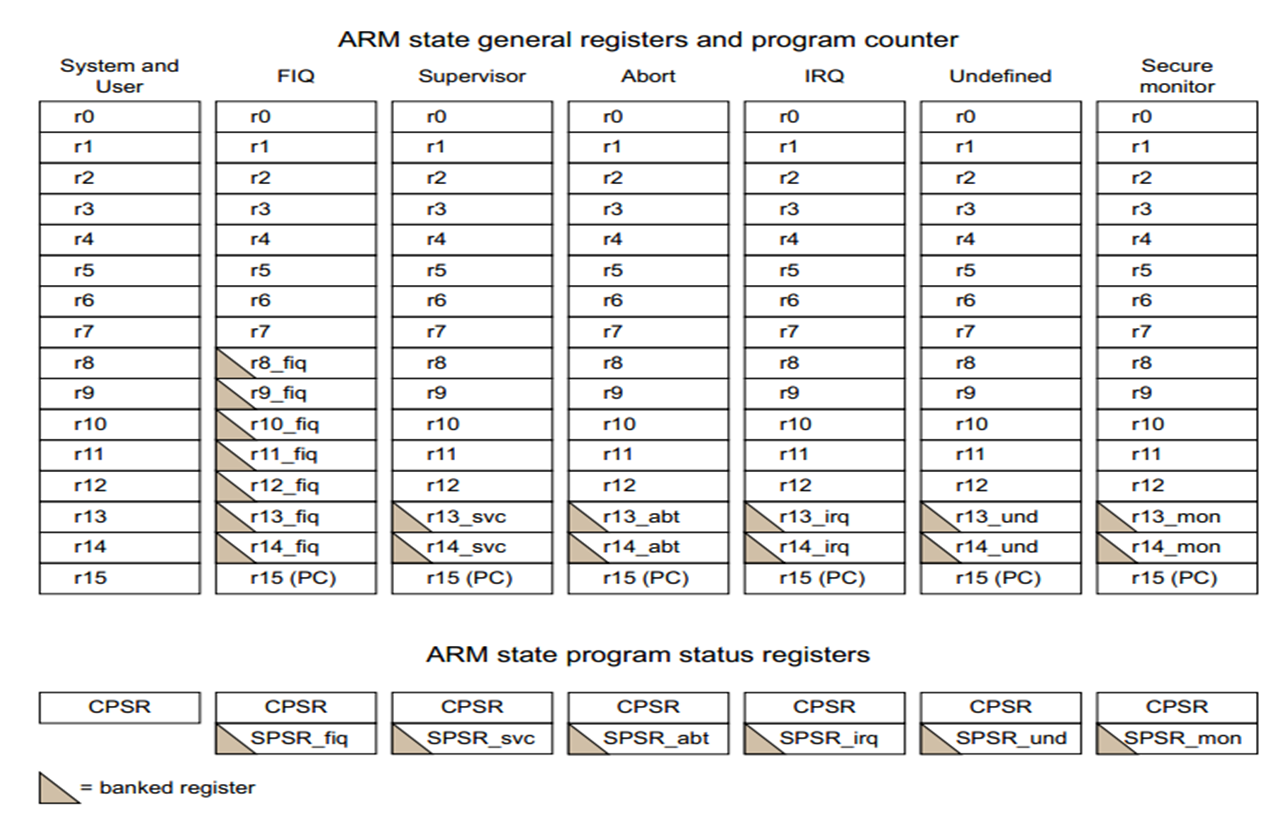
这是32位ARM架构(ARMv7及更早版本)的寄存器组织图,核心展示了ARM状态下不同处理器模式的通用寄存器、程序计数器和程序状态寄存器的映射关系,以及关键的**寄存器分组(banked register)**机制。
一、核心机制:寄存器分组
图中带阴影的单元格表示分组寄存器------它们在不同处理器模式下拥有独立的物理副本。当处理器切换模式时,会自动切换到对应模式的寄存器副本,无需软件保存/恢复,大幅提升异常处理和上下文切换的速度。
二、通用寄存器与程序计数器(r0-r15)
任意时刻,处理器只能看到16个通用寄存器(r0-r15),但整个系统实际包含37个物理通用寄存器。
| 寄存器范围 | 共享/分组特性 | 功能说明 |
|---|---|---|
| r0-r7 | 所有7种模式完全共享 | 通用数据寄存器,用于临时存储数据、函数参数和返回值 |
| r8-r12 | 仅FIQ模式有独立副本(r8_fiq-r12_fiq),其余模式共享 | 通用数据寄存器;FIQ模式独占这5个寄存器,无需保存即可直接使用,实现最快中断响应 |
| r13(SP) | 所有特权模式都有独立副本(r13_svc/r13_abt等) | 栈指针寄存器,每个特权模式拥有独立栈空间,避免不同模式栈互相干扰 |
| r14(LR) | 所有特权模式都有独立副本(r14_svc/r14_abt等) | 链接寄存器,保存子程序调用或异常返回的地址 |
| r15(PC) | 所有模式完全共享 | 程序计数器,指向当前正在取指的指令地址。注意:ARM状态下PC值=当前执行指令地址+8(源于经典三级流水线) |
三、程序状态寄存器
1. CPSR(当前程序状态寄存器)
所有模式共享,32位寄存器,保存处理器当前的核心状态:
- 条件标志位(N/Z/C/V):控制条件指令的执行
- 中断屏蔽位(I/F):分别屏蔽IRQ和FIQ中断
- 模式位(M4:0):决定处理器当前运行的模式
- T位:控制处理器处于ARM状态(32位指令)还是Thumb状态(16位指令)
2. SPSR(备份程序状态寄存器)
每个特权模式都有独立的SPSR副本(SPSR_fiq/SPSR_svc等):
- 当发生异常进入特权模式时,CPSR的当前值会自动保存到对应模式的SPSR
- 异常返回时,将SPSR的值恢复到CPSR,还原异常前的处理器状态
- 用户模式没有SPSR,因为它不是异常入口模式
四、7种处理器模式说明
| 模式名称 | 特权级别 | 主要用途 |
|---|---|---|
| User(用户) | 非特权 | 应用程序运行的默认模式,不能直接访问系统资源 |
| System(系统) | 特权 | 与用户模式共享所有寄存器,用于运行操作系统内核任务 |
| FIQ(快速中断) | 特权 | 处理高优先级、需要快速响应的中断 |
| IRQ(普通中断) | 特权 | 处理一般的外部硬件中断 |
| Supervisor(管理) | 特权 | 操作系统内核运行的核心模式,复位和软中断(SWI)会进入此模式 |
| Abort(中止) | 特权 | 处理内存访问异常(如预取指中止、数据中止) |
| Undefined(未定义) | 特权 | 执行未定义指令时进入,用于模拟协处理器指令等 |
| Secure monitor(安全监控) | 特权 | 支持ARM TrustZone技术,负责安全世界与非安全世界的切换 |
五、关键设计亮点
- FIQ模式的极致优化:独占r8-r14共7个分组寄存器,中断服务程序无需压栈保存寄存器,可直接执行,是ARM架构满足嵌入式实时性要求的核心设计。
- 模式隔离与安全:不同特权模式拥有独立的栈指针和程序状态备份,防止用户模式程序破坏系统内核状态。
- 低开销上下文切换:通过硬件自动切换分组寄存器,减少了异常处理时的软件开销。
仅 FIQ 模式有独立副本(r8_fiq-r12_fiq) 什么意思
这句话是ARM架构为了实现极致快速中断响应的核心设计,我用大白话和类比给你讲清楚:
一、先理解"寄存器副本"是什么
你可以把每个寄存器想象成一个临时储物柜,CPU干活时所有数据都要先放到这里。
"有独立副本"的意思是:这个储物柜不是大家共用的,而是专门给某个人(某一种处理器模式)单独准备的物理柜子。别人用他们的,你用你的,互不干扰。
二、"仅FIQ模式有"的具体含义
看你提供的表格中r8-r12这五行:
- 所有其他6种模式 (用户、系统、管理、中止、IRQ、未定义、安全监控):共用同一个物理的r8、r9、r10、r11、r12寄存器。也就是说,当处理器从IRQ模式切换到管理模式时,它们看到的r8-r12是完全相同的一组柜子。
- 只有FIQ模式 :它有自己单独的5个物理寄存器,分别叫r8_fiq、r9_fiq、r10_fiq、r11_fiq、r12_fiq。这5个柜子只有FIQ模式能访问,其他任何模式都看不到也用不了。
三、这个设计的巨大好处:让FIQ中断"快到极致"
这是ARM架构最经典的实时性优化,核心是省去了"保存/恢复寄存器"的耗时操作。
对比普通中断(IRQ)的处理流程
- 中断来了,CPU要立刻停下手里的活去处理中断
- 必须先把r8-r12里正在用的数据,全部保存到内存里(压栈)
- 才能使用r8-r12来执行中断服务程序
- 中断处理完,还要把刚才保存的数据从内存里恢复回r8-r12(出栈)
- 才能继续干之前的活
问题:访问内存的速度比访问寄存器慢几百倍,这两步"压栈/出栈"会产生很大的延迟。
FIQ中断的处理流程
- 中断来了,CPU立刻切换到FIQ模式
- 直接使用自己专属的r8_fiq-r12_fiq寄存器,里面是空的(或者保存的是上一次FIQ中断的数据)
- 中断处理完,直接切换回原来的模式即可
优势:完全省去了压栈和出栈的时间,中断响应速度比IRQ快得多。
四、补充说明
- FIQ模式不仅有r8-r12的独立副本,还有自己独立的r13(栈指针)、r14(链接寄存器)和SPSR(状态备份寄存器)。
- 也就是说,FIQ模式总共拥有7个专属寄存器,这意味着一个简单的FIQ中断服务程序可以完全不访问内存,只在寄存器里完成所有操作,达到纳秒级的响应速度。
- 这种设计专门用于处理对实时性要求极高的场景,比如工业控制中的电机调速、高速数据采集、汽车安全气囊的触发等。
r8_fiq与r8不是物理上同一个寄存器吗,别的模式为什么看不到
它们绝对不是同一个物理寄存器,是CPU内部完全独立的两个硬件存储单元 。你看不到的原因不是软件做了"隐藏",而是CPU硬件层面的"地址路由"机制决定的------这是ARM寄存器分组(Banked Register)最核心的硬件实现原理。
一、硬件实现:一个编号对应多个物理寄存器,靠"开关"切换
我用一个最贴近硬件的类比来说明:
- 你可以把CPU内部想象成一个有很多房间的大楼,每个物理寄存器就是一个独立的房间,里面放着数据。
- 寄存器编号(r0-r15)不是房间号,而是大楼门口的快递收件地址。
- 每个收件地址后面,连接着一个硬件多路选择器(MUX),它就像一个智能快递分拣开关。
- 这个开关的控制权,完全由CPSR寄存器里的**模式位(M4:0)**决定。
以r8为例的具体路由规则
当CPU执行指令访问"r8"这个地址时:
- 如果当前模式位是FIQ模式 (0b10001),硬件开关会自动把"r8"这个地址,连接到物理寄存器A(r8_fiq)
- 如果当前模式位是任何其他模式 (用户/系统/IRQ等),硬件开关会自动把"r8"这个地址,连接到物理寄存器B(通用r8)
关键结论:
- 物理寄存器A和B是两个完全独立的硬件单元,各自有自己的存储电路,互不影响。
- 任何时刻,一个地址只能连接到一个物理寄存器。
- 软件永远只能通过"r8"这个统一的名字访问,根本不知道也不需要知道背后具体是哪个物理寄存器。
二、为什么别的模式"看不到"r8_fiq?
因为硬件开关根本不会把r8_fiq连接到CPU的内部数据总线上,除非当前处于FIQ模式。
这就像:
- 你家有两个冰箱,一个放在客厅(通用r8),一个放在你的卧室(r8_fiq)。
- 家里的"取冰箱"指令,默认是去客厅拿东西。
- 只有当你切换到"卧室模式"时,"取冰箱"指令才会自动去卧室的冰箱拿东西。
- 你在客厅的时候,永远看不到也拿不到卧室冰箱里的东西,不是因为它被锁起来了,而是因为指令根本不会指向那里。
三、一个直观的代码实验验证
假设我们写一段汇编代码,在不同模式下读写r8:
asm
; 1. 先切换到用户模式,给r8赋值100
mov r8, #100 ; 此时写入的是 物理寄存器B(通用r8)
; 2. 触发一个FIQ中断,CPU自动切换到FIQ模式
; (以下是FIQ中断服务程序)
fiq_handler:
mov r0, r8 ; 此时读取的是 物理寄存器A(r8_fiq),值不是100!
mov r8, #200 ; 写入的是物理寄存器A,不会影响通用r8的值
subs pc, lr, #4 ; 退出FIQ,自动切回用户模式
; 3. 回到用户模式
mov r1, r8 ; 此时r1的值还是100,完全不受FIQ模式里r8操作的影响实验结果:用户模式下r8的值始终是100,FIQ模式里对r8的读写完全独立。
四、为什么要这么设计?而不是用同一个寄存器+内存保存?
核心原因是速度差了几百倍:
- 访问寄存器:1个CPU时钟周期
- 访问内存:几百个CPU时钟周期
如果r8_fiq和r8是同一个物理寄存器,那么FIQ中断来了就必须:
- 把r8里的用户数据保存到内存(几百个周期)
- 使用r8处理中断
- 把数据从内存恢复回r8(又几百个周期)
而现在的硬件分组设计,这两步耗时操作完全被硬件省略了。CPU切换模式时,只是拨动了一下硬件开关,耗时0个额外周期。
这就是为什么FIQ能做到"纳秒级响应",成为ARM架构在嵌入式实时领域称霸的核心原因。
五、补充:为什么不所有模式都做独立副本?
因为成本和功耗。
- 每个32位物理寄存器,都需要占用芯片上的晶体管资源。
- 如果7种模式每个都有16个独立寄存器,总共需要112个物理寄存器,芯片面积会大很多,功耗也会飙升。
ARM的设计是精准的取舍:
- 只给对实时性要求最高的FIQ模式,多分配了5个寄存器(r8-r12)
- 其他特权模式,只分配了最必要的2个寄存器(r13栈指针和r14链接寄存器)
- 这样既保证了关键场景的实时性,又控制了芯片的成本和功耗。
FIQ 模式只能访问r8_fiq吗 不能访问r8吗
是的,在FIQ模式下,你 只能访问r8_fiq,绝对不能直接访问那个所有其他模式共用的通用r8**。这不是软件做的权限限制,而是CPU硬件电路的物理连接决定的,没有任何指令可以绕过这个规则。
一、最核心的硬件事实
当CPU的CPSR模式位被设置为FIQ模式(0b10001)时:
- 所有汇编指令中出现的
r8这个名字,100%被硬件路由到物理寄存器r8_fiq - 那个通用r8的物理存储单元,此时完全与CPU的内部数据总线断开连接
- 软件没有任何办法,能让
r8这个编号指向通用r8的物理地址
用一个绝对准确的电路类比
你可以把每个寄存器编号想象成一个单刀双掷开关:
- 开关的公共端连接到CPU的指令执行单元(你写代码能控制的部分)
- 开关的两个触点分别连接到两个独立的物理寄存器:通用r8 和 r8_fiq
- 开关的拨杆 ,直接由CPSR寄存器的模式位硬件控制
当模式位是FIQ时,开关自动拨到r8_fiq;当模式位是其他任何值时,开关自动拨到通用r8。软件只能控制模式位,不能直接控制开关的位置。
二、一个彻底打消疑问的实验
假设在进入FIQ中断前,用户模式下的通用r8的值是0x12345678。现在进入FIQ模式,执行以下代码:
asm
; 此时处于FIQ模式
mov r0, r8 ; r0的值不是0x12345678,而是r8_fiq里原来的值
mov r8, #0xAAAAAAAA ; 写入的是r8_fiq,通用r8的值仍然是0x12345678
; 退出FIQ,自动切回用户模式
subs pc, lr, #4
; 回到用户模式
mov r1, r8 ; r1的值还是0x12345678,完全不受FIQ里操作的影响结论 :FIQ模式下对r8的所有读写,都与通用r8毫无关系。
三、那有没有办法在FIQ模式下"看到"通用r8?
有,但只能间接访问 ,而且会完全破坏FIQ的实时性优势,所以实际工程中绝对不会有人这么做。
两种间接访问方法
-
切换模式访问
你可以在FIQ模式下,临时把CPSR的模式位改成用户模式,此时
r8就会指向通用r8。但这样做:- 会破坏FIQ的中断屏蔽状态,可能导致其他中断嵌套
- 需要额外保存和恢复CPSR,增加了几十倍的延迟
- 完全违背了使用FIQ的初衷
-
内存中转
在进入FIQ之前,把通用r8的值提前保存到内存的某个固定地址。在FIQ模式下,通过读取这个内存地址来间接获取通用r8的值。但这样做:
- 访问内存的速度比访问寄存器慢几百倍
- 需要提前安排好内存空间,增加了系统复杂度
四、为什么要设计成"完全不能直接访问"?
这正是FIQ能做到"零延迟响应"的关键。
如果FIQ模式既能访问r8_fiq,又能访问通用r8,那么:
- 当FIQ中断到来时,你仍然需要先把通用r8里的数据保存到内存
- 否则,如果你在FIQ里不小心修改了通用r8,就会破坏被中断程序的状态
- 这样一来,FIQ和普通的IRQ就没有任何区别了
现在的设计是:FIQ模式拥有一个完全独立的寄存器环境。你在FIQ里可以放心大胆地使用r8-r14,完全不用担心会影响到其他模式的程序,也完全不需要做任何保存和恢复操作。
五、补充:r0-r7是个例外
注意,r0-r7在所有模式下都是共用同一个物理寄存器的。也就是说,在FIQ模式下,你访问r0,操作的就是那个所有模式都共用的通用r0。
这就是为什么一个标准的FIQ中断服务程序,通常只会使用r8-r13这几个专属寄存器。如果必须使用r0-r7,那么你还是需要把它们压栈保存,用完后再恢复。

用生活类比+逐行代码拆解讲透。这是ARM汇编最核心的基础,所有函数调用和异常处理都建立在这个机制上。
一、一句话先懂核心逻辑
BL 函数名 就相当于:
- 先在笔记本上记下"我现在看到第几行了,看完函数要从下一行继续"(这个"笔记本"就是LR寄存器)
- 然后跳转到函数的第一行去执行
- 函数执行完,照着笔记本上记的页码,翻回去继续看(这个"翻页"的动作就是把LR的值复制给PC)
二、最通俗的生活类比
想象你正在看一本说明书:
- 你手里的页码牌 就是
PC(程序计数器),它永远指向你正在看的那一页 - 你口袋里的便签纸 就是
LR(链接寄存器),专门用来记"一会儿要回到哪一页"
现在发生了这件事:
- 你正看到第100页(PC=100),这一页写着:"请先去看附录A的第200页,再回来继续"
- 你先在便签纸上写下101(LR=101)------因为看完附录A,你要从第101页继续看,而不是再看一遍第100页
- 然后你把页码牌翻到200页(PC=200),开始看附录A
- 附录A看完了,你看一眼便签纸上的101,把页码牌直接翻到101页(PC=LR)
- 你就从第101页开始,继续看原来的说明书了
这就是BL指令和LR寄存器工作的完整过程。
三、逐行代码拆解(绝对清晰)
我们写一段最简单的ARM汇编代码,把每一步PC和LR的值都标出来,你一看就懂。
asm
; 地址 指令
0x0000 mov r0, #1 ; 第1行:r0=1
0x0004 mov r1, #2 ; 第2行:r1=2
0x0008 BL add_func ; 第3行:调用add_func函数 【关键行】
0x000C mov r2, r0 ; 第4行:把函数返回值存到r2
0x0010 b . ; 第5行:程序结束,原地循环
; 这是add_func函数,地址从0x0020开始
0x0020 add r0, r0, r1 ; 函数第1行:r0=r0+r1=1+2=3
0x0024 mov pc, lr ; 函数第2行:返回 【关键行】我们一步一步看CPU是怎么执行的:
- 执行第1行(地址0x0000):PC=0x0000,执行完后PC自动变成0x0004
- 执行第2行(地址0x0004):PC=0x0004,执行完后PC自动变成0x0008
- 执行第3行(BL add_func,地址0x0008) :
- 第一步(自动) :CPU先把下一条指令的地址0x000C ,保存到LR寄存器里 →
LR=0x000C - 第二步(自动) :CPU把PC的值改成函数的地址0x0020 →
PC=0x0020 - 现在CPU就跳转到函数里去执行了
- 第一步(自动) :CPU先把下一条指令的地址0x000C ,保存到LR寄存器里 →
- 执行函数第1行(地址0x0020):PC=0x0020,计算r0=3,执行完后PC变成0x0024
- 执行函数第2行(mov pc, lr,地址0x0024) :
- 这就是"把LR的值复制到PC" →
PC=LR=0x000C - 现在CPU的PC指向了0x000C,也就是原来的第4行
- 这就是"把LR的值复制到PC" →
- 执行第4行(地址0x000C):PC=0x000C,把r0的值3存到r2里,执行完后PC变成0x0010
- 执行第5行:程序结束
四、解答你最可能有的两个疑问
疑问1:为什么LR保存的是"下一条指令的地址",而不是BL指令本身的地址?
因为BL指令已经执行完了。
如果LR保存的是BL指令的地址0x0008,那么函数返回后,CPU又会执行一遍BL指令,再次调用add_func,就会陷入无限循环。
所以正确的做法是,保存BL指令的下一条指令地址0x000C,这样返回后就能从被打断的地方继续往下执行。
疑问2:为什么"把LR的值复制到PC"就能实现返回?
因为PC是CPU的"指挥棒"。
PC寄存器的值,永远是CPU下一条要执行的指令的地址。你把PC改成什么值,CPU就会立刻跳转到那个地址去执行指令。
所以当你执行mov pc, lr时,就相当于告诉CPU:"别按顺序往下走了,直接去执行LR里存的那个地址的指令吧"。
五、两个非常重要的补充细节
1. BL和普通跳转指令B的区别
B 地址:只跳转,不保存LR。跳过去就再也回不来了,适合用在if/else、while这种不需要返回的跳转BL 地址:跳转+自动保存LR。专门用在函数调用,跳过去执行完还能回来
2. 异常返回和函数返回的微小区别
你图片里还提到了"产生异常时"的LR,这里有一个容易踩的坑:
- 函数调用返回 :直接用
mov pc, lr即可 - 异常返回 :必须用
subs pc, lr, #4(也就是把LR的值减4再复制给PC)
原因:异常发生时,CPU的流水线已经预取了异常指令的下两条指令,所以LR里自动保存的是"被打断指令的下下条地址"。减4之后,才能准确回到被异常打断的那条指令继续执行。
六、最后总结
BL 函数= 自动保存返回地址到LR + 跳转到函数mov pc, lr= 跳转到LR里保存的返回地址- 整个过程完全由CPU硬件自动完成,不需要你手动计算地址
- 这就是所有高级语言里"函数调用"功能在CPU层面的本质实现
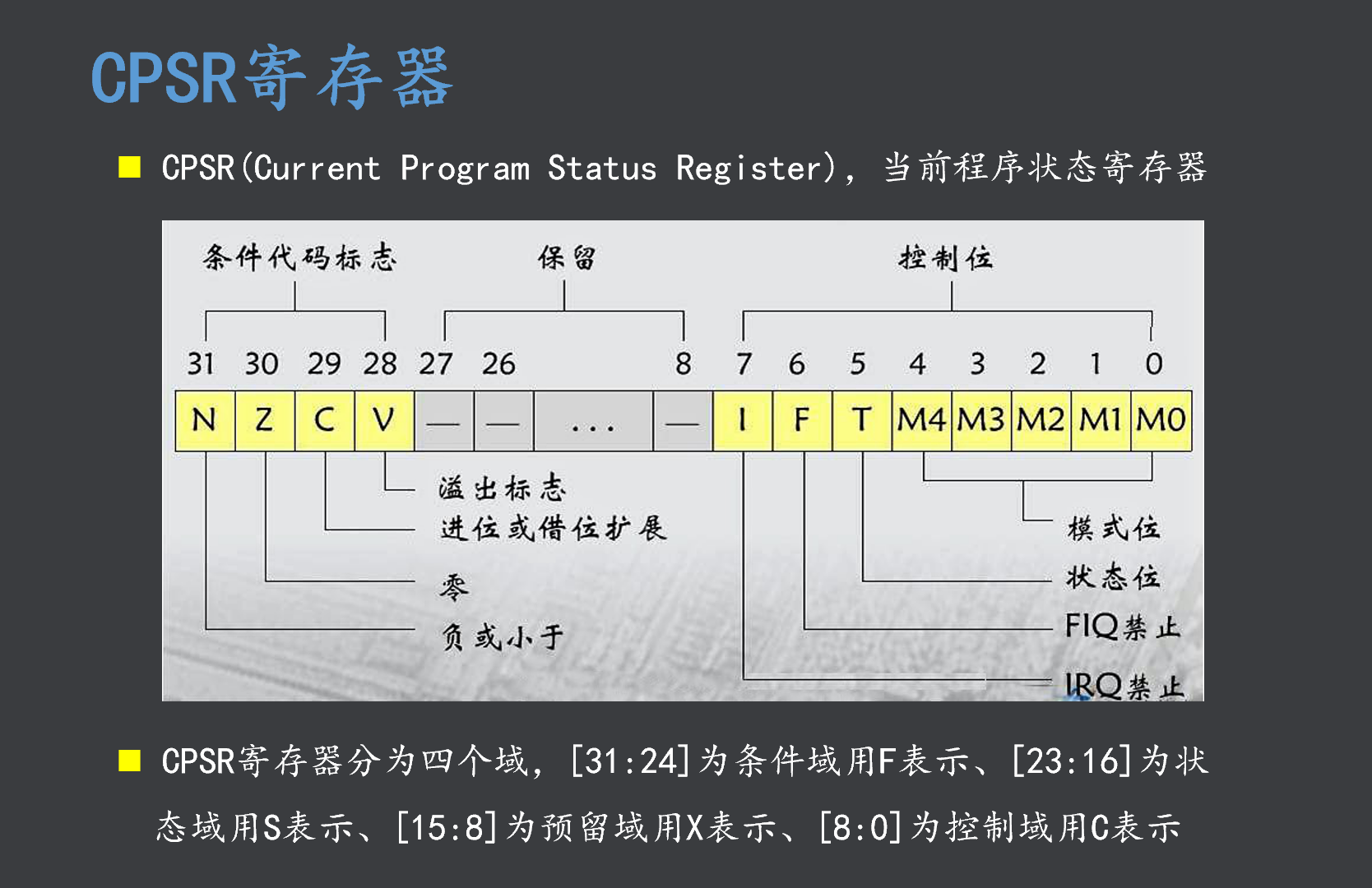
这是32位ARM架构(ARMv7及更早)的CPSR(当前程序状态寄存器)详解图 ,它是ARM CPU最核心的寄存器,相当于CPU的"状态总控制台",所有运算结果、中断开关、指令集类型和运行模式都由它控制。
一、CPSR总览
CPSR是一个32位的寄存器,所有7种处理器模式共享同一个物理CPSR。它的每一位都有明确的硬件含义,任何一位的变化都会直接改变CPU的行为。
二、核心位域详解(从高位到低位)
1. 条件代码标志位(31-28位):运算结果的"成绩单"
这4位是CPU执行算术/逻辑指令后自动设置的,所有ARM指令都可以根据这4位的值决定是否执行(这就是ARM著名的"条件执行"特性)。
| 位 | 名称 | 含义 | 置1条件 |
|---|---|---|---|
| 31 | N(负标志) | 负或小于 | 运算结果的最高位为1(即结果为负数) |
| 30 | Z(零标志) | 零 | 运算结果为0 |
| 29 | C(进位/借位标志) | 进位或借位扩展 | 加法:结果产生进位时置1 减法:结果产生借位时置0 移位/循环指令:保存移出的最后一位 |
| 28 | V(溢出标志) | 溢出 | 有符号数运算结果超出32位有符号数的表示范围时置1 |
关键区分:
- C位用于无符号数运算的溢出判断
- V位用于有符号数运算的溢出判断
- 这两个标志是独立的,互不影响
示例:
asm
mov r0, #0x7FFFFFFF ; r0 = 最大的32位有符号正数
add r1, r0, #1 ; r1 = 0x80000000
; 执行后:N=1(结果为负),Z=0,C=0(无进位),V=1(有符号溢出)2. 保留位(27-8位)
这20位是ARM公司预留的,用于未来架构扩展。软件绝对不能修改这些位,否则可能导致CPU进入不可预测的状态。
3. 控制位(7-0位):CPU的"控制面板"
这8位直接控制CPU的核心行为,只有在特权模式下才能修改。
| 位 | 名称 | 含义 | 置1效果 |
|---|---|---|---|
| 7 | I(IRQ禁止位) | IRQ中断禁止 | 置1时,CPU屏蔽所有普通外部中断 |
| 6 | F(FIQ禁止位) | FIQ中断禁止 | 置1时,CPU屏蔽所有快速中断 |
| 5 | T(状态位) | 指令集状态 | T=0:CPU处于ARM状态(执行32位指令) T=1:CPU处于Thumb状态(执行16位指令) |
| 4-0 | M4:0(模式位) | 处理器运行模式 | 5位二进制值决定CPU当前的7种运行模式 |
模式位M4:0对应表(与你之前看到的7种模式一一对应):
| M4:0 | 模式名称 |
|---|---|
| 0b10000 | User(用户) |
| 0b11111 | System(系统) |
| 0b10001 | FIQ(快速中断) |
| 0b10010 | IRQ(普通中断) |
| 0b10011 | Supervisor(管理) |
| 0b10111 | Abort(中止) |
| 0b11011 | Undefined(未定义) |
| 0b10110 | Secure monitor(安全监控) |
三、四个域的划分(图中底部说明)
ARM将32位的CPSR划分为4个独立的域,主要是为了在异常处理时能够选择性地保存和恢复状态,提高效率。
| 域 | 位范围 | 名称 | 包含内容 |
|---|---|---|---|
| F域 | 31:24 | 条件域 | 包含N、Z、C、V四个条件标志位 |
| S域 | 23:16 | 状态域 | 部分保留位和扩展状态位 |
| X域 | 15:8 | 预留域 | 全部为保留位 |
| C域 | 7:0 | 控制域 | 包含I、F、T和M4:0所有控制位 |
实际用途:在进入异常时,操作系统可以只保存C域(控制域),而不需要保存整个CPSR,减少上下文切换的开销。
四、重要补充知识点
-
CPSR与SPSR的关系
- 当发生异常时,CPU会自动将当前CPSR的值,保存到对应异常模式的SPSR(备份程序状态寄存器)中
- 异常返回时,再将SPSR的值恢复到CPSR,还原异常前的CPU状态
- 用户模式没有SPSR,因为它不是异常入口模式
-
CPSR的读写方式
- 不能直接用
mov指令修改整个CPSR - 必须使用专用指令:
mrs r0, cpsr:将CPSR的值读取到通用寄存器r0msr cpsr_c, r0:将r0的值写入CPSR的控制域(C域)msr cpsr_f, r0:将r0的值写入CPSR的条件域(F域)
- 不能直接用
-
条件执行的威力
因为有了这4个条件标志位,ARM指令可以在不跳转的情况下实现条件执行。例如:
asmadd r0, r1, r2 addeq r0, r0, #1 ; 只有当上面的加法结果为0(Z=1)时,这条指令才会执行这可以大幅减少分支跳转,提高代码执行效率。

