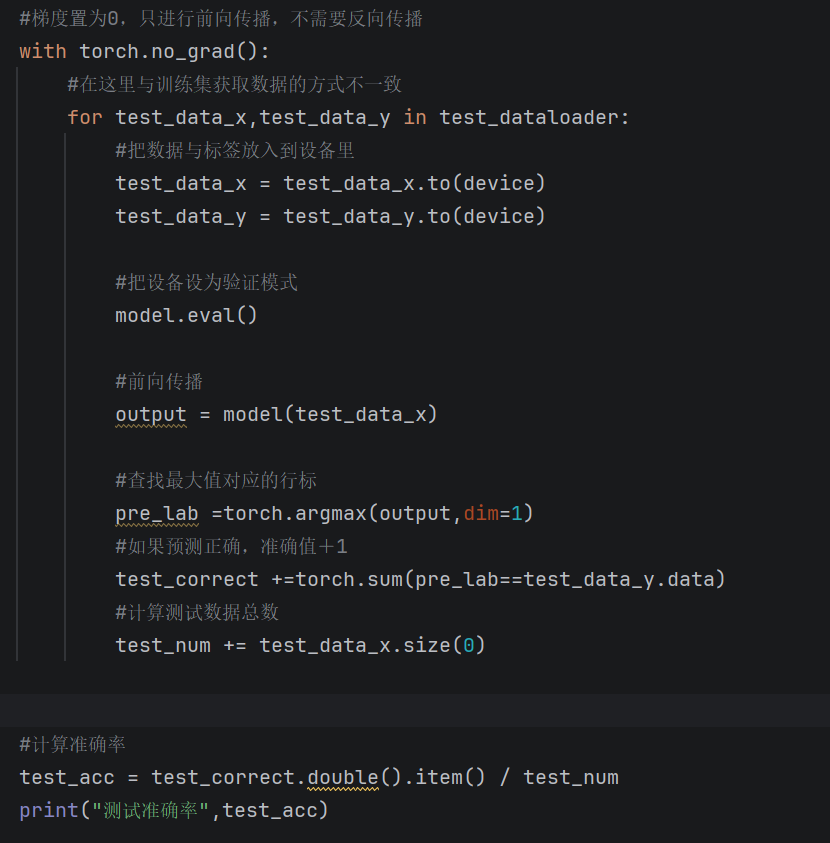
定义测试主函数
if __name__ == '__main__':
model = LeNet()模型实例化
model.load_state_dict(torch.load('best_model.pth'))加载训练得出的最优模型
调用数据划分函数,测试函数