内容
- [课题汇报&论文分享 4.14-4.20](#课题汇报&论文分享 4.14-4.20)
- [课题汇报&论文分享 4.21-4.27](#课题汇报&论文分享 4.21-4.27)
- [课题汇报&论文分享 4.28-5.04](#课题汇报&论文分享 4.28-5.04)
课题汇报&论文分享 4.14-4.20


https://cnblogs.com/chengjunkai/p/16755674.html
论文翻译
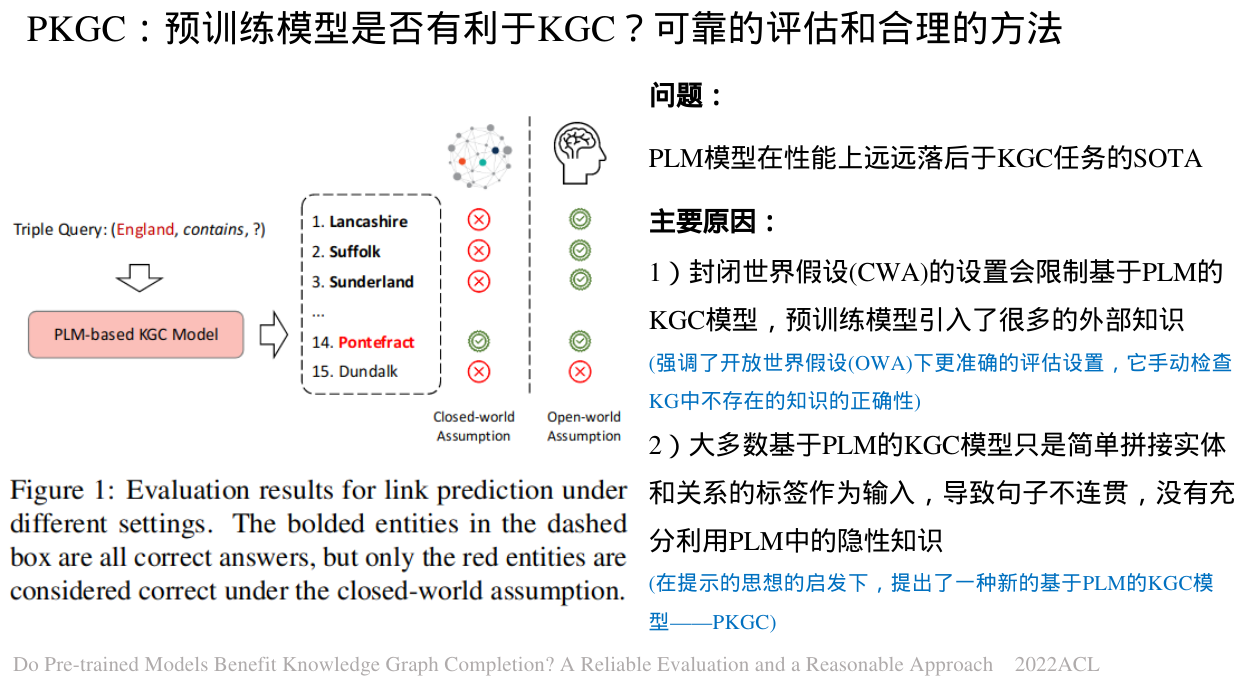
预训练模型被证明可以从文本中获得真实的知识,这促使着基于PLM的知识图谱补全(Knowledge graph completion, KGC)模型的提出,然而这些模型在性能上远远落后于KGC任务的SOTA。
<封闭世界假设 (Closed-world assumption, CWA)认为, 在给定的知识图谱中没有出现的三元组是错误的。我们可以很容易在 CWA 下评估没有标注的模型的性能。然而,CWA 本质上是一种近似,不能保证评估结果的准确性。该假设在给定的KGs中未知的任何知识都是不正确的。这样的设置有利于自动构建数据集,而无需手动注释。
开放世界假设 (Open-world assumption, OWA)认为知识图谱中包含的三元组是不完备的。因此,开放世界假设下的评估更准确、更接近真实场景,但需要额外的人工标注,仔细验证知识图谱中不存在的完整三元组是否正确。>
然而,PLMs的引入带来的很多未知的外部知识,都是在CWA下被认为是不正确的,这错误地降低了模型的性能。如图1所示,对于一个三元组查询(England,contain,?),基于PLM的KGC模型给出了许多正确的尾部实体(用粗体突出显示),但只有Pontefract在CWA下被认为是正确的,因为它存在于KGs中。
在本研究中,我们发现了基于PLM的KGC模型性能较弱的两个主要原因:1、不准确的评估设置 2、没有正确利用PLMs

为了使KGC评估更加可信,我们强调了一个基于开放世界假设(OWA)的新的评估设置------不在KGs中的知识不是错误的,而是未知的。
因此,CWA下的假正类应该被去除,只需要我们从未知中识别出准确的真和假三元组。对于这些未知的三元组,我们进行人工注释以检查它们是否有效。
链路预测任务要求模型给出每个实体是缺失实体的概率的降序。继之前的工作(Dettmers等人,2018年),我们使用两个评估指标,即MRR和Hits@N。然而,这两个度量不适用于OWA下的链路预测,因为我们不能通过手动注释获得所有可能的三元组的真实标签。例如,给定一个中型数据集,测试集中有10,000个实体和10,000个三元组,我们需要知道最多2亿(2 × 10,000 × 10,000)三元组的真实标签,这是不可能通过注释获得的。因此,我们使用替代评估。具体来说,我们从测试集中采样三元组,并用前1个预测实体填充缺失的实体。然后,我们手动注释这些三元组的正确比率。该评估度量被表示为CR@1。
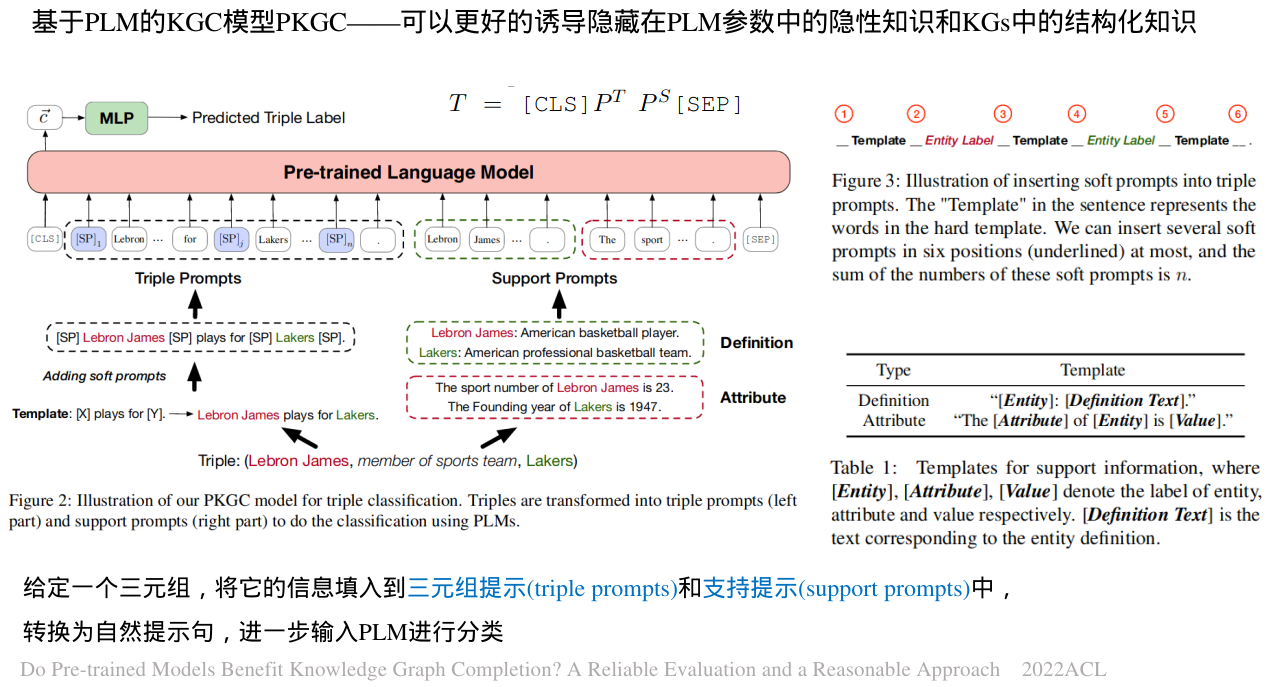
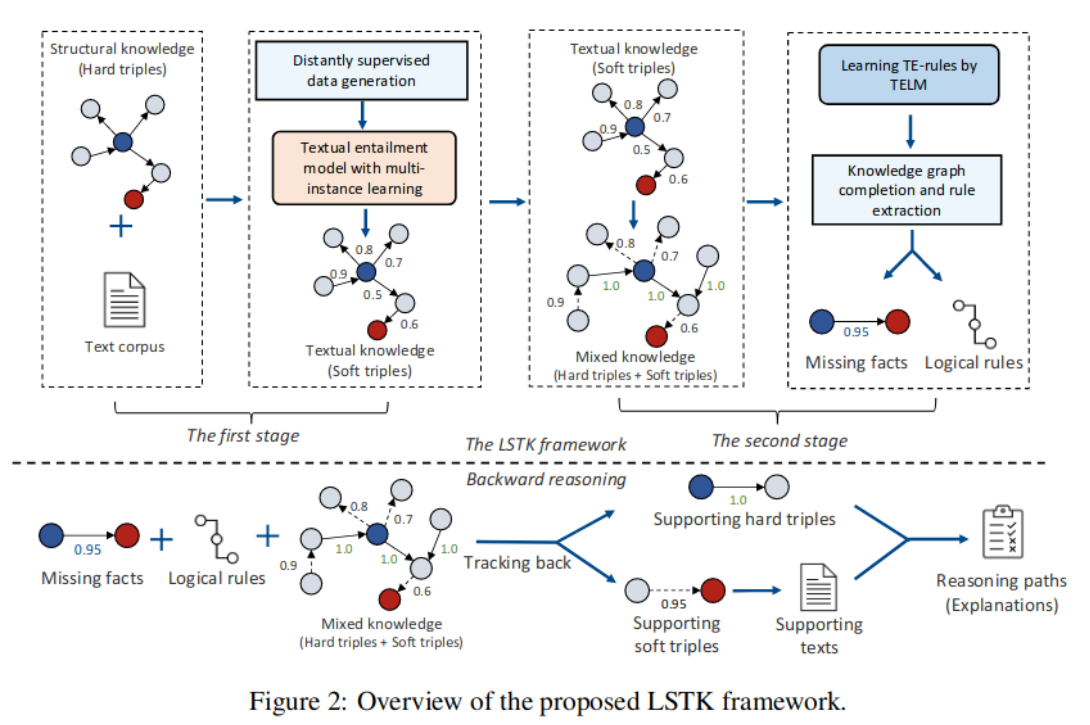
图2:模型PKGC下三元组分类任务示意图
软提示(Soft Prompt): Soft Prompt是在向量空间优化出来的提示,从一个Hard Prompt开始初始化,通过梯度搜索等方式进行优化(不改变原始的提示向量的数量和位置);
而Hard Prompt是人可以读的提示,即一段人类可以直观阅读的单词序列。
图3:将软提示插入三元组提示的图示。句子中的"Template"代表固定模板中的单词。我们最多可以在六个位置(下划线处)插入多个软提示,这些软提示的数量之和为n。
·KG中除了它本身的三元组信息外,还有许多可以帮助KGC的支持信息,如定义、属性等。在之前的KGE模型中,通常需要改变模型结构来引入特定类型的附加信息,这会带来大量额外的开销,不利于统一多类型支持信息。
·由于语言的通用性,在不改变模型结构的情况下,很容易在模型中引入各种支持信息。如表1所示,我们定义模板把支持信息转换为相应的句子。对于一个三元组(h,r,t),可能有多个对应的属性。为了避免过于复杂的模型,在本研究中,我们使用了随机策略来选择属性,即为一个三元组中的每个实体随机选择一个属性。
·值得注意的是,我们的模型不需要呈现所有支持信息。如果不存在,就不添加相应的信息。此外,我们的模型还可以很好地支持更多其他类型的支持信息,只需手动定义表1中所示的相应模板即可。
表1:支持信息的模板。其中Entity、Attribute和Value分别表示实体、属性和值的标签。定义文本是实体定义对应的文本。

除K可能是要标签平滑
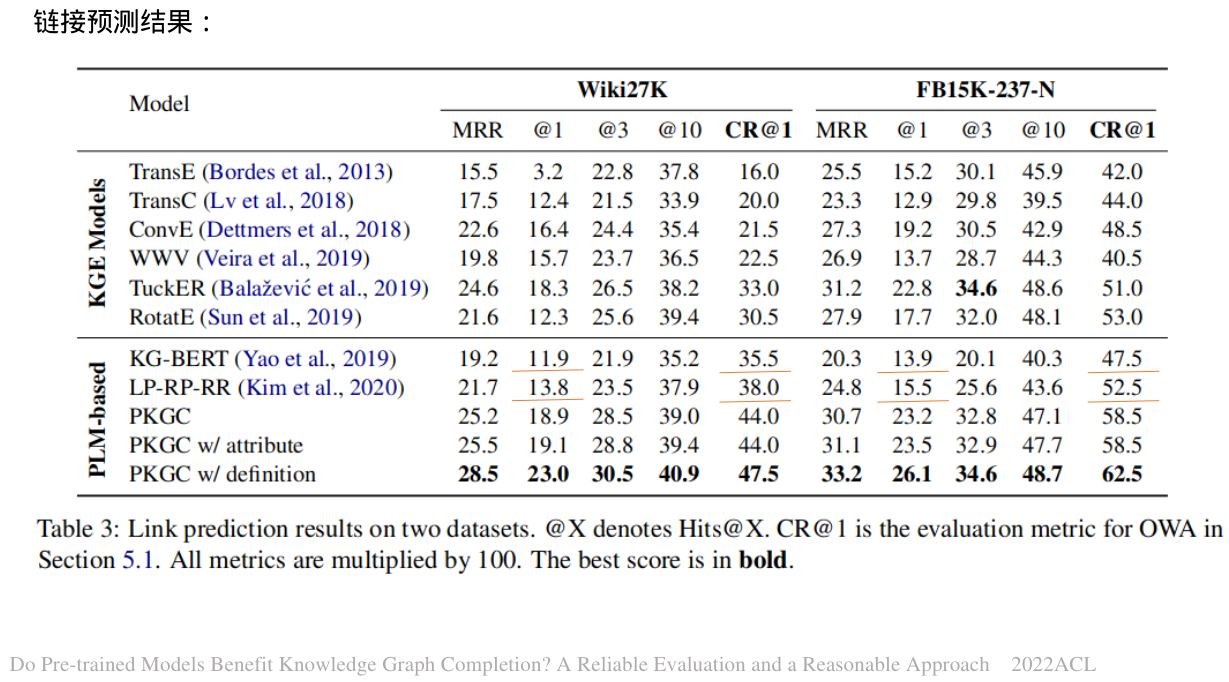
给出了CWA和OWA下模型的结果。具体来说,CWA下的结果供参考,OWA下的结果更能反映模型的真实性能。
从表中我们可以了解到,大多数模型在Hits@1和CR@1下的性能差异很大。这种性能差距在基于PLM的模型中更为明显。例如,在Wiki27K上,虽然KG-BERT和LP-RP-RR在Hit@1上低于几乎所有的KGE模型,但在CR@1上都优于它们。
我们可以看到,模型在CWA和OWA下的性能排名并不相同,这说明了CWA无法在链路预测任务上带来准确的评估结果。这项工作只是对CWA和OWA下KGC模型之间巨大性能差异的初步发现。我们认为应该在OWA下系统和全面地重新评估现有的KGC模型,我们把它留给未来的工作。
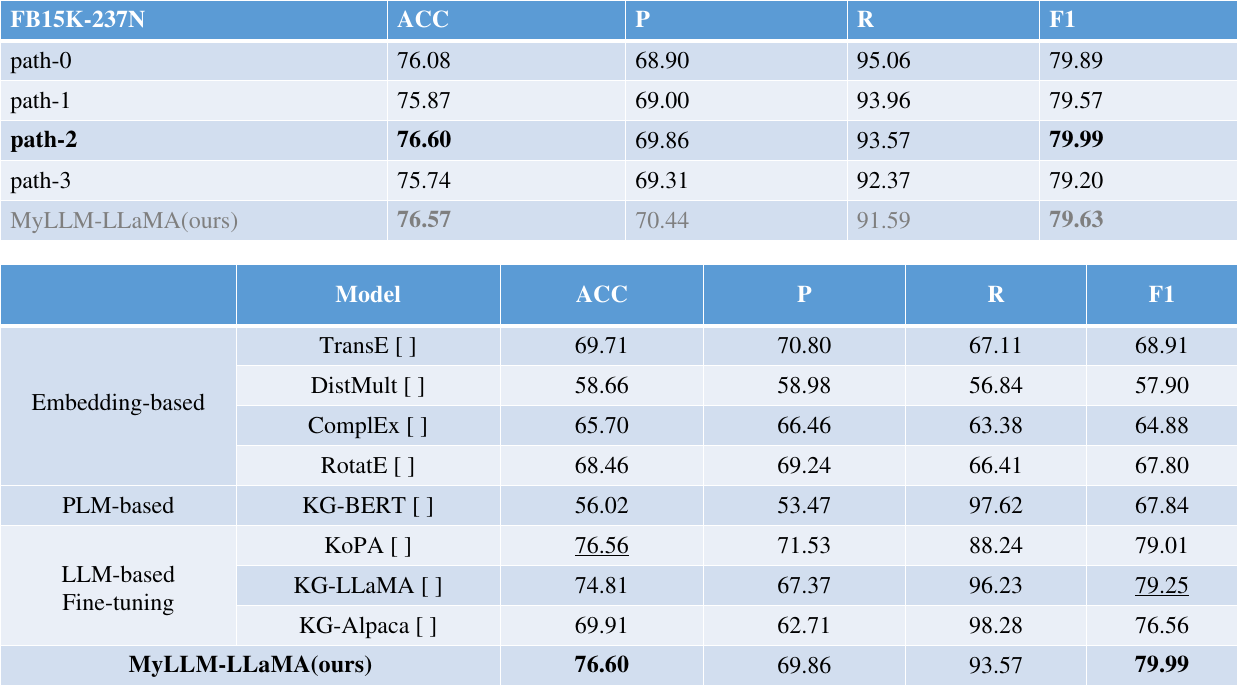
通过将我们的模型与基线模型的结果进行比较,我们发现虽然我们的模型在CWA下没有显著的性能优势,但在OWA下它显著优于以前的模型(KEG和基于PLM的模型)。这表明,在我们的模型中将三元组转换为句子的方法可以更好地利用PLMs中的隐性知识。对于我们的模型,添加支持信息可以实现性能的改善,其中定义带来更好的明显改善。可能的原因是定义是唯一的,不需要像属性一样随机选择。因此,它引入的噪声更少,也更准确。
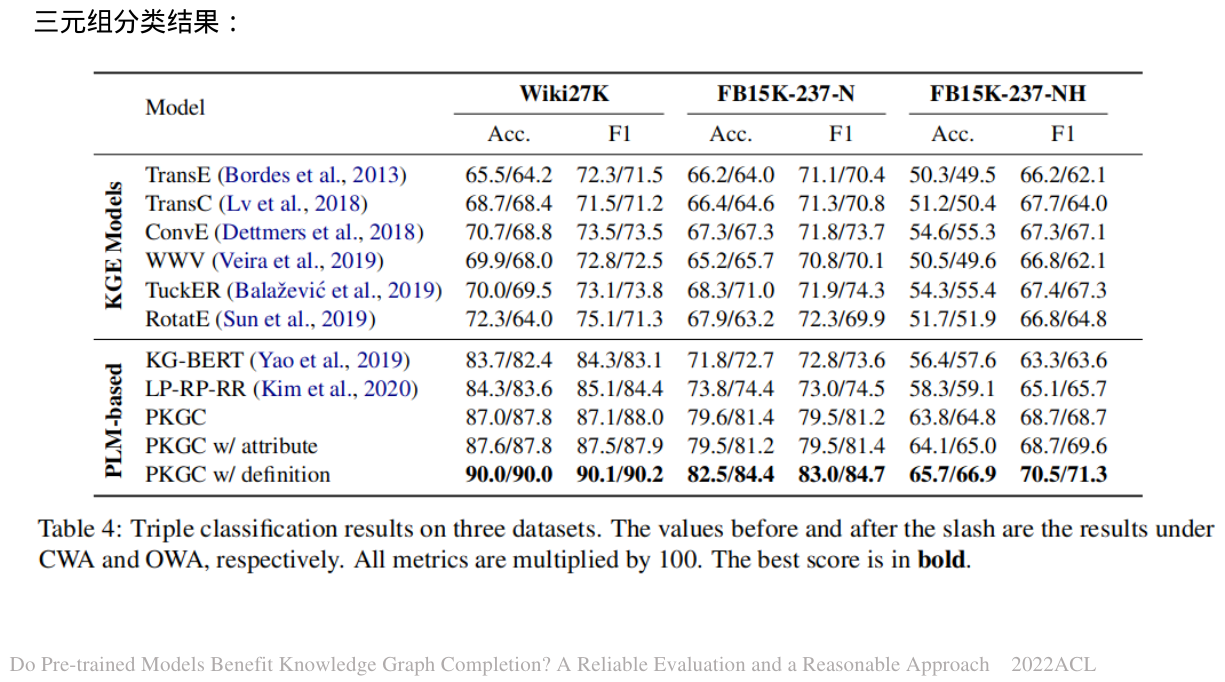
三元组分类任务旨在判断给定的三元组是否正确。这本质上是一个二元分类任务,因此我们使用准确度和F1作为评估指标。与链接预测相反,三元组分类任务能够低成本地评估模型在OWA下的性能,因为我们只需要通过注释来确保少量(与测试集中正三元组的数量一致)确实错误的负三元组。
为了增加任务的难度并更接近真实场景中的KGC任务,我们通过删除FB15K-237中包含中介节点的关系来获得数据集FB15K237-N。此外,为了使三元组分类更加困难,我们还通过仅修改负三元组来构建基于FB15K237-N的数据集FB15K-237-NH。它仅用于三重分类。
通过并排比较CWA和OWA下模型的性能,我们可以发现大多数模型的性能差距很小。这可能是因为三重分类任务中假阴性三重的比例很小。
具体来说,与KGE模型相比,我们的模型和其他基于PLM的KGC模型都取得了更好的结果,这表明PLM的引入可以帮助模型更好地确定三元组是否正确。还可能有一个原因是基于PLM的KGC模型使用分类损失来训练,并且可能更适合于三重分类任务。比较我们模型的所有变体,定义带来了更好的结果,这与链路预测中的表现是一致的,原因应该是类似的
课题汇报&论文分享 4.21-4.27

检索增强生成(RAG)通过将信息检索与大型语言模型(LLMs)相结合,在知识密集型任务中取得了显著进展,从而增强事实意识和生成准确性。
·然而标准RAG框架主要依赖于基于块的检索机制,其中文本被分割成固定长度的段落,并通过密集向量匹配进行检索。它无法捕捉实体之间的复杂关系,导致知识建模能力差,检索效率低,限制了其在细粒度知识驱动应用中的适用性
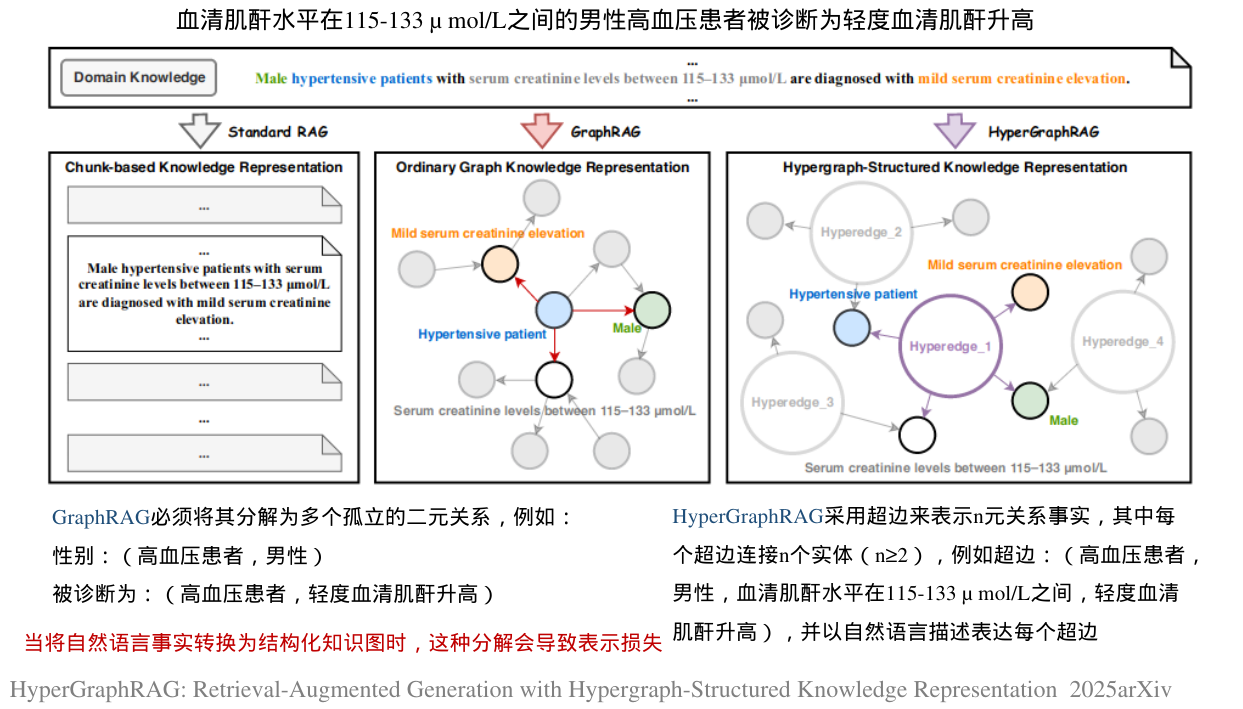
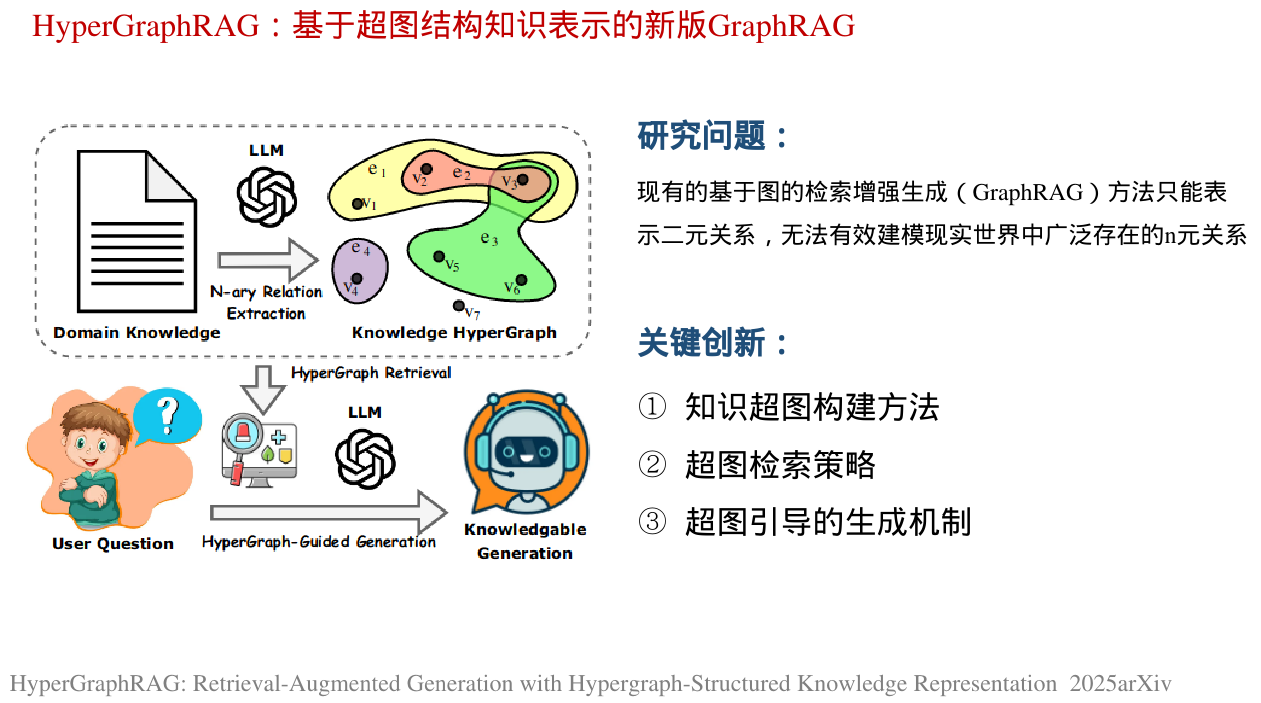
·GraphRAG(Edge等人,2024)通过将知识表示为基于图的结构,提高了检索精度,作为对传统RAG的增强。然而,以前的GraphRAG仅限于二元关系,这使得它不足以模拟现实世界知识中发现的两个以上实体之间普遍存在的n元关系
·为了解决这些限制,我们提出了HyperGraphRAG,如图1所示,这是一种新的基于图的RAG方法,具有超图结构化的知识表示。与仅限于二元关系的GraphRAG不同,Hyper-GraphRAG采用超边来表示n元关系事实,其中每个超边连接n个实体(n≥2),例如超边:(高血压患者,男性,血清肌酐水平在115-133 μ mol/L之间,轻度血清肌酐升高),并以自然语言描述表达每个超边。这种方法提高了知识的完整性、结构表达能力和推理能力,为知识密集型应用提供了更全面的支持
 为了实现HyperGraphRAG,我们引入了几个关键的创新。首先,我们提出了一种知识超图构建方法 ,利用基于LLM的n元关系提取来提取和构建多实体关系。得到的超图存储在二分图数据库中,具有用于实体和超边的单独向量数据库,以促进高效检索。其次,我们开发了一种超图检索策略 ,该策略采用向量相似性搜索来检索相关实体和超边,确保检索到的知识既精确又与上下文相关。最后,我们引入了一种超图引导的生成机制 ,该机制将检索到的n元事实与传统的基于块的RAG通道相结合,从而提高了响应质量。
为了实现HyperGraphRAG,我们引入了几个关键的创新。首先,我们提出了一种知识超图构建方法 ,利用基于LLM的n元关系提取来提取和构建多实体关系。得到的超图存储在二分图数据库中,具有用于实体和超边的单独向量数据库,以促进高效检索。其次,我们开发了一种超图检索策略 ,该策略采用向量相似性搜索来检索相关实体和超边,确保检索到的知识既精确又与上下文相关。最后,我们引入了一种超图引导的生成机制 ,该机制将检索到的n元事实与传统的基于块的RAG通道相结合,从而提高了响应质量。
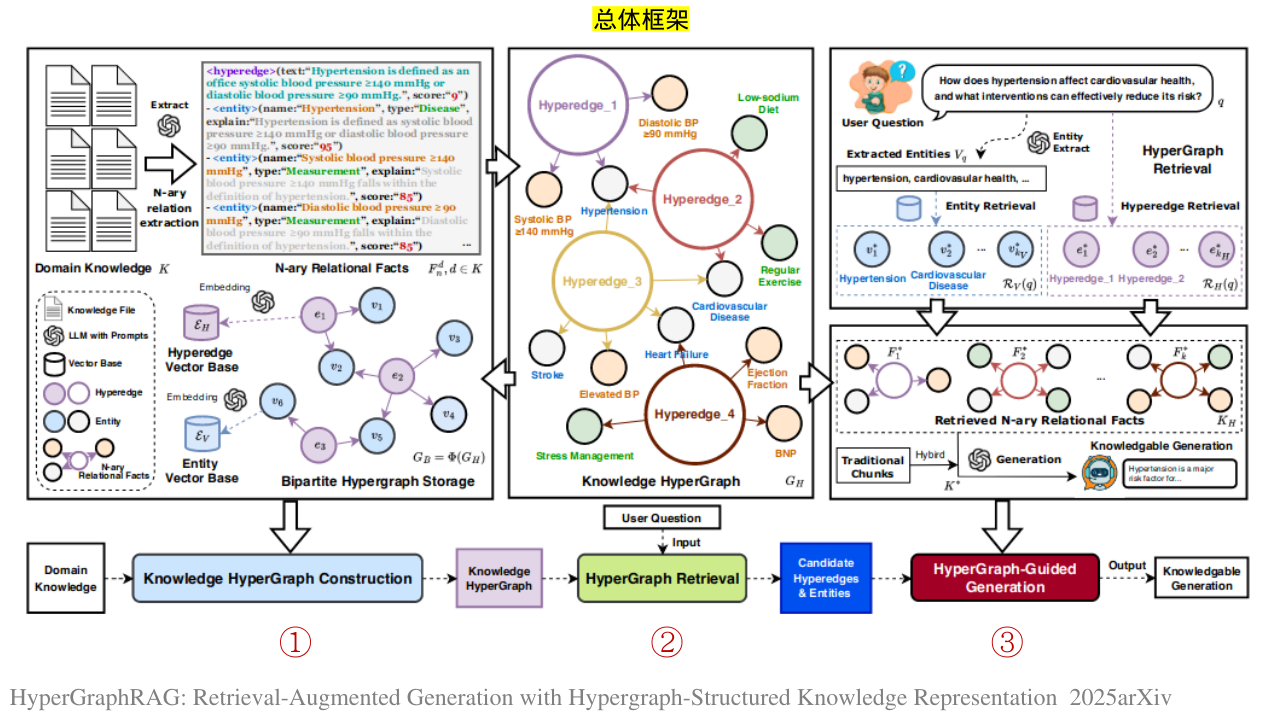
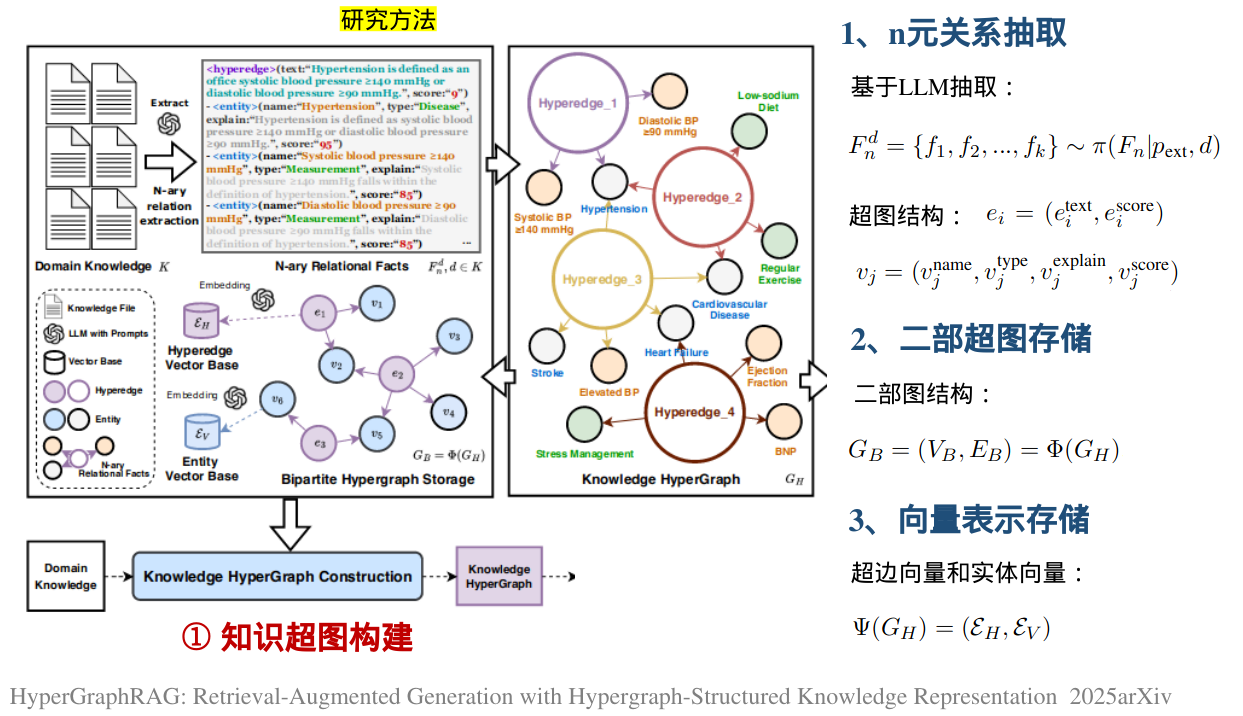
给定输入文本d,该文本被解析并分割成几个独立的知识片段。每个知识片段被认为是一个超边 :Ed H={e1,e2,...,ek},其中每个超边ei=(etext i,escore i)由两部分组成:自然语言描述etext i和表示该超边ei与原始文本d的关联强度的置信度得分escore i∈(0,10)。
pext n元关系抽取提示
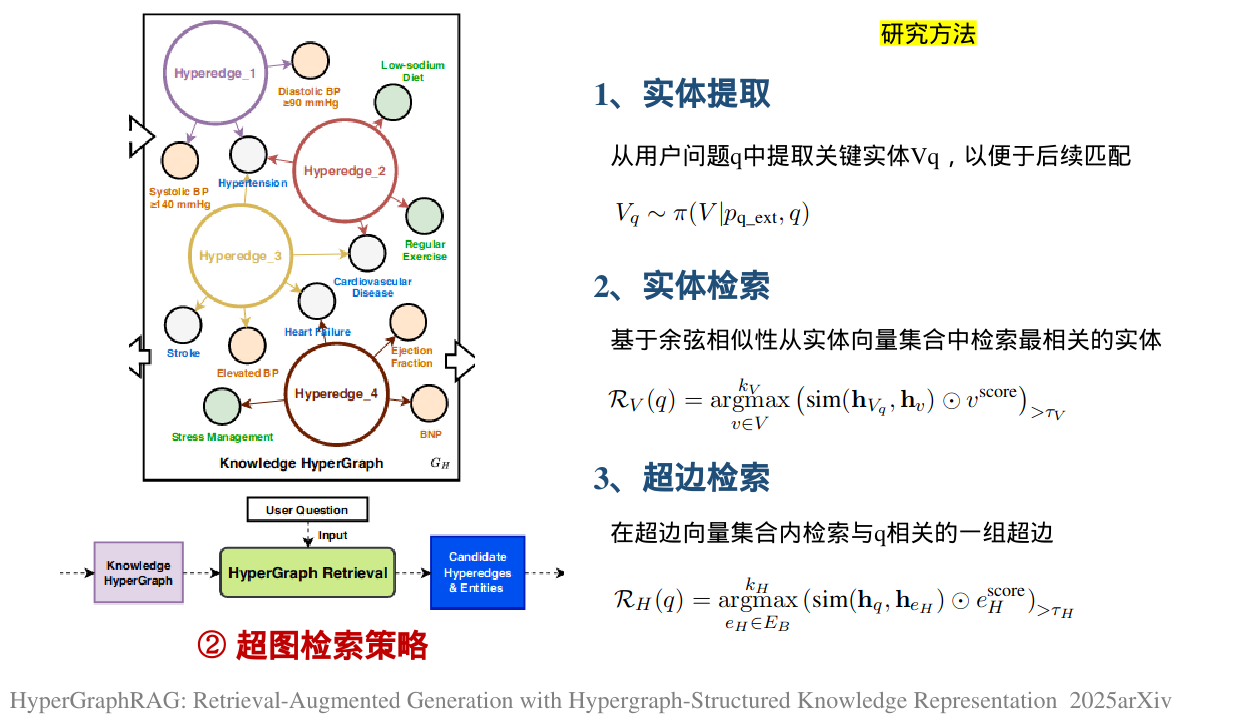
在构建和存储超图GH之后,我们需要设计一种高效的检索策略,将用户问题与相关的超边和实体进行匹配。超图检索包括实体提取、实体检索和超边检索。
在实体检索之前,我们从用户问题q中提取关键实体,以便于后续匹配。我们设计了一个实体提取提示pq_ext 和LLM π来执行实体提取:
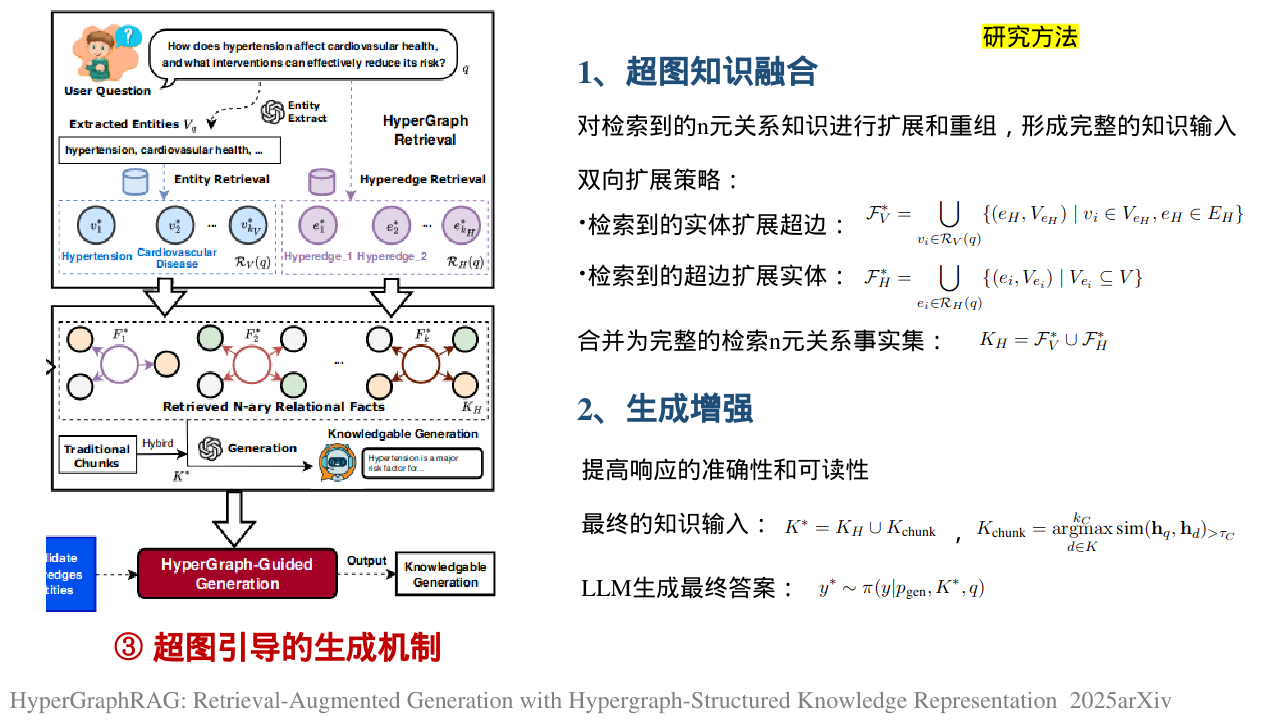
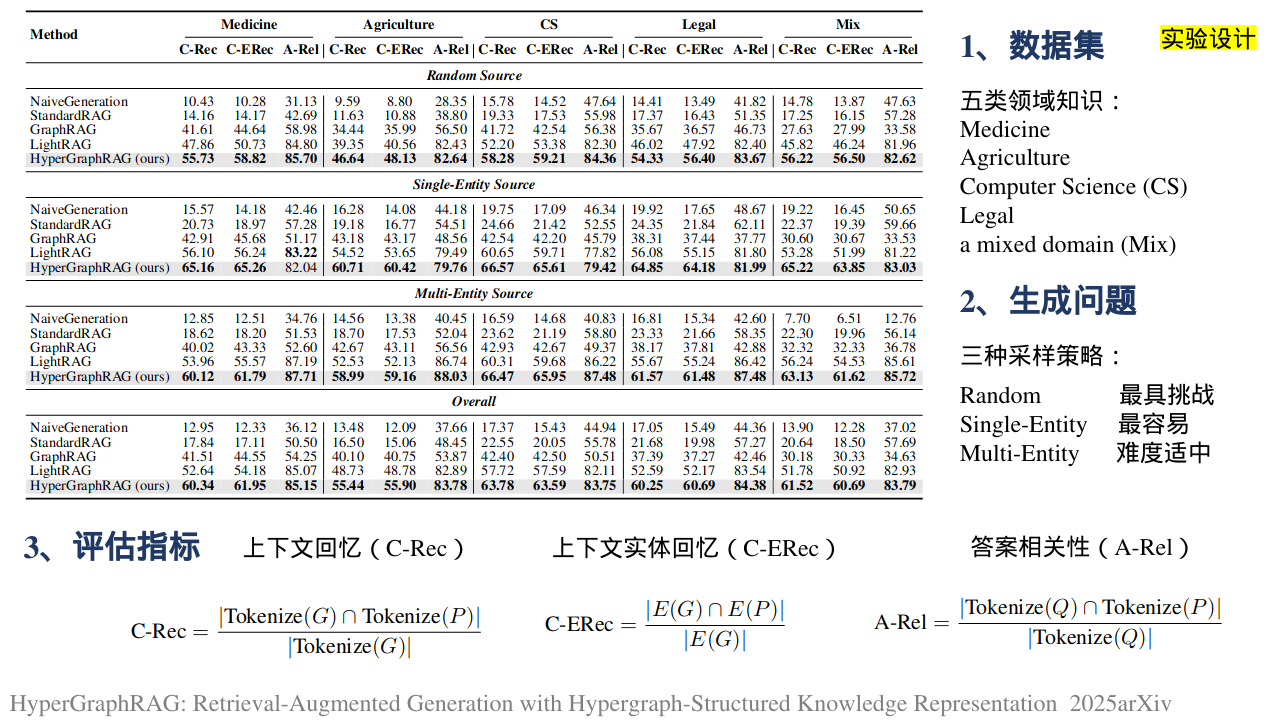
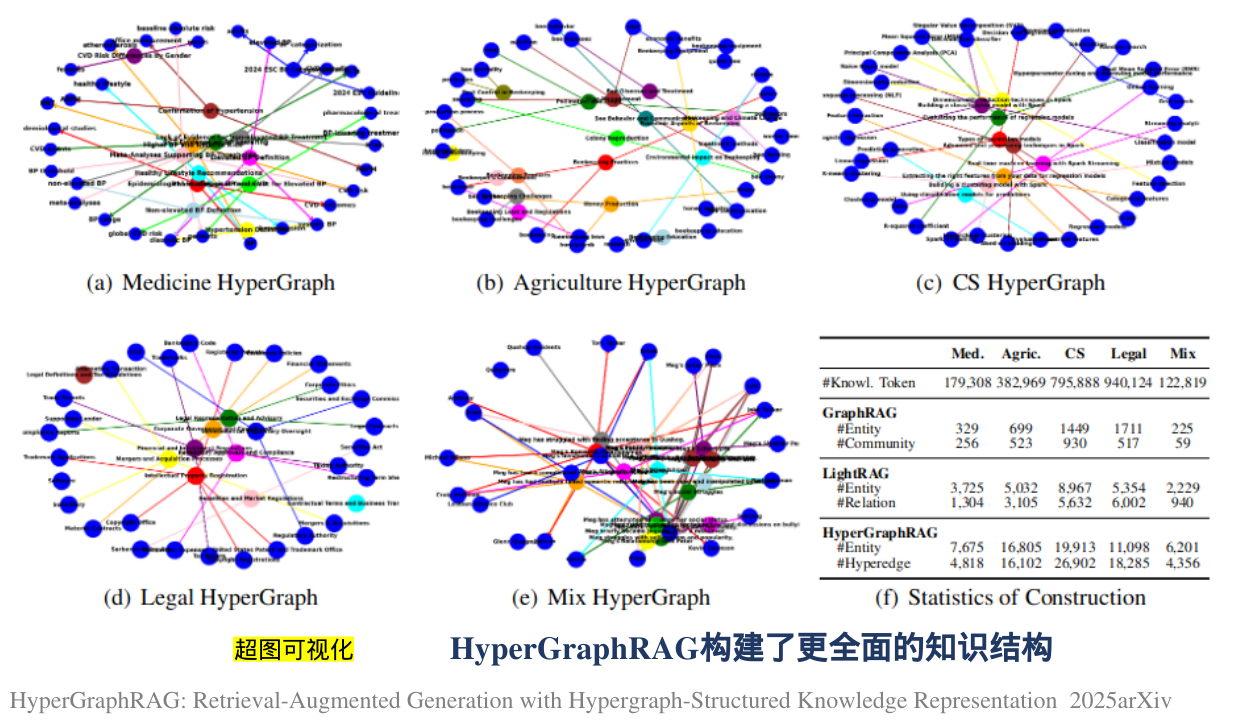
与GraphRAG只对二元关系建模不同,HyperGraphRAG通过超边连接多个实体,形成了一个更具互连性和表现力的网络
课题汇报&论文分享 4.28-5.04
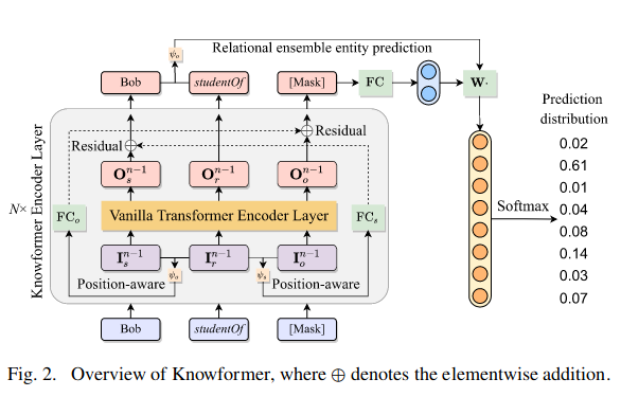
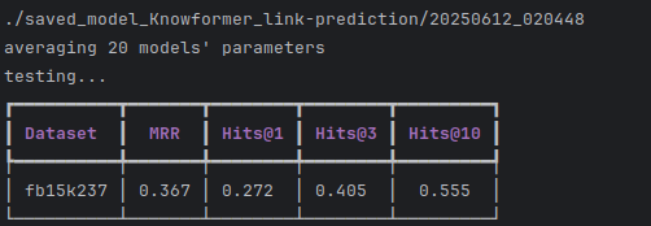
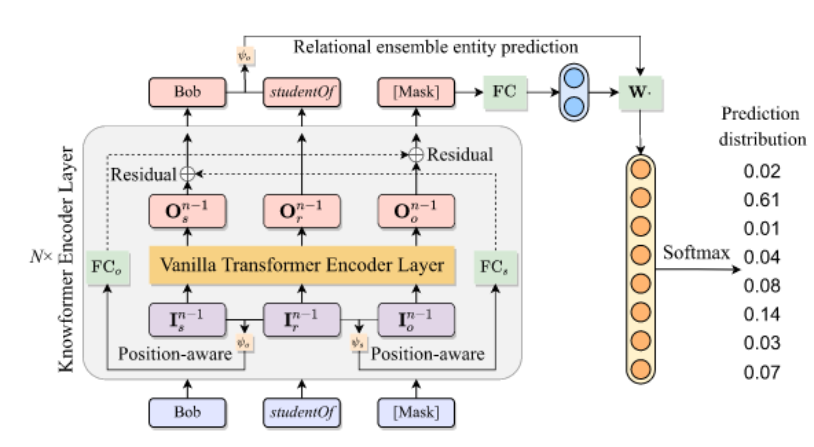
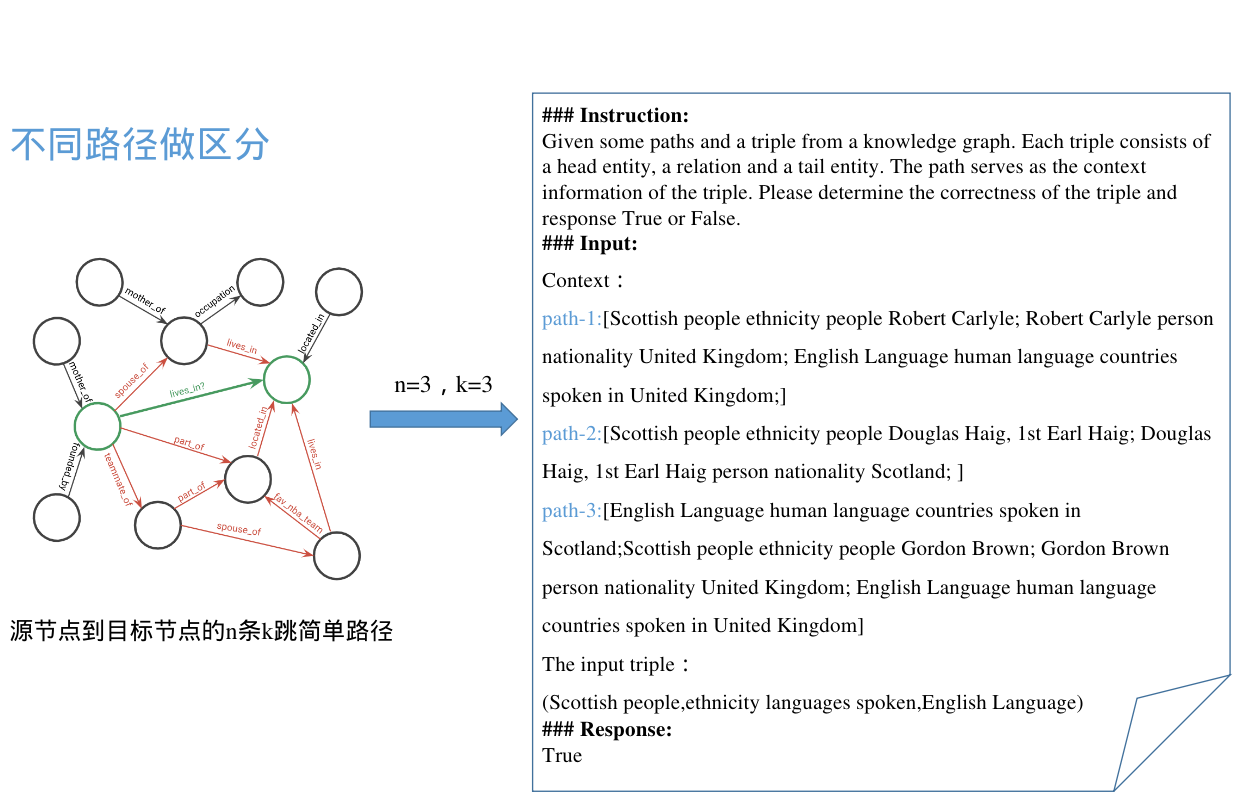
原始knowformer
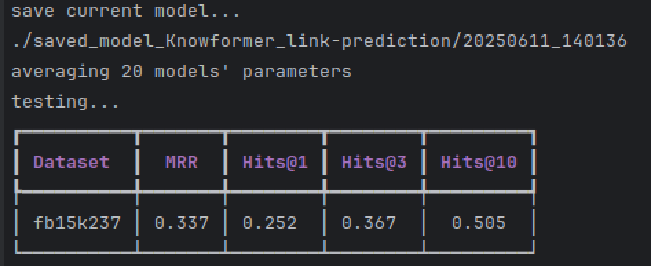
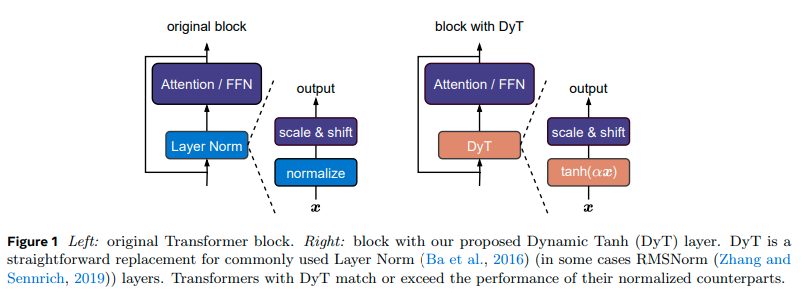
默认dyT


二、贡献
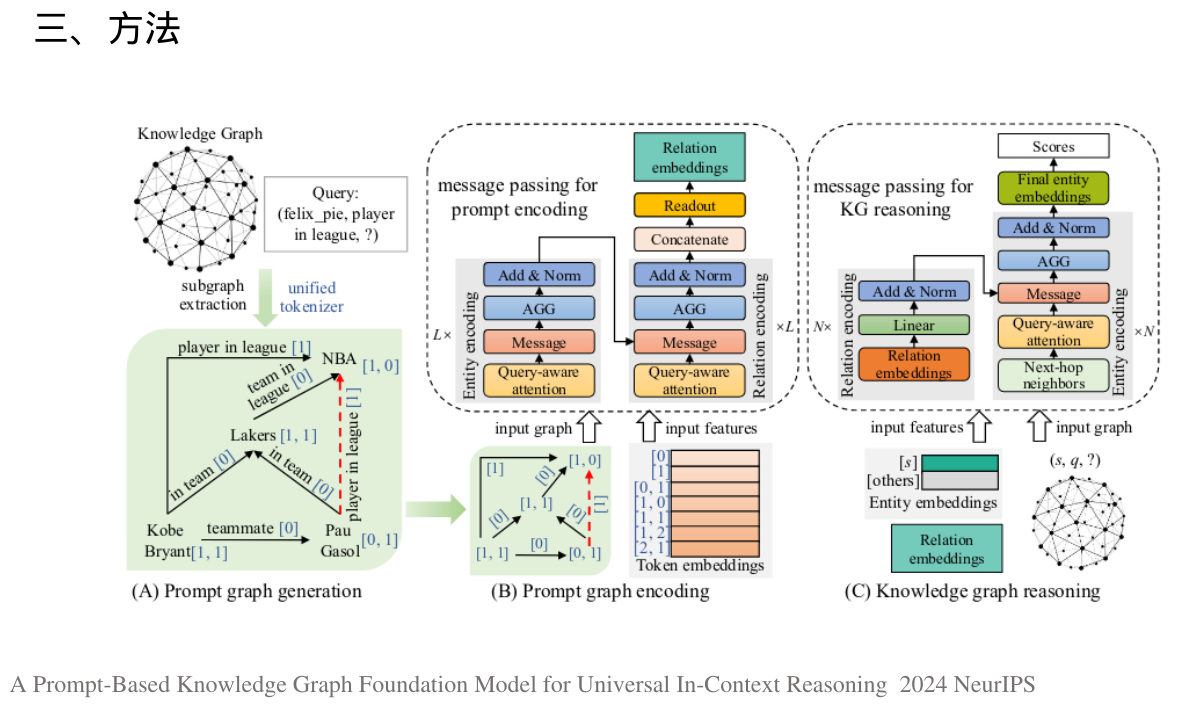
四、实验
五、结论