1.名词解释
1.1嵌入与嵌入模型
嵌⼊(Embedding)的核⼼思想就是将⼈类世界的符号(如单词、句⼦、产品、⽤⼾、图⽚)转换为计算机能够理解的数值形式(即向量,本质上是⼀个数字列表),并且要求这种转换能够保留原始符号的语义和关系。
嵌⼊模型(Embedding Models)是表⽰型模型。它的⽬标不是⽣成⽂本,⽽是为输⼊的⽂本创建 ⼀个最佳的、富含语义的数值表⽰(向量)。
⼤语⾔模型是⽣成式模型。它理解输⼊并⽣成新的⽂本(回答问题、写⽂章)
1.2向量
嵌⼊的结果是就是⼀个向量,它本质上是⼀个数字列表(⼀维数组)。
这能解决⼀个传统数据库(如MySQL)不擅⻓的问题:基于内容的相似性搜索,⽽不是
基于精确匹配的查询。
2.嵌入模型的使用
2.1定义模型
python
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-3-large", # 是 OpenAI 2024年发布的最新嵌⼊模型,⽣成3072维
的⾼质量向量
)2.2嵌入方法
在 LangChain 框架中基础 Embeddings 类( OpenAIEmbeddings 继承了它)设计了两个核⼼⽅法来处理⽂本嵌⼊。
• embed_documents() : ⽤于处理⽂档 Documents 。它的输⼊是多个⽂本。例如要将⼀个
知识库⾥的所有段落都转换成向量后存⼊数据库,就会使⽤这个⽅法。
它返回⼀个【⼆维列表】 ListList\[float] 。外层列表的每个元素对应⼀个输⼊⽂档,
内层列表则是该⽂档的向量表⽰。
• .embed_query() : ⽤于处理查询 Query 。它的输⼊是单个⽂本(⼀个字符串,str)。例
如,当⽤⼾提出⼀个问题时,需要将这个问题转换成向量,以便在数据库中搜索相似的⽂档段落,就会使⽤这个⽅法。
它返回⼀个【⼀维列表】,⾥⾯是浮点数( Listfloat ),代表单个查询⽂本的向量。
为什么会将嵌入方法设置成文档和询问。核心是不同厂商或者同一厂商对文档列表和用户输入问题有不同的优化策略使得向量形成更加合理。
2.2.1嵌入文档列表
python
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
# 1.加载文件
markdown_path = "../Docs/Markdown/xxx.md"
# single 模式加载后,默认只有⼀个 Document 对象
loader = UnstructuredMarkdownLoader(markdown_path)
data = loader.load()
# 2.二次切割
# ⽣成分割器
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=200, chunk_overlap=50
)
# 分割⽂档
documents = text_splitter.split_documents(data)
# 3.嵌入向量
# 定义嵌⼊模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 3.1嵌入文档
# 嵌⼊⽂档列表,⽣成向量列表
# 注意这⾥需要提取⽂档内容为字符串列表,才能传递给嵌⼊模型
texts = [doc.page_content for doc in documents]
documents_vector = embeddings.embed_documents(texts)2.2.2嵌入单个查询
python
# 3.2嵌入输入
query_vector = embeddings.embed_query("......")3.应用场景
3.1 语义搜索(Semantic Search)
传统搜索依赖关键词匹配(搜 "苹果" ,只能找到包含 "苹果" 这个词的⽂档)。语义搜索则能将查询(如 "⼀种红⾊的⽔果" )和⽂档库中的所有⽂档都转换为向量。然后计算查询 向量与所有⽂档向量的相似度,返回最相似的⽂档。这样即使⽂档⾥没有 "红⾊" 和 "⽔果" 这些词,但只要它是关于 "苹果" 的,就能被找到。
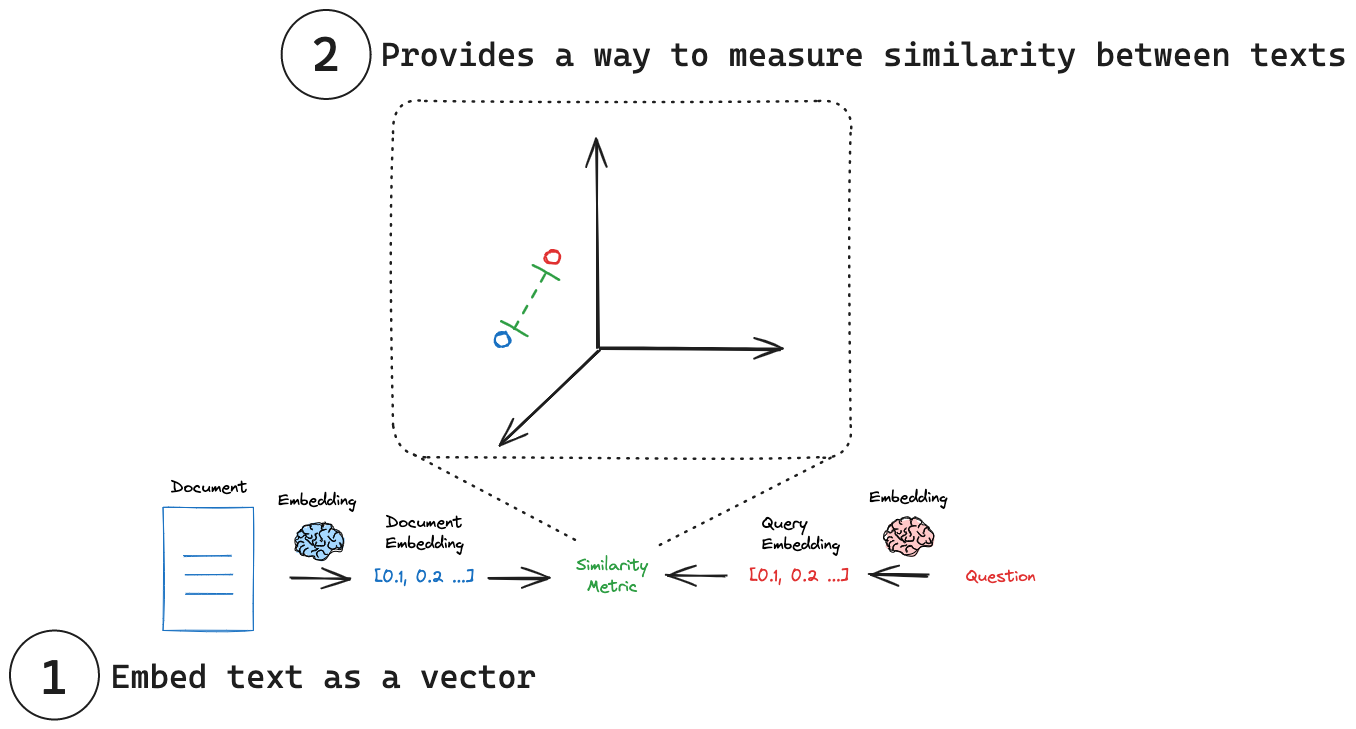
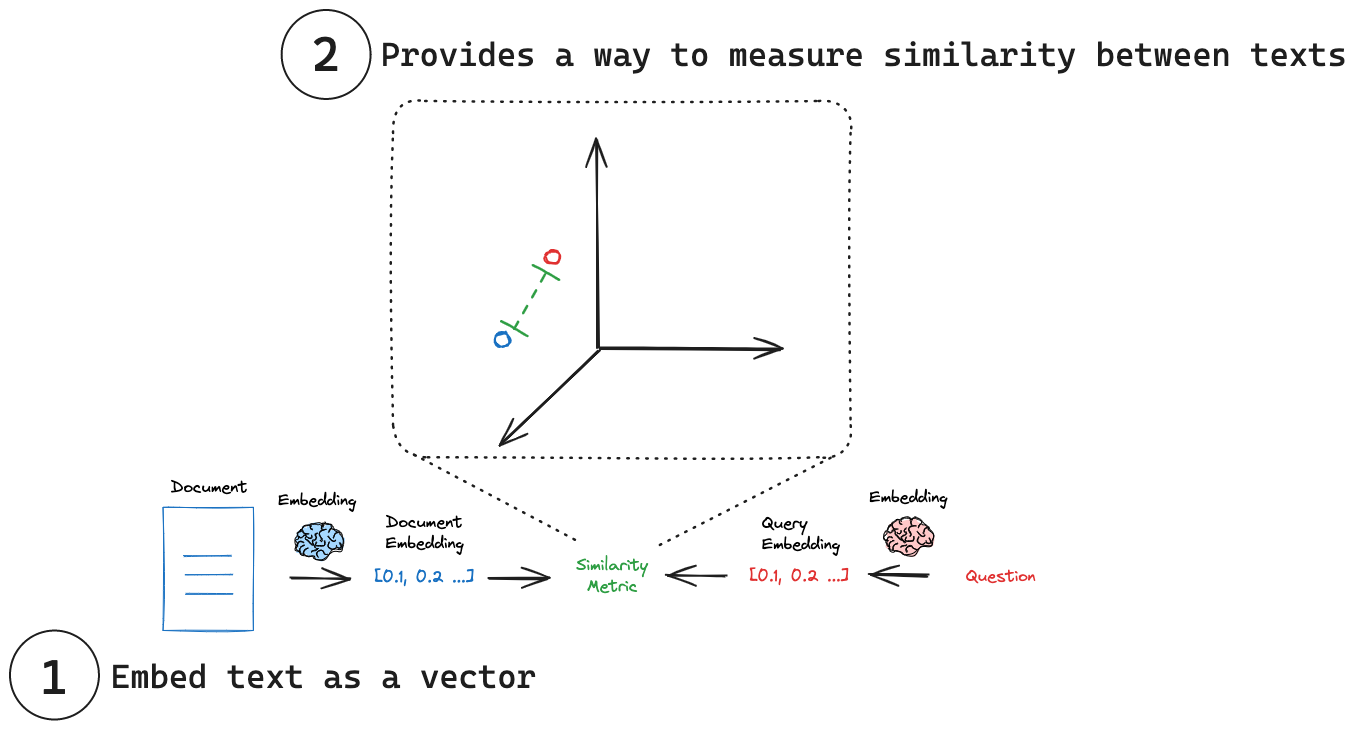
如下图为我们展⽰了借助嵌⼊模型进⾏⽂档搜索的过程:
- 为多⽂档⽣成其各⾃的向量,
- 为搜索查询语句⽣成向量,
- 衡量查询向量与每个⽂档向量之间的相似性,得到相似度最⾼的⽂档。
3.2 检索增强⽣成(Retrieval-Augmented Generation, RAG)
这是当前⼤语⾔模型应⽤的核⼼模式。当⽤⼾向 LLM 提问时,系统⾸先使⽤嵌⼊模型在知识库(如公司内部⽂档)中进⾏语义搜索,找到最相关的内容,然后将这些内容和问题⼀起交给 LLM 来⽣成答案。这极⼤地提⾼了答案的准确性和时效性。
3.3 推荐系统(Recommendation Systems)
将⽤⼾(根据其历史⾏为、偏好)和物品(商品、电影、新闻)都转换为向量。喜欢相似物品的⽤⼾,其向量会接近;相似的物品,其向量也会接近。通过计算⽤⼾和物品向量的相似度,就可以进⾏精准推荐。
3.4异常检测(Anomaly Detection)
正常数据的向量通常会聚集在⼀起。如果⼀个新数据的向量远离⼤多数向量的聚集区,它就可能是⼀ 个异常点(如垃圾邮件、欺诈交易)。