什么是 RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了 信息检索 与 大语言模型 的技术框架。它旨在通过引入外部知识源,弥补大模型在事实性、时效性及私有化知识方面的短板。
虽然function-call、SystemMessage可以用来解决一部分问题,但是我们的上下文篇幅是有限的,不可能给他非常大篇幅的系统提示词以及用户信息。
如果你要提供大量的业务领域信息, 就需要给他外接一个知识库。
比如:
-
用户提问
"今天下午北京会下雨吗?"
-
建立外部知识库(提前准备)
气象部门把每天的天气预报写在了内部文档里。
系统会把这些文档读取 → 分词 → 向量化 → 存入向量数据库 。
这一步叫 Embedding(嵌入),相当于把"天气文档"变成AI能快速检索的索引。
-
检索相关信息
系统拿到你的问题后,去向量数据库中**搜索"北京 + 今天下午 + 下雨"**相关的内容。
-
增强上下文
把检索到的实时天气预报(例如:"下午14:00-18:00,阴天,降水概率20%")和你的原始问题拼在一起。
-
大模型生成回答
大模型根据检索到的真实气象数据回答:
"根据最新预报,今天下午北京不会下雨,但云量较多,降水概率只有20%。"
那么什么是向量呢??
向量通常用来做相似性搜索,比如语义的一维向量,可以表示词语或短语的语义相似性。例如,"你好"、"hello"和"见到你很高兴"可以通过一维向量来表示它们的语义接近程度。
但是对于更加复杂的,我们无法通过一个维度来进行相似度搜索,就需要建立多维的向量。比如我们需要提取多个特征,如颜色、大小、品种等,将每个特征表示为向量的一个维度,从而形成一个多维向量。
如果需要检索见过更加精准, 我们肯定还需要更多维度的向量, 组成更多维度的空间,在多维向量空间中,相似性检索变得更加复杂。我们需要使用一些算法,如余弦相似度或欧几里得距离,来计算向量之间的相似性。这些向量数据库会帮我实现。
文本向量化:
java
public class EmbeddingTest {
public static void main(String[] args) {
QwenEmbeddingModel embeddingModel= QwenEmbeddingModel.builder()
.apiKey()
.build();
Response<Embedding> embed = embeddingModel.embed("你好");
System.out.println(embed.content().toString());
System.out.println(embed.content().vector().length);
}
}引入
QwenEmbeddingModel 默认模型

这句话经过OpenAiEmbeddingModel向量化之后得到的一个长度为1536的float数组。注意,1536是固定的,不会随着句子长度而变化。
那么,我们通过这种向量模型得到一句话对应的向量有什么作用呢?非常有用,因为我们可以基于向量来判断两句话之间的相似度。
对于向量模型生成出来的向量,我们可以持久化到向量数据库,并且能利用向量数据库来计算两个向量之间的相似度,或者根据一个向量查找跟这个向量最相似的向量。
在LangChain4j中,EmbeddingStore表示向量数据库。例子我们采用简单的In-memory存储在JVM中的向量数据库。但是一般企业的话还是要存储在磁盘的比较好。
java
@Test
public void testWeatherRAG() {
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
QwenEmbeddingModel embeddingModel = QwenEmbeddingModel.builder()
.apiKey()
.build();
// 存入天气信息1:北京天气
TextSegment segment1 = TextSegment.from("""
北京天气预报:
- 日期:2026年6月6日(星期六)
- 上午:晴转多云,气温 24-28℃,降水概率 5%
- 下午:多云,气温 28-31℃,降水概率 10%
- 晚上:阴天,气温 22-27℃,降水概率 30%
- 风力:东南风 2-3 级
- 湿度:45%-60%
""");
Embedding embedding1 = embeddingModel.embed(segment1).content();
embeddingStore.add(embedding1, segment1);
// 存入天气信息2:上海天气
TextSegment segment2 = TextSegment.from("""
上海天气预报:
- 日期:2026年6月6日(星期六)
- 上午:小雨,气温 22-25℃,降水概率 70%
- 下午:中雨,气温 24-27℃,降水概率 85%
- 晚上:小雨转阴,气温 21-24℃,降水概率 60%
- 风力:东风 3-4 级
- 湿度:70%-85%
""");
Embedding embedding2 = embeddingModel.embed(segment2).content();
embeddingStore.add(embedding2, segment2);
// 存入天气信息3:广州天气
TextSegment segment3 = TextSegment.from("""
广州天气预报:
- 日期:2026年6月6日(星期六)
- 上午:雷阵雨,气温 26-29℃,降水概率 65%
- 下午:雷阵雨转大雨,气温 28-32℃,降水概率 90%
- 晚上:大雨,气温 25-28℃,降水概率 95%
- 风力:南风 2-3 级,阵风 5 级
- 湿度:75%-90%
""");
Embedding embedding3 = embeddingModel.embed(segment3).content();
embeddingStore.add(embedding3, segment3);
// 用户查询:今天下午北京的天气
Embedding queryEmbedding = embeddingModel.embed("今天下午北京会下雨吗?需要带伞吗?").content();
// 构建查询条件 - 召回最相关的 1 条天气信息
EmbeddingSearchRequest build = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1)
.build();
// 执行向量检索
EmbeddingSearchResult<TextSegment> result = embeddingStore.search(build);
result.matches().forEach(embeddingMatch -> {
System.out.println("相似度分数: " + embeddingMatch.score()); // 会输出类似 0.85 的分数
System.out.println("检索到的天气信息: \n" + embeddingMatch.embedded().text());
});
}maxResults 返回的结果数量
minScore 最小相似度阈值
filter 元数据过滤器,用于精确筛选
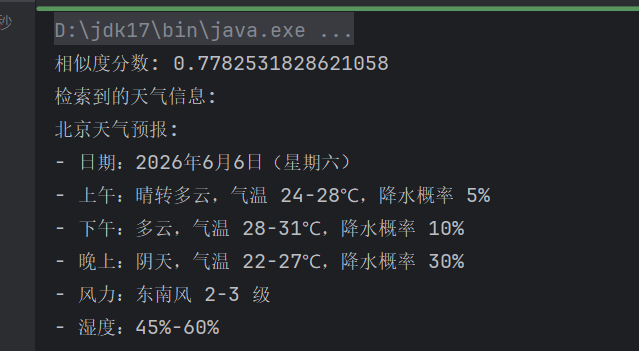
可以看到我们相似度分数以及检索到的天气信息就是北京。