1. DataFrame认知
-
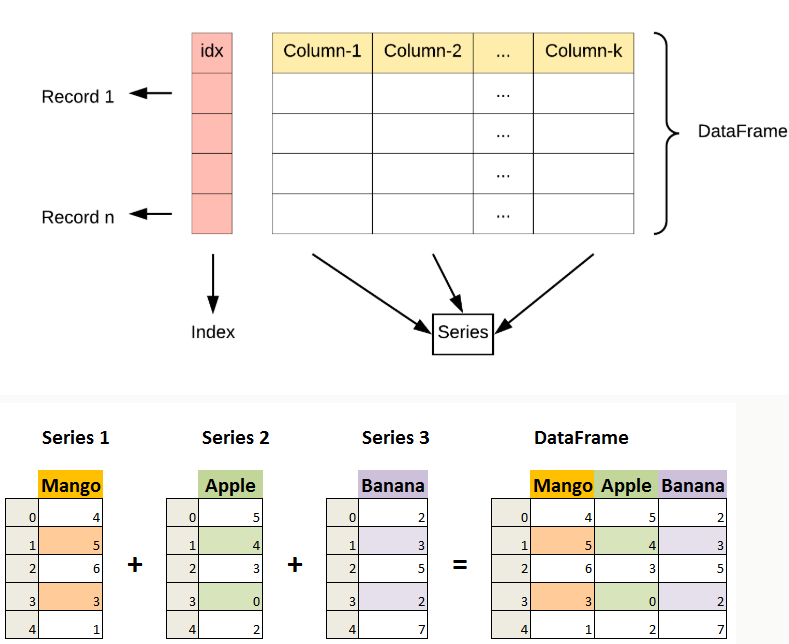
DataFrame 是 Pandas 中的另一个核心数据结构,类似于一个二维的表格或数据库中的数据表。
-
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。
-
DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
-
DataFrame 提供了各种功能来进行数据访问、筛选、分割、合并、重塑、聚合以及转换等操作。
-
DataFrame 是一个非常灵活且强大的数据结构,广泛用于数据分析、清洗、转换、可视化等任务。
2. DataFrame的创建
创建语法:
python
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)二维的、大小可变的(可以增删行、增删列)、可存储不同类型数据的表格型数据。该数据结构包含带标签的轴(行标签和列标签),算术运算会根据行标签和列标签自动对齐。是 pandas 中最主要(核心)的数据结构。
| 参数 | 含义 |
|---|---|
| data | 支持的数据类型:字典、数组、可迭代对象、dataframe、Series |
| index | 默认是0,1,2,...n-1 |
| columns | 默认为0,1,2,...n-1,若数据data中包含列标签,则保留columns指定的列。即当数据data中没有列名,使用指定的列名;当数据data中包含列名,只保留columns中指定的列 |
| dtype | 默认为None, 强制指定的数据类型。只允许传入一种数据类型。如果为 None,则自动推断。 |
| copy | 布尔值,默认为None。控制新表格和原数据是不是同一份数据。字典创建:DataFrame默认 = 复制(安全);DataFrame / 二维数组创建:默认 = 不复制(省内存)字典里有 Series:用 copy=False 能完全不复制,共用数据 |
python
# 1.通过字典创建dataframe
print('**********df1***********')
dct1 = {"name":('lisa','jane','liming'),
'age':[19,20,21]}
df1 = pd.DataFrame(dct1)
print(df1)
# 2.通过包含Series的字典创建dataframe
# 2.1 Series中不指定index
print('**********df2***********')
dct2 = {'course':['math','history','physics','chemisty'],
'score':pd.Series([99,88,77,66])}
df2 = pd.DataFrame(dct2)
print(df2)
# 2.2 Series中指定index
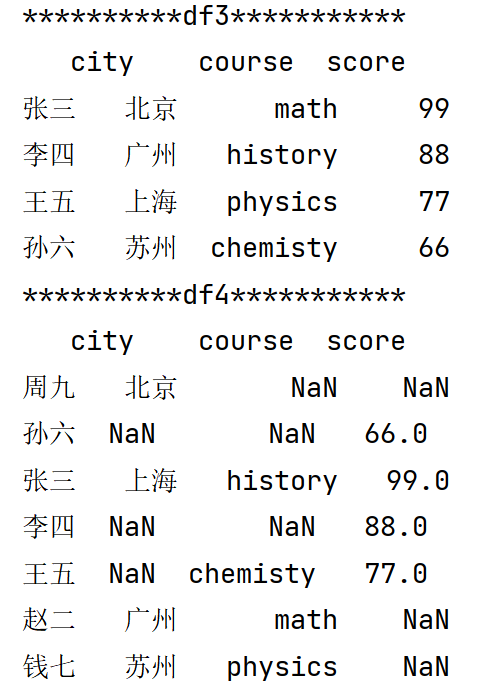
print('**********df3***********')
dct3 = {'city':['北京','广州','上海','苏州'],
'course':['math','history','physics','chemisty'],
'score':pd.Series([99,88,77,66],index=['张三','李四','王五','孙六'])}
df3 = pd.DataFrame(dct3)
print(df3)
# 2.3 多个Series中指定index,但其中还有普通列表,只有4个元素无法与合并后的6个索引匹配,报错
# ValueError: array length 4 does not match index length 6
# dct4 = {'city':['北京','广州','上海','苏州'],
# 'course':pd.Series(['math','history','physics','chemisty'],
# index=['赵二','张三','钱七','王五']),
# 'score':pd.Series([99,88,77,66],index=['张三','李四','王五','孙六'])}
#
# df4 = pd.DataFrame(dct4)
# print(df4)
print('**********df4***********')
# 2.3 多个Series中指定index,自动按索引对齐
dct4 = {'city':pd.Series(['北京','广州','上海','苏州'],
index=['周九','赵二','张三','钱七']),
'course':pd.Series(['math','history','physics','chemisty'],
index=['赵二','张三','钱七','王五']),
'score':pd.Series([99,88,77,66],index=['张三','李四','王五','孙六'])}
df4 = pd.DataFrame(dct4)
print(df4)
print('**********df5***********')
# 3. 通过array()数组创建dataframe
ar1 = np.array(np.random.randint(0,100,size=(4,3)))
df5 = pd.DataFrame(ar1,columns=['aa','bb','cc'])
print(df5)
print('**********df6***********')
# 通过dataframe创建
df6 = pd.DataFrame(df5,columns=['aa','cc'])
print(df6)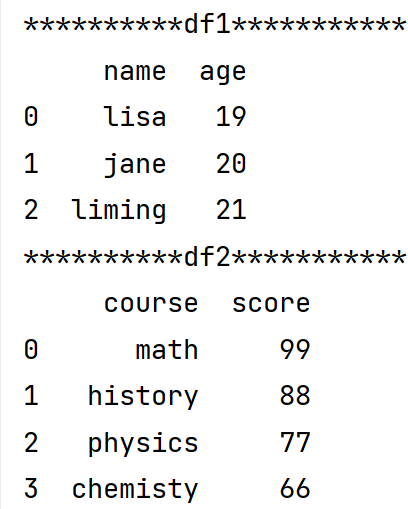

创建总结:
-
普通字典(列表 / 元组为值)构建
字典键作为 DataFrame 列名,字典内列表、元组数据按位置组成各列,所有容器元素长度必须保持一致,生成后默认生成从 0 开始的数字行索引,数据按顺序一一对应填充。
-
字典混用无索引 Series 与普通列表构建
未自定义索引的 Series 和普通列表规则一致,依靠下标位置匹配数据,要求所有数据长度相同;一旦字典内出现带自定义索引的 Series,就会整合全部索引扩充行数量,搭配固定长度无索引列表时,行列长度不一致直接触发报错。
-
全自定义索引 Series 组成字典构建
字典所有值全部为带独立索引的 Series 时,DataFrame 会汇总全部行索引并自动对齐数据,索引匹配成功填入原值,无匹配项填充缺失值 NaN,不受各 Series 索引顺序、元素数量差异影响,不会报长度错误。
-
数组、已有 DataFrame 数据源构建
使用二维 numpy 数组创建时,数组每行对应表格一行,可通过 columns 参数自定义列名,默认数字行索引;依托现有 DataFrame 新建表格时,借助 columns 参数可筛选指定列,填写原表不存在的列名会生成全 NaN 新列。
3. DataFrame常用属性
| 属性 | 含义 |
|---|---|
| dtypes | 返回 DataFrame的数据类型 |
| index | 返回DataFrame的行标签 |
| columns | 返回DataFrame的列标签 |
| values | 返回DataFrame的数据值 |
| shape | 返回DataFrame的形状(m*n) |
| ndim | 返回DataFrame的维度 |
| size | 返回DataFrame的数据个数:m*n |
| loc | 通过行标签、列标签获取DataFrame数据 |
| iloc | 基于纯整数位置的索引,用于按位置选取数据。不管行标签、列标签叫什么,只看 "第几个" |