
一、TCP Socket 编程基础
1.1前置准备:工具封装与错误处理
1.1.1参数校验与错误码
参数校验是服务端的第一步,避免非法输入导致崩溃,必须传入端口号。
cpp
void Usage(std::string& proc)
{
std::cout << "Usage: " << proc << "port" << std::endl;
}
// ./tcpserver 8080
int main(int argc, char* argv[])
{
std::unique_ptr<LoggerBuilder> builder(new GlobalLoggerBuilder());
builder->buildSink<StdoutSink>();
if(argc < 2)
{
Usage(argv[0]);
exit(USAGE_ERR);
}
return 0;
}我们的退出码也都可手动创建,后续边写边补全
cpp
enum ExitCode
{
OK = 0,
ERROR = 1
}1.1.2 NoCopy类:禁止拷贝的设计
Socket 类、线程池类这类资源管理类,不希望被拷贝(否则会导致文件描述符重复释放),继承NoCopy后,拷贝构造和赋值运算符都被禁用,避免误操作。
cpp
class NoCopy
{
public:
NoCopy() = default;
NoCopy(const NoCopy&) = delete;
NoCopy (const NoCopy&) = delete;
~NoCopy() = default;
};1.2TCP 核心 API 详解
1.2.1socket():创建套接字

domain=AF_INET**:指定 IPv4 协议**type=SOCK_STREAM:指定 TCP 协议,提供有序、可靠、双向的字节流传输- 返回值:文件描述符
fd,后续所有操作都基于这个fd
1.2.2 listen():让服务器进入监听状态
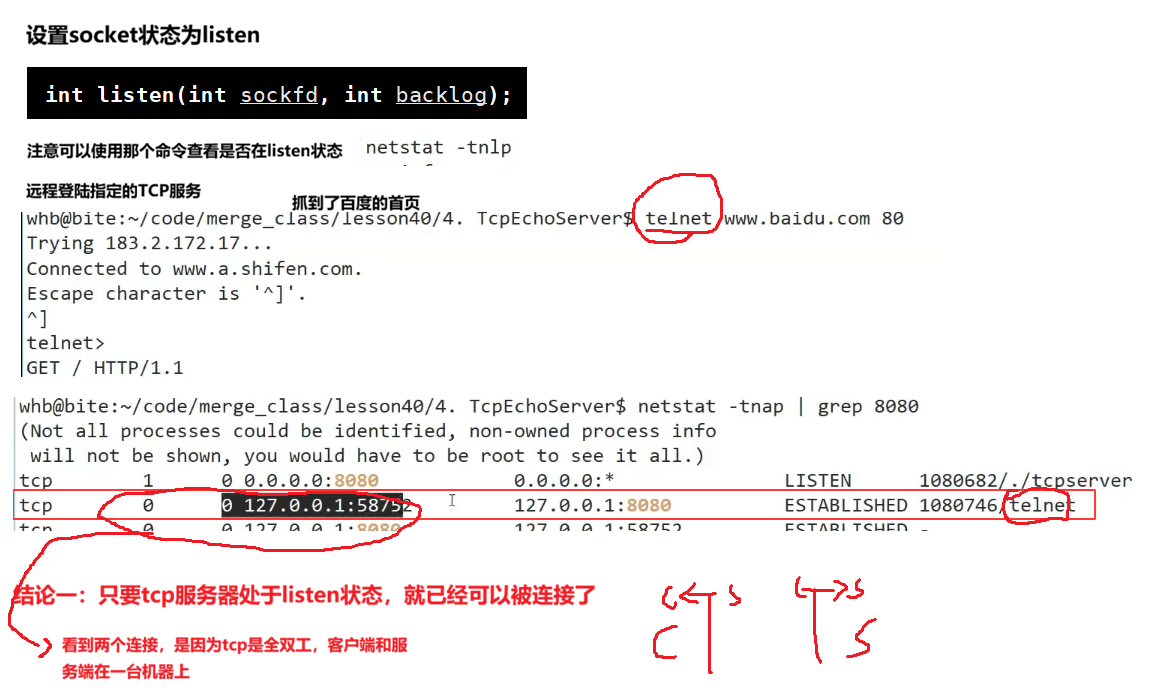
1.2.3 accept():从内核队列中取出连接
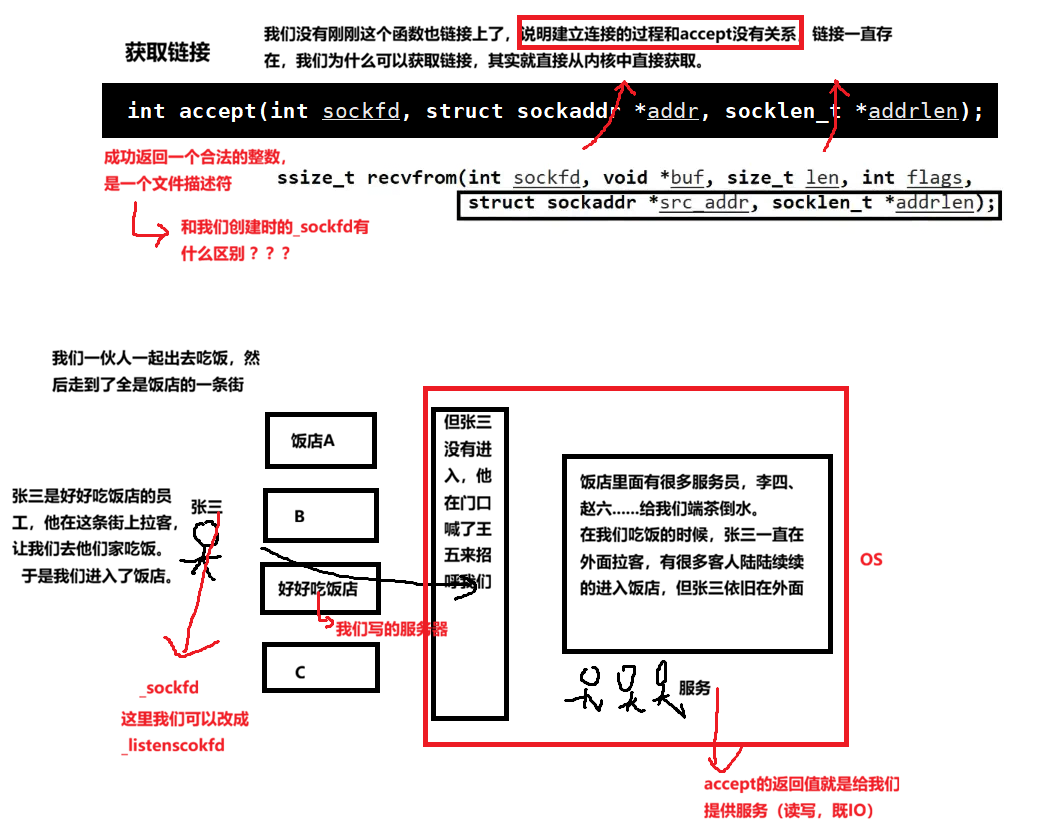
1.2.4 connect():客户端发起连接

客户端不需要手动
bind()!
- 客户端调用
connect()时,内核会自动分配临时端口并绑定,只有服务端需要固定端口,客户端端口可以随机分配。 - 客户端也不需要
listen()和accept(),直接向服务端发起连接即可。
1.3 基础问题:文件描述符的生命周期与继承
四个问题,是理解并发模型的关键:
- 问题 1:进程退出后,打开的 fd 会怎么样?
操作系统会自动回收进程的所有资源,包括打开的文件描述符,进程退出时所有fd都会被close(),但良好的习惯还是要手动关闭,避免泄漏。
- 问题 2:父进程 fork 子进程后,子进程能访问父进程的 fd 吗?
能!fork()后子进程会复制父进程的文件描述符表,同一个文件表项的引用计数会+1,父子进程共享同一个fd。这也是多进程模型里必须关闭 "无用 fd" 的原因!

- 问题 3:进程打开的 fd,线程能看到吗?
答案:能(1)✅
核心原理:
每个进程会维护一张文件描述符表(File Descriptor Table) ,这是进程级别的资源 ,归整个进程所有,而不是某个线程。同一个进程内的所有线程,都会共享这张文件描述符表。主线程调用 open()/socket() 得到的 fd,会被记录在进程的文件描述符表中,因此所有子线程都可以通过这个 fd 访问对应的文件 / 套接字。
结合TCP 服务端场景:
主线程 accept() 得到的客户端连接 connfd,传给子线程处理时,子线程能直接使用这个 connfd 读写数据,正是因为线程共享进程的文件描述符表。
- 问题 4:线程敢不敢关闭自己不需要的 fd?
答案:必须处理,但要谨慎关闭(不是简单的 "敢 / 不敢",关键是时机和方式)⚠️
核心矛盾:
线程共享文件描述符表,一个线程关闭了某个 fd,会导致进程内所有线程都无法再使用这个 fd,因此必须分场景处理:
表格
| 场景 | 操作方式 | 原因 |
|---|---|---|
主线程 accept 得到 connfd,传给子线程处理 |
主线程必须关闭 connfd |
accept 会让 connfd 的引用计数 +1,主线程不关闭的话,引用计数永远不会降到 0;即使子线程 close(connfd),连接也不会真正释放,会导致文件描述符泄漏 |
| 子线程处理完客户端请求 | 子线程必须关闭 connfd |
处理完后 connfd 已无用途,必须 close 让引用计数降到 0,内核才会真正释放连接资源,避免泄漏 |
其他线程还在读写某个 fd |
绝对不能关闭 | 否则其他线程后续的 read/write 会失败(返回 -1,错误码 EBADF),导致程序异常 |
补充:长服务 vs 短服务(TCP 服务端场景)
- 长服务 :连接建立后,进程 / 线程长期保持连接,持续提供服务(如聊天服务器,客户端一直在线,随时收发消息)。
- 特点:连接生命周期长,需要维护连接状态,线程 / 进程长期持有
connfd。
- 特点:连接生命周期长,需要维护连接状态,线程 / 进程长期持有
- 短服务 :客户端请求一次,服务器处理完立刻断开连接(如 HTTP 1.0,请求 - 响应后关闭连接)。
- 特点:连接生命周期短,处理完就释放
connfd,适合线程池处理,任务完成后线程可复用。
- 特点:连接生命周期短,处理完就释放

我们可以写三个版本,进程,线程,线程池,这里我放出进程版的源码,其他大家感兴趣可以直接实现:tcp单线程版简单回显 · 3e191a0 · 陈陈陈陈/Linux - Gitee.com
二、应用层自定义协议与序列化
2.1应用层
我们日常编写的、解决实际业务问题的网络程序,都运行在应用层。
Socket API 的读写接口,本质上都是按「无边界的字节流 / 字符串」方式收发数据,而业务中往往需要传输结构化数据(比如请求命令、参数、状态码等),这就需要通过「协议」来解决解析问题。
2.2协议是什么/为什么要定义协议
2.2.1核心本质
协议是通信双方约定好的、结构化的数据格式,是字节流和业务数据之间的 "翻译规则"。
- 没有协议:收到的字节流是无意义的乱码,无法区分 "哪一段是请求、哪一段是参数"
- 有了协议:双方按照约定的格式打包 / 解析数据,字节流就有了业务语义
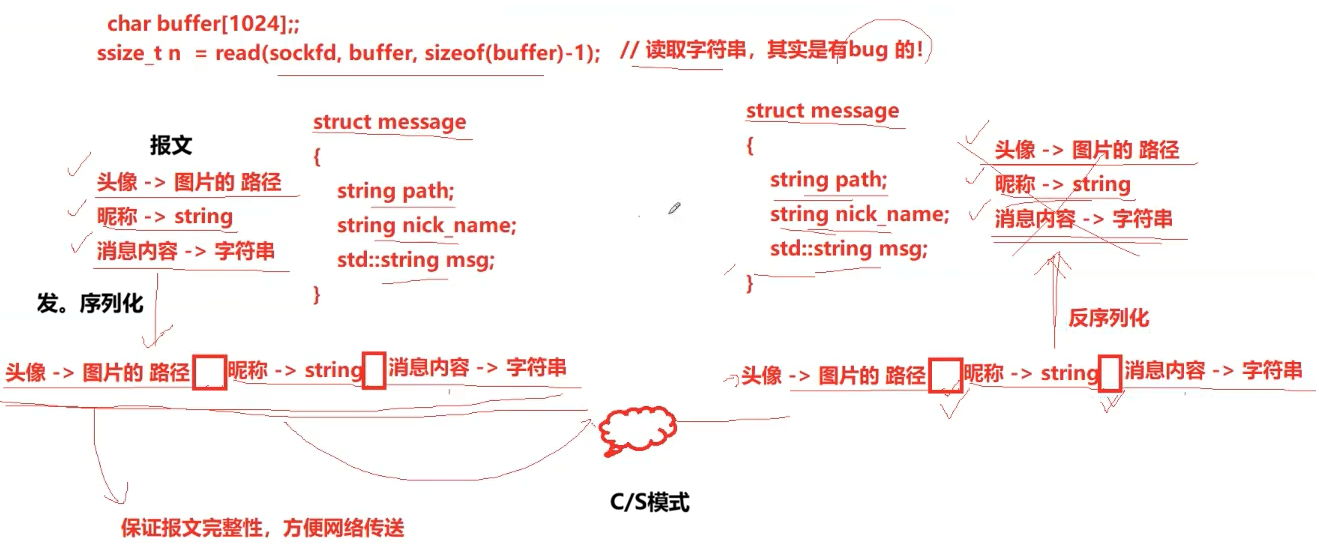
2.2.2为什么不能直接传结构体
1.最致命:结构体的「内存长相」,跨机器就乱套!
你在本地定义的结构体,是给当前电脑 / 编译器看的,换一台机器、换一个系统,内存布局完全不一样:
1. 字节序(大小端)问题
cpp
struct Msg {
int cmd; // 命令码 100
int len; // 数据长度
};- 你的电脑(x86)是小端序 ,
100在内存里是乱序存储的 - 对方电脑(ARM / 服务器)可能是大端序
- 直接发结构体 → 对方收到的数字全是错的
你必须用协议规定:数字必须用网络字节序(大端),才能跨机器解析。
2. 结构体对齐 / 内存填充
C 编译器会自动给结构体塞空字节(内存对齐):
cpp
struct Data {
char name; // 1字节
int age; // 4字节
};
// 你的编译器:总大小 8 字节(填充了3个空字节)
// 对方编译器:总大小 5 字节直接发结构体 → 两边大小不一样 → 解析直接崩溃
协议可以固定每个字段的长度、顺序,彻底解决这个问题。
2.TCP 是「流式协议」,裸传结构体解决不了粘包 / 拆包!
这是你笔记里重点强调的 TCP 核心特性:
TCP 传输的是无边界的字节流,不是独立的数据包。
裸传结构体的灾难:
- 你连续发 2 个结构体 → TCP 会把它们粘在一起发给对方
- 你发 1 个大结构体 → TCP 拆成 2 次发送
- 接收方根本不知道:从哪里开始、到哪里结束是一个完整结构体
协议的作用:
自定义协议 = 固定头部 + 长度字段
[魔数4字节][版本1字节][数据长度4字节][数据体N字节]接收方先读头部 → 拿到长度 → 精准读完整数据这是唯一能解决 TCP 粘包 / 拆包的方案,裸传结构体做不到!
3.跨语言、跨系统完全不兼容
你的服务端是 C/C++ 写的:
- 如果客户端是 Java / Python / Go
- 它们根本不认识 C 语言的结构体
- 直接发结构体 = 对牛弹琴
而协议是通用约定:不管什么语言,都能按照「格式」解析数据(二进制协议 / JSON 协议)这是分布式、多端通信的基础。
4.扩展性为 0,项目根本没法迭代
cpp
// 第一版结构体
struct Msg { int cmd; };
// 第二版加了个字段
struct Msg { int cmd; int data; };- 只要改一点点结构体,所有客户端 / 服务端必须同步升级
- 否则一收一发就错位崩溃
- 商用项目完全无法接受
协议支持:
- 版本号区分
- 可选字段
- 向前兼容改协议不用全量升级,这是工业级标准。
2.3实战案例:网络版计算器的两种协议约定方案
以 "客户端发送两个整数和运算符,服务端计算并返回结果" 为例,有两种典型的协议约定思路:
方案一:纯文本格式约定(如"1+2")
约定规则:
- 客户端发送形如
"1+2"的字符串; - 字符串中包含两个整型操作数,中间用运算符
+分隔; - 数字与运算符之间无空格,仅支持加法运算。
特点:
- 优点:实现简单,直接用字符串分割即可解析,无需额外处理
- 缺点:扩展性差,只能支持固定场景;解析规则硬编码,不通用
方案二:结构体 + 序列化 / 反序列化(结构化通用方案)
约定规则:
- 定义结构体表示交互信息(如包含操作数 1、操作数 2、运算符、结果的结构体);
- 发送数据时,按约定规则将结构体转换为字节流(序列化);
- 接收数据时,按相同规则将字节流还原为结构体(反序列化)。
特点:
- 优点:通用性强,支持复杂业务数据;易扩展,新增字段 / 业务无需大幅修改解析逻辑
- 缺点:需要额外实现序列化 / 反序列化逻辑,或依赖序列化库(如 Jsoncpp、Protobuf)
2.4 序列化 / 反序列化
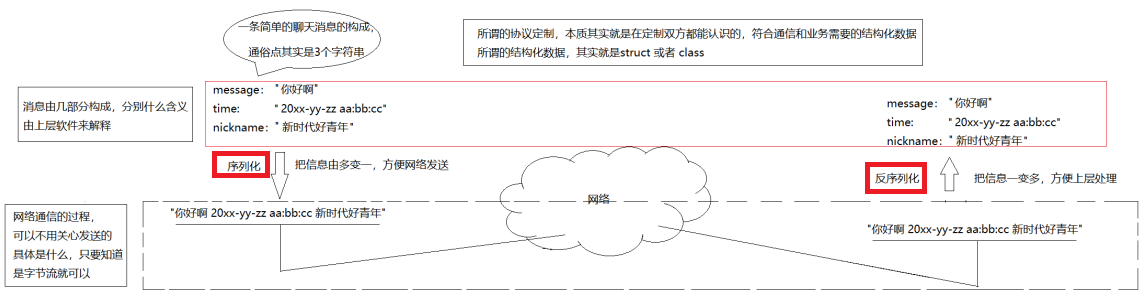
无论采用哪种数据传输方案(如纯文本格式、自定义二进制格式、序列化格式等),只要满足:一端发送时构造的数据,在另一端能够被正确解析 ,这种通信双方约定的数据格式与解析规则,就是应用层协议。
- 协议的本质是「共识」:没有固定的标准模板,收发双方规则一致即可,核心目标是让无边界的 TCP 字节流具备业务语义。
- 方案不唯一:纯文本格式(如
"1+2")、结构体序列化格式、JSON/Protobuf 等通用序列化格式,都可以作为协议的实现方式,核心是「可解析」。
2.5重新理解read、write、recv、send和tcp为什么支持全双工
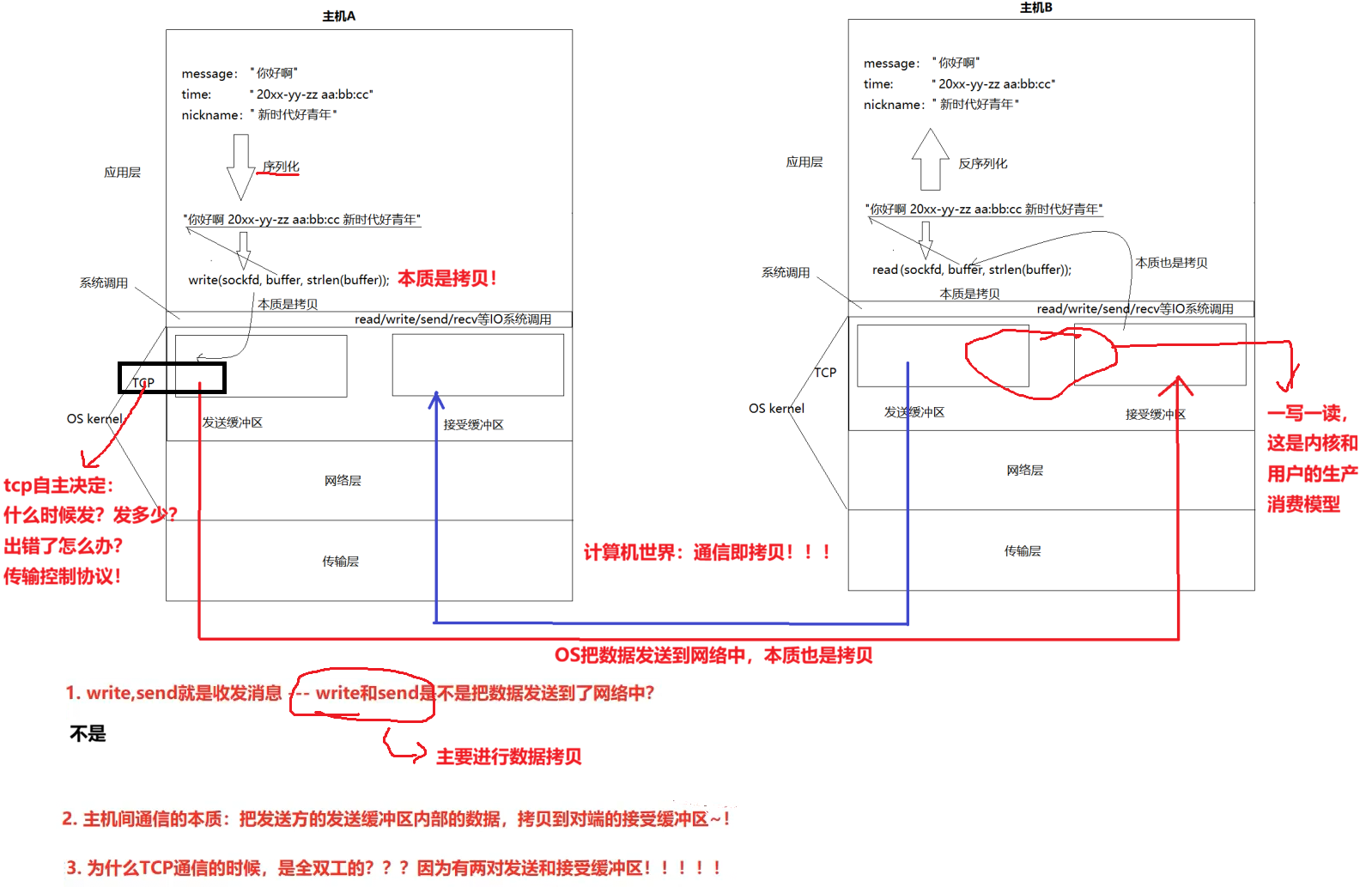
三、实现
我们要对Socket做模块化(Socket.hpp)
定制协议(Protccol.hpp)
源码在:Linux: Linux的学习库
四、Jsoncpp
4.1Jsoncpp 核心概述
Jsoncpp 是一个开源的 C++ 库,专门用于处理 JSON 数据,核心功能是:
- 序列化:将 C++ 数据结构(如对象、结构体)转换为 JSON 字符串,用于网络传输 / 文件存储。
- 反序列化:将 JSON 字符串还原为 C++ 数据结构,供业务逻辑解析使用。广泛用于需要处理 JSON 数据的 C++ 项目中(比如你的 TCP 自定义协议项目)。
| 特性 | 说明 |
|---|---|
| 简单易用 | 提供直观的 API,无需复杂配置即可处理 JSON 数据 |
| 高性能 | 经过优化,高效处理大量 JSON 数据 |
| 全面类型支持 | 支持所有 JSON 标准类型:对象、数组、字符串、数字、布尔值、null |
| 详细错误处理 | 解析失败时提供错误信息和位置,方便调试 |
4.2安装方法
不同 Linux 系统的安装命令:
# Ubuntu/Debian
sudo apt-get install libjsoncpp-dev
# CentOS/RHEL
sudo yum install jsoncpp-devel4.3序列化:C++ 数据 → JSON 字符串
序列化的目标是将 Json::Value 对象转换为 JSON 字符串,Jsoncpp 提供了 3 种常用方法,各有适用场景:
1. 方法 1:Json::Value::toStyledString()
- 特点 :直接将
Json::Value转换为格式化的 JSON 字符串(带缩进、换行,可读性强)。 - 适用场景:调试、日志打印,不适合网络传输(体积大,有多余字符)。
- 示例代码:
cpp
#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>
int main() {
Json::Value root;
root["name"] = "joe";
root["sex"] = "男";
// 序列化:格式化输出
std::string s = root.toStyledString();
std::cout << s << std::endl;
return 0;
}- 输出结果(带格式):
cpp
{
"name" : "joe",
"sex" : "男"
}2. 方法 2:Json::StreamWriter
- 特点 :支持自定义缩进、换行等格式,可灵活控制输出样式,比
toStyledString更灵活。 - 适用场景:需要自定义格式化输出的场景。
- 示例代码:
cpp
#include <iostream>
#include <sstream>
#include <memory>
#include <jsoncpp/json/json.h>
int main() {
Json::Value root;
root["name"] = "joe";
root["sex"] = "男";
// 创建 StreamWriter 工厂,生成 writer
Json::StreamWriterBuilder wbuilder;
std::unique_ptr<Json::StreamWriter> writer(wbuilder.newStreamWriter());
std::stringstream ss;
writer->write(root, &ss);
std::cout << ss.str() << std::endl;
return 0;
}3. 方法 3:Json::FastWriter
- 特点 :无缩进、无换行,输出紧凑的 JSON 字符串,性能更高,无多余字符。
- 适用场景:网络传输、存储(体积小,解析快,是项目中最常用的序列化方法)。
- 示例代码:
cpp
#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>
int main() {
Json::Value root;
root["name"] = "joe";
root["sex"] = "男";
// 序列化:紧凑格式
Json::FastWriter writer;
std::string s = writer.write(root);
std::cout << s << std::endl;
return 0;
}- 输出结果(紧凑格式):
cpp
{"name":"joe","sex":"男"}4.4反序列化:JSON 字符串 → C++ 数据
反序列化的目标是将 JSON 字符串解析为 Json::Value 对象,Jsoncpp 提供了以下方法:
1. 核心方法:Json::Reader
- 特点:提供详细的错误信息和解析位置,调试友好,是最常用的反序列化工具。
- 示例代码:
cpp
#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>
int main() {
// 模拟收到的 JSON 字符串(网络传输/文件读取)
std::string json_str = R"({"name":"张三","age":30,"city":"北京"})";
// 解析 JSON 字符串
Json::Reader reader;
Json::Value root;
bool parsingSuccessful = reader.parse(json_str, root);
// 错误处理
if (!parsingSuccessful) {
std::cout << "Failed to parse JSON: "
<< reader.getFormattedErrorMessages() << std::endl;
return -1;
}
// 访问解析后的数据
std::string name = root["name"].asString();
int age = root["age"].asInt();
std::string city = root["city"].asString();
std::cout << "Name: " << name << std::endl;
std::cout << "Age: " << age << std::endl;
std::cout << "City: " << city << std::endl;
return 0;
}- 输出结果:
cpp
Name: 张三
Age: 30
City: 北京2. 补充:Json::CharReader(不推荐)
- 更精细控制解析过程的派生类,通常场景下使用
Json::Reader或parseFromStream即可满足需求,无需手动使用CharReader。
4.5核心类:Json::Value 常用操作
Json::Value 是 Jsoncpp 的核心数据结构,用于表示和操作 JSON 数据,以下是常用操作:
1. 构造函数
Json::Value():创建空的Json::Value对象(默认类型为null)。Json::Value(ValueType type):根据指定类型创建对象(如nullValue、intValue、stringValue等)。
2. 访问元素
| 方法 | 说明 |
|---|---|
operator[](const char* key) |
通过字符串键访问对象元素,键不存在时创建新元素 |
operator[](const std::string& key) |
同上,使用 std::string 类型键 |
operator[](ArrayIndex index) |
通过索引访问数组元素,索引超出范围时创建新元素 |
at(const char* key) |
访问对象元素,键不存在时抛出异常 |
at(const std::string& key) |
同上,使用 std::string 类型键 |
3. 类型检查(判断 Json::Value 的数据类型)
isNull():检查是否为nullisBool():检查是否为布尔值isInt()/isInt64()/isUInt()/isUInt64():检查是否为整数类型isIntegral():检查是否为整数 / 可转换为整数的浮点数isDouble()/isNumeric():检查是否为浮点数 / 数字isString():检查是否为字符串isObject():检查是否为 JSON 对象(键值对集合)isArray():检查是否为 JSON 数组
4. 赋值与类型转换
-
赋值:支持直接将
bool、int、std::string等基础类型赋值给Json::ValuecppJson::Value v; v["is_valid"] = true; // 布尔值 v["count"] = 100; // 整数 v["desc"] = "test"; // 字符串 v["price"] = 99.99; // 浮点数 -
类型转换:将
Json::Value转换为对应基础类型cppbool is_valid = v["is_valid"].asBool(); int count = v["count"].asInt(); std::string desc = v["desc"].asString(); double price = v["price"].asDouble();
5. 数组与对象操作
- 通用:
size()返回元素数量,empty()检查是否为空,clear()清空所有元素 - 数组操作:
resize(ArrayIndex newSize):调整数组大小append(const Json::Value& value):在数组末尾添加元素
- 对象操作:
- 直接通过
operator[]添加键值对,无需额外操作
- 直接通过
五、进程间关系与守护进程
在 Linux 系统中,进程并非孤立存在,进程组、会话、控制终端构成了进程间的核心关联体系,而守护进程则是脱离终端、长期在后台运行的特殊进程,是系统服务的核心载体。
5.1进程组:进程的 "集体单位"
1.1 什么是进程组
每个进程除了进程 ID(PID),还属于一个进程组------它是一个或多个进程的集合,用于统一管理一组关联进程(如管道命令中的多个进程)。
- 每个进程组有唯一的进程组 ID(PGID) ,为正整数,存储于**
pid_t**类型
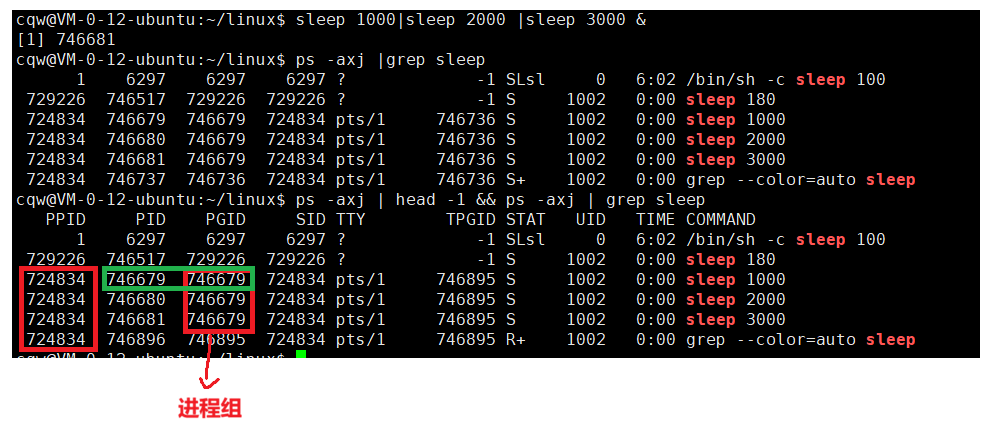
1.2 组长进程与进程组生命周期
- 组长进程:进程组 ID(PGID)等于自身 PID 的进程,负责创建进程组或组内进程
- 生命周期 :从进程组创建开始,到最后一个进程离开 为止 ------与组长进程是否终止无关,只要组内有一个进程存活,进程组就存在
5.2会话:进程组的 "上层容器"
2.1 什么是会话
会话是一个或多个进程组的集合,通常对应用户一次终端登录会话(打开一个终端即创建一个会话)。
- 每个会话有唯一的会话 ID(SID),会话首进程的 PID 即为 SID
- 核心特性:一个会话最多关联一个控制终端,用于处理用户输入输出与信号
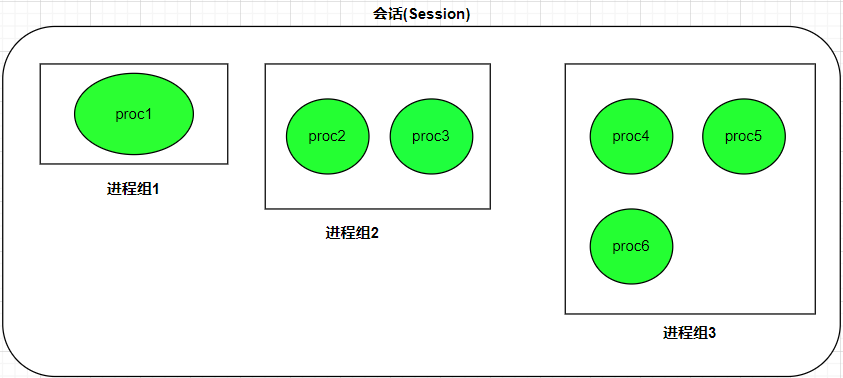
通常我们都是使用管道将几个进程编成⼀个进程组。如上图的进程组2和进程组3可能是由下列命令形成的:
&表示将进程组放在后台执行
cpp
[node@localhost code]$ proc2 | proc3 &
[node@localhost code]$ proc4 | proc5 | proc6 &2.2 创建会话:setsid () 函数
函数原型
cpp
#include <unistd.h>
pid_t setsid(void);- 功能:创建新会话,调用进程不能是进程组组长(否则报错)
- 返回值:成功返回会话 ID(SID),失败返回 - 1
调用后的核心变化
- 调用进程成为新会话的首进程(唯一进程)
- 调用进程成为新进程组的组长(PGID=PID)
- 彻底脱离原控制终端(后续无终端关联)
实操技巧:fork () 后调用 setsid ()
由于进程组组长无法调用 setsid (),标准做法是:
- 父进程 fork () 创建子进程
- 父进程立即 exit () 退出
- 子进程调用 setsid () 创建新会话(子进程非组长,调用成功)
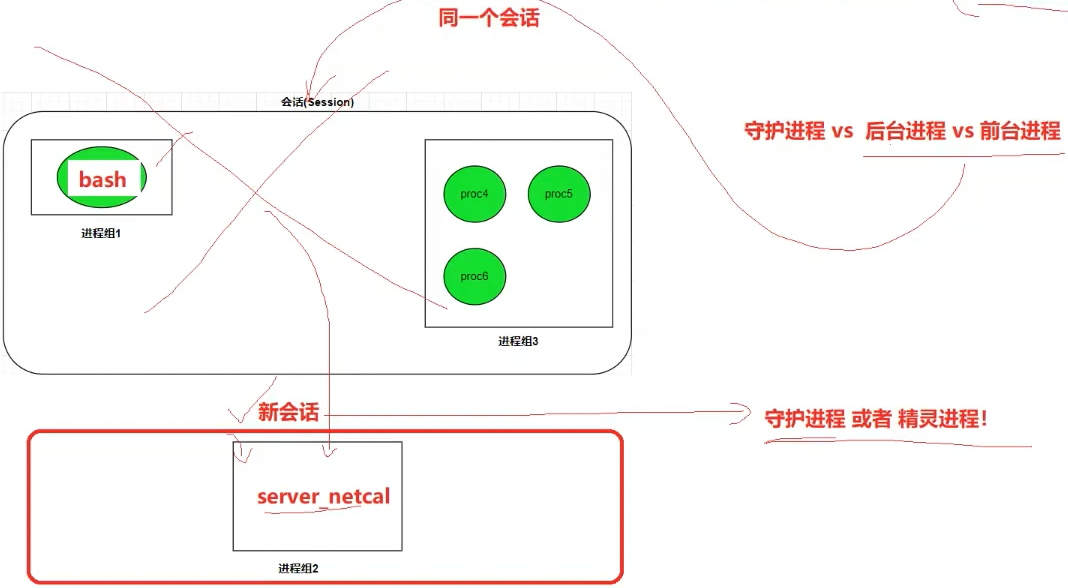
2.3 会话、进程组与终端的关系
- 一个会话包含1 个前台进程组 + 多个后台进程组
- 前台进程组:可直接与控制终端交互(接收键盘输入、信号)
- 后台进程组:仅在后台运行,无法接收终端输入
- 终端信号传递:
Ctrl+C(SIGINT)、Ctrl+\(SIGQUIT)、Ctrl+Z(SIGTSTP)仅发送给前台进程组
5.3作业控制:Shell 管理进程组的工具
3.1 作业的概念
作业是 Shell 管理的一组进程(通常对应一个命令或管道命令),分为前台作业 和后台作业:
- 前台作业:占用终端,可直接交互(如**
cat /etc/filesystems**) - 后台作业:不占用终端,后台运行(命令末尾加**
&** ,如**sleep 100 &**)
3.2 作业号与常用命令
1. 后台作业与作业号
后台命令执行后,Shell 返回作业号 ([n])和进程 PID:
cpp
cqw@VM-0-12-ubuntu:~$ cat /etc/filesystems | grep ext &
[1] 10570542. 常用作业控制命令
| 命令 | 功能 |
|---|---|
jobs |
查看当前用户所有后台 / 挂起作业(-l:显示详细信息,-p:仅显示 PID) |
fg %n |
将作业号为 n 的后台作业切到前台(缺省则切默认作业) |
Ctrl+Z |
挂起当前前台作业(状态变为 "已停止") |
3. 作业状态说明
- Running:后台作业正在运行
- Done:作业正常完成(状态码 0)
- Stopped :作业被
Ctrl+Z挂起 - Terminated:作业被终止
5.4守护进程:脱离终端的 "后台服务进程"
4.1 什么是守护进程
守护进程(Daemon)是脱离控制终端、长期在后台运行 的特殊进程,用于周期性执行任务或等待处理系统事件(如**httpd、mysqld、sshd**)。
- 核心特征:无控制终端(
ps中 TTY 列显示?)、生命周期长(随系统启动 / 关闭)、不依赖用户登录
4.2 守护进程的创建步骤(核心 5 步法)
1. 忽略关键信号
忽略SIGCHLD(子进程退出信号)、SIGPIPE(管道断开信号),避免异常退出。
2. fork () 创建子进程,父进程退出
- 目的:让子进程脱离 Shell 进程组,且非进程组组长(为后续 setsid () 做准备)
- 结果:子进程成为孤儿进程,由 1 号进程(init/systemd)收养
3. 子进程调用 setsid () 创建新会话
- 核心步骤:彻底脱离原会话与控制终端,成为新会话首进程、新进程组组长
4. 切换工作目录到根目录
- 目的:防止占用可卸载文件系统(如 U 盘),避免目录无法卸载
- 命令:
chdir("/")
5. 重定向标准 I/O 到 /dev/null
- 目的:关闭与终端的输入输出关联,避免资源占用与干扰
- 操作:关闭 0(stdin)、1(stdout)、2(stderr),或重定向到
/dev/null(凡是写到这个文件里的东西都被丢弃)