摘要
最近,扩散模型作为一种强大的生成式技术出现在机器人策略学习中,能够对多模态动作分布进行建模 。利用其端到端自动驾驶能力是一个充满希望的方向。然而,机器人扩散策略中大量的去噪步骤,以及交通场景更加动态、开放世界的性质,给以实时速度生成多样化的驾驶动作带来了巨大挑战 。为了应对这些挑战,我们提出了一种新颖的截断扩散策略 ,该策略结合了先验多模态锚点并截断扩散调度,使模型能够从锚定的高斯分布学习去噪至多模态驾驶动作分布 。此外,我们设计了一种高效的级联扩散解码器,以增强与条件场景上下文的交互。所提出的模型 DiffusionDrive 相比原始扩散策略将去噪步骤减少了 10 倍,仅需 2 步即可提供 Superior 的多样性和质量。在面向规划的 NAVSIM 数据集上,配合对齐的 ResNet-34 骨干网络,DiffusionDrive 在无需任何额外技巧(without bells and whistles)的情况下实现了 88.1 的 PDMS 分数,创下新纪录,同时在 NVIDIA 4090 上以 45 FPS 的实时速度运行。具有挑战性的场景上的定性结果进一步证实,DiffusionDrive 能够稳健地生成多样化的合理驾驶动作。
1. 引言
近年来,随着感知模型(检测 4, 17, 24, 42、跟踪 54--56、在线建图 27, 28, 32 等)的进步,直接通过原始传感器输入学习驾驶策略的端到端自动驾驶受到了广泛关注。这种数据驱动的方法为传统基于规则的运动规划提供了一个可扩展且鲁棒的替代方案,后者往往难以泛化到复杂的现实世界驾驶环境中。
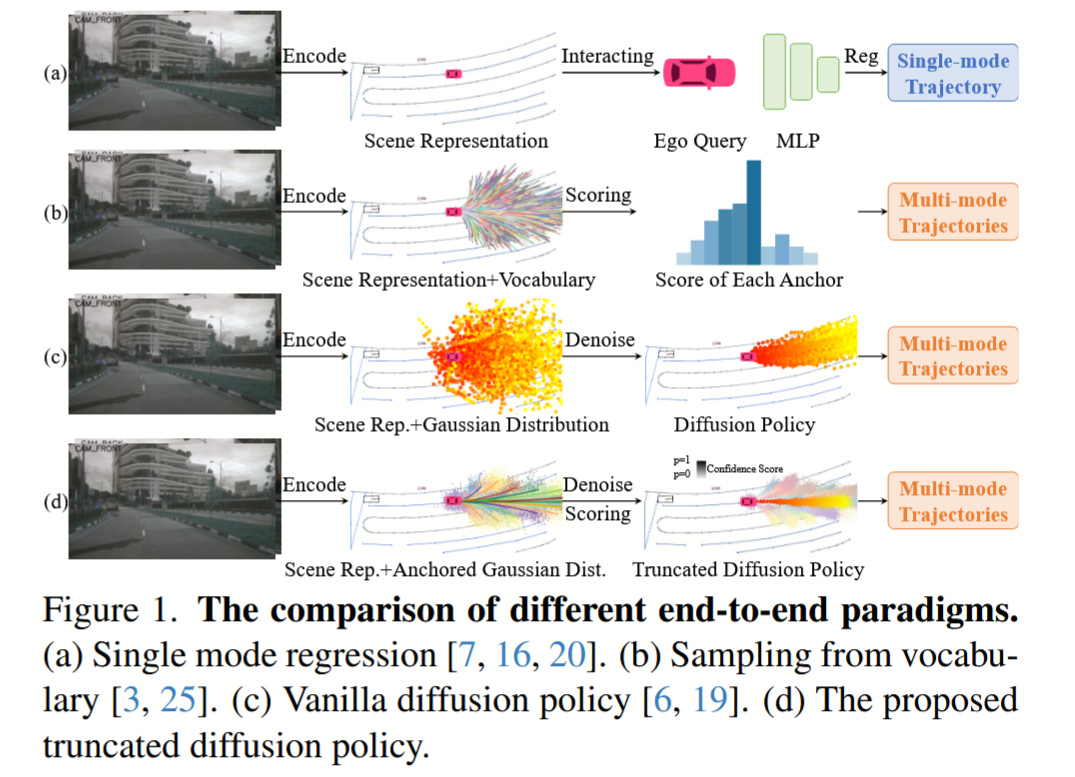
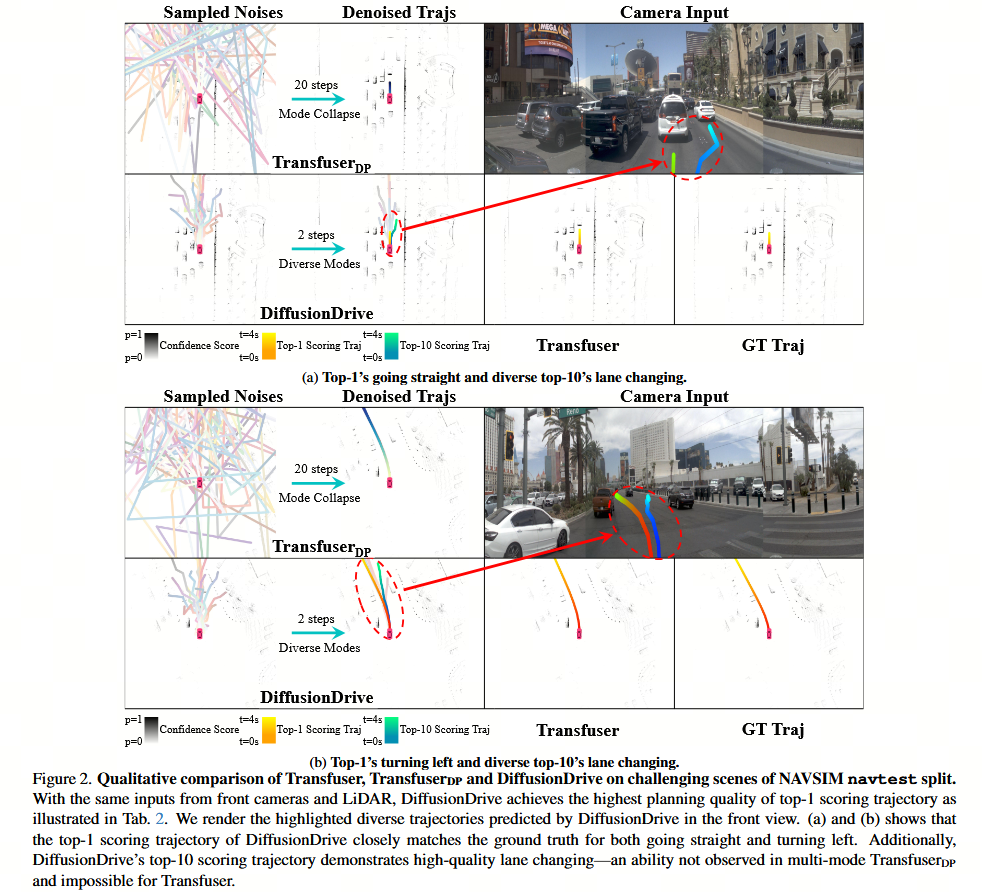
为了有效地从数据中学习,主流的端到端规划器(例如 Transfuser 7、UniAD 16、VAD 20)通常如图 1a 所示,从自车查询(ego-query)回归出单模态轨迹。然而,这种范式并未考虑到驾驶行为固有的不确定性和多模态性质 。最近,VADv2 20 引入了一个包含大量锚轨迹的大固定词汇表(4096 个锚点),以离散化连续动作空间并捕捉更广泛的驾驶行为,然后根据预测得分从这些锚点中进行采样,如图 1b 所示。然而,这种大固定词汇表范式从根本上受到锚轨迹数量和质量限制,经常在词汇表外场景中失效 。此外,管理大量锚点给实时应用带来了显著的计算挑战。扩散模型 6 已证明是机器人领域中一种强大的生成式决策制定策略,它可以通过迭代去噪过程直接从高斯分布中采样多模态的物理合理动作,而不是离散化动作空间。这启发我们将扩散模型在机器人领域的成功复制到端到端自动驾驶中。我们将原始的机器人扩散策略应用于著名的单模态回归方法 Transfuser 7,提出了一个变体 TransfuserDP,即用条件扩散模型 34 替换确定性的 MLP 回归头。虽然 TransfuserDP 提高了规划性能,但出现了两个主要问题:1) 如表 2 所示,原始 DDIM 扩散策略中的 20 次去噪步骤在推理期间引入了沉重的计算消耗,阻碍了自动驾驶的实时应用。2) 如图 2 所示,从不同高斯噪声中采样的轨迹彼此严重重叠。这凸显了驯服扩散模型以应对动态和开放世界交通场景的非平凡挑战。
他们发现,即使输入不同的随机噪声(这是扩散模型生成多样性的基础),最后生成的很多条路线都挤在一起,长得差不多。这说明很难让AI在复杂多变的真实交通环境中,生成既多样化又合理的预测结果。
扩散模型的核心魅力在于多样性。通过输入不同的"高斯噪声",理论上应该能生成千变万化的结果。比如,面对同一个路口,有的车左转,有的车右转,有的直行。
现象:如果你让AI生成100条可能的行驶路径,结果发现这100条线几乎重合,或者只有微小的差异。
问题所在:这意味着模型失去了"多样性"。它可能只会预测一种"最安全"或"最常见"的路径,而无法捕捉交通中常见的多种可能性(比如有人突然变道,有人准备停车)
传统方法的局限:早期的AI模型往往只输出一个"平均"结果。例如,如果前方路口50%的车左转,50%的车直行,简单模型可能输出一条"折中"的、现实中根本不会有人走的路线。
扩散模型的优势:扩散模型因其强大的生成能力,被认为有望解决多模态问题------即能够同时生成"左转"和"直行"等多种合理的可能性。
面临的瓶颈:然而,正如这段文本指出的,在复杂的交通场景中,模型往往"退步"了。它可能因为害怕出错,或者训练数据中的偏差,导致无论怎么换随机种子(噪声),生成的轨迹都趋于保守和单一。
Question. 我挑出来:有个疑问:为什么现在大家搞 Anchor Trajectory、Diffusion Policy、World Model,而不是直接像传统规划一样撒一堆 Reeds-Shepp / Dubins 曲线,然后挑一条最优的?
传统撒点规划解决的是"可行轨迹搜索 "问题,而扩散模型解决的是"驾驶行为分布建模"问题。
这是一个很好的问题。实际上你是在问:
为什么现在大家搞 Anchor Trajectory、Diffusion Policy、World Model,而不是直接像传统规划一样撒一堆 Reeds-Shepp / Dubins 曲线,然后挑一条最优的?
答案是:
传统撒点规划解决的是"可行轨迹搜索"问题,而扩散模型解决的是"驾驶行为分布建模"问题。
两者目标其实不一样。
Question.1 Reeds-Shepp 本质在干什么
RS曲线解决的是:
给定
- 起点姿态
- 终点姿态
求:
minL \min L minL
满足:
∣κ∣≤κmax |\kappa| \le \kappa_{max} ∣κ∣≤κmax
即:
最短可行路径问题
例如:
text
停车位
|
|
|
egoRS会产生:
text
左转
右转
倒车
前进组合路径。
它不考虑:
- 行人
- 其他车辆
- 红绿灯
- 驾驶习惯
- 社会交互
只考虑:
我的车能不能从A到B
Question.2 为什么自动驾驶不能只靠RS
假设路口:
text
Car B
↓
Car A → EgoRS会得到:
text
方案1:
直接穿过去
方案2:
轻微绕行
方案3:
停车等待从几何角度:
三条都合法。
但真正驾驶员会:
text
等Car B先走原因是:
社会规则。
而:
RS不知道社会规则。
它只知道:
python
path_length
curvature所以:
RS生成的是:
p(path∣start,end) p(path|start,end) p(path∣start,end)
而驾驶需要:
p(path∣scene) p(path|scene) p(path∣scene)
这完全不是一个东西。
Question.3 Anchor Trajectory在干什么
例如4096个轨迹:
text
直行
左变道
右变道
减速
停车
让行
...实际上是在学习:
p(τ∣scene) p(\tau|scene) p(τ∣scene)
其中:
τ=trajectory \tau = trajectory τ=trajectory
网络输出:
text
轨迹1 0.5
轨迹2 0.3
轨迹3 0.1
...这相当于:
text
未来驾驶行为词典而不是:
text
几何路径词典Question.4 Diffusion 为什么又比 Anchor 强
Anchor有一个问题:
词汇表有限。
例如:
text
4096条覆盖不了所有情况。
扩散模型直接学习:
p(τ) p(\tau) p(τ)
或者:
p(τ∣scene) p(\tau|scene) p(τ∣scene)
不需要离散化。
训练:
text
真实轨迹
↓
加噪声
↓
学习去噪推理:
text
高斯噪声
↓
迭代去噪
↓
轨迹得到:
text
左绕
右绕
等待
缓慢通过多个模式。
因此天然是:
连续空间多模态采样器。
Question.5 那扩散和RS的关系是什么
其实非常接近:
都在采样轨迹。
区别:
RS采样的是:
text
运动学可行轨迹扩散采样的是:
text
人类驾驶轨迹RS:
p(τ∣vehicle) p(\tau|vehicle) p(τ∣vehicle)
Diffusion:
p(τ∣vehicle,scene,human) p(\tau|vehicle,scene,human) p(τ∣vehicle,scene,human)
Question.6 能不能直接撒很多RS曲线
当然可以。
很多系统就是这么干的。
例如:
- Hybrid A*
- State Lattice
- EM Planner
- Apollo Planning
都是:
text
撒轨迹
↓
打分
↓
选最优例如:
text
5000条RS轨迹完全没问题。
但问题来了:
如果是复杂交互:
text
行人突然穿行
前车礼让
路口博弈需要撒多少?
可能:
text
50万条
500万条才能覆盖。
搜索空间爆炸。
Question.7 扩散其实是在学习"如何撒点"
这是最核心的一点。
传统:
text
随机撒或者:
text
规则撒
text
RS1
RS2
RS3
...
RS50000扩散:
直接学:
text
人类会撒在哪里然后只生成:
text
几十条
几百条高概率轨迹。
相当于:
text
暴力搜索变成
text
学习引导搜索Question.8 RL + RS 能不能替代轨迹规划
严格说:
RL + RS 仍然属于轨迹规划。
例如:
text
RS生成1000条候选
↓
RL网络评分
↓
选择最佳这叫:
Learning-based Planner
或者:
RL-guided Planning
它没有消灭规划。
只是把:
text
Cost Function变成:
text
Neural NetworkQuestion.9 为什么现在大量论文用 Diffusion + RL
因为Diffusion和RL分工明确:
Diffusion负责:
Generate
生成合理候选轨迹。
RL负责:
Evaluate
评估长期收益。
流程:
text
Scene
↓
Diffusion
↓
20条高质量轨迹
↓
RL Value Network
↓
选择最优而不是:
text
Scene
↓
50万条RS
↓
搜索计算量小很多。
从自动驾驶发展的角度看:
- Dubins / Reeds-Shepp:解决"车能不能这么走"。
- Hybrid A*:解决"怎么搜索可行轨迹"。
- Anchor Trajectory:解决"人通常会怎么走"。
- Diffusion Policy:解决"连续空间里可能怎么走"。
- RL:解决"长期来看哪条轨迹收益最高"。
因此 RL + RS 并不会让轨迹规划消失,它更像是"传统规划 + 学习评分器";而 Diffusion 想做的是直接学习轨迹分布,把大量无意义的 RS 搜索提前过滤掉。
插话完毕,回到正题
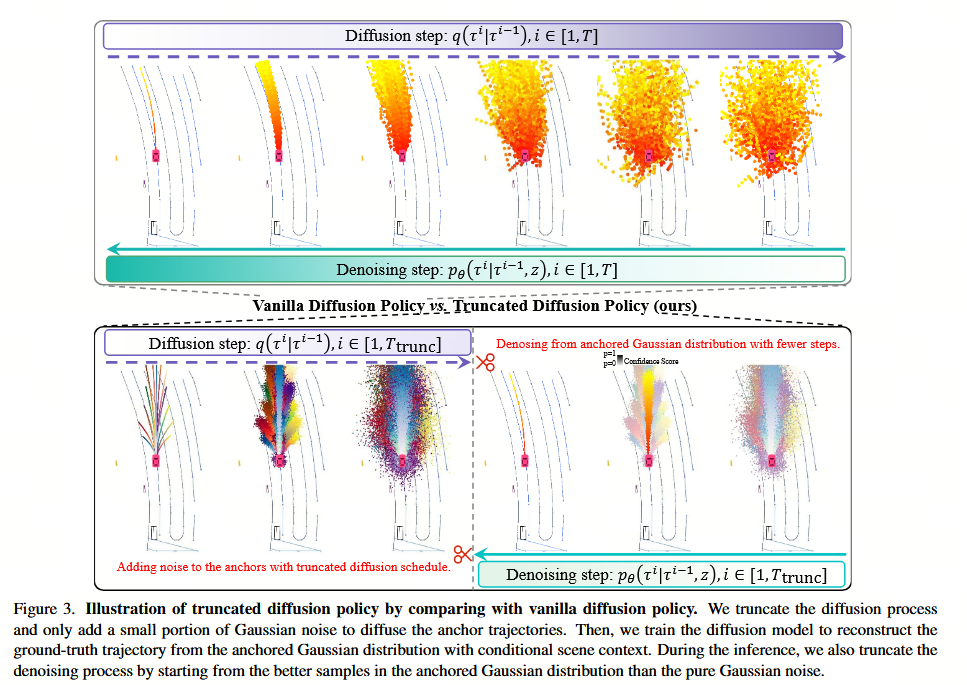
与从随机高斯噪声中根据场景上下文采样动作的原始扩散策略不同,人类驾驶员遵循既定的驾驶模式,并根据实时交通状况动态调整。这一洞察促使我们将这些先验驾驶模式嵌入到扩散策略中,即将高斯分布划分为围绕先验锚点中心分布的多个子高斯分布,称为锚定高斯分布。如图 3 所示,这是通过在先验锚点周围引入少量高斯噪声来截断扩散调度来实现的。得益于扩散模型的多模态分布表达能力,所提出的截断扩散策略有效地覆盖了潜在的动作空间,而无需像 VADv2 那样需要大量固定的锚点。通过从锚定高斯分布中获得更合理的初始噪声样本,我们可以截断去噪过程,将所需步骤从 20 步减少到仅 2 步------这是一项巨大的加速,满足了自动驾驶的实时要求。
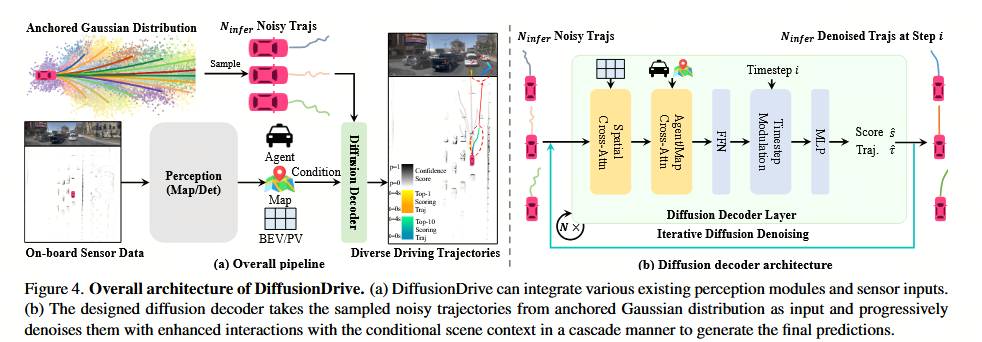
为了增强与条件场景上下文的交互,我们提出了一种基于 Transformer 的高效扩散解码器,该解码器不仅与来自感知模块的结构化查询交互,还通过稀疏可变形注意力机制 62 与鸟瞰图(BEV)和透视视图(PV)特征交互。此外,我们引入了一个级联机制,在每个去噪步骤中迭代地细化扩散解码器内的轨迹重建。
通过这些创新,我们提出了 DiffusionDrive,这是一个用于实时端到端自动驾驶的扩散模型。我们在面向规划的 NAVSIM 数据集 10 上使用非反应式仿真和闭环评估对我们的方法进行了基准测试。无需任何额外技巧,DiffusionDrive 在使用对齐的 ResNet-34 骨干网络的情况下,在 NAVSIM navtest 划分上实现了 88.1 的 PDMS 分数,显著优于之前的最先进方法。即使与 NAVSIM 挑战获胜方案 Hydra-MDP-V8192-W-EP 25 相比,后者遵循 VADv2 使用 8192 条锚轨迹,并进一步结合了后处理和额外监督,DiffusionDrive 仍然通过直接从人类演示中学习并在推理时无需后处理,以 1.6 PDMS 的优势超越它,同时在 NVIDIA 4090 上以 45 FPS 的实时速度运行。我们还在流行的 nuScenes 数据集 2 上通过开环评估进一步验证了 DiffusionDrive 的优越性,DiffusionDrive 比 VAD 快 1.8 倍,并在相同的 ResNet-50 骨干网络下,以低 20.8% 的 L2 错误和低 63.6% 的碰撞率超越 VAD 20,展示了最先进的规划性能。
我们的贡献总结如下:
- 我们率先将扩散模型引入端到端自动驾驶领域,并提出了一种新颖的截断扩散策略,以解决将原始扩散策略直接应用于交通场景时出现的模式坍缩和沉重计算开销问题。
- 我们设计了一种高效的基于 Transformer 的扩散解码器,以级联方式与条件信息进行交互,以实现更好的轨迹重建。
- 无需任何额外技巧,DiffusionDrive 显著优于之前的最先进方法,在使用相同骨干网络的情况下,在 NAVSIM navtest 划分上取得了 88.1 的破纪录 PDMS 分数,同时在 NVIDIA 4090 上保持 45 FPS 的实时性能。
- 我们通过定性分析证明,DiffusionDrive 能够生成更多样化和合理的轨迹,在各种具有挑战性的场景中展现出高质量的多模态驾驶动作。
2. 相关工作
端到端自动驾驶。UniAD 16 作为一项开创性工作,通过整合多种感知任务来提升规划性能,展示了端到端自动驾驶的潜力。VAD 20 进一步探索了使用紧凑的矢量化场景表示以提高效率。随后,一系列工作 5, 7, 12, 23, 26, 43, 45, 58 采用了单轨迹规划范式以进一步提升规划性能。最近,VADv2 3 将范式转向多模态规划,通过对大固定词汇表中的锚轨迹进行评分和采样。Hydra-MDP 25 通过引入来自基于规则的评分器的额外监督,改进了 VADv2 的评分机制。SparseDrive 39 探索了一种替代的无 BEV 解决方案。与现有的多模态规划方法不同,我们提出了一种利用强大生成式能力的新型范式用于端到端自动驾驶的扩散模型。
用于交通仿真的扩散模型。在交通仿真中,仅利用抽象感知真实标签 8, 18, 21, 44 驱动驾驶扩散策略的探索已有所开展。MotionDiffuser 21 和 CTG 60 是将扩散模型应用于多智能体运动预测的开山之作,它们使用条件扩散模型从高斯噪声中采样目标轨迹。CTG++ 59 进一步引入了大语言模型(LLM)以实现语言驱动引导,提升了可用性并实现了逼真的交通仿真。Diffusion-ES 48 则用进化搜索替代了基于奖励梯度引导的去噪过程。有别于那些仅依赖于感知真实标签、局限于交通仿真的扩散模型,我们通过提出的截断扩散策略和高效扩散解码器,释放了扩散模型在实时端到端自动驾驶中的潜力。
用于机器人策略学习的扩散模型。Diffusion Policy 6 展现了在机器人策略学习中的巨大潜力,能够有效捕捉多模态动作分布和高维动作空间。Diffuser 19 提出了一种用于轨迹采样的无条件扩散模型,并引入了无分类器引导和图像修复等技术以实现引导采样。随后,许多工作将扩散模型应用于各类机器人任务,包括静态机械臂操控运动学 1, 53、移动操作 47、自主导航 37, 51、四足运动 38 以及灵巧操作 46。然而,直接将原始的扩散策略(vanilla diffusion policy)应用于端到端自动驾驶面临着独特的挑战,因为它要求在动态且开放世界的交通场景中具备实时效率,并能够生成合理的多模态轨迹。在本工作中,我们提出了一种新颖的截断扩散策略(truncated diffusion policy)以应对这些挑战,并引入了在机器人领域尚未被探索的概念。
用于图像生成的扩散模型。 扩散模型已被广泛用于图像生成任务 33, 36, 49, 50, 61。DDIM 35 通过基于非马尔可夫扩散过程,以显著减少的步数实现高效采样,从而增强了 DDPM 14。流匹配(Flow matching)30, 31 通过直接建模连续概率流进一步优化了生成过程。TDPM 57 提出了截断去噪(truncated denoising),从隐式中间分布启动生成过程,从而加速采样。与这些方法相比,我们的方法在扩散策略中引入了明确的驾驶先验,有效地引导扩散过程朝向更准确且高效的生成,专门针对端到端自动驾驶进行了优化。
3. 方法
3.1. 预备知识
问题定义。 端到端自动驾驶以原始传感器数据作为输入,并预测自车未来的轨迹。轨迹表示为一系列路标点 τ={(xt,yt)}t=1Tf\tau = \{(x_t, y_t)\}_{t=1}^{T_f}τ={(xt,yt)}t=1Tf,其中 TfT_fTf 表示规划 horizon,(xt,yt)(x_t, y_t)(xt,yt) 是时间 ttt 时当前自车坐标系下每个路标点的位置。
条件扩散模型。 条件扩散模型将前向扩散过程定义为逐步向数据样本添加噪声,其定义如下:
q(τi∣τ0)=N(τi;αˉiτ0,(1−αˉi)I),(1) q(\tau^i | \tau^0) = \mathcal{N}\left(\tau^i; \sqrt{\bar{\alpha}_i}\tau^0, (1 - \bar{\alpha}_i)I\right), \quad (1) q(τi∣τ0)=N(τi;αˉi τ0,(1−αˉi)I),(1)
其中 τ0\tau^0τ0 是干净的数据样本,τi\tau^iτi 是时间步 iii 带噪声的数据样本(注:我们使用上标 iii 表示扩散时间步)。常数 αˉi=∏s=1iαs=∏s=1i(1−βs)\bar{\alpha}i = \prod{s=1}^i \alpha_s = \prod_{s=1}^i (1 - \beta_s)αˉi=∏s=1iαs=∏s=1i(1−βs),其中 βs\beta_sβs 是噪声调度。我们训练反向过程模型 fθ(τi,z,i)f_\theta(\tau^i, z, i)fθ(τi,z,i) 以在条件信息 zzz 的引导下从 τi\tau^iτi 预测 τ0\tau^0τ0,其中 θ\thetaθ 是模型的参数。
可训练模型参数。在推理过程中,经过训练的扩散模型 fθf_\thetafθ 在条件信息 zzz 的指导下,逐步将符合高斯分布采样的随机噪声 τT\tau_TτT 精炼为预测的干净数据样本 τ0\tau_0τ0,其定义如下:
pθ(τ0∣z)=∫p(τT)∏i=1Tpθ(τi−1∣τi,z)dτ1:T.(2)p_\theta(\tau_0 | z) = \int p(\tau_T) \prod_{i=1}^{T} p_\theta(\tau_{i-1} | \tau_i, z) d\tau_{1:T} . \quad (2)pθ(τ0∣z)=∫p(τT)i=1∏Tpθ(τi−1∣τi,z)dτ1:T.(2)
3.2. 调查
将 Transfuser 7 转化为条件扩散模型。 我们从具有代表性的确定性端到端规划器 Transfuser 7 出发,通过用条件扩散模型 UNet 替换回归多层感知机(MLP)层,将其转化为生成模型 TransfuserDP,该方法遵循 vanilla diffusion policy 6。在评估阶段,我们采样随机噪声,并通过 20 步逐步精炼它。表 2 显示,TransfuserDP 比确定性 Transfuser 实现了更好的规划质量。
模式坍塌(Mode collapse)。 为了进一步调查 vanilla diffusion policy 在驾驶中的多模态特性,我们从高斯分布中采样了 20 个随机噪声,并使用 20 步进行去噪。如图 2 所示,不同的随机噪声在经过去噪过程后收敛到相似的轨迹。为了对模式坍塌现象进行定量分析,我们定义了一个基于每个去噪轨迹与所有去噪轨迹并集的均值交并比(mIoU)的模式多样性得分 DDD:
D=1−1N∑i=1NArea(τi∩⋃j=1Nτj)Area(τi∪⋃j=1Nτj),(3)D = 1 - \frac{1}{N} \sum_{i=1}^{N} \frac{\text{Area}(\tau_i \cap \bigcup_{j=1}^{N} \tau_j)}{\text{Area}(\tau_i \cup \bigcup_{j=1}^{N} \tau_j)} , \quad (3)D=1−N1i=1∑NArea(τi∪⋃j=1Nτj)Area(τi∩⋃j=1Nτj),(3)
其中 τi\tau_iτi 表示第 iii 个去噪轨迹,NNN 是采样轨迹的总数,⋃j=1Nτj\bigcup_{j=1}^{N} \tau_j⋃j=1Nτj 是所有去噪轨迹的并集。较高的 mIoU 表明去噪轨迹的多样性较低。表 2 中的定量模式多样性结果进一步验证了图 2 中的观察结果。
沉重的去噪开销。 DDIM 35 扩散策略需要 20 步去噪才能将随机噪声转换为可行的轨迹,这引入了显著的额外计算开销,将帧率(FPS)从 60 降低到 7,如表 2 所示,使其难以应用于实时在线驾驶场景。
3.3. 截断扩散
人类驾驶遵循固定模式,这与 vanilla diffusion policy 中的随机噪声去噪不同。受此启发,我们提出了一种截断扩散策略,该策略从锚定高斯分布(anchored Gaussian distribution)开始去噪过程,而不是从标准高斯分布开始。为了使模型能够学习从锚定高斯分布去噪到期望的驾驶策略,我们在训练期间进一步截断扩散调度,仅向锚点添加少量高斯噪声。
训练。 我们首先通过向锚点 {ak}k=1Nanchor\{a_k\}{k=1}^{N{anchor}}{ak}k=1Nanchor 添加高斯噪声来构建扩散过程,这些锚点是通过对训练集进行 K-Means 聚类得到的,其中 ak={(xt,yt)}t=1Tfa_k = \{(x_t, y_t)\}_{t=1}^{T_f}ak={(xt,yt)}t=1Tf。我们将扩散噪声调度截断,以将锚点扩散到锚定高斯分布:
τki=αˉiak+1−αˉiϵ,ϵ∼N(0,I),(4)\tau^i_k = \sqrt{\bar{\alpha}_i} a_k + \sqrt{1 - \bar{\alpha}_i} \epsilon, \quad \epsilon \sim \mathcal{N}(0, I), \quad (4)τki=αˉi ak+1−αˉi ϵ,ϵ∼N(0,I),(4)
其中 i∈1,Ttrunci \in 1, T_{trunc}i∈1,Ttrunc,Ttrunc≪TT_{trunc} \ll TTtrunc≪T 是截断的扩散步数。
在训练期间,扩散解码器 fθf_\thetafθ 以 NanchorN_{anchor}Nanchor 个带噪轨迹 {τki}k=1Nanchor\{\tau^i_k\}{k=1}^{N{anchor}}{τki}k=1Nanchor 作为输入,并预测分类得分 {s^k}k=1Nanchor\{\hat{s}k\}{k=1}^{N_{anchor}}{s^k}k=1Nanchor 和去噪轨迹 {τ^k}k=1Nanchor\{\hat{\tau}k\}{k=1}^{N_{anchor}}{τ^k}k=1Nanchor:
{s^k,τ^k}k=1Nanchor=fθ({τki}k=1Nanchor,z),(5)\{\hat{s}k, \hat{\tau}k\}{k=1}^{N{anchor}} = f_\theta(\{\tau^i_k\}{k=1}^{N{anchor}}, z), \quad (5){s^k,τ^k}k=1Nanchor=fθ({τki}k=1Nanchor,z),(5)
其中 zzz 表示条件信息。我们将最接近真实轨迹 τgt\tau_{gt}τgt 的带噪轨迹附近分配为正样本 (yk=1)y_k = 1)yk=1),其余为负样本 (yk=0)y_k = 0)yk=0)。训练目标结合了轨迹重建与分类:
L=∑k=1NanchorykLrec(τ\^k,τgt)+λBCE(s\^k,yk),(6) L = \sum_{k=1}^{N_{anchor}} y_k L_{rec}(\\hat{\\tau}_k, \\tau_{gt}) + \\lambda BCE(\\hat{s}_k, y_k), (6) L=k=1∑NanchorykLrec(τ\^k,τgt)+λBCE(s\^k,yk),(6)
其中,λ\lambdaλ 用于平衡简单的 L1 重建损失 LrecL_{rec}Lrec 和二元交叉熵(BCE)分类损失。
推理过程。我们采用一种截断的去噪过程,该过程从锚定高斯分布中采样的噪声轨迹开始,并逐步去噪以生成最终预测。在每个去噪时间步,将上一步估计的轨迹输入至扩散解码器 fθf_\thetafθ,该解码器预测分类得分 {s^k}k=1Ninfer\{\hat{s}k\}{k=1}^{N_{infer}}{s^k}k=1Ninfer 以及坐标 {τ^k}k=1Ninfer\{\hat{\tau}k\}{k=1}^{N_{infer}}{τ^k}k=1Ninfer。获得当前时间步的预测后,我们应用 DDIM 35 更新规则以采样下一时间步的轨迹。
推理灵活性。我们方法的一个主要优势在于其推理过程的灵活性。尽管模型在训练时使用了 NanchorN_{anchor}Nanchor 条轨迹,但推理过程可以容纳任意数量的轨迹样本 NinferN_{infer}Ninfer,其中 NinferN_{infer}Ninfer 可根据计算资源或应用需求进行动态调整。
3.4. 架构
我们提出的方法 DiffusionDrive 的整体架构如图 4 所示。DiffusionDrive 能够集成先前端到端规划器 7, 16, 20, 39 中使用的各种现有感知模块,并接收不同的传感器输入。所设计的扩散解码器专为复杂且具有挑战性的驾驶应用而定制,能够增强与条件场景上下文的交互能力。
扩散解码器。给定从锚定高斯分布中采样的噪声轨迹集合 {τ^k}k=1Ninfer\{\hat{\tau}k\}{k=1}^{N_{infer}}{τ^k}k=1Ninfer,我们首先应用可变形空间交叉注意力机制 29, 42, 62,以基于轨迹坐标与鸟瞰图(BEV)或透视视图(PV)特征进行交互。随后,在轨迹特征与源自感知模块的智能体/地图查询(agent/map queries)之间执行交叉注意力机制,接着通过前馈网络(FFN)。为了编码扩散时间步信息,我们使用时调制层(Timestep Modulation layer),其后连接一个多层感知机(MLP),用于预测置信度得分以及相对于初始噪声轨迹坐标的偏移量。该扩散解码器层的输出作为后续级联扩散解码器层的输入。DiffusionDrive 进一步复用该级联扩散解码器,在推理过程中迭代地对轨迹进行去噪,且在不同去噪时间步共享参数。最终,选择具有最高置信度得分的轨迹作为输出。
实验
A. 进一步实现细节
我们针对 NAVSIM 10 和 nuScenes 2 数据集,提供了方法的其他实现细节。
NAVSIM 数据集:我们将 ResNet-34 13 主干网络以 ImageNet 预训练权重进行初始化,并按照 Transfuser 基线 10 设置,将激光雷达(LiDAR)的前、后、左、右四个方向的探测范围设定为 32 米。我们还按照 Transfuser 基线 10 执行辅助感知任务,包括 3D 目标检测和 2D 鸟瞰图(BEV)语义分割。目标查询(Object queries)和 BEV 特征作为所提出的扩散解码器的输入。
nuScenes 数据集:我们遵循 SparseDrive 基线 39 执行两阶段训练。模型直接使用第一阶段预训练权重进行初始化,该权重仅在感知任务(3D 目标检测/跟踪、向量化高清地图构建和运动预测)上进行训练,并由官方开源实现提供。我们在 nuScenes 数据集上对第二阶段模型进行 10 个 epoch 的训练,将 SparseDrive 中的规划模块替换为我们提出的扩散解码器和截断扩散机制。目标查询、地图查询(map queries)和局部视图(PV)特征作为扩散解码器的输入。
5. 结论
在本文中,我们提出了一种新颖的生成式驾驶决策模型 DiffusionDrive,用于端到端自动驾驶,该模型结合了所提出的截断扩散策略和高效级联扩散解码器。DiffusionDrive 能够从以锚点为中心的 Gaussian 分布中噪声去污处理可变数量的样本,从而以实时速度生成多样化的规划轨迹。综合实验与定性比较验证了 DiffusionDrive 在规划质量、运行效率以及模式多样性方面的优越性。