1.从"数据接入"转向"系统供数"
在过去20年里,企业的数据工程主要围绕ETL(Extract-Transform-Load)展开:数据从各业务系统抽取、清洗、整合,然后进入数据仓库供分析使用。这种模式帮助企业构建了统一的数据视图,但随着AI技术的兴起,每个企业都在谈ai使用,但是在数据工程领域,还是做不出生产级别的 AI 应用。先看三个数字:

第一个数字是 8 倍 与 320 倍。这是 OpenAI 在 2025 年 12 月发布的真实数据。调研显示,过去一年 ChatGPT Enterprise 的周消息增长量增长了 8 倍,但每个组织的推理 Token 消耗量却增长了 320 倍!!!巨大的增长,第二个数字是 88%。麦肯锡在 2025 年 报告中指出,88% 的组织已经在至少一个业务场景中常规性地使用 AI 了。在今天,"我们在用 AI"这句话已经不再是差异化的优势,而变成了像"我们上云了"一样的常态。真正的残酷在于第三个数字:只有 23% 的企业在业务流程中做到了规模化应用,如果放到国内的话,这个数据还会更低。这三个数字放在一起,说明了一件事:AI 的使用已经不是问题,但 AI 的工程化才是竞争的焦点。
接模型在今天几乎是零门槛的,调个 API 下午就能跑起来。但要变生产力,门槛在模型周边的系统工程。我们过去为"人"设计的数据系统,和我们今天要给"模型"用的数据系统,压根就不是一回事情。我们需要重新搭建一条生产线,我在这里面给大家取了一个响亮的名字:AI 数据工厂。
2.数据消费者从"人"变成了"模型"
从传统的 ETL 到现在的 Agent,到底变了些什么?核心在于:数据消费者已经从"人"变成了"模型"。

旧范式(ETL → 报表):交付物是表、指标和批处理任务。消费者是运营人员、分析师、老板。只要报表准时、准确、稳定就行。
新范式(Context → Agent):交付物是上下文(Context)、能力(Skills)和反馈(Feedback)。模型不看固定报表,它是动态检索、工具调用、按需加载。你不能提前把数据都聚合好,你必须具备"访问能力",让模型在需要的时候自己去拿。
这种转变带来一个致命问题:静默失败(Silent Failure)。过去表变了,发个邮件通知分析师改代码就行。但下游的模型不会读邮件,一旦 Schema 变了,它会默默地给出看似合理但完全错误的答案。它不报错,它在"悄悄地变差",这比直接报错更危险。
举个比喻:过去的数据工厂像食品工厂,把原材料做成罐头放在货架上;现在的 AI 数据工程像食品供应链,你不知道客户最后要做哪道菜,你必须保证他要什么、什么时候要,你都能第一时间给到。
3.有必要上Agent?
很多团队在接触 AI 时,第一个问题就是"我们要不要上 Agent"。这个问题问错了。正确的问法是:当前的业务问题,用最简单的方案能解决吗?
根据复杂度从低到高,有三类解决方案:

-
RAG(解决「知道什么」):知识问答、文档检索、政策解释。胜负手是检索质量与来源可信度。典型场景:客服知识库 10 万+ 文档实时检索。
-
Workflow(解决「按流程做什么」):工单分流、对账检查、报告生成。胜负手是步骤清晰、流程可控。典型场景:财务月结从 T+3 压缩到 T+0.5。
-
Agent(解决「不确定中完成任务」):跨系统调查、采购建议、故障定位。胜负手是规划 + 工具 + 异常处理。典型场景:供应链异常自动诊断 + 建议 + 审批。
黄金原则:能用 RAG 解决的,不要上 Workflow;能用 Workflow 的,不要上 Agent。 为什么?第一是成本:Agent 链路越长,Token 消耗越大,延迟越高;第二是可评测性:RAG 只有命中率和相关性指标,Agent 的成功路径可能有几十条,极难判断好坏;第三是可控性:Agent 自由度越高,越容易出现越权访问、信息泄露等大事故。Anthropic 的官方文档也强调过:从能工作的最简单事情开始。
4.AI 数据工厂:六层架构拆解
无论选择哪条路径,都需要一个坚实的底层架构来支撑。以下是六层架构的完整拆解,每一层都有清晰的职责边界。核心思想:底层是数据工厂,上层是智能体;中间靠 Context、Skills、Harness 与 Eval 连接。不是一条 pipeline,而是一座 AI 数据工厂。

❝
第一层:Data Foundation · 数据基础层(可接入)
这是整栋大厦的地基,核心指标是可接入性。建议优先构建统一的数据目录(Data Catalog)和元数据管理平台。负责将企业内所有数据来源统一纳管:
-
结构化数据:关系型数据库、数仓(Hive、BigQuery、Snowflake)
-
非结构化数据:日志、文档、图片、音视频
-
业务系统接口:ERP、CRM、OA 的实时 API
-
SaaS 数据源:Salesforce、飞书、钉钉等第三方平台
❝
第二层:Contract / Semantics · 数据契约层(可信任)
具体包括:规格说明书。定义指标、权限、版本和兼容性,防止静默失败。这是从 ETL 到 AI 最容易被忽视、也最关键的一层。演讲者用一句话点出了它的本质:AI 链路最怕的不是显性报错,而是 schema 漂移带来的 慢慢变差。
我讲一个真实的故事:之前我们做一个 RAG 企业客服,准确率调到了 95%。某天突然掉到 60%,排查了两个礼拜,才发现上游把"客户等级"从"VIP/ 高级 / 一般"改成了枚举值"T1/T2/T3"。上游觉得这是个小优化,没通知任何人。下游模型匹配不到等级,就开始自己编、瞎掰,导致大量合理但错误的回答。
数据契约就是把数据模型当成 API 管。在构建阶段(Build-time)就要暴露漂移,不让变更流到生产中。一定要通过 CI/CD 强制执行,而不是靠人约束。
解决方案:把数据模型当 API 管。
就像微服务的接口有版本管理和 breaking change 协议一样,数据模型也需要:
-
Build-time Fail(构建阶段拦截):在 CI/CD 阶段检测 schema 漂移,不让问题流向生产。当数据模型发生变化时,构建直接失败,强迫工程师显式处理变更。
-
Versioning(版本化管理):对每次 breaking change 进行版本号管理,配合 changelog,让下游系统知道"什么变了、影响是什么"。
-
Compatibility(兼容性过渡):不硬切,给迁移窗口。新旧版本双写,灰度放量,出问题能回滚。
一个必须做到的具体定义: 每张数据表都应该有显式的 contract 声明------字段名、数据类型、取值范围、指标口径、权限范围。这不是文档,而是可执行的约束。
❝
第三层:Context Layer · 上下文工程层(可理解)
这一层的核心认知升级是:Context ≠ Prompt。内共识:Context Engineering(上下文工程)正在取代 Prompt Engineering(提示词工程)。
Prompt 只是极小的一部分。真正的上下文包含:系统角色、检索到的数据、工具描述、记忆(短期 / 长期 / 状态)、范例(Few-shot)和消息状态。
一个 LLM 的 Context Window 实际上由六个模块组成:
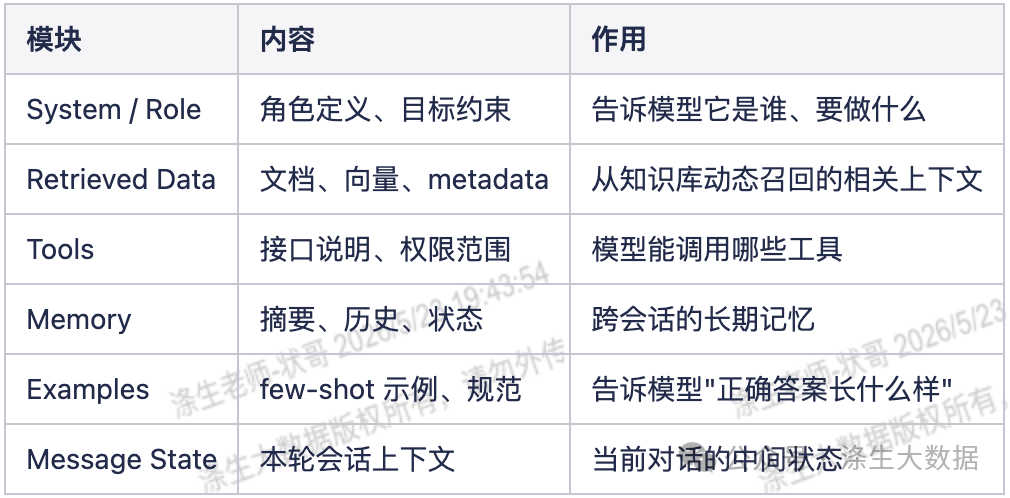
三条 Context Engineering 设计原则:
-
上下文要有限,不是越多越好。 塞满 Context Window 只会让模型的注意力分散。关键信息要精选,而不是堆砌。
-
工具 / 检索 / 策略必须分层组织。 不同类型的上下文有不同的更新频率和优先级,混在一起难以维护。
-
管理 attention budget,避免 context rot。 随着对话轮次增加,早期的上下文会"腐烂"------模型对远端内容的关注度会下降。需要主动压缩和淘汰过时内容。
此外,现代 Context 不只是 prompt 文本,还包括:通过 MCP 协议连接的外部资源、按需动态加载的 Skills、以及工具调用的中间结果。真正的竞争力,是你怎么组织上下文。
❝
第四层:Tools / Skills · 工具技能层(可复用)
这一层的认知升级是:企业真正的 AI 资产,不只是知识库,而是被封装出来的业务能力。Skills(技能) 是 2025 年底火起来的概念。Anthropic 推出了 Agent Skills 标准。Skills 就像文件夹,里面有元数据(Metadata)、指令集、工具适配器和输出规范。Skills 不是新名词,而是把业务逻辑封装成可复用、可评测、可审计的能力包。每个 Skill 由四个部分组成:
-
Metadata:这个 Skill 是什么,适合解决什么问题(相当于接口文档)
-
Instructions:触发后的执行逻辑(相当于业务规则代码)
-
Resources:所需的模板、规则、示例数据
-
Tools:实际调用的函数、脚本、外部接口
一个标准的 Skill 目录结构如下:
skill/ metadata.yaml # Skill 的描述和适用场景 instructions.md # 执行逻辑和决策规则 tool_adapter.py # 工具调用适配层 output_schema.json # 输出格式约束 examples/ # few-shot 示例 resources/ # 模板和规则文件
优先适合 Skill 化的五类场景:
-
订单异常诊断(高频、有明确判断规则)
-
指标归因分析(需要跨数据源、逻辑固定)
-
采购建议生成(需要结合历史数据和策略)
-
客服升级分流(有明确的触发条件和处理路径)
-
报告自动生成(模板固定、数据源稳定)
最佳实践:像管理微服务一样管理 Skill。 每个 Skill 有清晰的输入输出 Schema、有单元测试、有性能指标监控、有版本号。工具的质量,直接决定 Agent 的可靠程度。
❝
第五层:Orchestration / Harness · 编排治理层(可治理)
这一层的核心认知是:Prompt 决定智能体怎么说话,Harness 决定智能体怎么工作。管理着 10-20 个 Code Agent 帮他干活,离不开 Harness。
一个完整的 Agent 运行循环由四个阶段组成:
Planner(规划)→ Generator(执行)→ Evaluator(评估)→ Human / Gate(审批)
-
Planner:拆解任务、分配 Token 预算、定义验收标准。决定"要做什么"。
-
Generator:调用工具、生成草案、执行动作。决定"怎么做"。
-
Evaluator:检查执行结果、对照验收标准、决定是否返工(retry/reroute)。
-
Human / Gate:最终审批、兑底、发布。确保高风险操作必须有人签字。
六个必须实现的运行时控制点:
-
State(状态管理):跨步骤的中间状态存储,支持断点恢复
-
Budget(预算控制):Token 消耗和时间的硬限制,防止失控的无限循环
-
Retry(重试策略):指数退避、错误分类、限流配合,让失败可以优雅处理
-
Checkpoint(检查点):长任务的可恢复节点,避免从头重跑
-
Compaction(上下文压缩):主动压缩过长的 Context,防止 context rot
-
HITL(Human In The Loop):在关键决策点(如删除数据、触发资金、对外发送)强制人工确认
Harness 里至少要有:状态、预算、重试、检查点、人工审批与回放能力。缺了任何一个,Agent 在生产环境里都是一颗定时炸弹。
❝
第六层:Eval / Observability / Governance · 评测治理层(可评测)
这是整个架构的"质检车间",也是最容易被低估的一层没有评测的 AI 系统本质上只是玩具。测要分三层:
-
组件评测:单测检索召回率(Recall@K)、SQL 生成准确率、工具选择准确率。
-
任务评测:核心业务任务的成功率、业务 KPI 改善、人工满意度。
-
线上监控:答错反馈、Token 成本、响应延迟(P99)、人工接管率。
最关键的是建立 Quality Gate(发布门禁)。发布新版前,如果检索命中率低于阈值(比如 85%),或者工具误调用率高于 2%,就不允许发布。这让发布变成了严谨的工程操作,而不是"赌一把"。51% 的企业在 AI 落地中遇到过事故。治理必须在设计时内嵌。
六个支柱:最小权限(能只读绝不给删)、审计回放(Agent 行为不确定,必须能重现场)、策略前置、发布门禁、工具边界和 HITL 兜底。
-
Tracing(链路追踪):每一次 Agent 调用的完整执行链路,哪个工具被调用、耗时多少、返回什么
-
Monitoring(实时监控):成功率、延迟、Token 消耗、异常率的实时看板
-
Audit(操作审计):所有 Agent 操作的日志留存,满足合规要求
-
Release Gate(发布门禁):新版本 Agent 上线前,必须通过一组 Eval 测试集的评分门槛
-
Rollback(快速回滚):当线上 Agent 表现劣化时,能够在分钟级回滚到上一个稳定版本
没有 Eval,就没有工程化。 能够构建 Eval 框架、定义和衡量 Agent 质量,是这个时代最稀缺的工程能力。这是区分"AI 用户"与"AI 工程师"的真正分水岭。
5.落地路线图
竞争优势转向专有数据与 Skills 库:基础模型差距在缩小,护城河是你独有的数据、封装出来的 Skills 和那套工程系统。Agent 工程标准化:MCP 协议将成为 AI 的 USB 接口,实现跨平台复用。最稀缺的人才:系统串联者。能把数据、模型、工程、业务和治理拼在一起的人,是未来五年最值钱的角色。
阶段一:数据资产化(6-12 个月)
先把数据基础和契约层做扎实。建立统一数据目录,梳理指标口径,完成权限体系建设,引入数据契约框架(dbt contract 或 Great Expectations)。这不是 AI 工作,但它是 AI 工作的地基。没有可信的数据,任何 AI 应用都是空中楼阁。
阶段二:Context Engineering 与 RAG 落地(3-6 个月)
选择一个高频、低风险的业务场景,构建第一个 RAG 应用。重点不是模型选型,而是精细化管理:如何切片、如何检索、如何控制 attention budget。这个阶段会让团队深刻理解 Context Engineering 的工程挑战。
阶段三:Skill 化与 Agent 化(6-12 个月)
识别适合 Skill 化的业务场景(优先选高频、有明确规则的),完成第一批 Skill 的封装和测试。然后接入编排框架(LangGraph、AutoGen、Dify 等),构建第一个有业务价值的 Agent。重点投入在 Harness 层,特别是 HITL 机制、Checkpoint 和 Budget 控制。
阶段四:工程化与平台化(持续演进)
建立完整的 Eval 体系,构建内部的 Agent 开发平台,让业务团队能够低门槛地构建和部署自己的 Agent。这是真正意义上的智能生产线。
6.结语
企业不缺大模型,缺的是一座 AI 数据工厂。大模型本身只是一个原生态的东西,要让它变成生产力,需要的是一套标准化的软件工程。你要做的是:不再只是一个调 API 的人,而是成为一名 AI 生产系统的设计者。