标签:#AI Agent #记忆系统 #MemGPT #Reflexion #大模型工程化 #智能体开发
前言
记忆是智能的基石。没有记忆的AI Agent,永远只是一个"一次性工具"------每次对话都从零开始,无法记住用户偏好、无法从过往经验中学习、无法完成复杂长任务。
2026年,AI Agent技术全面爆发,但记忆系统仍然是绝大多数开发者的核心痛点:
- 长对话上下文溢出,模型"失忆"、跟丢目标
- 简单的对话历史记忆,无法提取结构化知识
- 跨会话无法记住用户信息,每次都要重复解释
- 经验无法复用,同样的错误反复犯
- 记忆检索不准确,引入无关信息导致幻觉
本文将全面覆盖市面上所有主流AI Agent记忆系统,从最基础的对话缓冲记忆,到最前沿的分层记忆、反思记忆、知识图谱记忆,逐一拆解原理、优缺点、适用场景,并提供完整的横向对比和实战代码,一篇吃透AI Agent记忆系统的全部知识。
一、AI Agent 记忆系统核心分类体系
记忆系统不是单一的技术,而是一个完整的分层体系。不同的分类维度对应不同的工程设计和应用场景。
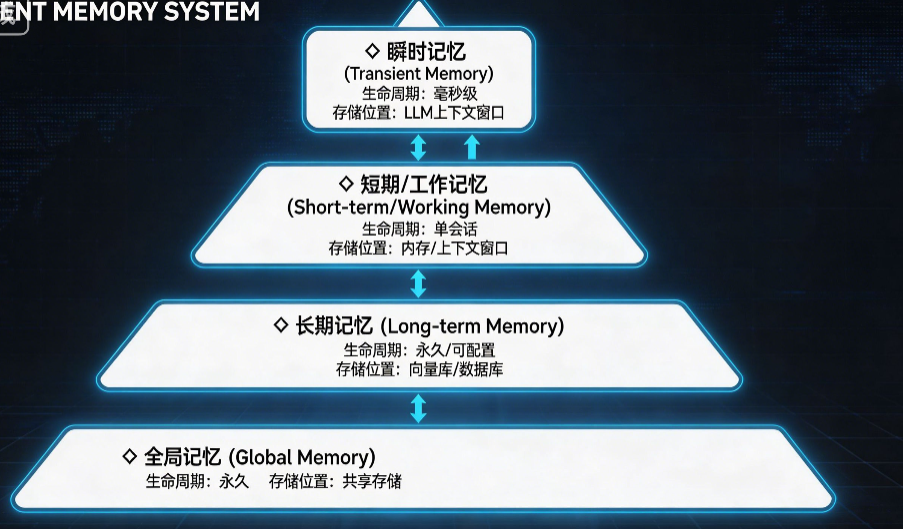
1.1 按生命周期与作用域分类(工程落地最常用)
这是工业界最实用的分类方式,直接指导架构设计:
| 分类 | 生命周期 | 作用域 | 存储位置 | 核心用途 |
|---|---|---|---|---|
| 瞬时记忆 | 毫秒级 | 当前推理步骤 | LLM上下文窗口 | 保存中间推理结果、工具返回值 |
| 短期/工作记忆 | 单会话 | 当前对话 | 内存/上下文窗口 | 保持单轮对话连贯性 |
| 长期记忆 | 永久/可配置 | 跨会话/跨用户 | 向量库/数据库/文件系统 | 记住用户偏好、历史经验、结构化知识 |
| 全局记忆 | 永久 | 所有Agent | 共享存储 | 多智能体协同、全局知识共享 |
1.2 按功能类型分类(心理学类比)
借鉴人类大脑的记忆机制,这是学术研究和前沿系统的主流分类:
- 工作记忆:当前正在处理的信息,容量有限、速度快
- 情景记忆:记录Agent的过往交互经历,带时间戳和上下文
- 语义记忆:从经验中蒸馏出的结构化事实和知识
- 程序记忆:可复用的技能、流程和行动规则
- 反思记忆:从失败中总结的经验教训和改进策略
1.3 按存储方式分类
- 参数记忆:编码在模型参数中,通过微调注入,更新成本高
- 上下文记忆:存储在LLM上下文窗口中,速度快但容量有限
- 外部记忆:存储在外部系统(向量库、数据库、文件),容量无限但有检索延迟
二、主流记忆系统详解(从基础到进阶)
2.1 基础对话记忆(LangChain系列)
这是最基础、最常用的记忆系统,所有Agent框架都内置支持,适合简单短对话场景。
2.1.1 ConversationBufferMemory(完整缓冲记忆)
核心原理:完整保存每一轮的"用户输入+模型回复",不做任何删减,直接拼接成上下文传入LLM。
优点 :实现简单、无信息丢失、无需额外计算
缺点 :长对话会导致上下文溢出、Token成本指数上升
适用场景:5轮以内的短对话、需要完整保留对话细节的场景(如客服咨询)
代码示例:
python
from langchain.memory import ConversationBufferMemory
# 初始化记忆
memory = ConversationBufferMemory()
# 保存对话历史
memory.save_context(
{"input": "我叫小明,喜欢编程"},
{"output": "你好小明!编程是一项很有趣的技能"}
)
# 加载记忆
print(memory.load_memory_variables({})["history"])2.1.2 ConversationBufferWindowMemory(滑动窗口记忆)
核心原理:只保存最近K轮对话,超出窗口的历史会被丢弃。
优点 :控制上下文长度、避免溢出、Token成本稳定
缺点 :会丢失较早的重要信息
适用场景:频繁交互的查询类任务(如天气、物流)、不需要长期记忆的场景
2.1.3 ConversationSummaryMemory(摘要记忆)
核心原理:不保存原始对话,而是定期用LLM将较早的对话内容生成摘要,用摘要代替原始内容。
优点 :大幅节省Token、支持更长对话
缺点 :依赖LLM摘要质量、会丢失细节、有额外计算成本
适用场景:中等长度对话、智能助理、长期交互场景
2.1.4 ConversationEntityMemory(实体记忆)
核心原理:自动从对话中提取实体(人、事、物)及其关系,结构化存储。
优点 :结构化知识、可扩展、支持复杂推理
缺点 :依赖实体提取准确度、实现复杂
适用场景:多主题、多角色的复杂交互场景
2.2 向量检索增强记忆(RAG记忆)
核心原理:将所有历史对话和知识向量化后存入向量数据库,当需要时,将当前查询向量化,检索最相关的历史片段注入上下文。
这是目前工业界最主流的长期记忆实现方案,解决了基础对话记忆容量有限的问题。
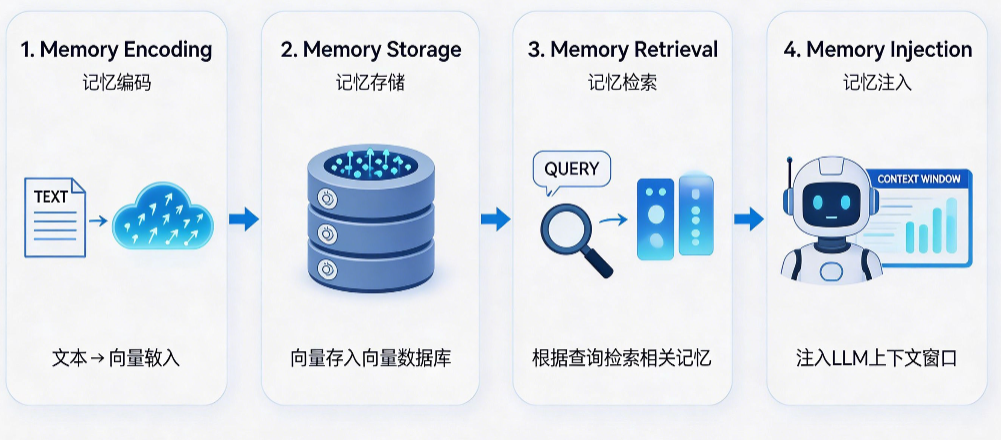
工作流程:
- 记忆编码:将对话历史、文档等文本转换为向量嵌入
- 记忆存储:将向量和原始文本存入向量数据库
- 记忆检索:根据当前查询,检索语义最相似的Top-K条记忆
- 记忆注入:将检索到的记忆拼接成上下文传入LLM
优点 :支持海量长期记忆、跨会话检索、实现相对简单
缺点 :检索精度依赖嵌入质量、可能引入无关信息、缺乏结构化理解
适用场景:文档问答、知识库助手、需要跨会话记住大量信息的场景
2.3 分层记忆系统(MemGPT)
核心原理:借鉴操作系统虚拟内存管理思想,将记忆分为多层,模拟人类大脑的记忆机制,解决上下文窗口有限的问题。
MemGPT是分层记忆的开创者,将记忆分为三层:
- 核心记忆(Core Memory):总是存在于LLM上下文中,存储最重要的信息(如用户身份、核心偏好、当前目标),容量KB级
- 回忆记忆(Recall Memory):可搜索的对话历史,存储所有过往交互,容量GB级
- 归档记忆(Archival Memory) :长期存储的知识和经验,容量无限
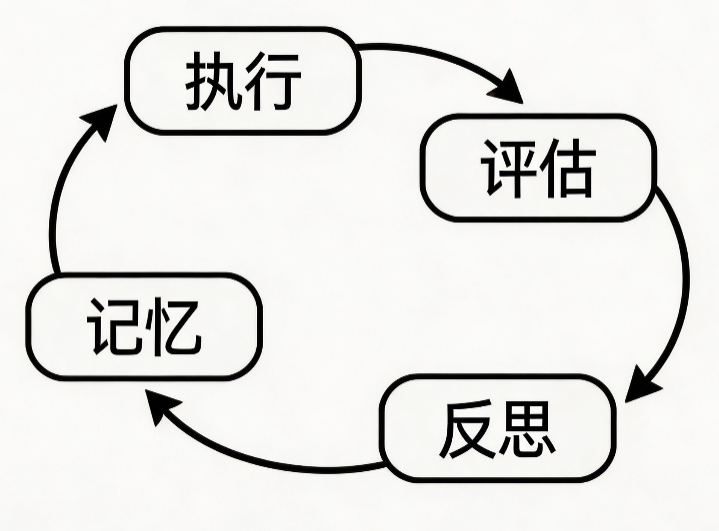
工作流程:
- 用户输入进入系统
- 自动将核心记忆注入上下文开头
- 根据用户输入,从回忆记忆和归档记忆中检索相关片段
- 将检索到的记忆注入上下文中间
- LLM基于增强后的上下文生成回复
- 自动将新对话存入回忆记忆,LLM可主动编辑核心记忆
优点 :用极低的成本支持百万级Token的长期记忆、跨会话能力强、支持自主记忆编辑
缺点 :实现复杂、检索和换入换出有延迟
适用场景:超长对话、个人数字助理、需要持续学习的Agent
2.4 反思记忆(Reflexion)
核心原理 :让Agent能够从失败中学习,将错误原因和改进策略总结成"经验教训"存入长期记忆,下次遇到类似任务时作为上下文传入,避免重蹈覆辙。
这是让Agent具备"自我进化"能力的关键技术。
工作流程:
- Agent执行任务
- 评估器评估任务执行结果
- 如果失败,反思模块总结失败原因和改进策略
- 将反思结果存入长期记忆
- 下次执行类似任务时,自动带上历史经验教训
代码示例:
python
class ReflexionAgent:
def __init__(self, base_agent):
self.base_agent = base_agent
self.reflection_memory = [] # 存储经验教训
def run(self, task):
# 带上历史教训
context = f"历史经验教训:{self.reflection_memory}\n当前任务:{task}"
# 执行任务
result = self.base_agent.run(context)
# 评估结果
if not self.evaluate(result):
# 总结教训并记忆
lesson = self.summarize_lesson(task, result)
self.reflection_memory.append(lesson)
# 带着教训重试
result = self.base_agent.run(context + f"\n本次教训:{lesson}")
return result优点 :显著提升复杂任务成功率、让Agent从经验中学习、减少重复错误
缺点 :需要额外的评估和反思步骤、增加推理时间
适用场景:复杂推理、代码生成、多步骤任务、需要高成功率的场景
2.5 知识图谱记忆
核心原理:将记忆以"实体-关系-实体"三元组的形式存储在知识图谱中,支持结构化查询和推理。
与向量记忆不同,知识图谱记忆能够理解知识之间的关系,支持更复杂的逻辑推理。
优点 :结构化知识、支持复杂推理、可解释性强、易于更新和维护
缺点 :实体和关系提取难度大、构建成本高、不适合非结构化文本
适用场景:需要复杂知识推理的场景、企业知识库、专家系统
2.6 多模态记忆
核心原理:不仅存储文本信息,还能存储和检索图片、视频、音频等多模态数据。
随着多模态大模型的发展,多模态记忆成为Agent的必备能力。
优点 :支持多模态交互、能够理解和记忆视觉、听觉信息
缺点 :多模态嵌入和检索技术复杂、存储成本高
适用场景:多模态助手、视觉Agent、视频分析Agent
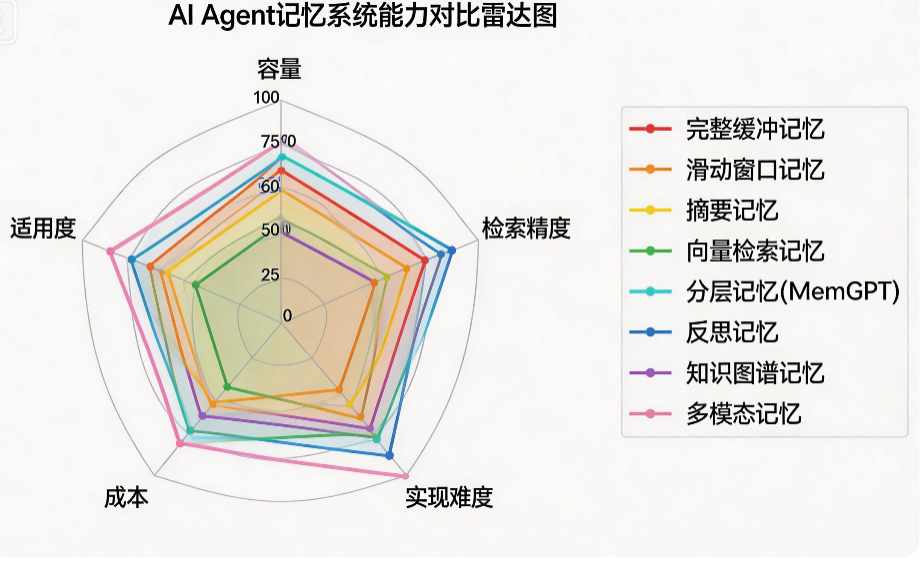
三、主流记忆系统横向对比(2026最新)
| 记忆系统 | 核心原理 | 容量 | 检索精度 | 实现难度 | 成本 | 适用场景 |
|---|---|---|---|---|---|---|
| 完整缓冲记忆 | 保存全部对话 | 小(受上下文限制) | 极高 | 极低 | 高(长对话) | 短对话、客服咨询 |
| 滑动窗口记忆 | 保存最近K轮 | 小 | 高 | 极低 | 低 | 简单查询、频繁交互 |
| 摘要记忆 | 对话摘要 | 中 | 中 | 低 | 中 | 中等长度对话、智能助理 |
| 向量检索记忆 | 语义相似性检索 | 大 | 中 | 中 | 中 | 文档问答、知识库助手 |
| 分层记忆(MemGPT) | 多层级虚拟内存 | 极大 | 高 | 高 | 低 | 超长对话、个人助理 |
| 反思记忆 | 经验教训总结 | 大 | 极高 | 高 | 中 | 复杂推理、代码生成 |
| 知识图谱记忆 | 结构化三元组 | 大 | 极高 | 极高 | 高 | 复杂知识推理、专家系统 |
| 多模态记忆 | 多模态嵌入检索 | 大 | 中 | 极高 | 高 | 多模态交互、视觉Agent |
四、工程落地中的常见问题与优化方案
4.1 记忆检索不准确问题
现象 :检索到无关的历史信息,导致模型产生幻觉或给出错误答案
解决方案:
- 使用更高质量的嵌入模型
- 增加元数据过滤(如时间戳、用户ID、会话ID)
- 采用混合检索(关键词+语义)
- 对检索结果进行重排序
4.2 上下文溢出问题
现象 :长对话或大量记忆注入导致上下文窗口溢出
解决方案:
- 采用分层记忆架构
- 对记忆进行摘要和压缩
- 动态调整注入的记忆数量
- 使用支持更大上下文窗口的模型
4.3 记忆一致性问题
现象 :记忆中存在矛盾的信息,导致模型行为不一致
解决方案:
- 实现记忆冲突检测和解决机制
- 定期更新和验证记忆
- 给记忆添加时间戳,优先使用最新信息
4.4 记忆遗忘问题
现象 :重要的历史信息被遗忘或无法检索到
解决方案:
- 实现重要性评分机制,优先保留重要记忆
- 定期对记忆进行巩固和重排
- 采用混合存储架构,重要信息存入核心记忆
五、实战:从零实现一个简单的分层记忆Agent
python
from dotenv import load_dotenv
import os
from openai import OpenAI
import json
load_dotenv()
client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_API_BASE")
)
class SimpleLayeredMemoryAgent:
def __init__(self):
# 核心记忆:总是存在于上下文中
self.core_memory = {
"user_name": "用户",
"preferences": [],
"current_goal": ""
}
# 长期记忆:存储历史对话和经验
self.long_term_memory = []
def add_to_long_term_memory(self, user_input, assistant_output):
"""添加对话到长期记忆"""
self.long_term_memory.append({
"user": user_input,
"assistant": assistant_output
})
def retrieve_relevant_memory(self, query, top_k=3):
"""从长期记忆中检索相关内容"""
# 简单的关键词检索(实际项目中使用向量检索)
relevant = []
for mem in self.long_term_memory:
if any(word in mem["user"] or word in mem["assistant"] for word in query.split()):
relevant.append(mem)
return relevant[-top_k:]
def run(self, user_input):
# 检索相关记忆
relevant_memory = self.retrieve_relevant_memory(user_input)
# 构建上下文
context = f"核心记忆:{json.dumps(self.core_memory, ensure_ascii=False)}\n"
if relevant_memory:
context += "相关历史对话:\n"
for mem in relevant_memory:
context += f"用户:{mem['user']}\n助手:{mem['assistant']}\n"
context += f"\n用户当前输入:{user_input}\n助手:"
# 生成回复
response = client.chat.completions.create(
model="qwen-turbo",
messages=[{"role": "user", "content": context}],
temperature=0.7
)
output = response.choices[0].message.content
# 保存对话到长期记忆
self.add_to_long_term_memory(user_input, output)
return output
# 测试
if __name__ == "__main__":
agent = SimpleLayeredMemoryAgent()
print(agent.run("你好,我叫小明"))
print(agent.run("我喜欢编程"))
print(agent.run("你还记得我叫什么吗?我喜欢什么?"))六、未来发展趋势
- 多模态记忆融合:统一存储和检索文本、图片、视频、音频等多模态信息
- 自主记忆管理:Agent能够自主判断什么信息重要、应该记住什么、应该忘记什么
- 记忆推理与生成:不仅能检索记忆,还能基于记忆进行推理和生成新的知识
- 多智能体共享记忆:多个Agent能够共享和协作更新同一个记忆库
- 神经符号混合记忆:结合神经网络的泛化能力和符号系统的精确性
七、总结
AI Agent记忆系统正在从简单的对话历史存储,向结构化、多层次、可推理、可进化的方向快速发展。
- 简单场景:使用基础对话记忆即可满足需求
- 需要长期记忆:优先选择向量检索增强记忆
- 超长对话和个人助理:采用分层记忆架构(如MemGPT)
- 复杂任务和自我进化:加入反思记忆能力
- 需要复杂知识推理:考虑知识图谱记忆
选择合适的记忆系统,是开发稳定、高效、智能的AI Agent的关键。没有最好的记忆系统,只有最适合特定场景的记忆系统。
原创干货,点赞收藏,后续持续更新Agent记忆系统的工程化落地和前沿技术!