【Java基础】IO 流(下):缓冲流、转换流、序列化与综合案例
-
- 概念入口
- [一、先看 IO 下篇的整体地图](#一、先看 IO 下篇的整体地图)
-
- [1.1 基础流和增强流的关系](#1.1 基础流和增强流的关系)
- [1.2 一句话抓住主线](#1.2 一句话抓住主线)
- 二、缓冲流:让读写更高效
-
- [2.1 为什么需要缓冲流](#2.1 为什么需要缓冲流)
- [2.2 字节缓冲流](#2.2 字节缓冲流)
- [2.3 用字节缓冲流复制文件](#2.3 用字节缓冲流复制文件)
- [2.4 字符缓冲流](#2.4 字符缓冲流)
- [2.5 字符缓冲流适合什么场景](#2.5 字符缓冲流适合什么场景)
- 三、转换流:解决编码和乱码问题
-
- [3.1 先理解编码和解码](#3.1 先理解编码和解码)
- [3.2 为什么 FileReader / FileWriter 容易埋坑](#3.2 为什么 FileReader / FileWriter 容易埋坑)
- [3.3 InputStreamReader:字节输入流到字符输入流的桥梁](#3.3 InputStreamReader:字节输入流到字符输入流的桥梁)
- [3.4 OutputStreamWriter:字符输出流到字节输出流的桥梁](#3.4 OutputStreamWriter:字符输出流到字节输出流的桥梁)
- [3.5 综合小练习:GBK 文本转 UTF-8](#3.5 综合小练习:GBK 文本转 UTF-8)
- 四、序列化:把对象保存到文件
-
- [4.1 什么是序列化和反序列化](#4.1 什么是序列化和反序列化)
- [4.2 ObjectOutputStream 写出对象](#4.2 ObjectOutputStream 写出对象)
- [4.3 ObjectInputStream 读取对象](#4.3 ObjectInputStream 读取对象)
- [4.4 serialVersionUID 是什么](#4.4 serialVersionUID 是什么)
- [4.5 transient:不想保存的字段](#4.5 transient:不想保存的字段)
- [4.6 序列化多个对象](#4.6 序列化多个对象)
- 五、打印流:更方便地输出数据
-
- [5.1 PrintStream 是什么](#5.1 PrintStream 是什么)
- [5.2 写入文件](#5.2 写入文件)
- [5.3 改变 System.out 的输出位置](#5.3 改变 System.out 的输出位置)
- [六、压缩流与解压缩流:简单认识 zip 文件](#六、压缩流与解压缩流:简单认识 zip 文件)
-
- [6.1 核心类](#6.1 核心类)
- [6.2 压缩单个文件](#6.2 压缩单个文件)
- [6.3 解压 zip 文件](#6.3 解压 zip 文件)
- [七、IO 综合案例:文本排序并转换编码](#七、IO 综合案例:文本排序并转换编码)
-
- [7.1 需求说明](#7.1 需求说明)
- [7.2 实现代码](#7.2 实现代码)
- [7.3 这个案例值得记什么](#7.3 这个案例值得记什么)
- 八、常见误区速查表
- 总结

🎬 博主名称: 超级苦力怕
🔥 个人专栏: 《Java 后端修炼手册》《Java 基础语言》
🚀 每一次思考都是突破的前奏,每一次复盘都是精进的开始!
文章元信息:
- 适合读者: 已经学过 File、字节流、字符流,想继续理解缓冲流、编码、序列化和常见 IO 综合写法的 Java 初学者
- 前置知识: 建议先读《IO 流(上):File、字节流与字符流》,理解 File、字节流、字符流和 try-with-resources 的基本用法
概念入口
IO 流上篇解决的是 IO 入门三件事:文件路径怎么表示,字节流怎么复制文件,字符流怎么读写文本。那一篇的重点是"能跑起来"。
本文开始进入 IO 的进阶部分:为什么实际开发更常见缓冲流?为什么文本一遇到中文就可能乱码?怎样明确指定 UTF-8 或 GBK?对象为什么能写入文件?压缩包又是怎么一项一项写进去的?这些内容不追求一次讲完整个 IO 体系,而是帮助把 Java 常见 IO 工具串成一张能用的地图。
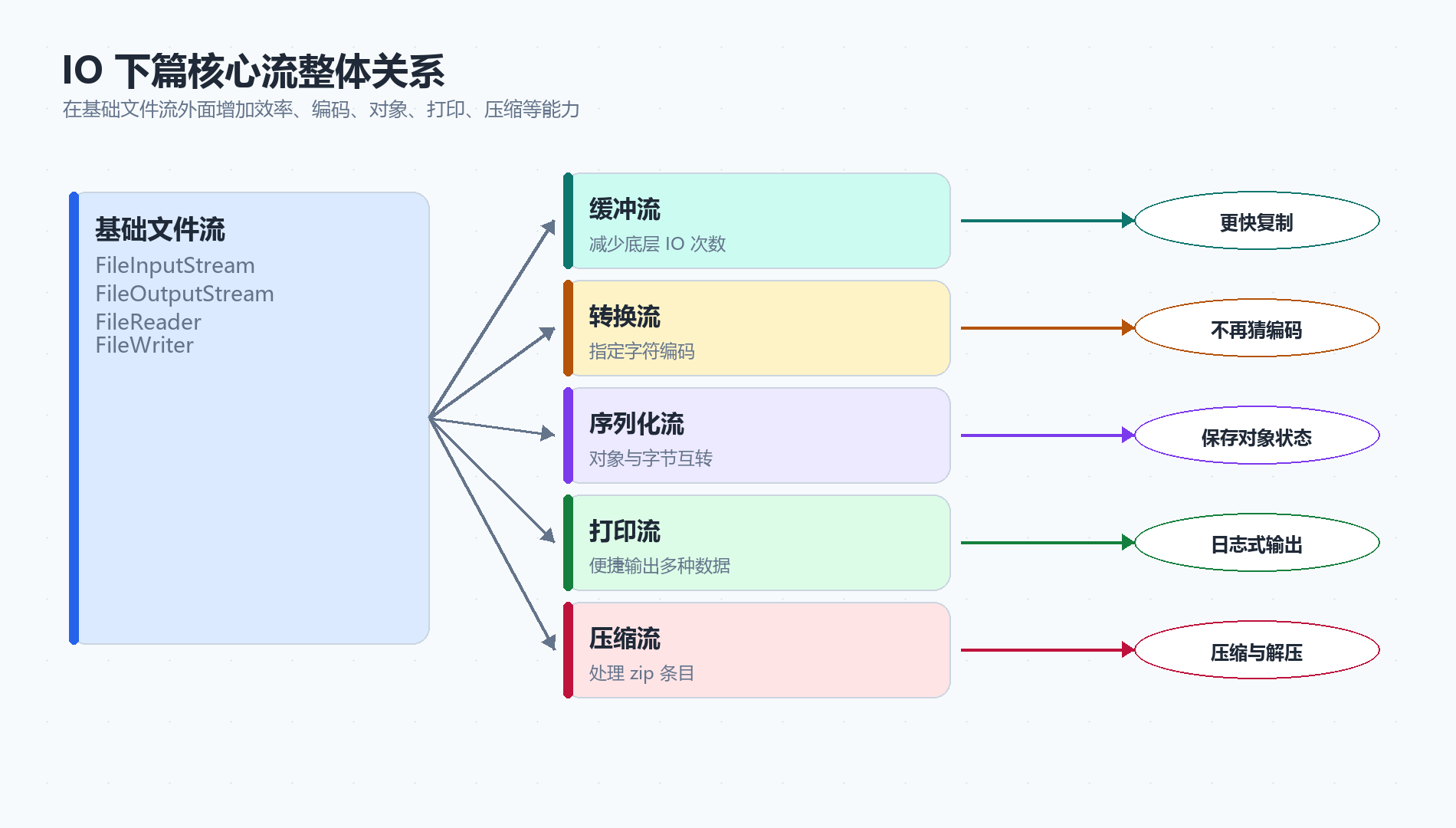
一、先看 IO 下篇的整体地图
1.1 基础流和增强流的关系
在 IO 上篇里,已经见过四个最基础的文件流:
| 类型 | 输入 | 输出 |
|---|---|---|
| 字节流 | FileInputStream |
FileOutputStream |
| 字符流 | FileReader |
FileWriter |
这些流可以直接读写文件,但实际开发中,经常会在它们外面再套一层"增强能力":
| 增强目标 | 常用类 | 解决什么问题 |
|---|---|---|
| 提高读写效率 | BufferedInputStream、BufferedOutputStream、BufferedReader、BufferedWriter |
减少频繁访问磁盘或底层流 |
| 指定字符编码 | InputStreamReader、OutputStreamWriter |
解决 UTF-8、GBK 等编码不一致导致的乱码 |
| 保存对象 | ObjectOutputStream、ObjectInputStream |
把对象转成字节保存,再恢复成对象 |
| 方便打印 | PrintStream、PrintWriter |
更方便地输出各种类型的数据 |
| 处理压缩包 | ZipInputStream、ZipOutputStream |
读取或写入 zip 压缩包条目 |
1.2 一句话抓住主线
主线可以这样理解:
- 缓冲流:让读写更高效。
- 转换流:让字节和字符之间按指定编码转换。
- 序列化流:让对象变成字节,保存到文件中。
- 打印流:让输出更方便。
- 压缩流:让文件进入或离开 zip 压缩包。
💡 核心结论: IO 下篇不是推翻上篇,而是在上篇基础流之上继续增强。可以把基础流理解成"通道",把缓冲流、转换流、序列化流理解成"套在通道上的功能层"。
二、缓冲流:让读写更高效
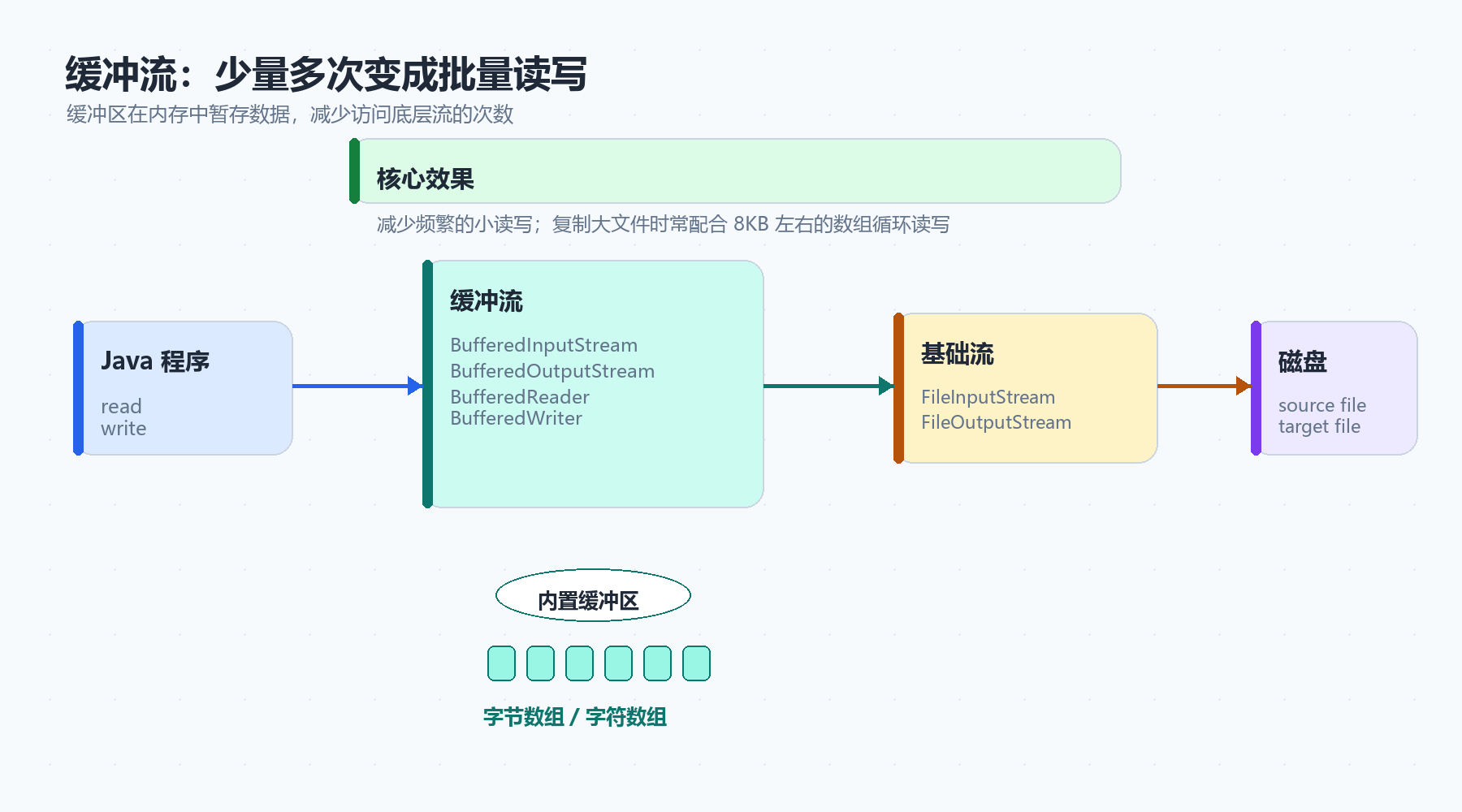
2.1 为什么需要缓冲流
普通流每次读写都可能和底层文件系统打交道。如果数据量很大,频繁的小读写会让效率变低。
缓冲流的思路很朴素:
先把一批数据放进内存缓冲区,再统一读写,减少底层 IO 次数。
就像搬书:
- 一次搬一本,也能搬完,但很慢。
- 一次抱一摞,再来回搬,效率通常更高。
2.2 字节缓冲流
字节缓冲流有两个常用类:
| 类 | 作用 |
|---|---|
BufferedInputStream |
字节缓冲输入流 |
BufferedOutputStream |
字节缓冲输出流 |
构造方法的特点是:它们不直接关联文件,而是包装已有的字节流。
java
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("source.png"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("target.png"));2.3 用字节缓冲流复制文件
java
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("source.png"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("target.png"))
) {
byte[] buffer = new byte[8 * 1024];
int len;
while ((len = bis.read(buffer)) != -1) {
bos.write(buffer, 0, len);
}
}这段代码和上篇的文件复制非常像,只是把基础流换成了缓冲流:
java
new BufferedInputStream(new FileInputStream("source.png"))
new BufferedOutputStream(new FileOutputStream("target.png"))注意两点:
- 关闭外层缓冲流即可,外层流关闭时会带着关闭内部流。
- 写出时仍然要用
bos.write(buffer, 0, len),不要直接写整个数组。
⚠️ 误区:用了缓冲流就不用数组了
正确理解: 缓冲流内部有缓冲区,代码里也可以再使用数组批量读写。两者并不冲突,实际复制大文件时,缓冲流 + 数组是常见写法。
2.4 字符缓冲流
字符缓冲流有两个常用类:
| 类 | 作用 | 特有方法 |
|---|---|---|
BufferedReader |
字符缓冲输入流 | readLine() |
BufferedWriter |
字符缓冲输出流 | newLine() |
BufferedReader 的 readLine() 很常用,它可以一次读取一行文本:
java
try (BufferedReader br = new BufferedReader(new FileReader("in.txt"))) {
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
}需要注意:readLine() 读到的一行内容不包含换行符。
如果要写出多行文本,可以使用 BufferedWriter 的 newLine():
java
try (BufferedWriter bw = new BufferedWriter(new FileWriter("out.txt"))) {
bw.write("第一行");
bw.newLine();
bw.write("第二行");
bw.newLine();
}newLine() 会根据当前系统写入合适的换行符,比手写 \n 更稳妥。
2.5 字符缓冲流适合什么场景
字符缓冲流特别适合按行处理文本,比如:
- 读取日志文件。
- 读取配置文件。
- 处理一行一行的数据。
- 文本排序、文本过滤、文本格式转换。
但它仍然只适合纯文本。图片、音频、视频、压缩包这类文件,仍然应该使用字节流。
三、转换流:解决编码和乱码问题
3.1 先理解编码和解码
计算机最终保存的是字节,人能看懂的是字符。
所以文本读写一定绕不开两个动作:
| 动作 | 含义 |
|---|---|
| 编码 | 字符按照某种规则变成字节 |
| 解码 | 字节按照某种规则还原成字符 |
例如:
- 用 UTF-8 编码保存。
- 却用 GBK 解码读取。
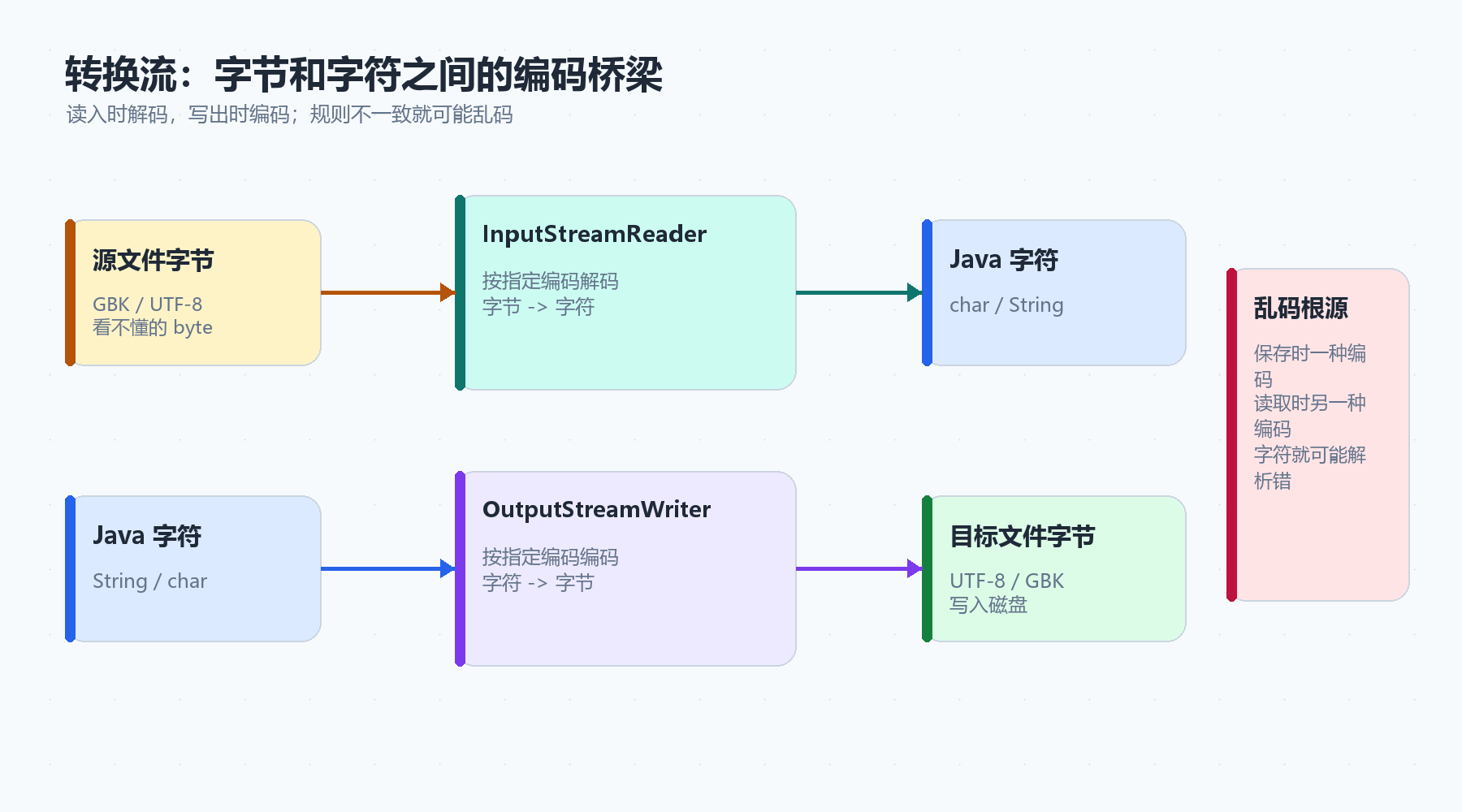
两边规则不一致,就容易乱码。
3.2 为什么 FileReader / FileWriter 容易埋坑
在 IO 上篇里,使用过:
java
new FileReader("a.txt")
new FileWriter("a.txt")这种写法很短,适合入门理解字符流,但它有一个明显限制:
简化构造方法会使用默认编码。文件真实编码和默认编码不一致时,就可能乱码。
比如文件是 GBK 编码,程序却按 UTF-8 去读,中文就可能变成一串看不懂的符号。
⚠️ 关键提醒: 字符流不等于自动解决编码问题。
FileReader/FileWriter的简化写法只是把编码选择藏起来了。想明确指定编码,就要使用转换流。
3.3 InputStreamReader:字节输入流到字符输入流的桥梁
InputStreamReader 是从字节流到字符流的桥梁。
它做的事情是:
读取字节,并按照指定编码解码成字符。
常见构造方法:
java
InputStreamReader reader1 = new InputStreamReader(new FileInputStream("a.txt"));
InputStreamReader reader2 = new InputStreamReader(new FileInputStream("a.txt"), "GBK");更推荐明确写出编码:
java
try (
InputStreamReader reader = new InputStreamReader(
new FileInputStream("gbk.txt"),
"GBK"
)
) {
int ch;
while ((ch = reader.read()) != -1) {
System.out.print((char) ch);
}
}如果要按行读取,可以再套一层 BufferedReader:
java
try (
BufferedReader br = new BufferedReader(
new InputStreamReader(new FileInputStream("gbk.txt"), "GBK")
)
) {
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
}这就是典型的"层层包装":
java
FileInputStream -> InputStreamReader -> BufferedReader含义分别是:
FileInputStream:从文件读字节。InputStreamReader:按指定编码把字节解码成字符。BufferedReader:提高读取效率,并支持按行读取。
3.4 OutputStreamWriter:字符输出流到字节输出流的桥梁
OutputStreamWriter 是从字符流到字节流的桥梁。
它做的事情是:
接收字符,并按照指定编码写成字节。
示例:
java
try (
OutputStreamWriter writer = new OutputStreamWriter(
new FileOutputStream("utf8.txt"),
"UTF-8"
)
) {
writer.write("你好,Java IO");
}如果要按行写文本,可以再套一层 BufferedWriter:
java
try (
BufferedWriter bw = new BufferedWriter(
new OutputStreamWriter(new FileOutputStream("utf8.txt"), "UTF-8")
)
) {
bw.write("第一行");
bw.newLine();
bw.write("第二行");
}这时结构是:
java
FileOutputStream -> OutputStreamWriter -> BufferedWriter含义分别是:
FileOutputStream:向文件写字节。OutputStreamWriter:按指定编码把字符编码成字节。BufferedWriter:提高写出效率,并支持newLine()。
3.5 综合小练习:GBK 文本转 UTF-8
需求:
把一个 GBK 编码的文本文件,转换成 UTF-8 编码的新文件。
代码:
java
try (
BufferedReader br = new BufferedReader(
new InputStreamReader(new FileInputStream("gbk.txt"), "GBK")
);
BufferedWriter bw = new BufferedWriter(
new OutputStreamWriter(new FileOutputStream("utf8.txt"), "UTF-8")
)
) {
String line;
while ((line = br.readLine()) != null) {
bw.write(line);
bw.newLine();
}
}这个例子很重要,因为它把本文的两个核心点连起来了:
- 读入时,指定原文件编码。
- 写出时,指定目标文件编码。
💡 核心结论: 只要涉及中文乱码,第一反应不要怀疑循环逻辑,先确认"保存时的编码"和"读取时的编码"是不是一致。
四、序列化:把对象保存到文件
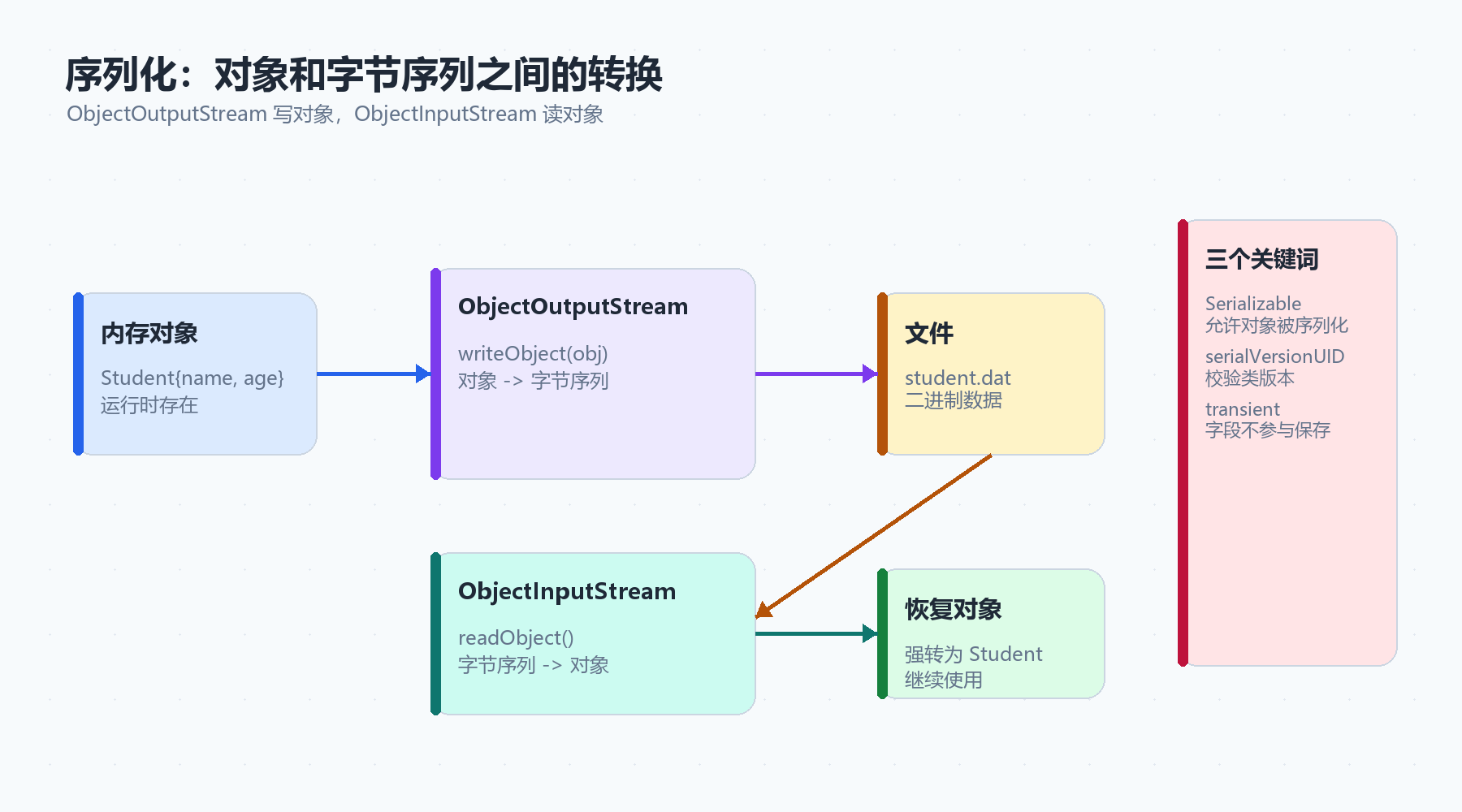
4.1 什么是序列化和反序列化
程序运行时,对象存在内存里。程序一结束,普通对象就没了。
如果想把对象保存到文件中,就需要把对象转换成字节序列,这个过程叫:
序列化。
以后再从文件中把字节序列读回来,还原成对象,这个过程叫:
反序列化。
4.2 ObjectOutputStream 写出对象
ObjectOutputStream 用于把对象写出到文件。
常见写法:
java
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("student.dat"))) {
Student student = new Student("张三", 18);
oos.writeObject(student);
}但不是所有对象都能直接写出。
被序列化的类需要实现 Serializable 接口:
java
import java.io.Serializable;
public class Student implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Student{name='" + name + "', age=" + age + "}";
}
}Serializable 是一个标记接口,它本身不要求你实现方法,只是告诉 Java:
这个类的对象允许被序列化。
如果没有实现它,运行时可能抛出 NotSerializableException。
4.3 ObjectInputStream 读取对象
反序列化使用 ObjectInputStream:
java
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("student.dat"))) {
Student student = (Student) ois.readObject();
System.out.println(student);
}readObject() 的返回值类型是 Object,所以通常需要强制类型转换。
同时,反序列化可能遇到两个常见异常:
| 异常 | 常见原因 |
|---|---|
IOException |
文件不存在、读取失败、数据格式不对 |
ClassNotFoundException |
找不到对应类的 .class 文件 |
4.4 serialVersionUID 是什么
序列化文件里不只保存对象字段,还会保存类版本信息。
如果对象保存之后,类结构发生了变化,反序列化时可能抛出 InvalidClassException。
因此,常见写法是手动声明:
java
private static final long serialVersionUID = 1L;入门阶段可以先这样理解:
serialVersionUID用来判断"文件里的对象版本"和"当前代码里的类版本"是否匹配。
不写也能编译,但 Java 会自动生成一个版本号。类稍微一改,自动生成的版本号可能变化,反序列化就容易失败。
4.5 transient:不想保存的字段
如果某个字段不希望被序列化,可以使用 transient 修饰。
java
public class Account implements Serializable {
private static final long serialVersionUID = 1L;
private String username;
private transient String password;
}password 被 transient 修饰后,不会写入序列化文件。反序列化回来时,它会变成默认值:
- 引用类型默认是
null。 int默认是0。boolean默认是false。
⚠️ 注意: 序列化文件不是普通文本,也不适合手动打开修改。它更像 Java 对象的二进制保存格式。
4.6 序列化多个对象
如果要保存多个对象,不建议一个一个反复写对象。当前阶段可以先用数组保存多个对象,再把整个数组写出去。
java
Student[] students = {
new Student("张三", 18),
new Student("李四", 19),
new Student("王五", 20)
};
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("students.dat"))) {
oos.writeObject(students);
}读取时:
java
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("students.dat"))) {
Student[] students = (Student[]) ois.readObject();
for (Student student : students) {
System.out.println(student);
}
}前提是:数组里的元素类型也要支持序列化。学完集合后,也可以用 ArrayList<Student> 这类集合保存多个对象再序列化,但本文先不把集合当成必备前置知识。
五、打印流:更方便地输出数据
5.1 PrintStream 是什么
最熟悉的一句代码:
java
System.out.println("hello");这里的 System.out 本质上就是一个 PrintStream。
打印流的特点是:
- 可以方便打印各种类型的数据。
- 支持
print()、println()。 - 可以输出到控制台,也可以输出到文件。
5.2 写入文件
java
try (PrintStream ps = new PrintStream("log.txt")) {
ps.println("程序启动");
ps.println(100);
ps.println(true);
}写入后,文件里会出现类似内容:
text
程序启动
100
true5.3 改变 System.out 的输出位置
System.out 默认输出到控制台,也可以临时改成输出到文件:
java
try (PrintStream ps = new PrintStream("console.log")) {
System.setOut(ps);
System.out.println("这句话会写入文件");
System.out.println(123);
}这个知识点适合理解打印流,不建议在普通练习代码里随便改 System.out,因为后面的控制台输出也会被影响。
六、压缩流与解压缩流:简单认识 zip 文件
6.1 核心类
Java 提供了处理 zip 压缩包的流:
| 类 | 作用 |
|---|---|
ZipInputStream |
从 zip 压缩包中读取条目 |
ZipOutputStream |
向 zip 压缩包中写入条目 |
ZipEntry |
表示压缩包里的一个文件或文件夹 |
可以把 zip 压缩包理解成一个小文件系统:
- 压缩包本身是一个文件。
- 压缩包内部有很多条目。
- 每个条目可能是文件,也可能是文件夹。
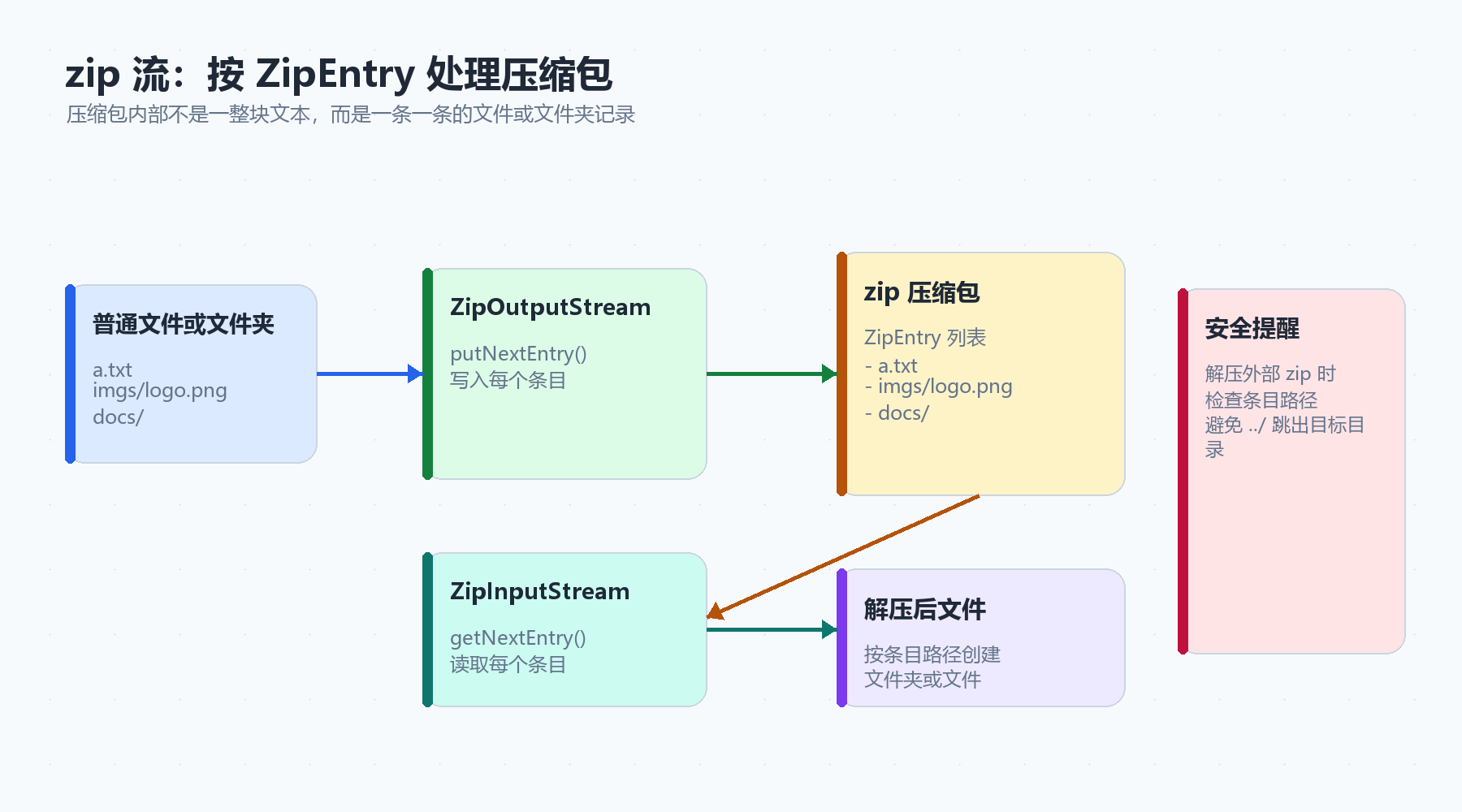
6.2 压缩单个文件
下面示例把 a.txt 压缩为 a.zip:
java
try (
ZipOutputStream zos = new ZipOutputStream(new FileOutputStream("a.zip"));
FileInputStream fis = new FileInputStream("a.txt")
) {
ZipEntry entry = new ZipEntry("a.txt");
zos.putNextEntry(entry);
byte[] buffer = new byte[8 * 1024];
int len;
while ((len = fis.read(buffer)) != -1) {
zos.write(buffer, 0, len);
}
zos.closeEntry();
}关键步骤:
- 创建
ZipOutputStream。 - 创建
ZipEntry,表示压缩包里的文件名。 - 调用
putNextEntry()放入条目。 - 把文件内容写入压缩流。
- 调用
closeEntry()结束当前条目。
6.3 解压 zip 文件
下面示例把 a.zip 解压到 output 文件夹:
java
File destDir = new File("output");
destDir.mkdirs();
try (ZipInputStream zis = new ZipInputStream(new FileInputStream("a.zip"))) {
ZipEntry entry;
while ((entry = zis.getNextEntry()) != null) {
File outFile = new File(destDir, entry.getName());
if (entry.isDirectory()) {
outFile.mkdirs();
} else {
File parent = outFile.getParentFile();
if (parent != null) {
parent.mkdirs();
}
try (FileOutputStream fos = new FileOutputStream(outFile)) {
byte[] buffer = new byte[8 * 1024];
int len;
while ((len = zis.read(buffer)) != -1) {
fos.write(buffer, 0, len);
}
}
}
zis.closeEntry();
}
}入门阶段先抓住一句话:
解压就是不断读取压缩包里的
ZipEntry,如果是文件夹就创建文件夹,如果是文件就把字节写出来。
⚠️ 安全提醒: 真实项目中解压外部 zip 文件时,还要防止条目路径里带有../这类跳出目标目录的路径。这个问题叫 Zip Slip,后续做项目时需要特别注意。
七、IO 综合案例:文本排序并转换编码
7.1 需求说明
假设有一个 GBK 编码的文本文件 in.txt,内容是乱序的:
text
3.学习缓冲流
1.认识 File
2.掌握字节流和字符流
4.理解转换流现在希望:
- 按行读取文本。
- 根据每行开头的序号排序。
- 输出到
out.txt。 - 输出文件使用 UTF-8 编码。
这个案例会同时用到:
BufferedReaderBufferedWriterInputStreamReaderOutputStreamWriter- 数组
7.2 实现代码
java
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
public class IODemo {
public static void main(String[] args) throws IOException {
String[] lines = new String[4];
try (
BufferedReader br = new BufferedReader(
new InputStreamReader(new FileInputStream("in.txt"), "GBK")
)
) {
String line;
while ((line = br.readLine()) != null) {
int dotIndex = line.indexOf(".");
int order = Integer.parseInt(line.substring(0, dotIndex));
lines[order - 1] = line;
}
}
try (
BufferedWriter bw = new BufferedWriter(
new OutputStreamWriter(new FileOutputStream("out.txt"), "UTF-8")
)
) {
for (String sortedLine : lines) {
if (sortedLine != null) {
bw.write(sortedLine);
bw.newLine();
}
}
}
}
}这个写法假设序号是从 1 到 4 的连续数字,所以可以直接用 order - 1 当数组下标。学完 Map 后,如果序号不连续,或者数量不固定,可以再用 TreeMap 做更通用的排序映射。
输出后的 out.txt:
text
1.认识 File
2.掌握字节流和字符流
3.学习缓冲流
4.理解转换流7.3 这个案例值得记什么
它不是为了炫代码,而是把 IO 下篇的关键能力串起来:
| 代码 | 作用 |
|---|---|
InputStreamReader(..., "GBK") |
按 GBK 解码读取 |
BufferedReader |
按行读取 |
String[] lines |
按序号保存每一行 |
OutputStreamWriter(..., "UTF-8") |
按 UTF-8 编码写出 |
BufferedWriter |
高效写文本并支持换行 |
💡 核心结论: 真实 IO 代码经常不是"只用一个流",而是多个流组合起来完成任务。理解每一层负责什么,比死记类名更重要。
八、常见误区速查表
| 常见误区 | 更准确的理解 |
|---|---|
| 缓冲流会改变文件内容 | 不会,它只是提高读写效率 |
用了缓冲流就不用 close() |
仍然要关闭,推荐使用 try-with-resources |
readLine() 会保留换行符 |
不会,它读取一行内容,但不包含行尾换行符 |
| 字符流能自动解决乱码 | 不能,乱码本质上是编码和解码规则不一致 |
FileReader 可以自由指定编码 |
简化构造方法使用默认编码,指定编码应使用转换流 |
| UTF-8 和 GBK 只是名字不同 | 它们是不同编码规则,中文占用字节数可能不同 |
| 序列化就是把对象转成文本 | 不是,序列化结果通常是二进制数据 |
| 所有对象都能直接序列化 | 不是,类通常要实现 Serializable |
transient 字段也会保存 |
不会,它修饰的字段不会被默认序列化 |
| zip 文件就是一个普通文件复制 | 不是,要按 ZipEntry 一个条目一个条目处理 |
总结
知识点总表
| 知识点 | 一句话理解 |
|---|---|
| 缓冲流 | 在基础流外面加缓冲区,提高读写效率 |
BufferedInputStream / BufferedOutputStream |
字节缓冲输入 / 输出流,适合复制任意文件 |
BufferedReader |
字符缓冲输入流,常用 readLine() 按行读取 |
BufferedWriter |
字符缓冲输出流,常用 newLine() 写系统换行 |
| 编码 | 字符变成字节的规则 |
| 解码 | 字节还原成字符的规则 |
| 转换流 | 字节流和字符流之间的桥梁,可以指定编码 |
InputStreamReader |
按指定编码把字节解码成字符 |
OutputStreamWriter |
按指定编码把字符编码成字节 |
| 序列化 | 把对象转换成字节保存 |
| 反序列化 | 从字节恢复对象 |
Serializable |
标记类的对象可以被序列化 |
serialVersionUID |
判断序列化数据和当前类版本是否匹配 |
transient |
表示字段不参与默认序列化 |
| 打印流 | 更方便地输出各种类型的数据 |
| 压缩流 | 通过 ZipEntry 处理 zip 压缩包中的条目 |
最终记忆:
- 缓冲流解决效率问题。
- 转换流解决编码指定问题。
- 序列化流解决对象保存问题。
- 打印流解决便捷输出问题。
- 压缩流解决 zip 条目读写问题。
到这里,Java 基础 IO 的主干就比较完整了:上篇负责"文件、字节、字符",下篇负责"效率、编码、对象、压缩和综合使用"。继续往后学集合、数据结构、多线程时,这些 IO 基础都会反复出现。
