原子操作类实现原理
在Java中,多线程同时更新一个变量是不安全的,所以Java提供了多种原子操作类来实现变量的线程安全更新。这些原子操作类总体上可以分为4种原子更新方式,分别是原子更新基本类型、原子更新数组、原子更新引用和原子更新属性。
1、AtomicInteger实现原理
在多线程环境下,i++操作不是原子性的,存在线程不安全的问题。那如何实现线程安全的i++操作呢?在JDK1.5之前,需要通过synchronized关键字来确保多线程的安全性。虽然synchronized关键字能确保多线程的安全性,但是synchronized关键字涉及线程之间的资源竞争与锁的获取和释放,整体性能比较低。JDK1.5提供了int类型的原子类AtomicInteger。
1.1、设计原理
Thomas E. Anderson提出的SPIN ONTEST-AND-SET的设计思想。AtomicInteger就是采用了这一设计思想,在内部定义了一个volatile关键字修饰的int类型的value变量。另外,AtomicInteger通过CAS硬件原语方式对value变量进行修改,expect是每次修改前的value值,update是要修改的预期值。如果修改成功,可以按场景需要返回修改前的值或者修改后的值。伪代码如代码所示。


1.2、源码分析
AtomicInteger仅对Unsafe的底层接口做了相关的包装。
AtomicInteger的内部定义了static的全局变量Unsafe,同时定义了value字段在对象里的内存偏移量value。JVM通过对象的基础内存地址+内存偏移量就能快速获取value字段的内存地址,这种设计可以加快value字段内存寻址的速度。Unsafe初始化过程如代码所示。

1. value的读取与赋值
因为volatile关键字可以确保value的实时可见性与赋值的原子性,所以get方法与set方法都是线程安全的。getAndSet方法是通过Unsafe的getAndSetInt方法来实现线程安全性的。如下代码是value字段的读取与赋值方法。

2. value++与value--
针对数值的value++与value--操作,AtomicInteger提供了getAndIncrement、getAnd-Decrement、getAndAdd这3个方法,如代码所示。这3个方法都是调用Unsafe的getAndAddInt方法来实现的。


3. ++value与--value
对于数值的++value与--value操作并返回修改后的值,AtomicInteger提供了increment-AndGet、decrementAndGet、addAndGet方法,如代码所示。这3个方法都是调用Unsafe的getAndAddInt方法来实现的。

2、AtomicBoolean实现原理
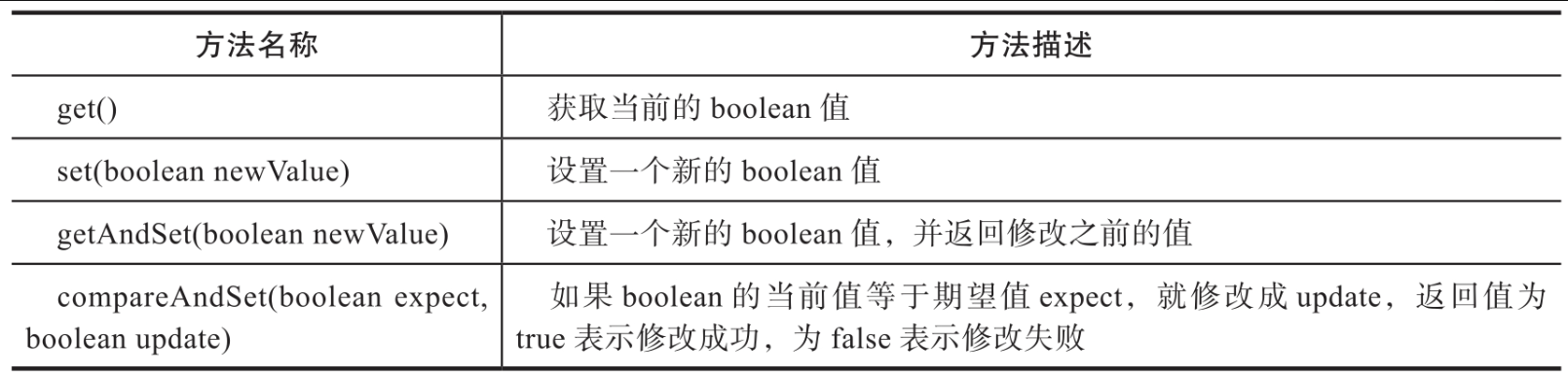
AtomicBoolean的功能是线程安全地修改boolean类型的变量。AtomicBoolean提供了boolean类型变量的安全读取与修改方法,具体方法如表所示。
2.1、设计原理
虽然Java定义了boolean类型,但是只对它提供了非常有限的支持。JVM并没有定义boolean类型的操作能力,而是采用int类型来代替。同样,AtomicBoolean内部也定义了int类型的变量value,并用volatile关键字修饰。value的值为1表示true,value的值为0表示false。volatile能确保多线程的可见性。AtomicBoolean是通过VarHandle的CAS能力来实现数据修改的,并通过volatile与CAS组合来确保多线程的可见性与原子性。
2.2、源码分析
AtomicBoolean的功能完全是依赖VarHandle的CAS相关能力来实现的。AtomicBoolean仅仅是对VarHandle的底层接口进行了相关的封装。
1. VarHandle全局引用
AtomicBoolean的内部定义了static的全局变量VarHandle,这么做是为了保证JVM安全性,因为VarHandle直接和JVM进行交互,会存在一定的安全隐患。
2. boolean值的读取与设置
volatile关键字可以确保赋值操作可见性与原子性,get方法与set方法都是线程安全的。get方法是获取到int值后与0进行比较,不等于0就是true,等于0就是false。set方法会先把boolean转换为int后再设置值。
getAndSet方法每次会先调用get方法获取最新的值,然后调用VarHandle的getAndSet方法来修改value的值。boolean值的读取与设置如代码所示。

3. boolean值的比较与交换
compareAndSet方法会先将boolean类型的值转换为int,然后调用VarHandle的compare-AndSet方法来修改value的值,boolean值的比较与交换如代码清单所示。

3、AtomicIntegerArray实现原理
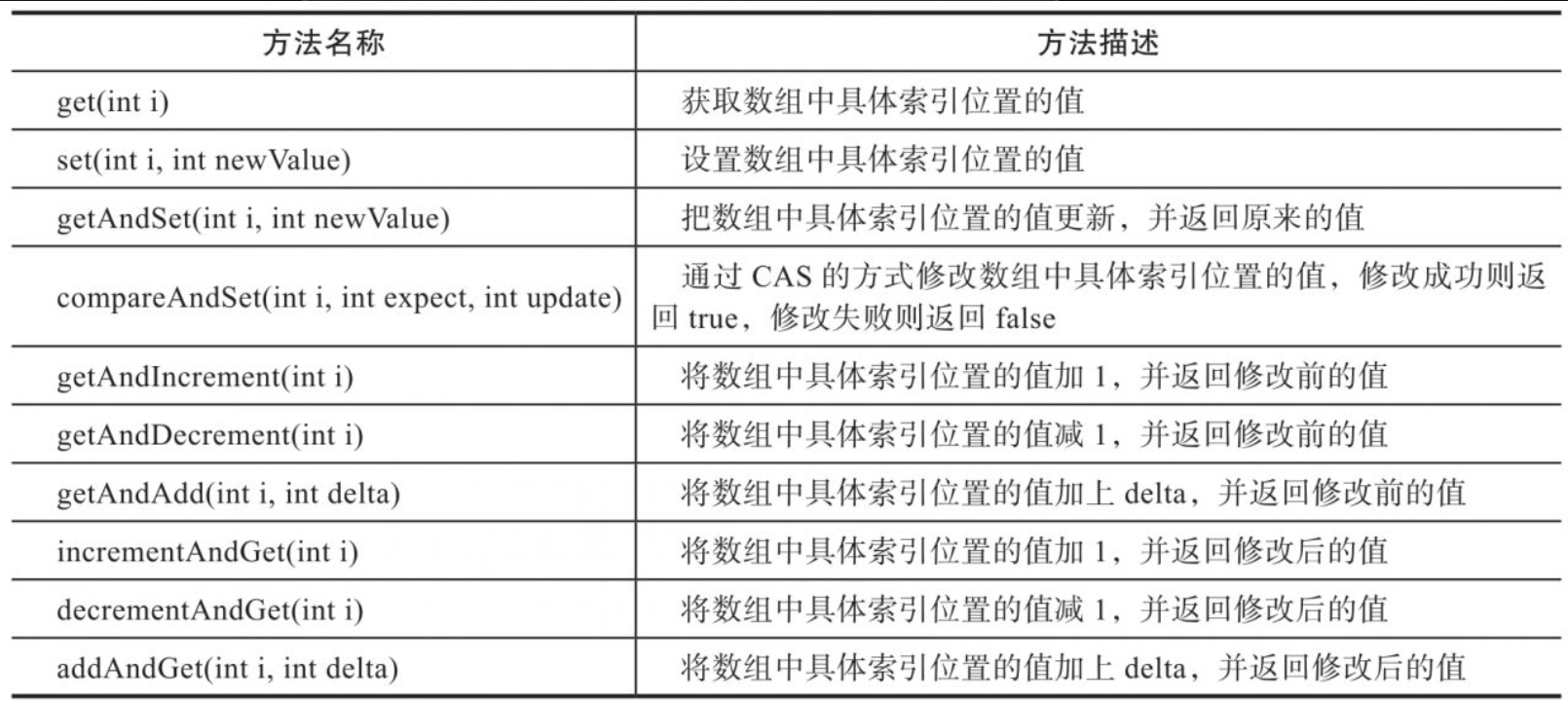
AtomicIntegerArray提供了安全修改int型数组元素的相关方法,具体方法如表所示。
3.1、设计原理
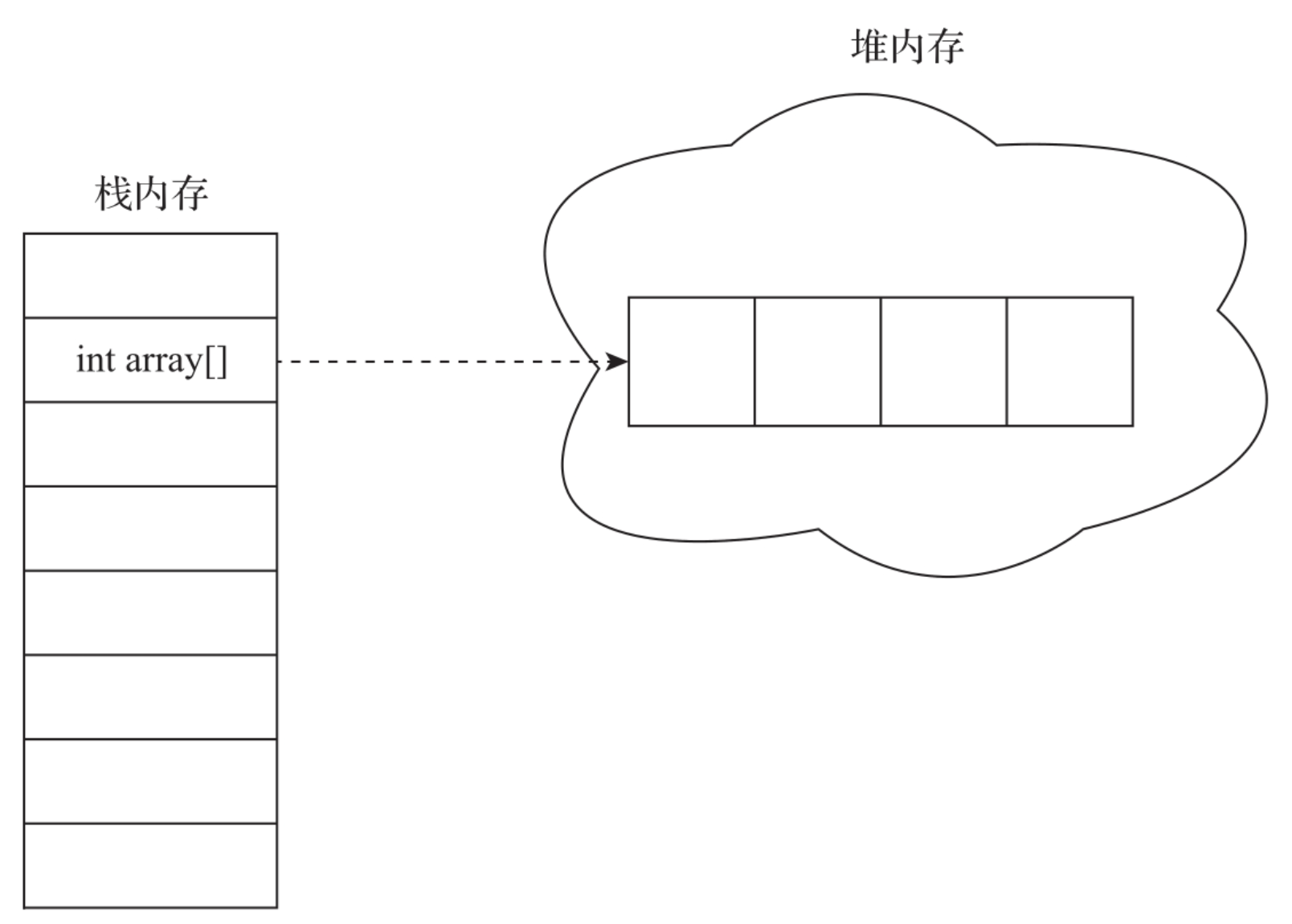
数组的数据是存储在堆内存中的,线程栈中只存储数组的引用指针,指向的是数组的内存首地址。每次操作数组中某个具体数据的时候,都只将数组中具体位置的元素读出来,对数据进行修改后写回,具体过程如图所示。
如下代码是一个简单的ArrayTest数组用例,用来演示数组的数据读写过程。ArrayTest定义了一个int数组,set方法对数组的0号元素进行了赋值。

可以通过javap-v ArrayTest.class命令来查看编译后的字节码,set方法的字节码如代码所示。
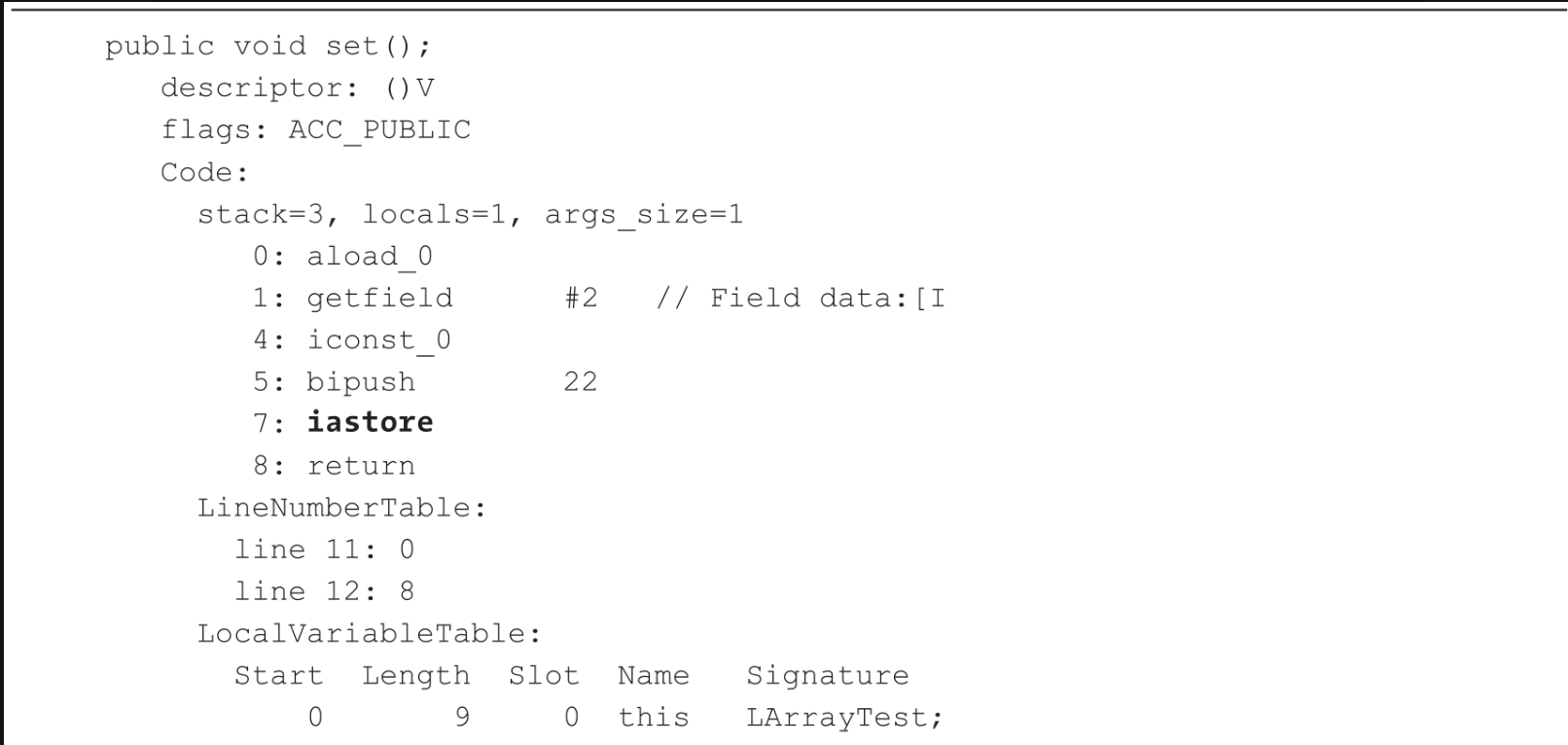
在JVM中,iastore指令专门用于对数组进行赋值。在执行iastore指令前,需要将值、索引、数组引用3个参数压入操作数栈。iastore指令会弹出这3个值,并将值赋给数组中指定索引位置上的值。在代码清单7-9中,getfield指令用于获取数组的首地址,iconst_0是在内存中定义了本地变量0(即数组的0号索引),然后调用bipush指令对数组的0号位置赋值22,最后调用iastore指令通过值、索引、数组引用来修改数组中0号索引位置上的值。多个线程同时修改数组的不同元素是可以做到线程安全的。如下图所示,线程1对0号索引位置元素进行修改不会影响线程2对1号索引位置元素的修改。
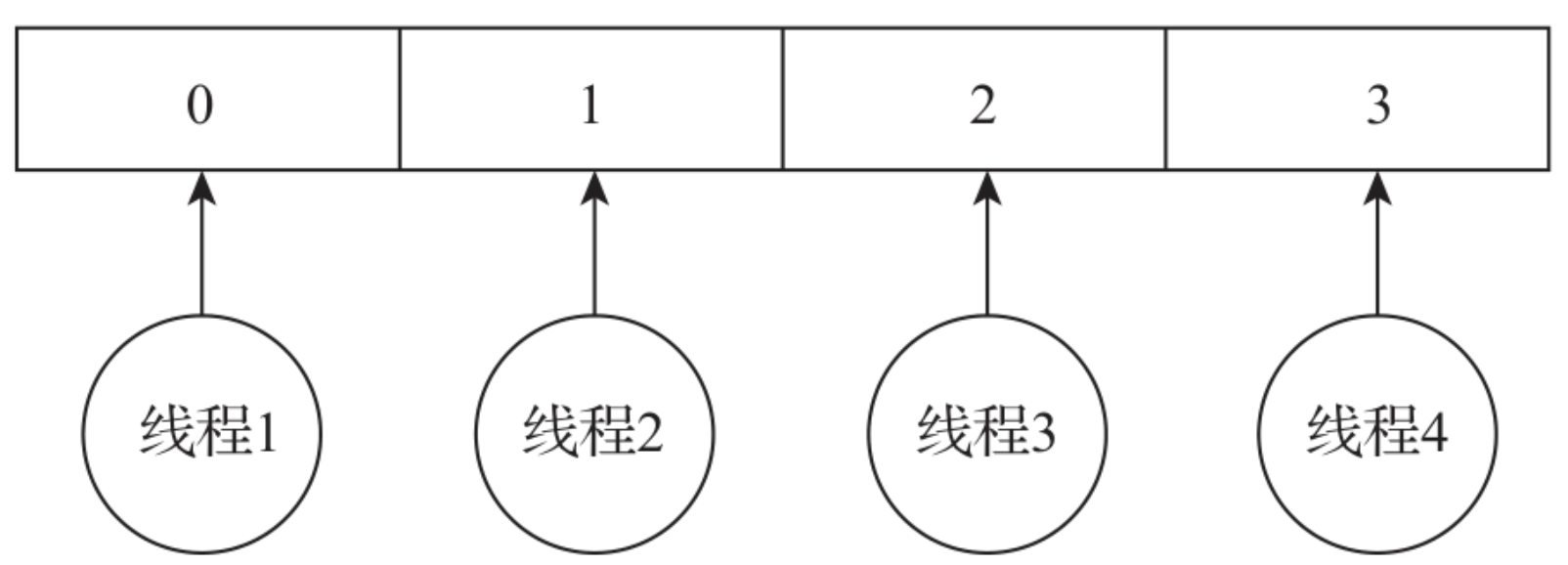
而线程1、线程2、线程3同时修改数组中1号索引位置上的数据,则会出现线程安全的问题,如图所示。
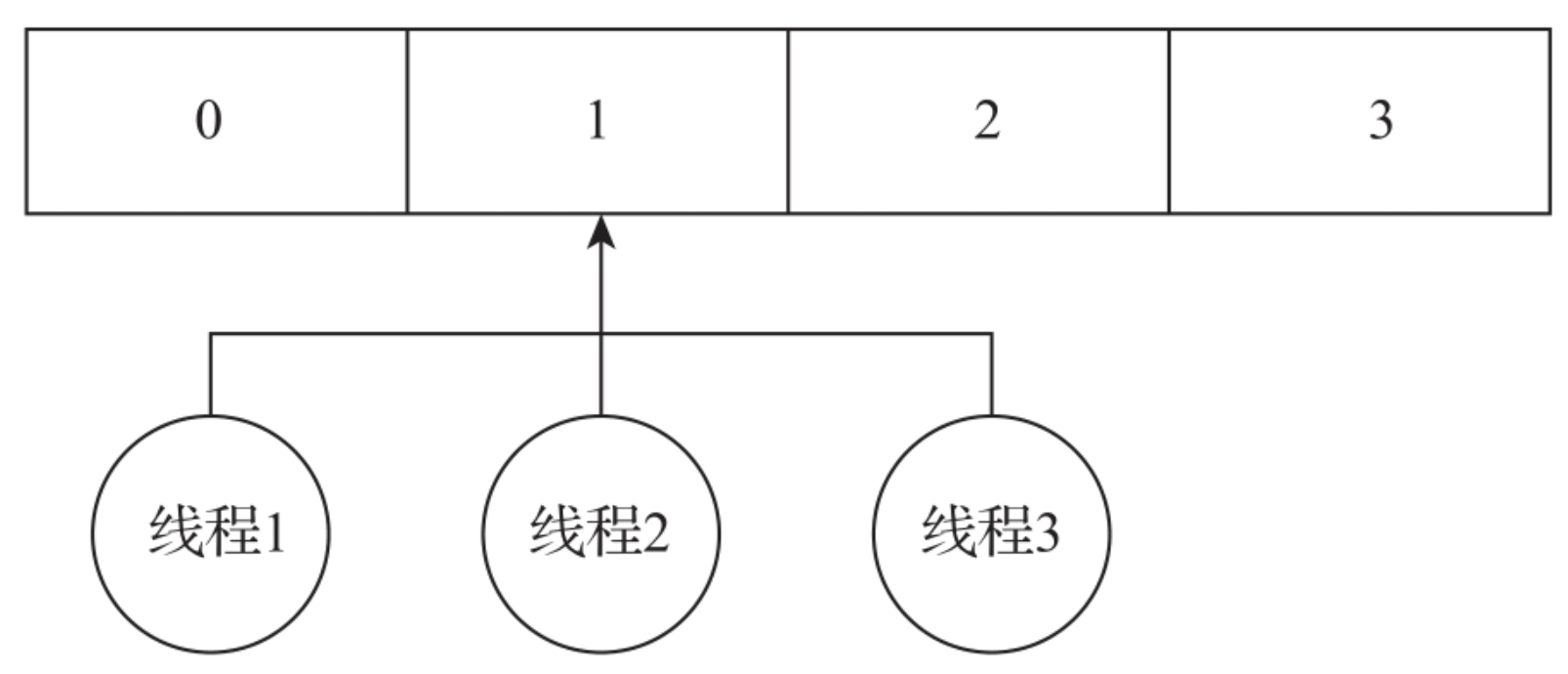
AtomicIntegerArray真正要解决的问题是:实现多线程同时对int数组中某个具体元素的线程的安全修改。由AtomicInteger实现原理可知,只要知道数组元素的内存偏移量,就可以通过VarHandle的相关方法来读取或者修改数组内容的值。
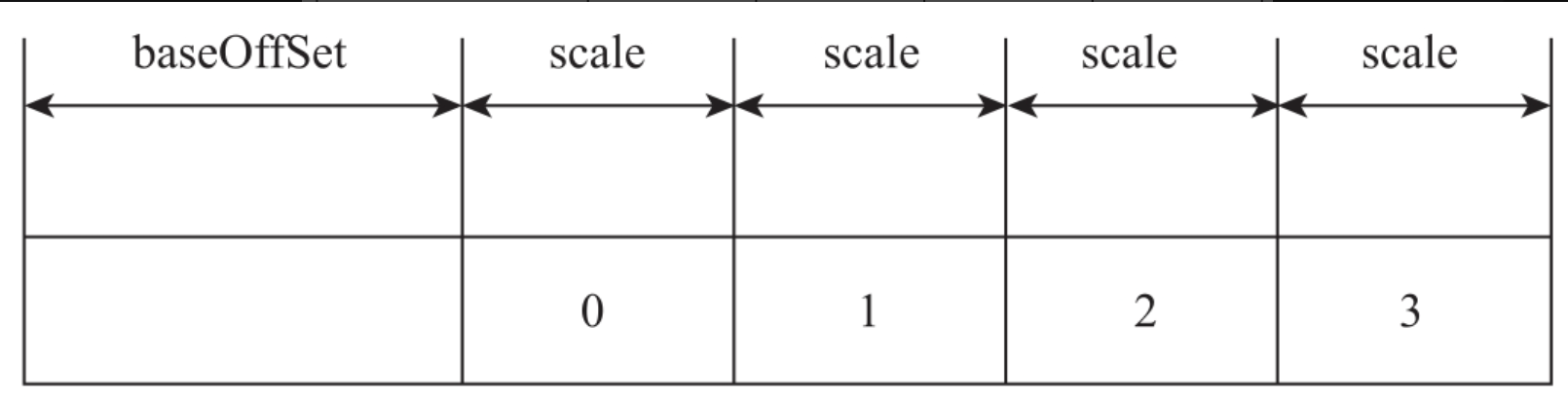
如下图所示,数组元素偏移量就是数组的首地址相对于对象的偏移量(baseOffSet)+每个元素的长度(scale)*具体的索引值,例如3号索引位置的内存偏移量就是baseOffSet+scale×3。
3.2、源码分析
AtomicIntegerArray通过VarHandle的volatile实现内存实时同步以及CAS原子性修改的相关能力。
1. VarHandle初始化
如代码所示,AtomicIntegerArray的内部定义了VarHandle的全局变量AA。

2. 数据读取与修改
数据读取是通过VarHandle的getVolatile来实现的。数据修改是通过VarHandle的setVolatile实现的。数据读取与修改的实现如代码所示。

3. CAS修改数组元素
compareAndSet方法提供了CAS修改数组元素的能力,如代码所示。

4. 数组元素加减
AtomicIntegerArray提供了一组对数组元素加1与减1的方法,这些方法最终都是调用VarHandle的getAndAdd方法来实现的,如代码所示。

4、AtomicIntegerFieldUpdater实现原理
AtomicIntegerFieldUpdater是一种基于反射的实用工具,可以对指定类的volatile关键字修饰的int字段进行原子性修改,以确保int类型数据修改的安全性。
如代码所示,AtomicIntegerUpdaterTest是一个AtomicIntegerFieldUpdater的使用示例,其内部定义了一个volatile关键字修饰的age属性(即年龄字段),以及AtomicIntegerFieldUpdater的更新器updater,然后在addAge方法里面调用了AtomicInte-gerFieldUpdater的addAndGet方法来增加age属性的值。
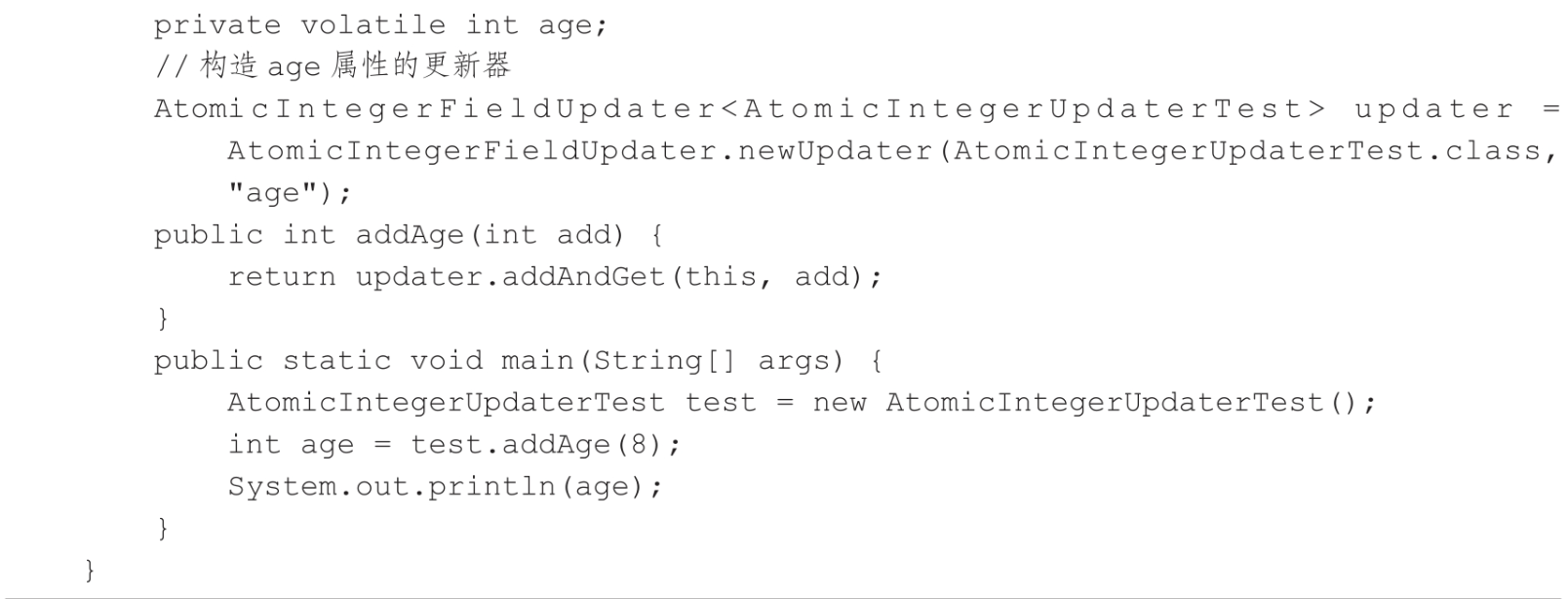
用AtomicIntegerFieldUpdater修改的字段需要用volatile关键字进行修饰,同时AtomicIntegerFieldUpdater构造函数需要用类名+字段名来构造更新器,并且字段是这个类自己定义的,而不是继承过来的。
如下代码是一个AtomicIntegerFieldUpdater错误使用的示例。AbstractUpdater抽象类定义了age属性,然后FailUpdater继承了抽象类AbstractUpdater。理论上,Fail-Updater获得了age的读写能力,但当FailUpdater定义了AtomicIntegerFieldUpdater的实例updater来更新age时,最终是失败的,系统会抛出NoSuchFieldException异常。

AtomicIntegerFieldUpdater提供了线程安全的int类型读取与修改方法,如表所示。


4.1、设计原理
AtomicIntegerFieldUpdater采用了模板方法的设计模式。AtomicIntegerFieldUpdater实现了数据修改的getAndSet、getAndIncrement、getAndAdd、incrementAndGet等相关方法。compareAndSet方法是扩展方法,由子类AtomicIntegerFieldUpdaterImpl来实现。Atomic-IntegerFieldUpdaterImpl的UML图如图所示。
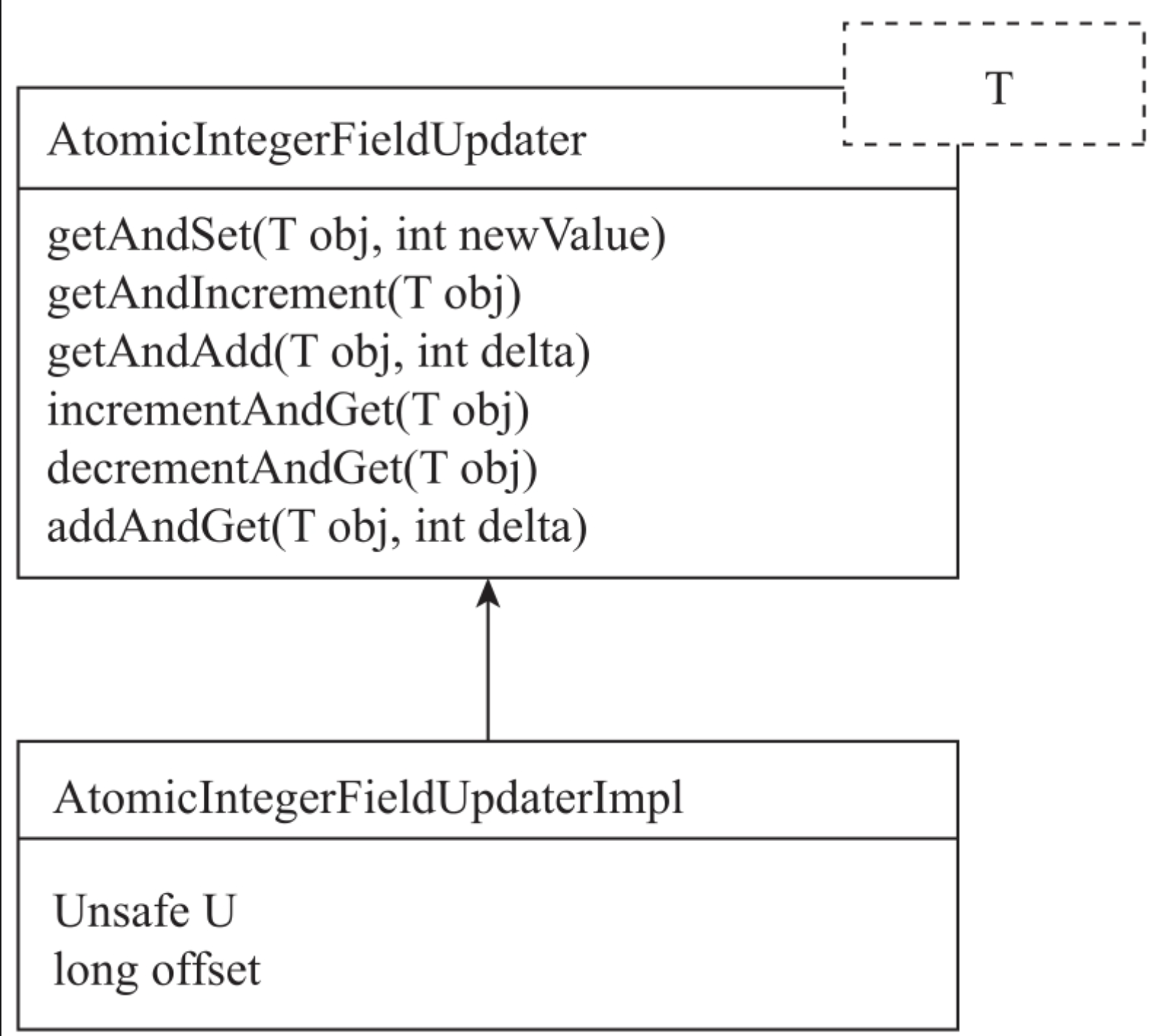
AtomicIntegerFieldUpdaterImpl有两个重要的功能:一是通过反射获取到要修改的int字段的内存偏移量;二是调用Unsafe的CAS方法对字段进行线程安全的修改。Atomic-IntegerFieldUpdater整体上是由反射+Unsafe的能力组合实现的。
4.2、AtomicIntegerFieldUpdater源码分析
AtomicIntegerFieldUpdater实现了数据修改的相关方法,如代码所示。所有方法都是先通过get方法读取到预期值prev,然后调用compareAndSet方法来设置新的值。如果修改失败了,则通过while循环进行多次尝试。AtomicIntegerFieldUpdater定义了两个扩展方法:get方法,用来获取字段的当前值;compareAndSet方法,通过CAS方式来修改字段的值。
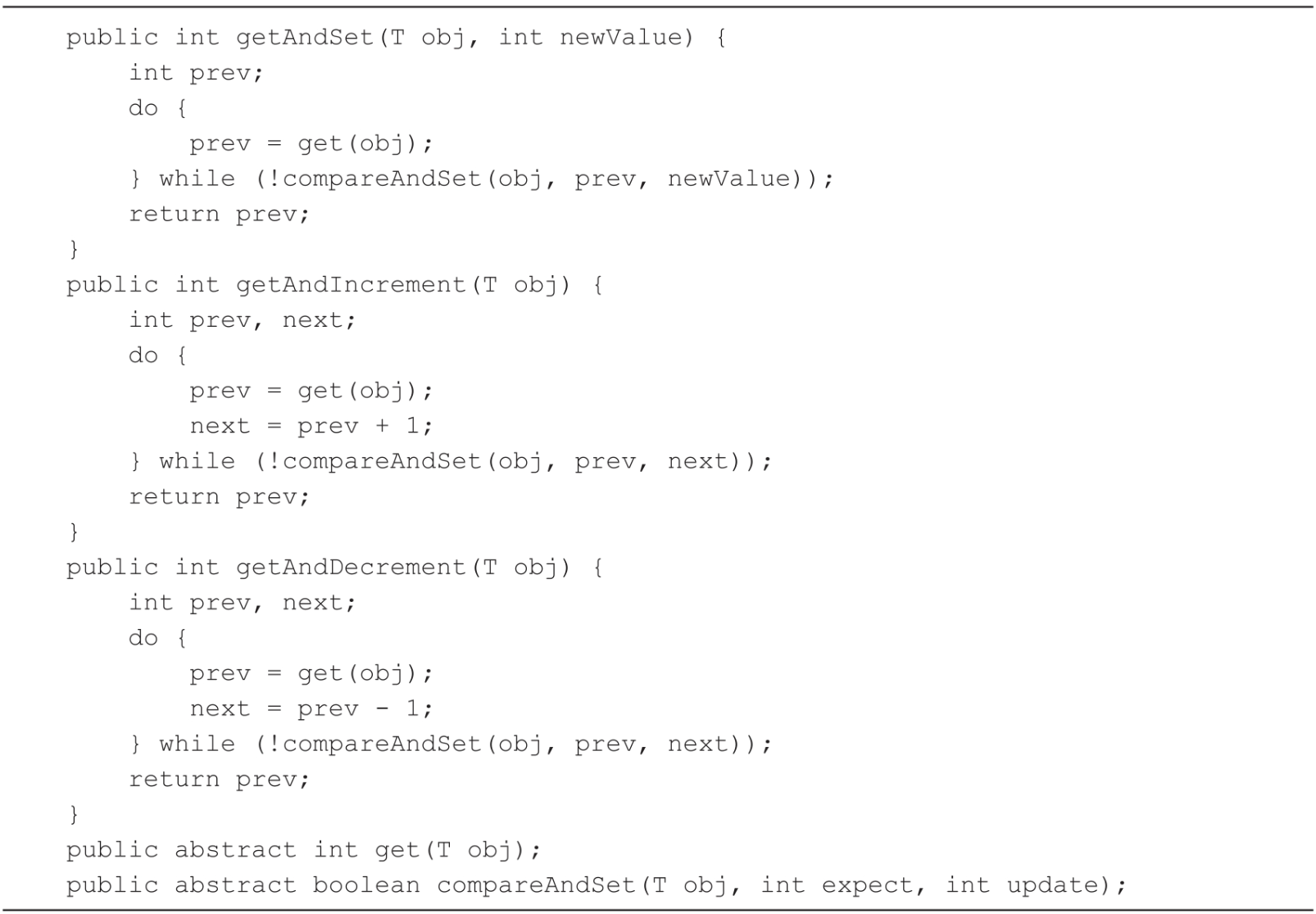
4.3、AtomicIntegerFieldUpdaterImpl源码分析
AtomicIntegerFieldUpdaterImpl的构造函数有3个参数:tclass是要修改字段的所属类,fieldName是要修改的字段名称,caller是调用者的类名称。在上面的例子中,Atomic-IntegerUpdaterTest中的tclass与caller都是AtomicIntegerUpdaterTest.class,而fieldName是age。构造函数首先会调用Class的getDeclaredField方法获取要修改的Field字段,如果字段不存在则抛出异常。接着调用ReflectUtil的ensureMemberAccess方法来修改字段的访问标志,确保caller能访问tclass中的Field字段。然后调用Unsafe的objectFieldOffset方法获取Field字段对应的内存偏移量。对象属性偏移量计算核心代码(中间去掉校验相关代码)如代码所示。
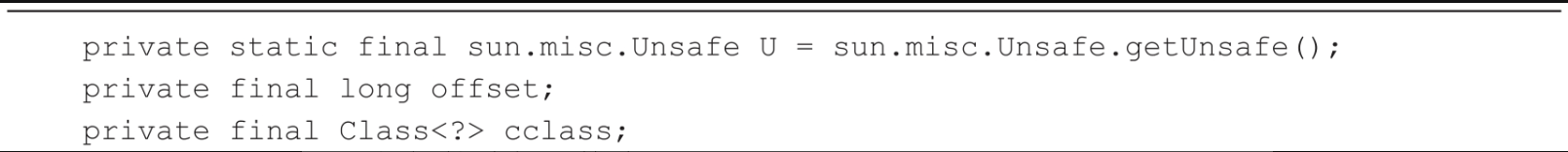

在构造函数内部获取到字段对应的内存偏移量,后面就可以调用Unsafe相关的int类型数据修改方法进行字段的修改了。
数据修改比较简单,就是调用Unsafe的compareAndSwapInt、putIntVolatile、getInt-Volatile等方法进行修改,如代码所示。

5、long的原子性修改实现原理
Java为long类型提供了线程安全的修改类。AtomicLong是long类型的原子类,Atomic-LongArray是long数组安全修改的原子类,AtomicLongFieldUpdater是long类型的线程安全修改的工具类。
5.1、AtomicLong
AtomicLong的设计原理和AtomicInteger基本上是一样的,内部定义了一个volatile关键字修饰的long类型的value变量。AtomicLong通过CAS硬件原语对值进行修改,expect是每次修改前的value的当前值,update是要修改的预期值。如果修改成功,返回值可以按场景需要返回修改前的值或者修改后的值。如果修改失败,则通过循环多次尝试修改,直到成功为止。
AtomicLong提供了线程安全的long类型变量的读取与修改方法,如表所示。
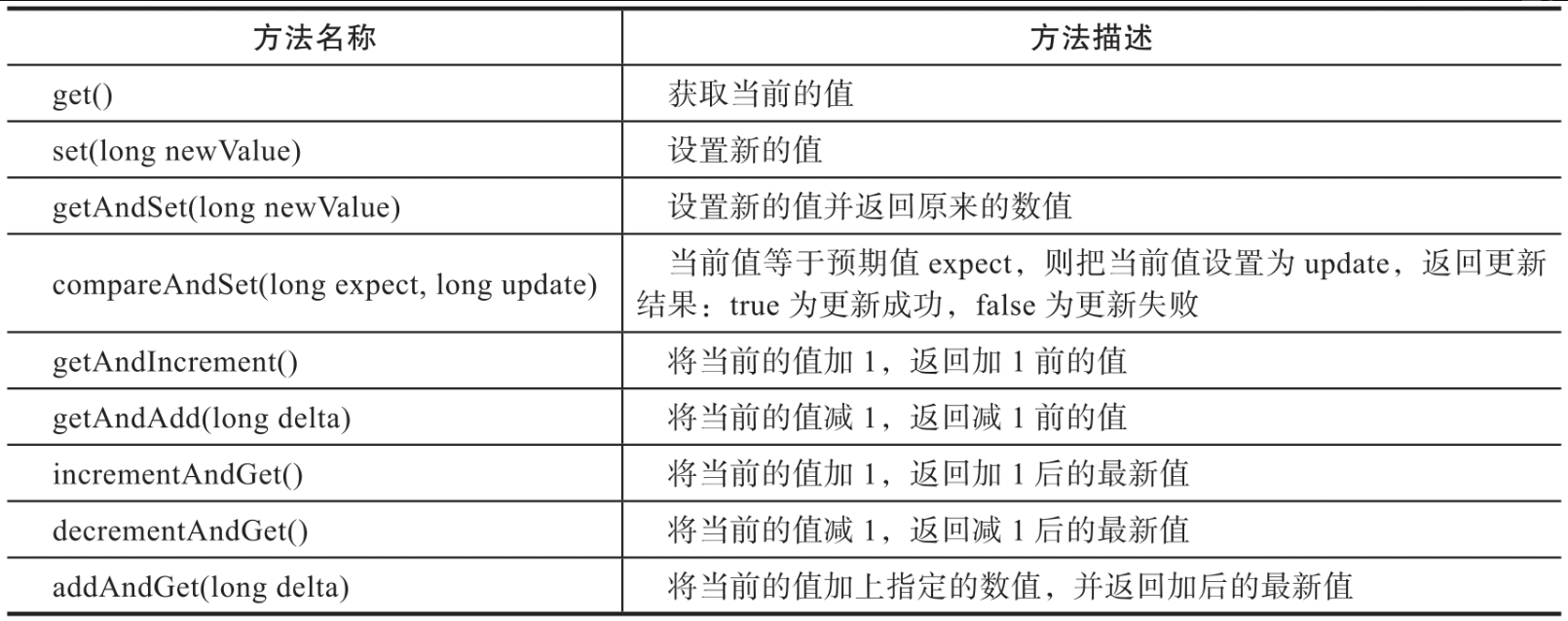
AtomicLong的功能完全依赖于Unsafe的volatile内存实时同步能力,以及CAS原子性修改的相关能力。AtomicLong和AtomicInteger的实现基本是一样的,有兴趣的读者可以自己查看源码。
5.2、AtomicLongArray
AtomicLongArray的设计原理和AtomicIntegerArray基本上也是一致的,读者可以自己打开源码试着分析一下。AtomicLongArray提供了线程安全的long数组的读取与修改方法,如表所示。

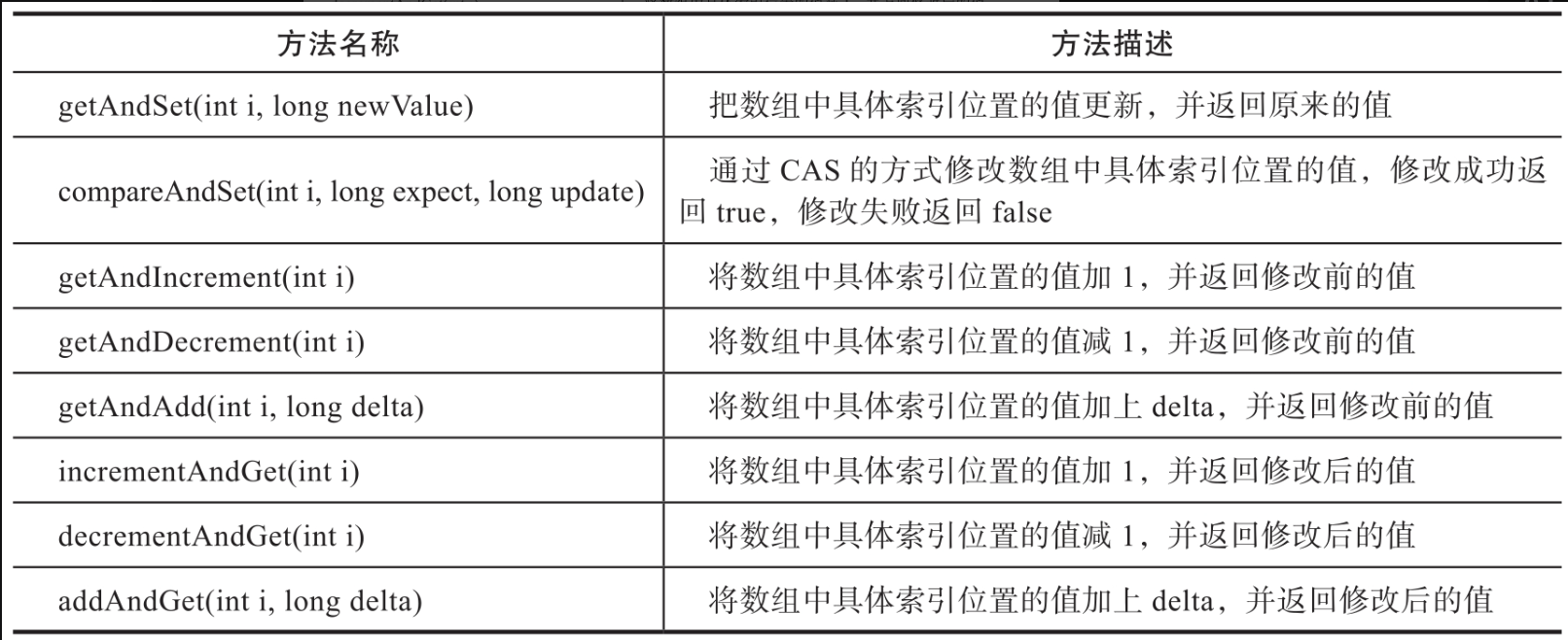
5.3、AtomicLongFieldUpdater
AtomicLongFieldUpdater的设计原理和AtomicIntegerFieldUpdater基本上是一致的。首先通过Java反射获取到要修改的long字段的内存偏移量,然后调用Unsafe的CAS相关方法实现long字段的线程安全读取与修改。AtomicLongFieldUpdater是由反射+Unsafe的能力组合实现的。AtomicLongFieldUpdater提供了线程安全的long类型数据读取与修改方法,如表所示。
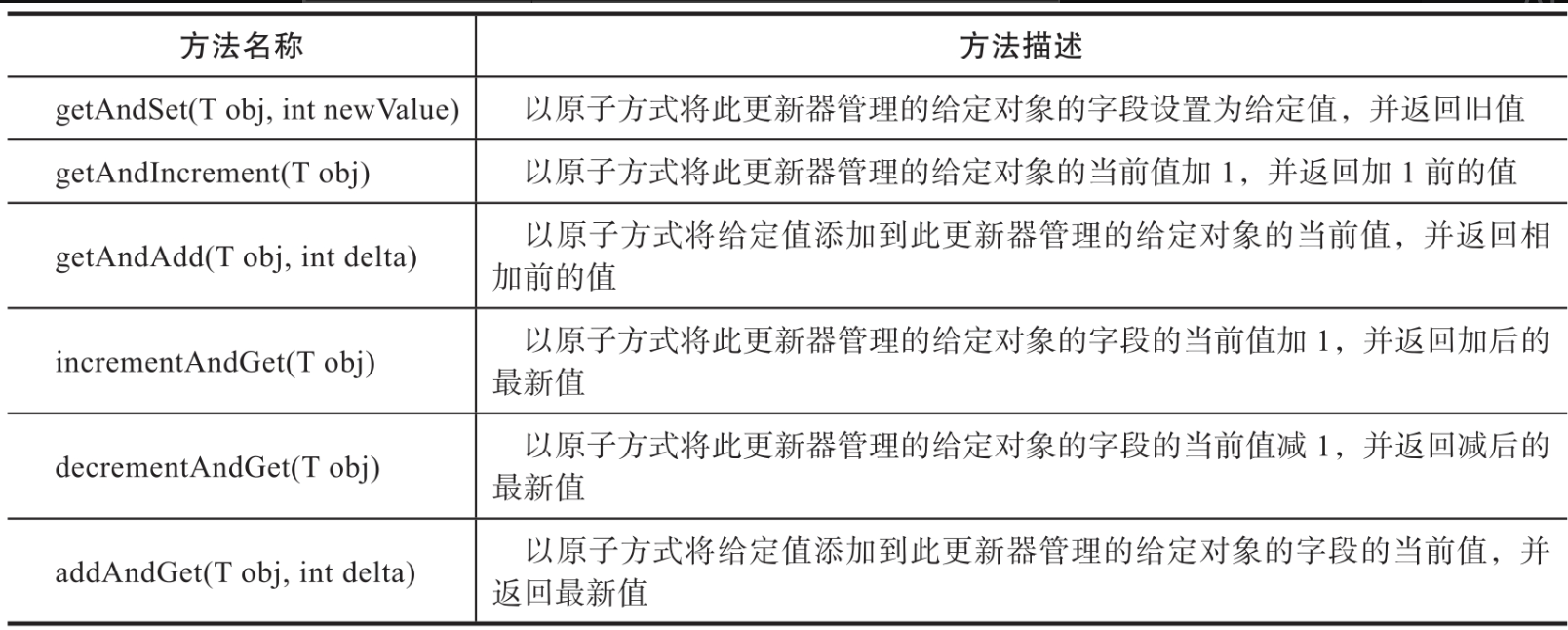
AtomicLongFieldUpdater在实现上与AtomicIntegerFieldUpdater也基本是一样的。
6、LongAdder实现原理
相比synchronized阻塞算法,AtomicInteger、AtomicLong等原子计数器拥有更好的性能。但是在高并发的场景下,大量线程同时通过CAS方式更新一个变量,任意一个时刻只有一个线程能够成功,其他线程只能通过自旋方式进行尝试。在某些高并发场景下,AtomicInteger和AtomicLong的性能并不是很好,所以在JDK8中新增了LongAdder来满足高并发场景下的数据统计。LongAdder提供了多线程环境下的long的安全读取与修改方法,如表所示。
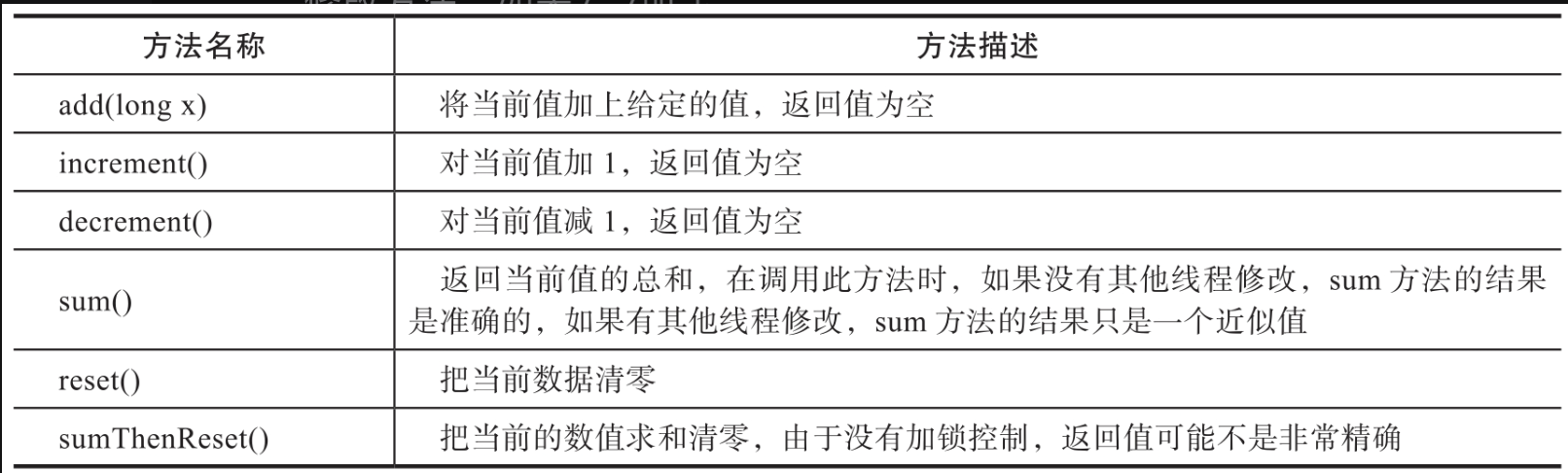
6.1、设计原理
在高并发的场景中,多个线程会同时通过CAS方式来修改对应的value,导致Atomic-Long的性能很低。LongAdder是采用分治算法的思想设计的。LongAdder定义了Cell数组(计算单元数组),每个Cell(计算单元)都能实现long值的计算。每个线程都会根据线程ID对数组进行取模来获取对应的Cell,这样每个线程都只会向对应的Cell发起计算请求。LongAdder的设计原理如图所示。
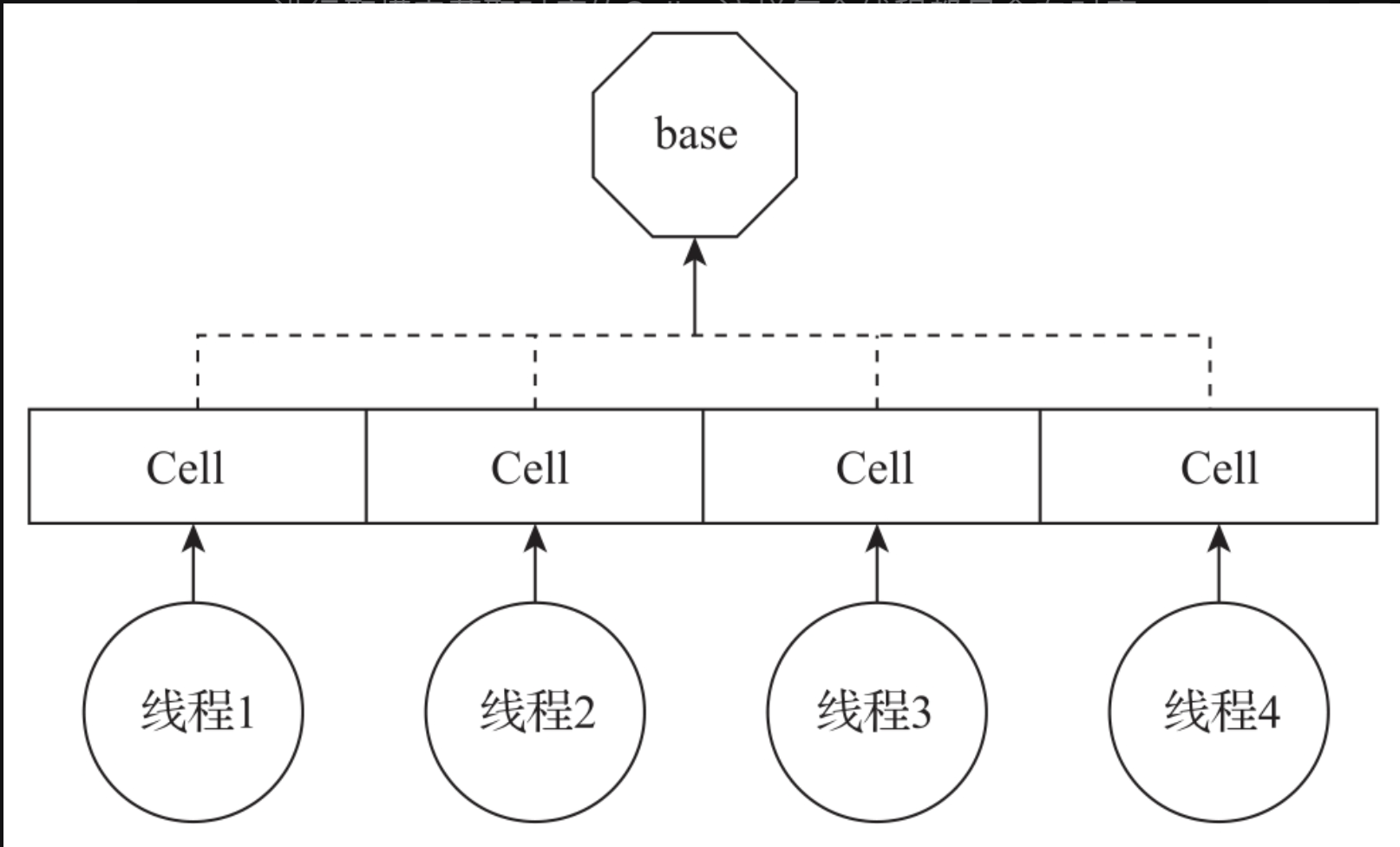
这样把原来多个线程对同一个long字段的CAS修改的竞争,转换成每个线程对自己的对应Cell的竞争。
整个Cell数组的最大长度为CPU的个数,例如CPU的个数为4,那Cell数组的最大长度为4。在没有并发冲突的情况下,仅有一个线程可以直接对base变量进行操作。当有两个线程同时操作LongAdder时,LongAdder才会开始构建Cell数组。当出现多个线程竞争同一个Cell的时候,LongAdder会每次进行倍数扩容,其扩容过程如图所示。
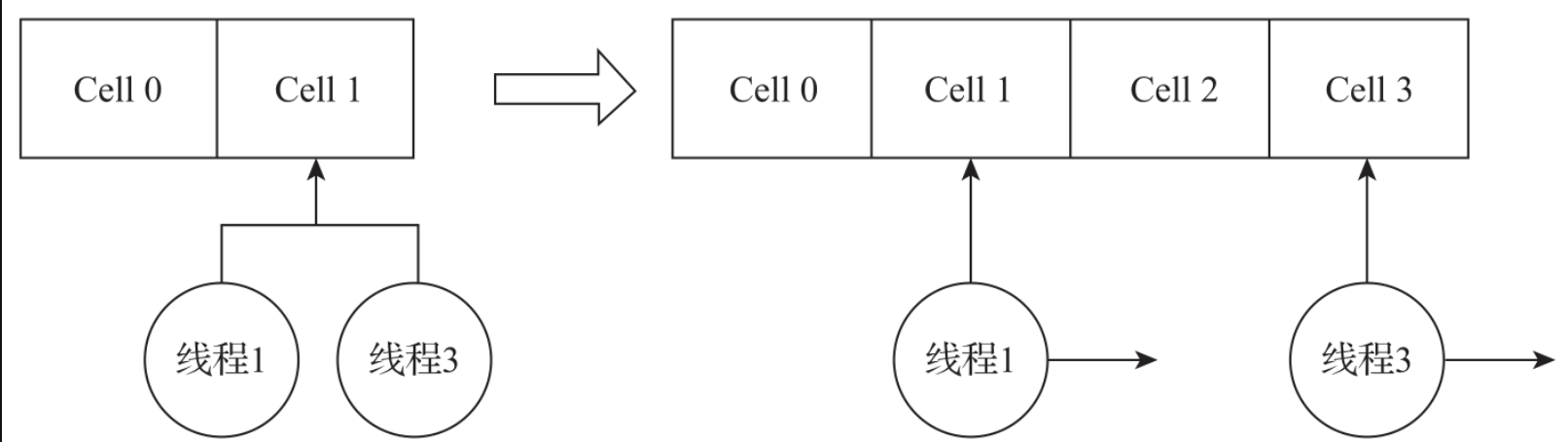
开始Cell数组只有两个元素,线程1与线程3同时操作Cell1节点,此时线程3会失败并触发扩容机制。数组扩容之后,线程1操作Cell 0节点,而线程3操作Cell 2节点。
数组的扩容采取的是渐进式扩容机制,这样能确保内存空 间与CPU使用效率之间的最大平衡,我们非常熟悉的ArrayList、HashMap也都采用了同样的扩容原理。
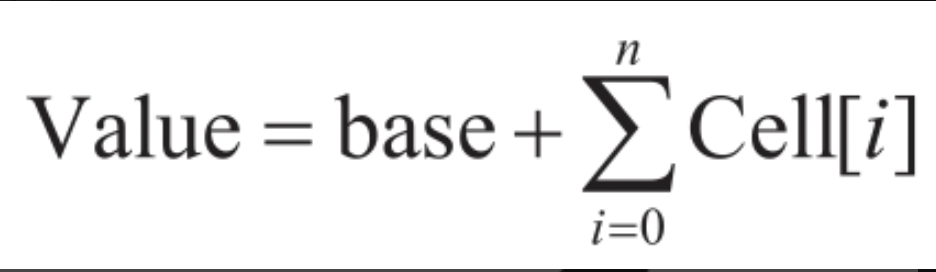
其中,i为数组下标,n为数组的长度。
6.2、源码分析
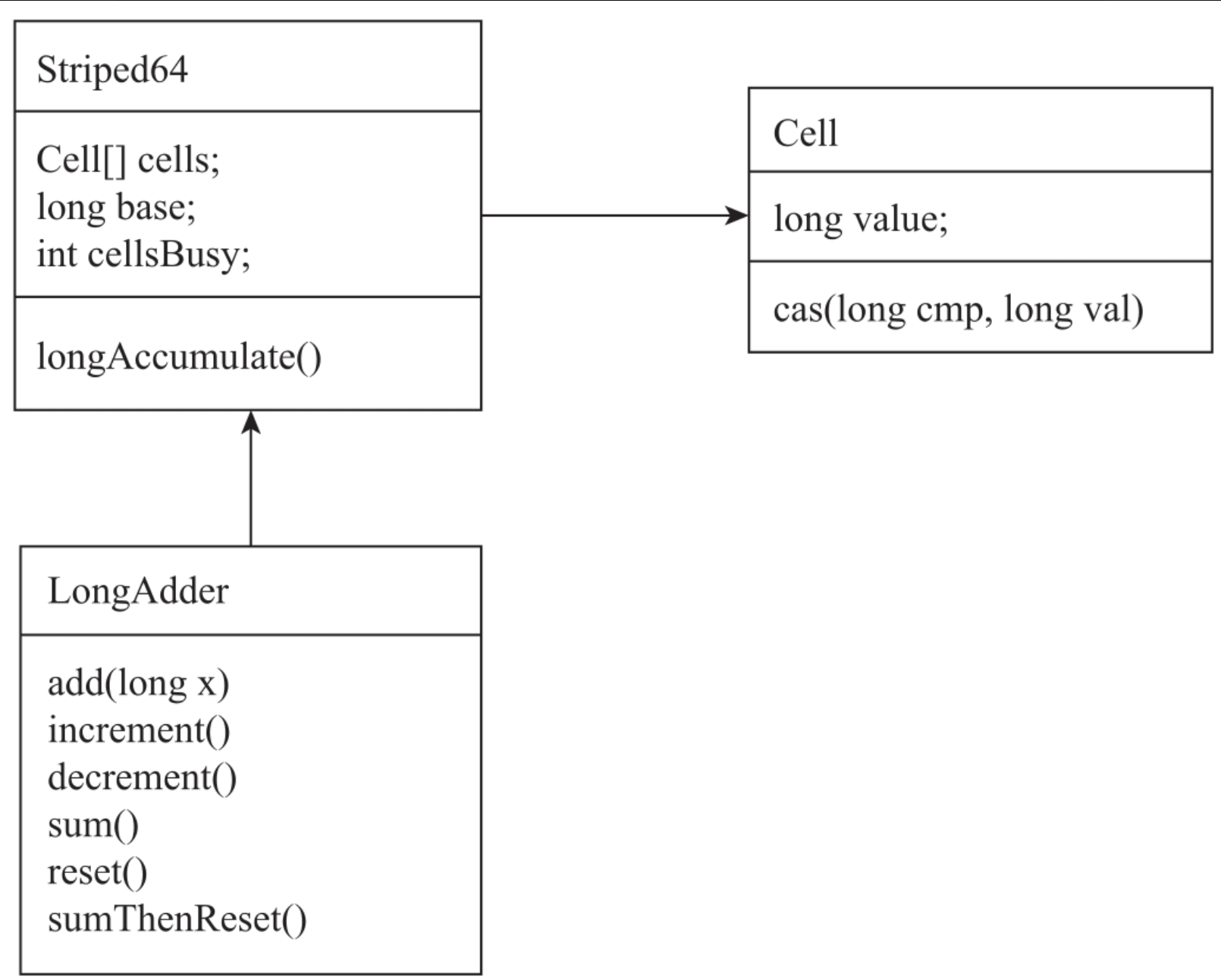
Cell是基础的计算单元,内部定义了一个volatile修饰的long类型的变量value,并提供了以CAS方式修改value的方法。Striped64主要提供了Cell数组的管理功能。LongAdder继承了抽象类Striped64,提供long类型数据的计数功能,UML图如图所示。
接下来采用自底向上的方式详细讲解LongAdder的源码实现。
1. Cell源码
Cell内部定义了两个变量:一个是volatile修饰的value,另一个是VarHandle的实例VALUE。Cell是通过VarHandle的weakCompareAndSetRelease方法来实现value字段的安全修改。Cell的具体实现如代码所示。

2. Striped64源码
Striped64定义了3个变量:计算单元的数组cells、数组操作锁状态cellsBusy,以及基础值base。cellsBusy表示数组操作的锁状态:0表示没有线程操作,1表示有线程操作。在对cells数组操作前,线程必须调用casCellsBusy方法来获取锁。Cell数据管理的实现如代码所示。

casCellsBusy就是调用VarHandle的compareAndSet方法来将cellsBusy修改成1,如果修改成功表示获取到锁了。在锁释放的时候,线程必须将cellsBusy设置为0,这样能够确保任一时刻只有一个线程管理Cell数组。
3. LongAdder源码
add方法是LongAdder的核心计算方法,它的功能是完成值的相加。increment方法与decrement方法都是通过add方法来实现的。但add方法的代码有点难以理解,所以笔者按照真实代码执行的顺序来讲解。在单线程操作时,add方法会调用casBase方法来修改base值,如果修改成功则直接返回。如果修改失败,add方法会调用Striped64的longAccumulate方法来计算。多线程同时操作时,add方法会先判断当前线程对应的Cell是否为空。如果Cell不为空,则add方法会调用Cell的cas方法进行线程安全的修改。如果Cell为null或者Cell计算失败,则调用Striped64的longAccumulate方法计算。longAccumulate方法会根据线程ID对Cell数组进行取模,找到对应的Cell,然后通过CAS方式修改Cell的值。代码是数值增加的实现。

sum方法的功能是统计整个LongAdder的值。LongAdder的值包含两部分:一部分是base的值,另一部分是Cell数组中所有元素的值。sum方法实现如代码所示。

sum方法的执行流程如下:首先将base的值赋给临时变量sum,然后逐个遍历Cell数组,将数组的值累加到sum中。因为整个统计过程并未加锁,所以sum方法统计到的可能是一个近似值。如果在统计过程中没有线程对base或者Cell数组中的值进行修改,则sum方法的结果是精准的。如果有其他线程在修改,sum方法统计到的就是一个近似值。
reset方法的功能是重置整个计数器的值,它主要包含两部分:一是重置base的值,将base的值设置为0;二是将Cell数组的每个Cell值设置为0。计数器重置的实现如代码所示。
