集中式和分布式选型
集中式选型标准:
- 落到数据库的 QPS<=30000,TPS<=1500(按每个事务20条SQL来算)建议采用集中式架构。
- TP系统数据规模<=1000GB,建议采用集中式架构。
- 若TPS要求较低,例如历史库,可以适当增加单Set数据容量至不超过2TB。
- 应用系统分析统计类SQL居多,对函数依赖较多且应用侧改造困难的场景建议采用集中式架构。
分布式选型标准:
- 落到数据库的 QPS>30000,TPS>1500(按每个事务20条SQL来算)建议采用分布式架构。
- TP系统数据规模>1000GB,建议采用分布式架构。
- 单个数据库实例管理最大物理分片数建议不超过64分片。
高可用方案
TDSQL 高可用标准部署
TDSQL的标准部署能做到RPO=0,RTO≤30s(含故障检测时间,可配置调整修改 RTO <=8s),是能完全满足金融客户的要求。
TDSQL的标准两地三中心部署架构如下:
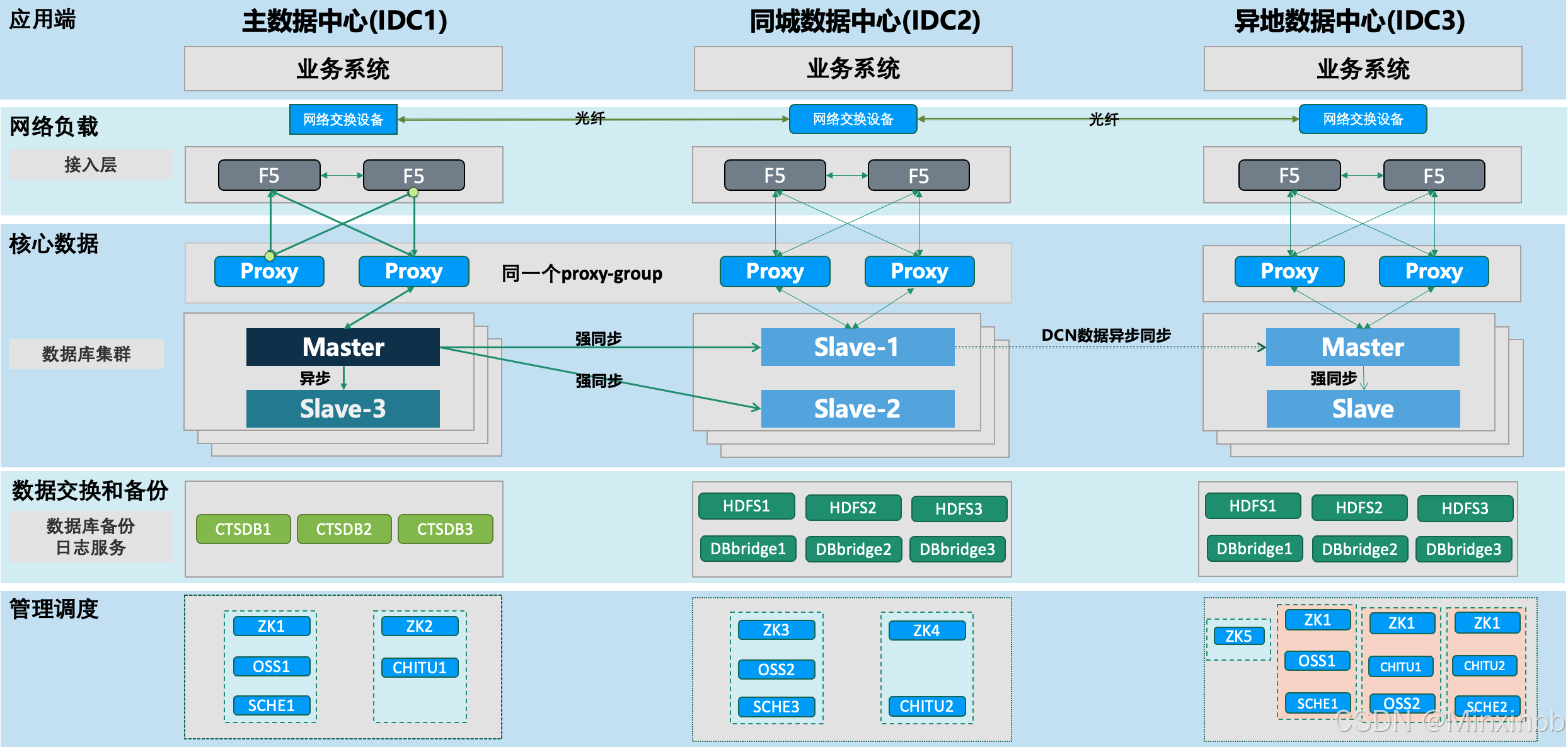
TDSQL高可用故障场景及预期
1.主IDC单个proxy故障
Proxy为无状态组件,主备中心坏掉任意一个都不影响读写,连接会failover到存活节点。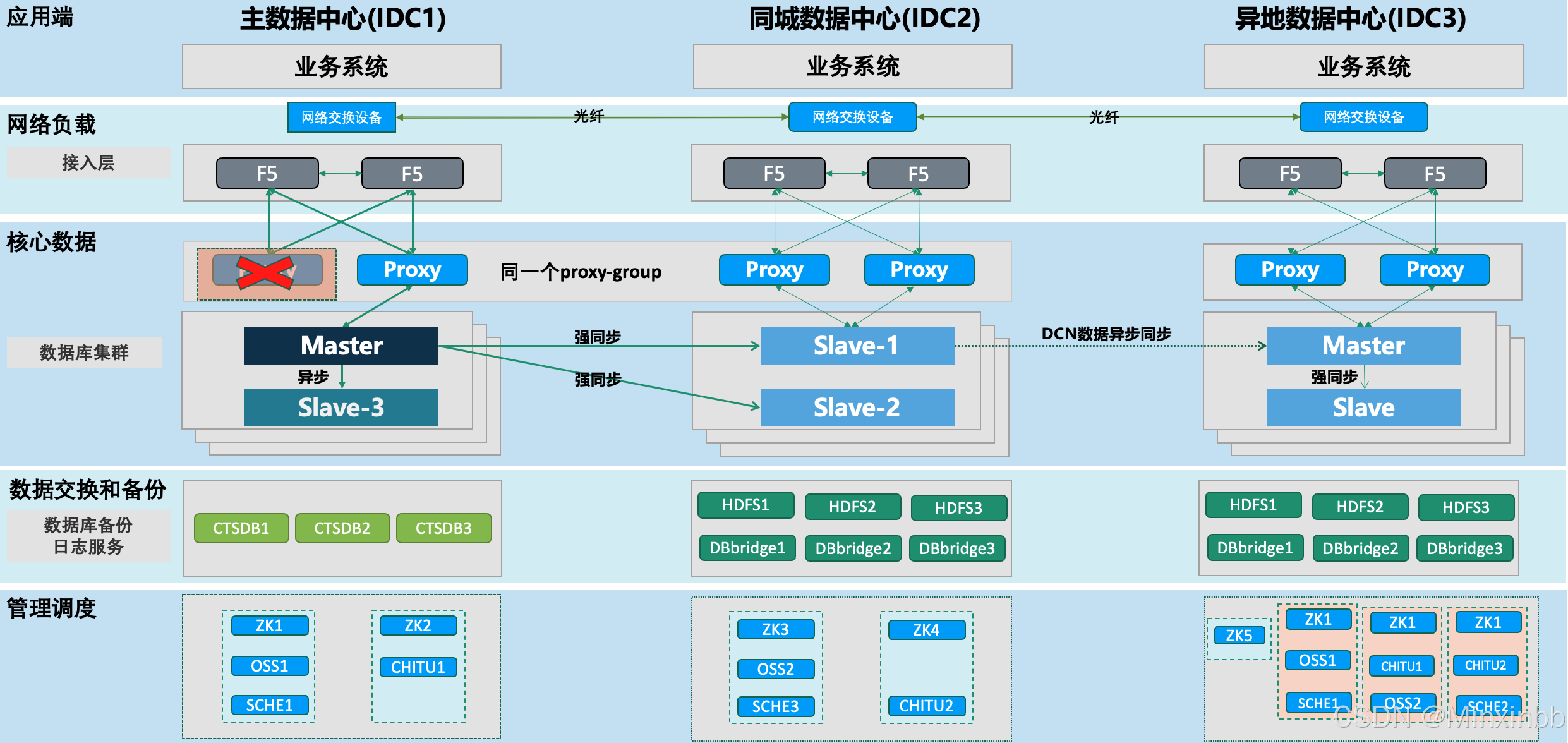
2.主IDC proxy均故障
2.1. 若主中心两个Proxy均发生故障,上层DNS或者JDBC会指向备数据中心的F5,备数据中心的F5会自动将流量导向同城备用proxy,同城备中心的proxy会将流量路由到主数据中心的数据库。
2.2. 待主数据中心的Proxy修复正常之后,修改上层的连接,将流量恢复到主数据中心的F5。
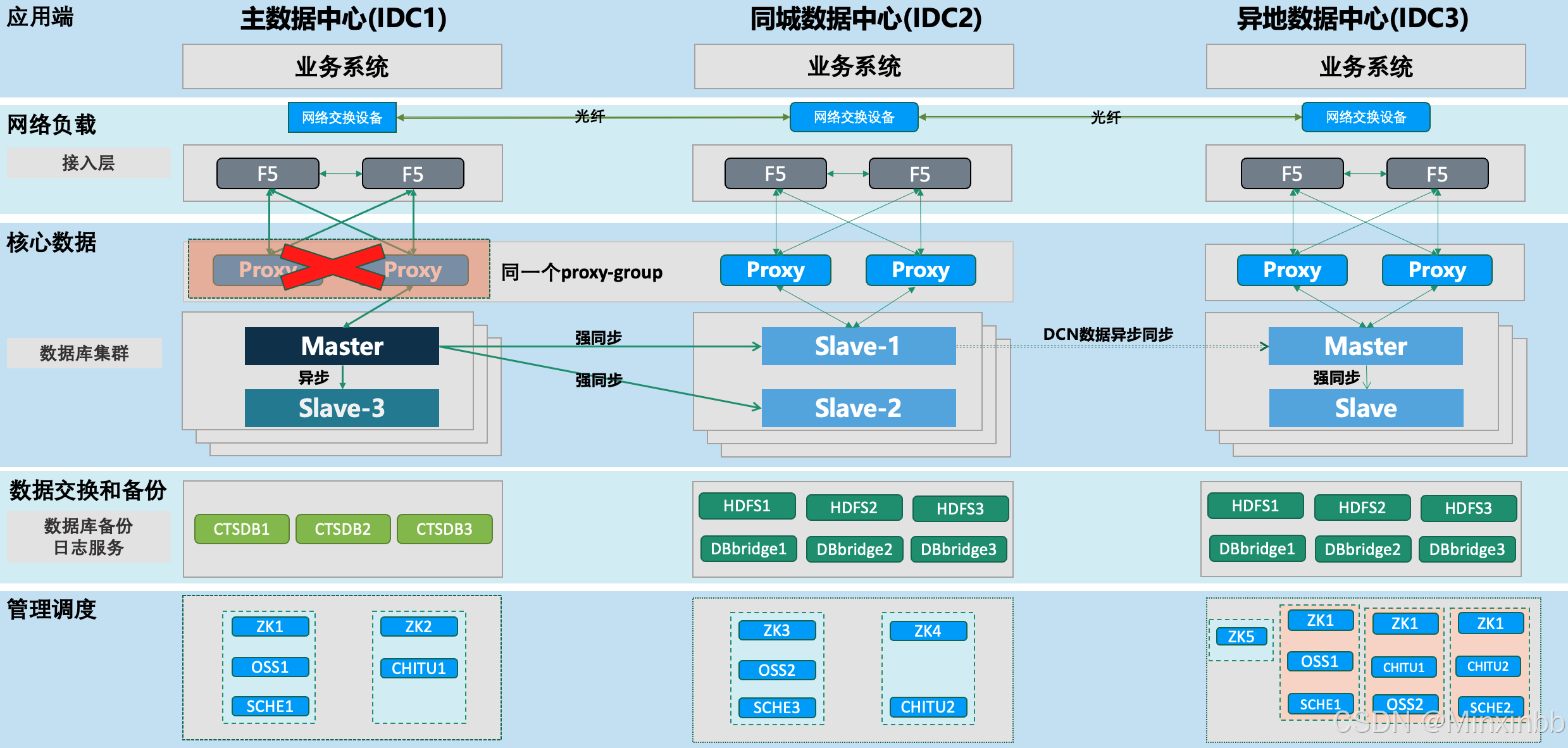
3.主IDC的数据库主节点宕机
3.1. TDSQL的数据库主节点宕机后,ZK和Proxy会自动完成选主。
3.2. 同站点Slave3节点将通过自动选主成为Master主节点。
3.3. 由于是同机房同网段等原因,Slave3节点和主节点最快完成数据同步。ZK选举也是该节点的票最高。
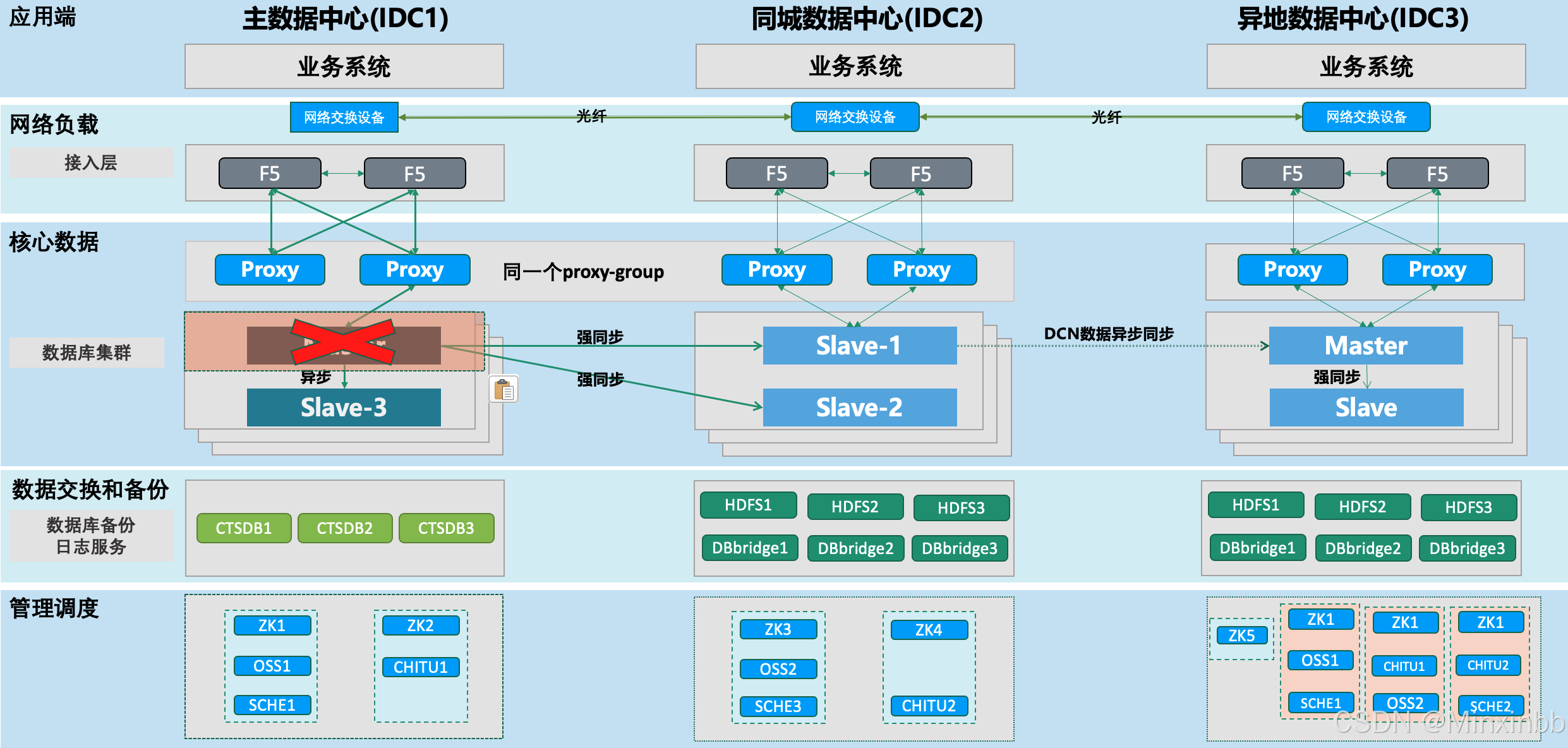
4.管控主机故障
4.1. 主备数据中心的管控主机宕机均不影响TDSQL对外提供服务。
4.2. 管控组件都是高可用部署的,比如OSS1宕机之后,OSS2会自动完成角色切换,对chitu上的操作无影响。
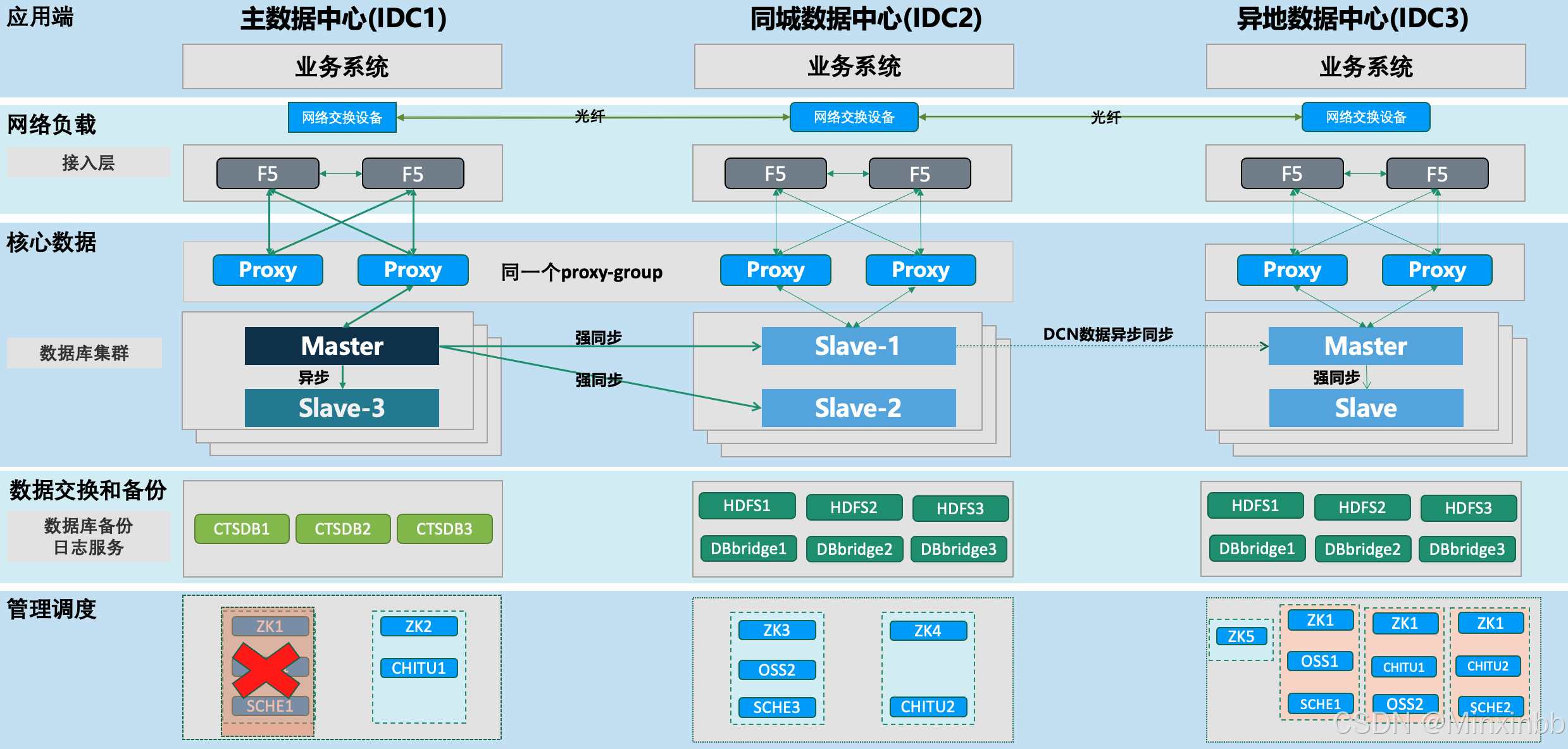
5.整个主数据中心异常
5.1. 整个主数据中心异常,因为zk是2+2+1部署的,主IDC异常之后,同城备IDC接管。
5.2. 同城中心将Slave-1和Slave-2中数据最接近主的slave会自动切换为Master并对外提供服务。
5.3. 赤兔平台无状态,可在同城中心直接访问。
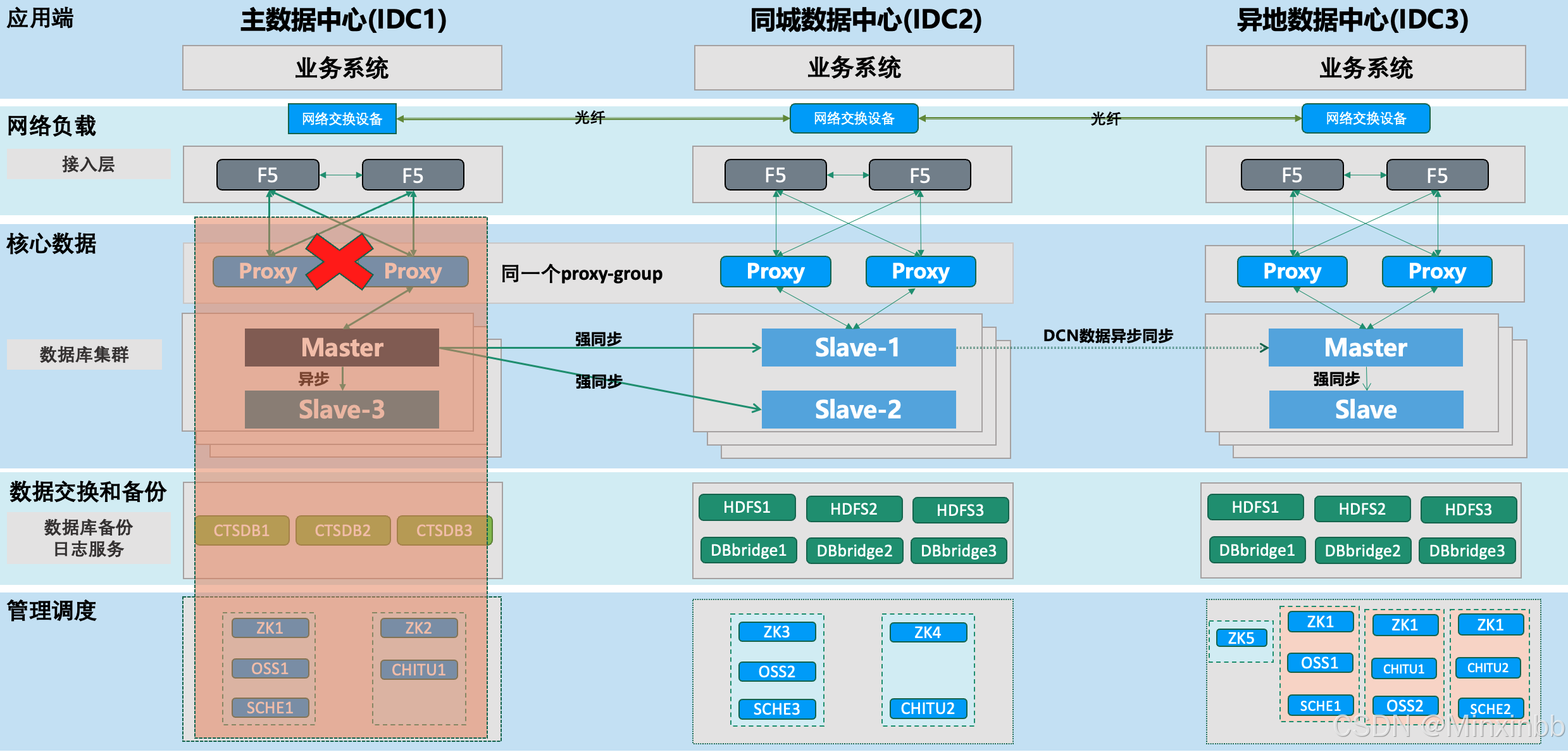
6.同城机房全部故障
6.1. 需要人为干预,手动完成强制DCN切换。
6.2. 人工对业务数据进行验证。
6.3. 全局业务流量切换至IDC3。
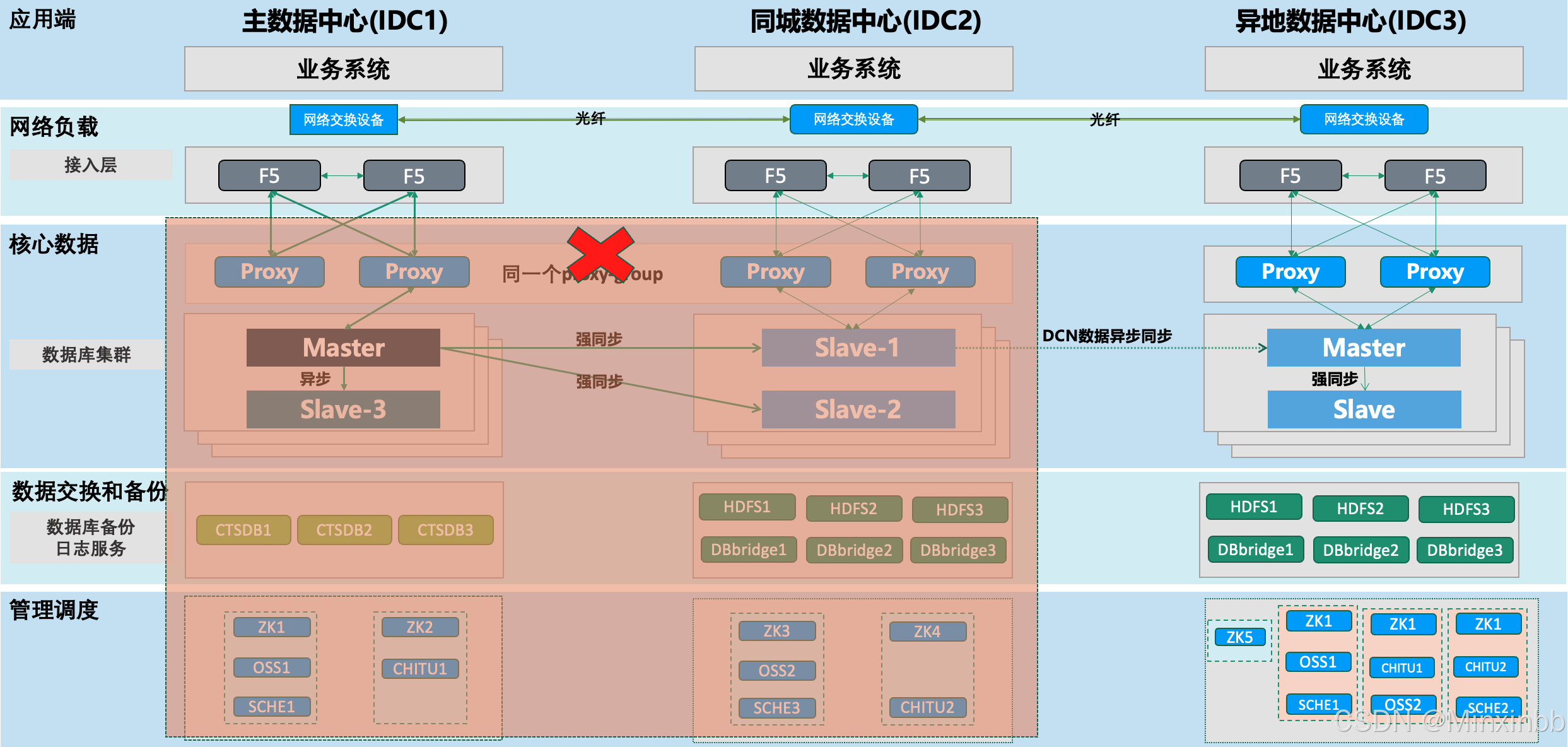
部署网络要求
针对客户核心业务,建议2地3中心架构,同城两机房之间网络延迟要求低于 3 ms,异地之间的网络使用专线,延迟要求低于 30 ms。
资源评估模型
本文以某银行核心系统为例说明:
bash
DB服务器数量
数量模型1=总数据量 / 基线数据量 ✖ 总副本数量 / 每台服务器能放的数据节点实例数量。
数量模型2=总QPS / 基线QPS ✖(总副本数量/每台服务器能放的数据节点实例数量)。
数量模型3=分片数 ✖ 总副本数量 / 单台机器副本数。
最终数量 = Max(数量模型1 , 数量模型2,数量模型3)。
日常CPU使用率峰值:<=30%,联机高峰期<=50%,使用率<=60%。
bash
Proxy服务器数量
同一网关组部署Proxy机器数量>=2。
分布式:Proxy:DB=1:4
灾备中心:Proxy:DB=1:6
集中式:Proxy:DB=1:6
bash
多租户实例共享规划
建议一台机器部署2个副本,平均每个副本空间:
单盘容量 ✖ 盘数 ✖ raid损耗比 ✖ 60%(预留资源)/2
平均每副本CPU=CPU/2
bash
NAS备份资源
备份策略:每天做全量备份(含数据文件+日志文件)。
日志文件:数据文件的5%-30%。
bash
赤兔及管控平台
单中心部署需要3台
同城双中心需要5台
两地三中心需要8台
单个节点容量基线
参考值:1TB(在线库使用1TB,历史库可使用2TB)
管理能力:理论上TDSQL单实例管理更多的数据量(多达几十TB),但是数据量过大会带来更多管理上的开销,比如数据库备份恢复、重做备机、数据回档、表的DDL变更开销和风险等。
性能考量:实例越大,对TPS要求越高,而且实例越大,内存命中率反而越低,性能会受到影响,另外,根据经验,当主库负载超过1万TPS,主备会出现延迟,影响数据库的性能。
业界主流:经统计,目前腾讯的客户数据库实例,基本上都是1TB以内。
建议:在没有特定需求的前提下,业务部门应从数据库管理和性能等角度出发,经过实际测试来确定合理的数据库容量。
bash
单节点QPS基线
参考值:
QPS值与业务模型强相关,不同业务系统的QPS差别较大。指标以实际测试为主。
某大行的结合应用的实测案例如下:
某客户核心的快捷支付交易测试案例中, 涉及SQL语句20条(读写比为9:11),在1000万用户数体系下, TPS ≈ 5000-6000 (CPU使用率≈ 60%)。 业务整体交易的响应时间为20~25ms。另外,根据经验,读多写少的应用,可以获得更高的QPS值,同时CPU使用率、响应时间和延迟会更低,业务部门在评估时,可酌情提高QPS标准。
建议:
响应时间依据业务测试性能基线,满足业务时延要求下的QPS;如果存在超长的情况,可以考虑应用优化或者分片方案。
业务部门应从实际的业务逻辑实测,CPU使用率、响应时间和主从延迟等维度,经过实际测试来确定合理的QPS值,作为最终的分片依据。库表最佳实践
- 建议单库不超过300-400个表。
- 单个表不超过5000W行。
- DELETE对应一次操作不建议超过5000条。
- 对于大事务,事务大小不建议超过1GB,事务中 INSERT|UPDATE|DELETE|REPLACE 语句操作的行数控制在 2000 以内,以及WHERE 子句中 IN 列表的传参个数控制在 500 以内。
- 包含了 ORDER BY、GROUP BY、DISTINCT这些查询的语句,WHERE条件过滤出来的结果集请保持在 1000 行以内,否则导致IO、CPU 过高。
- 建议多表 JOIN不要超过 5个表。在多表 JOIN中,尽量选取结果集较小的表作为驱动表,来 JOIN其他表,JOIN操作,确保第二个表(探针表的关联列存在 INDEX)。
- 另外对于大表,建议不多于2张以上的表JOIN,同时JOIN之间的列上要求要有索引,对于小表(如配置信息类的) 允许超过2张表以上的JOIN。
- 针对流水表,建议使用分区表设计,从而规避流水表增长过快,虽然后期可以通过做DELETE清理,但流水表大部分是追加INSERT操作,很难复用之前清理的碎片空间,从而导致了实例容量使用率过高问题。
- 单个索引中每个索引记录的长度不能超过 2KB,索引列太长,可以使用 prefix 列创建INDEX。
- 单个表上的索引个数建议不能超过 5个,单个索引的字段建议不要超过5个。
- 排序规则不允许使用utf8mb4_general_ci(不区分大小写),应使用utf8mb4_bin(区分大小写)同一个数据库中所有表、字段必须使用相同的字符集,应保证应用程序连接、数据库、表、字段字符集一致。
- 库的名称必须控制在 32 个字符以内。
- 必须统一用英文小写字母命名数据库名,不得使用中文命名,不得使用符号(下划线除外)。
- 创建数据库时必须显式指定字符集,并且字符集只能是 utf8 或者 utf8mb4。