摘 要
随着大数据时代的到来,数据分析技术在各个领域的广泛应用为决策提供了重要依据。四川作为中国的旅游大省,拥有丰富的自然和人文景观,吸引了大量游客。本文基于Hadoop大数据平台,对四川景点的综合数据进行分析,旨在挖掘游客行为、偏好以及景点的热门程度,为旅游管理和市场营销提供数据支持。
首先,本文收集了近年来去哪儿旅行网站的相关数据,包括流行景点的名称、景点等级、折扣、地址、简介、图片、评分、评论、价格、销售数量等信息。接着,采用数据清洗和预处理的方法,确保数据的准确性和可靠性。在数据分析阶段,运用Python中的Pandas、NumPy和Matplotlib等库,对数据进行可视化分析,识别出主要的游客群体及其偏好,进一步探讨不同季节和节假日对景点访问量的影响。
采用协同过滤算法对景点数据进行深度挖掘。通过收集并存储用户在各景点的评分、浏览历史等海量数据于HDFS,利用MapReduce框架进行高效的数据预处理与相似度计算。算法首先构建用户-景点评分矩阵,随后依据用户相似性或景点相似性进行推荐,从而生成个性化的景点推荐列表。此过程不仅揭示了用户的旅游偏好,还为景点推广和路线规划提供了科学依据,有效促进了四川旅游资源的优化配置与个性化服务的发展。
关键词:Hadoop;四川景点综合;数据分析与预测;协同过滤算法
1.3论文所做工作及思路
本论文致力于探讨基于 Hadoop 的四川景点综合数据分析与应用,主要围绕数据挖掘、可视化及其在流行景点中的实际应用展开。
数据源获取:首先收集来自"去哪儿旅行"网站的多维度数据,包括热门景点、景点评论等,以构建一个全面的景点数据库。
数据清洗:运用Python强大的数据处理和分析库,如Pandas、NumPy、Matplotlib等,对数据进行清洗和预处理。这一步骤不仅提高了数据的质量,也为后续分析打下了坚实基础。
数据存储:清洗后的数据需要存储在数据库和CSV文件中,以便后续的分析和建模。
数据可视化:利用Matplotlib和Seaborn等工具进行可视化展示,从而使得数据的趋势和特征更加直观。
景点推荐:通过协同过滤算法算法,深入挖掘数据中的潜在规律,通过对热门景点的时间序列分析,算法综合考虑用户行为数据与景点特征,为用户生成个性化推荐列表,同时为景点管理部门提供科学的决策依据,助力提升四川旅游资源的吸引力和游客满意度。
1.4章节安排
共分5章。
第1章绪论:对四川景点综合的背景进行阐述,首先会对四川的自然和人文景观进行概述,着重介绍其独特的地理位置和丰富的旅游资源。这一部分旨在为后续的数据分析奠定基础,帮助读者理解四川景点的多样性。最后讲述关于本论文的工作与思路可以大致解论文所做的工作。
第2章相关技术介绍:介绍Hadoop作为数据分析工具的优势,如何利用Python的各种库(如Pandas、NumPy和Matplotlib)来处理和分析四川景点综合数据。
第3章需求分析:涉及数据的获取与预处理,还包括对景点特征的提取与分析方法的探讨。功能需求分析上讲了关于模型的相关数据源和数据处理等方面,非功能需求分析上主要讲解了模型的性能要求和准确性要求。
第4章景点数据分析与处理:讲解对数据收集和预处理的方法,通过分析数据的缺失和数据的错误从而处理数据。
第5章景点数据应用:论文将重点放在分析结果的应用上,包括如何利用这些数据为四川的旅游管理提供决策支持,提升游客体验和景区的运营效率。
3.2功能需求分析
3.2.1数据收集
数据源来自国内的"去哪儿旅行"网站。"去哪儿旅行"网站提供了关于四川景点信息的数据爬取文件,以json格式存储,后续处理中转换为csv文件便于操作。
数据采集方式:数据采集通过requests方法进行批量采集,导致数据实时性较低。
数据获取频率:数据来自国内官网,更新频率较低,因此采集频率为一次性。
数据量估计:收集到的比赛数据原始大小为111MB,经过手动筛选后存储了近5w条数据生成了travelinfo.csv个文件,用于数据分析。
数据格式和结构:景点数据主要为字符串类型,相关字段使用文本方式存储,有助于减少存储空间和便于数据处理与可视化分析。
通过对数据收集的功能需求进行分析和定义,可以确保数据采集过程的顺利进行,并为后续的数据处理和分析提供高质量的数据基础。
3.2.2数据整理与选择
在进行四川景点的综合数据分析时,数据的整理与选择显得尤为重要。四川是一个旅游资源丰富的省份,拥有众多的自然景观和人文景点,如何从庞大的数据中提取出有价值的信息,成为了研究的关键。首先,需要收集多种来源的数据,包括旅游网站、用户评论和统计数据等。这些数据能够提供关于名称、景点等级、折扣、地址、简介、图片、评分、评论、价格、销售数量等多维度的信息。然而,原始数据往往存在冗余、噪声和不完整性,因此数据清洗的过程必不可少。通过去除重复数据、修正错误信息和填补缺失值,可以提高数据的质量,从而增强分析的准确性。
接下来,选择合适的特征也是至关重要的。不同的分析目标需要不同的特征支持,例如,若着重于游客满意度,可以选择与景点服务质量、环境卫生等相关的数据;而若分析旅游趋势,游客的流量变化、季节性因素则更为关键。通过使用Hadoop等大数据处理工具,可以高效地处理和分析这些数据,使得最终得到的结果更具参考价值。这一系列的数据整理与选择过程,不仅提高了分析的效率,更为后续的应用提供了坚实的基础。
3.2.3数据展示
在四川景点综合数据分析中,数据展示的环节显得尤为重要。通过Hadoop大数据处理平台,能够将大量的景点信息进行有效整合,并以直观的方式呈现给用户。具体而言,数据展示可以通过多种形式进行,如图表、地图和仪表盘等。
图表能够清晰地显示各个景点的游客数量、满意度和评价分布等关键指标,帮助用户快速理解景点的受欢迎程度和游客体验。而地图的应用则能让用户直观地看到不同景点的地理分布,便于规划旅行路线。与此同时,仪表盘汇总了各类数据,通过交互式界面,用户可以根据自己的需求选择查看不同的指标,增强了数据的可用性和灵活性。针对四川省内各大景点的综合分析,数据展示不仅仅是简单的数字罗列,而是通过可视化手段将复杂的信息转化为易于理解的形式。这样的展示方式不仅提升了数据的可读性,也为游客提供了决策依据,帮助他们选择最适合自己的旅游目的地。
基于Hadoop的强大计算能力,数据展示的实时性和准确性得到了保障,使得用户可以获取最新的景点信息,从而丰富他们的旅行体验。通过这种方式,四川的旅游资源得以更好地被挖掘和利用。
3.2.4景点推荐算法
巧妙融合协同过滤算法与Hadoop大数据处理技术,以实现个性化的四川景点推荐。通过深入挖掘用户在Hadoop平台上的浏览、评价及行为数据,构建景点-用户关联矩阵,并运用协同过滤算法计算景点间的相似度及用户偏好。该算法能够智能识别用户的兴趣偏好,从海量的四川景点中筛选出与用户历史行为高度匹配的景点,生成个性化的推荐列表。
4.1爬取去哪儿旅行网站
4.1.1爬取步骤
在进行四川景点综合数据分析之前,数据的获取至关重要。为此,首先需要选择合适的网络爬虫工具,常用的有Scrapy和BeautifulSoup等,这些工具能够帮助提取网页中的结构化数据。接下来,明确目标网站,通常选择旅游相关的平台,如携程、去哪儿或大部分地方政府的旅游官网。在确定目标后,分析网页结构,找到需要抓取的数据字段,比如景点名称、地址、评分、游客评论等。这一步骤涉及到对HTML文档的解析,利用爬虫工具中的选择器功能,能够轻松定位到这些信息。确保在抓取时遵循robots.txt协议,尊重网站的抓取规则,避免对服务器造成负担。数据抓取的频率也需要控制,以便于网站正常运行,防止被封禁。完成抓取后,数据会被存储为CSV或JSON格式,方便后续分析。
在进行景点数据的爬取时,首先明确爬取"去哪儿旅行"网站和所需数据的具体类型。利用requests库向目标网站"https://piao.qunar.com/daytrip/list.htm"和"https://piao.qunar.com/ticket/list.htm?region=四川"发送HTTP请求,以获取网页的HTML内容。解析网页内容后,可以通过Beautiful Soup提取出所需的字段,如景点名称、价格、评论等。
通过查找特定class属性为'result_list'的div标签,获取包含对局数据的div。遍历div列表,对每个div标签进行处理,提取景点相关的数据。最后将数据循环遍历存放到data.csv文件中。
整个爬取和分析的过程,不仅要求技术的掌握,更需要对数据的敏感度和对景点知识的理解,以便从复杂的原始数据中提取出有价值的信息。
数据介绍:此处json数据是从去哪儿旅行网站分析出的获取景点数据相关的api接口"https://piao.qunar.com/ticket/list.json?region=四川\&keyword=四川\&page=4"上获取到的数据,其中包含评论信息。
4.4.4数据迁移模块
定义了MySQl的jdbc信息,mysql的账号密码信息,mysql中数据表的信息,以及hive外部表的存储的hdfs路径信息。
bash
bin/sqoop export \
--connect jdbc:mysql://hadoop02:3307/jd\
--username root \
--password 12345678\
--table travelinfo \
--num-mappers 1 \
--export-dir / jd/ads/old_new \
--input-fields-terminated-by ","这段代码是一个Sqoop命令行工具,它用于将数据从Hadoop文件系统(HDFS)导出到关系型数据库中。下面是每个选项的解释:
(1)bin/sqoop export:这是Sqoop的主命令,用于启动数据的导出过程。
(2)--connect jdbc:mysql://hadoop01:3307/jd:指定了要导出数据到的数据库的JDBC连接字符串。它连接到一个运行在hadoop01服务器上的MySQL数据库,MySQL服务监听在3307端口,数据库名为jd。
(3)--username root:连接数据库的用户名,用户名为root。
(4)--password 1234567:连接数据库的密码,密码为123456。
(5)--table travelinfo:目标数据库中将要导入数据的表名,表名为travelinfo。
(6)--num-mappers 1:指定了用于导出数据的Map任务的数量。
(7)--export-dir /jd/ads:这是HDFS中包含要导出数据的目录。Sqoop将从这个目录中读取数据并将其导入到上面指定的表中。
(8)--input-fields-terminated-by ",":指定了输入数据的字段分隔符,这里是逗号。意味着Sqoop期望每条记录的字段是由逗号分隔的。
4.4数据分析与可视化
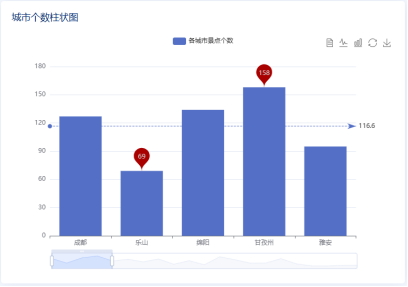
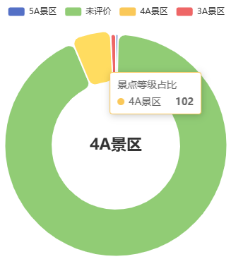
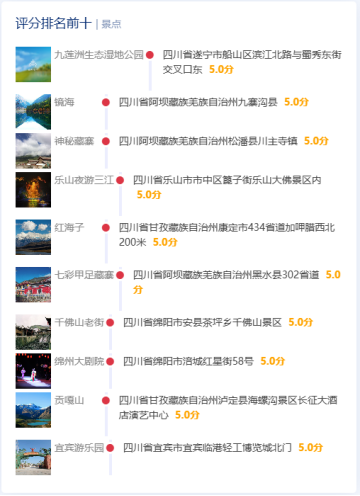
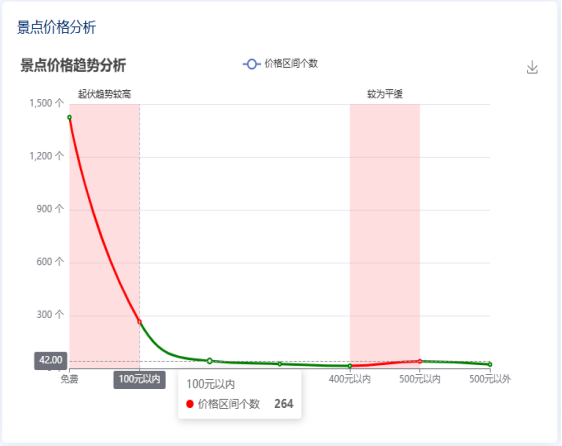
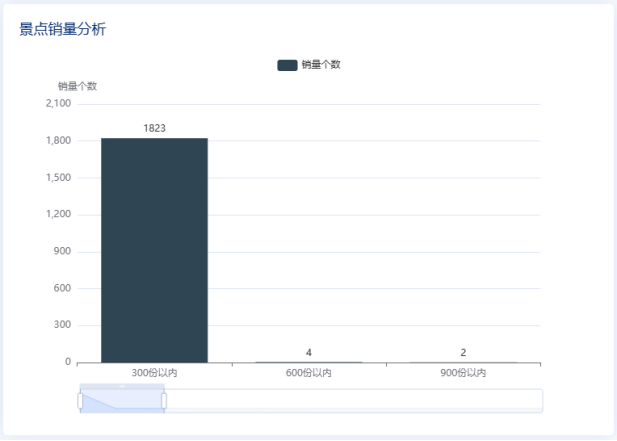
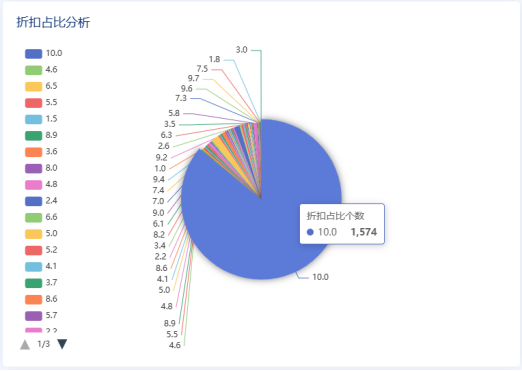

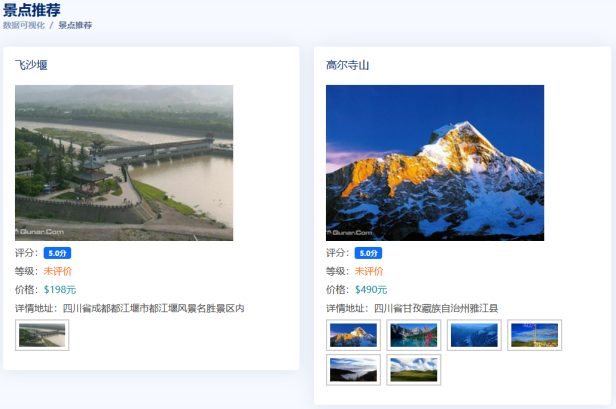
5.1景点推荐
5.1.1协同过滤算法
协同过滤推荐算法是一种基于用户行为或兴趣相似性的推荐技术。它通过分析用户的历史行为数据或兴趣偏好,发现用户之间的相似性或物品之间的相似性,进而为用户推荐可能感兴趣的内容或产品。
协同过滤算法主要分为基于用户的协同过滤(User-based CF)和基于物品的协同过滤(Item-based CF)两种。基于用户的协同过滤算法是通过计算用户之间的相似度,找到与目标用户兴趣相似的其他用户,然后推荐这些相似用户评价高但目标用户尚未评价的内容或产品。而基于物品的协同过滤算法则是通过分析物品之间的相似性,推荐与用户已喜欢物品相似的其他物品。
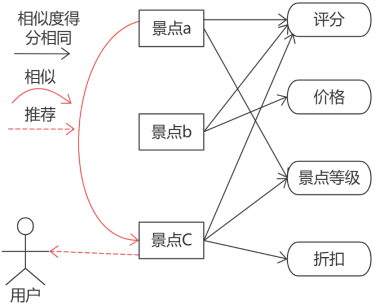
在协同过滤算法中,相似度的计算是关键。常用的相似度度量方法包括杰卡德(Jaccard)相似系数、余弦相似度和皮尔逊相关系数等。这些方法可以帮助准确地衡量用户或物品之间的相似程度,从而为推荐提供可靠的依据。这儿使用的基于景点的协同过滤,景点a和景点c相似,则把景点c推荐,如图5-1所示。
5.1.3协同过滤算法代码实现
协同过滤算法代码实现(核心代码):
bash
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# 假设的评分矩阵,行代表用户,列代表景点,值代表评分(0表示未评分)
ratings = np.array([
[4, 0, 2, 0, 1],
[0, 3, 4, 3, 0],
[2, 4, 0, 3, 2],
[5, 0, 3, 0, 4],
[0, 2, 3, 0, 5]
])
# 计算用户之间的余弦相似度
user_similarity = cosine_similarity(ratings)
# 将相似度矩阵转换为DataFrame以便查看
user_similarity_df = pd.DataFrame(user_similarity, index=range(ratings.shape), columns=range(ratings.shape))
# 推荐函数
def recommend_scenic_spots(user_index, ratings, user_similarity, top_n=2):
# 获取当前用户与其他用户的相似度
similar_users = user_similarity[user_index]
# 排除自身相似度(设为0)
similar_users[user_index] = 0
# 获取相似用户的索引,按相似度降序排列
similar_users_indices = np.argsort(-similar_users)
# 取前top_n个相似用户
top_similar_users = similar_users_indices[:top_n]
# 基于相似用户的评分来推荐景点
recommended_spots = {}
for i in top_similar_users:
user_ratings = ratings[i]
for spot_index in range(len(user_ratings)):
if user_ratings[spot_index] > 0 and ratings[user_index][spot_index] == 0:
if spot_index not in recommended_spots:
recommended_spots[spot_index] = user_ratings[spot_index]
else:
recommended_spots[spot_index] += user_ratings[spot_index]
# 按推荐分数降序排列景点
recommended_spots = sorted(recommended_spots.items(), key=lambda x: x, reverse=True)
return recommended_spots
# 为用户推荐景点
recommended_spots = recommend_scenic_spots(0, ratings, user_similarity)
print("为用户推荐的景点索引及推荐分数:", recommended_spots)