国标参考文献格式
McDERMOTT J H, SCHULTZ A F, UNDURRAGA E A, et al. Indifference to dissonance in native Amazonians reveals cultural variation in music perceptionJ. Nature, 2016, 535(7613): 547-550.
正文逐字逐句翻译
信函
doi:10.1038/nature18635
亚马逊原住民对不协和音无偏好,揭示音乐感知存在文化差异
乔希·H·麦克德莫特¹、艾伦·F·舒尔茨²、爱德华多·A·温杜拉加³⁴、里卡多·A·戈多伊³
音乐存在于所有人类文明之中,但音乐在多大程度上由生物属性塑造,学界至今仍存争议。其中广受探讨的一种现象是:部分音高组合在西方人听来悦耳,即协和音;其余组合则令人不适,即不协和音⁽¹⁾。协和与不协和的对立是西方音乐的核心构成,自古希腊时期开始,其起源问题便吸引着历代学者展开研究⁽²⁻¹⁰⁾。科学界普遍认为,人类对协和音的审美偏好根植于生物本能⁽¹¹⁻¹⁴⁾,因此是全人类共通的先天特质⁽¹⁵⁾⁽¹⁶⁾。与之相反,民族音乐学者⁽¹⁷⁾与作曲家⁽⁸⁾提出观点:协和审美是西方音乐文化的产物⁽⁶⁾。该议题长期悬而未决,部分原因在于:针对不同文明群体的协和偏好跨文化对比研究数据十分匮乏⁽¹⁸⁾。本文针对提斯曼人------一处极少接触西方文明的亚马逊原住民族群开展对照实验,同时选取玻利维亚与美国不同西方音乐接触程度的受试群体作为参照。实验要求受试者对各类声响的悦耳程度打分。结果显示,提斯曼人虽具备和西方人相近的声音分辨能力,对熟悉声响、声学粗糙感的审美取向也与西方人类似,但他们对协和和弦、不协和和弦与人声和声给出的愉悦评分没有显著区别。与之相比,玻利维亚城镇居民明显偏爱协和音,只是偏好强度低于美国受试者。上述结论证明:在完全隔绝西方音乐熏陶的文明中,人类不存在协和音偏好;该审美倾向并非人类先天自带的本能,也不是源于人类日常聆听自然界泛音的生理结果。群体间的偏好差异大概率由后天接触的和声音乐环境决定,说明文化在塑造人类音乐审美中占据主导地位。
本研究设计两组实验,受试人群按西方音乐接触程度划分。实验一:招募美国本土受试者,另设三组玻利维亚受试:(1)首都拉巴斯市区居民;(2)圣博尔哈乡镇居民;(3)亚马逊雨林偏远村落圣玛丽亚的刀耕狩猎原住民提斯曼人。玻利维亚城市与乡镇居民通用西班牙语,家中普遍配备电视、收音机;提斯曼人大多仅使用本民族母语,村落无电力、自来水设施,不通公路,仅能搭乘独木舟抵达,几乎没有收音机接触外源音乐的渠道⁽¹⁹⁾,他们和西方文明的接触仅限于偶尔前往周边集镇。为区分西方人群内部个体差异与跨文化差异,美国受试拆分为两组:乐器演奏经验≥2年的音乐人、乐器演奏经验≤1年的普通民众。
提斯曼人是本研究的核心受试对象:现有录音资料与田野调研证实,提斯曼本土音乐不存在和声、复调以及多人同台合奏的形式⁽²⁰⁾(提斯曼本土音乐介绍详见实验方法,本土民歌音频范例见补充音频1、2)。本土音乐完全无和声的特点,引出关键研究问题:在从未接触过和声结构的前提下,该族群是否会天然区分协和、不协和音并产生对应的审美好恶。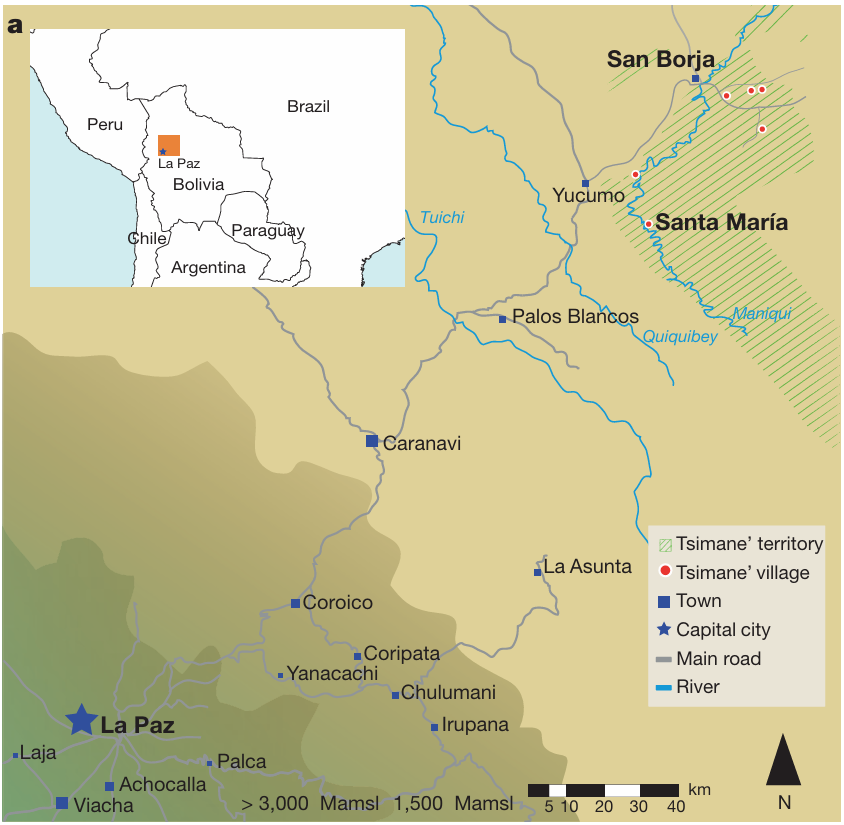

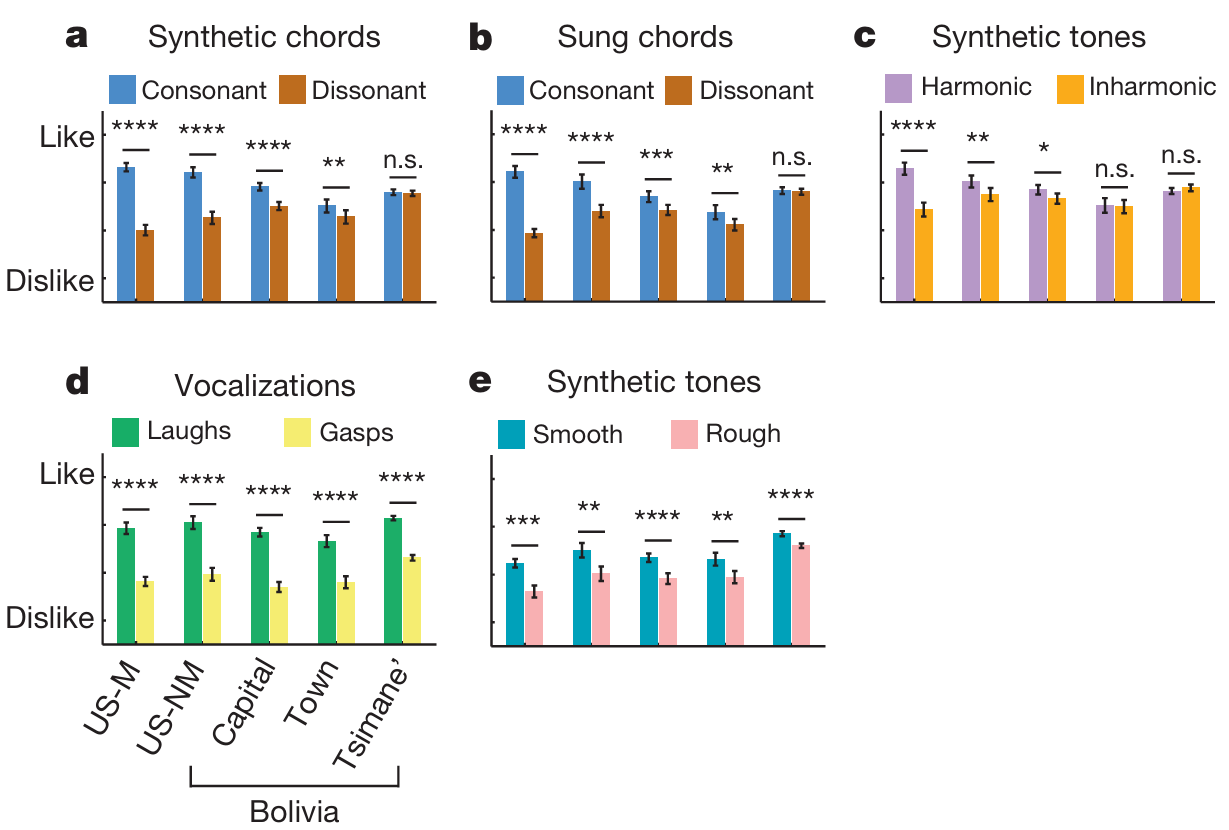

受试者佩戴耳机聆听音频(对应图1b配图说明翻译:受试者通过笔记本电脑搭配封闭式耳机收听声音,设备缺电时使用汽油发电机供电;除分辨能力测试实验(图4)以外,所有实验中受试者听完单段音频后使用四分制量表对悦耳度打分),采用四分制量表评价声音悦耳程度。各组受试对协和、不协和和弦的评分呈现巨大群体差异(对应图2a、b配图说明翻译:实验一五项听觉实验,受试共五组:23名美国音乐人(US-M)、25名美国非音乐人(US-NM)、24名玻利维亚首都居民、26名玻利维亚乡镇居民、64名提斯曼人;每组实验包含两类西方人悦耳度评价差异显著的声响;和弦分为合成器模拟钢琴音色和弦、专业歌手真人演唱和弦;传统分类里大三度、纯四度、纯五度、大三和弦为协和和弦,小二度、大二度、三全音、大七度、增三和弦为不协和和弦;人声素材为人类笑声与喘息声;合成音频分为谐波属性差异组、粗糙感差异组;显著性标记:P<0.05P<0.05P<0.05;P<0.01P<0.01P<0.01; P<0.001P<0.001P<0.001;****P<0.0001P<0.0001P<0.0001;n.s.代表无统计学显著差异,双尾t检验,未做多重比较校正;数据为均值±标准误,显著性事后检验基于方差分析结果)。和过往研究结论一致,美国人表现出强烈的协和偏好,且音乐人偏好程度显著高于普通民众(合成和弦:F(46,1)=7.44F(46,1)=7.44F(46,1)=7.44,P=0.009P=0.009P=0.009;真人演唱和弦:F(46,1)=12.97F(46,1)=12.97F(46,1)=12.97,P=0.001P=0.001P=0.001)。玻利维亚城乡居民同样存在统计学显著的协和偏好,但偏好幅度更低(全部组别P<0.01P<0.01P<0.01,t检验)。唯独提斯曼人对协和和弦与不协和和弦的愉悦打分持平;无论和弦是电子合成音色还是真人演唱录制,该结论均成立,两种素材下组别与和弦类型均存在交互效应(合成音:F(124,4)=48.43F(124,4)=48.43F(124,4)=48.43,P<10−23P<10^{-23}P<10−23;真人演唱:F(126,4)=26.79F(126,4)=26.79F(126,4)=26.79,P<10−15P<10^{-15}P<10−15)。提斯曼人对不同和弦的评分虽略有浮动(合成和弦:F(9,270)=1.96F(9,270)=1.96F(9,270)=1.96,P=0.04P=0.04P=0.04;演唱和弦:F(9,288)=1.93F(9,288)=1.93F(9,288)=1.93,P=0.05P=0.05P=0.05),整体呈现偏好宽音程、排斥窄音程的倾向(拓展数据图1),但不会按照协和/不协和属性稳定区分和弦优劣。
更换实验素材,采用两类单音:一类频率呈整数倍谐波关系,另一类频率非谐波(学界普遍认为该属性是区分协和、不协和和弦的核心指标⁽⁴⁾⁽¹²⁾⁽¹³⁾⁽²¹⁾⁽²²⁾,对应图2c),实验结果和和弦测试结论保持一致:美国人偏爱谐波单音,音乐人偏好显著强于普通受试(F(46,2)=16.12F(46,2)=16.12F(46,2)=16.12,P=0.0002P=0.0002P=0.0002);玻利维亚城市居民的谐波偏好大幅减弱,乡镇居民与提斯曼人完全不存在该偏好,刺激类型与受试组别交互作用显著(F(157,4)=22.49F(157,4)=22.49F(157,4)=22.49,P<10−13P<10^{-13}P<10−13)。
为排除受试不理解实验指令、不会进行悦耳度评分的干扰变量,增设人类情绪化发声评分实验(对应图2d):全部受试群体均认为笑声比喘息声更好听(F(157,1)=200.48F(157,1)=200.48F(157,1)=200.48,P<1×10−29P<1×10^{-29}P<1×10−29),组别和刺激无交互效应(F(157,4)=1.09F(157,4)=1.09F(157,4)=1.09,P=0.36P=0.36P=0.36)。由此可见,面对具备固定正负情绪属性的熟悉声响时,提斯曼人的审美取舍和其余族群完全一致。
为验证提斯曼人是否对所有陌生声响都无法形成审美偏好,继续测试另一影响西方听众审美的声学属性------声音粗糙度(对应图2e):通过双耳同放、双耳分放两组播放方式调控双音频率差,生成顺滑音色与粗糙音色。和弦、谐波实验结论相反,全部受试群体统一偏好顺滑音色、排斥粗糙音色,组间无交互差异(F(157,1)=85.51F(157,1)=85.51F(157,1)=85.51,P<10−15P<10^{-15}P<10−15;交互项F(157,4)=2.04F(157,4)=2.04F(157,4)=2.04,P=0.09P=0.09P=0.09),即便美国受试在此项实验中的偏好差值是全部测试项目里最低的。
实验二 更换一批提斯曼受试者与美国专业音乐人重复并拓展上述实验。第一项拓展实验:使用提斯曼本土民歌实录素材,对原旋律做移调叠加处理,分别生成传统意义上协和、不协和的人声和声(范例音频见补充音频3~10),让美国、提斯曼受试者打分;同时补充真人演唱音程、合成双音程、真人三和弦三组平行对照实验用于结果重复验证。
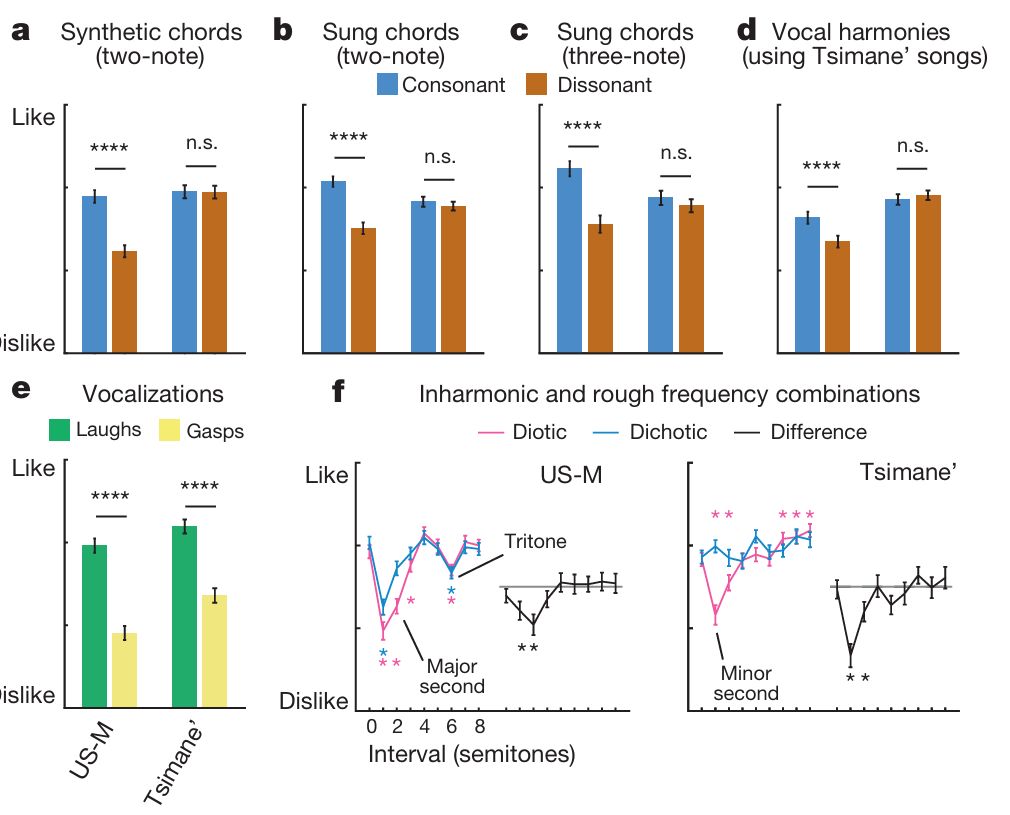

和弦相关实验数据复刻实验一结论(对应图3a~c配图说明翻译:实验二偏好测试均值,受试为47名美国音乐人、50名提斯曼人;双音和弦采用十二平均律音程,三和弦选用大三和弦、增三和弦;人声和声由提斯曼歌手原曲移调叠加生成;e图为人声笑、喘息音评分;显著性*P<0.05P<0.05P<0.05、**P<0.01P<0.01P<0.01、***P<0.001P<0.001P<0.001、****P<0.0001P<0.0001P<0.0001,双尾t检验;f图纯音音程分双耳同播、双耳分播两种呈现模式,蓝粉星代表和纯一度评分存在显著差异(P<0.05P<0.05P<0.05,威尔科克森符号秩检验),黑色曲线为分播减同播的评分差值,黑星代表差值显著偏离0;数据为均值±标准误):美国人稳定偏好协和音,提斯曼人无区分偏好,刺激类型与受试组别交互显著(合成音程:F(72,1)=42.4F(72,1)=42.4F(72,1)=42.4,P<10−8P<10^{-8}P<10−8;演唱音程:F(95,1)=39.4F(95,1)=39.4F(95,1)=39.4,P<10−7P<10^{-7}P<10−7;演唱三和弦:F(95,1)=17.9F(95,1)=17.9F(95,1)=17.9,P<10−4P<10^{-4}P<10−4)。提斯曼人对单组和弦的评分仍随音程跨度变化(拓展数据图2),评分高低和音程大小高度正相关(提斯曼组:合成素材相关系数r=0.94r=0.94r=0.94,P<10−5P<10^{-5}P<10−5;演唱素材r=0.81r=0.81r=0.81,P=0.001P=0.001P=0.001);美国人评分不受音程跨度影响(合成r=0.07r=0.07r=0.07,P=0.82P=0.82P=0.82;演唱r=0.23r=0.23r=0.23,P=0.48P=0.48P=0.48)。
即便依托提斯曼本土民歌改编和声(对应图3d),结果规律不变:美国受试即便完全不熟悉原曲,依旧判定协和改编版本更好听(t(46)=6.2t(46)=6.2t(46)=6.2,P<10−6P<10^{-6}P<10−6);提斯曼人对协和、不协和改编版本评分无差别(t(49)=1.2t(49)=1.2t(49)=1.2,P=0.22P=0.22P=0.22),刺激与组别交互F(95,1)=30.2F(95,1)=30.2F(95,1)=30.2,P<10−6P<10^{-6}P<10−6。提斯曼受试者能区分不同原曲片段的悦耳度差异(χ2(25)=49.01\chi^{2}(25)=49.01χ2(25)=49.01,P=0.003P=0.003P=0.003,拓展数据图3),说明他们可以对音乐形成稳定审美,只是审美标准不以协和/不协和作为评判依据。人声情绪发声复测(对应图3e)再次验证:提斯曼与美国人全都偏爱笑声、厌恶喘息声(F(95,1)=129.4F(95,1)=129.4F(95,1)=129.4,P<10−18P<10^{-18}P<10−18,组别交互F(95,1)=1.8F(95,1)=1.8F(95,1)=1.8,P=0.18P=0.18P=0.18),提斯曼完全具备完成评分任务的能力。以上结果再次证实:提斯曼族群不存在与生俱来的协和音审美偏好。
基于实验一粗糙度、谐波实验结论,增设半音跨度0~8个半音的纯双音测试(对应图3f):该音程区间既包含频率呈简单整数比的协和音程,也包含非整数比的不协和音程;采用两种播放范式:双耳同步接收双音(同耳播放,易因频率差产生拍频粗糙感)、两音分置左右耳(分耳播放,消除拍频但保留音程比例关系),以此剥离声学粗糙度与频率谐波关系两个变量。
美国人在同播、分播两种播放条件下,均在小二度、大二度、三全音等不协和音程处出现评分低谷。分耳播放时音程评分仍随音程变化(χ2(7)=62.7\chi^{2}(7)=62.7χ2(7)=62.7,P<10−10P<10^{-10}P<10−10),证明除粗糙度外,谐波比例本身也会影响西方人的审美;音程小于3个半音时,同耳播放评分低于分耳播放,分播-同播差值随音程显著改变(χ2(7)=20.6\chi^{2}(7)=20.6χ2(7)=20.6,P=0.004P=0.004P=0.004;仅1、2半音差值显著P<0.05P<0.05P<0.05),该现象是人类反感声学粗糙感的典型特征(窄音程下耳蜗滤波引发声波拍频震颤)⁽⁵⁾⁽⁷⁾⁽²¹⁾。
提斯曼受试同样反感粗糙音色:仅窄音程(1、2半音)出现同耳评分低于分耳的规律,分播同播差值显著变化(χ2(7)=29.25\chi^{2}(7)=29.25χ2(7)=29.25,P=0.0001P=0.0001P=0.0001;仅1、2半音P<0.05P<0.05P<0.05);但他们的评分不受频率谐波关系影响,分耳播放全音程评分无统计学波动(χ2(7)=9.52\chi^{2}(7)=9.52χ2(7)=9.52,P=0.22P=0.22P=0.22),三全音位置也没有出现西方人特有的低分凹陷。由此证明:反感声音粗糙是跨文化共通的生理偏好,但偏爱频率简单整数比的协和审美不存在普适性;西方语境的不协和概念,和声学不和谐高度绑定,和声学粗糙感分属两套感知体系⁽²¹⁾⁽²²⁾。
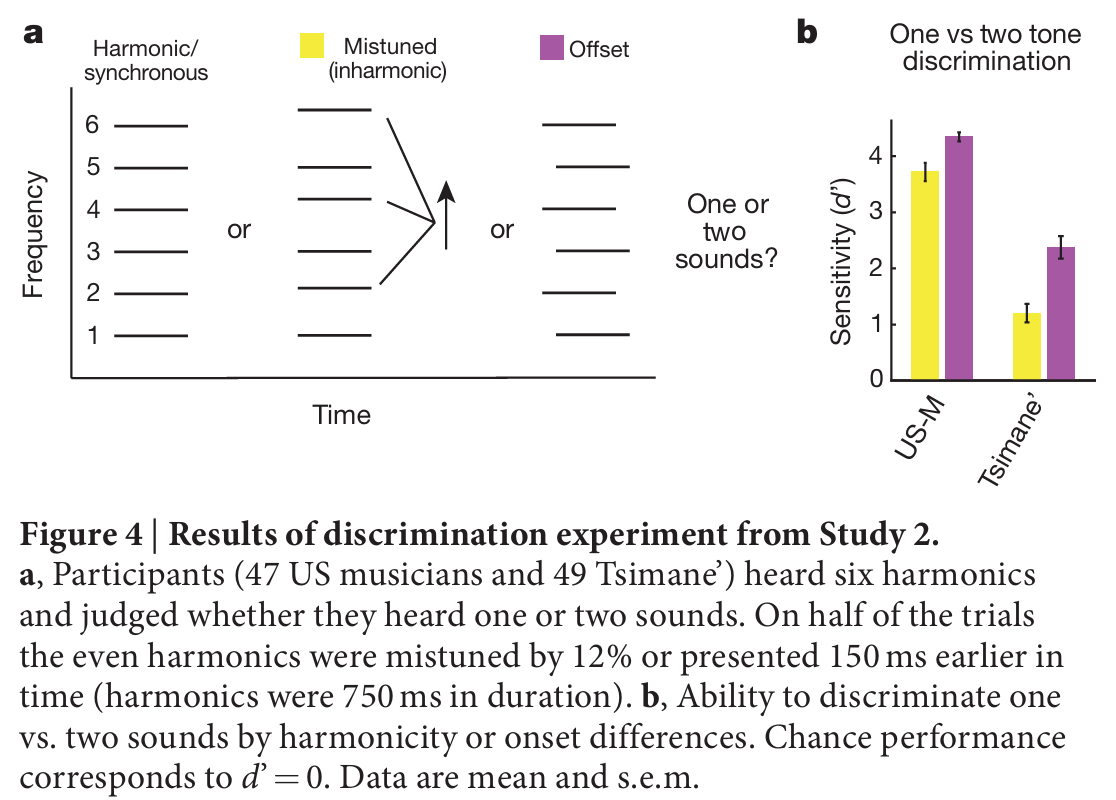
提斯曼人对协和/非谐波音无感,有可能是无法分辨两类音频的声学区别,为此设计单音/双音分辨实验(对应图4a配图说明翻译:受试者聆听6个泛音构成的复合音;一半试次里偶数次泛音做12%失谐处理,或提前150ms发声,两种操作都会破坏谐波结构,使听觉拆分为两个独立音源;受试者需要判断听到一个还是两个声音;图4b:分辨灵敏度d′d'd′,随机猜测水平对应d′=0d'=0d′=0,数据均值±标准误):受试者收听基频衍生的前六阶泛音,半数试次中偶数泛音做失谐偏移、或是提前发声,两种操作都会打破谐波绑定,西方人会拆分成两个独立声响。
美国受试可精准分辨音源数量(失谐:t(46)=22.9t(46)=22.9t(46)=22.9,P<10−26P<10^{-26}P<10−26;错时:t(46)=54.4t(46)=54.4t(46)=54.4,P<10−42P<10^{-42}P<10−42);提斯曼整体分辨准确率偏低,但两项任务表现全部显著高于随机猜测(失谐:t(48)=7.3t(48)=7.3t(48)=7.3,P<10−8P<10^{-8}P<10−8;错时:t(48)=11.8t(48)=11.8t(48)=11.8,P<10−15P<10^{-15}P<10−15),说明他们生理上可以感知谐波/非谐波的声学差异。筛选分辨能力最优的三分之一提斯曼受试者(失谐条件平均灵敏度d′d'd′=2.0,拓展数据图4配图说明翻译:a选取美国表现最差三分之一受试、提斯曼分辨最优三分之一受试;b对比两组受试的和弦、人声和声协和偏好;高分提斯曼依旧无协和偏好,欧美低分受试者仍显著偏爱协和音,证明无偏好不是分辨能力不足导致),即便这群人能精准识别谐波变化,依旧对协和、不协和音无审美区分;听觉分辨能力与审美偏好相互剥离。
综合全部实验:提斯曼人可以完成声音愉悦度评判,面对具备固定情绪的人声(笑声、喘息)、区分声音粗糙/顺滑时,审美选择和西方人保持一致;生理上能够识别协和、不协和对应的声学差异;唯独不会在审美层面偏好协和音。
跨文化实验结果证明:协和音审美偏好并非人类先天本能,也不是源于自然界自带谐波声响(如动物、人类说话泛音)的日常听觉输入;该偏好建立在后天长期聆听协和和声音乐的基础上。玻利维亚城乡居民因日常零星接触西式传媒音乐,形成微弱协和偏好,过往婴幼儿相关实验观测到的微弱协和倾向也可以用后天微量音乐暴露解释⁽²⁸⁻³⁰⁾。提斯曼本土音乐全程无和声结构,未来可选取长期浸泡在不协和为主的异域音乐中的族群开展对照,验证后天音乐环境塑造审美;当然,除西方音乐外,其他文明音乐同样会培养听众对特定音程组合的偏爱。
学界之所以长期认为协和偏好由生物基因决定,源于协和、不协和音在粗糙度、谐波结构上具备客观声学差异⁽⁴⁾⁽⁵⁾⁽⁷⁾⁽⁹⁾⁽¹²⁾⁽²¹⁾⁽²²⁾,分类并非完全主观。但本实验证实:对谐波、简单整数音程、协和和弦的喜爱程度,和受试者接触西方文明的程度正相关。因此西方人偏爱谐波音,不是听觉生理结构的必然结果,而是长期聆听大量协和和声结构的西式音乐所养成的后天习惯⁽²¹⁾⁽²²⁾。人类天生排斥刺耳声学粗糙感是跨文化共性,但该生理反应和音乐层面的协和、不协和审美无关,现实里常规乐曲极少出现强粗糙声响⁽²¹⁾⁽²²⁾。生物因素仅能决定人类可以分辨哪些声学差异,部分审美倾向更容易通过后天学习形成。
受制于全球西方文化快速普及,与世隔绝的原住民样本越来越稀缺,跨文化音乐感知实验难以开展;但本研究证实,原住民跨文明对照实验对探明人类音乐行为多样性具备不可替代的科研价值。
本文在线补充实验方法、拓展附图、原始实验数据可查阅期刊官网,仅在线部分收录的参考文献条目详见网络版。
收稿日期:2014年11月11日;录用日期:2016年6月10日;网络首发:2016年7月13日。
参考文献(原文保留不动)
- Parncutt, R. & Hair, G. Consonance and dissonance in theory and psychology: Disentangling dissonant dichotomies. J. Interdiscipl. Music Stud. 5, 119--166 (2011).
- Huron, D. Interval-class content in equally tempered pitch-class sets: Common scales exhibit optimum tonal consonance. Music Percept. 11, 289--305 (1994).
- Bigand, E., Parncutt, R. & Lerdahl, F. Perception of musical tension in short chord sequences: the influence of harmonic function, sensory dissonance, horizontal motion, and musical training. Percept. Psychophys. 58, 124--141 (1996).
- Stumpf, C. Tonpsychologie (Verlag S. Hirzel, 1890).
- von Helmholtz, H. Die Lehre von den Tonempfindungen als physiologische Grundlage fur die Theorie der Musik (F. Vieweg und Sohn, 1863).
- Lundin, R. W. Toward a cultural theory of consonance. J. Psychol. 23, 45--49 (1947).
- Plomp, R. & Levelt, W. J. M. Tonal consonance and critical bandwidth. J. Acoust. Soc. Am. 38, 548--560 (1965).
- Cazden, N. The definition of consonance and dissonance. Int. Rev. Aesthet. Soc. 11, 123--168 (1980).
- Sethares, W. A. Tuning, Timbre, Spectrum, Scale (Springer, 1999).
- Tenney, J. A History of 'Consonance' and 'Dissonance' (Excelsior Music Publishing Company, 1988).
- Fishman, Y. I. et al. Consonance and dissonance of musical chords: neural correlates in auditory cortex of monkeys and humans. J. Neurophysiol. 86, 2761--2788 (2001).
- Tramo, M. J., Cariani, P. A., Delgutte, B. & Braida, L. D. Neurobiological foundations for the theory of harmony in western tonal music. Ann. NY Acad. Sci. 930, 92--116 (2001).
- Bidelman, G. M. & Heinz, M. G. Auditory-nerve responses predict pitch attributes related to musical consonance-dissonance for normal and impaired hearing. J. Acoust. Soc. Am. 130, 1488--1502 (2011).
- Bowling, D. L. & Purves, D. A biological rationale for musical consonance. Proc. Natl Acad. Sci. USA 112, 11155--11160 (2015).
- Butler, J. W. & Daston, P. G. Musical consonance as musical preference: a cross-cultural study. J. Gen. Psychol. 79, 129--142 (1968).
- Fritz, T. et al. Universal recognition of three basic emotions in music. Curr. Biol. 19, 573--576 (2009).
- Brown, S. & Jordania, J. Universals in the world's musics. Psychol. Music 41, 229--248 (2013).
- Maher, T. F. "Need for resolution" ratings for harmonic musical intervals: A comparison between Indians and Canadians. J. Cross Cult. Psychol. 7, 259--276 (1976).
- Godoy, R. et al. Moving beyond a snapshot to understand changes in the well-being of native Amazonians. Curr. Anthropol. 50, 563--573 (2009).
- Riester, J. Canción y Producción en la Vida de un Pueblo Indígena: los Chimane del Oriente Boliviano (Los Amigos del Libro, 1978).
- McDermott, J. H., Lehr, A. J. & Oxenham, A. J. Individual differences reveal the basis of consonance. Curr. Biol. 20, 1035--1041 (2010).
- Cousineau, M., McDermott, J. H. & Peretz, I. The basis of musical consonance as revealed by congenital amusia. Proc. Natl Acad. Sci. USA 109, 19858--19863 (2012).
- Terhardt, E. On the perception of periodic sound fluctuations (roughness). Acustica 30, 201--213 (1974).
- Kumar, S., Forster, H. M., Bailey, P. & Griffiths, T. D. Mapping unpleasantness of sounds to their auditory representation. J. Acoust. Soc. Am. 124, 3810--3817 (2008).
- Arnal, L. H., Flinker, A., Kleinschmidt, A., Giraud, A. L. & Poeppel, D. Human screams occupy a privileged niche in the communication soundscape. Curr. Biol. 25, 2051--2056 (2015).
- Moore, B. C., Glasberg, B. R. & Peters, R. W. Thresholds for hearing mistuned partials as separate tones in harmonic complexes. J. Acoust. Soc. Am. 80, 479--483 (1986).
- Darwin, C. J. Perceiving vowels in the presence of another sound: constraints on formant perception. J. Acoust. Soc. Am. 76, 1636--1647 (1984).
- Zentner, M. R. & Kagan, J. Perception of music by infants. Nature 383, 29 (1996).
- Trainor, L. J., Tsang, C. D. & Cheung, V. H. W. Preference for sensory consonance in 2- and 4-month-old infants. Music Percept. 20, 187--194 (2002).
- Plantinga, J. & Trehub, S. E. Revisiting the innate preference for consonance. J. Exp. Psychol. Hum. Percept. Perform. 40, 40--49 (2014).
致谢
本研究获美国国家科学基金会(资助R.A.G.)、麦克唐纳学者项目(资助J.H.M.)资助;感谢玻利维亚提斯曼田野调研团队(尤其T.万卡)协助田野工作,C·加西亚协助绘制地理图,E·吉布森统筹后勤,N·雅各比、M·萨利纳斯协助原住民歌手录音访谈,S·波帕姆、L·陈协助数据采集,D·博宾格、K·伍兹对文稿提出修改意见。
作者贡献
J.H.M.、A.F.S.、E.A.U.、R.A.G.共同完成实验设计、数据采集与论文撰写。
作者相关信息
转载与版权事宜详见官网www.nature.com/reprints;作者声明无利益冲突;读者可在期刊官网评论区留言交流;通讯作者:J.H.M.(jhm@mit.edu)。
审稿人信息
《自然》期刊感谢S·特雷哈布与匿名审稿人完成同行评审工作。
实验方法翻译
受试人员(实验一)
美国音乐人组:23人,女性19名;平均年龄20.2岁,标准差2.4岁;乐器平均演奏7.7年,标准差4.9年(跨度2~18年);均非职业音乐人,大部分系统上过专业课,平均上课6.8年,标准差4.3年;受试定居纽约,仅2人幼年移民美国,其余本土出生。
美国非音乐组:25人,女性12名;平均年龄37.9岁,标准差15.1岁;乐器/合唱参与平均0.2年,标准差0.3年(跨度0~1年);68%受试者从未参与任何器乐、合唱训练,专业课平均0.1年,标准差0.3年;全部生于美国、定居波士顿都市圈。过往大量西方同类实验已验证结论不受年龄、地域、性别干扰,因此美国受试未刻意均衡人口结构;非音乐人人口构成、音乐接触度和玻利维亚各组受试匹配。
玻利维亚拉巴斯(首都):24人,女性14名;平均29.9岁,标准差9.3岁;本土出生定居拉巴斯;仅3人有器乐学习经历(平均0.3年,标准差0.8),5人有歌唱经历(平均0.5年,标准差1.1)。
玻利维亚圣博尔哈(乡镇):26人,女性15名;平均31.6岁,标准差12.9岁;常年居住亚马逊盆地贝尼省圣博尔哈小镇;旱季可通车,雨季滑坡洪涝仅能飞机抵达;17人有歌唱经验,8人会演奏乐器。
提斯曼原住民(圣玛丽亚村):64人,女性31名;平均31.5岁,标准差10.2岁;村落无水电,仅能沿马尼基河乘独木舟抵达;原住民大多不清楚确切周岁,年龄为估算值⁽³⁴⁾;限定16~35岁亚组(41人,平均25岁,标准差5.8)重复分析,结论不变;本土音乐仅少数长老在聚会表演,绝大多数受试不从事音乐活动。
美国样本量参考过往实验效应量与数据离散度;玻利维亚城镇受试样本数对标美国分组,提斯曼样本受野外客观条件限制取当地最大可行样本。拓展数据表1为实验一受试人口汇总(对应拓展表1翻译:
| 项目 | 美国音乐人 | 美国非音乐人 | 拉巴斯(首都) | 圣博尔哈(乡镇) | 圣玛丽亚提斯曼 |
|---|---|---|---|---|---|
| 总人数 | 23 | 25 | 24 | 26 | 64 |
| 女性数 | 19 | 12 | 14 | 15 | 31 |
| 平均年龄 | 20.2 | 37.9 | 29.9 | 31.6 | 31.5 |
和弦素材与处理(实验一)
和弦素材沿用前期成熟实验音源⁽²¹⁾,共计10类和弦:不协和类(小二度、大二度、三全音、大七度、增三和弦);协和类(大三度、纯四度、纯五度、大三和弦);纯一度(中立音);上述分类在西方受试中已被证实稳定呈现高低分区分。全部和弦采用十二平均律。
合成和弦 :正弦相位、包含前10阶泛音的复合音;泛音振幅每八度衰减14dB,模拟自然乐器频谱;包络由10ms半汉宁窗与衰减系数2.5 s−12.5\ \mathrm{s^{-1}}2.5 s−1的指数衰减函数相乘得到,总时长截断至2秒。
真人演唱和弦:专业演唱者用元音/u/(呜)录制;150Hz四阶巴特沃斯高通滤波消除麦克风底噪;起音保留原始波形仅加10ms汉宁窗,尾端线性渐变衰减至零,总时长和合成音统一;音源试听网页:http://mcdermottlab.mit.edu/consonance_examples/index.html。
每种和弦搭配四个不同根音:合成音选用#C4、#D4、F4、G4;人声音选用#G3、#A4、#B4、D4(C4为中央C,人声根音整体下移适配歌手音域);合成、人声各40段音频分两个模块播放;受野外时间限制,提斯曼受试拆分实验,33人做人声模块、31人做合成模块;其余全部受试完成两项模块。
统计时将所有协和和弦、不协和和弦评分各自取均值,纯一度数据不纳入主体分析简化图表;除拓展图1外,全部统计基于分组均值。
谐波/非谐波单音素材(实验一)
音源沿用既往实验配置⁽²¹⁾,谐波音分三类:①1、2、4、8泛音;②1、2、3、5、9泛音;③仅基频单音;非谐波音三类:①偶次泛音上移0.5半音、奇次下移0.5半音(抖动型);②全部泛音统一+30Hz偏移;③1.5半音双纯音、双耳分放规避拍频;三类非谐波失谐偏移量均远超人类失谐感知阈值(约1%基频)⁽²⁶⁾,西方人可清晰感知违和刺耳。
全部音频泛音振幅每八度衰减14dB,包络参数同合成和弦(10ms汉宁窗+2.5 s−12.5\ \mathrm{s^{-1}}2.5 s−1指数衰减,截断2s);每种音源4个不同基频,取自中央C上方连续4个半音点位;谐波、非谐波素材随机混排为一组共44试次。统计:三类谐波均值合并、三类非谐波均值合并开展对比。
顺滑/粗糙音色素材(实验一)
通过同耳双放(同播,近频拍频→粗糙)、分耳双放(分播,无拍频→顺滑)生成成对音色⁽⁵⁾⁽⁷⁾⁽²¹⁾⁽³⁵⁾⁽³⁶⁾;音高差:中低频区间1.5半音、高频0.75半音保证拍频粗糙可闻;素材分低、中、高三组频域,每组4个基频;三类分播顺滑合并均值、三类同播粗糙合并均值做统计。
人声情绪素材(实验一)
选用蒙特利尔情绪人声库子集⁽³⁷⁾:笑声、喘息、哭喊各5段;过往证实西方人偏好笑声、厌恶喘息与哭喊,哭喊数据不纳入正文简化图表,仅对比笑/喘息。15条素材随机播放。
音频硬件与播放(实验一)
全部音源归一化为统一有效值响度;森海塞尔HD280Pro封闭式耳机播放,固定70分贝声压级舒适音量;野外缺电使用汽油发电机供电。
实验流程(实验一)
单模块内素材随机顺序播放;受试口头四档评级:非常喜欢/轻微喜欢/轻微讨厌/非常讨厌,主试盲听记录数据(主试无法获知播放音源,避免引导);多实验穿插完成,受试间实验顺序平衡抵消先后误差;施测时间:提斯曼2011.67、美国音乐人&圣博尔哈2012.12、拉巴斯2012.7、美国非音乐人2014.3~4;全部实验经提斯曼部族理事会、麻省理工人类伦理委员会、布兰迪斯大学人体受试者保护委员会审批,受试知情同意后参与。
受试人员(实验二)
美国音乐人:47人,女性32名;平均25.9岁,标准差7.5;器乐平均8.4年(1~25年),非职业音乐人;定居波士顿本土出生,全项实验完成。
提斯曼受试:50人,女性27名;平均27.4岁,标准差9.8,年龄估算;受试来自圣博尔哈周边五村落,旱季可通车,部分村落通电;筛选无收音机受试降低西方音乐接触;27人完成合成音程测试、1人未参加分辨实验;样本量受野外环境约束,美国样本匹配提斯曼规模;拓展数据表2(对应拓展表2翻译:
| 项目 | 美国音乐人 | 提斯曼人 |
|---|---|---|
| 总人数 | 47 | 50 |
| 女性数 | 32 | 27 |
| 平均年龄 | 25.9 | 27.4 |
和弦素材(实验二)
双音音程0~11半音,四类根音,共48试次;三和弦选用大三、小三、减三、增三,四类根音16试次,正文仅统计大三(协和)、增三(不协和);合成音根音中央C起四个音,人声根音#G3起适配音域,元音随机选用ah/ooh;单实验内部随机打乱试次。
提斯曼原生歌曲改编和声素材(实验二)
录制两名原住民歌手同一旋律多遍演唱,选取波形时序高度重合片段;STRAIGHT算法⁽³⁸⁾单旋律移调叠加生成1~11半音和声,附加单旋律、纯一度对照;共26段原曲,每曲两次复用,4次/音程,总计52试次;随机分配音程-曲目,19名提斯曼能辨认至少一首本土曲目。
纯音程素材(实验二)
沿用实验一粗糙音色生成逻辑,音程0~8半音,同播/分播双范式,523Hz、740Hz两个基频;0半音同播与分播音源完全一致。
单/双音源分辨任务(实验二)
基频衍生前六泛音,四类试次:①25%偶泛音+12%失谐;②25%偶泛音提前150ms发声;③50%原始无改动;受试判断听到一个/两个声响,结束即时正误反馈;基频9档(200/300/400Hz±0/4/8半音)共36试次,泛音时长750ms、首尾10ms汉宁窗,75dB播放;练习版20试次(5档基频)。
实验二流程
响度、耳机配置同实验一;受试口头评分,主试电脑录入;各模块随机排布,分辨实验对半概率放在首尾;施测:提斯曼2015.7、美国音乐人2015.7~10。
数据统计方法
偏好实验:同条件多重复评分取个体均值,再合并协和/不协和大类做组均值,图表展示全受试均值±标准误;分辨实验:用击中率、虚警率计算个体听觉灵敏度d′d'd′,图表为分组均值±标准误。
重复测量方差分析检验刺激主效应、刺激×组别交互;莫奇利球形检验不满足时采用格林豪斯-盖泽校正;事后双尾t检验,方差显著后才开展两两比较、不做多重比较校正;音程-评分相关性用皮尔逊相关;部分非正态数据(单曲目评分、纯音程实验)采用弗里德曼检验组间差异、威尔科克森符号秩配对检验。
提斯曼本土音乐补充说明
提斯曼民歌世代口传,多在集会饮用本土玉米酒奇恰时由资深歌者独唱;已有文献整理140首传统民歌,题材围绕狩猎劳作、婚恋社群、民俗信仰⁽²⁰⁾;音阶多见无半音五声音阶,部分由跨度纯四度的三音构成;配有吹管、弹拨器乐,鼓类不再用于伴奏;史料记载上世纪中期有传统舞蹈,现已失传。
本土音乐最关键特征:无多人同期合奏。访谈10位本土音乐人确认:演出依次独唱、不同时同台合奏;实验人为两名乐手邀约同台,歌手普遍抗拒、即便勉强配合也无法对齐旋律,佐证合奏文化缺失。
音乐源流:近百年受传教士、玻利维亚高地居民带来的西洋乐器、安第斯音乐、基督教圣歌影响⁽⁴¹⁾;2002~2010年马尼基河流域13村落纵向调研:30%成年人拥有电池收音机,但大量设备缺电损坏,收听音乐占比不明;近年玻利维亚乡村电网铺设,外源音乐持续侵蚀本土传统,萨满(民歌主要传承人)遭新教传教取缔,传统民歌传承逐步萎缩⁽³⁹⁾⁽⁴⁰⁾。
拓展附图说明翻译
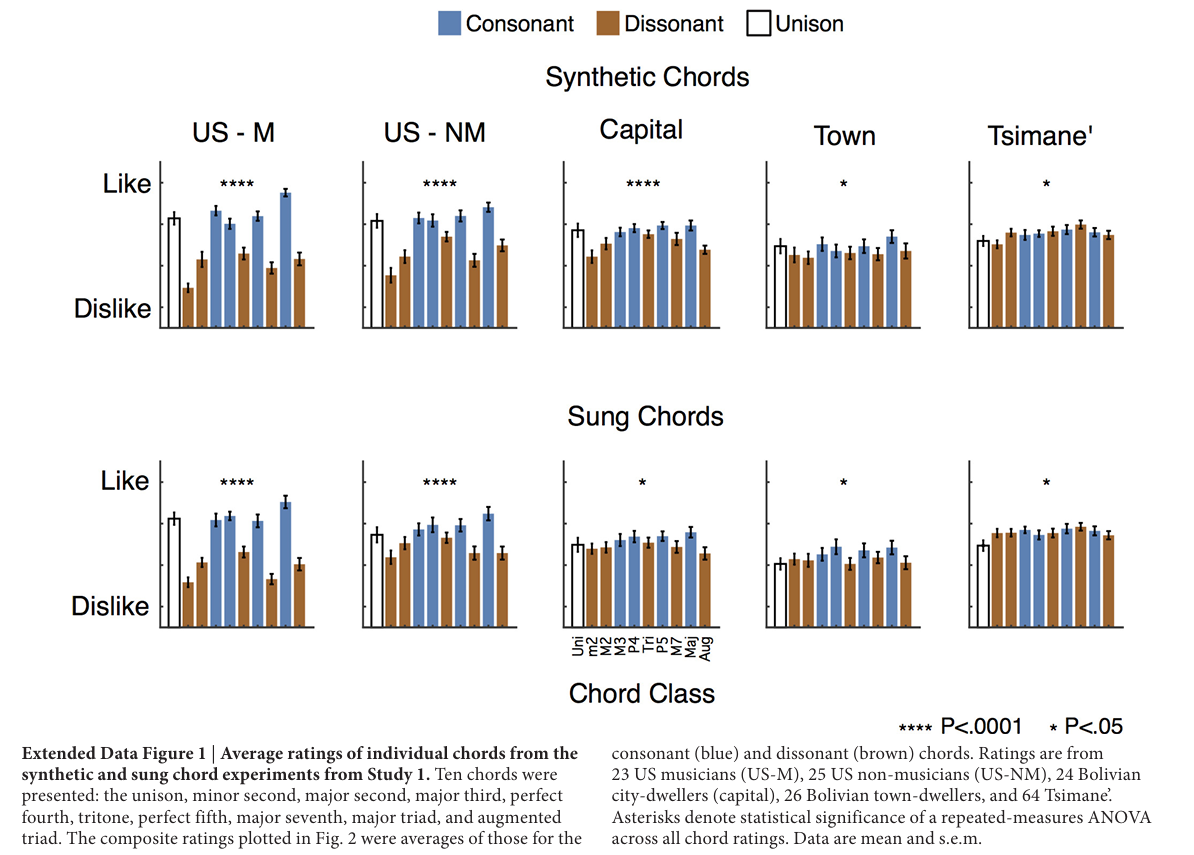
拓展图1:实验一单个和弦分项愉悦评分,协和蓝、不协和棕;受试23美音、25美普通、24首都居民、26乡镇居民、64提斯曼;*P<0.05P<0.05P<0.05、**P<0.01P<0.01P<0.01、***P<0.001P<0.001P<0.001、****P<0.0001P<0.0001P<0.0001、n.s.无显著差异;整体方差分析显著性标注;数据均值±标准误。
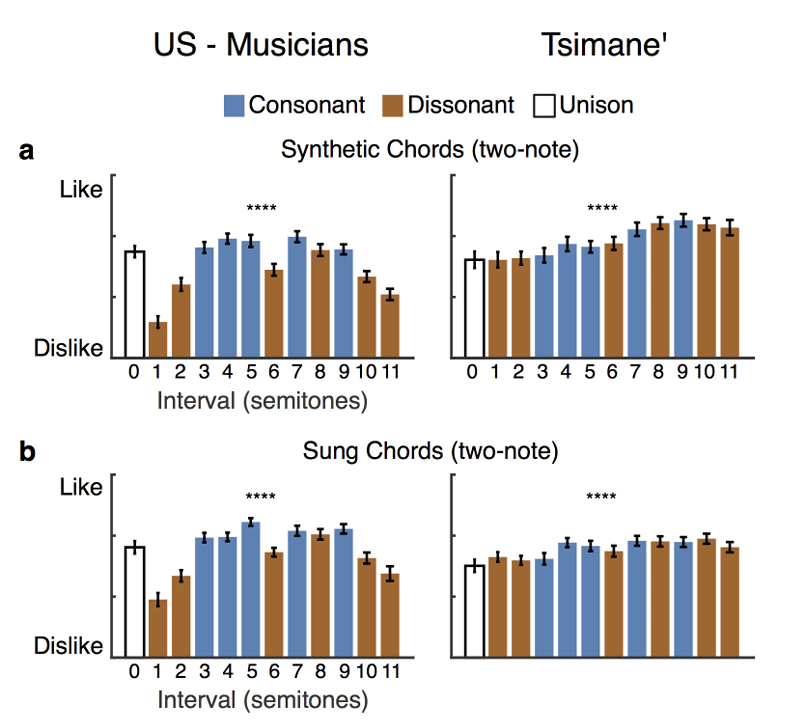
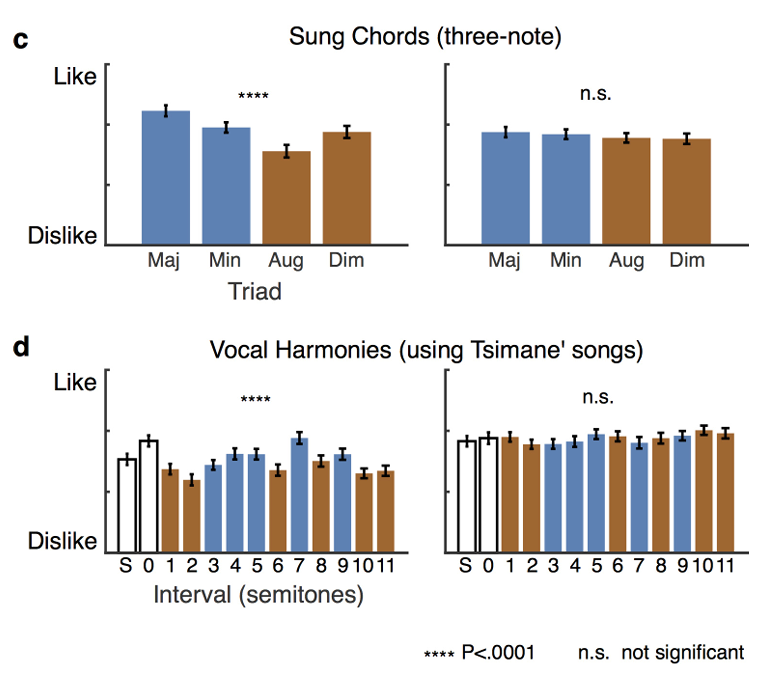
拓展图2:实验二单音程、三和弦、原生和声分项评分;美国人评分由协和属性主导,提斯曼评分随音程宽度变化;S=单旋律、0=纯一度同旋律叠加;均值±标准误。
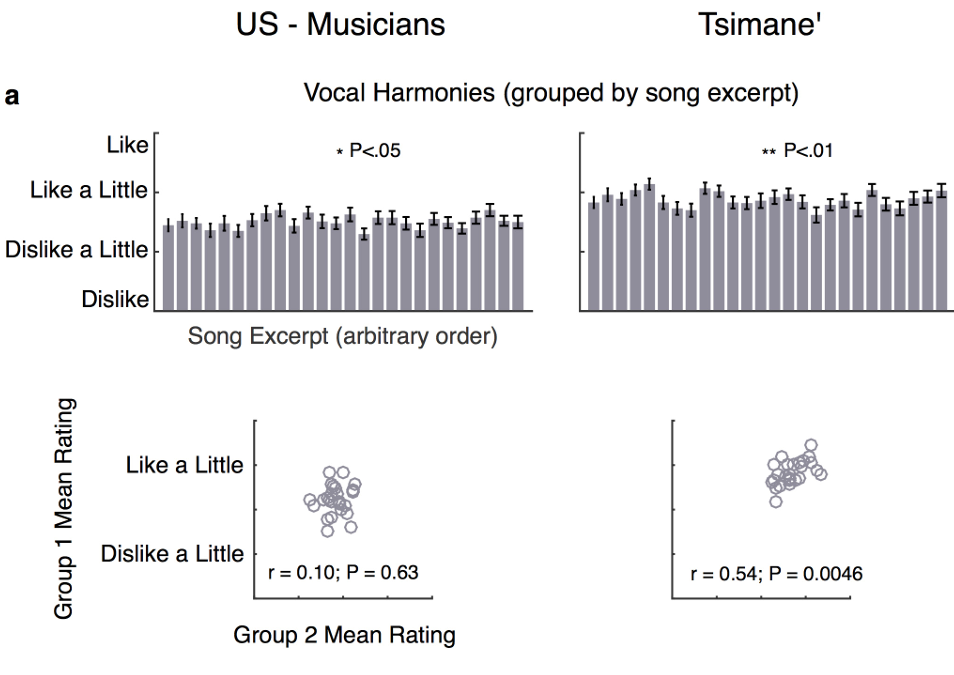
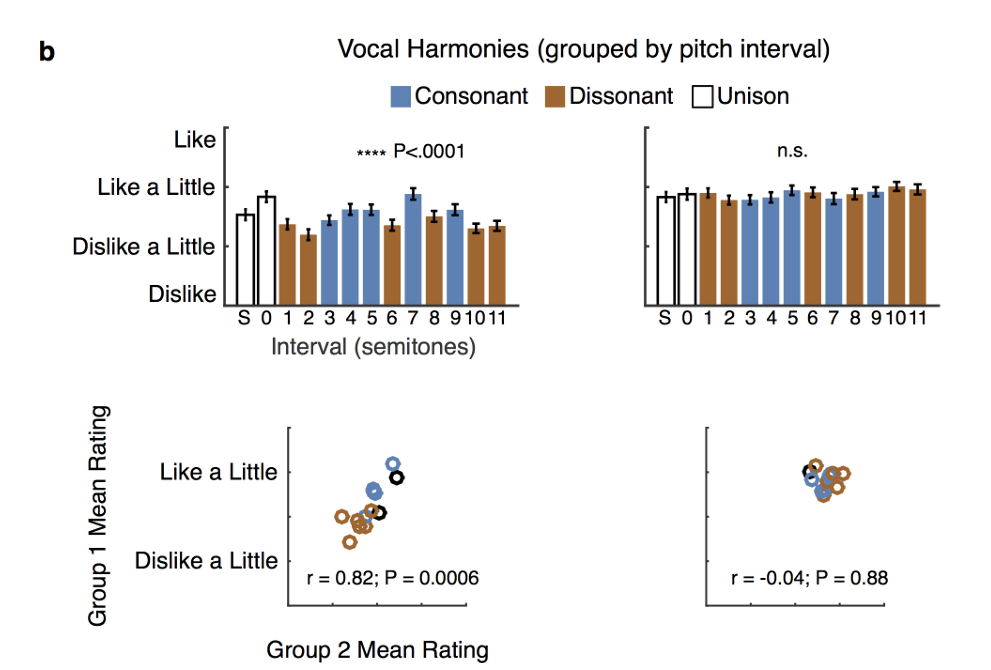
拓展图3:a按原曲片段分组评分,美、提斯曼均可区分曲目好恶,但双方曲目偏好无相关;前后半受试评分相关性:提斯曼组相关显著、美国人无稳定相关;b按和声音程分组,美国人音程偏好高度稳定相关、提斯曼无;弗里德曼非参数检验,P<0.05P<0.05P<0.05、**P<0.01P<0.01P<0.01、 ***P<0.0001P<0.0001P<0.0001、n.s.不显著;均值±标准误。
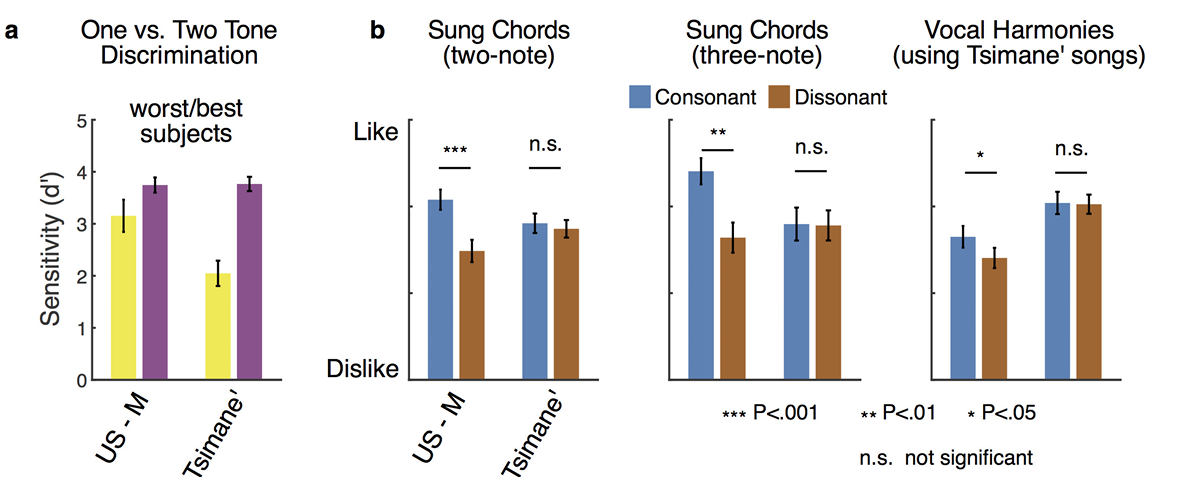
拓展图4:a筛选美国分辨最差1/3、提斯曼分辨最优1/3;b高分提斯曼仍无协和偏好,低分美国人依旧偏爱协和;P<0.05P<0.05P<0.05、P<0.01P<0.01P<0.01、 P<0.001P<0.001P<0.001、n.s.不显著;证明协和偏好缺失不是听觉分辨不足导致;均值±标准误。