Multi-Agent vs 单 Agent vs 工作流编排------架构选型对比与决策框架
你的应用真的需要 Multi-Agent 吗?三种 LLM 应用架构的深度对比与选型决策指南。
一、引言
2024 年初,我做了一个简单的 ChatBot,单 Agent + 两个工具,跑得好好的。年中,团队说要上 Multi-Agent,"像 CrewAI 那样"。我说先让我试试。
试完之后我的结论是:大多数应用根本不需要 Multi-Agent------但真正需要的那些场景,不用 Multi-Agent 又会非常痛苦。
问题在于,业界讨论往往把三种架构混为一谈:
- 单 Agent + 工具调用(Single Agent with Tools)
- Multi-Agent 系统(Multiple Agents)
- 传统工作流编排(Workflow Orchestration)
这篇文章的目标是帮你搞清楚:这三种架构分别是什么、各自适合什么场景、以及如何做选型决策。
读完你会获得:
- 三种架构的清晰定义和边界
- 6 个维度的深度对比(含实测数据)
- 一个可操作的决策树
- 混合架构的设计思路
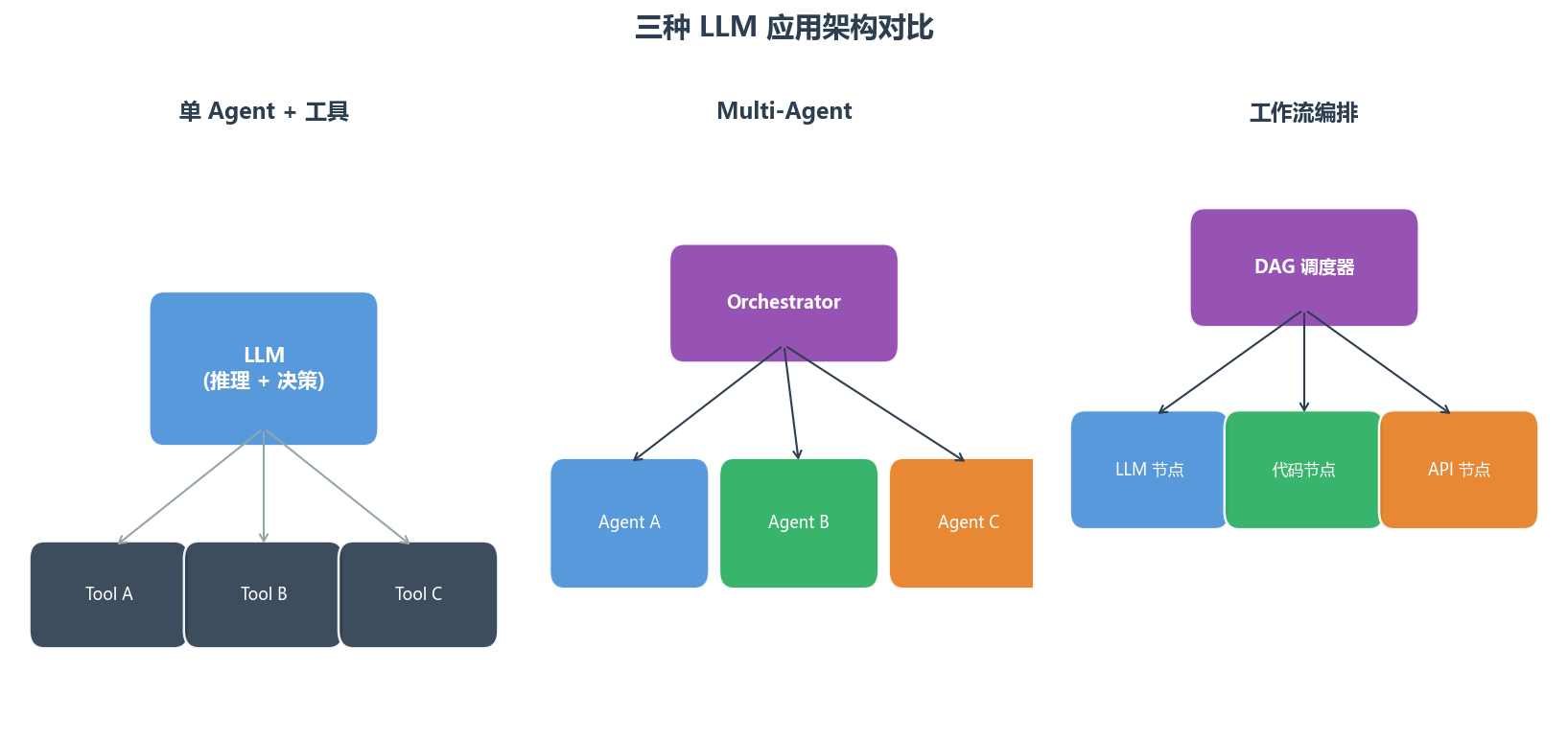
二、先厘清概念:三种架构到底是什么
2.1 单 Agent + 工具调用
用户输入 → [LLM (推理 + 决策)] ←→ [工具1, 工具2, 工具3]
↓
输出这是最基础的 LLM 应用架构。一个 LLM 实例,通过 function calling / tool use 机制调用外部工具。
关键特征:
- 只有一个"大脑",所有决策由这一个 LLM 做出
- 工具是被动的------LLM 调用它,它返回结果
- 没有"同伴",没有"第二意见"
代表框架:OpenAI Function Calling、LangChain Agent、Claude Tool Use
python
# 单 Agent 模式:简洁直接
from openai import OpenAI
client = OpenAI()
tools = [
{"type": "function", "function": {"name": "search", ...}},
{"type": "function", "function": {"name": "calculate", ...}},
]
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "今年的 GDP 增长率是多少?"}],
tools=tools,
)2.2 Multi-Agent 系统
用户输入 → Orchestrator → Agent A (角色1)
↓ → Agent B (角色2)
↓ → Agent C (角色3)
↓ ↓
└── 汇总/筛选 ←┘
↓
输出多个具有独立"人格"(system prompt)的 LLM 实例协作完成一个任务。每个 Agent 有自己的角色、目标、可用的工具。
关键特征:
- 多个"大脑"分工协作
- Agent 之间通过对话或结构化数据通信
- 有明确的协调机制(Sequential / Hierarchical / Debate)
代表框架:CrewAI、AutoGen、LangGraph(Multi-Agent 模式)
python
# Multi-Agent 模式:角色分离
from crewai import Agent, Task, Crew
researcher = Agent(role="研究员", goal="收集资料", ...)
writer = Agent(role="写手", goal="撰写文章", ...)
reviewer = Agent(role="编辑", goal="审校纠错", ...)
crew = Crew(
agents=[researcher, writer, reviewer],
tasks=[research_task, write_task, review_task],
process=Process.sequential,
)2.3 传统工作流编排
用户输入 → [规则引擎 / DAG 调度器]
↓
┌────┴────┐
LLM 调用1 纯代码逻辑
│ │
LLM 调用2 API 调用
└────┬────┘
↓
输出用确定性的流程控制(DAG、状态机、规则引擎)编排 LLM 调用和传统代码逻辑。LLM 只是工作流中的一个节点,而非决策中枢。
关键特征:
- 流程由确定性逻辑控制(不是 LLM 自主决策)
- LLM 被当作"高级函数"使用------输入文本,输出文本
- 流程可以包含条件分支、循环、异常处理
代表框架:LangGraph(Graph 模式)、Temporal、Airflow、Prefect
python
# 工作流模式:确定性控制流
from langgraph.graph import StateGraph
workflow = StateGraph(State)
workflow.add_node("classify", classify_intent) # LLM 节点
workflow.add_node("handle_query", search_and_answer) # LLM + 工具
workflow.add_node("handle_action", execute_action) # 纯代码
workflow.add_conditional_edges("classify", router, {
"query": "handle_query",
"action": "handle_action",
})三、六个维度的深度对比
3.1 决策权归属
| 架构 | 决策者 | 灵活性 | 可控性 |
|---|---|---|---|
| 单 Agent | LLM | 高 | 低 |
| Multi-Agent | LLM × N | 很高 | 低 |
| 工作流 | 代码逻辑 | 中 | 高 |
关键洞察:LLM 做决策越多,灵活性越高但可控性越低。如果你的业务流程需要严格的合规审计,工作流是更好的选择。
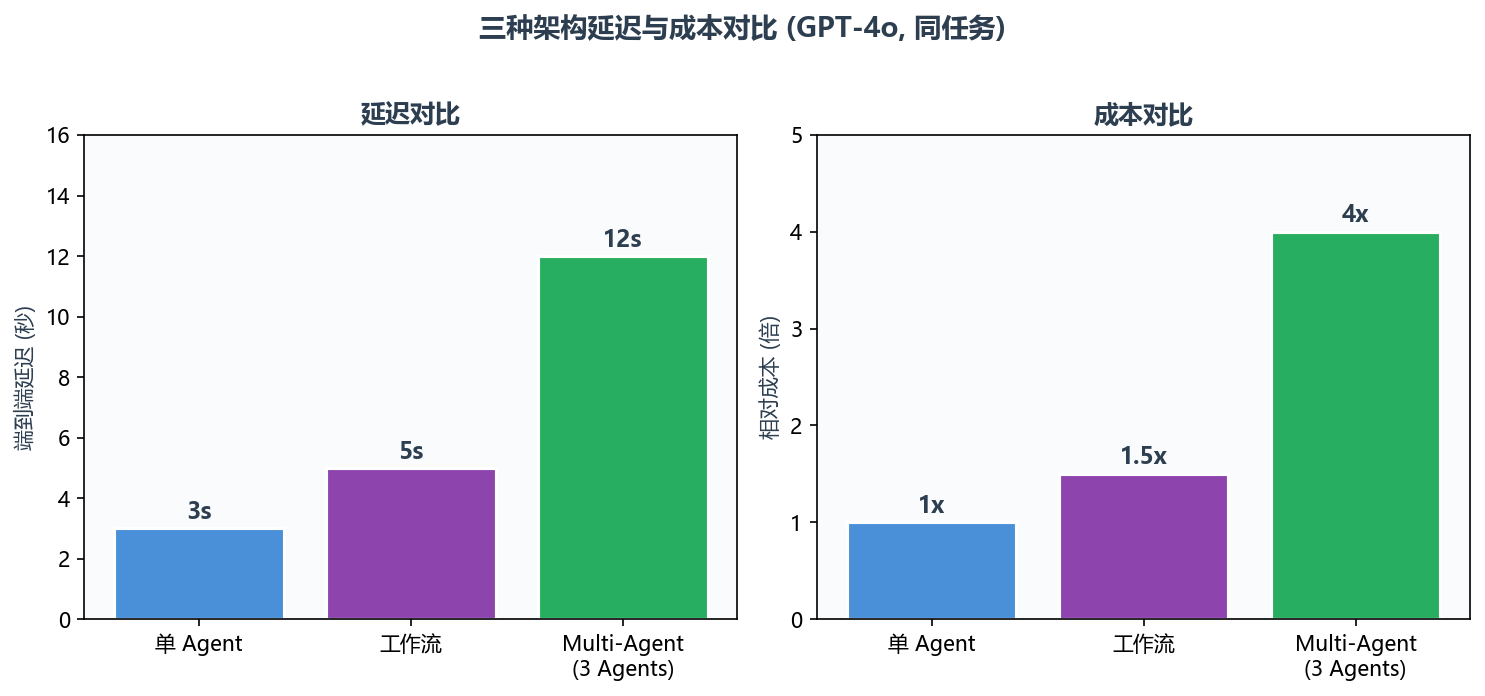
3.2 延迟与成本
实测数据(同任务,GPT-4o):
| 架构 | LLM 调用次数 | 端到端延迟 | Token 消耗 | 相对成本 |
|---|---|---|---|---|
| 单 Agent | 1-3 次 | ~3 秒 | ~2K | 1x |
| Multi-Agent (3 Agents) | 3-6 次 | ~12 秒 | ~8K | 4x |
| 工作流 | 按需(通常 1-3 次) | ~5 秒 | ~3K | 1.5x |
数据来自同一任务(技术文章生成)在三种架构下各运行 10 次的平均值。
3.3 错误处理
| 架构 | 错误发现 | 错误恢复 | 典型失败模式 |
|---|---|---|---|
| 单 Agent | 依赖用户反馈 | 重新生成 | 幻觉输出无人纠正 |
| Multi-Agent | Agent 间互相检查 | 内部反馈回路 | 集体幻觉、无限循环 |
| 工作流 | 确定性异常捕获 | 重试/降级/告警 | LLM 节点返回格式错误 |
3.4 可调试性
单 Agent: 输入 → [黑盒] → 输出 ★★☆☆☆ 难调试
Multi-Agent: 输入 → [黑盒1] → [黑盒2] → [黑盒3] ★☆☆☆☆ 非常难调试
工作流: 输入 → [节点1] → [节点2] → [节点3] ★★★★☆ 可调试
每个节点输入输出可观测工作流 的每个节点有明确的输入输出,你可以单独测试每个节点,加上日志和 Tracing 即可完整追踪。Multi-Agent 的 Agent 间对话上下文是一个"灰色地带"------你很难精确知道一个 Agent 为什么做出了某个决策。
3.5 扩展性
| 架构 | 加功能的方式 | 复杂度增长 |
|---|---|---|
| 单 Agent | 加 Tool / 改 Prompt | 线性(prompt 变长,效果下降) |
| Multi-Agent | 加 Agent / 加 Task | 指数级(Agent 间交互组合爆炸) |
| 工作流 | 加节点 / 改图 | 线性(图变大,但每个节点独立) |
3.6 适用场景矩阵
| 场景 | 单 Agent | Multi-Agent | 工作流 |
|---|---|---|---|
| 简单问答 | ✅ 最佳 | ❌ 过度 | ⚠️ 可用但多余 |
| 代码生成 + 自审 | ⚠️ 勉强 | ✅ 最佳 | ✅ 可用 |
| 内容生产流水线 | ⚠️ 可用 | ✅ 最佳 | ✅ 最佳 |
| 客服路由 + 处理 | ✅ 可用 | ⚠️ 过度 | ✅ 最佳 |
| 需要严格合规审批 | ❌ 不可控 | ❌ 不可控 | ✅ 最佳 |
| 探索性任务 | ✅ 最佳 | ⚠️ 可实验 | ❌ 不够灵活 |
| RAG 系统 | ✅ 最佳 | ❌ 过度 | ⚠️ 可用 |
四、决策框架
4.1 决策树
你的任务是否涉及严格合规或需要确定性流程控制?
├── 是 → 用工作流编排
└── 否 → 任务能否被清晰地分解为 3+ 个有不同"技能要求"的子任务?
├── 否 → 单 Agent 够用,不要过度设计
└── 是 → 子任务之间是否需要动态协调(不只是顺序执行)?
├── 否 → 用工作流编排(确定性流程更可靠)
└── 是 → 用 Multi-Agent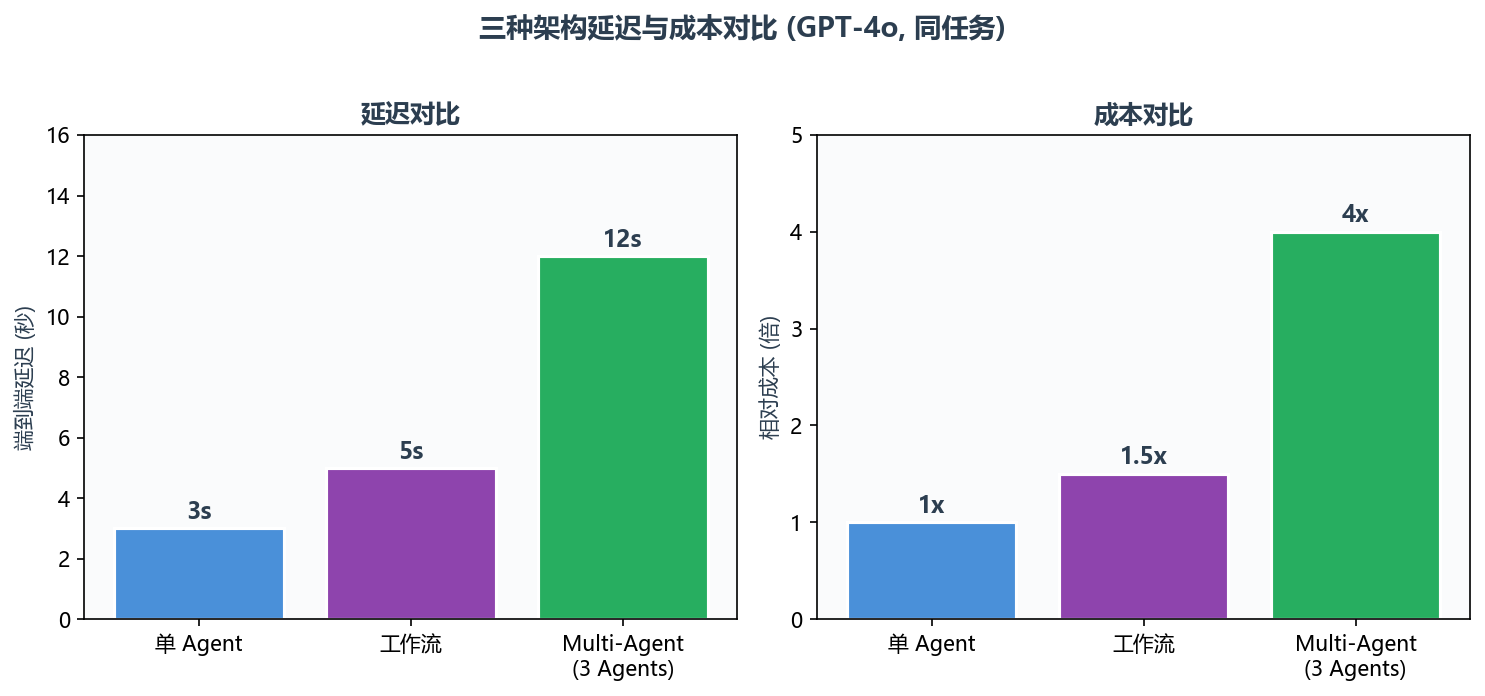
4.2 自检清单
在做 Multi-Agent 之前,请回答:
- 单 Agent + 更好的 prompt + 更多的工具是否够用?
- 你的任务中是否有自然的分工边界(如"做事的人"和"检查的人"需要不同的思维方式)?
- 你是否愿意接受4x 以上的成本增长 和2x 以上的延迟增长?
- 你是否已经搭建好了分布式 Tracing + 日志系统来调试多 Agent?
- 你是否清楚每个 Agent 的出错的后果和兜底方案?
如果任何一项回答"否"------先别上 Multi-Agent。
4.3 渐进式升级路径
不要一步到位上 Multi-Agent。推荐这个路径:
阶段 1: 单 Agent + 工具
↓ (当 prompt 越来越长、输出质量不稳定时)
阶段 2: 单 Agent + 更好的 prompt 工程 + 更多工具
↓ (当确认是"能力边界"而非"prompt 质量"问题时)
阶段 3: 引入第二个 Agent(如 Planner + Executor)
↓ (验证多 Agent 协作确实带来可测量的质量提升)
阶段 4: 扩展到 3-5 个 Agent重要的不是你有几个 Agent,而是每个 Agent 是否解决了明确的、单 Agent 解决不了的问题。
五、混合架构:最好的选择可能是"都要"
现实中,最强大的系统往往是混合的。以一个"代码审查 Bot"为例:
GitHub Webhook 触发
↓
┌─ 工作流层(确定性流程)─────────────┐
│ 1. 解析 PR 信息 │
│ 2. 判断代码语言 │
│ 3. 分支路由 │
└────────────┬─────────────────────────┘
↓
┌─ Multi-Agent 层(需要对抗性审查时)──┐
│ Reviewer Agent → 发现问题 │
│ Fixer Agent → 提出修复 │
│ Reviewer Agent → 验证修复 │
└────────────┬─────────────────────────┘
↓
┌─ 工作流层(结果处理)───────────────┐
│ 4. 生成 Review Comment │
│ 5. 发布到 PR │
│ 6. 记录审计日志 │
└──────────────────────────────────────┘原则:确定性的归工作流,不确定的归 Agent,需要多视角的归 Multi-Agent。
六、总结
- 单 Agent 是默认选项:大多数场景下,一个 LLM + 几个工具就足够了。不要因为 Multi-Agent "很酷"就上。
- 工作流是"安全牌":当流程可以预先定义清楚时,用确定性逻辑控制 LLM 调用------可控、可调试、可审计。
- Multi-Agent 是"特种兵":只在需要不同思维模式协作(创建 vs 审查)、需要交叉验证、或任务天然可分解为独立角色时才用。
- 三种架构不是互斥的:最好的系统往往混合使用------工作流做骨架,单 Agent 做大多数决策,Multi-Agent 解决最棘手的子问题。
- 从简单开始,渐进升级:不要一步到位设计 5-Agent 系统。从 1 个 Agent 开始,真的不够用了再加。
架构选型的第一原则永远是:用最简单的东西解决当前的问题。Multi-Agent 不是目的,解决问题才是。