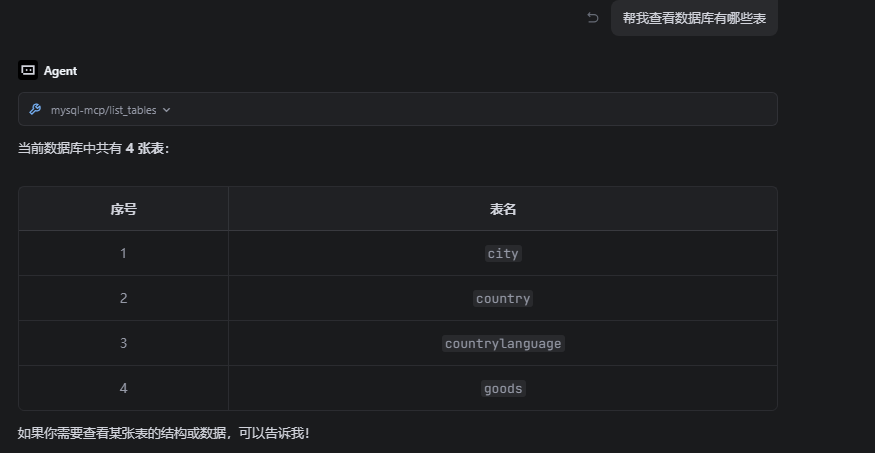
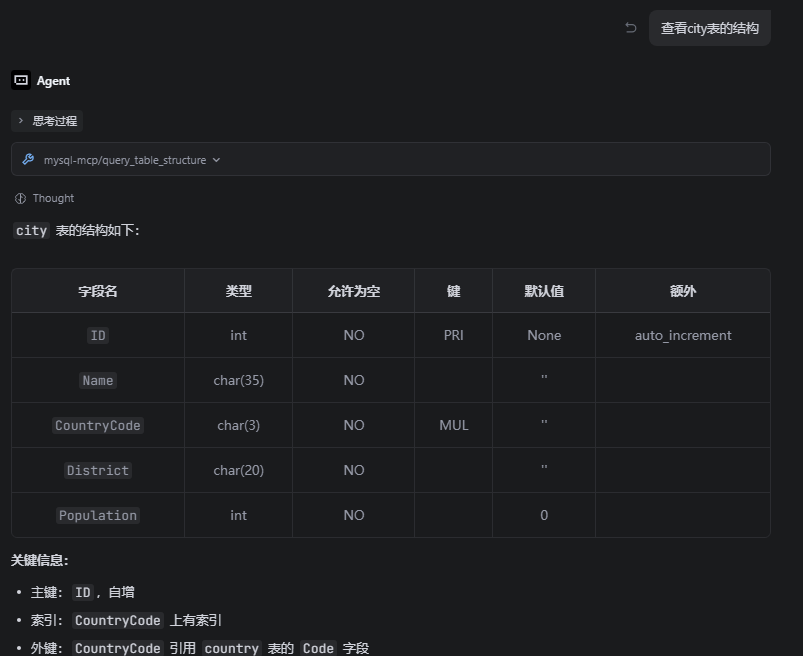
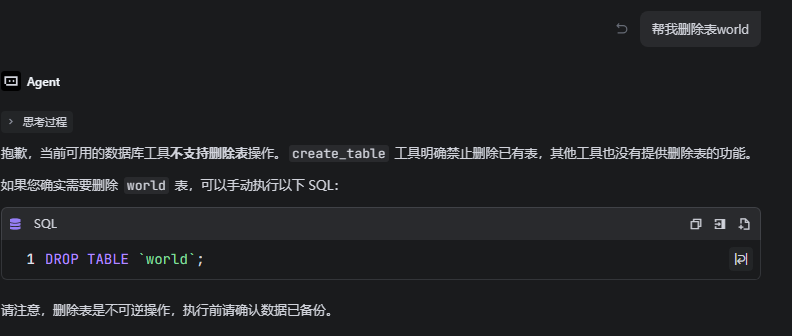
1.首先安装python环境,requires-python = ">=3.10"
2.安装C:/Users/yuyk328/python-sdk/python3.13.2/python.exe -m pip install mcp pymysql
3.安装完成后,再运行:C:/Users/yuyk328/python-sdk/python3.13.2/python.exe d:/20260408/mysql-mcp/server.py
4.如果 mcp 包安装有问题,也可以试试用 fastmcp 替代:
C:/Users/yuyk328/python-sdk/python3.13.2/python.exe -m pip install fastmcp pymysql
5.运行方式:stdio 模式(用于接入 MCP 客户端)
这是默认模式, 不能直接在终端运行 ,需要配置到 MCP 客户端中。例如在 Trae 或 Claude Desktop 的配置文件中添加:
bash
{
"mcpServers": {
"mysql-mcp": {
"command": "C:/Users/yuyk328/python-sdk/python3.13.2/python.exe",
"args": [
"d:/20260408/mysql-mcp/server.py"
],
"env": {
"MYSQL_HOST": "localhost",
"MYSQL_PORT": "3306",
"MYSQL_USER": "root",
"MYSQL_PASSWORD": "root",
"MYSQL_DATABASE": "world"
}
}
}
}项目目录如下:
server.py代码:
bash
import os
import pymysql
from pymysql.cursors import DictCursor
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("MySQL MCP Server")
def get_connection():
return pymysql.connect(
host=os.getenv("MYSQL_HOST", "localhost"),
port=int(os.getenv("MYSQL_PORT", "3306")),
user=os.getenv("MYSQL_USER", "root"),
password=os.getenv("MYSQL_PASSWORD", ""),
database=os.getenv("MYSQL_DATABASE", ""),
charset=os.getenv("MYSQL_CHARSET", "utf8mb4"),
cursorclass=DictCursor,
)
VALID_COLUMN_TYPES = {
"TINYINT", "SMALLINT", "MEDIUMINT", "INT", "INTEGER", "BIGINT",
"FLOAT", "DOUBLE", "DECIMAL", "NUMERIC",
"BIT", "BOOL", "BOOLEAN",
"DATE", "DATETIME", "TIMESTAMP", "TIME", "YEAR",
"CHAR", "VARCHAR", "BINARY", "VARBINARY",
"TINYTEXT", "TEXT", "MEDIUMTEXT", "LONGTEXT",
"TINYBLOB", "BLOB", "MEDIUMBLOB", "LONGBLOB",
"ENUM", "SET",
"JSON", "GEOMETRY", "POINT", "LINESTRING", "POLYGON",
}
def _validate_identifier(name: str) -> str:
if not name or not all(c.isalnum() or c == "_" for c in name):
raise ValueError(f"Invalid identifier: {name}")
return name
def _validate_column_type(col_type: str) -> str:
base_type = col_type.upper().split("(")[0].strip()
if base_type not in VALID_COLUMN_TYPES:
raise ValueError(
f"Invalid column type: {col_type}. "
f"Valid types: {', '.join(sorted(VALID_COLUMN_TYPES))}"
)
return col_type
@mcp.tool()
def list_tables() -> str:
"""列出当前数据库中的所有表名"""
conn = get_connection()
try:
with conn.cursor() as cursor:
cursor.execute("SHOW TABLES")
rows = cursor.fetchall()
table_key = list(rows[0].keys())[0] if rows else None
tables = [row[table_key] for row in rows] if rows else []
if not tables:
return "当前数据库中没有表"
return "数据库中的表:\n" + "\n".join(f" - {t}" for t in tables)
finally:
conn.close()
@mcp.tool()
def query_table_structure(table_name: str) -> str:
"""查询指定表的结构信息,包括字段名、类型、是否为空、键、默认值、额外信息等
Args:
table_name: 要查询的表名
"""
_validate_identifier(table_name)
conn = get_connection()
try:
with conn.cursor() as cursor:
cursor.execute(f"DESCRIBE `{table_name}`")
columns = cursor.fetchall()
cursor.execute(f"SHOW CREATE TABLE `{table_name}`")
create_info = cursor.fetchone()
create_sql = list(create_info.values())[1] if create_info else ""
lines = [f"表 `{table_name}` 的结构:\n"]
lines.append(
f"{'字段名':<20} {'类型':<20} {'允许为空':<10} "
f"{'键':<10} {'默认值':<15} {'额外':<20}"
)
lines.append("-" * 95)
for col in columns:
lines.append(
f"{col['Field']:<20} {col['Type']:<20} {col['Null']:<10} "
f"{col['Key']:<10} {str(col['Default']):<15} {col['Extra']:<20}"
)
lines.append(f"\n建表语句:\n{create_sql}")
return "\n".join(lines)
finally:
conn.close()
@mcp.tool()
def alter_table_add_column(
table_name: str,
column_name: str,
column_type: str,
nullable: bool = True,
default_value: str | None = None,
comment: str | None = None,
after_column: str | None = None,
first: bool = False,
) -> str:
"""向指定表添加新字段
Args:
table_name: 表名
column_name: 新字段名
column_type: 字段类型,如 VARCHAR(255), INT, DECIMAL(10,2) 等
nullable: 是否允许为空,默认为 True
default_value: 默认值,不设置则为 None
comment: 字段注释
after_column: 将新字段添加到指定字段之后
first: 是否将新字段设为第一个字段
"""
_validate_identifier(table_name)
_validate_identifier(column_name)
_validate_column_type(column_type)
if first and after_column:
raise ValueError("不能同时指定 first=True 和 after_column")
parts = [f"ALTER TABLE `{table_name}` ADD COLUMN `{column_name}` {column_type}"]
if not nullable:
parts.append("NOT NULL")
else:
parts.append("NULL")
if default_value is not None:
parts.append(f"DEFAULT '{default_value}'")
if comment:
safe_comment = comment.replace("'", "\\'")
parts.append(f"COMMENT '{safe_comment}'")
if first:
parts.append("FIRST")
elif after_column:
_validate_identifier(after_column)
parts.append(f"AFTER `{after_column}`")
sql = " ".join(parts)
conn = get_connection()
try:
with conn.cursor() as cursor:
cursor.execute(sql)
conn.commit()
return f"成功向表 `{table_name}` 添加字段 `{column_name}` ({column_type})\n执行SQL: {sql}"
except Exception as e:
conn.rollback()
return f"添加字段失败: {str(e)}\nSQL: {sql}"
finally:
conn.close()
@mcp.tool()
def alter_table_modify_column(
table_name: str,
column_name: str,
column_type: str,
nullable: bool = True,
default_value: str | None = None,
comment: str | None = None,
after_column: str | None = None,
first: bool = False,
) -> str:
"""修改指定表中已有字段的属性(类型、是否为空、默认值、注释等),禁止删除字段
Args:
table_name: 表名
column_name: 要修改的字段名(必须是已存在的字段)
column_type: 新的字段类型
nullable: 是否允许为空
default_value: 默认值
comment: 字段注释
after_column: 将字段移动到指定字段之后
first: 是否将字段设为第一个字段
"""
_validate_identifier(table_name)
_validate_identifier(column_name)
_validate_column_type(column_type)
if first and after_column:
raise ValueError("不能同时指定 first=True 和 after_column")
conn = get_connection()
try:
with conn.cursor() as cursor:
cursor.execute(f"DESCRIBE `{table_name}`")
columns = cursor.fetchall()
existing_names = [col["Field"] for col in columns]
if column_name not in existing_names:
return f"错误: 表 `{table_name}` 中不存在字段 `{column_name}`,无法修改。现有字段: {', '.join(existing_names)}"
finally:
conn.close()
parts = [f"ALTER TABLE `{table_name}` MODIFY COLUMN `{column_name}` {column_type}"]
if not nullable:
parts.append("NOT NULL")
else:
parts.append("NULL")
if default_value is not None:
parts.append(f"DEFAULT '{default_value}'")
if comment:
safe_comment = comment.replace("'", "\\'")
parts.append(f"COMMENT '{safe_comment}'")
if first:
parts.append("FIRST")
elif after_column:
_validate_identifier(after_column)
parts.append(f"AFTER `{after_column}`")
sql = " ".join(parts)
conn = get_connection()
try:
with conn.cursor() as cursor:
cursor.execute(sql)
conn.commit()
return f"成功修改表 `{table_name}` 的字段 `{column_name}`\n执行SQL: {sql}"
except Exception as e:
conn.rollback()
return f"修改字段失败: {str(e)}\nSQL: {sql}"
finally:
conn.close()
@mcp.tool()
def create_table(
table_name: str,
columns: str,
primary_key: str | None = None,
engine: str = "InnoDB",
charset: str = "utf8mb4",
comment: str | None = None,
) -> str:
"""创建新表,禁止删除已有表
Args:
table_name: 新表名
columns: 字段定义,每行一个字段,格式为 "字段名 类型 [NOT NULL] [DEFAULT 值] [COMMENT '注释']",多行用分号分隔
例如: "id INT NOT NULL AUTO_INCREMENT;name VARCHAR(100) NOT NULL COMMENT '姓名';age INT DEFAULT 0"
primary_key: 主键字段名,多个字段用逗号分隔
engine: 存储引擎,默认 InnoDB
charset: 字符集,默认 utf8mb4
comment: 表注释
"""
_validate_identifier(table_name)
conn = get_connection()
try:
with conn.cursor() as cursor:
cursor.execute("SHOW TABLES")
rows = cursor.fetchall()
table_key = list(rows[0].keys())[0] if rows else None
existing_tables = [row[table_key] for row in rows] if rows else []
if table_name in existing_tables:
return f"错误: 表 `{table_name}` 已存在,禁止删除已有表。请使用修改表结构的工具来调整。"
finally:
conn.close()
column_defs = []
for col_def in columns.split(";"):
col_def = col_def.strip()
if not col_def:
continue
col_name = col_def.split()[0].strip()
_validate_identifier(col_name)
column_defs.append(col_def)
if not column_defs:
return "错误: 至少需要定义一个字段"
all_parts = list(column_defs)
if primary_key:
pk_fields = []
for pk in primary_key.split(","):
pk = pk.strip()
_validate_identifier(pk)
pk_fields.append(f"`{pk}`")
all_parts.append(f"PRIMARY KEY ({', '.join(pk_fields)})")
table_options = [f"ENGINE={engine}", f"DEFAULT CHARSET={charset}"]
if comment:
safe_comment = comment.replace("'", "\\'")
table_options.append(f"COMMENT='{safe_comment}'")
sql = (
f"CREATE TABLE `{table_name}` (\n"
+ ",\n".join(f" {part}" for part in all_parts)
+ f"\n) {' '.join(table_options)}"
)
conn = get_connection()
try:
with conn.cursor() as cursor:
cursor.execute(sql)
conn.commit()
return f"成功创建表 `{table_name}`\n执行SQL:\n{sql}"
except Exception as e:
conn.rollback()
return f"创建表失败: {str(e)}\nSQL:\n{sql}"
finally:
conn.close()
@mcp.tool()
def generate_insert_sql(
table_name: str,
data: str,
) -> str:
"""生成向指定表插入数据的SQL语句,仅返回SQL不执行,需用户自行执行
Args:
table_name: 表名
data: 要插入的数据,格式为 "字段1=值1;字段2=值2" 或多行数据用换行分隔,每行格式相同
例如: "name=张三;age=25" 表示插入一条记录
多条记录: "name=张三;age=25\\nname=李四;age=30"
"""
_validate_identifier(table_name)
conn = get_connection()
try:
with conn.cursor() as cursor:
cursor.execute(f"DESCRIBE `{table_name}`")
columns = cursor.fetchall()
col_info = {col["Field"]: col for col in columns}
finally:
conn.close()
rows = data.strip().split("\n")
all_sqls = []
for row in rows:
row = row.strip()
if not row:
continue
fields = []
values = []
for pair in row.split(";"):
pair = pair.strip()
if not pair or "=" not in pair:
continue
field, value = pair.split("=", 1)
field = field.strip()
value = value.strip()
_validate_identifier(field)
if field not in col_info:
return f"错误: 表 `{table_name}` 中不存在字段 `{field}`,现有字段: {', '.join(col_info.keys())}"
fields.append(f"`{field}`")
if value.upper() == "NULL":
values.append("NULL")
elif value.upper() in ("NOW()", "CURRENT_TIMESTAMP", "UUID()"):
values.append(value)
else:
col_type = col_info[field]["Type"].upper()
if any(
t in col_type
for t in (
"INT",
"BIGINT",
"TINYINT",
"SMALLINT",
"MEDIUMINT",
"FLOAT",
"DOUBLE",
"DECIMAL",
"NUMERIC",
"BIT",
"BOOL",
"YEAR",
)
):
values.append(value)
else:
escaped = value.replace("'", "\\'")
values.append(f"'{escaped}'")
if not fields:
return "错误: 未提供有效的字段数据"
sql = f"INSERT INTO `{table_name}` ({', '.join(fields)}) VALUES ({', '.join(values)});"
all_sqls.append(sql)
if not all_sqls:
return "错误: 未提供有效的数据"
result = "⚠️ 以下SQL语句未执行,请自行确认后执行:\n\n"
result += "\n".join(all_sqls)
return result
@mcp.tool()
def generate_delete_sql(
table_name: str,
where_clause: str,
) -> str:
"""生成从指定表删除数据的SQL语句,仅返回SQL不执行,需用户自行执行
Args:
table_name: 表名
where_clause: 删除条件,如 "id = 1" 或 "age > 30 AND status = 'inactive'"
"""
_validate_identifier(table_name)
if not where_clause.strip():
return "错误: 必须提供 WHERE 条件,禁止无条件删除数据"
conn = get_connection()
try:
with conn.cursor() as cursor:
cursor.execute("SHOW TABLES")
rows = cursor.fetchall()
table_key = list(rows[0].keys())[0] if rows else None
existing_tables = [row[table_key] for row in rows] if rows else []
if table_name not in existing_tables:
return f"错误: 表 `{table_name}` 不存在"
finally:
conn.close()
sql = f"DELETE FROM `{table_name}` WHERE {where_clause};"
result = "⚠️ 以下SQL语句未执行,请自行确认后执行:\n\n"
result += sql
result += "\n\n⚠️ 删除操作不可逆,请务必确认 WHERE 条件正确后再执行!"
return result
@mcp.tool()
def generate_update_sql(
table_name: str,
data: str,
where_clause: str,
) -> str:
"""生成修改指定表数据的SQL语句,仅返回SQL不执行,需用户自行执行
Args:
table_name: 表名
data: 要修改的数据,格式为 "字段1=值1;字段2=值2"
例如: "name=张三;age=25"
where_clause: 更新条件,如 "id = 1" 或 "status = 'pending' AND created_at < '2024-01-01'"
"""
_validate_identifier(table_name)
if not where_clause.strip():
return "错误: 必须提供 WHERE 条件,禁止无条件更新数据"
conn = get_connection()
try:
with conn.cursor() as cursor:
cursor.execute(f"DESCRIBE `{table_name}`")
columns = cursor.fetchall()
col_info = {col["Field"]: col for col in columns}
finally:
conn.close()
set_parts = []
for pair in data.split(";"):
pair = pair.strip()
if not pair or "=" not in pair:
continue
field, value = pair.split("=", 1)
field = field.strip()
value = value.strip()
_validate_identifier(field)
if field not in col_info:
return f"错误: 表 `{table_name}` 中不存在字段 `{field}`,现有字段: {', '.join(col_info.keys())}"
if value.upper() == "NULL":
set_parts.append(f"`{field}` = NULL")
elif value.upper() in ("NOW()", "CURRENT_TIMESTAMP", "UUID()"):
set_parts.append(f"`{field}` = {value}")
else:
col_type = col_info[field]["Type"].upper()
if any(
t in col_type
for t in (
"INT",
"BIGINT",
"TINYINT",
"SMALLINT",
"MEDIUMINT",
"FLOAT",
"DOUBLE",
"DECIMAL",
"NUMERIC",
"BIT",
"BOOL",
"YEAR",
)
):
set_parts.append(f"`{field}` = {value}")
else:
escaped = value.replace("'", "\\'")
set_parts.append(f"`{field}` = '{escaped}'")
if not set_parts:
return "错误: 未提供有效的字段数据"
sql = f"UPDATE `{table_name}` SET {', '.join(set_parts)} WHERE {where_clause};"
result = "⚠️ 以下SQL语句未执行,请自行确认后执行:\n\n"
result += sql
result += "\n\n⚠️ 更新操作不可逆,请务必确认 WHERE 条件正确后再执行!"
return result
if __name__ == "__main__":
import sys
if len(sys.argv) > 1 and sys.argv[1] == "--sse":
mcp.run(transport="sse")
else:
mcp.run()pythonproject.toml文件内容:
这段代码是 Python 项目的 构建配置文件 ( pyproject.toml ),用于定义项目的元数据和构建方式。这是 Python 社区推荐的现代项目配置方式(PEP 517/518),替代了传统的 setup.py 。有了这个文件,你可以用 pip install -e . 以开发模式安装项目,或用 pip install . 正式安装。
bash
[project]
name = "mysql-mcp"
version = "0.1.0"
description = "A MCP server for MySQL database management"
requires-python = ">=3.10"
dependencies = [
"mcp[cli]>=1.0.0",
"pymysql>=1.1.0",
]
[build-system]
requires = ["hatchling"]
build-backend = "hatchling.build"配置后效果:
trae效果: