3753------没理清
数位DP,说白了也还是DP,找好状态,定义好状态转移
pos当前第几位,prev为前一位数字,trend为前面的关系,然后tight是否紧贴
到本位时,就看tight,如果是1,就可以选择两条路,即继续紧贴,或者就随便选
然后如果不是1,就随便选
不过是给定了一个区间a,b问a,b之间的数量,这如何求解?就比如a是一位数,b是5位数的
dfs就是求从0到num的res数量,然后前缀和去减
为什么一定要在外层包装一个coutUpTo?这样会导致DP不共用







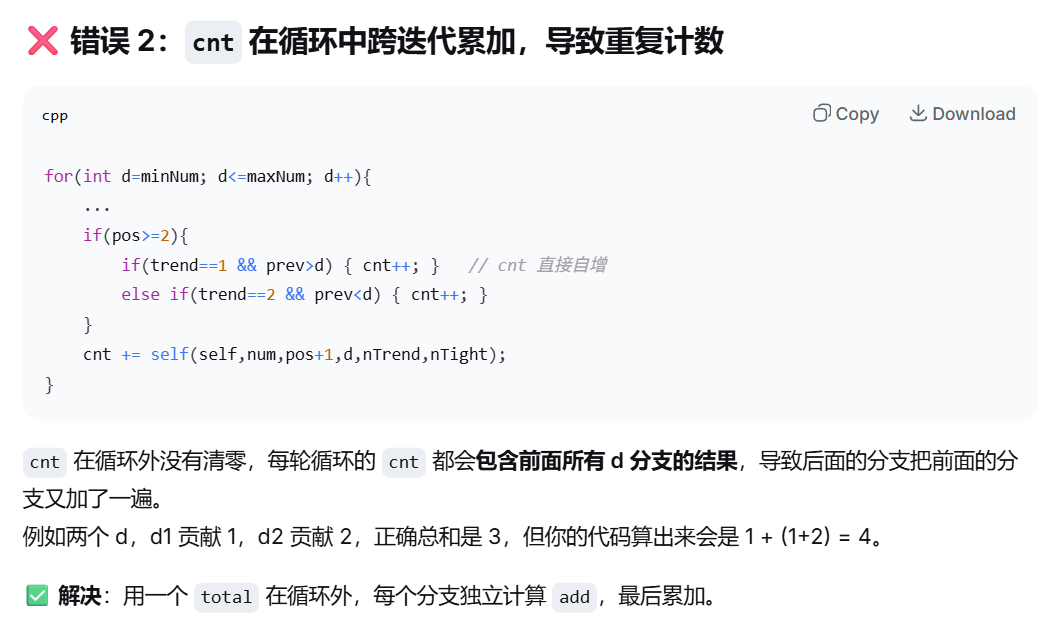
badCode
class Solution {
public:
long long totalWaviness(long long num1, long long num2) {
long long res=0;
auto dfs=[&](auto&&self,string num,int pos,int prev,int trend,bool tight){
if(pos>=num.size()){return 0;}
if(dp[]){return dp[];}
int cur_num=num[pos]-'0',maxNum=tight?cur_num-1:9,cnt=0,minNum=(pos==0)?1:0,n_trend;
if(tight){
if(cur_num>prev){
n_trend=1;
if(trend==2){cnt++;}
}
else if(cur_num<prev){
n_trend=2;
if(trend==1){cnt++;}
}
else{n_trend=0;}
cnt+=self(self,num,pos+1,cur_num,n_trend,tight);
if(cur_num==1){
dp[]=cnt;
return dp[];
}
}
for(int i=minNum;i<=maxNum;i++){
if(i>prev){
n_trend=1;
if(trend==2){cnt++;}
}
else if(i<prev){
n_trend=2;
if(trend==1){cnt++;}
}
else{n_trend=0;}
cnt+=self(self,num,pos+1,i,n_trend,false);
}
dp[]=cnt;
return dp[];
};
int begTrend2;
//这里确定一下从第三个字开始时,前两个字的Trend;需要特判一下长度不超过2的情况,因为这样会非法;
//然后dfs的时候就直接从第3位开始;
return dfs(dfs,to_string(num2),2,-)
}
};
class Solution {
public:
long long totalWaviness(long long num1, long long num2) {
long long res=0;
vector<vector<vector<vector<long long>>>>dp(18,
vector<vector<vector<vector<long long>>>(18,vector<vector<long long>>(10,vector<long long>(3,-1)));
auto dfs=[&](auto&&self,string num,int pos,int prev,int trend,bool tight){
if(pos==num.size()){return 0LL;}
int ntrend=0,nTight;
if(!tight&&prev!=-1&&dp[pos][prev][trend]!=-1){
return dp[pos][prev][trend];
}
long long cnt=0;
int maxNum=tight?num[pos]-'0':9;
int minNum=(pos==0)?1:0;
for(int d=minNum;d<=maxNum;d++){
bool nTight=tight&&(d==maxNum);
if(prev!=-1){
//计算nTrend
if(d>prev){nTrend=1;}
else if(d<prev){nTrend=2;}
else{nTrend=0;}
//计算cnt
if(pos>=2){
if(trend==1&&prev>d){cnt++;}//1为上升
else if(trend==2&&prev<d){cnt++;}//2为下降
}
}
cnt+=self(self,num,pos+1,d,nTrend,nTight);
}
if(!tight){
dp[pos][prev][trend]=cnt;
}
return cnt;
};
string snum1=to_string(num1-1),snum2=to_string(num2);
return dfs(dfs,snum2,0,-1,0,true)-dfs(dfs,snum1,0,-1,0,true);
}
};
流水线拆分
IF











BTB


这个BTB的用处在哪里?我现在理解的是,分支预测会在每取出一条指令后就对该指令后的下一条指令做预测(这里预测的是指令的地址,还是指令本身?);最开始先是pc得到next_pc,然后在IF阶段去ICACHE里找这个pc所对应的指令,这时候就已经开始预测了吗?就是在IF取值的时候,用的是BTB给出的pc?


什么叫"taken branch"带来的气泡?以及PFS选出fetch_pc=X时,X所对应的那个指令应该就处于IF阶段吧,然后TLB翻译X,但是ICache又去取X对应的指令,ICache里存的也是虚拟地址吗?就是TLB如果不翻译成物理地址,ICache怎么取?什么是taken branch?
对于ICache,如果在第N拍,x对应的指令在IF阶段去让ICache取指令,但是ICache miss了,那N+1拍,即x的ID阶段,取不到指令,ICache还在往RAM上找,这会怎么办?




推进有效条件









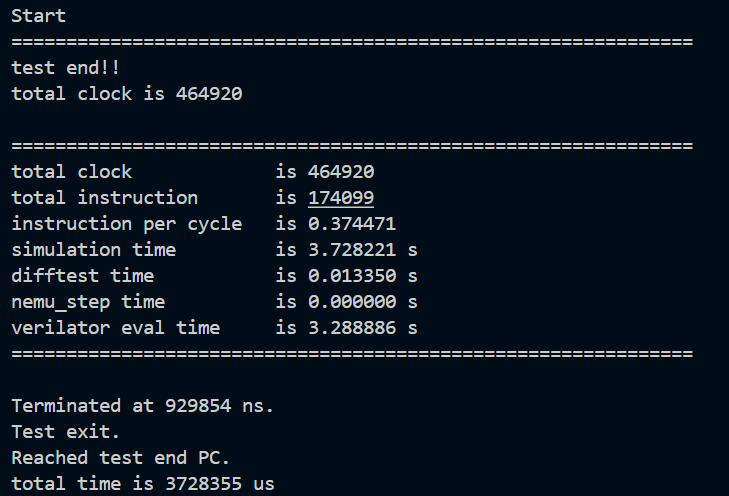
测试
当前推荐的工作指令流是:
# 1. 进入 chiplab 工作目录
cd /home/jiake/project/learn/newCpu
# 2. 设置环境
export CHIPLAB_HOME=$PWD
export PATH=$CHIPLAB_HOME/toolchains/loongson-gnu-toolchain-8.3-x86_64-loongarch32r-linux-gnusf-v2.0/bin:$PATH
改 CPU 代码只进 myCPU:
cd /home/jiake/project/learn/newCpu/IP/myCPU
# 修改 RTL 后
git status
git add .
git commit -m "your message"
git push
跑 func 测试:
cd /home/jiake/project/learn/newCpu/sims/verilator/run_prog
./configure.sh --run func/func_lab19 --disable-trace-comp --disable-simu-trace --output-uart-info --threads 8
make -j8 compile
make clean_soft
make -j8 soft
make -j8 run BUS_DELAY=n DUMP_WAVEFORM=0
如果只是重复跑同一个测试、没有改 RTL:
cd /home/jiake/project/learn/newCpu/sims/verilator/run_prog make -j8 run BUS_DELAY=n DUMP_WAVEFORM=0
如果改了 IP/myCPU 的 RTL,至少重新:
make -j8 compile
make -j8 run BUS_DELAY=n DUMP_WAVEFORM=0
范式










我现在理解的就是对于原来的,在module里直接声明的各类一条一条的信号,就是通过pack,把相关的所有信号打包在一起,比如流水线间的传递,异常相关等,就是按功能分类凑在一起;然后到取的时候再assign取出来;然后那些package都定义在.sv文件中;不过为什么要叫pipline_type?感觉就是一个记录所有package类型的,total之类的名字可能更合适?
TLB

Res
if2id