1. 论文背景
最近的文本生成视频模型(Text-to-Video, T2V)已经可以生成比较流畅、视觉效果不错的视频。但是,当 prompt 涉及复杂的物理变化、因果关系或者常识推理时,模型仍然容易出错。
例如:
text
A piece of ice on a brown piece of paper sitting under the sun.人类很容易知道这个场景后续应该发生什么:
text
冰块在太阳下会逐渐融化
→ 出现水
→ 水逐渐浸湿纸张但是普通 T2V 模型可能只会生成一个"冰块在纸上"的视频,并不一定能正确表现"融化""水洼出现""纸被浸湿"这样的状态演化过程。
因此,这篇论文关注的核心问题是:
如何让视频生成模型更好地生成符合物理、常识和因果逻辑的状态变化过程?
可以把它归到:
text
causal / physical / commonsense reasoning for video generation也就是视频生成中的因果、物理和常识推理方向。
2. 核心思想
VChain 的核心思想是:
利用多模态大模型的推理能力,先生成一串关键视觉状态,再用这些关键帧辅助视频生成模型生成更合理的视频。
论文把这一串关键视觉状态称为:
text
Chain of Visual Thoughts也就是"视觉思维链"。
它和普通 Chain-of-Thought 的区别是:
text
普通 CoT:中间推理过程是文字
VChain:中间推理过程是一组图像关键帧例如对于"冰块在太阳下"这个 prompt,VChain 会先生成类似这样的关键帧序列:
text
img0:完整冰块放在纸上
img1:冰块开始融化
img2:出现水洼
img3:纸张被水浸湿这些图像关键帧可以作为视频生成模型的"视觉锚点",帮助模型知道视频应该朝哪个方向演化。
3. 方法流程
VChain 的方法主要分为三个阶段:
text
1. Visual Thought Reasoning
2. Sparse Inference-Time Visual-State Adaptation
3. Video Sampling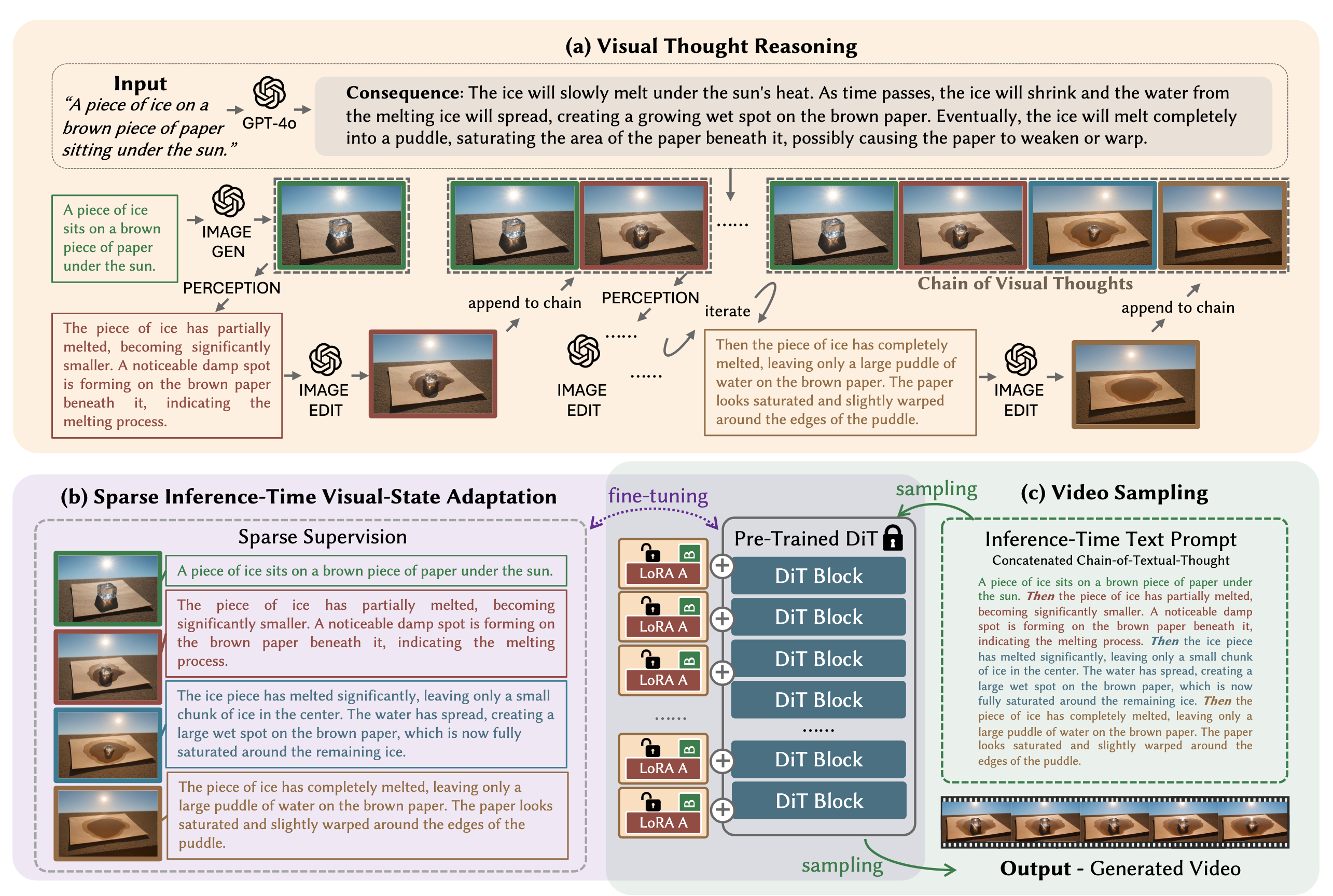
3.1 Visual Thought Reasoning
第一阶段是用 GPT-4o 做视觉推理。
给定用户输入的 prompt:
text
pGPT-4o 首先推理这个场景可能导致什么结果,也就是论文里说的 consequence。
例如:
text
输入:A piece of ice on a brown piece of paper sitting under the sun.
GPT-4o 推理:
冰块会因为太阳的热量融化,形成水洼,并逐渐浸湿纸张。然后 GPT-4o 会生成第一帧的描述 txt0,再调用图像生成模型生成第一张图 img0。
之后,GPT-4o 会根据当前已经生成的视觉链,继续预测下一步应该如何变化,并生成对应的图像编辑指令 txti,再得到下一张图 imgi。
最终会得到:
text
chainvis = [img0, img1, ..., imgN-1]
chaintxt = [txt0, txt1, ..., txtN-1]其中:
text
chainvis:一组关键帧
chaintxt:每张关键帧对应的文字描述这一阶段的作用是:
让多模态大模型先帮视频生成模型"想清楚"事件应该如何发展。
3.2 Sparse Inference-Time Visual-State Adaptation
第二阶段是 VChain 最关键的地方。
对于一个 user prompt,前面已经得到了:
text
chainvis = [img0, img1, ..., imgN-1]
chaintxt = [txt0, txt1, ..., txtN-1]VChain 会把每一张关键帧 imgi 当作一个 one-frame video,并和对应的文字描述 txti 配对,构造一个很小的训练集:
text
(img0, txt0)
(img1, txt1)
...
(imgN-1, txtN-1)然后用这些 pairs 对视频生成模型进行临时 LoRA 微调。
也就是说,对于每一个 user prompt,都会临时训练一个 prompt-specific LoRA。
可以理解为:
text
一个 prompt
→ 生成 N 张关键帧
→ 得到 N 个 image-text pairs
→ 用这些 pairs 临时训练 LoRA
→ 得到当前 prompt 专属的 adapted video generator注意,这里并不是训练出一个新的大模型,而是在原始预训练视频模型的基础上,临时训练一个 LoRA adapter。
所以更准确地说,得到的是:
text
frozen pre-trained video generator + prompt-specific LoRA3.3 flow-matching objective
对于每张关键帧 imgi,模型会把它看作目标图像,然后在噪声和目标图像之间采样一个中间状态,让模型学习如何从噪声状态走向目标图像。
论文中使用的是 flow-matching objective,而不是传统 DDPM 里直接预测噪声的 loss。
可以简单理解为:
text
VChain / flow matching:预测从噪声到目标图像的流动方向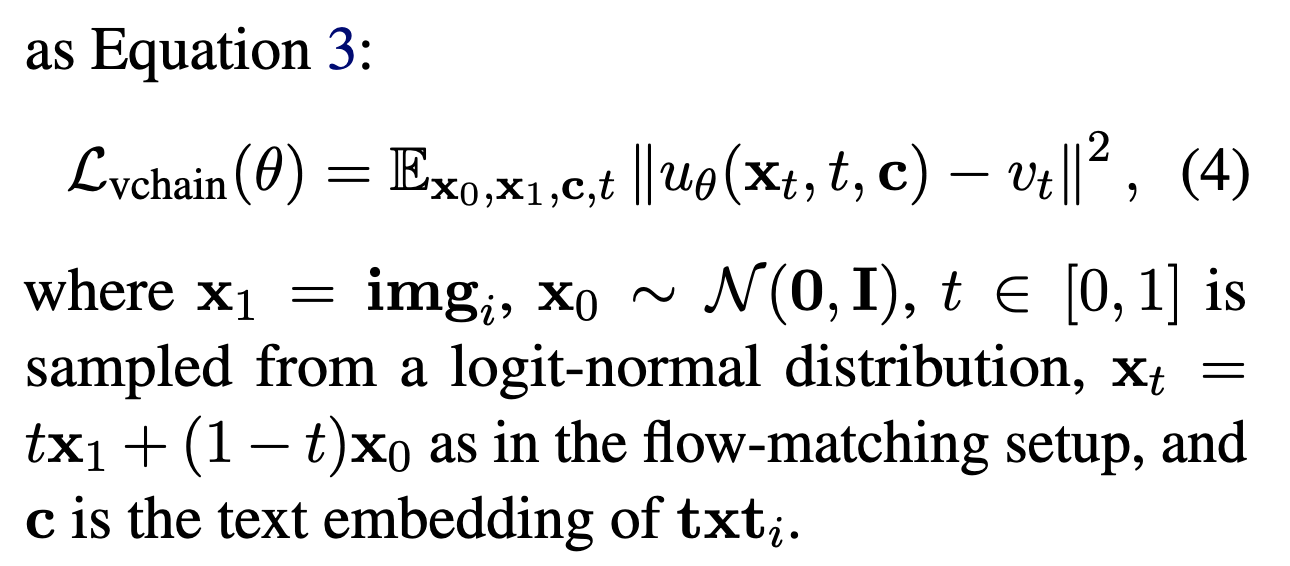
3.4 Video Sampling
第三阶段是最终生成视频。
前面第二阶段已经得到了一个临时适配后的 video generator。然后 VChain 会把所有 textual thoughts 拼成一个长 prompt:
text
txtconcat = txt0 + txt1 + ... + txtN-1最后把这个长 prompt 输入到已经 LoRA-adapted 的视频生成模型中,生成最终视频。
整体可以写成:
text
user prompt
→ GPT-4o 推理 consequence
→ 生成 chainvis 和 chaintxt
→ 用 (imgi, txti) 训练 prompt-specific LoRA
→ 拼接 textual thoughts 得到长 prompt
→ 输入 LoRA-adapted video generator
→ 输出 video4. 我的理解
我理解 VChain 本质上是:
利用 LVLM / MLLM 的视觉理解和因果推理能力,来辅助 T2V 模型生成更合理的视频。
它不是简单地让 GPT-4o 帮忙扩写 prompt,而是进一步生成了关键帧序列。
普通 prompt augmentation 只是告诉模型:
text
冰块会融化,纸会被浸湿。而 VChain 是直接给模型构造出一组视觉状态:
text
完整冰块
→ 开始融化
→ 出现水洼
→ 纸张被浸湿这些关键帧再通过 LoRA tuning 被注入到视频生成模型中。
所以 VChain 的重点不是画质提升,而是增强视频中的:
text
状态演化
因果一致性
物理合理性
常识推理5. 这篇论文的贡献
我觉得这篇论文的主要贡献有三个。
5.1 提出了 Chain of Visual Thoughts
以前很多方法主要是让 LLM 生成更详细的文字 prompt。
VChain 的不同点是:它让多模态大模型生成一组视觉关键帧,把推理过程从文字变成了图像。
这使得视频生成模型不只是看到文字描述,还能看到一些关键视觉状态。
5.2 把 LVLM 的推理能力引入视频生成
视频生成模型本身不一定擅长因果推理,但是 GPT-4o 这类多模态大模型具有较强的视觉理解和未来状态预测能力。
VChain 的思路是:
text
LVLM 负责推理事件如何发展
image generation model 负责生成关键帧
video generation model 负责生成连续视频这种分工比较清晰。
5.3 通过 inference-time tuning 注入关键帧信息
VChain 没有重新训练整个视频生成模型,而是在每个 prompt 上临时训练一个 LoRA。
这种方式的优点是:
text
不需要大规模真实视频数据
不需要人工标注
可以针对每个 prompt 生成专属的视觉状态链6. 不足与思考
6.1 代码和完整实现问题
没有公开完整可复现实验代码。
6.2 需要补充一个更有说服力的对比实验
我觉得论文还应该比较一种 baseline(Offline LoRA fine-tuning):
把所有 user prompts 生成的 paired data 收集起来,统一做一次 LoRA fine-tuning,得到一个新的 fine-tuned model,然后在测试时只输入长 prompt 生成 video。
也就是说,不是每个 prompt 都临时训练一个 LoRA,而是:
text
训练阶段:
所有 prompt 的 (imgi, txti) pairs
→ 组成一个训练集
→ 统一训练一个 reusable LoRA / fine-tuned model
测试阶段:
长 prompt
→ fine-tuned model
→ video这个对比很重要,因为它可以回答:
VChain 一定需要 inference-time tuning 吗?
如果把所有 visual thoughts 数据积累起来,统一训练一个 LoRA,说不定可以让模型真正学到一些通用的物理、常识和因果状态演化能力。
这样相比每个 prompt 临时 tuning,可能有几个优势:
text
推理更快
部署更简单
不需要每次都训练 LoRA
base model / adapter 得到长期增强
对社区更有贡献如果这方法效果接近甚至超过 VChain,那么说明 VChain 的关键贡献可能并不是 inference-time tuning,而是 visual thought 数据本身。
7. 总结
VChain 是一篇比较有启发性的工作。它关注的是视频生成中一个很重要的问题:
模型能不能生成符合因果、物理和常识的视频状态演化过程?
未来的视频生成模型不应该只追求画质和流畅度,还应该具备对视觉状态变化、物理规律和因果关系的理解能力。