前言
前面我们学了思维链(让模型学会思考)和 Few-shot/Zero-shot(让模型理解任务)。但还有一个关键问题没解决:模型思考完之后,输出的东西怎么让程序稳定地解析? 如果模型的回答是一段自由文本,程序很难从中精准提取"意图是什么""参数有哪些"。这就是结构化输出要解决的核心问题。
什么是结构化输出?
结构化输出 是指:让 LLM 按照预定义的格式(如 JSON、XML、YAML 或自定义语法)生成内容,并且确保输出严格符合该格式。
关键点:
- 格式预定义:开发者事先声明"我要什么结构"。
- 强制符合:不是"建议",而是"必须"。
- 程序可解析:输出可以直接被
json.loads()或 XML 解析器处理,无需人工清洗。
为什么需要结构化输出?
大语言模型(LLM)本质是概率性的文本生成器。你问它一个问题,它返回的是自然语言。
这在聊天场景没问题。但在工程化应用中,我们需要把 LLM 集成到自动化系统里,例如:
- 从发票中提取"金额、日期、供应商"并存入数据库
- 让 LLM 决定调用哪个 API,并生成参数
- 多个 Agent 之间交换信息
这时候自然语言就不行了:它不稳定、难解析、字段可能缺失、格式随机。
核心痛点:LLM 输出不可控,程序无法可靠消费。
非结构化输出的解析成本与风险
如果依赖非结构化输出(自由文本),你需要面对三个成本:
成本一:解析代码的复杂度爆炸
你需要写大量正则、规则来覆盖模型可能的各种表达方式。模型今天说"调用 create_inspection_task",明天说"我需要执行 create_inspection_task 功能",后天说"让我来帮你创建巡检任务"。每种变体都需要规则去匹配,规则数量很快失控。
成本二:解析失败的级联影响
一次解析失败,整个后续链路都断掉。行动组件拿不到工具名,工具调不出去;工具调不出去,任务卡死;任务卡死,用户等不到回复。一个格式问题能导致全链路崩溃。
成本三:非结构化输出的幻觉更难检测
模型在自由文本中可能混入看似合理但错误的信息。结构化输出中,如果模型输出 {"intent": "delete_all_tasks"},程序可以直接校验这个意图是否在允许列表中。自由文本里,同样的危险意图可能藏在礼貌用语中,很难被规则匹配到。
结论:在生产级智能体系统中,推理组件与行动组件之间的接口必须是结构化的。这是系统各模块能够可靠协作的前提。
格式约束的层级
不是所有场景都需要最严格的 JSON。结构化程度越高,对模型的要求越高,实现成本也越高。根据需求选择合适的约束层级,是工程上的重要权衡。
自由文本(无约束)
形态:模型输出纯自然语言,没有任何格式限制。
示例:
我建议您创建巡检任务,时间是明天上午。适用场景:
- 聊天机器人的闲聊回复
- 对用户直接展示的文本(不需要程序解析)
- 创意写作、开放式问答
优点:模型最自然,生成质量最高,Token 消耗最少。
缺点:程序无法可靠解析,完全不适合机器消费。
标记分隔格式
形态:用特定的标记(如 XML 标签、Markdown 标题、自定义分隔符)把不同语义的部分分开。
示例(XML 标签):
xml
<reasoning>用户想创建巡检任务,时间是明天上午。</reasoning>
<action>create_inspection_task</action>
<params>
<time>2026-06-08T09:00</time>
</params>示例(Markdown 标题):
shell
### 推理
用户想要创建一个明天上午的巡检任务。
### 动作
create_inspection_task
### 参数
- time: 2026-06-08T09:00适用场景:
- 需要同时展示给人类和程序消费的内容
- 输出中既有自由文本也有结构化数据
- 模型对纯 JSON 输出不够稳定的过渡方案
优点:在自然语言和结构化之间取得平衡。人类可读,程序可以用标签作为锚点解析。
缺点:仍需写解析逻辑,标签可能出现嵌套错误或遗漏,格式稳定性不如纯 JSON。
严格结构化格式
形态:模型只输出一个合法的 JSON 或 YAML 对象,不包含任何额外文字。
json
{
"intent": "create_inspection_task",
"confidence": 0.95,
"slots": {
"time": "2026-06-08T09:00",
"task_type": null
}
}适用场景:
- 工具调用(Function Calling)
- 意图识别结果
- 槽位提取结果
- 任何需要被下游程序直接消费的接口
优点:解析极简单,json.loads 一行代码完成。格式可被 JSON Schema 验证,非法输出能被程序立即检测。 缺点:对模型能力要求高,弱模型可能输出非法 JSON(少引号、多逗号、嵌套错误)。约束越强,模型生成质量可能略有下降(模型在"分心"处理格式)。
各层级的适用场景与选择
| 场景 | 推荐格式 | 理由 |
|---|---|---|
| 对用户展示的最终回复 | 自由文本 | 人类消费,不需要解析 |
| 需要同时展示和解析 | 标记分隔格式 | 兼顾可读性和可解析性 |
| 工具调用、意图识别 | 严格 JSON | 程序消费,必须稳定解析 |
| 弱模型、快速原型 | 标记分隔格式 | 比 JSON 容易让模型遵循,解析难度尚可 |
| 强模型、生产环境 | 严格 JSON | 解析零风险,配合受限解码几乎不出错 |
常见的结构化输出格式
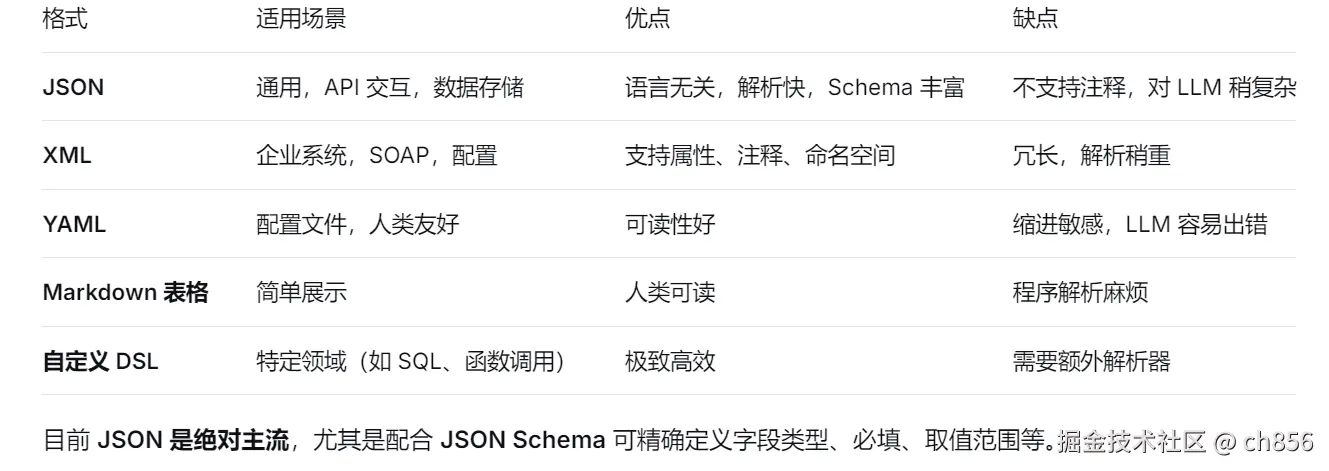
实现结构化输出的技术演进
方式一:提示词约束(最浅,最不稳定)
思路:在提示词中用自然语言描述期望的输出格式,不提供示例。
diff
请以 JSON 格式输出,必须包含以下字段:
- intent(字符串):用户意图
- confidence(浮点数):0-1 的置信度
- slots(对象):提取的参数
只输出 JSON,不要包含其他任何文字。效果:依赖模型的指令遵循能力。强模型能做到 80-90% 的格式正确率,弱模型可能只有 50-60%。
优点:零成本,不占用额外 Token。
缺点:格式正确率不稳定,尤其是字段多、嵌套深的时候。
方式二:JSON 模式(JSON Mode,中等可靠性)
思路:在提示词中提供 2-3 个完整示例,每个示例严格遵循期望的 JSON 格式。
css
示例1:
用户: 帮我建一个明天上午的巡检任务
输出: {"intent": "create_inspection_task", "slots": {"time": "2026-06-08T09:00"}}
示例2:
用户: 查看6月7号的巡检任务数量
输出: {"intent": "query_inspection_task_count", "slots": {"date": "2026-06-07"}}
现在请处理以下用户输入,只输出JSON:
用户: {user_input}
输出:效果:格式正确率可以提升到 90-98%(取决于模型能力)。
优点:比纯描述效果好很多,是当前最常用的方案。
缺点:占用额外 Token;如果示例的 JSON 结构和实际期望有细微出入,模型可能模仿错误。
方式三:API 级别的 response_format 参数
思路:直接使用 LLM API 提供的结构化输出功能。
lua
response = client.chat.completions.create(
model="gpt-4o",
messages=[...],
response_format={
"type": "json_schema",
"json_schema": {
"name": "intent_result",
"schema": {
"type": "object",
"properties": {
"intent": {"type": "string"},
"confidence": {"type": "number"},
"slots": {"type": "object"}
},
"required": ["intent", "confidence", "slots"]
}
}
}
)效果:格式正确率接近 100%,由 API 提供方在服务端保证。
优点:最简单,不需要额外库,不需要手动设置受限解码。
缺点:仅部分 API 支持(GPT-4o、GPT-4-turbo 等较新模型);Schema 复杂度有限制;不跨模型通用。
方式四:约束解码(Constraint Decoding,最深,最可靠)
思路:在模型生成每个 token 时,通过修改输出概率分布,强制将不符合格式要求的 token 概率置为零,确保每一步生成的 token 都在合法范围内。
原理:
- 定义输出格式的 Schema(如 JSON Schema)。
- 在模型生成时,每一步都根据 Schema 计算出当前允许生成的 token 列表。
- 将非法 token 的概率置零,模型只能从合法 token 中选择。
效果:格式正确率接近 100%。只要 Schema 定义对了,模型不可能输出非法 JSON。
实现方式:
- guidance 库(微软):用模板语法定义输出结构,支持 JSON、自定义语法。
- outlines 库:基于正则表达式或 JSON Schema 做受限生成。
- llama.cpp 的 grammar 功能:通过 GBNF 语法约束输出。
技术原理深挖(约束解码)
传统 LLM 生成(采样):
输入 → 模型 → 计算所有词元概率 → 采样一个词元 → 追加到输入 → 循环约束解码
输入 → 模型 → 计算所有词元概率 → 用 FSM 过滤非法词元 → 从合法词元中采样 → 追加 → 更新 FSM 状态 → 循环
格式解析的鲁棒性工程
无论用哪种手段,都不可能保证 100% 的格式正确率。生产系统必须有一层健壮的兜底解析,确保偶尔的格式错误不会导致全链路崩溃。
常见解析失败模式
模式一:JSON 外有额外文字
json
好的,我已经理解了您的需求。
{"intent": "create_inspection_task", "slots": {...}}
请问还有其他需要吗?模型在 JSON 前后加了礼貌用语。直接 json.loads 会报错。
模式二:JSON 内部语法错误
css
{"intent": "create_inspection_task", "slots": {"time": "明天上午", }}多了一个尾逗号。或者少了一个引号、用了中文引号、嵌套层次错误。
模式三:字段缺失或名称不对
css
{"action": "create_inspection_task", "params": {"time": "..."}}字段名写成了 action 而不是 intent,params 而不是 slots。虽然语义正确,但 Schema 校验不通过。
模式四:值类型不对
json
{"intent": "create_inspection_task", "confidence": "0.95"}confidence 应该是数字,模型输出成了字符串。
正则兜底与自动修复
策略一:JSON 提取
先不管模型在 JSON 外面加了什么,用正则把 JSON 部分提取出来:
python
import re
import json
def extract_json(text):
# 尝试匹配最外层大括号
match = re.search(r'{.*}', text, re.DOTALL)
if match:
return match.group(0)
return text这解决了"JSON 外有额外文字"的问题。
策略二:自动修复
提取出 JSON 字符串后,尝试修复常见语法错误:
python
import json
def safe_json_parse(text, max_attempts=3):
for attempt in range(max_attempts):
try:
return json.loads(text)
except json.JSONDecodeError as e:
text = attempt_fix(text, e)
return None
def attempt_fix(text, error):
# 尝试修复:去掉尾逗号
text = re.sub(r',\s*}', '}', text)
text = re.sub(r',\s*]', ']', text)
# 尝试修复:中文引号转英文
text = text.replace('\u201c', '"').replace('\u201d', '"')
# 尝试修复:单引号转双引号(需谨慎,可能在字符串内部)
# ...
return text策略三:LLM 二次解析
如果规则修复都失败了,把原始输出发回给 LLM,让它重新输出正确格式:
javascript
以下内容无法被JSON解析,请将其中的关键信息提取为合法的JSON:
{原始输出}
只输出JSON:这是兜底中的兜底。增加一次额外的 LLM 调用,成本和延迟都上升,但能救回大部分格式错误。
解析失败后的重生成闭环
当所有兜底都失败时,进入重生成流程:
makefile
第一次生成 → 解析失败 → 尝试修复 → 仍失败
│
▼
第二次生成(带错误反馈):
提示词中加入: "你上次的输出无法解析。请严格只输出JSON,不要包含任何其他文字。"
│
├── 成功 → 返回结果 + 记录该次失败
│
└── 仍失败 → 第三次生成(切换模型或降级处理)
│
├── 成功 → 返回结果 + 告警
│
└── 仍失败 → 返回兜底回复 + 触发人工介入