当 AI 编程任务变复杂时,一个通用助手很容易被迫扮演所有角色:产品分析师、架构师、实现者、测试工程师、审查者、文档作者。短任务里这没问题,但一旦任务跨模块、跨领域、持续多轮,单个 Agent 的上下文和判断就会变得吃紧。revfactory/harness 的想法是:不要让一个 Agent 硬扛所有事,而是先为项目设计一支领域化 Agent 团队。
它把自己定义为 Claude Code 的 Team-Architecture Factory。用户描述项目领域或说出类似 "build a harness for this project" 的意图后,它会生成适合该项目的 agents 和 skills,并从预设架构模式中选择团队组织方式。也就是说,Harness 不是直接帮你写某个功能,而是帮你搭建"更适合写这个项目的 AI 团队"。
它为什么不是普通插件
普通 AI coding 插件往往提供一组固定命令:写代码、查 bug、做 review、生成测试。Harness 的层级更高。它试图根据你的项目类型生成一套团队结构,再把团队成员和技能写入 .claude/agents/ 与 .claude/skills/。换句话说,它不是"一个技能",而是"生成技能和代理的技能"。
README 把它放在 L3 Meta-Factory 层,这个说法有点抽象,但意思很有用:L1 可能是具体工具,L2 可能是跨工具流程,L3 则是生成流程和团队架构的系统。Harness 关心的是"怎样为某个领域构造 Agent 团队",而不是"怎样解决某一个固定任务"。
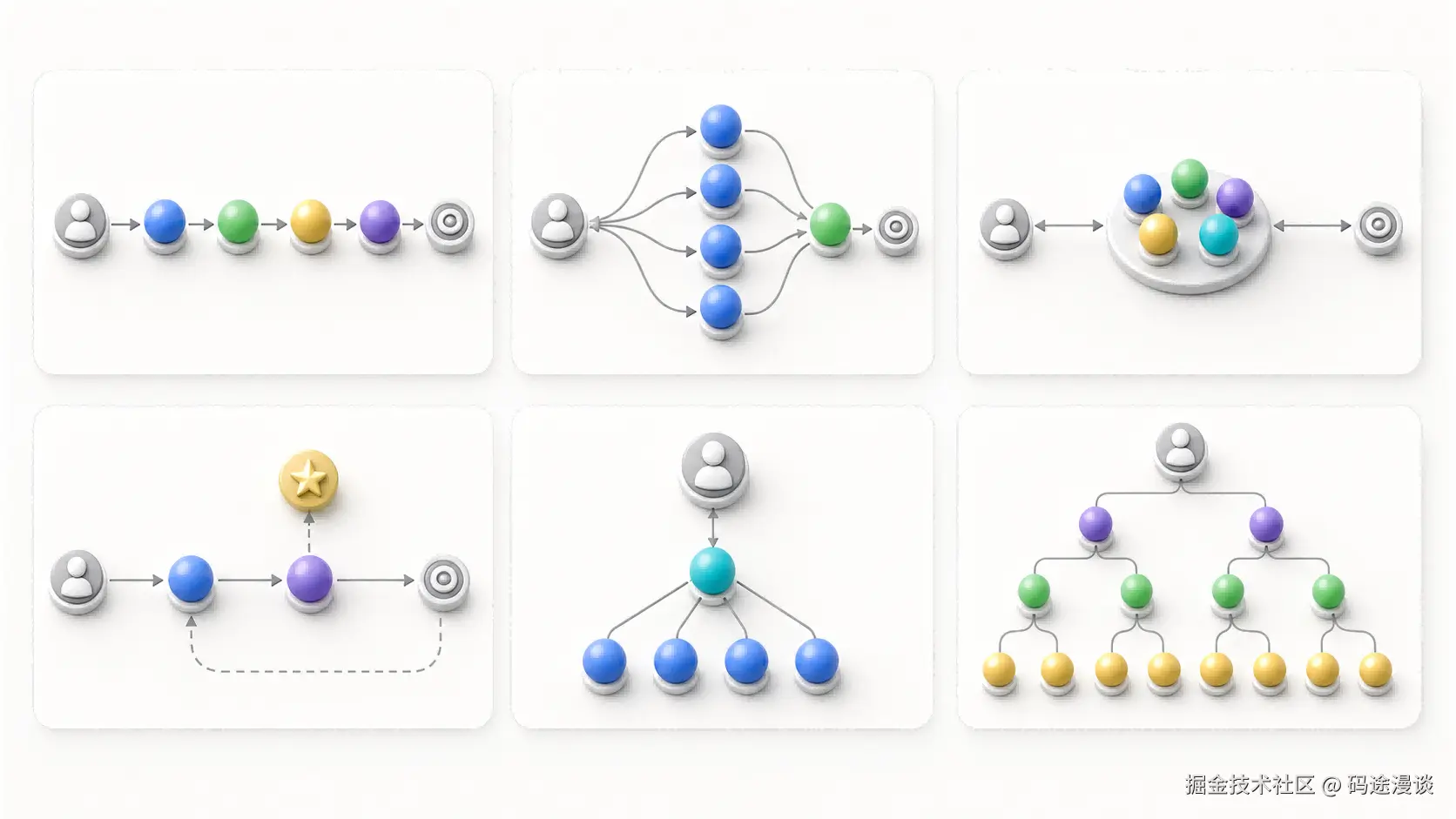
六种团队架构模式
项目 README 提到六种预设架构:Pipeline、Fan-out/Fan-in、Expert Pool、Producer-Reviewer、Supervisor、Hierarchical Delegation。理解这六种模式,是理解 Harness 的关键。
Pipeline 适合顺序明确的任务,比如"需求分析 -> 设计 -> 实现 -> 测试 -> 文档"。它的好处是阶段清楚,输出可逐步传递。
Fan-out/Fan-in 适合并行探索,比如让多个 Agent 分别研究不同方案,最后汇总选择。它能降低单一路径思维的风险。
Expert Pool 适合领域复杂的项目。比如一个金融系统可能需要安全、数据、后端、合规、前端等不同专家参与。
Producer-Reviewer 适合强调质量的任务。一个 Agent 产出,另一个 Agent 审查,减少自我确认偏差。
Supervisor 适合需要统一协调的任务。监督者负责拆解、分派、检查进度和处理异常。
Hierarchical Delegation 则适合更大规模的任务,把复杂目标逐级拆成子任务,让不同层级的 Agent 承担不同粒度的判断。

工作流:从领域描述到团队落地
README 中的 Workflow 大致分为六个阶段:Domain Analysis、Team Architecture Design、Agent Definition Generation、Skill Generation、Integration & Orchestration、Validation & Testing。
第一阶段是领域分析。系统需要理解项目是什么、任务复杂度在哪里、常见风险是什么、需要哪些专业角色。
第二阶段是团队架构设计。它会判断应该使用哪种团队模式,或者组合哪些模式。比如一个前端重构任务可能适合 Producer-Reviewer,而一个研究型任务可能更适合 Fan-out/Fan-in。
第三阶段生成 Agent 定义。也就是把"安全审查者""后端实现者""测试策略师"这类角色落成 Claude Code 可识别的 agent 文件。
第四阶段生成 Skills。Agent 只有角色还不够,还需要知道何时触发、如何工作、该读哪些上下文、输出什么格式。
第五阶段做编排。多个 Agent 之间要传递数据、处理错误、合并结果,否则团队会变成一堆孤立角色。
第六阶段做验证。项目强调 dry-run、触发验证、with-skill vs without-skill 对比测试,这一点很重要,因为生成出来的团队必须证明自己真的比默认方式更好。
适合的使用场景
Harness 适合任务复杂、角色分工自然存在的项目。比如:
- 大型代码库重构。
- 多模块产品开发。
- 安全审计和修复计划。
- 数据平台或后端系统设计。
- 游戏、前端、移动端等需要多角色协作的项目。
- 需要把团队经验沉淀成 Claude Code agents 和 skills 的长期项目。
如果你的团队已经反复对 AI 说"先让架构师看一下,再让实现者写,再让 reviewer 检查",Harness 的概念就很自然:把这种分工固化下来。
不适合的场景
如果只是改一个小 bug、写一个简单脚本、补一段文案,Harness 可能过重。团队架构本身有成本:要生成、理解、维护,还要确保触发正确。
另外,它明显围绕 Claude Code 生态设计。如果你的主要工作环境不是 Claude Code,可能需要先评估兼容性或寻找类似概念的移植方式。README 中也提到与 Archon、ECC、meta-harness 等邻近项目的关系,这说明它处在一个快速变化的 AI coding 工具生态里。
安装与使用路线
README 提供了 marketplace 安装方式,也支持直接作为 global skill 安装。最适合的上手方式不是先在生产项目里使用,而是在一个中等复杂度的试验项目里运行一次,让它生成 agents 和 skills,然后审查输出。
建议上手步骤:
- 选择一个你熟悉的小型或中型项目。
- 运行 Harness 生成团队。
- 查看生成的
.claude/agents/和.claude/skills/。 - 让默认 Claude Code 和 Harness 团队分别处理同类任务。
- 比较任务分解、输出质量、审查深度和上下文使用情况。
如果生成结果过于复杂,就收窄团队;如果角色太泛,就补充领域描述;如果触发不稳定,就调整 skill 描述。
二次开发可以看哪里
仓库本身不大,README、docs/quickstart.md、docs/experimental-dependency.md 是理解项目的主要入口。真正值得研究的是它生成出来的 agent 和 skill 结构,以及六种 architecture pattern 如何映射到不同任务。
如果你想把类似思想迁移到其他 AI coding 环境,重点不是复制文件,而是复制方法:领域分析、团队模式选择、角色定义、技能生成、编排协议、验证对比。
读完后的判断
Harness 代表了 AI coding 的一个明显趋势:从"一个大模型助手"走向"可配置的 AI 工程组织"。当任务足够简单时,单助手最快;当任务足够复杂时,结构本身就是能力。Harness 值得看,正因为它把这种结构显式化了。