大模型量化到底在做什么:从浮点数表示到 Qwen FP8 实践
一、为什么大模型必须量化
大模型推理的第一个现实问题,往往不是"算不算得动",而是"放不放得下、搬不搬得快"。
以 27B 参数模型为例,如果权重以 BF16 或 FP16 存储,每个参数大致占 2 Byte,那么仅权重本身就需要:
Plain
27B x 2 Byte ≈ 54 GB这还没算 KV Cache、激活值、中间缓冲区和运行时碎片,上下文越长、并发越高,KV Cache 占用还会继续增长。
量化要解决的核心矛盾:
-
用更少的 bit 存权重,降低模型常驻显存
-
用更少的数据搬运完成一次前向,缓解显存带宽瓶颈
-
在精度可接受的前提下,让同一张卡承载更大的 batch、更长的上下文或更大的模型
因此,量化不是单纯为了"文件变小",而是大模型部署里绕不开的工程手段: 它把一部分数值精度让出来,换取更现实的显存预算和推理吞吐。
二、浮点数在计算机里是怎么表示的
理解量化之前,最好先把浮点数的表示方式弄明白。因为现代大模型使用的很多"低精度格式",本质上都是在浮点数的三段结构上做取舍。
浮点数可以看成二进制世界里的科学计数法。它通常由三部分组成:
-
符号位
sign -
指数位
exponent -
尾数位
mantissa或fraction
对一个规格化浮点数来说,它的值可以写成:
Plain
value = (-1)^sign x 2^(exponent - bias) x 1.fraction这里有三个关键点。
-
符号位只决定正负,即
0是正,1是负。 -
指数位决定动态范围,也就是这个格式到底能表示多大的数。指数通常不是直接存真实指数,而是存一个"加了偏移量的指数",这个偏移量叫
bias,比如 8 位指数常见的偏移量是127,因此:
Plain
真实指数 = 存储指数 - 127为什么需要这个偏移量?
因为真实指数既可能是正数,也可能是负数,比如
2^3表示放大 8 倍,2^-3表示缩小到 1/8。可是在硬件里,指数位本身更适合按无符号整数来存和比较。于是 IEEE 754 采用了一个很工程化的办法: 先把真实指数整体向右平移一个固定值,存进去时加上bias,读出来时再减掉bias。这样,负指数、零指数、正指数都能塞进同一个无符号字段里。举个直观例子,8 位指数的
bias = 127,那么真实指数-3会存成124,真实指数0会存成127,真实指数3会存成130。
- 尾数位决定精度:二进制浮点数在规格化之后,前面通常都会写成
1.xxxxx x 2^n的形式。也就是说,小数点前这一位在非零情况下几乎总是1。既然它几乎是固定的,硬件就没必要每次都专门存一遍,只需要存后面的xxxxx部分,读取时再默认把前面的1.补回来。这就是所谓的 hidden bit。
一个简单例子: -6.5 如何表示
先把 6.5 写成二进制:
Plain
6.5 = 110.1规格化之后是:
Plain
1.101 x 2^2于是:
-
符号位:
1 -
真实指数:
2 -
若偏移量为
127,存储指数就是129 -
尾数存
101...
这件事的重要性在于: 当你把指数位和尾数位砍短时,你牺牲的不是同一种能力
-
砍指数位,主要损失动态范围,更容易溢出或下溢
-
砍尾数位,主要损失有效精度,数值会变"糙"
这也是为什么 BF16 和 FP16 虽然都只有 16 位,但它们的工程含义完全不同。
三、FP32 / FP16 / BF16 / FP8 到底差在哪
先把最常见的几种格式放在一起看:
表里的 符号位 / 指数位 / 尾数位 表示这个格式内部的 bit 分配。1B 参数权重约占用 只估算权重本体,不包含 scale、KV Cache、激活值和运行时额外开销。
| 格式 | 位宽 | 符号位 | 指数位 | 尾数位 | 1B 参数权重约占用 | 特点 | 常见用途 |
|---|---|---|---|---|---|---|---|
FP32 |
32 bit | 1 | 8 | 23 | 约 4 GB |
范围大,精度高,最稳 | 训练基准、优化器状态、调试 |
FP16 |
16 bit | 1 | 5 | 10 | 约 2 GB |
精度还行,但指数位少,范围窄 | 早期混合精度训练、推理 |
BF16 |
16 bit | 1 | 8 | 7 | 约 2 GB |
指数位与 FP32 一样,范围大但精度较粗 |
现代大模型训练默认格式 |
FP8-E4M3 |
8 bit | 1 | 4 | 3 | 约 1 GB |
精度略好、范围较小,最大值约 ±448 |
前向权重、激活值 |
FP8-E5M2 |
8 bit | 1 | 5 | 2 | 约 1 GB |
范围更大、精度更低,最大值约 ±57344 |
梯度、更强调范围的场景 |
为什么 BF16 在大模型训练里几乎成为默认选项
一句话总结: BF16 用 16 bit 拿到了接近 FP32 的动态范围
它保留了 8 位指数,所以不容易因为数值过大或过小而溢出;同时把尾数从 FP32 的 23 位砍到 7 位,牺牲一部分精度来换显存和吞吐。
对大模型训练来说,范围稳定通常比小数点后很多位更重要,所以 BF16 成了现代大模型训练里的主力格式。
为什么 FP8 又能再往下压一层
FP8 把单个数压到 8 bit,相比 BF16/FP16 又减半一次。对推理来说,这直接减少权重存储和显存带宽压力;如果硬件有原生 FP8 Tensor Core,还可能带来更高吞吐。
它的代价也很明确: 指数位和尾数位都更少,动态范围和精度都更脆弱,因此 FP8 很依赖缩放因子、量化粒度和混合精度设计,通常不会把所有层、所有计算都一刀切成 FP8。
四、量化到底在做什么
量化不是简单把模型文件里的 BF16 改成 FP8 或 INT8,更准确地说,它是在做三件事:
-
找出哪些张量可以低精度保存。
-
给这些张量选择合适的低精度格式和缩放因子。
-
推理时用低精度存储、高精度累加的方式完成计算。
先决定压谁
大模型里能量化的对象很多,但最常见的是三类:
-
权重: 参数固定,最适合提前离线量化,也是最直接的显存节省来源。 -
激活值: 用户输入后动态生成,通常需要运行时动态 scale,收益更大但实现更难。 -
KV Cache: 长上下文推理时占用很高,量化后可以显著降低长上下文显存压力。
所以你看到的 W8A8,意思通常就是 Weight 8-bit, Activation 8-bit,也就是权重和激活都用 8 bit 表示,只压权重则可以理解为 W8A16 或类似形式。
再决定怎么压
量化的关键是 scale。对于整数型量化,最常见的简化公式是:
Plain
x_q = round(x / s)
x ≈ x_q x s这里 s 就是缩放因子,它负责把原始数值范围映射到低比特格式能表达的范围里
FP8 虽然是浮点数,不像 INT8/INT4 那样完全套这个公式,但工程上同样离不开 scale。原因是不同层、不同通道、不同 block 的数值分布差异很大,如果大家共用一个范围,误差会非常明显。
量化粒度决定误差和成本
scale 可以有不同粒度:
-
per-tensor: 整个张量一个 scale -
per-channel: 每个输出通道一个 scale -
per-group: 若干元素一组一个 scale -
per-block: 二维 block 一个 scale,例如128 x 128
粒度越细,越能适应局部数值分布,误差通常越小;但 scale 元数据更多,内核实现也更复杂。很多现代 FP8 模型会用 block-wise 量化,因为它比 per-tensor 更稳,又比过细粒度更容易和高性能内核对齐。
什么时候做量化
部署里最常见的是 PTQ,也就是 Post-Training Quantization: 模型训练完之后再量化。它不需要重训底座模型,成本低,适合把现成模型转换成推理版本。
PTQ 大致会做这几步:
-
加载已经训练好的高精度模型,比如
BF16/FP16。 -
选一批校准数据,或者直接扫描权重分布。
-
统计每层、每通道或每个 block 的数值范围。
-
根据目标格式计算 scale,把权重或激活映射到低精度范围。
-
保存量化后的权重、scale 元数据和量化配置。
所以 PTQ 的核心不是"继续训练模型",而是"给训练好的模型重新找一套低精度表示方式"。如果只做权重量化,甚至可以不需要大量校准数据;如果要量化激活值,校准数据就更重要,因为激活分布依赖真实输入。
另一类是 QAT,也就是 Quantization-Aware Training: 训练时就模拟量化误差,让模型提前适应低精度。它通常效果更稳,但成本更高,更像训练工程而不是普通部署工程。
所以,如果你的目标是"把一个现成大模型跑起来",一般先看官方量化版或 PTQ;如果你要极致压缩且质量要求很高,再考虑 QAT。
五、以Qwen3.5-27B-FP8为例,看 FP8 量化如何落地
Qwen/Qwen3.5-27B-FP8 不是"训练时全程 FP8"的模型,而是一个面向推理发布的 FP8 量化检查点,官方模型卡的说法是: 仓库包含 post-trained model 的 FP8 量化权重和配置文件,采用 fine-grained FP8 quantization,block size 为 128

原始模型通常仍然来自高精度训练
大模型训练阶段更关注数值稳定性,所以主干训练常用 BF16 这类格式,FP8 版本一般是在训练完成之后,通过 PTQ 产出的推理检查点。
也就是说,常见流程是:
-
先得到高精度模型,例如
BF16。 -
对主要权重做 FP8 量化。
-
保存 FP8 权重、量化配置和 scale 元数据。
-
推理框架读取这些信息,用支持 FP8 的 kernel 执行推理。
2. block size = 128 说明它不是粗粒度量化
如果整个权重矩阵只用一个 scale,局部数值分布差异会被抹平,误差很容易变大。block-wise 的做法是把矩阵切成小块,每个 block 单独记录 scale。
以一个尺寸接近 [5120, 17408] 的线性层为例,如果按 128 x 128 分块,scale 数量大致是:
Plain
5120 / 128 = 40
17408 / 128 = 136
scale 数量 ≈ 40 x 136这比整个矩阵共用一个 scale 更精细,也比每个元素一个 scale 更容易被高性能内核支持。FP8 的难点就在这里: 不是只把权重转成 8 bit,而是要给不同 block 找到合适的数值范围。
3. weight_scale_inv 是反量化线索
打开量化模型的索引或权重文件,常能看到类似 weight_scale_inv 的张量名。它说明 FP8 权重旁边还保存了 scale 相关元数据。
可以把推理时的逻辑理解成:
-
权重本体以 FP8 保存,降低显存和带宽压力。
-
每个 block 配套保存 scale 或 scale 的倒数。
-
GEMM 时 kernel 使用这些 scale,把低精度输入映射回合适的数值空间。
-
累加通常仍在更高精度里完成,例如
FP16 / BF16 / FP32。
所以 FP8 推理不是"所有数学都用 8 bit 算完",而是"低精度存储和搬运,高精度累加和关键计算"。
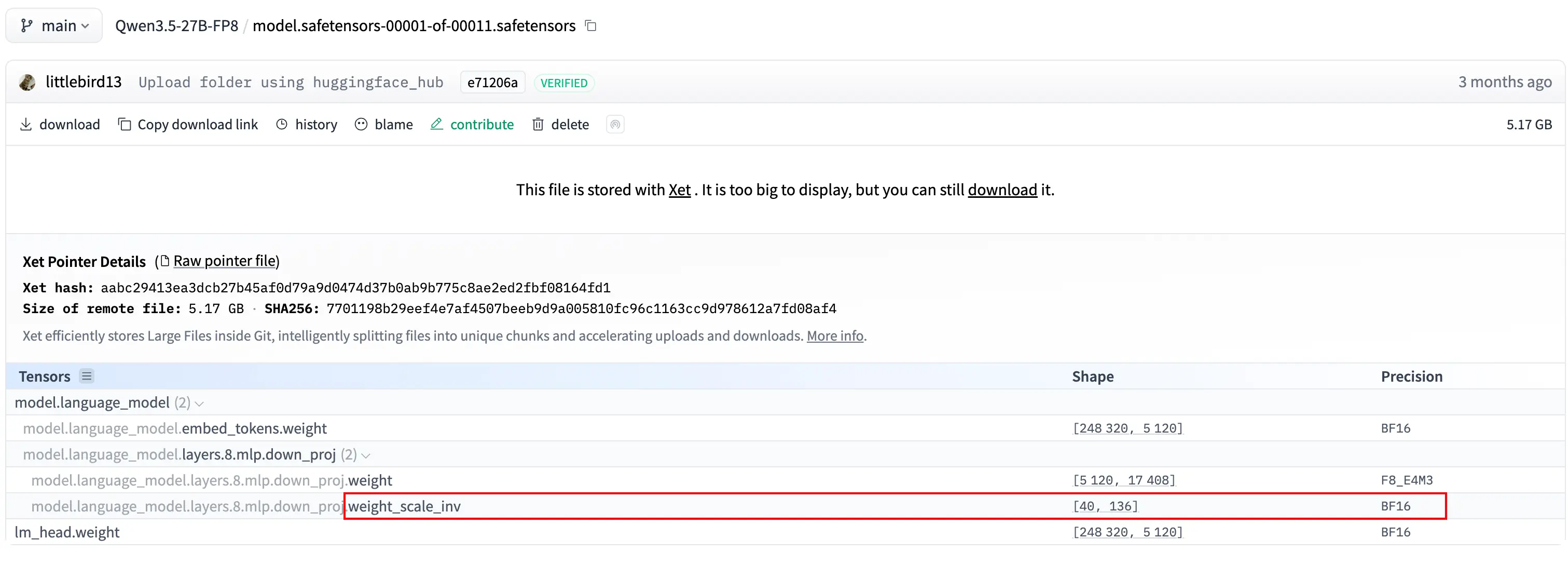
混合精度是质量的关键
高质量量化通常不会把所有层都压成 FP8,像 embed_tokens、lm_head、layernorm 这类层更容易影响最终输出分布,参数占比也未必大,保留较高精度通常更划算,如上图所示 embed_tokens和 lm_head权重仍为 BF16
真正值得压的是那些参数量大、矩阵乘法密集、对轻微误差相对不敏感的线性层,FP8 的收益主要来自这里: 大头权重变小,搬运更快,同时用 scale 和混合精度把质量损失控制住。
六、如果我想自己做量化,应该怎么做
先明确目标
量化通常有三种目标:
-
模型放不下: 优先做权重量化,先解决显存。
-
吞吐不够: 关注
W8A8、FP8 kernel、batch 场景下的端到端吞吐。 -
长上下文撑不住: 除了权重,还要看 KV Cache 量化。
目标不同,最优方案不一样:FP8 很适合有原生硬件支持、又希望尽量保留质量的推理场景;如果是在消费级显卡上硬塞模型,INT4/GPTQ/AWQ/GGUF 可能更现实。
路线 A: 直接使用官方量化检查点
这是最省心的方式。如果目标模型已经有官方 FP8、GPTQ、AWQ 或 GGUF 版本,通常优先用官方或社区验证较多的版本。
例如用 vLLM 跑 Qwen/Qwen3.5-27B-FP8:
Bash
pip install vllm
vllm serve "Qwen/Qwen3.5-27B-FP8"这条路线适合上线前验证,也适合先建立性能和质量基线。
路线 B: 在线量化,快速试效果
如果手里只有 BF16/FP16 模型,可以用推理框架在加载时做在线量化。例如 vLLM 支持类似下面的方式:
Bash
vllm serve meta-llama/Llama-3.1-8B --quantization fp8_per_tensor
vllm serve meta-llama/Llama-3.1-8B --quantization fp8_per_block在线量化适合快速实验,但它更像"部署时临时压缩",不一定是质量和速度最优的最终形态。
路线 C: 离线 PTQ,生成自己的量化检查点
如果要长期部署,最好做离线 PTQ,把量化后的模型保存下来。它和在线量化的区别是: scale 计算、权重转换和文件保存提前完成,部署时直接加载量化检查点。
实践上,PTQ 通常就是一个 Python 脚本。这个脚本一般接收三类输入:
-
原始模型: 通常是 Hugging Face 上的
BF16/FP16checkpoint。 -
量化方案: 比如
FP8_BLOCK、W8A8-INT8、INT4等。 -
忽略层和校准数据: 哪些层不压,以及是否需要用样本统计激活分布。
以 llmcompressor 的 FP8 block 量化为例,一个最小脚本大概长这样:
Python
from compressed_tensors.offload import dispatch_model
from transformers import AutoModelForCausalLM, AutoTokenizer
from llmcompressor import oneshot
from llmcompressor.modifiers.quantization import QuantizationModifier
MODEL_ID = "Qwen/Qwen3-30B-A3B"
SAVE_DIR = "Qwen3-30B-A3B-FP8-BLOCK"
model = AutoModelForCausalLM.from_pretrained(MODEL_ID, dtype="auto")
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
recipe = QuantizationModifier(
targets="Linear",
scheme="FP8_BLOCK",
ignore=["lm_head", "re:.*embed_tokens.*"],
)
oneshot(model=model, recipe=recipe)
# 简单 sanity check: 看量化后还能不能正常生成。
dispatch_model(model)
input_ids = tokenizer("Hello my name is", return_tensors="pt").input_ids.to(model.device)
output = model.generate(input_ids, max_new_tokens=20)
print(tokenizer.decode(output[0], skip_special_tokens=True))
model.save_pretrained(SAVE_DIR)
tokenizer.save_pretrained(SAVE_DIR)跑完之后,SAVE_DIR 里就是一个新的量化模型目录,里面会包含量化后的权重、scale 元数据和配置文件。后续可以用 vLLM 或 Transformers 加载它做推理测试。
这里真正要关心的不是代码有多长,而是几个选择:
-
targets: 量化作用到哪些模块。targets="Linear"表示只量化线性层,因为大模型里大部分参数量和矩阵乘法开销都集中在Linear层。 -
scheme: 用FP8_BLOCK,还是更粗的 per-tensor。 -
ignore: 哪些层不量化,比如lm_head、embed_tokens、layernorm。 -
eval: 用哪些真实任务样本验证质量。 -
hardware: 目标 GPU 是否真的支持对应格式和 kernel。
离线量化还有一个容易忽略的点: 做量化时通常需要先加载原始高精度模型,所以量化过程本身也需要足够显存。
七、总结
量化的本质不是改一个 dtype,而是重新设计数值表达、scale 粒度和推理计算路径
BF16 适合训练,是因为它保留了足够大的动态范围;FP8 适合推理,是因为它能进一步降低权重存储和显存带宽压力。以 Qwen3.5-27B-FP8 为例,真正起作用的是细粒度 block-wise FP8、scale 元数据、混合精度和推理框架的 kernel 支持。
做实践时,最稳的路线是: 先跑高精度基线,再试官方量化版或在线量化,最后根据真实任务决定是否做离线 PTQ。不要迷信最低 bit,能在质量、显存、吞吐和硬件兼容之间取得平衡,才是好的量化方案。
参考资料
-
Qwen 官方配置与索引文件:
config.json、model.safetensors.index.json -
NVIDIA Transformer Engine 文档: FP8 primer 与 block scaling
-
NVIDIA Technical Blog: FP8 formats and training/inference overview
-
vLLM 官方文档: FP8 W8A8、Online Quantization、Supported Hardware