系列文章目录
B站视频内容智能分析系统(二):Docker Compose 一键部署
文章目录
- 系列文章目录
- 前言
- [一、为什么选 Docker Compose](#一、为什么选 Docker Compose)
- 二、整体结构
- [三、Profiles 区分环境](#三、Profiles 区分环境)
- [1. 核心思路](#1. 核心思路)
- [2. 两种环境对比](#2. 两种环境对比)
- 四、服务拆解
- [1. 基础设施:ChromaDB](#1. 基础设施:ChromaDB)
- [2. Text-to-SQL 服务](#2. Text-to-SQL 服务)
- [3. RAG 服务](#3. RAG 服务)
- [4. Router Agent](#4. Router Agent)
- [5. 前端 + Nginx](#5. 前端 + Nginx)
- [6. GPU 转录服务(仅开发机)](#6. GPU 转录服务(仅开发机))
- [7. bilibili-monitor(按需运行)](#7. bilibili-monitor(按需运行))
- [8. bilibili-cron(定时调度)](#8. bilibili-cron(定时调度))
- [五、Dockerfile 编写:国内镜像加速](#五、Dockerfile 编写:国内镜像加速)
- [1. apt 换阿里云镜像](#1. apt 换阿里云镜像)
- [2. pip 换清华 TUNA 镜像](#2. pip 换清华 TUNA 镜像)
- [3. npm 换淘宝镜像](#3. npm 换淘宝镜像)
- [4. 完整的 bilibili-monitor Dockerfile](#4. 完整的 bilibili-monitor Dockerfile)
- [六、Volume 与数据共享](#六、Volume 与数据共享)
- [1. 四个 Named Volume](#1. 四个 Named Volume)
- [2. Bind Mount](#2. Bind Mount)
- [3. Docker Socket 挂载](#3. Docker Socket 挂载)
- 七、环境变量管理
- [1. .env 文件结构](#1. .env 文件结构)
- [2. 变量透传](#2. 变量透传)
- [3. 默认值语法](#3. 默认值语法)
- 八、健康检查与依赖关系
- [1. healthcheck 配置](#1. healthcheck 配置)
- [2. depends_on 启动顺序](#2. depends_on 启动顺序)
- [九、Nginx 反向代理配置](#九、Nginx 反向代理配置)
- 十、一键启动与验证
- 总结
前言
上一篇讲了整体架构,这篇来讲怎么把它跑起来。
这个项目一共有 7 个 Docker 容器,如果一个个手动 docker run,光端口映射和环境变量就能搞半天。所以我用 Docker Compose 做统一编排,一行命令启动所有服务。
这篇会把 docker-compose.yml 从头到尾拆一遍,包括 profiles 怎么用、Dockerfile 怎么写国内镜像加速、Volume 怎么设计数据共享、健康检查和依赖顺序怎么配。
截图:docker compose up 启动过程,显示各容器依次创建和启动
一、为什么选 Docker Compose
先说为什么不用 Kubernetes。
理由很简单:单机部署,不需要 K8s 的复杂度。
这个项目的生产环境是一台 NAS(Intel N150 + 8GB 内存),开发环境是一台笔记本电脑。都是单机,没有多节点的需求。Docker Compose 在这种场景下是最合适的选择:
- 一个 YAML 文件搞定所有容器:端口、环境变量、Volume、依赖关系全在里面
- profiles 区分环境:同一个文件,dev 和 nas 两套环境
- 一键启动/停止 :
docker compose up -d启动,docker compose down停止 - 重建方便 :改了代码之后
docker compose up -d --build就能重建镜像并重启
如果你的项目也是单机多容器,Docker Compose 基本就是最优解。
二、整体结构
先看一下整个 docker-compose.yml 的结构(不含具体配置,只看骨架):
yaml
services:
# ===== 基础设施 =====
chromadb: # 向量数据库
profiles: [dev, nas]
# ===== 核心业务 =====
text-to-sql: # 结构化查询
profiles: [dev, nas]
rag: # 语义检索
profiles: [dev, nas]
router-agent: # 路由分发
profiles: [dev, nas]
# ===== 前端 =====
frontend: # React + Nginx
profiles: [dev, nas]
gpu-service: # GPU 转录
profiles: [dev]
# ===== 按需服务 =====
bilibili-monitor: # B站采集(非常驻)
profiles: [dev, nas]
bilibili-cron: # 定时调度
profiles: [nas]
volumes:
duckdb-data: # 结构化数据
chromadb-data: # 向量数据
bilibili-data: # 音频/转写/checkpoint
bilibili-cron-logs: # 定时任务日志8 个服务,4 个 Volume。每个服务通过 profiles 标签控制在哪个环境下启动。
三、Profiles 区分环境
1. 核心思路
Docker Compose 的 profiles 功能可以标记每个服务属于哪个"环境"。启动时指定 profile,只有匹配的服务才会启动。
yaml
services:
chromadb:
profiles: [dev, nas] # 两个环境都启动
gpu-service:
profiles: [dev] # 仅开发环境(有 GPU)
bilibili-cron:
profiles: [nas] # 仅生产环境(定时采集)这样同一个 YAML 文件就能服务两个环境,不需要维护两份配置文件。
2. 两种环境对比
| 服务 | dev(开发机) | nas(NAS) | 说明 |
|---|---|---|---|
| chromadb | ✅ | ✅ | 向量数据库,两边都要 |
| text-to-sql | ✅ | ✅ | SQL 查询服务 |
| rag | ✅ | ✅ | RAG 检索服务 |
| router-agent | ✅ | ✅ | 路由 Agent |
| frontend | ✅ | ✅ | 前端 |
| gpu-service | ✅ | ❌ | 需要 NVIDIA GPU |
| bilibili-monitor | ✅ | ✅ | 按需运行 |
| bilibili-cron | ❌ | ✅ | 定时采集仅生产环境 |
启动命令:
bash
# 开发机(含 GPU 转录)
docker compose --profile dev up -d
# NAS 生产(含定时调度)
docker compose --profile nas up -d四、服务拆解
接下来逐个拆解每个服务的配置。
1. 基础设施:ChromaDB
ChromaDB 是向量数据库,存的是文档的 Embedding 向量。它用的是官方镜像,不需要自己写 Dockerfile。
yaml
chromadb:
image: chromadb/chroma:latest
container_name: chromadb
profiles: [dev, nas]
ports:
- "8001:8000"
volumes:
- chromadb-data:/data
environment:
- IS_PERSISTENT=TRUE
- ANONYMIZED_TELEMETRY=FALSE
restart: unless-stopped
mem_limit: 1g
healthcheck:
test: ["CMD-SHELL", "bash -c 'exec 3<>/dev/tcp/localhost/8000'"]
interval: 30s
timeout: 10s
retries: 3
start_period: 15s几个关键点:
image: chromadb/chroma:latest:直接用官方镜像,不用自己构建IS_PERSISTENT=TRUE:开启持久化,数据写到/data目录- 端口映射
8001:8000:容器内是 8000,映射到宿主机的 8001(避免和其他服务冲突) mem_limit: 1g:NAS 只有 8GB 内存,每个服务都得限制- healthcheck:ChromaDB 官方镜像没有内置健康检查,这里用 bash 的 TCP 连接检测替代 curl
2. Text-to-SQL 服务
yaml
text-to-sql:
build:
context: ./text-to-sql
dockerfile: Dockerfile
container_name: text-to-sql
profiles: [dev, nas]
ports:
- "8010:8010"
environment:
- MINIMAX_API_KEY=${MINIMAX_API_KEY}
- MINIMAX_BASE_URL=${MINIMAX_BASE_URL:-https://api.minimaxi.com/anthropic}
- DATABASE_PATH=/app/data/content.db
volumes:
- duckdb-data:/app/data
restart: unless-stopped
mem_limit: 2g
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8010/"]
interval: 30s
timeout: 10s
retries: 3
start_period: 10sbuild.context: ./text-to-sql:Dockerfile 在 text-to-sql 目录下DATABASE_PATH=/app/data/content.db:DuckDB 数据库文件路径duckdb-data:/app/data:DuckDB 数据存在 Named Volume 里,多个服务共享mem_limit: 2g:Text-to-SQL 用了 MiniMax M2.7 做 SQL 生成,内存消耗较大
3. RAG 服务
yaml
rag:
build:
context: .
dockerfile: personal-knowledge-rag/Dockerfile
container_name: rag
profiles: [dev, nas]
ports:
- "8090:8090"
environment:
- LLM_PROVIDER=${LLM_PROVIDER:-deepseek}
- LLM_MODEL=${RAG_LLM_MODEL:-deepseek-v4-pro}
- REFINE_API_KEY=${REFINE_API_KEY}
- REFINE_API_URL=${REFINE_API_URL}
- REFINE_MODEL=${REFINE_MODEL:-deepseek-v4-flash}
- SILICONFLOW_API_KEY=${SILICONFLOW_API_KEY}
- CHROMA_HOST=chromadb
- CHROMA_PORT=8000
volumes:
- ./personal-knowledge-rag/video_knowledge:/app/video_knowledge
- ./personal-knowledge-rag/chroma_db:/app/chroma_db
depends_on:
chromadb:
condition: service_healthy
restart: unless-stopped
mem_limit: 2gRAG 服务的 build context 是 .(项目根目录),因为它的 Dockerfile 需要访问 shared/ 目录(共享的 Python 模块)。这是一个容易踩的坑------如果 context 设成子目录,COPY shared/ 就会找不到文件。
注意 depends_on 用了 condition: service_healthy,确保 ChromaDB 健康检查通过后才启动 RAG。
4. Router Agent
Router Agent 是整个系统的入口,需要透传很多环境变量:
yaml
router-agent:
build:
context: ./router-agent
dockerfile: Dockerfile
container_name: router-agent
profiles: [dev, nas]
ports:
- "8000:8000"
environment:
- CHAT_API_KEY=${MINIMAX_API_KEY}
- SQL_SERVICE_URL=http://text-to-sql:8010
- RAG_SERVICE_URL=http://rag:8090
# 透传给 bilibili-monitor(通过 Docker SDK 触发)
- BILIBILI_COOKIE=${BILIBILI_COOKIE}
- REFINE_API_URL=${REFINE_API_URL}
- REFINE_API_KEY=${REFINE_API_KEY}
- REFINE_MODEL=${REFINE_MODEL:-deepseek-v4-flash}
volumes:
- duckdb-data:/app/data
- /var/run/docker.sock:/var/run/docker.sock
- ./bilibili-monitor/config:/app/bilibili-config
depends_on:
text-to-sql:
condition: service_healthy
rag:
condition: service_healthy这里有一个特别重要的配置:/var/run/docker.sock:/var/run/docker.sock。
Router Agent 需要通过 Docker SDK 动态启动 bilibili-monitor 容器来执行采集任务。挂载 Docker socket 后,容器内就能控制宿主机的 Docker daemon。这是一个比较"暴力"的做法,但在单机场景下是最简单的方案。
SQL_SERVICE_URL 和 RAG_SERVICE_URL 用的是 Docker 内部 DNS(容器名直接当主机名),不需要写 IP 地址。
5. 前端 + Nginx
yaml
frontend:
build:
context: ./text-to-sql/frontend
dockerfile: Dockerfile
container_name: frontend
profiles: [dev, nas]
ports:
- "80:80"
volumes:
- ./text-to-sql/frontend/nginx.conf:/etc/nginx/conf.d/default.conf:ro
depends_on:
- router-agent
- text-to-sql
restart: unless-stopped
mem_limit: 256m前端用的是多阶段构建:先 npm run build 编译 React 代码,再把产物 COPY 到 Nginx 镜像里。:ro 表示只读挂载,防止容器内意外修改 nginx 配置。
内存限制只给了 256m,因为 Nginx 本身非常轻量。
6. GPU 转录服务(仅开发机)
yaml
gpu-service:
build:
context: ./bilibili-monitor
dockerfile: Dockerfile.gpu
container_name: gpu-service
profiles: [dev]
ports:
- "8011:8011"
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
mem_limit: 4gdeploy.resources.reservations.devices 这个配置是用来做 GPU 直通的。需要宿主机安装 NVIDIA Container Toolkit,Docker Compose 会自动把 GPU 设备映射到容器内。
注意 profiles: [dev],NAS 上没有 GPU,不会启动这个服务。
7. bilibili-monitor(按需运行)
bilibili-monitor 比较特殊------它不是常驻服务,只在采集时启动,跑完就退出。
yaml
bilibili-monitor:
build:
context: .
dockerfile: bilibili-monitor/Dockerfile
container_name: bilibili-monitor
profiles: [dev, nas]
restart: "no"
mem_limit: 4g
command: ["echo", "bilibili-monitor 镜像就绪,等待前端触发采集..."]restart: "no":不自动重启,跑完就退出command覆盖了 Dockerfile 的 CMD:默认只是打印一条消息,表示镜像就绪。实际采集是通过 Router Agent 的 Docker SDK 动态启动新容器来执行的
为什么不在这里直接跑采集?因为前端需要控制采集参数(选哪些 UP主、是否全量扫描),这些参数是通过 API 传给 Router Agent,再由 Router Agent 动态构建 docker run 命令来启动的。
8. bilibili-cron(定时调度)
yaml
bilibili-cron:
image: docker:cli
container_name: bilibili-cron
profiles: [nas]
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- ./bilibili-monitor/cron_entry.sh:/usr/local/bin/cron_entry.sh:ro
entrypoint: /bin/sh
command: >
-c "
apk add --no-cache bash > /dev/null 2>&1;
chmod +x /usr/local/bin/cron_entry.sh;
echo '17 */6 * * * /usr/local/bin/cron_entry.sh' > /etc/crontabs/root;
echo '[bilibili-cron] 定时任务已启动(每6小时运行,:17 触发)';
crond -f -l 2
"
restart: unless-stopped
mem_limit: 128m这个容器用的是 docker:cli 官方镜像(Alpine Linux + Docker CLI),里面跑一个 crond 守护进程。每 6 小时通过 cron_entry.sh 脚本触发一次 bilibili-monitor 容器。
为什么用 17 */6 而不是 0 */6?因为整点(:00)是各种定时任务的高峰期,错峰到 :17 可以减少同时启动的资源争抢。
只给了 128m 内存,因为 crond + docker cli 几乎不占资源。
五、Dockerfile 编写:国内镜像加速
在国内构建 Docker 镜像,最大的痛点就是下载慢。我在每个 Dockerfile 里都做了三级镜像加速。
1. apt 换阿里云镜像
dockerfile
# 使用国内 Debian 镜像加速 apt 安装
RUN sed -i 's|deb.debian.org|mirrors.aliyun.com|g' /etc/apt/sources.list.d/debian.sources 2>/dev/null; \
sed -i 's|deb.debian.org|mirrors.aliyun.com|g' /etc/apt/sources.list 2>/dev/null; \
true2>/dev/null 和 true 是为了兼容不同版本的 Debian 基础镜像。新版 Debian 的源配置在 /etc/apt/sources.list.d/debian.sources,旧版在 /etc/apt/sources.list,两个都改一遍,哪个报错忽略就行。
2. pip 换清华 TUNA 镜像
dockerfile
RUN pip install --no-cache-dir -i https://pypi.tuna.tsinghua.edu.cn/simple/ \
--trusted-host pypi.tuna.tsinghua.edu.cn \
-r requirements.txt--no-cache-dir 不缓存下载的安装包,减小镜像体积。--trusted-host 避免 HTTPS 证书问题。
3. npm 换淘宝镜像
前端的 Dockerfile 里,npm 安装也要换源:
dockerfile
RUN npm config set registry https://registry.npmmirror.com
RUN npm cinpm ci 比 npm install 更适合 Docker 构建,它严格按照 package-lock.json 安装,更快也更稳定。
4. 完整的 bilibili-monitor Dockerfile
dockerfile
FROM python:3.11-slim
# apt 换阿里云
RUN sed -i 's|deb.debian.org|mirrors.aliyun.com|g' /etc/apt/sources.list.d/debian.sources 2>/dev/null; \
sed -i 's|deb.debian.org|mirrors.aliyun.com|g' /etc/apt/sources.list 2>/dev/null; \
true
# 安装系统依赖(ffmpeg 用于音频转写)
RUN apt-get update && apt-get install -y --fix-missing \
ffmpeg \
curl \
&& rm -rf /var/lib/apt/lists/*
WORKDIR /app
# 复制共享模块
COPY shared/ ./shared/
ENV PYTHONPATH=/app/shared
# pip 换清华 TUNA
COPY bilibili-monitor/requirements.txt .
RUN pip install --no-cache-dir -i https://pypi.tuna.tsinghua.edu.cn/simple/ \
--trusted-host pypi.tuna.tsinghua.edu.cn \
-r requirements.txt
COPY bilibili-monitor/src/ ./src/
COPY bilibili-monitor/config/ ./config/
RUN mkdir -p downloads transcripts data chromadb
ENV PYTHONUNBUFFERED=1
ENV WHISPER_DEVICE=cpu
ENV WHISPER_MODEL=small
ENV COMPUTE_TYPE=int8
CMD ["python", "src/monitor_all.py"]几个小技巧:
COPY shared/ ./shared/:bilibili-monitor 的构建上下文是项目根目录,所以能直接 COPY 根目录下的 shared/ 模块ENV PYTHONPATH=/app/shared:让 Python 能找到 shared 模块PYTHONUNBUFFERED=1:确保 Python 的 print 输出实时刷新到 Docker 日志,不被缓冲
截图:Docker build 过程,可以看到使用清华 pip 镜像的下载速度
六、Volume 与数据共享
1. 四个 Named Volume
yaml
volumes:
duckdb-data: # DuckDB 数据库
chromadb-data: # ChromaDB 向量数据
bilibili-data: # B站原始数据(音频、转写、checkpoint)
bilibili-cron-logs: # 定时任务日志数据共享关系:
duckdb-data:/app/data
├── bilibili-monitor 写入(采集时写 video_meta)
├── text-to-sql 读取(SQL 查询)
└── router-agent 读取(查询日志 + 统计数据)
chromadb-data:/data
├── chromadb 管理(向量存储和检索)
└── bilibili-monitor 通过 HTTP API 写入
bilibili-data:/app/downloads
├── bilibili-monitor 写入(下载的音频、转写文本、checkpoint 文件)
└── gpu-service 读取(GPU 转写时访问音频文件)duckdb-data 是最关键的------bilibili-monitor 采集时把数据写进去,text-to-sql 和 router-agent 从里面读。三个容器共享同一个 Volume,数据天然一致。
2. Bind Mount
除了 Named Volume,还有一些用 Bind Mount(直接映射宿主机目录):
yaml
# RAG 服务的 Bind Mount
volumes:
- ./personal-knowledge-rag/video_knowledge:/app/video_knowledge
- ./personal-knowledge-rag/chroma_db:/app/chroma_db
# Router Agent 的 Bind Mount
volumes:
- ./bilibili-monitor/config:/app/bilibili-configBind Mount 的好处是宿主机可以直接看到和编辑文件,方便调试。缺点是路径和宿主机绑定,换台机器可能需要改路径。
3. Docker Socket 挂载
yaml
volumes:
- /var/run/docker.sock:/var/run/docker.sockRouter Agent 和 bilibili-cron 都挂载了 Docker socket,这样它们可以在容器内控制宿主机的 Docker daemon(启动/停止其他容器)。
这是单机部署的常见做法,但需要注意安全风险------如果容器被攻破,攻击者就能控制整个 Docker daemon。在生产环境中,更安全的方案是使用 Docker API 的 TLS 认证。
七、环境变量管理
1. .env 文件结构
所有的 API Key 和可配置项都放在项目根目录的 .env 文件里(不提交到 Git):
bash
# Embedding API(SiliconFlow)
EMBEDDING_PROVIDER=siliconflow
EMBEDDING_API_KEY=sk-xxx
EMBEDDING_BASE_URL=https://api.siliconflow.cn/v1
EMBEDDING_MODEL=BAAI/bge-large-zh-v1.5
# Chat API(MiniMax M2.7)
CHAT_API_KEY=sk-xxx
CHAT_BASE_URL=https://api.minimaxi.com/anthropic
CHAT_MODEL=MiniMax-M2.7
# DeepSeek(精炼 + RAG 问答)
REFINE_API_URL=https://api.deepseek.com/v1/chat/completions
REFINE_API_KEY=sk-xxx
REFINE_MODEL=deepseek-v4-flash
# B站 Cookie
BILIBILI_COOKIE=
# Whisper 转写
WHISPER_DEVICE=cpu
WHISPER_MODEL=small
COMPUTE_TYPE=int8.env 文件会被 Docker Compose 自动读取,通过 ${变量名} 语法注入到容器里。
2. 变量透传
Router Agent 是一个"中间人"------它自己需要 MiniMax API Key 来做意图分类,同时还需要把 bilibili-monitor 的各种环境变量透传下去(因为采集是通过 Docker SDK 动态启动的):
yaml
router-agent:
environment:
# 自己用的
- CHAT_API_KEY=${MINIMAX_API_KEY}
- SQL_SERVICE_URL=http://text-to-sql:8010
- RAG_SERVICE_URL=http://rag:8090
# 透传给 bilibili-monitor
- BILIBILI_COOKIE=${BILIBILI_COOKIE}
- REFINE_API_URL=${REFINE_API_URL}
- REFINE_API_KEY=${REFINE_API_KEY}
- REFINE_MODEL=${REFINE_MODEL:-deepseek-v4-flash}
- WHISPER_DEVICE=${WHISPER_DEVICE:-cpu}
- WHISPER_MODEL=${WHISPER_MODEL:-small}3. 默认值语法
Docker Compose 支持 ${变量:-默认值} 语法:
yaml
- REFINE_MODEL=${REFINE_MODEL:-deepseek-v4-flash}意思是:如果 .env 里配了 REFINE_MODEL,就用配的值;没配就用 deepseek-v4-flash。这样即使用户的 .env 里漏了某个变量,服务也能正常启动。
八、健康检查与依赖关系
1. healthcheck 配置
每个常驻服务都配了健康检查,确保服务真的可用后才算"启动完成":
yaml
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8010/"]
interval: 30s
timeout: 10s
retries: 3
start_period: 10stest:用 curl 请求服务的健康检查端点,-f表示 HTTP 4xx/5xx 时返回非零退出码interval: 30s:每 30 秒检查一次start_period: 10s:启动后前 10 秒不算失败(给服务初始化的时间)retries: 3:连续失败 3 次才标记为 unhealthy
ChromaDB 的健康检查比较特殊,因为官方镜像里没有 curl:
yaml
healthcheck:
test: ["CMD-SHELL", "bash -c 'exec 3<>/dev/tcp/localhost/8000'"]用 bash 内置的 /dev/tcp 做 TCP 连接检测,不需要安装额外的工具。
2. depends_on 启动顺序
yaml
rag:
depends_on:
chromadb:
condition: service_healthy # 等 ChromaDB 健康
router-agent:
depends_on:
text-to-sql:
condition: service_healthy # 等 Text-to-SQL 健康
rag:
condition: service_healthy # 等 RAG 健康
frontend:
depends_on:
- router-agent # 等 Router Agent 启动
- text-to-sql # 等 Text-to-SQL 启动最终的启动顺序:
chromadb(healthy)
→ rag(healthy)
→ text-to-sql(healthy)
→ router-agent(healthy)
→ frontendcondition: service_healthy 比简单的 depends_on 更可靠------它不仅等服务启动,还等健康检查通过。这避免了 Router Agent 在 RAG 还没完全就绪时就开始转发请求的问题。
九、Nginx 反向代理配置
前端容器同时承担 Nginx 反向代理的职责,完整配置:
nginx
server {
listen 80;
server_name localhost;
root /usr/share/nginx/html;
index index.html;
# Docker 内置 DNS,避免容器重建后 IP 变化导致 502
resolver 127.0.0.11 valid=10s;
# SPA 路由 - 所有非文件路径都返回 index.html
location / {
try_files $uri $uri/ /index.html;
}
# 代理 Router Agent API
location /api/ {
client_max_body_size 500m;
set $upstream_router http://router-agent:8000;
proxy_pass $upstream_router;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_read_timeout 120s;
}
# 静态资源缓存
location ~* \.(js|css|png|jpg|jpeg|gif|ico|svg|woff|woff2)$ {
expires 1y;
add_header Cache-Control "public, immutable";
}
}几个细节:
-
resolver 127.0.0.11:Docker 的内置 DNS 服务器。用set $upstream_router变量而不是直接写proxy_pass http://router-agent:8000,是因为 Nginx 只在启动时解析 DNS。如果 router-agent 容器重建后 IP 变了,直接写死会导致 502。用变量 + resolver 可以让 Nginx 定期重新解析。 -
client_max_body_size 500m:默认 Nginx 只允许 1MB 的上传。我们需要支持 UP主导入(ZIP 文件可能几百 MB),所以调到 500m。这是一个实际的 bug 修复------之前用户导入大文件时直接 413 错误。 -
try_files $uri $uri/ /index.html:React SPA 的路由处理。所有非文件路径都返回 index.html,让前端路由接管。 -
静态资源缓存 1 年:Vite 构建的静态文件带 hash,可以放心长缓存。
截图:Nginx 反向代理架构图------浏览器 :80 → Nginx → /api/ 转发到 router-agent:8000
十、一键启动与验证
全部配置好之后,启动整个系统只需要两步:
bash
# 1. 配置环境变量
cp .env.example .env
# 编辑 .env,填入 API Key
# 2. 一键启动
docker compose --profile dev up -d --build--build 参数会在启动前重新构建镜像。如果代码没有变化,Docker 会使用缓存,不会重新下载依赖。
验证所有服务是否正常:
bash
docker compose ps预期输出:
NAME STATUS
chromadb Up (healthy)
text-to-sql Up (healthy)
rag Up (healthy)
router-agent Up (healthy)
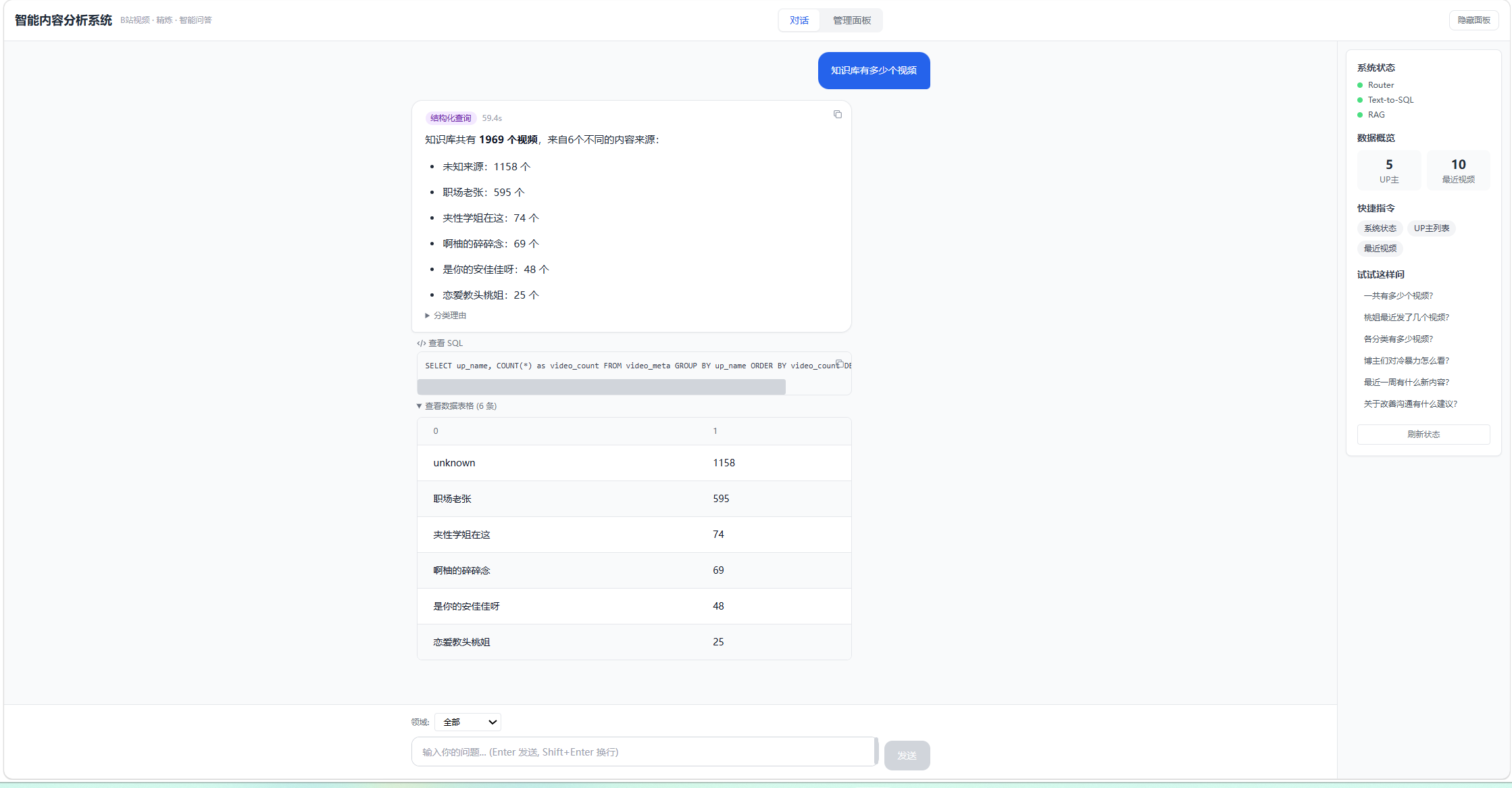
frontend Up测试问答功能:
bash
curl -X POST http://localhost:8000/api/chat \
-H "Content-Type: application/json" \
-d '{"question": "知识库有多少个视频"}'或者直接打开浏览器访问 http://localhost,就能看到前端界面了。
总结
Docker Compose 把 7 个容器的端口映射、环境变量、Volume 挂载、依赖关系、健康检查全部编排在一个 YAML 文件里,一行命令启动整个系统。profiles 机制让同一个文件服务两套环境,国内镜像加速让构建速度从"去喝杯咖啡"变成"去倒杯水"。下一篇讲 bilibili-monitor 的视频自动采集。