hive分区表加字段insert字段为空
原因
哈喽朋友们,昨天又在生产环境遇到一个分区表加字段后,insert 进去字段为空的问题。原因是要在分区表中加字段,一般为了不影响历史数据都通过alter table table_name add columns 加字段,环境依旧是华为云DataArts。
现象
字段加完以后,运行完etl之后,查询发现对应字段竟然都是空的!
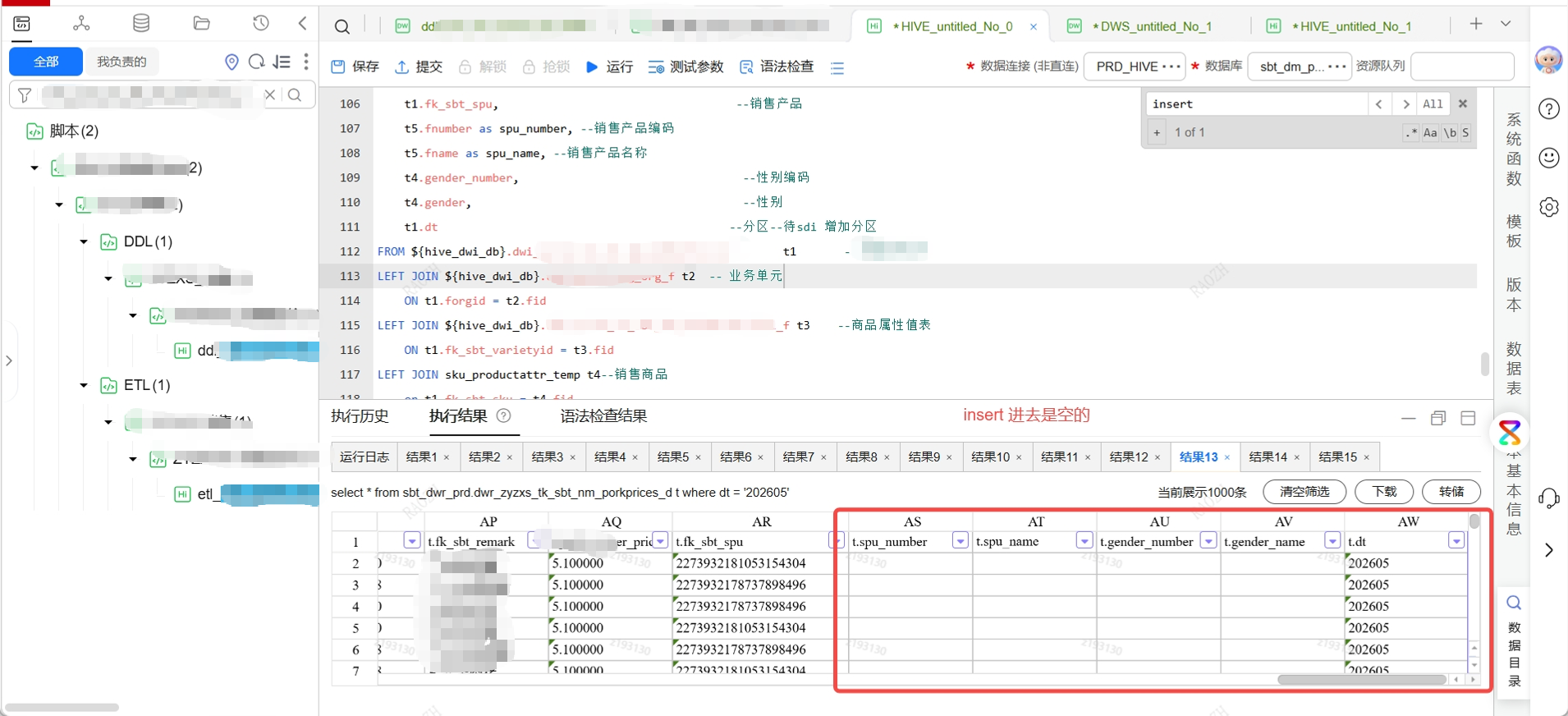
赶紧查下select 有没有问题。
代码完全没问题,那问题就出在元数据上。通过show create table table_name 发现字段都add上去在最后呀,为啥?
即便是MSCK repair table table_name 修复元数据也没有用。
表存储格式是PARQUET列式存储。
解决方案
加字段时加上一个关键字:CASCADE
这样加上去的字段能够在历史分区上都生效,不然新加的字段只会在新的分区上生效。
sql
ALTER TABLE table_name ADD COLUMNS (fk_sbt_spu bigint COMMENT '销售产品id')
改成
ALTER TABLE table_name ADD COLUMNS (fk_sbt_spu bigint COMMENT '销售产品id') CASCADE另外,如果字段已经通过不带CASCADE关键字的add语句加到了分区表上面,咋整?
①通过ALTER TABLE table_name replace columns(保留一个历史字段) CASCADE 把表结构元数据刷掉;
②再ALTER TABLE table_name replace columns(所有最新字段) CASCADE 刷新整个分区表的元数据(含历史分区);
③再执行etl进行数据插入,历史分区新增字段就有数据了。这样就不用重建表了。
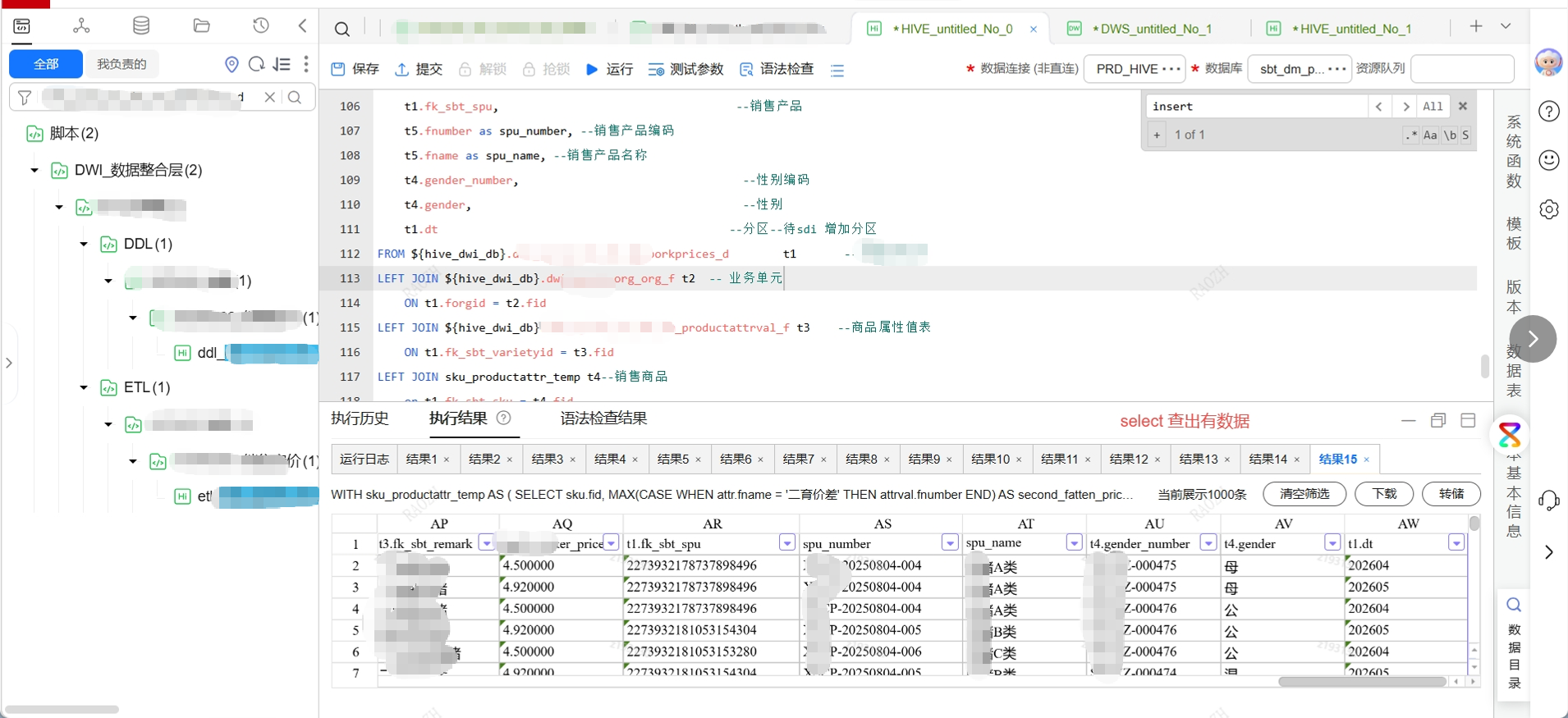
最后再跑下select 分区表,结果和第二张图一样,搞定!