文章目录
- ARM架构基础知识扫盲
-
- [1. ARM架构概述](#1. ARM架构概述)
-
- [1.1 什么是ARM](#1.1 什么是ARM)
- [1.2 ARM架构版本](#1.2 ARM架构版本)
- [1.3 Cortex-M系列处理器](#1.3 Cortex-M系列处理器)
- [2. Cortex-M4核心特性](#2. Cortex-M4核心特性)
-
- [2.1 主要特性](#2.1 主要特性)
- [2.2 性能参数](#2.2 性能参数)
- [3. Cortex-M系列处理器全景](#3. Cortex-M系列处理器全景)
-
- [3.1 处理器总览](#3.1 处理器总览)
- [3.2 各处理器详细对比](#3.2 各处理器详细对比)
-
- [3.2.1 Cortex-M0 --- 最小最低功耗](#3.2.1 Cortex-M0 — 最小最低功耗)
- [3.2.2 Cortex-M0+ --- M0 的增强版](#3.2.2 Cortex-M0+ — M0 的增强版)
- [3.2.3 Cortex-M3 --- 经典主流处理器](#3.2.3 Cortex-M3 — 经典主流处理器)
- [3.2.4 Cortex-M4 --- DSP + FPU 的全能型](#3.2.4 Cortex-M4 — DSP + FPU 的全能型)
- [3.2.5 Cortex-M7 --- 高性能旗舰](#3.2.5 Cortex-M7 — 高性能旗舰)
- [3.2.6 Cortex-M23 --- ARMv8-M 入门安全型](#3.2.6 Cortex-M23 — ARMv8-M 入门安全型)
- [3.2.7 Cortex-M33 --- ARMv8-M 主流安全型](#3.2.7 Cortex-M33 — ARMv8-M 主流安全型)
- [3.2.8 Cortex-M55 --- AI/ML 加速型](#3.2.8 Cortex-M55 — AI/ML 加速型)
- [3.2.9 Cortex-M85 --- 最高性能安全型](#3.2.9 Cortex-M85 — 最高性能安全型)
- [3.3 架构版本演进](#3.3 架构版本演进)
- [3.4 选型指南](#3.4 选型指南)
- [3.5 性能横向对比](#3.5 性能横向对比)
- [3.6 常见误区](#3.6 常见误区)
- [4. 寄存器组织](#4. 寄存器组织)
-
- [4.1 通用寄存器](#4.1 通用寄存器)
- [4.2 特殊寄存器](#4.2 特殊寄存器)
- [4.3 程序状态寄存器(PSR)](#4.3 程序状态寄存器(PSR))
- [4.4 栈指针](#4.4 栈指针)
- [5. 内存映射](#5. 内存映射)
-
- [5.1 STM32F407内存布局](#5.1 STM32F407内存布局)
- [5.2 关键地址](#5.2 关键地址)
- [5.3 外设地址示例](#5.3 外设地址示例)
- [6. 异常模型](#6. 异常模型)
-
- [6.1 异常类型](#6.1 异常类型)
- [6.2 异常处理流程](#6.2 异常处理流程)
- [6.3 EXC_RETURN值](#6.3 EXC_RETURN值)
- [6.4 中断优先级](#6.4 中断优先级)
- [7. 指令集概述](#7. 指令集概述)
-
- [7.1 Thumb-2指令集](#7.1 Thumb-2指令集)
- [7.2 数据处理指令](#7.2 数据处理指令)
- [7.3 加载/存储指令](#7.3 加载/存储指令)
- [7.4 分支指令](#7.4 分支指令)
- [7.5 比较指令](#7.5 比较指令)
- [7.6 特殊指令](#7.6 特殊指令)
- [8. ARM与RISC-V架构对比](#8. ARM与RISC-V架构对比)
-
- [8.1 RISC-V简介](#8.1 RISC-V简介)
- [8.2 主要区别概览](#8.2 主要区别概览)
- [8.3 指令集架构对比](#8.3 指令集架构对比)
-
- [7.3.1 设计哲学差异](#7.3.1 设计哲学差异)
- [7.3.2 指令格式对比](#7.3.2 指令格式对比)
- [7.3.3 寄存器对比](#7.3.3 寄存器对比)
- [8.4 中断与异常处理对比](#8.4 中断与异常处理对比)
- [8.5 生态系统对比](#8.5 生态系统对比)
- [8.6 开发工具对比](#8.6 开发工具对比)
- [8.7 芯片厂商与产品对比](#8.7 芯片厂商与产品对比)
- [8.8 性能与功耗对比](#8.8 性能与功耗对比)
- [8.9 代码示例对比](#8.9 代码示例对比)
- [8.10 如何选择?](#8.10 如何选择?)
- [8.11 未来发展趋势](#8.11 未来发展趋势)
- [9. 总结](#9. 总结)
ARM架构基础知识扫盲
1. ARM架构概述
1.1 什么是ARM
ARM(Advanced RISC Machines)是一种采用精简指令集(RISC)的处理器架构。ARM架构广泛应用于嵌入式系统、移动设备、物联网设备等领域。
1.2 ARM架构版本
| 架构版本 | 特点 | 典型应用 |
|---|---|---|
| ARMv6 | 基础架构,支持Thumb指令集 | Cortex-M0, Cortex-M0+ |
| ARMv7 | 增强性能,支持Thumb-2指令集 | Cortex-M3, Cortex-M4, Cortex-M7 |
| ARMv8 | 64位支持,增强安全性 | Cortex-A系列, Cortex-M23, Cortex-M33 |
1.3 Cortex-M系列处理器
Cortex-M系列是ARM针对微控制器市场设计的处理器系列:
- Cortex-M0/M0+:最低功耗,最简单的设计
- Cortex-M3:平衡性能和功耗
- Cortex-M4:支持DSP和浮点运算
- Cortex-M7:高性能,支持缓存
- Cortex-M23/M33:支持TrustZone安全扩展
2. Cortex-M4核心特性
以 STM32F407 为例,基于ARM Cortex-M4核心。
2.1 主要特性
-
Thumb-2指令集
- 支持16位和32位混合指令
- 兼容Thumb和ARM指令集的优势
-
硬件除法
- 支持有符号和无符号除法
- 单周期除法指令
-
DSP扩展
- 单周期乘法累加(MAC)
- 饱和运算指令
- 位操作指令
-
浮点单元(FPU)
- 单精度浮点运算
- 符合IEEE 754标准
-
嵌套向量中断控制器(NVIC)
- 低延迟中断处理
- 支持最多240个中断
- 可配置优先级
-
内存保护单元(MPU)
- 最多8个保护区域
- 支持权限控制
2.2 性能参数
| 参数 | 值 |
|---|---|
| 最高主频 | 168 MHz |
| 流水线级数 | 3级 |
| 乘法器 | 单周期32位乘法 |
| 除法器 | 2-12周期除法 |
| 中断延迟 | 12个周期 |
3. Cortex-M系列处理器全景
Cortex-M系列是ARM针对微控制器(MCU)市场设计的处理器IP核,覆盖从最低功耗到最高性能的完整产品线。除了 Cortex-M4,还有以下处理器:
3.1 处理器总览
| 处理器 | 架构版本 | 流水线 | 最高主频 | DSP | FPU | TrustZone | 典型应用 |
|---|---|---|---|---|---|---|---|
| Cortex-M0 | ARMv6-M | 2级 | 50 MHz | 无 | 无 | 无 | 最低成本/功耗 MCU |
| Cortex-M0+ | ARMv6-M | 2级 | 100 MHz | 无 | 无 | 无 | 低功耗 IoT 节点 |
| Cortex-M3 | ARMv7-M | 3级 | 100 MHz | 无 | 无 | 无 | 通用 MCU |
| Cortex-M4 | ARMv7E-M | 3级 | 168 MHz | 有 | 单精度 | 无 | 电机控制、音频处理 |
| Cortex-M7 | ARMv7E-M | 6级 | 480 MHz | 有 | 双精度 | 无 | 高性能嵌入式 |
| Cortex-M23 | ARMv8-M Baseline | 2级 | 75 MHz | 可选 | 无 | 可选 | 安全 IoT 节点 |
| Cortex-M33 | ARMv8-M Mainline | 4级 | 150 MHz | 可选 | 可选 | 可选 | 安全嵌入式系统 |
| Cortex-M55 | ARMv8.1-M | 4-7级 | 250 MHz | 有 | 有 | 可选 | AI/ML 边缘计算 |
| Cortex-M85 | ARMv8.1-M | 8级 | 400+ MHz | 有 | 有 | 可选 | 高性能安全 MCU |
3.2 各处理器详细对比
3.2.1 Cortex-M0 --- 最小最低功耗
定位:ARM Cortex-M 系列中最简单、最小、最低功耗的处理器。
┌─────────────────────────────────────────────────┐
│ Cortex-M0 │
├─────────────────────────────────────────────────┤
│ 架构: ARMv6-M │
│ 流水线: 2级 (取指 → 执行) │
│ 指令集: Thumb (仅16位指令,不含Thumb-2的32位指令)│
│ 中断: 最多32个外部中断 │
│ 门数: ~12K 门 (极小) │
│ 功耗: 0.042 mW/MHz (40nm工艺) │
│ 性能: 0.84 CoreMark/MHz │
└─────────────────────────────────────────────────┘关键特性:
- 无硬件除法:需要软件模拟除法
- 无位操作指令:不支持 CLZ、RBIT 等
- 无 MPU:不支持内存保护
- 中断优先级少:最多支持 4 级优先级
- 不支持非对齐访问:所有内存访问必须对齐
典型芯片:
- STM32F0 系列 (ST)
- LPC1100 系列 (NXP)
- EFM32 Zero Gecko (Silicon Labs)
- ATtiny 系列 (Microchip,部分型号)
应用场景:
- 低成本消费电子(遥控器、玩具)
- 简单传感器节点
- 电池供电的低功耗设备
- 替代传统 8 位/16 位单片机
3.2.2 Cortex-M0+ --- M0 的增强版
定位:在 M0 基础上改进,增加了更多实用特性,是目前出货量最大的 Cortex-M 处理器之一。
┌─────────────────────────────────────────────────┐
│ Cortex-M0+ │
├─────────────────────────────────────────────────┤
│ 架构: ARMv6-M │
│ 流水线: 2级 (优化为单周期执行大多数指令) │
│ 指令集: Thumb + 微控制器专用扩展 │
│ 中断: 最多32个外部中断 │
│ 门数: ~13K 门 │
│ 功耗: 0.037 mW/MHz (40nm工艺,比M0更低) │
│ 性能: 0.93 CoreMark/MHz │
└─────────────────────────────────────────────────┘相比 M0 的改进:
- 单周期 I/O 端口:通过专用的 I/O 端口实现快速 GPIO 操作
- 微跟踪缓冲区 (MTB):支持低成本的指令跟踪调试
- 更低功耗:优化了时钟门控,功耗比 M0 更低
- 可选 MPU:支持 8 区域内存保护
- 向量表重定位:支持将向量表重定位到任意地址
典型芯片:
- STM32L0/L4 系列 (ST,超低功耗产品线)
- LPC800 系列 (NXP)
- SAM L 系列 (Microchip)
- EFM32 Happy Gecko (Silicon Labs)
- nRF52 系列 (Nordic,蓝牙 SoC)
应用场景:
- 物联网终端节点(传感器采集)
- 可穿戴设备(手环、手表)
- 智能家居设备
- 超低功耗电池供电设备
3.2.3 Cortex-M3 --- 经典主流处理器
定位:Cortex-M 系列的经典之作,平衡了性能和成本,是历史上最成功的 MCU 处理器之一。
┌─────────────────────────────────────────────────┐
│ Cortex-M3 │
├─────────────────────────────────────────────────┤
│ 架构: ARMv7-M │
│ 流水线: 3级 (取指 → 解码 → 执行) │
│ 指令集: Thumb-2 (16位+32位混合指令) │
│ 中断: 最多240个外部中断,最多256级优先级 │
│ 门数: ~33K 门 │
│ 功耗: 0.052 mW/MHz (40nm工艺) │
│ 性能: 1.25 CoreMark/MHz │
│ 最高主频: 100 MHz │
└─────────────────────────────────────────────────┘关键特性:
- 硬件除法:支持 SDIV/UDIV 指令(2-12 周期)
- Thumb-2 指令集:16 位和 32 位指令混合,代码密度和性能兼顾
- 位操作指令:支持 CLZ、RBIT、BFI、UBFX 等
- MPU:可选 8 区域内存保护
- 低延迟中断:12 周期中断延迟,支持晚到异常处理
- 嵌套中断:硬件自动支持中断嵌套
- SysTick 定时器:内置系统滴答定时器
典型芯片:
- STM32F1 系列 (ST,最经典的 ARM MCU)
- LPC1700 系列 (NXP)
- TM4C123 系列 (TI)
- GD32F103 (GigaDevice,国产替代)
应用场景:
- 工业控制(PLC、电机驱动)
- 消费电子(家电、打印机)
- 汽车电子(车身控制、传感器)
- 教学和原型开发
3.2.4 Cortex-M4 --- DSP + FPU 的全能型
定位:在 M3 基础上增加 DSP 和 FPU 扩展,适合需要数字信号处理的应用。
┌─────────────────────────────────────────────────┐
│ Cortex-M4 │
├─────────────────────────────────────────────────┤
│ 架构: ARMv7E-M │
│ 流水线: 3级 │
│ 指令集: Thumb-2 + DSP 扩展 │
│ DSP: 单周期16/32位MAC、饱和运算、SIMD │
│ FPU: 单精度浮点 (IEEE 754) │
│ 中断: 最多240个外部中断 │
│ 门数: ~44K 门 (不含FPU) │
│ 功耗: 0.064 mW/MHz (含FPU) │
│ 性能: 1.25 CoreMark/MHz (不含FPU) / 3.42 DMIPS/MHz │
│ 最高主频: 168 MHz │
└─────────────────────────────────────────────────┘相比 M3 的增强:
- DSP 指令:MAC、MLA、SMLAL、USAT、SSAT、CLZ、RBIT 等
- SIMD 指令:支持 8 位/16 位数据并行运算
- 单精度 FPU:支持 float 类型硬件运算(可选,大部分芯片包含)
- 饱和运算:防止溢出的定点运算
典型芯片:
- STM32F4 系列 (ST)
- STM32F3 系列 (ST,混合信号)
- LPC4000 系列 (NXP)
- TM4C129 系列 (TI,带以太网)
- ATSAME4 系列 (Microchip)
应用场景:
- 电机控制(FOC 矢量控制)
- 音频处理(编解码、均衡器)
- 传感器融合(IMU、姿态解算)
- 数字电源(DC-DC、逆变器)
- 医疗设备(监护仪、超声)
3.2.5 Cortex-M7 --- 高性能旗舰
定位:Cortex-M 系列中性能最强的处理器,接近 Cortex-A 级别的性能。
┌─────────────────────────────────────────────────┐
│ Cortex-M7 │
├─────────────────────────────────────────────────┤
│ 架构: ARMv7E-M │
│ 流水线: 6级 (取指1 → 取指2 → 解码 → 执行 → 访存 → 写回) │
│ 指令集: Thumb-2 + DSP + 双精度 FPU │
│ DSP: 增强型,支持双精度运算 │
│ FPU: 双精度浮点 (IEEE 754) │
│ 缓存: 可选 I-Cache + D-Cache (4-64KB) │
│ TCM: 指令TCM + 数据TCM (0-16MB) │
│ 中断: 最多240个外部中断 │
│ 性能: 5.01 CoreMark/MHz / 6.14 DMIPS/MHz │
│ 最高主频: 480 MHz │
└─────────────────────────────────────────────────┘相比 M4 的增强:
- 6 级流水线:更高主频,更优性能
- 双精度 FPU:支持 double 类型硬件运算
- 缓存系统:可选 I-Cache 和 D-Cache,提升外部存储器访问效率
- 紧耦合存储器 (TCM):零等待周期的高速存储器
- 超标量取指:支持分支预测和双字取指
- AXI 总线接口:高性能总线,支持突发传输
典型芯片:
- STM32F7 系列 (ST)
- STM32H7 系列 (ST,主频 480MHz)
- i.MX RT 系列 (NXP,主频 600MHz)
- SAME70/V71 系列 (Microchip)
- XMC4500 系列 (Infineon)
应用场景:
- 高分辨率显示控制(LCD、TFT)
- 复杂音频处理(多通道、高采样率)
- 工业以太网通信
- 高性能电机控制(多轴同步)
- 图像处理(人脸识别、条码识别)
- 实时操作系统(复杂多任务)
3.2.6 Cortex-M23 --- ARMv8-M 入门安全型
定位:ARMv8-M 架构的入门级处理器,支持 TrustZone 安全扩展。
┌─────────────────────────────────────────────────┐
│ Cortex-M23 │
├─────────────────────────────────────────────────┤
│ 架构: ARMv8-M Baseline │
│ 流水线: 2级 │
│ 指令集: Thumb (ARMv8-M baseline) │
│ TrustZone: 可选支持 │
│ 中断: 最多240个外部中断 │
│ 门数: ~16K 门 (不含TrustZone) │
│ 性能: 0.95 CoreMark/MHz │
│ 最高主频: 75 MHz │
└─────────────────────────────────────────────────┘关键特性:
- TrustZone:可选的硬件安全隔离,将系统分为安全区和非安全区
- 安全属性单元 (SAU):最多 8 个安全区域
- 硬件除法:支持 SDIV/UDIV
- 低功耗:针对电池供电场景优化
- 向后兼容:与 M0/M0+ 代码高度兼容
与 M0/M0+ 的区别:
- 增加了 TrustZone 安全扩展
- 支持硬件除法
- 支持更宽的中断优先级范围
- 增加了安全相关的调试特性
典型芯片:
- STM32L5 系列 (ST)
- Nuvoton M2351 (新唐)
- MAX32520 (Maxim)
应用场景:
- 安全 IoT 节点
- 支付终端
- 智能门锁
- 安全认证设备
3.2.7 Cortex-M33 --- ARMv8-M 主流安全型
定位:ARMv8-M 架构的主流处理器,兼具安全性和性能,是当前新项目的热门选择。
┌─────────────────────────────────────────────────┐
│ Cortex-M33 │
├─────────────────────────────────────────────────┤
│ 架构: ARMv8-M Mainline │
│ 流水线: 4级 │
│ 指令集: Thumb-2 + DSP (可选) + FPU (可选) │
│ TrustZone: 可选支持 │
│ DSP: 可选 (与M4类似) │
│ FPU: 单精度 (可选) │
│ 中断: 最多480个外部中断 │
│ 性能: 4.02 CoreMark/MHz │
│ 最高主频: 150 MHz │
└─────────────────────────────────────────────────┘关键特性:
- TrustZone:完整的安全隔离机制
- 可选 DSP+FPU:灵活配置,按需选择
- 协处理器接口:支持自定义硬件加速器
- 内存屏障增强:改进了多核/多主场景下的内存一致性
- 信号量指令:新增 LDRT/STRT 等特权访问指令
- 增强的调试:支持更多断点和观察点
与 M4 的区别:
- 增加了 TrustZone 安全扩展
- 增加了协处理器接口
- 改进了中断控制器(支持更多中断)
- 增强了安全调试特性
典型芯片:
- STM32U5 系列 (ST,超低功耗 + 安全)
- STM32L5 系列 (ST)
- LPC5500 系列 (NXP)
- nRF5340 (Nordic,蓝牙5.2 SoC)
- EFM32PG22 (Silicon Labs)
- RA4M1/RA6M1 (Renesas)
应用场景:
- 安全物联网网关
- 智能家居安全控制
- 工业安全 PLC
- 医疗设备(需要安全认证)
- 蓝牙/Wi-Fi 安全通信
3.2.8 Cortex-M55 --- AI/ML 加速型
定位:Cortex-M 系列中首款支持 Helium(M-Profile Vector Extension)的处理器,专为 AI/ML 推理设计。
┌─────────────────────────────────────────────────┐
│ Cortex-M55 │
├─────────────────────────────────────────────────┤
│ 架构: ARMv8.1-M │
│ 流水线: 4-7级 (可变) │
│ Helium: M-Profile 向量扩展 (128位) │
│ DSP: 增强型 Helium DSP │
│ FPU: 单精度 + 可选双精度 │
│ TrustZone: 可选 │
│ 性能: 4.6 CoreMark/MHz (标量) │
│ 向量性能: 15.6 GMAC/s (8位MAC) │
│ 最高主频: 250 MHz │
└─────────────────────────────────────────────────┘关键特性:
- Helium 向量扩展 :128 位向量寄存器,支持 SIMD 运算
- 8 位/16 位/32 位整数并行运算
- 16 位/32 位浮点并行运算
- 单周期多 MAC 运算
- 自动向量化:编译器自动将循环向量化
- 自定义指令:通过 CDE (Custom Datapath Extension) 支持自定义硬件加速
- 低延迟内存访问:优化了缓存和 TCM 访问
典型芯片:
- STM32U5 系列 (部分型号)
- i.MX RT1170 (NXP)
- Musca-B1 (ARM 参考设计)
应用场景:
- 语音识别(关键词唤醒)
- 异常检测(振动分析、故障预测)
- 传感器融合 + AI 推理
- 图像分类(低分辨率)
- 预测性维护
3.2.9 Cortex-M85 --- 最高性能安全型
定位:Cortex-M 系列中性能最强的处理器,兼具安全性和 AI 能力。
┌─────────────────────────────────────────────────┐
│ Cortex-M85 │
├─────────────────────────────────────────────────┤
│ 架构: ARMv8.1-M │
│ 流水线: 8级 │
│ Helium: 128位向量扩展 │
│ TrustZone: 可选 │
│ FPU: 双精度浮点 │
│ 缓存: 可选 I-Cache + D-Cache │
│ TCM: 指令TCM + 数据TCM │
│ 性能: 6.28 CoreMark/MHz (目前M系列最高) │
│ 最高主频: 400+ MHz │
└─────────────────────────────────────────────────┘关键特性:
- 8 级流水线:接近 Cortex-A 级别的性能
- Branch Target Identification (BTI):硬件级别的控制流完整性保护
- Pointer Authentication (PAC):防止 ROP 攻击
- 增强的 Helium:更高吞吐量的向量运算
- 多核支持:支持多核配置
典型芯片:
- 预计 2024-2025 年量产
应用场景:
- 高性能安全 MCU
- 边缘 AI 推理
- 高端工业控制
- 汽车域控制器
3.3 架构版本演进
ARMv6-M (2004)
├── Cortex-M0 ─── 最小最低功耗
└── Cortex-M0+ ─── 增加 MTB、低功耗优化
ARMv7-M (2005)
└── Cortex-M3 ─── Thumb-2、硬件除法、NVIC
ARMv7E-M (2010)
├── Cortex-M4 ─── 增加 DSP + 单精度 FPU
└── Cortex-M7 ─── 6级流水线 + 双精度 FPU + 缓存
ARMv8-M Baseline (2016)
└── Cortex-M23 ─── 增加 TrustZone
ARMv8-M Mainline (2016)
└── Cortex-M33 ─── TrustZone + 可选 DSP/FPU + 协处理器
ARMv8.1-M (2019)
├── Cortex-M55 ─── 增加 Helium 向量扩展
└── Cortex-M85 ─── 8级流水线 + BTI/PAC 安全特性3.4 选型指南
┌─────────────────────────────────────────────────────────────────────┐
│ Cortex-M 选型决策树 │
└─────────────────────────────────────────────────────────────────────┘
需求分析
│
┌───────────┼───────────┐
│ │ │
成本/功耗优先 性能/功能优先 安全优先
│ │ │
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ M0/M0+ │ │ 需要FPU? │ │ 需要 │
│ │ │ │ │TrustZone?│
└──────────┘ └────┬─────┘ └────┬─────┘
┌────┴────┐ ┌──┴───┐
│ │ │ │
是 否 是 否
│ │ │ │
▼ ▼ ▼ ▼
┌────────┐ ┌────┐ ┌────┐ ┌────┐
│需要高 │ │M3 │ │M23 │ │M3 │
│性能? │ │ │ │M33 │ │M4 │
└───┬────┘ └────┘ └────┘ └────┘
┌────┴────┐
│ │
是 否
│ │
▼ ▼
┌────────┐ ┌────────┐
│M7/M85 │ │M4/M33 │
│(需AI?) │ │ │
│→M55/M85│ │ │
└────────┘ └────────┘按应用场景推荐:
| 应用场景 | 推荐处理器 | 理由 |
|---|---|---|
| 最低成本替换 8 位单片机 | M0/M0+ | 最小门数,最低功耗 |
| 超低功耗电池设备 | M0+ | 0.037 mW/MHz,MTB 调试 |
| 通用工业控制 | M3 | 成熟生态,性价比高 |
| 电机 FOC 控制 | M4 | DSP 指令,硬件除法 |
| 高精度浮点计算 | M7 | 双精度 FPU,缓存 |
| 蓝牙/Wi-Fi IoT | M33 | 安全 + 低功耗 + 无线 |
| 语音/图像 AI | M55 | Helium 向量加速 |
| 高端安全 MCU | M85 | BTI/PAC + 高性能 |
3.5 性能横向对比
CoreMark/MHz 性能对比 (越高越好):
Cortex-M0 ████░░░░░░░░░░░░░░░░░░░░░░ 0.84
Cortex-M0+ █████░░░░░░░░░░░░░░░░░░░░░ 0.93
Cortex-M3 ██████░░░░░░░░░░░░░░░░░░░░ 1.25
Cortex-M4 ██████░░░░░░░░░░░░░░░░░░░░ 1.25 (不含FPU)
Cortex-M23 █████░░░░░░░░░░░░░░░░░░░░░ 0.95
Cortex-M33 ████████████████░░░░░░░░░░ 4.02
Cortex-M55 ██████████████████░░░░░░░░ 4.60
Cortex-M7 ████████████████████░░░░░░ 5.01
Cortex-M85 ████████████████████████░░ 6.283.6 常见误区
-
M4 比 M3 更好?
- M4 增加了 DSP/FPU,但如果不需要这些功能,M3 更经济
- 门数更少,功耗更低
-
M7 是 M4 的升级版?
- M7 不仅仅是"更快的 M4",它有缓存、TCM、AXI 总线等
- 编程模型更复杂,需要考虑缓存一致性
-
ARMv8-M 比 ARMv7-M 更好?
- ARMv8-M 的主要价值在于 TrustZone 安全扩展
- 如果不需要安全特性,ARMv7-M 可能更合适
-
M33 可以替代 M4?
- M33 的 DSP/FPU 是可选的,需要确认芯片型号是否包含
- M33 的编程模型与 M4 有差异(TrustZone 相关)
-
Helium 可以替代专用 DSP?
- Helium 是通用向量扩展,不如专用 DSP 高效
- 对于简单 DSP 任务,M4 的 DSP 指令可能更合适
4. 寄存器组织
4.1 通用寄存器
Cortex-M4有16个32位通用寄存器:
R0-R12: 通用数据寄存器
R13 (SP): 栈指针寄存器
R14 (LR): 链接寄存器
R15 (PC): 程序计数器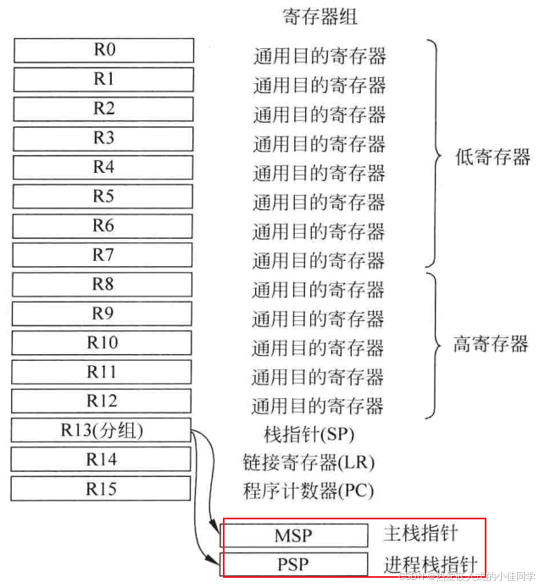
4.2 特殊寄存器
| 寄存器 | 名称 | 功能 |
|---|---|---|
| PSR | 程序状态寄存器 | 包含APSR, IPSR, EPSR |
| PRIMASK | 中断屏蔽寄存器 | 控制全局中断 |
| FAULTMASK | 故障屏蔽寄存器 | 控制故障处理 |
| BASEPRI | 基优先级寄存器 | 设置优先级阈值 |
| CONTROL | 控制寄存器 | 控制特权级别和栈选择 |
4.3 程序状态寄存器(PSR)
PSR由三个部分组成:
-
APSR(应用程序状态寄存器)
- N: 负数标志
- Z: 零标志
- C: 进位标志
- V: 溢出标志
- Q: 饱和标志
-
IPSR(中断程序状态寄存器)
- 包含当前异常编号
-
EPSR(执行程序状态寄存器)
- 包含Thumb状态位
- 包含IT指令状态
4.4 栈指针
Cortex-M4有两个栈指针:
- MSP(主栈指针):默认栈指针,用于异常处理和特权级代码
- PSP(进程栈指针):可选栈指针,用于用户级代码
5. 内存映射
5.1 STM32F407内存布局
0x0000 0000 - 0x1FFF FFFF: Flash存储器(512KB)
0x2000 0000 - 0x3FFF FFFF: SRAM(192KB)
0x4000 0000 - 0x5FFF FFFF: 外设
0x6000 0000 - 0x9FFF FFFF: 外部RAM
0xA000 0000 - 0xDFFF FFFF: 外部设备
0xE000 0000 - 0xE00F FFFF: 系统控制块(SCS)5.2 关键地址
| 地址范围 | 用途 |
|---|---|
| 0x0800 0000 | Flash起始地址 |
| 0x2000 0000 | SRAM起始地址 |
| 0x4002 0000 | AHB1外设基地址 |
| 0x4001 0000 | APB2外设基地址 |
| 0x4000 0000 | APB1外设基地址 |
| 0xE000 E000 | NVIC基地址 |
| 0xE000 ED00 | 系统控制块基地址 |
5.3 外设地址示例
c
// GPIO端口F基地址
#define GPIOF_BASE 0x40021400
// USART1基地址
#define USART1_BASE 0x40011000
// RCC基地址
#define RCC_BASE 0x400238006. 异常模型
6.1 异常类型
Cortex-M4支持以下异常类型:
| 异常编号 | 异常类型 | 优先级 | 说明 |
|---|---|---|---|
| 1 | 复位 | -3 | 系统复位 |
| 2 | NMI | -2 | 不可屏蔽中断 |
| 3 | HardFault | -1 | 硬件故障 |
| 4 | MemManage | 可配置 | 内存管理故障 |
| 5 | BusFault | 可配置 | 总线故障 |
| 6 | UsageFault | 可配置 | 用法故障 |
| 7-10 | 保留 | - | - |
| 11 | SVCall | 可配置 | 系统服务调用 |
| 12 | DebugMon | 可配置 | 调试监视器 |
| 13 | 保留 | - | - |
| 14 | PendSV | 可配置 | 可挂起系统调用 |
| 15 | SysTick | 可配置 | 系统定时器 |
| 16+ | 外部中断 | 可配置 | 外设中断 |
6.2 异常处理流程
-
异常发生
- 处理器检测到异常条件
- 保存当前状态到栈
-
状态保存
- 硬件自动保存R0-R3, R12, LR, PC, xPSR
- 软件可选择保存R4-R11
-
异常处理
- 跳转到异常处理程序
- 执行异常处理代码
-
异常返回
- 使用EXC_RETURN值返回
- 恢复保存的状态
- 继续执行被中断的代码
6.3 EXC_RETURN值
| 值 | 含义 |
|---|---|
| 0xFFFFFFF1 | 返回到Handler模式,使用MSP |
| 0xFFFFFFF9 | 返回到Thread模式,使用MSP |
| 0xFFFFFFFD | 返回到Thread模式,使用PSP |
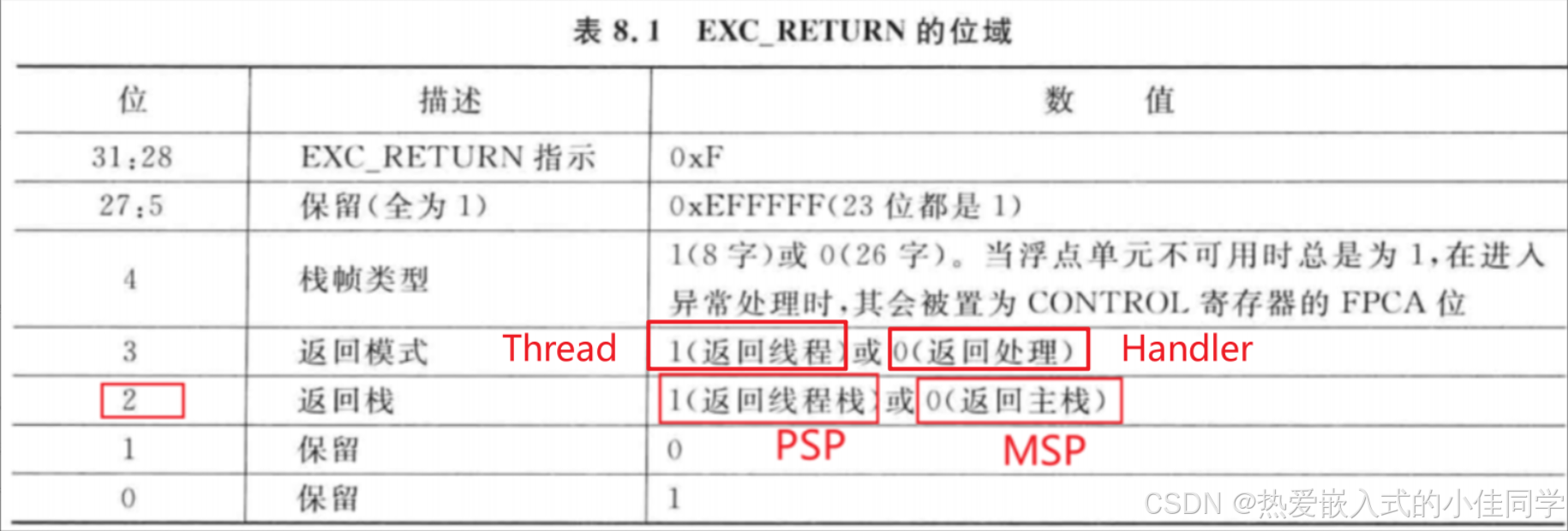
6.4 中断优先级
Cortex-M4支持可配置的中断优先级:
- 优先级分组:可配置抢占优先级和子优先级
- 优先级范围:0-255(STM32F407使用高4位,0-15)
- 数值越小,优先级越高
7. 指令集概述
7.1 Thumb-2指令集
Cortex-M4使用Thumb-2指令集,支持16位和32位指令混合使用。
7.2 数据处理指令
| 指令 | 功能 | 示例 |
|---|---|---|
| MOV | 数据传送 | MOV R0, R1 |
| MVN | 按位取反传送 | MVN R0, R1 |
| ADD | 加法 | ADD R0, R1, R2 |
| SUB | 减法 | SUB R0, R1, R2 |
| MUL | 乘法 | MUL R0, R1, R2 |
| AND | 按位与 | AND R0, R1, R2 |
| ORR | 按位或 | ORR R0, R1, R2 |
| EOR | 按位异或 | EOR R0, R1, R2 |
| BIC | 位清除 | BIC R0, R1, R2 |
| LSL | 逻辑左移 | LSL R0, R1, #2 |
| LSR | 逻辑右移 | LSR R0, R1, #2 |
| ASR | 算术右移 | ASR R0, R1, #2 |
| ROR | 循环右移 | ROR R0, R1, #2 |
7.3 加载/存储指令
| 指令 | 功能 | 示例 |
|---|---|---|
| LDR | 加载字 | LDR R0, [R1] |
| LDRB | 加载字节 | LDRB R0, [R1] |
| LDRH | 加载半字 | LDRH R0, [R1] |
| LDRSB | 加载有符号字节 | LDRSB R0, [R1] |
| LDRSH | 加载有符号半字 | LDRSH R0, [R1] |
| STR | 存储字 | STR R0, [R1] |
| STRB | 存储字节 | STRB R0, [R1] |
| STRH | 存储半字 | STRH R0, [R1] |
| LDM | 多寄存器加载 | LDM R0, {R1-R3} |
| STM | 多寄存器存储 | STM R0, {R1-R3} |
| PUSH | 压栈 | PUSH {R0-R3, LR} |
| POP | 出栈 | POP {R0-R3, PC} |
7.4 分支指令
| 指令 | 功能 | 示例 |
|---|---|---|
| B | 无条件分支 | B label |
| BEQ | 相等时分支 | BEQ label |
| BNE | 不相等时分支 | BNE label |
| BL | 带链接的分支 | BL function |
| BX | 寄存器分支 | BX LR |
| BLX | 带链接的寄存器分支 | BLX R0 |
7.5 比较指令
| 指令 | 功能 | 示例 |
|---|---|---|
| CMP | 比较 | CMP R0, R1 |
| CMN | 负数比较 | CMN R0, R1 |
| TST | 位测试 | TST R0, #0x01 |
| TEQ | 等值测试 | TEQ R0, R1 |
7.6 特殊指令
| 指令 | 功能 | 示例 |
|---|---|---|
| SVC | 系统服务调用 | SVC #0 |
| MRS | 读特殊寄存器 | MRS R0, PSR |
| MSR | 写特殊寄存器 | MSR PSR, R0 |
| CPSID | 禁用中断 | CPSID I |
| CPSIE | 启用中断 | CPSIE I |
| WFI | 等待中断 | WFI |
| WFE | 等待事件 | WFE |
| SEV | 发送事件 | SEV |
| NOP | 空操作 | NOP |
| DSB | 数据同步屏障 | DSB |
| ISB | 指令同步屏障 | ISB |
| DMB | 数据内存屏障 | DMB |
8. ARM与RISC-V架构对比
8.1 RISC-V简介
RISC-V是一个开源的精简指令集架构(ISA),由加州大学伯克利分校于2010年发起。与ARM的商业授权模式不同,RISC-V采用BSD许可证,任何人都可以免费使用。
┌─────────────────────────────────────────────────────────────────────────┐
│ RISC-V vs ARM 商业模式 │
└─────────────────────────────────────────────────────────────────────────┘
ARM商业模式: RISC-V商业模式:
┌─────────────────┐ ┌─────────────────┐
│ ARM公司 │ │ RISC-V基金会 │
│ (私有) │ │ (非营利) │
└────────┬────────┘ └────────┬────────┘
│ │
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ 授权收费 │ │ 开源免费 │
│ IP核授权 │ │ 规范公开 │
└────────┬────────┘ └────────┬────────┘
│ │
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ 芯片厂商 │ │ 任何人/公司 │
│ (ST, NXP等) │ │ 可自行设计 │
└─────────────────┘ └─────────────────┘8.2 主要区别概览
| 对比维度 | ARM | RISC-V |
|---|---|---|
| 商业模式 | 商业授权,需付费 | 开源免费,BSD许可证 |
| 起源 | 1985年,Acorn公司 | 2010年,伯克利大学 |
| 指令集 | 复杂,历史包袱多 | 简洁,模块化设计 |
| 生态成熟度 | 非常成熟 | 快速发展中 |
| 市场份额 | 占主导地位 | 新兴市场 |
| 授权厂商 | 500+合作伙伴 | 开放,无需授权 |
| 典型应用 | 手机、嵌入式、服务器 | IoT、AI、教育、研究 |
8.3 指令集架构对比
7.3.1 设计哲学差异
┌─────────────────────────────────────────────────────────────────────────┐
│ 设计哲学对比 │
└─────────────────────────────────────────────────────────────────────────┘
ARM设计哲学: RISC-V设计哲学:
┌─────────────────────────┐ ┌─────────────────────────┐
│ "做加法" │ │ "做减法" │
│ │ │ │
│ • 向后兼容性 │ │ • 最小化基础指令集 │
│ • 丰富的功能 │ │ • 模块化扩展 │
│ • 硬件优化 │ │ • 软件优先 │
│ • 复杂的指令 │ │ • 简单的指令 │
└─────────────────────────┘ └─────────────────────────┘
ARM: 200+ 基础指令,很多历史遗留指令
RISC-V: 47条基础指令(RV32I),可选扩展7.3.2 指令格式对比
ARM指令格式(Thumb-2):
assembly
; ARM Thumb-2指令长度可变:16位或32位
; 示例:
MOV R0, #5 ; 16位指令
ADD R0, R1, R2 ; 16位指令
LDR R0, [R1, #4] ; 32位指令
B.W label ; 32位分支指令RISC-V指令格式:
assembly
; RISC-V指令长度固定:32位(标准)或16位(压缩扩展)
; 示例(RV32I基础指令集):
addi x1, x0, 5 ; 立即数加法,32位
add x3, x1, x2 ; 寄存器加法,32位
lw x5, 4(x1) ; 加载字,32位
beq x1, x2, label ; 条件分支,32位
c.add x1, x2 ; 压缩指令,16位(需要C扩展)7.3.3 寄存器对比
┌─────────────────────────────────────────────────────────────────────────┐
│ 寄存器组织对比 │
└─────────────────────────────────────────────────────────────────────────┘
ARM Cortex-M4: RISC-V (RV32I):
┌─────────────────────┐ ┌─────────────────────┐
│ R0-R12 (通用) │ │ x0-x31 (32个通用) │
│ R13 (SP) 栈指针 │ │ x0 硬连线0 │
│ R14 (LR) 链接 │ │ x1 返回地址 │
│ R15 (PC) 程序计数 │ │ x2 栈指针 │
│ 特殊寄存器若干 │ │ x3-x31 通用 │
└─────────────────────┘ └─────────────────────┘
│ │
▼ ▼
┌─────────────────────┐ ┌─────────────────────┐
│ 16个寄存器 │ │ 32个寄存器 │
│ R0-R15 │ │ x0-x31 │
│ 部分有特殊用途 │ │ x0恒为0,其余通用 │
└─────────────────────┘ └─────────────────────┘8.4 中断与异常处理对比
| 特性 | ARM Cortex-M | RISC-V |
|---|---|---|
| 中断控制器 | NVIC(内置) | PLIC/CLINT(外置或可选) |
| 中断数量 | 最多240个外部中断 | 取决于实现 |
| 优先级 | 硬件优先级,可配置 | 软件管理为主 |
| 向量表 | 硬件向量表 | 可选向量模式 |
| 上下文保存 | 硬件自动保存部分寄存器 | 软件保存全部寄存器 |
| 嵌套中断 | 硬件支持 | 需要软件实现 |
┌─────────────────────────────────────────────────────────────────────────┐
│ 中断处理流程对比 │
└─────────────────────────────────────────────────────────────────────────┘
ARM Cortex-M 中断处理:
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ 中断发生 │───>│ 硬件自动保存 │───>│ 跳转到向量表 │
│ │ │ R0-R3,R12, │ │ 对应处理函数 │
│ │ │ LR,PC,xPSR │ │ │
└──────────────┘ └──────────────┘ └──────────────┘
RISC-V 中断处理:
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ 中断发生 │───>│ 硬件保存PC │───>│ 跳转到mtvec │
│ │ │ 到mepc寄存器 │ │ 保存的地址 │
│ │ │ 其余软件保存 │ │ │
└──────────────┘ └──────────────┘ └──────────────┘8.5 生态系统对比
┌─────────────────────────────────────────────────────────────────────────┐
│ 生态系统成熟度对比 │
└─────────────────────────────────────────────────────────────────────────┘
ARM RISC-V
│ │
┌───────────────┼───────────────┐ ├───────────────────┐
│ │ │ │ │
▼ ▼ ▼ ▼ ▼
┌───────┐ ┌───────────┐ ┌──────────┐ ┌───────────┐ ┌───────────┐
│开发工具│ │ 操作系统 │ │ 编译器 │ │ 开发工具 │ │ 操作系统 │
│ │ │ │ │ │ │ │ │ │
│Keil │ │FreeRTOS │ │GCC │ │GCC/LLVM │ │Linux │
│IAR │ │RT-Thread │ │Clang │ │GDB │ │FreeRTOS │
│STM32 │ │Zephyr │ │ │ │OpenOCD │ │RT-Thread │
│CubeIDE│ │Linux │ │ │ │ │ │Zephyr │
└───────┘ └───────────┘ └──────────┘ └───────────┘ └───────────┘
│ │ │ │ │
└───────────────┴───────────────┘ └───────────────────┘
│ │
▼ ▼
┌─────────────┐ ┌─────────────┐
│ 生态成熟度 │ │ 生态成熟度 │
│ ★★★★★ │ │ ★★★☆☆ │
│ (非常成熟) │ │ (快速发展) │
└─────────────┘ └─────────────┘8.6 开发工具对比
| 工具类型 | ARM | RISC-V |
|---|---|---|
| IDE | Keil MDK, IAR, STM32CubeIDE | VS Code + 插件, Freedom Studio |
| 编译器 | ARM GCC, ARM Clang, IAR | RISC-V GCC, LLVM |
| 调试器 | J-Link, ST-Link, ULINK | J-Link, OpenOCD, FT2232 |
| 仿真器 | QEMU (部分支持) | QEMU, Spike |
| RTOS | FreeRTOS, RT-Thread, uC/OS | FreeRTOS, RT-Thread, Zephyr |
| 操作系统 | Linux, Windows IoT | Linux (多发行版支持) |
8.7 芯片厂商与产品对比
┌─────────────────────────────────────────────────────────────────────────┐
│ 主要芯片厂商对比 │
└─────────────────────────────────────────────────────────────────────────┘
ARM 生态: RISC-V 生态:
┌─────────────────────────┐ ┌─────────────────────────┐
│ │ │ │
│ ┌─────┐ ┌─────┐ │ │ ┌─────┐ ┌─────┐ │
│ │ ST │ │ NXP │ │ │ │SiFive│ │GD32 │ │
│ │ │ │ │ │ │ │ │ │ │ │
│ └─────┘ └─────┘ │ │ └─────┘ └─────┘ │
│ │ │ │
│ ┌─────┐ ┌─────┐ │ │ ┌─────┐ ┌─────┐ │
│ │TI │ │Infineon│ │ │ │阿里 │ │芯来 │ │
│ │ │ │ │ │ │ │平头哥│ │科技 │ │
│ └─────┘ └─────┘ │ │ └─────┘ └─────┘ │
│ │ │ │
│ 产品举例: │ │ 产品举例: │
│ STM32系列 │ │ SiFive FE310 │
│ LPC系列 │ │ GD32VF103 │
│ i.MX系列 │ │ 玄铁C910 │
└─────────────────────────┘ └─────────────────────────┘8.8 性能与功耗对比
| 对比项 | ARM Cortex-M4 | RISC-V (同等定位) |
|---|---|---|
| 典型主频 | 168 MHz | 100-200 MHz |
| 流水线 | 3级 | 2-5级(取决于实现) |
| 功耗 | 中等 | 通常更低 |
| 面积 | 中等 | 通常更小 |
| 性能/MHz | 较高 | 接近或相当 |
| DSP支持 | 硬件支持 | 需要P扩展 |
| FPU | 硬件支持 | 需要F/D扩展 |
8.9 代码示例对比
实现相同功能的代码对比:
c
// 功能:计算两个数组的点积
// C代码(ARM和RISC-V通用)
int dot_product(int *a, int *b, int n) {
int sum = 0;
for (int i = 0; i < n; i++) {
sum += a[i] * b[i];
}
return sum;
}
assembly
; ARM Thumb-2 汇编实现
dot_product:
MOV R3, #0 ; sum = 0
loop:
CMP R2, #0 ; 比较n
BEQ done ; if n == 0, 跳转到done
LDR R4, [R0], #4 ; R4 = *a++, 后索引
LDR R5, [R1], #4 ; R5 = *b++, 后索引
MLA R3, R4, R5, R3 ; R3 = R4 * R5 + R3
SUB R2, R2, #1 ; n--
B loop ; 继续循环
done:
MOV R0, R3 ; 返回值
BX LR ; 返回
assembly
; RISC-V 汇编实现
dot_product:
li a3, 0 ; sum = 0
loop:
beq a2, zero, done ; if n == 0, 跳转到done
lw t0, 0(a0) ; t0 = *a
lw t1, 0(a1) ; t1 = *b
mul t2, t0, t1 ; t2 = t0 * t1
add a3, a3, t2 ; sum += t2
addi a0, a0, 4 ; a++
addi a1, a1, 4 ; b++
addi a2, a2, -1 ; n--
j loop ; 继续循环
done:
mv a0, a3 ; 返回值
ret ; 返回8.10 如何选择?
┌─────────────────────────────────────────────────────────────────────────┐
│ 选择建议 │
└─────────────────────────────────────────────────────────────────────────┘
选择ARM的场景:
┌─────────────────────────────────────────────────────────────────────────┐
│ ✓ 需要成熟的生态系统和丰富的第三方库 │
│ ✓ 产品需要快速上市 │
│ ✓ 团队已有ARM开发经验 │
│ ✓ 需要商业支持和长期维护 │
│ ✓ 移动设备、消费电子、汽车电子 │
└─────────────────────────────────────────────────────────────────────────┘
选择RISC-V的场景:
┌─────────────────────────────────────────────────────────────────────────┐
│ ✓ 成本敏感的产品(无需授权费) │
│ ✓ 需要定制化处理器 │
│ ✓ 教育和研究用途 │
│ ✓ 对开源有硬性要求 │
│ ✓ IoT、AI边缘计算等新兴领域 │
│ ✓ 国产替代需求 │
└─────────────────────────────────────────────────────────────────────────┘8.11 未来发展趋势
| 趋势 | ARM | RISC-V |
|---|---|---|
| 生态发展 | 继续完善,保持领先 | 快速追赶,逐渐成熟 |
| 市场扩展 | 服务器、PC市场 | IoT、AI、汽车 |
| 技术演进 | ARMv9, 更多安全特性 | 标准化、模块化完善 |
| 国产化 | 受限于授权 | 国产RISC-V芯片崛起 |
| 人才需求 | 稳定 | 快速增长 |
总结:
- ARM 是当前嵌入式开发的主流,生态成熟,工具完善
- RISC-V 是未来趋势,开源免费,适合定制化和新兴应用
- 建议先掌握ARM,再学习RISC-V,两者并不冲突
- 很多厂商同时支持两种架构(如GD32既有ARM也有RISC-V产品)
9. 总结
ARM架构是嵌入式开发的基础,掌握ARM架构对于理解和调试单片机程序至关重要。