文章目录
- [1. 数据收集](#1. 数据收集)
-
- [1.1 数据的读取:pd.read_csv()](#1.1 数据的读取:pd.read_csv())
- [1.2 数据的写入:df.to_csv()](#1.2 数据的写入:df.to_csv())
- [1.3 数据查看与选择](#1.3 数据查看与选择)
- [2. 数据清洗](#2. 数据清洗)
-
- [2.1 缺失值处理](#2.1 缺失值处理)
-
- [2.1.1 发现缺失值:isnull() 与 notnull()](#2.1.1 发现缺失值:isnull() 与 notnull())
- [2.1.2 删除缺失值:dropna()](#2.1.2 删除缺失值:dropna())
- [2.1.3 填充缺失值:fillna()](#2.1.3 填充缺失值:fillna())
- [2.1.4 可以混合处理吗?](#2.1.4 可以混合处理吗?)
- [2.2 重复值处理](#2.2 重复值处理)
- [2.3 异常值处理](#2.3 异常值处理)
-
- [发现异常值:describe() + 条件判断](#发现异常值:describe() + 条件判断)
- 处理异常值:布尔过滤(最简洁的方式)
- 删除异常值:drop()
- 补充:clip()
- [2.4 数据格式处理](#2.4 数据格式处理)
- [3. 数据分析](#3. 数据分析)
-
- [3.1 数据排序sort_values() 与 sort_index()](#3.1 数据排序sort_values() 与 sort_index())
- [3.2 分组分析:groupby()](#3.2 分组分析:groupby())
-
- [为什么执行 groupby() 后只看到内存地址?](#为什么执行 groupby() 后只看到内存地址?)
- 多列分组
- 同时计算多个统计量:agg()
- 链式操作
- [4. 总结](#4. 总结)
📁 代码讲义:data_analysis.ipynb
📅 更新日期:2026-06-07
🔗 前置知识:Series、DataFrame 讲解篇
📂 示例数据:movies.csv(300条电影记录)、sales.csv(1000条销售记录)
1. 数据收集
1.1 数据的读取:pd.read_csv()
pandas 提供了丰富的 read_xxx 系列方法,可以从各种格式的文件中读取数据。核心规律 :什么文件后缀,就用什么方法,如read_csv 读 CSV,read_excel 读 Excel,read_json 读 JSON,read_sql 读数据库,以此类推。
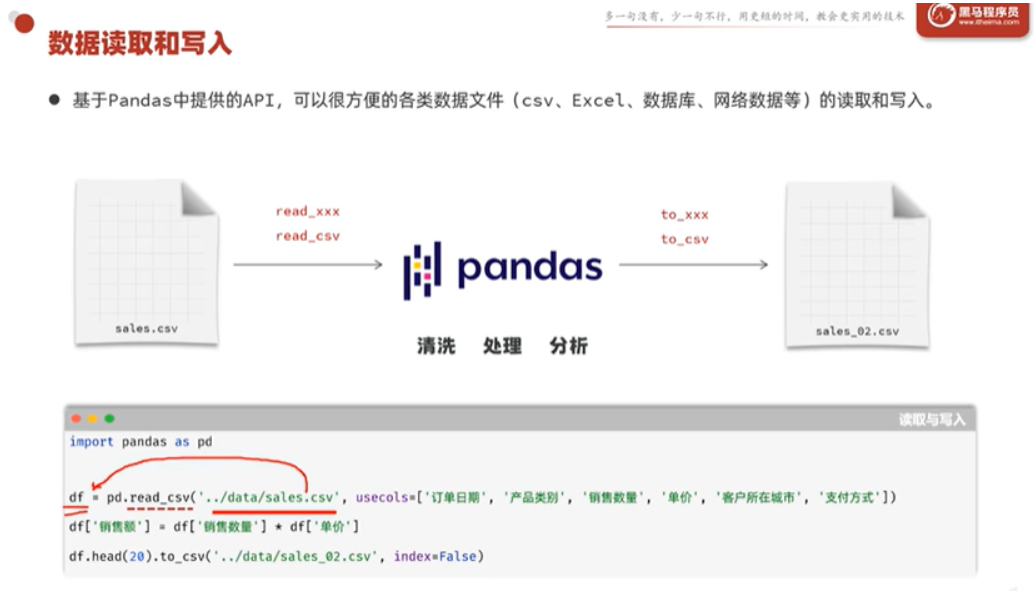
常用参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
filepath_or_buffer |
str | 必填 | 文件路径(支持相对路径和绝对路径) |
usecols |
list | None |
指定读取哪些列(按列名或列索引) |
nrows |
int | None |
只读取前 N 行 |
encoding |
str | 'utf-8' |
文件编码(中文 Windows 常见 'gbk') |
sep |
str | ',' |
分隔符(CSV 默认逗号,TSV 用 '\t') |
skiprows |
int/list | None |
跳过指定行(跳过标题行或说明行时很有用) |
index_col |
int/str | None |
指定某列作为行索引 |
na_values |
list/dict | None |
额外将哪些值识别为 NaN(如 [''] 把空字符串当缺失值) |
python
# 基础读取
df = pd.read_csv(r'D:\data\movies.csv')
# 指定列读取
df = pd.read_csv(r'D:\data\movies.csv', usecols=['电影名', '类型', '评分'])
# 只读取前 5 行预览
df_preview = pd.read_csv(r'D:\data\movies.csv', nrows=5)📌 返回值 :
pd.read_csv()返回一个 DataFrame 。实际上所有read_xxx方法默认都返回 DataFrame,哪怕只有一列数据,也是(n, 1)的二维表。
💡 行设限:usecols只控制列,行需要通过nrows参数来限制读取行数,或者在读完后通过.iloc[]、.loc[]或布尔过滤来筛选。这两个方向是独立控制的,十分灵活。当然列也可以。即后面1.3的数据查看与选择,这也就是之后说他们的关系密不可分。
1.2 数据的写入:df.to_csv()
读取和写入是对称的设计:read_xxx 读进来,to_xxx 写出去。除了 to_csv,还有 to_excel、to_json 等等。
常用参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
path_or_buf |
str | 必填 | 输出文件路径 |
index |
bool | True |
是否写入行索引列 |
encoding |
str | 'utf-8' |
输出编码 |
sep |
str | ',' |
分隔符 |
columns |
list | None |
只输出指定列 |
header |
bool/list | True |
是否写入列名 |
python
# 不写入行索引
# 如果不设置 index=False,第一列会是 0, 1, 2... 的默认行索引
df.to_csv(r'D:\data\output.csv', index=False)⚠️ index=False 与 set_index() 的陷阱
看这段代码:
python
df_full = pd.read_csv('movies.csv')
df_full = df_full.set_index('电影名') # 把 '电影名' 提升为行索引
df_full.to_csv('output.csv', index=False)再次读取 output.csv 时,你会发现 '电影名' 列消失了 !原因是:set_index('电影名') 把这一列提升为行索引,它不再是普通的数据列。此时 to_csv(index=False) 跳过了行索引,这一列也就不会被保存。
解决办法:
- 方案一:
to_csv(..., index=True):保留索引列,但会在左边多一列索引 - 方案二:
df.reset_index().to_csv(..., index=False): 先把索引还原为普通列再保存 - 方案三:不要用
set_index(),直接将那列作为普通数据列处理
核心理解 :
index=False中的index指的是 pandas 的行索引(index),不是数据中的任何一列!
1.3 数据查看与选择
数据读取进来后,第一步往往是快速概览 。以下是与数据读取紧密相关的高频方法。更详细的 loc/iloc/布尔过滤讲解请参考Series、DataFrame 讲解篇
python
# 快速查看
df.head(5) # 前 5 行
df.tail(3) # 后 3 行
df.shape # (行数, 列数)
df.columns # 所有列名
df.dtypes # 每列数据类型
# 全面概览
df.info() # 列名、非空值数量、数据类型、内存占用(最常用!)
df.describe() # 数值列的统计摘要(计数、均值、标准差、四分位数)
# 布尔过滤(后续异常值处理的基础)
df[(df['评分'] >= 85) & (df['时长'] > 150)] # 选评分高且时长长📖 更详细的
loc/iloc/布尔过滤讲解,请参阅 Series / DataFrame 讲解篇。
数据的读取收集和数据查看与选择本质上密不可分:读进来是为了选出来你需要的。
2. 数据清洗
数据清洗是数据分析中最耗时、也最关键的环节。原始数据往往"千疮百孔",我们需要纠正数据中可识别的错误:缺失值、重复值、异常值、格式不一致,这些问题如果不去处理,后续的分析结果很可能被误导。
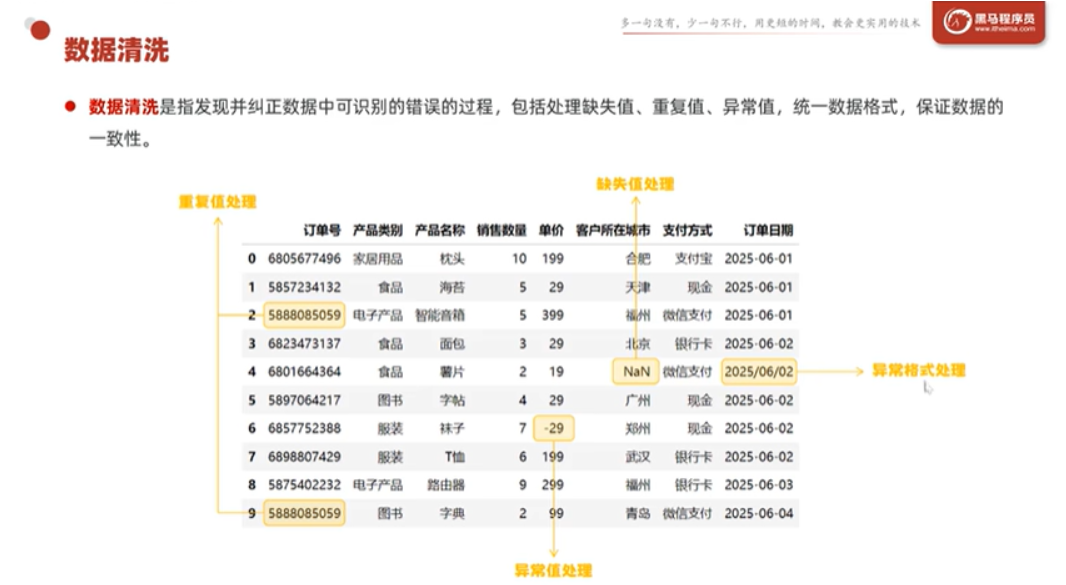
🗂️ 本节使用
sales.csv进行演示,这是一个包含 1000 条记录的销售数据集,暗含了真实世界中常见的数据质量问题。
🧠 统一心法 :数据清洗的每一个子问题:缺失值、重复值、异常值、格式不一致等都遵循同一个思维框架:发现 → 处理。先用对应的方法定位问题,再根据业务场景决定是删、是填、还是替换。这套思维方式比记住具体方法更重要。
2.1 缺失值处理
python
# 加载销售数据:注意 na_values 参数:将空字符串也识别为缺失值
# CSV 中的 ""," 这样的空引号默认读出来是空字符串 "",不是 NaN
# 加 na_values=[''] 后,pandas 会正确将它们识别为缺失值
df_sales = pd.read_csv('sales.csv', na_values=[''])
df_sales.isnull().sum() # 查看各列缺失值数量2.1.1 发现缺失值:isnull() 与 notnull()
isnull()会逐个位置检查是否为空(NaN),返回与原数据形状完全相同 的布尔 DataFrame/Series,为空的位置是True,有值的位置是False。notnull():与isnull()相反,非空为True。
📌 返回值 :
df.isnull()→ 布尔 DataFrame (形状与 df 一致);df['列'].isnull()→ 布尔 Series。
python
# 查看每个位置是否缺失(返回布尔 DataFrame)
df.isnull()
# 统计每列缺失个数(更实用的方式)
df.isnull().sum()
# 也可以用 info() 直观查看
df.info()2.1.2 删除缺失值:dropna()
当缺失值占比很小、或者缺失行/列对分析价值不大时,直接删除是最干净的做法。
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
axis |
int | 0 |
0 = 删行,1 = 删列 |
how |
str | 'any' |
'any' = 任一空就删,'all' = 全空才删 |
thresh |
int | None |
至少 N 个非空值才保留 |
subset |
list | None |
只检查指定列(最常用) |
inplace |
bool | False |
是否原地修改 |
📌 返回值:返回一个新的 DataFrame,原数据不被修改。
python
# dropna 默认删除任何包含缺失值的行
df_clean = df_sales.dropna()
# 只检查指定列的缺失,其他列不管
df_drop_subset = df_sales.dropna(subset=['客户所在城市'])2.1.3 填充缺失值:fillna()
当缺失值不能随便丢弃时(比如关键字段只有少数缺失),就需要填充。
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
value |
scalar/dict | --- | 填充值;传字典可为不同列设不同的填充值 |
method |
str | None |
'ffill' = 向前填充,'bfill' = 向后填充 |
axis |
int | 0 |
填充方向 |
limit |
int | None |
最多填充几个 |
inplace |
bool | False |
是否原地修改 |
📌 返回值:返回一个新的 DataFrame,原数据不被修改。
python
# 用固定值填充
df_filled = df.fillna('未知')
# 不同列不同填充值
df_filled = df.fillna({'客户所在城市': '未知城市', '单价': 0})
# 向前填充(用前一行的值)
df_filled = df.ffill()
# 向后填充(用后一行的值)
df_filled = df.bfill()ffill() 和 bfill() 本质上就是 fillna(method='ffill') 和 fillna(method='bfill') 的快捷方式。
2.1.4 可以混合处理吗?
当然可以!现实中最常见的做法是:核心字段删,次要字段填。
python
# 核心字段有缺失 → 删
df = df.dropna(subset=['订单号', '产品名称'])
# 次要字段有缺失 → 填
df['客户所在城市'] = df['客户所在城市'].fillna('未知')⚠️ 缺失值处理的核心认知:数据到底变了没?
这是每个 pandas 初学者都必须彻底搞懂的问题。请看下表:
| 方法 | 修改原 df? | 如何保存结果 |
|---|---|---|
df.dropna() |
❌ 不修改 | df2 = df.dropna() 或 df.dropna(inplace=True) |
df.fillna(x) |
❌ 不修改 | df2 = df.fillna(x) 或 df.fillna(x, inplace=True) |
df.ffill() / df.bfill() |
❌ 不修改 | df2 = df.ffill() 或 df.ffill(inplace=True) |
python
# 验证:不赋值就没变!
df_test = df.copy()
df_test.fillna('已填充') # 只是"返回"了一个新 df,没有保存
print(df_test.isnull().sum()) # 缺失值数量还是原来的!
df_test = df_test.fillna('已填充') # 必须赋值
print(df_test.isnull().sum()) # 变为 0推荐习惯 :始终用赋值
df = df.dropna(...),更清晰、更不容易忘记保存结果。
2.2 重复值处理
drop_duplicates()同样默认返回新对象,不修改原 df。
查看重复值:duplicated()
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
subset |
list | None |
检查哪些列(默认所有列全部对比) |
keep |
str | 'first' |
'first' = 首次出现标 False;'last' = 最后出现标 False;False = 全部标 True |
📌 返回值 :布尔 Series。
True表示该行与之前出现过的行重复。
python
# 检查所有列完全重复的行
df.duplicated()
# 只看产品名称是否重复(其他列不同不算)
df.duplicated(subset=['产品名称'])删除重复值:drop_duplicates()
python
# keep='first'(默认):保留最早出现的,删后续重复的
df.drop_duplicates(subset=['产品名称'], keep='first')
# keep='last':保留最后出现的,删之前的
df.drop_duplicates(subset=['产品名称'], keep='last')
# keep=False:一个不留,所有重复的全部删掉
df.drop_duplicates(subset=['产品名称'], keep=False)keep 参数的选择取决于业务逻辑。比如产品表中产品名称应该唯一,那就 keep=False 把重复的全部清掉再排查;而日志表中可能只需要保留最新的一条,就用 keep='last'。
drop_duplicates()同样默认返回新对象,不修改原 df。
2.3 异常值处理
异常值是与正常数据分布显著偏离的值,比如负数销量、不合理的极端价格等等。
异常值的处理同样遵循 发现 → 处理 的框架:先通过统计描述或条件筛查来发现哪些值不对劲,再选择是过滤剔除还是截断修正。
发现异常值:describe() + 条件判断
python
# 第一步:发现------用 describe() 看数据分布
df[['销售数量', '单价']].describe()
# 从输出中发现:单价 min = -29(不可能!),这就是异常值
# 也可以直接统计异常值的数量
(df['单价'] < 0).sum() # 看看有多少条负价格记录处理异常值:布尔过滤(最简洁的方式)
python
# 第二步:处理------用布尔条件过滤掉异常行
df_valid = df[df['单价'] >= 0]
df_valid = df[(df['单价'] >= 0) & (df['销售数量'] > 0)]删除异常值:drop()
错误做法:df.drop(布尔条件)
python
df.drop(df['单价'] < 0) # ❌ 报错!为什么不对? 因为 df.drop() 需要的是索引标签(label) ,不是布尔条件。df['单价'] < 0 返回的是一个布尔 Series(一堆 True/False),drop() 会尝试把这些 True/False 当作标签去查找,自然找不到,直接报 KeyError。
如果真的想用 drop,需要先拿到异常行的索引:
python
bad_idx = df[df['单价'] < 0].index # 取出异常行的索引标签
df.drop(bad_idx) # 按索引删除df.drop(bad_idx) 不会改变 df 本身,而是返回一个新的 DataFrame
📌 返回值:返回一个新的 DataFrame,原数据不被修改。
补充:clip()
有时候不想删数据,只想把异常值"拉回"合理范围:
python
df['单价'] = df['单价'].clip(lower=0, upper=10000)
# 小于 0 的全部变成 0,大于 10000 的全部变成 100002.4 数据格式处理
格式不一致同样遵循 发现 → 处理 的思路。先用 dtypes、nunique()、value_counts() 等方法发现 异常格式,再用 replace()、astype()、str 方法修正。以下是几个最高频的方法:
整体替换:replace()
replace(old_value, new_value) 把指定值全部替换为新值。适合统一命名、修正错别字等场景。
python
df['支付方式'] = df['支付方式'].replace('现金', '现金支付')字符串局部替换:str.replace()
.str 访问器提供了类似 Python 字符串方法的全套操作,但它们是向量化的(一次处理整个列)。
python
# 去除首尾空格
df['产品名称'] = df['产品名称'].str.strip()
# 替换子串
df['产品名称'] = df['产品名称'].str.replace('旧字', '新字')
# 其他常用字符串操作
df['列'].str.upper() # 转大写
df['列'].str.lower() # 转小写
df['列'].str.contains('x') # 是否包含某字符类型转换:astype()
python
df['单价'] = df['单价'].astype(float) # int → float
df['类别'] = df['类别'].astype('category') # 转为分类类型,节省内存3. 数据分析
数据清洗完毕后,进入分析阶段。
3.1 数据排序sort_values() 与 sort_index()
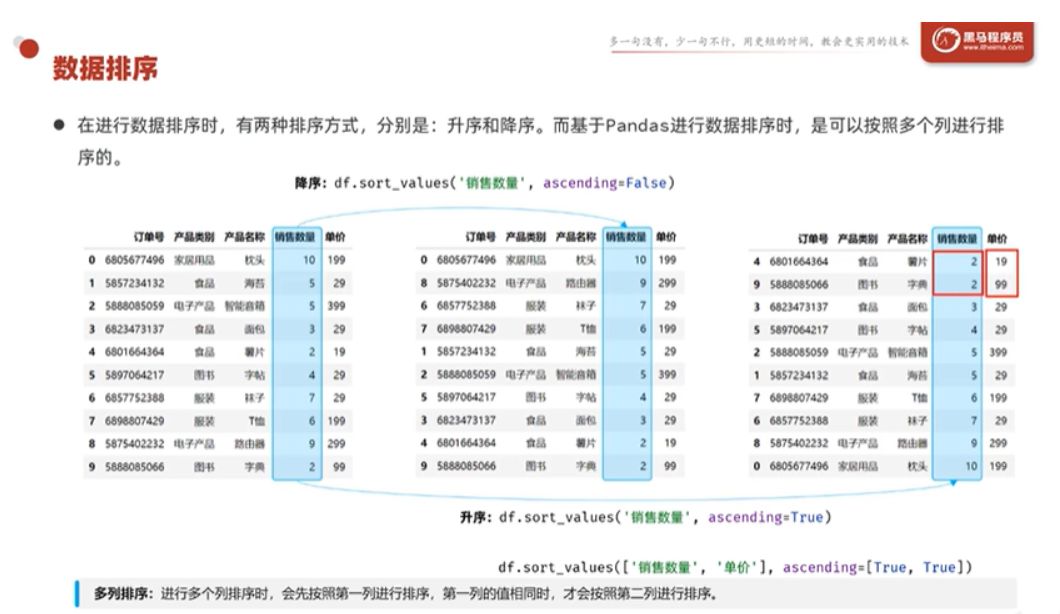
按值排序:sort_values()
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
by |
str/list | 必填 | 按哪一列(或多列)排序 |
ascending |
bool/list | True |
True = 升序↑,False = 降序↓ |
inplace |
bool | False |
是否原地修改 |
na_position |
str | 'last' |
缺失值排在哪:'first' 开头 / 'last' 末尾 |
📌 返回值:新的 DataFrame。
python
# 单列排序:评分从高到低
df.sort_values('评分', ascending=False)
# 多列排序:先按评分降序,评分相同时按时长升序
df.sort_values(by=['评分', '时长'], ascending=[False, True])💡 多列排序的逻辑是:先按第一个列排序,第一个列值相同时,再按第二个列排序 。就像 Excel 中的"主要关键字→次要关键字"。箭头记忆法:
True↑升序,False↓降序。
按索引排序:sort_index()
python
df.sort_index(ascending=False) # 按行索引降序排列3.2 分组分析:groupby()
分组分析是数据分析的精华。其核心是 分割-应用-合并(split-apply-combine)三步:
- 分割:按某个(或某几个)特征把数据分成若干组
- 应用:对每个组执行统计操作(求和、求均值等)
- 合并:将各组结果汇总为一张表

为什么执行 groupby() 后只看到内存地址?
很多初学者会困惑:
python
grouped = df.groupby('语言')
print(grouped)
# 输出:<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001BD24E77F20>这是什么?为什么不是一张表格?
因为 groupby() 返回的是一个 DataFrameGroupBy 对象,它只是一个"分组蓝图"------记录了"如何分组",但还没有执行任何计算。它本身不是表格,只是一个中间状态。
📌 必须再接一个聚合函数 (
.mean()、.sum()、.count()等),pandas 才会真正去计算并返回结果表格。
python
# ✅ 正确用法:groupby() + 聚合函数
df.groupby('语言')['评分'].mean() # 各语言电影的平均评分
df.groupby('语言')['评分'].sum() # 各语言电影的评分总和
df.groupby('语言')['评分'].count() # 各语言电影的数量多列分组
python
# 按 类型+语言 分组,算评分均值,再排序
result = (df
.groupby(['类型', '语言'])['评分']
.mean()
.sort_values(ascending=False)
)同时计算多个统计量:agg()
python
# 对评分列同时计算 数量、均值、最大值、最小值
df.groupby('语言')['评分'].agg(['count', 'mean', 'max', 'min'])
# 对不同列做不同聚合
df.groupby('语言').agg({
'评分': 'mean', # 评分取平均
'时长': 'max', # 时长取最大
'电影名': 'count' # 电影数量
})链式操作
分组的结果可以继续链式调用排序、筛选等操作,这正是 pandas 的强大之处:
python
# 一步到位:分组 → 聚合 → 排序 → 取前 5
(df
.groupby('客户所在城市')['销售额']
.sum()
.sort_values(ascending=False)
.head(5)
)4. 总结
数据分析完整流程
数据收集 数据清洗 数据分析
┌──┐ ┌──────┐ ┌────┐
│读│ ──────────→ │查漏补缺│ ──────────→ │排序│
│取│ raw data │去重纠错│ clean data │分组│
│写│ │统一格式│ │统计│
│入│ └──────┘ └────┘
└──┘🔑 黄金法则 :pandas 的清洗和分析方法,除非你明确设置了
inplace=True,否则全部返回新对象 ,原 DataFrame 一直不变。要保存结果,必须赋值 :df = df.xxx()。
希望这篇笔记能帮你理清数据分析。配套的data_analysis.ipynb 包含了文中所有代码的可运行版本,以及一些代码案例帮助理解,可以边读边动手实践。
以上为个人学习总结,旨在梳理个人理解。如有疏漏或不当之处,欢迎指正与交流。如果文章对你有帮助,别忘了点个赞、留个言,让更多的小伙伴看到~ 我们下篇再见!
📁 代码讲义:data_analysis.ipynb
📅 更新日期:2026-06-07
🔗 前置知识:Series、DataFrame 讲解篇
📂 示例数据:movies.csv(300条电影记录)、sales.csv(1000条销售记录)