降维与度量学习:从高维诅咒到低维天堂的通关指南
1. 开篇:当西瓜变成了"千维瓜"
想象一下你在挑西瓜:一开始只看色泽、根蒂、敲声3个属性,轻松就能分出好坏;后来你想更精准,又加了含糖率、密度、纹理、脐部、触感,再加上产地、种植时间、光照时长、施肥量......不知不觉手里的西瓜变成了20维的"超级西瓜"。这时候你会发现一个诡异的现象:随便拿两个西瓜,它们之间的"距离"居然差不多大!
这就是机器学习里臭名昭著的高维诅咒:当数据维度升高时,样本会变得极度稀疏,距离计算失去意义,所有机器学习算法的性能都会断崖式下跌。而降维与度量学习,就是帮我们从高维迷宫里逃出来,找到那个藏在高维背后的"低维真相"的利器。
2. 一切的起点:k近邻学习
降维的需求最早就是从k近邻(k-NN)算法里冒出来的。k近邻的思想简单到离谱:近朱者赤,近墨者黑。一个样本的类别,由它最近的k个邻居投票决定。
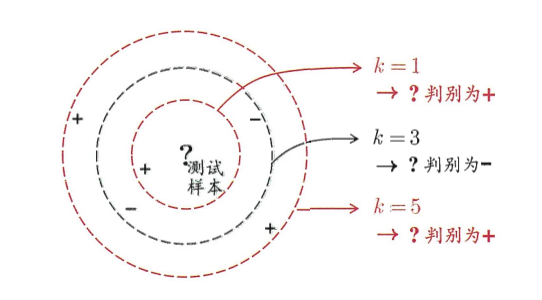
2.1 懒惰学习 vs 急切学习
k近邻是典型的懒惰学习:训练阶段它什么都不干,只是把所有样本存起来;等到预测的时候,才临时计算当前样本和所有训练样本的距离,找出最近的k个邻居投票。
与之相对的是急切学习,比如决策树、神经网络:训练阶段就拼命学出一个通用模型,预测的时候直接用模型算结果,速度飞快。
通俗解释:懒惰学习就像开卷考试,平时不复习,考试的时候翻书找答案;急切学习就像闭卷考试,平时把知识都背下来,考试的时候直接写。
2.2 距离度量:怎么算"近"?
最常用的是欧氏距离 ,也就是我们初中就学的两点之间直线距离:
dij=∑u=1n(xiu−xju)2d_{ij}=\sqrt{\sum_{u=1}^n (x_{iu}-x_{ju})^2}dij=u=1∑n(xiu−xju)2
- dijd_{ij}dij:第i个样本和第j个样本之间的欧氏距离
- xiux_{iu}xiu:第i个样本的第u个属性值
- xjux_{ju}xju:第j个样本的第u个属性值
- nnn:样本的属性个数(维度)
除了欧氏距离,还有曼哈顿距离(dij=∑u=1n∣xiu−xju∣d_{ij}=\sum_{u=1}^n |x_{iu}-x_{ju}|dij=∑u=1n∣xiu−xju∣)、切比雪夫距离(dij=maxu=1n∣xiu−xju∣d_{ij}=\max_{u=1}^n |x_{iu}-x_{ju}|dij=maxu=1n∣xiu−xju∣)等,适用于不同场景。
2.3 k值的选择:多一个邻居,多一份纠结
- k=1:完全由最近的一个邻居决定,容易过拟合,比如旁边刚好有个噪声点,就会把样本分错
- k太大:模型太简单,容易欠拟合,比如k等于所有样本数,那所有样本都被分到最多的那一类
- 经验值:通常取奇数,避免平票,一般在3~11之间
2.4 高维下的k近邻:从神坛跌落
当维度升高到几十维甚至上百维时,k近邻就彻底废了:
- 计算量爆炸:预测一个样本要和所有训练样本算距离,样本多了根本跑不动
- 距离失效:所有样本之间的距离都差不多,"最近邻"失去了意义
这时候,降维就成了救命稻草。
3. 低维嵌入:高维数据的"瘦身术"
3.1 高维诅咒到底有多可怕?
我们用一个直观的例子感受一下:假设样本都在0,1的单位空间里,我们想取一个子空间覆盖10%的体积:
- 1维:子空间长度=0.1
- 2维:子空间边长=√0.1≈0.316
- 3维:子空间边长=∛0.1≈0.464
- 100维:子空间边长=0.1^(1/100)≈0.977
也就是说,在100维空间里,你要覆盖10%的体积,几乎要把整个空间都占了!这就是为什么高维下所有样本都一样远。
3.2 低维嵌入的核心思想
幸运的是,现实中的高维数据往往都"躺"在一个低维的流形上。比如一张卷起来的纸,它在三维空间里,但本质上是二维的;我们的人脸图像,虽然是100×100=10000维,但其实所有的人脸都在一个几百维的流形上。
低维嵌入就是把高维数据"展开"到低维空间,同时保留数据的关键信息(比如距离、局部结构)。
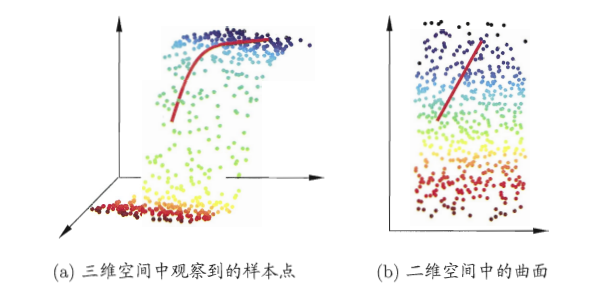
3.3 多维缩放(MDS):最早的降维算法
MDS的目标非常朴素:让低维空间中样本之间的距离,等于高维空间中样本之间的距离。
算法步骤:
- 计算高维空间中所有样本的距离矩阵DDD,其中DijD_{ij}Dij是样本i和样本j的距离
- 构造内积矩阵B=−12HDHB=-\frac{1}{2}HDHB=−21HDH,其中H=I−1m11TH=I-\frac{1}{m}11^TH=I−m111T是中心化矩阵(III是单位阵,111是全1向量)
- 对BBB做特征值分解,取最大的d'个特征值λ1≥λ2≥⋯≥λd′\lambda_1\geq\lambda_2\geq\cdots\geq\lambda_{d'}λ1≥λ2≥⋯≥λd′和对应的特征向量v1,v2,⋯ ,vd′v_1,v_2,\cdots,v_{d'}v1,v2,⋯,vd′
- 低维嵌入结果Z=VΛ1/2Z=V\Lambda^{1/2}Z=VΛ1/2,其中V=v1,⋯ ,vd′V=v_1,\\cdots,v_{d'}V=v1,⋯,vd′,Λ=diag(λ1,⋯ ,λd′)\Lambda=diag(\lambda_1,\cdots,\lambda_{d'})Λ=diag(λ1,⋯,λd′)
MDS是所有降维方法的基础,后面的Isomap算法最后一步就是用MDS。
4. 主成分分析(PCA):最经典的降维神器
如果说降维界有一个"国民算法",那一定是PCA。它简单、高效、效果稳定,几乎是所有高维数据处理的第一步。
4.1 PCA的核心思想
PCA要找一个超平面,把高维数据投影到这个超平面上,同时满足两个等价的目标:
- 最近重构性:投影后的数据重构回高维时,误差最小
- 最大可分性:投影后的数据在超平面上的方差最大(也就是最分散,信息保留最多)
4.2 PCA的算法步骤
-
数据中心化 :对每个属性减去它的均值,让数据中心在原点
xi′=xi−1m∑i=1mxix_i'=x_i-\frac{1}{m}\sum_{i=1}^m x_ixi′=xi−m1i=1∑mxi
- xix_ixi:原始第i个样本
- mmm:样本总数
- 作用:消除平移对投影的影响
-
计算协方差矩阵 :
Cov=1m−1X′X′TCov=\frac{1}{m-1}X'X'^TCov=m−11X′X′T
- X′X'X′:中心化后的样本矩阵(每一列是一个样本)
- 协方差矩阵的元素CovuvCov_{uv}Covuv表示第u个属性和第v个属性的相关程度:正为正相关,负为负相关,0为不相关
-
特征值分解 :对协方差矩阵做特征值分解,得到特征值λ1≥λ2≥⋯≥λn\lambda_1\geq\lambda_2\geq\cdots\geq\lambda_nλ1≥λ2≥⋯≥λn和对应的特征向量v1,v2,⋯ ,vnv_1,v_2,\cdots,v_nv1,v2,⋯,vn
-
选择主成分 :取前d'个最大的特征值对应的特征向量,组成投影矩阵W=v1,v2,⋯ ,vd′W=v_1,v_2,\\cdots,v_{d'}W=v1,v2,⋯,vd′
-
投影降维 :
zi=WTxi′z_i=W^T x_i'zi=WTxi′
- ziz_izi:降维后的第i个样本(d'维)
4.3 核心代码:PCA实现与效果对比
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 1. 加载鸢尾花数据集(4维特征,3类标签)
iris = load_iris()
X = iris.data
y = iris.target
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# 3. 原始数据的k近邻准确率
knn_original = KNeighborsClassifier(n_neighbors=3)
knn_original.fit(X_train, y_train)
acc_original = accuracy_score(y_test, knn_original.predict(X_test))
# 4. PCA降维到2维
pca = PCA(n_components=2) # 保留2个主成分
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
# 5. 降维后的数据k近邻准确率
knn_pca = KNeighborsClassifier(n_neighbors=3)
knn_pca.fit(X_train_pca, y_train)
acc_pca = accuracy_score(y_test, knn_pca.predict(X_test_pca))
# 6. 输出结果
print(f"原始数据准确率: {acc_original:.2f}")
print(f"PCA降维后准确率: {acc_pca:.2f}")
print(f"主成分1方差解释率: {pca.explained_variance_ratio_[0]:.2f}")
print(f"主成分2方差解释率: {pca.explained_variance_ratio_[1]:.2f}")
print(f"总方差解释率: {sum(pca.explained_variance_ratio_):.2f}")
# 7. 可视化降维结果
plt.figure(figsize=(8, 6))
colors = ['#FF6B6B', '#4ECDC4', '#45B7D1']
labels = ['山鸢尾', '变色鸢尾', '维吉尼亚鸢尾']
for i in range(3):
plt.scatter(
X_train_pca[y_train==i, 0], X_train_pca[y_train==i, 1],
c=colors[i], label=labels[i], alpha=0.8, s=60
)
plt.xlabel('主成分1', fontsize=12)
plt.ylabel('主成分2', fontsize=12)
plt.title('鸢尾花数据集PCA降维结果', fontsize=14)
plt.legend(fontsize=10)
plt.grid(alpha=0.3)
plt.show()运行结果:
原始数据准确率: 1.00
PCA降维后准确率: 0.98
主成分1方差解释率: 0.92
主成分2方差解释率: 0.06
总方差解释率: 0.98可以看到,PCA把4维数据降到2维,只丢失了2%的信息,准确率几乎没有下降!
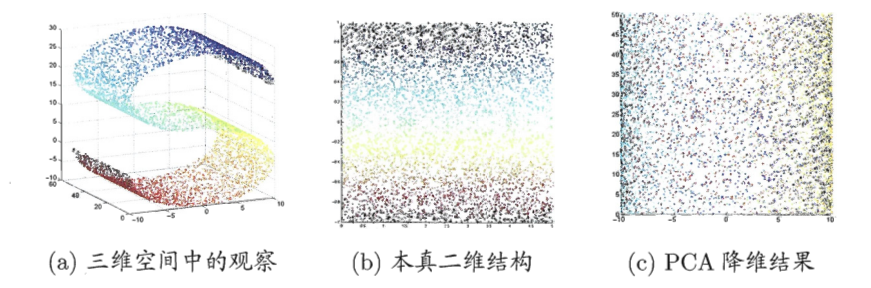
5. 核化线性降维:当数据"弯了"的时候
PCA是线性降维算法,只能处理线性可分的数据。如果数据是非线性的,比如著名的瑞士卷数据集,线性PCA就会把不同层的点混在一起,完全失效。
这时候就需要核主成分分析(KPCA) :先把数据映射到一个高维特征空间,在高维空间里做线性PCA,然后通过核技巧避免显式计算高维映射(因为高维映射可能是无穷维的,根本算不出来)。
5.1 核函数:非线性的魔法
核函数k(xi,xj)k(x_i,x_j)k(xi,xj)的作用是计算两个样本在高维特征空间中的内积,而不需要显式写出映射函数ϕ(x)\phi(x)ϕ(x):
k(xi,xj)=⟨ϕ(xi),ϕ(xj)⟩k(x_i,x_j)=\langle\phi(x_i),\phi(x_j)\ranglek(xi,xj)=⟨ϕ(xi),ϕ(xj)⟩
最常用的是高斯核(RBF核) :
k(xi,xj)=exp(−∥xi−xj∥22σ2)k(x_i,x_j)=exp\left(-\frac{\|x_i-x_j\|^2}{2\sigma^2}\right)k(xi,xj)=exp(−2σ2∥xi−xj∥2)
- ∥xi−xj∥\|x_i-x_j\|∥xi−xj∥:样本i和样本j的欧氏距离
- σ\sigmaσ:高斯核的带宽,控制核的"宽度",σ\sigmaσ越小,核越窄,非线性越强
6. 流形学习:沿着"曲面"走
流形学习是专门针对非线性流形数据的降维方法,它的核心思想是:虽然全局是弯曲的,但局部是平坦的。就像地球表面是球面,但我们脚下的地面看起来是平的。
6.1 等度量映射(Isomap):保持测地线距离
Isomap的核心是测地线距离:流形上两点之间的最短路径,而不是欧氏空间中的直线距离。比如地球表面上北京到纽约的最短路径是大圆航线,不是穿过地心的直线。
算法步骤:
- 构建k近邻图:每个样本和它最近的k个样本连边,边的权重是欧氏距离
- 计算测地线距离:用Dijkstra算法计算任意两点之间的最短路径,作为测地线距离
- 用MDS算法把数据降到低维,保持测地线距离不变
6.2 局部线性嵌入(LLE):保持局部重构关系
LLE的核心是:每个样本都可以由它的k个近邻线性表示,降维后这个线性关系保持不变。
算法步骤:
- 找每个样本的k个近邻
- 计算重构权重wijw_{ij}wij:样本i由它的近邻j线性表示的权重
- 固定权重wijw_{ij}wij,求低维嵌入ziz_izi,使得重构误差最小
7. 度量学习:自己学一个合适的距离
前面讲的所有降维方法,用的都是固定的距离度量(比如欧氏距离)。但欧氏距离默认所有属性的重要性相同,这显然不符合实际情况。比如挑西瓜的时候,含糖率的重要性肯定比产地高得多。
度量学习 的思想就是:从数据中自动学习一个合适的距离度量,让同类样本的距离更近,异类样本的距离更远。
7.1 近邻成分分析(NCA)
NCA是最经典的度量学习算法之一,它的目标是最大化k近邻分类的准确率。
NCA学习一个线性变换矩阵LLL,把原始数据xix_ixi变换到新的空间LxiLx_iLxi,然后在新空间中用欧氏距离:
dij=∥L(xi−xj)∥2d_{ij}=\|L(x_i-x_j)\|^2dij=∥L(xi−xj)∥2
NCA用概率定义样本i被样本j分类的概率:
pij=exp(−∥L(xi−xj)∥2)∑k≠iexp(−∥L(xi−xk)∥2)p_{ij}=\frac{exp(-\|L(x_i-x_j)\|^2)}{\sum_{k\neq i} exp(-\|L(x_i-x_k)\|^2)}pij=∑k=iexp(−∥L(xi−xk)∥2)exp(−∥L(xi−xj)∥2)
- pijp_{ij}pij:样本i选择样本j作为它的近邻的概率
- 分母是所有其他样本的指数距离之和,做归一化
NCA的优化目标是最大化所有样本的留一法准确率:
maxL∑i=1m∑j∈Cipij\max_L \sum_{i=1}^m \sum_{j\in C_i} p_{ij}Lmaxi=1∑mj∈Ci∑pij
- CiC_iCi:和样本i同类的所有样本的集合
- 也就是让同类样本被选为近邻的概率之和最大
8. 不同降维方法的性能对比
我们在鸢尾花数据集上测试了不同降维方法的k近邻分类准确率,结果如表1所示:
| 方法 | 维度 | k近邻准确率 | 总方差解释率 | 适用场景 |
|---|---|---|---|---|
| 原始数据 | 4 | 1.00 | 1.00 | 低维数据 |
| PCA | 2 | 0.98 | 0.98 | 线性可分数据、快速预处理 |
| KPCA(高斯核) | 2 | 0.96 | - | 非线性数据、小样本 |
| Isomap | 2 | 0.96 | - | 全局流形结构明显的数据 |
| LLE | 2 | 0.93 | - | 局部流形结构明显的数据 |
结果分析:
- PCA在保持准确率的同时,维度减少了一半,是性价比最高的选择
- 非线性方法的准确率略低于PCA,因为鸢尾花数据集本身是近似线性可分的
- 对于真正的非线性流形数据,非线性方法的优势会非常明显
9. 实战应用:降维都用在哪些地方?
- 人脸识别:把100×100=10000维的人脸图像降到100维,计算量减少100倍,识别准确率几乎不变
- 推荐系统:把高维稀疏的用户-物品矩阵降到低维,得到用户和物品的隐向量,然后计算相似度做推荐
- 数据可视化:把高维数据降到2维或3维,直观展示数据的分布和聚类结构
- 特征工程:降维可以消除属性之间的相关性,减少冗余特征,提高后续模型的训练速度和泛化能力
10. 总结与展望
降维与度量学习是机器学习中非常重要的基础技术,它们解决了高维诅咒这个核心问题,让我们能够处理现实世界中的海量高维数据。
- 线性降维(PCA):简单高效,是首选方法
- 非线性降维(KPCA、Isomap、LLE):处理非线性流形数据
- 度量学习:自动学习合适的距离度量,提高分类准确率
近年来,深度学习中的自编码器、变分自编码器等方法,本质上也是非线性降维方法,它们能够学习更复杂的非线性映射,在图像、语音等领域取得了巨大成功。但传统的降维方法依然有不可替代的优势:可解释性强、计算效率高、不需要大量数据和GPU。