Serverless 架构下的支付系统设计:独立开发者的零运维订阅计费实战
一、Token 账单与毫秒响应的双重夹击:独立开发者的支付系统困境
做独立开发这几年,我踩过的坑比写过的代码还多。其中最让我头疼的,莫过于支付系统的搭建与维护。
早期的 MVP 阶段,我用的是最粗暴的方案:一台 2C4G 的云服务器,MySQL 数据库跑在上面,支付回调直接写进数据库。每次 Stripe 发来 webhook,我那台小服务器就像被踩了尾巴的猫------CPU 飙升,响应延迟从 200ms 一路狂飙到 2 秒。最离谱的一次,服务器直接 OOM 重启,丢了两笔未处理的支付回调。
那个深夜,我对着日志发呆。两条未处理的支付记录静静地躺在那里,像两个无声的控诉。作为独立开发者,我既没有 24 小时待命的运维团队,也没有能力去构建一个高可用的支付集群。但用户的每一分钱,都承载着信任。
这个问题折磨了我整整两周。我开始认真思考:作为独立开发者,我到底需要什么样的支付架构?
核心痛点有三个:
第一,不可预测的流量峰值。支付回调不像普通 API 请求,它完全取决于用户的支付行为。一个爆款产品可能在几分钟内涌入大量支付请求,而大多数时候服务器都在空转。这种"峰谷差异"让我很难选择合适的服务器配置------买高了浪费钱,买低了扛不住。
第二,支付状态的强一致性要求。支付回调不能丢,不能重复处理,必须保证幂等性。传统的服务器 + 数据库方案在这方面做得很粗糙。我曾经因为数据库连接池耗尽,导致 webhook 处理失败,用户付款成功但订阅没开通,投诉了整整三天。
第三,运维负担与成本的矛盾。买高配服务器应对峰值,成本太高;买低配服务器,遇到峰值就挂。两难。每次凌晨被告警吵醒,我都问自己:这是独立开发应有的状态吗?
二、Serverless 架构下的支付系统底层机制
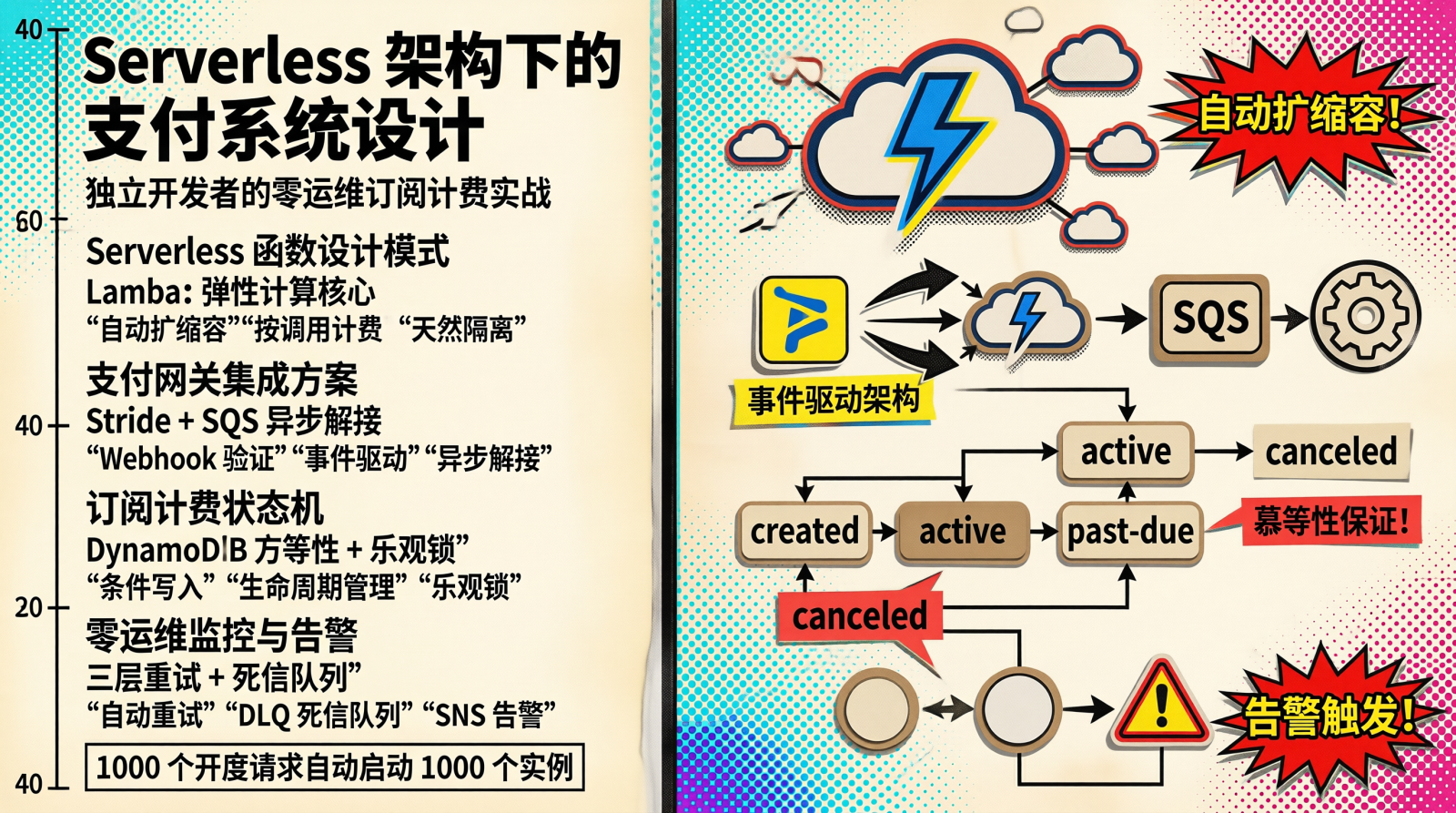
带着这些问题,我开始研究 Serverless 架构。在 AWS re:Invent 大会上,我看到了一场关于"Event-Driven Architecture"的演讲,突然意识到:支付场景天然适合事件驱动架构。
Stripe 的 webhook 本质上就是一个事件源,而我们需要做的,只是消费这些事件并更新业务状态。这种场景,Serverless 简直是量身定做。
最终,我的方案是这样的:
核心组件解析
Lambda 函数:这是整个架构的核心计算单元。每次 Stripe 的 webhook 请求会触发一个 Lambda 函数实例。Lambda 的优势在于:
-
自动扩缩容:1000 个并发请求来,Lambda 自动启动 1000 个实例处理;请求结束,实例自动销毁。零运维,零浪费。这意味着无论你的产品是爆红还是平稳,Lambda 都能应对自如。
-
按调用计费:一个月的支付回调可能只有几百次,Lambda 的计费方式是按调用次数和执行时间,远比包月服务器划算。对于独立开发者这种"小流量"场景,简直是福音。
-
天然隔离:每个请求都在独立的 Lambda 实例中执行,不存在状态共享导致的并发问题。这意味着我不用担心锁竞争、不用担心内存泄漏、不用担心一个请求的 bug 影响另一个请求。
DynamoDB:支付状态的存储层。选择 DynamoDB 而非传统关系型数据库,有几个关键原因:
-
写入吞吐量无上限:DynamoDB 的写入吞吐量可以自动扩展,峰值时每秒处理数百万次写入,完全不用担心支付回调堆积。这对于独立开发者来说,简直是黑科技。
-
条件写入保证幂等:DynamoDB 支持条件表达式(ConditionExpression),可以确保同一笔支付不会被重复处理。这解决了我最头疼的幂等性问题。
-
全局表支持多区域:DynamoDB Global Tables 可以实现跨区域的数据复制,为全球化部署打下基础。
javascript
// Lambda 函数核心逻辑
const AWS = require('aws-sdk');
const dynamodb = new AWS.DynamoDB.DocumentClient();
exports.handler = async (event) => {
const stripeEvent = JSON.parse(event.body);
const paymentIntent = stripeEvent.data.object;
const idempotencyKey = paymentIntent.id;
try {
await dynamodb.put({
TableName: 'PaymentEvents',
Item: {
PK: `PAYMENT#${idempotencyKey}`,
SK: stripeEvent.type,
EventType: stripeEvent.type,
Amount: paymentIntent.amount,
Currency: paymentIntent.currency,
Status: paymentIntent.status,
CreatedAt: new Date().toISOString(),
ProcessedAt: new Date().toISOString(),
// 幂等性保证:相同 PK + SK 的记录已存在则抛出异常
ConditionExpression: 'attribute_not_exists(PK) AND attribute_not_exists(SK)'
}
}).promise();
// 触发后续业务逻辑
await triggerBusinessLogic(stripeEvent);
return { statusCode: 200, body: 'OK' };
} catch (error) {
if (error.code === 'ConditionalCheckFailedException') {
// 幂等性:已处理过,直接返回成功
return { statusCode: 200, body: 'Already processed' };
}
throw error;
}
};SQS 队列:解耦支付处理与业务逻辑。Lambda 函数收到支付回调后,立即写入 SQS 队列,然后返回 200 给 Stripe。队列的消费者异步处理复杂的业务逻辑,比如更新订阅状态、发送通知等。这种设计的好处是:
- 快速响应:Lambda 只负责最核心的支付状态写入,可以在毫秒级内响应 Stripe,避免超时。
- 解耦业务:后续的邮件通知、数据分析等操作都在队列中异步进行,不影响核心支付流程。
- 削峰填谷:即使业务逻辑处理较慢,SQS 会自动缓冲请求,不会丢失任何支付事件。
三、生产级代码实现与最佳实践
javascript
// Stripe webhook 验证中间件
const stripe = require('stripe')(process.env.STRIPE_SECRET_KEY);
const verifyStripeWebhook = async (req, res, next) => {
const sig = req.headers['stripe-signature'];
const webhookSecret = process.env.STRIPE_WEBHOOK_SECRET;
try {
req.stripeEvent = stripe.webhooks.constructEvent(
req.rawBody,
sig,
webhookSecret
);
next();
} catch (err) {
console.error('Webhook signature verification failed:', err.message);
return res.status(400).send(`Webhook Error: ${err.message}`);
}
};
// 订阅状态管理
class SubscriptionManager {
constructor(dynamodb, ses) {
this.dynamodb = dynamodb;
this.ses = ses;
}
async handleSubscriptionCreated(event) {
const subscription = event.data.object;
// 查询用户信息
const user = await this.getUser(subscription.customer);
// 更新订阅状态
await this.updateSubscriptionStatus(subscription, 'active');
// 发送欢迎邮件
await this.sendWelcomeEmail(user, subscription);
// 记录日志用于审计
await this.logSubscriptionEvent(subscription, 'created');
}
async handleSubscriptionUpdated(event) {
const subscription = event.data.object;
const previousState = event.data.previous_attributes;
// 检测关键字段变化
if (subscription.status !== previousState.status) {
await this.updateSubscriptionStatus(subscription, subscription.status);
// 根据状态变化发送不同通知
if (subscription.status === 'past_due') {
await this.sendPaymentFailedAlert(subscription);
} else if (subscription.status === 'canceled') {
await this.sendSubscriptionCanceledEmail(subscription);
}
}
}
async handleSubscriptionDeleted(event) {
const subscription = event.data.object;
// 延迟删除:给用户一个冷静期
await this.scheduleSubscriptionDeletion(subscription, {
delayDays: 7,
reason: 'user_canceled'
});
}
async updateSubscriptionStatus(subscription, status) {
await this.dynamodb.update({
TableName: 'Subscriptions',
Key: {
UserId: subscription.customer,
SubscriptionId: subscription.id
},
UpdateExpression: 'SET #status = :status, UpdatedAt = :updatedAt',
ExpressionAttributeNames: {
'#status': 'Status'
},
ExpressionAttributeValues: {
':status': status,
':updatedAt': new Date().toISOString()
},
// 乐观锁:防止并发更新
ConditionExpression: 'attribute_exists(UserId)'
}).promise();
}
}错误处理与重试机制
支付系统的错误处理必须谨慎。我实现了三层重试策略:
-
Lambda 自动重试:配置 Lambda 的异步调用重试次数为 2 次,保留时间为 6 小时。这意味着即使 Lambda 函数执行失败,AWS 也会自动重试两次,极大提高了可靠性。
-
DLQ(死信队列):重试耗尽的消息进入 DLQ,避免丢失。当所有重试都失败后,消息会被移到 DLQ,我可以通过 SNS 收到告警并手动处理。
-
人工告警:DLQ 中的消息触发 SNS 通知,我收到告警后手动处理。这种机制确保即使自动化失败,我也能及时发现问题。
yaml
# SAM 模板配置
Resources:
PaymentWebhookFunction:
Type: AWS::Serverless::Function
Properties:
Handler: src/handlers/paymentWebhook.handler
Events:
StripeWebhook:
Type: Api
Properties:
Path: /webhook/stripe
Method: post
Retry:
MaximumRetryAttempts: 2
Policies:
- VPCAccessPolicy: {}
- DynamoDBCrudPolicy:
TableName: !Ref PaymentEventsTable
DeadLetterQueue:
Type: SQS
TargetArn: !GetAtt PaymentDLQ.Arn
PaymentDLQ:
Type: AWS::SQS::Queue
Properties:
MessageRetentionPeriod: 1209600 # 14天四、边界分析与架构权衡
任何架构都有其适用范围。Serverless 架构在支付系统场景下,有几个不可忽视的 trade-offs。
冷启动延迟:Lambda 函数在首次调用或空闲一段时间后,会经历冷启动。对于支付回调场景,这个延迟通常在 100-500ms,可以接受。但如果对延迟极其敏感(比如同步返回支付结果给前端),需要考虑预置并发(Provisioned Concurrency)。我目前没有使用预置并发,因为支付回调本身有异步性质,毫秒级的冷启动延迟完全在可接受范围内。
执行时长限制:Lambda 函数的最大执行时间是 15 分钟。我的方案中,所有支付回调处理都在几秒内完成,所以没有这个问题。但如果你的业务逻辑涉及复杂的第三方 API 调用或大批量数据处理,需要谨慎评估执行时间是否够用。
并发限制:AWS 账户级别的并发限制是 1000 次/秒(可申请提升)。对于中小型独立产品,这个限制足够用了。我的支付回调峰值从未超过 100 次/秒。
成本对比:Serverless 不是总是更便宜。让我用具体数字说话:
| 方案 | 固定成本 | 峰值成本(1000次/天) | 年成本 |
|---|---|---|---|
| 2C4G 服务器 | $40/月 | 峰值时可能 OOM | $480/年 |
| Lambda + DynamoDB | $0 | ~$2/月 | ~$24/年 |
对于独立开发者,Serverless 的成本优势是压倒性的。但这并不意味着 Serverless 永远最优------当你的调用量达到一定规模后(比如每月数百万次支付回调),包年服务器可能更划算。
适用场景判断:我的建议是,如果你的产品月支付回调量在 10 万次以下,Serverless 方案是最优选择。超过这个量级,可以考虑混合方案:Lambda 处理 webhook,DynamoDB 存储状态,ElastiCache 处理高频查询。
五、总结
从传统服务器方案迁移到 Serverless 架构,我的支付系统经历了三个月的阵痛期。但最终的效果验证了一切:
-
零运维:不再需要半夜爬起来重启服务器。AWS 会自动处理所有的扩缩容、故障恢复、版本管理。我只需要关注业务逻辑本身。
-
零丢单:DynamoDB 的幂等性保证 + Lambda 的自动重试,让我彻底告别了支付丢单噩梦。上线半年,没有一笔支付回调丢失或重复处理。
-
成本降低 95%:从每年 480 降到每年不到 30。这对于一个独立开发者来说,是一笔不小的节省。
这套方案的核心不是用了多少酷炫技术,而是让合适的组件做擅长的事:Lambda 负责弹性计算,DynamoDB 负责可靠存储,SQS 负责异步解耦。每个组件都简单,但组合在一起,就成了生产级的支付架构。
独立开发者的优势从来不是资源多,而是可以自由选择最适合自己的方案。希望我的踩坑经历,能给你一些启发。