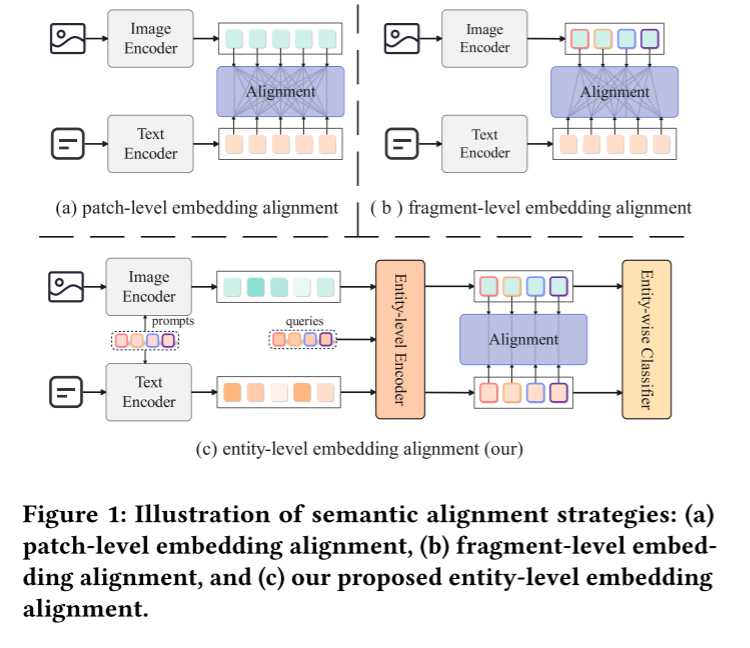
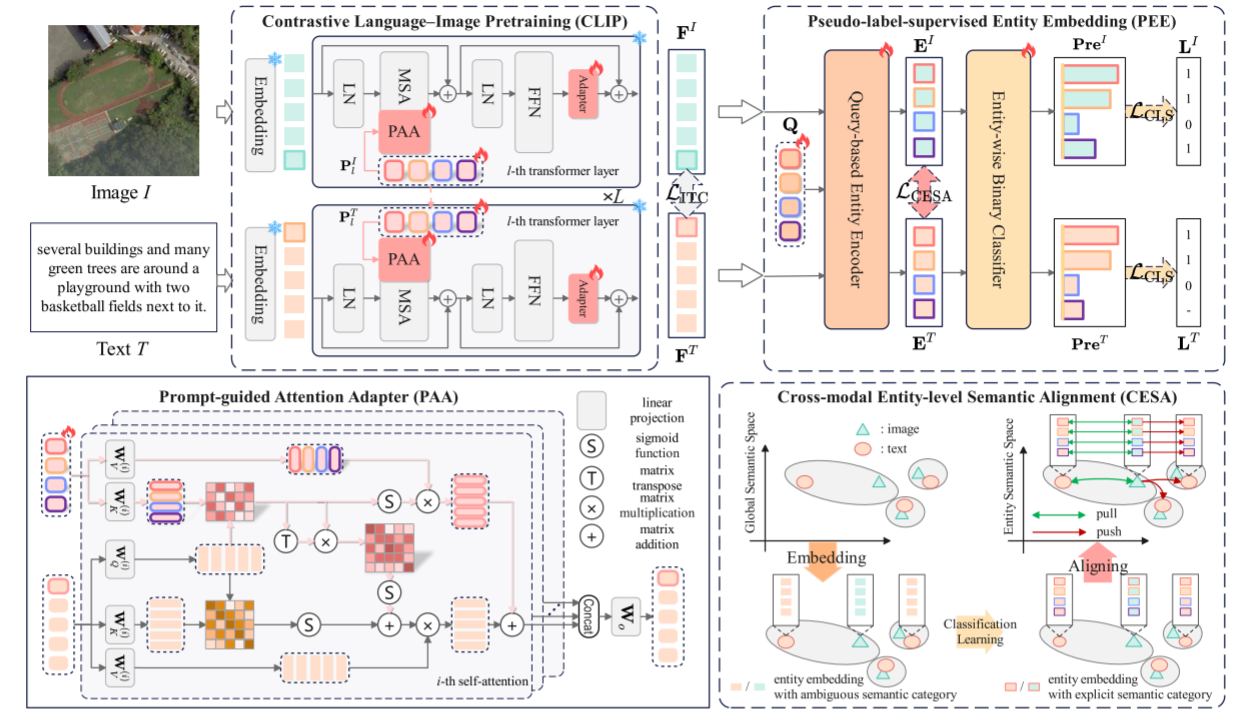
EAPA网络结构如图2所示。本文选取CLIP作为语义建模的骨干网络,该模型由视觉编码器与文本编码器两部分构成,两类编码器均由嵌入层和后续 L L L层Transformer堆叠而成。
定义遥感图文检索数据集: O = { ( I n , T n ) } n = 1 N \boldsymbol{O}=\{(I_{n}, T_{n})\}_{n=1}^{N} O={(In,Tn)}n=1N, N N N为图文匹配样本对的总数量。
输入图像 I I I先被切分为若干图像块,经过嵌入层运算生成附带位置编码的视觉Token序列;在序列首部添加专用**CLS标记用于聚合全局语义,得到图像初始输入特征 I 0 ∈ R N I × D I \boldsymbol{I}^{0} \in \mathbb{R}^{N_{I} ×D_{I}} I0∈RNI×DI,式中 N I N_{I} NI代表序列长度, D I D_{I} DI为特征嵌入维度。
与之对应,文本 T T T通过字节对编码(BPE)完成分词,经嵌入并叠加位置编码后,在序列尾部拼接EOS终止标记**表征全文整体语义,最终得到文本初始特征 T 0 ∈ R N T × D T \boldsymbol{T}^{0} \in \mathbb{R}^{N_{T} ×D_{T}} T0∈RNT×DT。
I 0 I^0 I0与 T 0 T^0 T0均经过 L L L层Transformer完成特征交互与表征学习。单层Transformer由多头自注意力(MSA)和前馈网络(FFN)组成,两模块均配置残差连接与层归一化(LN),计算公式如下:
X ^ l = M S A ( L N ( X l − 1 ) ) + X l − 1 (1) \hat{X}^{l}=MSA\left(LN\left(X^{l-1}\right)\right)+X^{l-1} \tag{1} X^l=MSA(LN(Xl−1))+Xl−1(1)
X l = F F N ( L N ( X ^ l ) ) + X ^ l X^{l}=FFN\left(LN\left(\hat{X}^{l}\right)\right)+\hat{X}^{l} Xl=FFN(LN(X^l))+X^l
式中: X l − 1 X^{l-1} Xl−1、 X ^ l \hat{X}^{l} X^l、 X l X^{l} Xl依次代表第 l l l层Transformer的输入、中间特征与输出。
M S A ( X ) = C o n c a t ( S A ( 1 ) , . . . , S A ( K ) ) W o MSA(X)=Concat\left(SA^{(1)}, ..., SA^{(K)}\right) W_{o} MSA(X)=Concat(SA(1),...,SA(K))Wo
S A ( i ) ( X ) = s o f t m a x ( X Q ( i ) ( X K ( i ) ) ⊤ d h ) X V ( i ) (4) SA^{(i)}(X)=softmax\left( \frac {X_{Q}^{(i)}(X_{K}^{(i)})^{\top }}{\sqrt {d_{h}}}\right) X_{V}^{(i)} \tag{4} SA(i)(X)=softmax(dh XQ(i)(XK(i))⊤)XV(i)(4)
X Q ( i ) = X W Q ( i ) , X K ( i ) = X W K ( i ) , X V ( i ) = X W V ( i ) (5) X_{Q}^{(i)}=XW_{Q}^{(i)}, X_{K}^{(i)}=XW_{K}^{(i)}, X_{V}^{(i)}=XW_{V}^{(i)} \tag{5} XQ(i)=XWQ(i),XK(i)=XWK(i),XV(i)=XWV(i)(5)
式中: W Q ( i ) 、 W K ( i ) 、 W V ( i ) W_{Q}^{(i)}、W_{K}^{(i)}、W_{V}^{(i)} WQ(i)、WK(i)、WV(i) 为第 i i i个注意力头的映射权重矩阵, W o W_o Wo是输出投影矩阵; K K K代表注意力头总数, d h d_h dh为单个注意力头的特征维度。
前馈网络(FFN)由两层全连接层构成,中间层使用GELU激活函数:
F F N ( X ) = G E L U ( X W 1 + b 1 ) W 2 + b 2 FFN(X)=GELU\left(X W_{1}+b_{1}\right) W_{2}+b_{2} FFN(X)=GELU(XW1+b1)W2+b2
式中: W 1 、 W 2 W_1、W_2 W1、W2为权重矩阵, b 1 、 b 2 b_1、b_2 b1、b2为偏置参数。
经过 L L L层Transformer运算得到的最终输出,通过可学习线性投影映射至维度为 D D D的公共特征空间,得到图像特征 F I ∈ R N I × D F^{I} \in \mathbb{R}^{N_{I} ×D} FI∈RNI×D与文本特征 F T ∈ R N T × D F^{T} \in \mathbb{R}^{N_{T} ×D} FT∈RNT×D。
采用图像全局特征 F C L S I F_{CLS}^{I} FCLSI和文本全局特征 F E O S T F_{EOS}^{T} FEOST的余弦相似度 S S S衡量二者整体语义匹配程度,其中 F C L S I F_{CLS}^{I} FCLSI、 F E O S T F_{EOS}^{T} FEOST分别为图像CLS标记与文本EOS标记对应的嵌入向量。
2.1.2 适配器(Adapter)
原始适配器8借助残差连接嵌入每层Transformer的前馈网络FFN之后,实现特征表征面向遥感任务的适配。适配器由降维投影层 W d o w n W_{down} Wdown、非线性激活函数与升维投影层 W u p W_{up} Wup三部分组成。此时式(2)改写为:
X l = A d a p t e r ( F F N ( L N ( X ^ l ) ) ) + X ^ l X^{l}=Adapter\left(FFN\left(LN\left(\hat{X}^{l}\right)\right)\right)+\hat{X}^{l} Xl=Adapter(FFN(LN(X^l)))+X^l
A d a p t e r ( X ) = s 1 ⋅ ( G E L U ( X W d o w n ) W u p ) + X (8) Adapter (X)=s_{1} \cdot\left(GELU\left(X W_{down }\right) W_{up }\right)+X \tag{8} Adapter(X)=s1⋅(GELU(XWdown)Wup)+X(8)
式中: s 1 ∈ R s_{1} \in \mathbb{R} s1∈R为可学习缩放系数,用于调控适配器模块的作用权重。
具体而言,本文引入可学习提示向量辅助模型学习遥感语义实体知识,每条提示对应一类特定语义,引导注意力聚焦相关遥感实体。针对第 l l l层Transformer,定义图像提示 P l I ∈ R N P × D I P_{l}^{I} \in \mathbb{R}^{N_{P} ×D_{I}} PlI∈RNP×DI与文本提示 P l T ∈ R N P × D T P_{l}^{T} \in \mathbb{R}^{N_{P} ×D_{T}} PlT∈RNP×DT, N P N_{P} NP代表提示数量。所有提示参数初始随机赋值。为促进跨模态语义对齐,在后 L s h a r e L_{share} Lshare层Transformer中,图像提示经变换得到匹配的文本提示。
P C − S A ( i ) ( X ) = s o f t m a x ( X Q ( i ) ( X K ( i ) ) ⊤ d h ) ⏟ 原始注意力 + s 2 ⋅ s o f t m a x ( X Q ( i ) ( P K ( i ) ) ⊤ P K ( i ) ( X Q ( i ) ) ⊤ d h ) ⏟ 提示条件注意力 X V ( i ) PC-SA ^{(i)}(X)=\left\\underbrace{softmax\\left(\\frac{X_{Q}\^{(i)}\\left(X_{K}\^{(i)}\\right)\^{\\top}}{\\sqrt{d_{h}}}\\right)}_{原始注意力}+ s_{2} \\cdot \\underbrace{softmax\\left(\\frac{X_{Q}\^{(i)}\\left(P_{K}\^{(i)}\\right)\^{\\top} P_{K}\^{(i)}\\left(X_{Q}\^{(i)}\\right)\^{\\top}}{\\sqrt{d_{h}}}\\right)}_{提示条件注意力}\\right X_{V}^{(i)} PC−SA(i)(X)= 原始注意力 softmax dh XQ(i)(XK(i))⊤ +s2⋅提示条件注意力 softmax dh XQ(i)(PK(i))⊤PK(i)(XQ(i))⊤ XV(i)
式中 P K ( i ) = P W K ( i ) P_{K}^{(i)}=P W_{K}^{(i)} PK(i)=PWK(i), s 2 ∈ R s_{2} \in \mathbb{R} s2∈R为可学习缩放系数。第一项为由输入查询、键值计算得到的原始自注意力分布;第二项借助提示生成的语义先验修正注意力权重。通过融合原生注意力与提示约束注意力,PC-SA能够让模型更精准地捕获实体层级语义特征。
P D − C A ( i ) ( X ) = s o f t m a x ( X Q ( i ) ( P K ( i ) ) ⊤ d h ) P V ( i ) (10) PD-CA ^{(i)}(X)=softmax\left(\frac {X_{Q}^{(i)}\left(P_{K}^{(i)}\right)^{\top }}{\sqrt {d_{h}}}\right) P_{V}^{(i)} \tag{10} PD−CA(i)(X)=softmax dh XQ(i)(PK(i))⊤ PV(i)(10)
将PAA模块嵌入原始多头自注意力结构后,式(1)改写为:
X ^ ( l ) = M S A P A A ( L N ( X ( l − 1 ) ) ) + X ( l − 1 ) (11) \hat{X}^{(l)}=MSA_{PAA}\left(LN\left(X^{(l-1)}\right)\right)+X^{(l-1)} \tag{11} X^(l)=MSAPAA(LN(X(l−1)))+X(l−1)(11)
M S A P A A ( X ) = C o n c a t ( P C − S A ( 1 ) , . . . , P C − S A ( K ) ) ⏟ 原始语义信息 + s 3 ⋅ C o n c a t ( P D − C A ( 1 ) , . . . , P D − C A ( K ) ) ⏟ 提示衍生语义信息 W o \begin{aligned} MSA_{PAA }(X)= & \left\\underbrace{ Concat \\left( PC-SA \^{(1)}, ..., PC-SA \^{(K)}\\right)}_{原始语义信息} + \\right. \\\\ \& \\left.s_{3} \\cdot \\underbrace{ Concat \\left(PD-CA\^{(1)}, ..., PD-CA\^{(K)}\\right)}_{提示衍生语义信息}\\right W_{o} \end{aligned} MSAPAA(X)= 原始语义信息 Concat(PC−SA(1),...,PC−SA(K))+s3⋅提示衍生语义信息 Concat(PD−CA(1),...,PD−CA(K)) Wo
L I T C = − 1 N ∑ i = 1 N ( l o g e x p ( S i , i / τ ) ∑ j = 1 N e x p ( S i , j / τ ) + l o g e x p ( S i , i / τ ) ∑ j = 1 N e x p ( S j , i / τ ) ) \mathcal{L}{ITC}=-\frac {1}{N} \sum {i=1}^{N}\left( log \frac {exp \left(S{i, i} / \tau\right)}{\sum {j=1}^{N} exp \left(S{i, j} / \tau\right)}+log \frac{exp \left(S{i, i} / \tau\right)}{\sum_{j=1}^{N} exp \left(S_{j, i} / \tau\right)}\right) LITC=−N1i=1∑N(log∑j=1Nexp(Si,j/τ)exp(Si,i/τ)+log∑j=1Nexp(Sj,i/τ)exp(Si,i/τ))
式中: S i , j S_{i,j} Si,j代表批次内第 i i i张图像全局特征与第 j j j条文本全局特征的余弦相似度, τ \tau τ为可学习温度系数,批次样本总量为 N N N。
借助spaCy开源工具包内置轻量级英文自然语言处理模型en_core_web_sm7,从文本 T T T中提取名词短语;再通过Sentence-Transformers库的paraphrase-MiniLM-L6-v2模型26,分别对提取的名词短语与预先定义的类别名称做特征嵌入。逐一计算各名词短语和类别名称间的余弦相似度,保留每个类别对应的最大相似度数值,最终得到相似度向量 S T ∈ R N E S^{T} \in \mathbb{R}^{N_{E}} ST∈RNE,用来表征各类别和当前文本的关联程度。
步骤2:文本伪标签分配
依据相似度得分 S T S^{T} ST划定文本伪标签,规则如下:
L i T = { 1 , S i T ≥ θ h (确定存在该类别) 0 , S i T ≤ θ l (确定不存在该类别) − 1 , 其他情况(类别归属不确定) L_{i}^{T}= \begin{cases} 1, & S_{i}^{T} \geq \theta {h}(确定存在该类别)\\ 0, & S{i}^{T} \leq \theta _{l}(确定不存在该类别)\\ -1, & 其他情况(类别归属不确定) \end{cases} LiT=⎩ ⎨ ⎧1,0,−1,SiT≥θh(确定存在该类别)SiT≤θl(确定不存在该类别)其他情况(类别归属不确定)
式中 θ h \theta_{h} θh、 θ l \theta_{l} θl分别为预先设定的高低阈值。
步骤3:图像伪标签聚合
单张图像 I I I通常配套5条匹配文本 T 1 , . . . , T 5 T_{1}, ..., T_{5} T1,...,T5,汇总全部文本伪标签以确定图像伪标签 L i I L_{i}^{I} LiI:
L i I = { 1 , ∃ k ∈ { 1 , . . . , 5 } ,满足 L i T k = 1 0 , ∀ k ∈ { 1 , . . . , 5 } ,满足 L i T k = 0 − 1 , 其余情形 L_{i}^{I}= \begin{cases} 1, & \exists k \in \{ 1, ..., 5\},满足 L_{i}^{T_{k}}=1 \\ 0, & \forall k \in\{ 1, ..., 5\},满足 L_{i}^{T_{k}}=0 \\ -1, & 其余情形 \end{cases} LiI=⎩ ⎨ ⎧1,0,−1,∃k∈{1,...,5},满足LiTk=1∀k∈{1,...,5},满足LiTk=0其余情形
2.3.2 基于查询的实体编码器
随机初始化实体查询矩阵 Q ∈ R N E × D Q \in \mathbb{R}^{N_{E} ×D} Q∈RNE×D,依托改进型查询式实体编码器18,分别从图像特征 F I F^{I} FI、文本特征 F T F^{T} FT中提取图像实体嵌入 E I ∈ R N E × D E^{I} \in \mathbb{R}^{N_{E} ×D} EI∈RNE×D与文本实体嵌入 E T ∈ R N E × D E^{T} \in \mathbb{R}^{N_{E} ×D} ET∈RNE×D。
为进一步提升实体嵌入的表征能力,本文对编码器结构做出两处优化改进:
第一,使用前文提出的提示条件自注意力替换原生自注意力,优化注意力权重分布;
第二,采用卷积门控线性单元28替代传统前馈网络,更高效地捕获各实体查询之间的局部关联特征。
2.3.3 逐实体二分类
针对实体嵌入开展多标签分类,将每个实体嵌入对应类别的判别视作一项独立二分类任务。具体来说,类别 i i i对应的图像实体嵌入 E i I E_{i}^{I} EiI与文本实体嵌入 E i T E_{i}^{T} EiT,经由带Sigmoid激活的线性层,分别输出类别预测概率 P r e i I ∈ R Pre_{i}^{I} \in \mathbb{R} PreiI∈R、 P r e i T ∈ R Pre_{i}^{T} \in \mathbb{R} PreiT∈R,计算公式如下:
P r e i I = S i g m o i d ( W i ⋅ E i I + b i ) , P r e i T = S i g m o i d ( W i ⋅ E i T + b i ) (16) Pre_{i}^{I}=Sigmoid\left(W_{i} \cdot E_{i}^{I}+b_{i}\right),\ Pre_{i}^{T}=Sigmoid\left(W_{i} \cdot E_{i}^{T}+b_{i}\right) \tag{16} PreiI=Sigmoid(Wi⋅EiI+bi), PreiT=Sigmoid(Wi⋅EiT+bi)(16)
式中: W i ∈ R D W_{i} \in \mathbb{R}^{D} Wi∈RD与 b i b_{i} bi为类别 i i i专属线性层参数, ⋅ \cdot ⋅代表向量点积运算。
L C L S = − 1 N ∑ n = 1 N ( E i ∼ S I n B ( L i I n , P r e i I n ) + E j ∼ S T n B ( L j T n , P r e j T n ) ) \mathcal{L}{CLS}=-\frac{1}{N} \sum{n=1}^{N}\left(\mathbb{E}{i \sim \mathcal{S}{I_{n}}} \mathcal{B}\left(L_{i}^{I_{n}}, Pre_{i}^{I_{n}}\right)+\mathbb{E}{j \sim \mathcal{S}{T_{n}}} \mathcal{B}\left(L_{j}^{T_{n}}, Pre_{j}^{T_{n}}\right)\right) LCLS=−N1n=1∑N(Ei∼SInB(LiIn,PreiIn)+Ej∼STnB(LjTn,PrejTn))
式中: B ( l , p ) = l log p + ( 1 − l ) log ( 1 − p ) \mathcal{B}(l,p)=l \log p+(1-l)\log(1-p) B(l,p)=llogp+(1−l)log(1−p)代表二分类交叉熵计算公式; S I n = { i ∣ L i I n ≠ − 1 } \mathcal{S}{I{n}}=\{i \mid L_{i}^{I_{n}} \neq-1\} SIn={i∣LiIn=−1}、 S T n = { j ∣ L j T n ≠ − 1 } \mathcal{S}{T{n}}=\{j \mid L_{j}^{T_{n}} \neq-1\} STn={j∣LjTn=−1}分别表示当前图像、文本中标签取值确定(非 − 1 -1 −1)的类别集合, N N N为样本总数。
补充说明:标签 − 1 -1 −1代表类别不确定样本,不参与分类损失计算。
2.4 跨模态实体级语义对齐
为实现显式的实体级语义对齐学习,本文计算相同语义类别下图像实体嵌入与文本实体嵌入的聚合相似度。具体而言,给定图像实体特征 E I E^{I} EI与文本实体特征 E T E^{T} ET,对同类别实体配对做缩放点积相似度运算,再聚合得到整体实体相似度:
E S = 1 ∣ N E ∣ ∑ i = 1 N E E i I ( E i T ) ⊤ D E S=\frac{1}{\left|N_{E}\right|} \sum_{i=1}^{N_{E}} \frac{E_{i}^{I}\left(E_{i}^{T}\right)^{\top}}{\sqrt{D}} ES=∣NE∣1i=1∑NED EiI(EiT)⊤
式中:实体相似度 E S ∈ R ES \in \mathbb{R} ES∈R用于量化图像 I I I和文本 T T T在实体维度的语义匹配程度, N E N_E NE为实体类别总数, D D D是特征维度。
本文定义跨模态实体级语义对齐损失如下:
L C E S A = − 1 N ∑ i = 1 N ( l o g e x p ( E S i , i / τ ) ∑ j = 1 N e x p ( E S i , j / τ ) + l o g e x p ( E S i , i / τ ) ∑ j = 1 N e x p ( E S j , i / τ ) ) \mathcal{L}{CESA}=-\frac{1}{N} \sum{i=1}^{N}\left(log \frac{exp \left(E S_{i, i} / \tau\right)}{\sum_{j=1}^{N} exp \left(E S_{i, j} / \tau\right)}+log \frac{exp \left(E S_{i, i} / \tau\right)}{\sum_{j=1}^{N} exp \left(E S_{j, i} / \tau\right)}\right) LCESA=−N1i=1∑N(log∑j=1Nexp(ESi,j/τ)exp(ESi,i/τ)+log∑j=1Nexp(ESj,i/τ)exp(ESi,i/τ))
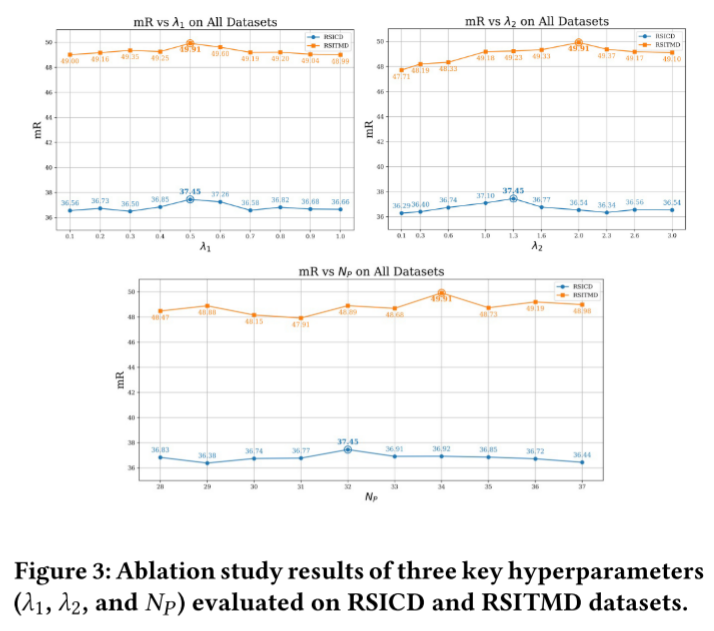
L = L I T C + λ 1 L C L S + λ 2 L C E S A (20) \mathcal{L}=\mathcal{L}{ITC}+\lambda{1} \mathcal{L}{CLS}+\lambda{2} \mathcal{L}_{CESA} \tag{20} L=LITC+λ1LCLS+λ2LCESA(20)
式中: L I T C \mathcal{L}{ITC} LITC为基于全局特征的图文对比损失, L C L S \mathcal{L}{CLS} LCLS为实体嵌入的分类损失, L C E S A \mathcal{L}_{CESA} LCESA为跨模态实体级语义对齐损失;超参数 λ 1 、 λ 2 \lambda_1、\lambda_2 λ1、λ2用于权衡三项损失各自的权重占比。