Cloud_Shy 陪你解读《Effective Python 3rd Edition》:从练气到老魔

第四章 Dictionaries(字典)
与 Python 中的列表和序列天然相辅相成的是一种名为字典的类型。字典用于存储映射到相应值的查找键(这通常被称为关联数组或哈希表)。其灵活性使得字典非常适合于簿记工作:能够动态追踪新增和变化的数据项以及它们彼此间的关系。在编写新程序时,使用字典是一种很好的开始方式,即便你尚未确定可能还需要哪些其他数据结构或类。
字典在添加和移除元素时能够提供持续时间(平均时间)的性能表现,这远远优于单纯使用列表所能达到的效果。因此,不难理解字典为何是 Python 用于实现其面向对象特性的核心数据结构。Python 还拥有特殊的语法及相关内置模块,这些模块能够赋予字典超出其他语言中简单哈希表类型所能具备的额外功能。
Item 25:在依赖字典插入顺序时需保持谨慎
在 Python 版本 3.5 及更早版本中,遍历字典实例时返回的键会以任意顺序呈现。遍历的顺序与项目最初被插入字典时的顺序并不一致。例如,以下代码使用 Python 版本 3.5 创建了一个将动物名称映射为其对应婴儿名称的字典:
# Python 3.5
baby_names = {
"cat": "kitten",
"dog": "puppy",
}
print(baby_names)
>>>
{'dog': 'puppy', 'cat': 'kitten'}提示:Python 3.5 版本较为古早,博主这里就不提供实际演示了。
当我创建这个字典时,键的排列顺序为"猫"、"狗",但当我将其打印出来时,键的排列顺序却相反:"狗"、"猫"。这种行为颇为令人诧异,加大了重现测试用例的难度,增大了调试的复杂性,尤其令初学 Python 的人感到困惑。
之所以会出现这种情况,是因为较旧版本的 Python 中的字典类型是通过结合内置的 hash 函数以及 Python 解释器进程开始执行时分配的随机种子来实施其哈希表算法的。这些行为共同导致了字典排序结果与插入顺序不符,并且在程序执行过程中会随机进行洗牌。
自 Python 3.6 版本起,且自 3.7 版本起正式成为 Python 规范的一部分后,字典便能够保留插入顺序。如今,这段代码始终会以与程序员最初创建时相同的方式打印出字典内容:
baby_names = {
"cat": "kitten",
"dog": "puppy",
}
print(baby_names)
>>>
{'cat': 'kitten', 'dog': 'puppy'}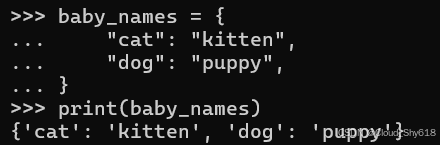
对于 Python 3.5 及更早版本而言,由 dict 提供的所有依赖于迭代顺序的方法------包括键、值、项和 popitem------同样会表现出这种看似随机的行为:
# Python 3.5
print(list(baby_names.keys()))
print(list(baby_names.values()))
print(list(baby_names.items()))
print(baby_names.popitem()) # Randomly chooses an item
>>>
['dog','cat']
['puppy','kitten']
[('dog','puppy'),('cat','kitten')]
('dog','puppy')这些方法如今能够提供一致的插入排序方式,当你编写程序时,可以依赖这一排序方式:
print(list(baby_names.keys()))
print(list(baby_names.values()))
print(list(baby_names.items()))
print(baby_names.popitem()) # Last item inserted
>>>
['cat', 'dog']
['kitten', 'puppy']
[('cat', 'kitten'), ('dog', 'puppy')]
('dog', 'puppy')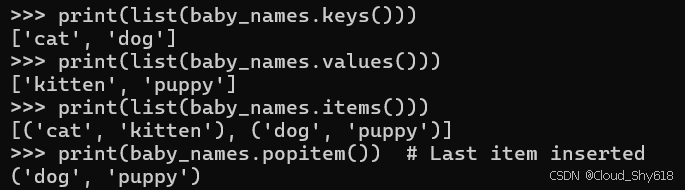
这一变化对其他依赖于 dictt 类型及其具体实现方式的 Python 特性产生了诸多影响。函数的关键字参数------包括 **kwargs catch-all 通用参数(参见 Item 35: "通过关键字参数提供可选行为"和 Item 37: "用仅限关键字和仅限位置参数来增强清晰度")------在 Python 早期版本中以看似随机的顺序传递,这可能导致调试函数调用过程变得更加困难:
# Python 3.5
def my_func(**kwargs):
for key, value in kwargs.items():
print("%s = %s" % (key, value))
my_func(goose="gosling", kangaroo="joey")
>>>
kangaroo = joey
goose = gosling类也会使用 dict 类型来为其实例字典赋值。在 Python 的早期版本中,object 字段会显示出随机化行为:
# Python 3.5
class MyClass:
def __init__(self):
self.alligator = "hatchling"
self.elephant = "calf"
a = MyClass()
for key, value in a.__dict__.items():
print("%s = %s" % (key, value))
>>>
elephant = calf
alligator = hatchling同样,你现在可以假定这些实例字段分配的顺序将反映在 __dict__ 中:
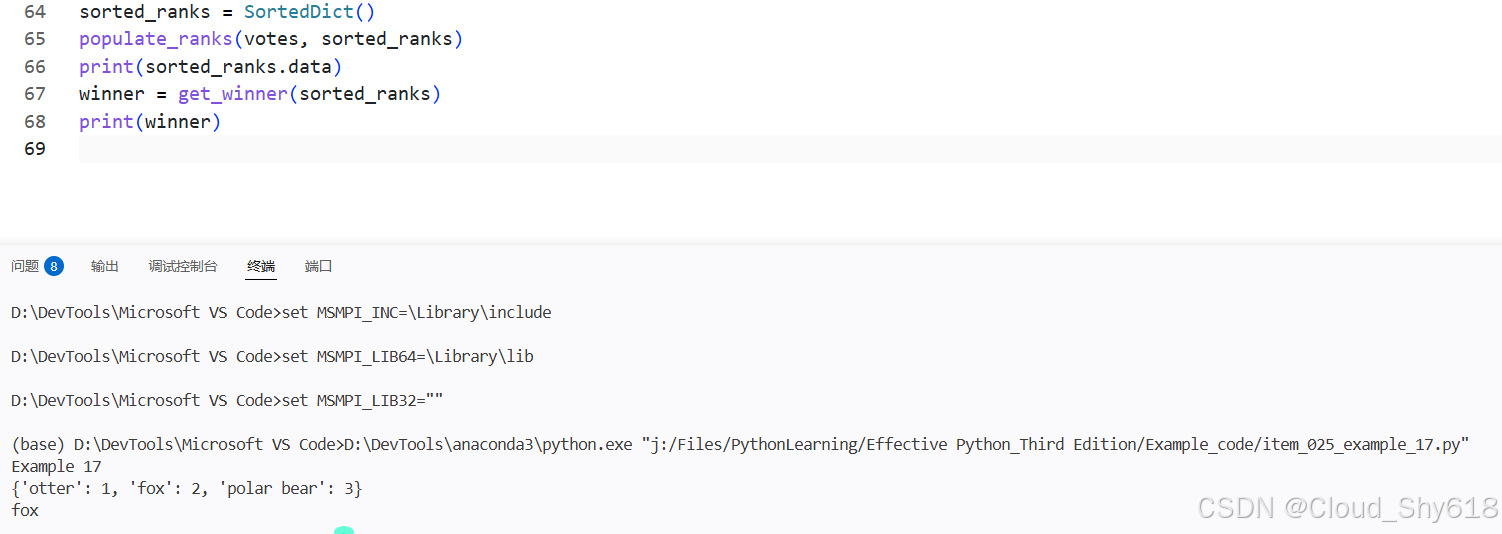
class MyClass:
def __init__(self):
self.alligator = "hatchling"
self.elephant = "calf"
a = MyClass()
for key, value in a.__dict__.items():
print(f"{key} = {value}")
>>>
alligator = hatchling
elephant = calf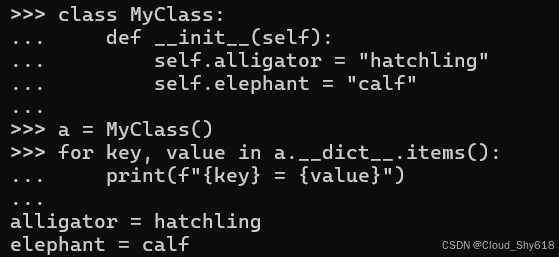
字典保存插入顺序的方式现已成为 Python 语言规范的一部分。对于上述语言特性,您可依赖此行为,甚至将其纳入您为类与函数所设计的 API 中(请参阅 Item 65:"考虑类体定义顺序以确立属性间关系" 以获取示例")。
注意:很长一段时间以来,collections 内置模块都有一个 Ordered Dict 类来保留插入顺序。尽管此类的行为与标准 dict 类型(自 Python 3.7 起)的行为类似,但 Ordered Dicta 的性能特征却截然不同。 如果您需要处理高速率的键插入和 popitem 调用(例如,实现最近最少使用的缓存),Ordered Dict 可能比标准 Python dict 类型更适合(请参阅 Item 92:"优化前的配置文件" 以了解如何确保您需要它)。
但是,您不应该总是假设在处理字典时会出现插入排序行为。 Python 使程序员可以轻松定义自己的自定义容器类型,这些类型模拟标准协议、匹配列表、字典和其他类型(请参阅 Item 57:"从 collections.abc 继承自定义容器类型的类")。Python 不是静态类型的,因此大多数代码依赖于 duck 类型(其中对象的行为是其事实上的类型),而不是严格的类层次结构(请参阅 Item 3:"永远不要期望 Python 在编译时检测错误")。这可能会导致意外。
例如,假设我正在编写一个程序,用于展示一场评选最可爱幼小动物竞赛的结果。在此情况下,我会首先使用一个字典来记录每种动物所获的总票数:
votes = {
"otter": 1281,
"polar bear": 587,
"fox": 863,
}现在,我定义了一个函数来处理这些投票数据,并将每个动物名称的排名信息保存到一个事先准备好的空字典中。在此示例中,该字典可作为驱动 UI 元素的数据模型:
def populate_ranks(votes, ranks):
names = list(votes.keys())
names.sort(key=votes.get, reverse=True)
for i, name in enumerate(names, 1):
ranks[name] = i我还需要一个函数,它能告诉我哪只动物赢得了比赛。这个函数的工作原理是假定 populate_ranks 函数会以升序方式分配 ranks 字典中的内容,这意味着第一个键必定是获胜者:
def get_winner(ranks):
return next(iter(ranks))在此,我确认这些功能均按设计要求运行,并实现了我所预期的结果:
ranks = {}
populate_ranks(votes, ranks)
print(ranks)
winner = get_winner(ranks)
print(winner)
>>>
{'otter': 1, 'fox': 2, 'polar bear': 3}
otter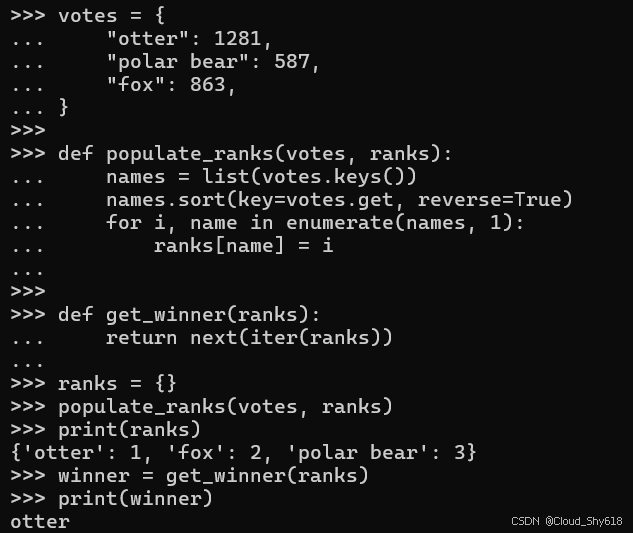
现在,假设该程序的要求发生了变化。显示结果的 UI 元素应改成按照字母顺序排列,而非排名。为实现这一目标,我可以通过使用 collections.abc 内置模块来定义一个类似字典的新类,该类可按字母顺序遍历其内容:
from collections.abc import MutableMapping
class SortedDict(MutableMapping):
def __init__(self):
self.data = {}
def __getitem__(self, key):
return self.data[key]
def __setitem__(self, key, value):
self.data[key] = value
def __delitem__(self, key):
del self.data[key]
def __iter__(self):
keys = list(self.data.keys())
keys.sort()
for key in keys:
yield key
def __len__(self):
return len(self.data)我能够使用一个已排序字典实例来代替标准字典,并沿用之前的函数,且不会引发任何错误,因为该类符合标准字典的协议要求。然而,结果却是错误的:
sorted_ranks = SortedDict()
populate_ranks(votes, sorted_ranks)
print(sorted_ranks.data)
winner = get_winner(sorted_ranks)
print(winner)
>>>
{'otter': 1, 'fox': 2, 'polar bear': 3}
fox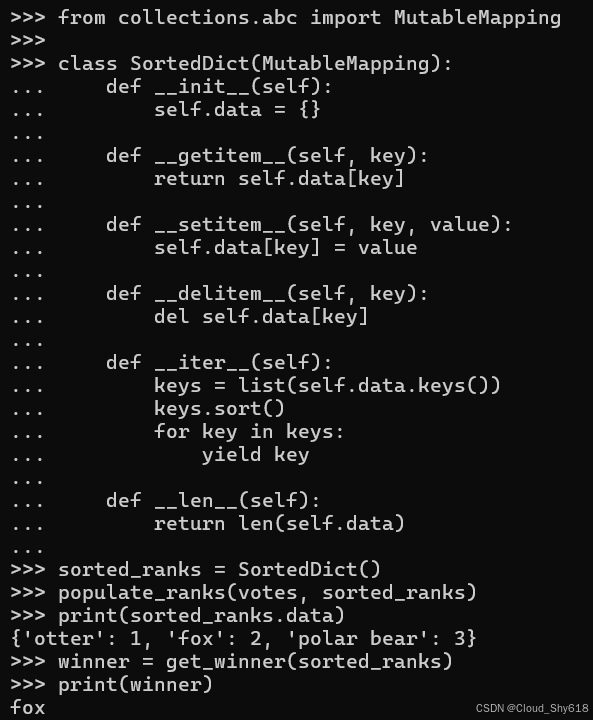
这里的问题是 get_winner 的实现假设字典的迭代是按插入顺序匹配 populate_ranks 的。此代码使用 Sorted Dict 而不是 dict,因此该假设不再成立。因此,为获胜者返回的值是 "fox",按字母顺序排在第一位。
有三种方法可以缓解这个问题。首先,我可以重新实现 get_winner 函数,不再假设 ranks 字典具有特定的迭代顺序。这是最保守、最稳健的解决方案:
def get_winner(ranks):
for name, rank in ranks.items():
if rank == 1:
return name
winner = get_winner(sorted_ranks)
print(winner)
>>>
otter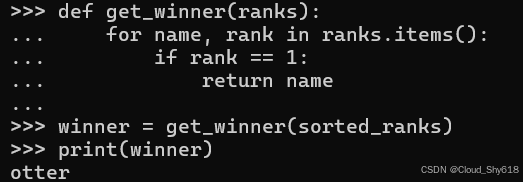
第二种方法是在函数顶部添加显式检查,以确保排名类型符合我的期望,如果不符合则引发异常。该解决方案可能比更保守的方法具有更好的运行时性能:
def get_winner(ranks):
if not isinstance(ranks, dict):
raise TypeError("must provide a dict instance")
return next(iter(ranks))
get_winner(sorted_ranks)
>>>
Traceback ...
TypeError: must provide a dict instance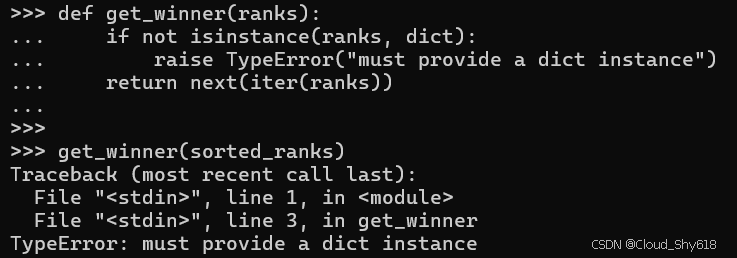
第三种方法是使用类型注释来强制传递给 get_winner 是一个字典实例的值,而不是具有类似字典行为的 MutableMapping(请参阅 Item 124:"考虑通过键入进行静态分析以消除错误")。在这里,我在上述代码的类型注释版本上以严格模式运行 mypytool:
from typing import Dict, MutableMapping
def populate_ranks(votes: Dict[str, int], ranks: Dict[str, int]) -> None:
names = list(votes.keys())
names.sort(key=votes.__getitem__, reverse=True)
for i, name in enumerate(names, 1):
ranks[name] = i
def get_winner(ranks: Dict[str, int]) -> str:
return next(iter(ranks))
from typing import Iterator, MutableMapping
class SortedDict(MutableMapping[str, int]):
def __init__(self) -> None:
self.data: Dict[str, int] = {}
def __getitem__(self, key: str) -> int:
return self.data[key]
def __setitem__(self, key: str, value: int) -> None:
self.data[key] = value
def __delitem__(self, key: str) -> None:
del self.data[key]
def __iter__(self) -> Iterator[str]:
keys = list(self.data.keys())
keys.sort()
for key in keys:
yield key
def __len__(self) -> int:
return len(self.data)
votes = {
"otter": 1281,
"polar bear": 587,
"fox": 863,
}
sorted_ranks = SortedDict()
populate_ranks(votes, sorted_ranks)
print(sorted_ranks.data)
winner = get_winner(sorted_ranks)
print(winner)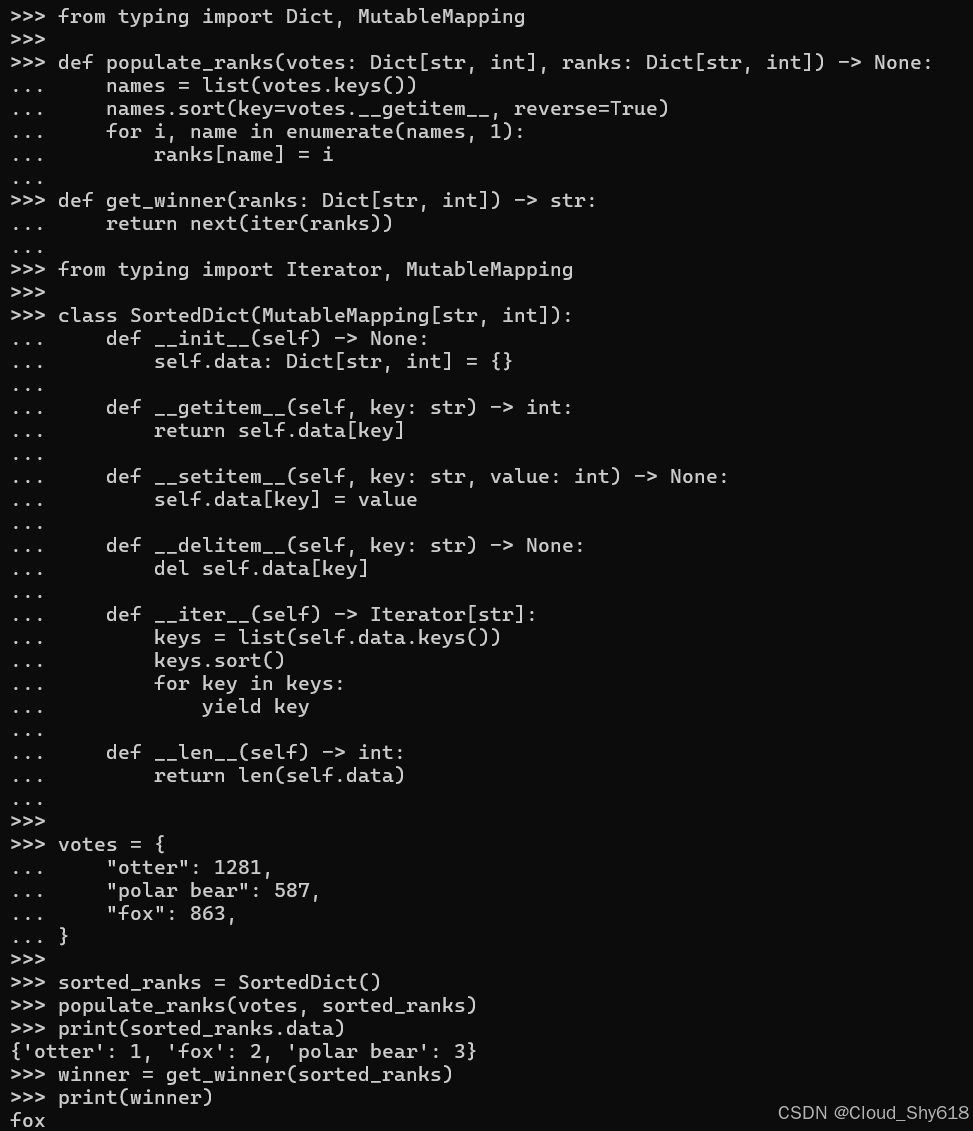
疑惑:博主这里运行出来是没有报错的,另外也去下载了源代码在 VS Code 中运行后,也是同样的结果。有小伙伴懂的,请不吝赐教。
该方法可以正确检测 dict 和 Sorted Dict 类型之间的不匹配,并将不正确的用法标记为错误。该解决方案提供了静态类型安全性和运行时性能的最佳组合。
注意:
- 从 Python 3.7 开始,您可以相信,迭代字典实例的内容将以与最初添加键相同的顺序进行。
- Python 可以轻松定义行为类似字典但不是字典实例的对象。对于这些类型,您不能假设插入顺序将被保留。
- 小心对于类似字典的类,可以通过三种方式解决:编写不依赖插入顺序的代码,在运行时显式检查 dict 类型,或者需要使用类型注释和静态分析的 dict 值。
Item 26:优先使用 getover in 和 Key Error 来处理丢失的字典键
与字典交互的三个基本操作是访问 、赋值 和删除键及其关联值。字典的内容是动态的,因此完全有可能(甚至很可能)当您尝试访问或删除某个键时,它并不存在。例如,假设我正在尝试确定人们最喜欢的面包类型,以设计三明治店的菜单。在这里,我定义了一个计数器字典,其中包含每款面包的当前投票:
counters = {
"pumpernickel": 2,
"sourdough": 1,
}要增加新投票的计数器,我需要查看 key 是否存在,如果丢失,则插入默认计数器值为零的 key,然后增加计数器的值。这需要访问 key 两次并赋值一次。在这里,我通过使用带有 inoperator 的 if 语句来完成此任务,该 inoperator 在键存在时返回 True:
key = "wheat"
if key in counters:
count = counters[key]
else:
count = 0
counters[key] = count + 1
print(counters)
>>>
{'pumpernickel': 2, 'sourdough': 1, 'wheat': 1}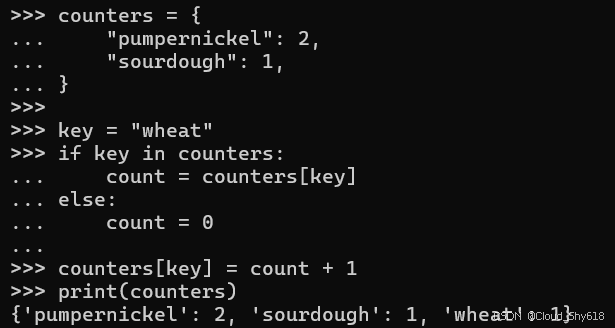
完成相同行为的另一种方法是,当您尝试获取不存在的键的值时,依赖字典如何引发 Key ErrorException。抛开引发和捕获异常的成本(参见 Item 80:"利用 try/ except/else/finally 中的每个块"),理论上,这种方法更有效,因为它只需要一次访问和一次赋值:
try:
count = counters[key]
except KeyError:
count = 0
counters[key] = count + 1这种获取存在的键或返回默认值的流程非常常见,因此 dict 内置类型提供了 get 方法来完成此任务。get 的第二个参数是在键(第一个参数)不存在的情况下返回的默认值(请参阅 Item 32:"优先引发异常而不是返回 None",了解这是否是一个好的接口)。这种方法也只需要一次访问和一次赋值,但它比 Key Error 示例短得多,并且避免了异常处理开销:
count = counters.get(key, 0)
counters[key] = count + 1可以通过各种方式缩短 inoperator 和 Key Error 方法,但所有这些替代方案都需要重复代码以赋值,这使得它们的可读性较差,需要避免:
if key not in counters:
counters[key] = 0
counters[key] += 1
if key in counters:
counters[key] += 1
else:
counters[key] = 1
try:
counters[key] += 1
except KeyError:
counters[key] = 1因此,对于简单类型的字典,使用 get 方法是最短、最清晰的选择。
注意:如果您正在维护这样的计数器字典,那么值得考虑 collections 内置模块中的 Counter 类,它提供了您可能需要的大部分功能。如果字典中的值是更复杂的类型(例如列表)怎么办?例如,假设我不仅想统计选票,还想知道谁为每种类型的面包投票。在这里,我通过将名称列表与每个键相关联来做到这一点:
votes = {
"baguette": ["Bob", "Alice"],
"ciabatta": ["Coco", "Deb"],
}
key = "brioche"
who = "Elmer"
if key in votes:
names = votes[key]
else:
votes[key] = names = []
names.append(who)
print(votes)
>>>
{'baguette': ['Bob', 'Alice'],
'ciabatta': ['Coco', 'Deb'],
'brioche': ['Elmer']}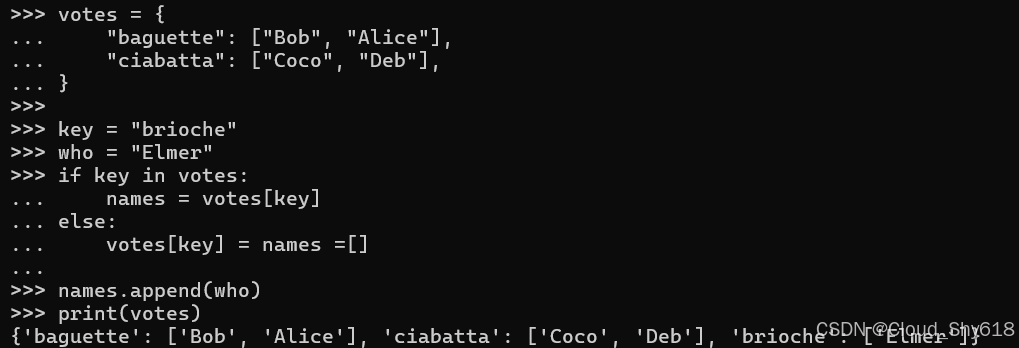
如果 key 存在,则依靠 inoperator 需要两次访问,或者如果 key 丢失,则需要一次访问和一次分配。此示例与上面的计数器示例不同,因为如果 key 尚不存在,则可以将每个键的值盲目赋值给空列表的默认值。三重赋值语句 (voteskey = names = \[\]) 将键填充在一行而不是两行中。一旦将默认值插入到字典中,我就不需要再次分配它,因为在稍后调用追加时通过引用修改了列表(有关信息,请参阅 Item 30:"清楚函数参数可以改变")。
当字典值(value)是列表时,也可以依赖引发 Key Error 异常。如果存在 key,则此方法需要一次 key 访问,如果缺少 key,则需要一次 key 访问和一次赋值,这使得它比 inoperator 更高效(忽略异常处理机制的成本):
try:
names = votes[key]
except KeyError:
votes[key] = names = []
names.append(who)同样,当 key 存在时,我可以使用 get 方法获取列表值,或者如果 key 不存在,则执行一次获取和一次赋值:
names = votes.get(key)
if names is None:
votes[key] = names = []
names.append(who)如果在 if 语句中使用赋值表达式(Python 3.8 中引入;请参阅 Item 8:"使用赋值表达式防止重复"),涉及使用 get 获取列表值的方法可以进一步缩短一行,从而提高可读性:
if(names := votes.get(key)) is None:
votes[key] = names = []
names.append(who)值得注意的是,dict 类型还提供了 setdefault 方法来帮助进一步缩短此模式。setdefault 尝试获取字典中键的值。如果该键不存在,该方法会将该键分配给提供的默认值。然后该方法返回该键的值:原始存在的值或新插入的默认值。在这里,我使用 setdefault 来实现与上面 get 示例中相同的逻辑:
names = votes.setdefault(key, [])
names.append(who)这按预期进行,并且比使用带有赋值表达式的 get 更短。然而,这种方法的可读性并不理想。方法名称 setdefault 并没有立即表明其目的。当它正在做的事情是获取值时,为什么要设置它?为什么不叫它 get_or_set 呢?我在这里争论自行车棚的颜色,但重点是,如果您是代码的新读者并且不完全熟悉 Python,您可能很难理解这段代码试图完成的任务,因为 setdefault 不是不言自明的。
还有一个重要的问题:当键丢失时,传递给 setdefault 的默认值会直接分配到字典中,而不是被复制。在这里,我演示了当值是列表时的效果:
data = {}
key = "foo"
value = []
data.setdefault(key, value)
print("Before:", data)
value.append("hello")
print("After: ", data)
>>>
Before: {'foo': []}
After: {'foo': ['hello']}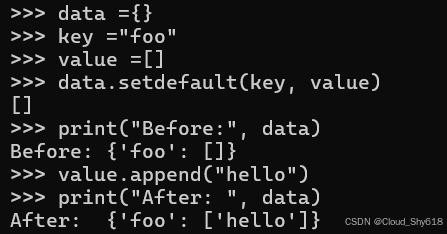
因此,我需要确保始终为使用 setdefault 访问的每个键构建新的默认值。在此示例中,这会导致显着的性能开销,因为我必须为每个调用分配一个列表实例。如果我重用一个对象作为默认值(我可能会尝试这样做以提高效率或可读性),我可能会引入奇怪的行为和错误(请参阅 Item 36:"使用 None 和 Docstrings 指定动态默认参数",了解此问题的另一个示例)。
回到前面的示例,该示例使用字典值计数器而不是投票者列表:在这种情况下为什么不同时使用 setdefault 方法?在这里,我使用这种方法重新实现相同的示例:
count = counters.setdefault(key, 0)
counters[key] = count + 1这里的问题是对 setdefault 的调用是多余的。在递增计数器后,您总是需要将字典中的键分配给新值,因此 setdefault 完成的额外分配是不必要的。使用 get 计数器更新的早期方法仅需要一次访问和一次赋值,而使用 setdefault 则需要一次访问和两次赋值。
只有在少数情况下,使用 setdefault 是处理缺失字典键的最短方法(例如,对于构造成本低廉且不会引发异常的列表实例默认值)。在这些非常具体的情况下,似乎值得接受令人困惑的方法名称 setdefault,而不是必须编写更多字符和行来使用 get。然而,在这些情况下,通常你真正应该做的是使用 defaultdict(参见 Item 27:"优先使用 defaultdict 而不是 setdefault 来处理内部状态中的缺失项")。
注意:
- 有四种常见方法可以检测和处理字典中缺失的键:使用 inoperators、Key Error 异常、get 方法和 setdefault 方法。
- get 方法最适合包含计数器等基本类型的字典,并且当创建字典默认值成本较高或可能引发异常时,最好与赋值表达式一起使用。
- 当 dict 的 setdefault 方法似乎最适合您的问题时,您应该考虑使用 defaultdict 。