
彻底吃透 C++ unordered_map 与 unordered_set:底层原理、用法、性能全解析
在 C++ 开发中,哈希表容器是处理「快速查找、插入、删除」场景的核心工具,unordered_map 和 unordered_set 就是 C++11 标准引入的基于哈希表实现的关联容器,完美解决了传统有序容器(map/set)在查询效率上的瓶颈。
本文将从底层原理、核心特性、基础用法、高级技巧、性能对比、常见坑点六个维度,带你彻底掌握这两个容器,成为开发中的「哈希表高手」。
一、前置认知:什么是 unordered_map /unordered_set?
官方定义
unordered_map:无序键值对容器,存储key-value结构,key 唯一,通过 key 快速映射到 value,不保证有序。unordered_set:无序唯一元素容器,仅存储独立元素,元素唯一,不存储键值对,不保证有序。核心本质
两者底层完全一致,都是 ** 哈希表(Hash Table)** 实现,区别仅在于:
unordered_set只存「键」,无「值」;unordered_map存「键 - 值」,键值一一对应。与有序容器(map/set)的核心区别
特性 map / set unordered_map / unordered_set 是否有序 有序(自动排序) 无序 底层结构 红黑树 哈希表 查询速度 O (log n) 稳定 O (1) 超快 插入速度 O(log n) O(1) Key 要求 必须支持 < 比较 必须支持哈希、== 内存占用 较低 较高 迭代器 支持双向迭代 支持单向迭代 适用场景 需要有序、范围查询 只需要快速查找
二、底层原理:哈希表是如何工作的?
要真正用好 unordered 容器,必须理解哈希表的核心机制,这也是它高效的根源。
1. 核心流程
- 哈希函数:将容器的 key / 元素,通过哈希函数转换成一个哈希值(整数)。
- 桶定位:用哈希值对「哈希表桶数」取模,得到元素存储的桶索引。
- 存储 / 查找:元素直接放入对应桶中;查找时直接定位桶,无需遍历全容器。
2. 关键概念:桶(Bucket)与 哈希冲突
- 桶:哈希表的底层是一个数组,数组的每个元素就是一个「桶」,桶里存储实际元素。
- 哈希冲突:不同的 key 经过哈希函数计算,得到了相同的桶索引( unavoidable)。
3. 冲突解决:链地址法
C++ 标准规定 unordered 容器使用链地址法解决冲突:每个桶是一个链表,冲突的元素会挂载到同一个桶的链表中。
理想情况:每个桶只有 1 个元素,查询 O (1);
冲突严重:一个桶链表很长,查询退化为 O (n)。
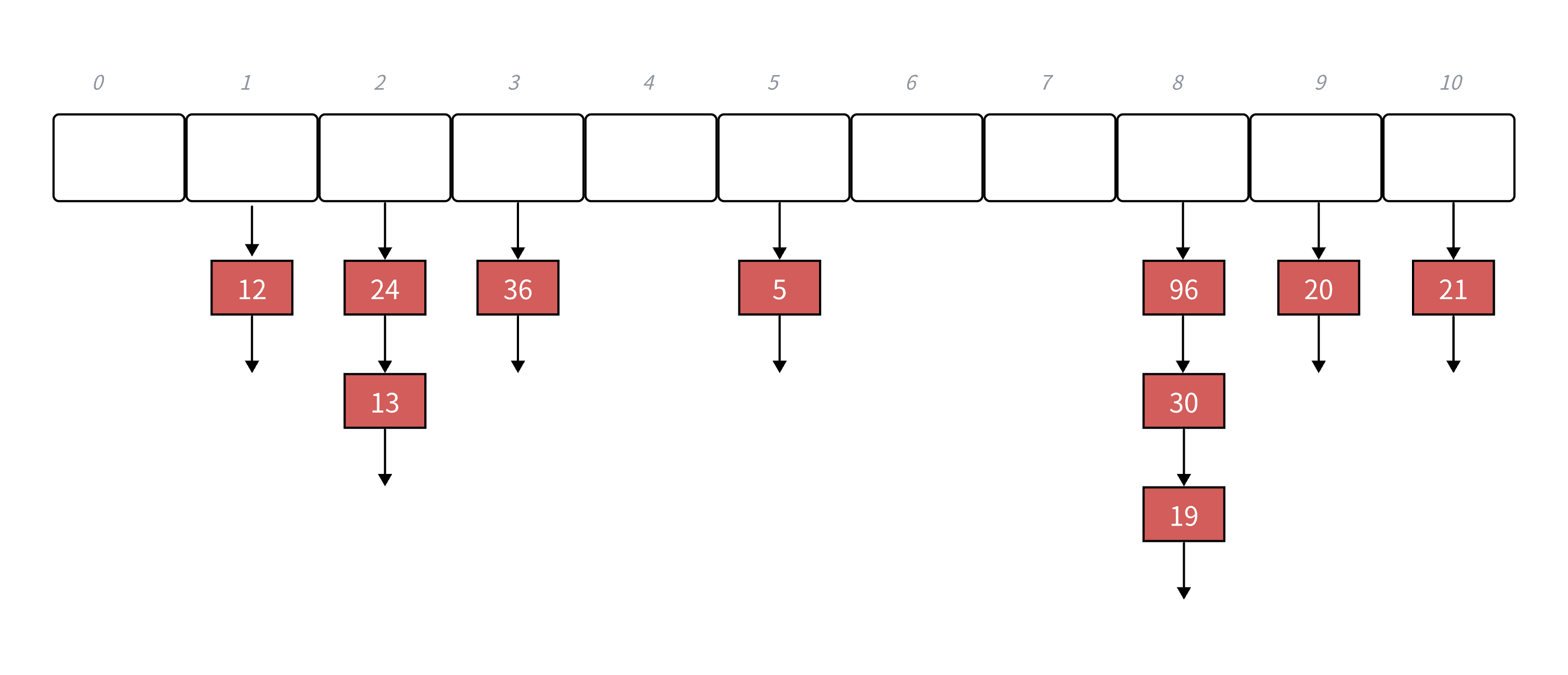
• 下⾯演⽰ {19,30,5,36,13,20,21,12,24,96} 等这⼀组值映射到M=11的表中。
h(19) = 8,h(30) = 8,h(5) = 5,
h(36) = 3,h(13) = 2,h(20) = 9,
h(21) =10,h(12) = 1,h(24) = 2,h(96) = 88
4. 自动扩容
为了避免冲突过多,unordered 容器会自动扩容:
1. 负载因子(元素个数 / 桶数)超过默认阈值(
1.0)时;2. 自动重建哈希表,桶数翻倍,重新计算所有元素的桶索引,减少冲突。
假设哈希表中已经映射存储了N个值,哈希表的⼤⼩为M,那么 ,负载因⼦有些地⽅也翻译为 载荷因⼦/装载因⼦ 等,他的英⽂为load factor。负载因⼦越⼤,哈希冲突的概率越⾼,空间利⽤率越⾼; 负载因⼦越⼩,哈希冲突的概率越低,空间利⽤率越低 ;
四、高级特性:进阶使用技巧
1. 自定义类型作为 key / 元素
默认情况:unordered 容器只支持基础类型(int、string、double 等)作为 key / 元素。如果要使用自定义结构体 / 类,必须满足两个条件:
- 提供哈希函数;
- 提供相等比较函数。
示例:自定义结构体作为 unordered_map 的 key
cpp#include <unordered_map> #include <string> using namespace std; // 自定义结构体 struct Student { int id; string name; // 重载 == 运算符(相等比较) bool operator==(const Student& other) const { return id == other.id && name == other.name; } }; // 自定义哈希函数(核心) struct HashStudent { size_t operator()(const Student& s) const { // 组合哈希值:使用标准哈希函数,避免冲突 return hash<int>()(s.id) ^ hash<string>()(s.name); } }; // 使用自定义哈希+相等比较 unordered_map<Student, int, HashStudent> stu_map;2. 桶与哈希表操作(底层调试)
unordered 提供了直接操作哈希表底层的 API,方便排查性能问题:
cppunordered_map<int, int> umap = {{1,1}, {2,2}, {3,3}}; // 桶数量 cout << "桶数:" << umap.bucket_count() << endl; // 元素所在的桶索引 cout << "key=1 所在桶:" << umap.bucket(1) << endl; // 负载因子 cout << "负载因子:" << umap.load_factor() << endl; // 手动扩容(预留空间,减少自动扩容开销) umap.reserve(100); // 预留至少存储 100 个元素的空间3. 注意:\[\] 运算符的坑(仅 unordered_map)
map[key]如果 key 不存在,会自动插入一个默认值的 key-value,这会导致容器元素增多,慎用!
cppunordered_map<int, int> umap; // 未找到 key=10,自动插入 {10, 0} cout << umap[10] << endl; // 容器大小变为 1,而非 0解决方案:查找时永远用
find()或count(),不要用[]判断存在。
五、哈希算法函数:
| 算法分类 | 算法名称 | 核心原理 | 核心适用场景 | 核心优点 | 核心缺点 | 平均时间复杂度 |
|---|---|---|---|---|---|---|
| 哈希函数类(key→数组下标核心映射) | 除留余数法(除法散列法) | 用 key 对哈希表容量 m 取模,index = key % m,m 优先选质数 |
通用动态哈希表,C++ unordered_map、Python dict、Java HashMap 默认实现 |
实现极简、计算速度极快、质数容量下分布均匀、全语言通用 | 仅原生支持整数 key,非整数类型需先转哈希值;合数容量冲突率飙升 | O(1) |
| 直接定址法 | 直接用 key 本身或 key 的线性函数作为下标,index = a*key + b |
key 取值范围连续且已知的场景,如学号、身份证号、固定区间枚举值 | 完全无哈希冲突、查找绝对稳定 O (1)、无额外计算开销 | key 范围大时空间浪费严重,无法处理离散无规律 key | O(1) | |
| 数字分析法 | 分析 key 的每一位数字特征,选取分布均匀的几位组合成最终下标 | key 位数固定且有规律的场景,如手机号、车牌号、设备 SN 码 | 针对性强、冲突率极低、充分利用 key 的有效信息 | 需提前分析 key 的分布规律,通用性差,无法适配无规律 key | O(1) | |
| 平方取中法 | 先计算 key 的平方值,取平方结果的中间几位作为哈希下标 | key 的每一位分布不均匀,平方后中间位随机性更强的场景 | 随机性好、key 的所有位都能影响结果、分布均匀度高 | 计算量比取模法大,不适合超大数值 key,平方后有溢出风险 | O(1) | |
| 折叠法 | 将长 key 分割成位数相同的几段,叠加求和后取模作为下标 | key 位数极长的场景,如银行卡号、IP 地址、长数字序列号 | 能充分利用 key 的所有位信息,长 key 下分布均匀度远超取模法 | 实现稍复杂,计算量略大,分割规则需提前设计 | O(1) | |
| 随机数法 | 用 key 作为随机数种子,生成固定范围的随机数作为哈希下标 | key 分布完全无规律、对冲突率要求极低的通用场景 | 随机性极强、冲突率极低、适配所有类型 key | 随机数生成有固定计算开销,不同语言随机函数实现差异大 | O(1) | |
| 冲突解决类(哈希冲突核心处理方案) | 链地址法(拉链法) | 每个哈希桶挂载一条单向链表,冲突的 key 追加到对应链表尾部;查找先定位桶,再遍历链表匹配 key | 通用动态哈希表,C++ unordered_map、Python dict、JDK1.8 前 Java HashMap |
实现简单、删除操作无坑、负载因子容忍度高、无数据聚集现象 | 链表过长会导致查找效率退化,有链表指针的额外内存开销 | 平均 O (1)最坏 O (n) |
| 线性探测法(开放寻址) | 哈希冲突后,从当前位置依次向后寻找空桶,找到后存放数据;查找时按相同规则遍历 | 内存连续要求高、无额外指针开销的场景,如嵌入式开发、数据库底层索引 | 内存完全连续、无链表开销、CPU 缓存友好、遍历速度快 | 极易出现数据聚集现象,负载因子升高后冲突率急剧上升,删除操作复杂(需占位标记) | 平均 O (1)最坏 O (n) | |
| 二次探测法(开放寻址) | 哈希冲突后,按pos±1²、pos±2²、pos±3²...的跳跃式规则寻找空桶 |
缓解线性探测的聚集问题,通用开放寻址哈希表场景 | 大幅缓解数据聚集、冲突率远低于线性探测、依然保持缓存友好 | 探测步长增长快,容易跳过空桶,删除操作依然复杂,最坏情况无法找到空桶 | 平均 O (1)最坏 O (n) | |
| 双重哈希法(开放寻址) | 设计两个无关联的哈希函数,冲突后用第二个哈希函数计算探测步长,pos = (hash1(key) + i*hash2(key)) % m |
对冲突率要求极高的场景,如加密存储、高性能缓存、路由表 | 聚集现象几乎为 0、冲突率最低、探测路径完全随机、长期性能稳定 | 需要设计两个无关联的高质量哈希函数,实现复杂,计算量略大 | 平均 O (1)最坏 O (n) | |
| 再哈希法 | 哈希冲突后,更换另一个哈希函数重新计算下标,直到找到空桶为止 | 哈希函数可灵活更换的自定义哈希表场景,教学演示、轻量工具 | 冲突率低、无数据聚集、实现逻辑简单易懂 | 需要提前准备多个哈希函数,最坏情况所有哈希函数都冲突,无法处理极端场景 | 平均 O (1)最坏 O (n) | |
| 公共溢出区法 | 建立基础表 + 溢出表两张表,无冲突的 key 存入基础表,所有冲突的 key 统一放入溢出表 | 冲突率极低、数据量固定的静态哈希表场景,如常量映射、关键字匹配 | 基础表完全无冲突、查找速度极快、实现逻辑简单 | 溢出表需要额外内存空间,大量冲突时溢出表查找会退化到 O (n) | 平均 O (1)最坏 O (n) | |
| 扩容与重哈希类(维持哈希表高效的核心机制) | 常规翻倍扩容 | 负载因子超过阈值时,将哈希表容量直接翻倍,遍历所有元素重新哈希到新表中 | 通用动态哈希表,C++ unordered_map、Python dict 默认扩容策略 |
实现极简、扩容后容量充足、冲突率大幅下降、适配绝大多数场景 | 扩容瞬间需要遍历全量元素,有明显性能抖动,空间翻倍可能造成内存浪费 | 日常操作 O (1)扩容 O (n) |
| 质数扩容法 | 负载因子超标时,将容量更换为下一个更大的质数,再重新哈希所有元素 | 对哈希分布均匀性要求极高的场景,如高性能缓存、数据库底层、高频交易系统 | 质数容量大幅降低取模冲突、数据分布更均匀、长期运行性能更稳定 | 需要提前维护质数表,扩容步长不固定,实现逻辑比翻倍扩容稍复杂 | 日常操作 O (1)扩容 O (n) | |
| 渐进式重哈希(增量扩容) | 扩容时不一次性迁移全量元素,而是在每次增删查操作时,同步迁移部分元素,分批次完成扩容 | 对性能抖动要求极低的高并发场景,如 Redis、分布式缓存、在线服务核心组件 | 无扩容瞬间性能抖动、接口响应时间完全稳定、高并发场景友好 | 实现逻辑复杂,需要同时维护新旧两个哈希表,内存占用会短暂翻倍 | 日常操作 O (1)扩容开销分摊到每次操作 | |
| 收缩扩容(缩容) | 当元素数量减少到预设阈值时,将哈希表容量缩小,释放多余内存 | 内存敏感、数据量波动大的场景,如嵌入式设备、移动端应用、轻量工具 | 大幅节省内存、避免空间浪费、适配数据量的动态收缩 | 缩容需要重新哈希全量元素,有固定性能开销,频繁增删会导致反复扩容缩容 | 日常操作 O (1)缩容 O (n) | |
| 进阶优化类(工业级高性能哈希表核心优化) | 红黑树优化拉链法 | 当链表长度超过预设阈值(Java HashMap 为 8)时,自动将链表转为红黑树,把查找时间从 O (n) 降到 O (logn) | 高冲突场景、大数据量哈希表,JDK1.8+ Java HashMap 核心优化 |
彻底解决链表过长导致的性能退化问题,高冲突场景下性能依然稳定 | 红黑树实现逻辑复杂,插入删除有节点旋转开销,小数据量下效率不如链表 | 平均 O (1)最坏 O (logn) |
| 布谷鸟哈希 | 用两个独立的哈希函数,每个 key 有两个可选存储位置;冲突时把已有的 key "踢" 到它的另一个可选位置,循环直到所有 key 都有合法位置 | 对查找速度要求极高的场景,如高性能路由表、网络转发、高频缓存查询 | 查找操作绝对 O (1)、无链表额外开销、内存利用率极高 | 插入操作最坏情况 O (n),实现逻辑复杂,极端场景会出现循环踢除无法插入 | 查找 O (1)插入平均 O (1) | |
| 完美哈希 | 针对固定不变的 key 集合,专门设计无冲突的哈希函数,实现绝对 O (1) 的查找性能 | 静态 key 集合场景,如编程语言关键字匹配、固定路由表、常量映射表 | 完全无哈希冲突、查找性能拉满、无额外分支判断 | 仅适用于固定不变的 key 集合,key 新增 / 删除需要重新设计哈希函数,构建成本高 | 查找 O (1)构建 O (n) | |
| 一致性哈希 | 将哈希空间组织成一个环形结构,节点和 key 都映射到环上,key 顺时针寻找最近的节点完成映射 | 分布式系统、负载均衡、缓存集群,如 Redis Cluster、Nginx 负载均衡 | 节点增减时仅影响少量 key,无大规模数据迁移,分布式场景友好 | 实现逻辑复杂,需要通过虚拟节点解决数据倾斜问题,查找复杂度 O (logn) | 查找 O (logn)插入 / 删除 O (logn) |
C++ 哈希表(开放定址法 + 线性探测)
一、整体设计概览
模块 职责 Status标记槽位状态 HashData哈希节点 HashFunc哈希函数(支持特化) HashTable哈希表主体
二、核心代码实现
1️⃣ 状态枚举(解决"假空"问题)
enum Status { EXIST, EMPTY, DELETE };✅为什么需要 DELETE?
开放定址法中,删除元素不能直接置空,否则会破坏查找链。
2️⃣ 哈希节点结构
template<class K, class V> struct HashData { pair<K, V> _kv; Status _status = EMPTY; };
3️⃣ 哈希函数(支持 string 特化)
通用版本
template<class K> struct HashFunc { size_t operator()(const K& key) { return (size_t)key; } };string 特化(BKDR Hash)
cpptemplate<> struct HashFunc<string> { size_t operator()(const string& str) { size_t hash = 0; for (auto ch : str) { hash += ch; hash *= 131; // 减少 abab / abba 冲突 } return hash; } };
4️⃣ 素数表扩容(STL 风格)
cppinline unsigned long __stl_next_prime(unsigned long n) { static const int __stl_num_primes = 28; static const unsigned long __stl_prime_list[__stl_num_primes] = { 53, 97, 193, 389, 769, 1543, 3079, 6151, 12289, 24593, 49157, 98317, 196613, 393241, 786433, 1572869, 3145739, 6291469, 12582917, 25165843, 50331653, 100663319, 201326611, 402653189, 805306457, 1610612741, 3221225473, 4294967291 }; const unsigned long* pos = lower_bound(__stl_prime_list, __stl_prime_list + __stl_num_primes, n); return pos == __stl_prime_list + __stl_num_primes ? *(pos - 1) : *pos; }📌**为什么用素数?**
👉减少取模后的哈希冲突。
5️⃣ 哈希表主体
cpptemplate<class K, class V, class Hash = HashFunc<K>> class HashTable { public: HashTable() : _tables(__stl_next_prime(1)) , _n(0) {}
6️⃣ Insert(重点)
cppbool Insert(const pair<K, V>& kv) { if (Find(kv.first)) return false; // 负载因子 ≥ 0.7 扩容 if ((double)_n / _tables.size() >= 0.7) { HashTable<K, V, Hash> newHT; newHT._tables.resize(__stl_next_prime(_tables.size() + 1)); for (auto& data : _tables) { if (data._status == EXIST) newHT.Insert(data._kv); } _tables.swap(newHT._tables); } Hash hs; size_t hash0 = hs(kv.first) % _tables.size(); //size () = 真正有多少个桶 ✅ //capacity () = 预留了多少空间 ❌ size_t hashi = hash0; size_t i = 1; while (_tables[hashi]._status == EXIST) { hashi = (hash0 + i) % _tables.size(); ++i; } _tables[hashi]._kv = kv; _tables[hashi]._status = EXIST; ++_n; return true; }📌扩容必须重新哈希,不能直接拷贝
7️⃣ Find(线性探测)
HashData<K, V>* Find(const K& key) { Hash hs; size_t hash0 = hs(key) % _tables.size(); size_t hashi = hash0; size_t i = 1; while (_tables[hashi]._status != EMPTY) { if (_tables[hashi]._status == EXIST && _tables[hashi]._kv.first == key) return &_tables[hashi]; hashi = (hash0 + i) % _tables.size(); ++i; } return nullptr; }
8️⃣ Erase(惰性删除)
bool Erase(const K& key) { auto* ptr = Find(key); if (ptr) { ptr->_status = DELETE; --_n; return true; } return false; }
三、关键成员变量
cppprivate: std::vector<HashData<K, V>> _tables; size_t _n = 0;//有效数据个数
四、面试高频问答 ✅
问题 一句话答案 为什么 DELETE 不能置空? 会切断探测链 负载因子为什么 ≤ 0.7? 防止探测过长 开放定址法缺点? 冲突堆积 string 哈希怎么写? BKDR / 特化
五、 完整代码
cppusing namespace std; enum Status { EXIST, EMPTY, DELETE }; template<class K, class V> struct HashData { pair<K, V> _kv; Status _status = EMPTY; }; template<class K> struct HashFunc { size_t operator()(const K& key) { return (size_t)key; } }; //特化,string转int template<> struct HashFunc<string> { // BKDR size_t operator()(const string& str) { size_t hash = 0; for (auto ch : str) { hash += ch; hash *= 131;//减少冲突,例如abab和abba } return hash; } }; template<class K, class V, class Hash = HashFunc<K>> class HashTable { public: HashTable() :_tables(__stl_next_prime(1)) , _n(0) { } inline unsigned long __stl_next_prime(unsigned long n) { // Note: assumes long is at least 32 bits. static const int __stl_num_primes = 28; static const unsigned long __stl_prime_list[__stl_num_primes] = { 53, 97, 193, 389, 769, 1543, 3079, 6151, 12289, 24593, 49157, 98317, 196613, 393241, 786433, 1572869, 3145739, 6291469, 12582917, 25165843, 50331653, 100663319, 201326611, 402653189, 805306457, 1610612741, 3221225473, 4294967291 }; const unsigned long* first = __stl_prime_list; const unsigned long* last = __stl_prime_list + __stl_num_primes; const unsigned long* pos = lower_bound(first, last, n); return pos == last ? *(last - 1) : *pos; } bool Insert(const pair<K, V>& kv) { if (Find(kv.first)) return false; // 负载因子 >= 0.7 就扩容 if ((double)_n / _tables.size() >= 0.7) { HashTable<K, V, Hash> newHT; newHT._tables.resize(__stl_next_prime(_tables.size() + 1)); // 遍历旧表将所有值映射到新表 for (auto& data : _tables) { if (data._status == EXIST) { newHT.Insert(data._kv); } } _tables.swap(newHT._tables); _n = newHT._n; // 必须同步更新元素数量 } Hash hs; size_t hash0 = hs(kv.first) % _tables.size();//初始位置 size_t hashi = hash0; size_t i = 1; // 线性探测 while (_tables[hashi]._status == EXIST) { hashi = (hash0 + i) % _tables.size(); ++i; } _tables[hashi]._kv = kv; _tables[hashi]._status = EXIST; ++_n; return true; } HashData<K, V>* Find(const K& key) { Hash hs; size_t hash0 = hs(key) % _tables.size(); size_t hashi = hash0; size_t i = 1; // 线性探测 while (_tables[hashi]._status != EMPTY) { if (_tables[hashi]._status == EXIST && _tables[hashi]._kv.first == key) return &_tables[hashi]; hashi = (hash0 + i) % _tables.size(); ++i; } return nullptr; } bool Erase(const K& key) { auto* ptr = Find(key); if (ptr) { ptr->_status = DELETE; --_n; return true; } else { return false; } } private: std::vector<HashData<K, V>> _tables; size_t _n = 0; // 有效数据个数 };
