定义一个接口,加上注解,框架自动生成实现------AiServices 把声明式编程带到了 Agent 开发里。这篇文章深入解析它的工作机制和 5 个核心能力。
上篇文章里我们展示了一个「能聊天的 Agent」:定义一个 IndustrialAssistant 接口,调 AiServices.builder().build(),就能自动调用工具、管理记忆、返回结果。
看起来像魔法。但魔法背后是什么?这篇深挖下去。
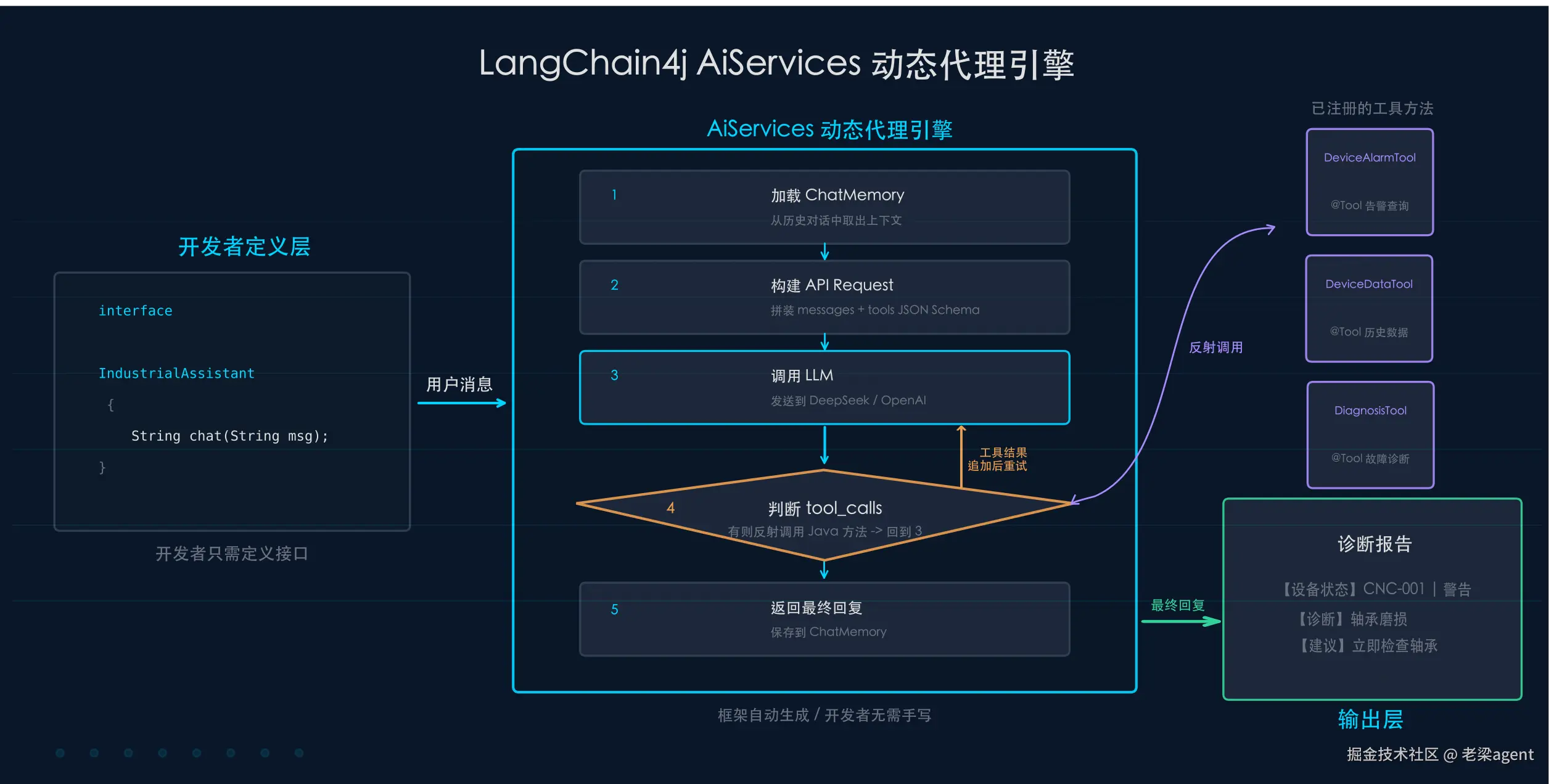
核心:动态代理
AiServices 的本质是 Java 动态代理 。AiServices.builder(IndustrialAssistant.class).build() 返回的,是 JDK 在运行时生成的 $Proxy 对象。
typescript
你写的接口 框架生成的代理
IndustrialAssistant → $Proxy0 implements IndustrialAssistant
chat(String msg) invoke() {
→ 加载 ChatMemory 中的历史消息
→ 构建 OpenAI API Request
(messages + tools JSON Schema)
→ 调用 LLM
→ 如果有 tool_calls → 反射调用对应方法
→ 工具结果追加到消息列表 → 再调 LLM
→ 返回最终回复
}一句话总结 :你定义的接口方法是"意图",代理对象的 invoke() 是"引擎"。引擎自动处理消息编排、工具调用、记忆管理------这些都是你不需要手写的胶水代码。
为什么不直接写实现类?
因为 Agent 的调用链有太多模板代码。以一次工具调用为例,手写代码大概是这样的(伪代码):
java
// 手写 Agent 调用链(伪代码)
public String chat(String userMessage) {
// 1. 从 ChatMemory 加载历史
List<Message> history = chatMemory.messages();
// 2. 构建 OpenAI Request
ChatCompletionRequest request = ChatCompletionRequest.builder()
.model("deepseek-chat")
.messages(history + currentMessage)
.tools(buildToolSchema(alarmTool, dataTool, diagnosisTool)) // 反射提取 @Tool
.build();
// 3. 调 LLM
ChatCompletionResponse response = chatModel.chat(request);
// 4. 如果 LLM 返回 tool_calls,反射调用 Java 方法
if (response.hasToolCalls()) {
for (ToolCall tc : response.getToolCalls()) {
String result = invokeToolByName(tc.name, tc.arguments);
history.add(tc, result); // 工具结果也加入上下文
}
// 5. 把工具结果发回 LLM,获取最终回复
response = chatModel.chat(buildFollowUpRequest(history));
}
// 6. 保存到 ChatMemory
chatMemory.add(userMessage, response);
return response.getContent();
}这就是 AiServices 帮你省掉的胶水代码。代理对象的 invoke() 内部就是上面的流程------但它是框架写好的,你只需要定义接口。
能力 1:@SystemMessage --- 给 Agent 一个「人设」
@SystemMessage 是告诉 LLM「你是谁」和「你的边界在哪」的入口。
java
interface IndustrialAssistant {
@SystemMessage("""
你是一个工业设备运维专家,服务于智能工厂的设备监控与故障诊断。
你的知识有限,无法访问实时设备数据。
当用户询问设备状态、告警、历史数据、故障原因时,你必须使用提供的工具查询,
不要凭猜测回答。
回复规范:
- 用结构化方式呈现诊断结果(问题、原因、建议)
- 涉及安全风险时,明确标注优先级(HIGH/MEDIUM/LOW)
- 不确定时如实说明,不要编造数据
""")
String chat(String message);
}这段 SystemMessage 里有两个关键设计:
1. 限制知识边界。「你的知识有限,无法访问实时设备数据」+「必须使用提供的工具查询,不要凭猜测回答」。这两句话直接对应我们之前踩过的坑------LLM 凭通用知识「编」答案而不调用工具。明确告诉它「你不知道」,它才会用工具。
2. 指定回复范式。「用结构化方式呈现」「标注优先级」「不确定时如实说明」------这些不是约束 LLM 的「自由」,而是在约束它的「输出格式」。当 Agent 面向运维工程师时,回复必须可执行。
SystemMessage 和 @Tool 描述的关系
很多人混淆这两者。简单区分:
| 机制 | 作用 | 写给谁看的 |
|---|---|---|
@SystemMessage |
定义 Agent 的整体人格和回复规范 | LLM 的所有推理阶段 |
@Tool 描述 |
定义单个工具的触发条件和功能 | LLM 判断「要不要调这个工具」时 |
SystemMessage 是全局的,@Tool 描述是局部的。两者配合------SystemMessage 说「你必须用工具」,@Tool 描述说「这个工具是干什么的」。
能力 2:@UserMessage --- 模板化提示
如果你的接口方法需要携带具体的指令,@UserMessage 可以定义方法级别的提示模板:
java
interface DiagnosticAssistant {
@SystemMessage("""
你是一个工业设备故障诊断专家。你必须使用提供的工具查询设备数据,
然后基于工具返回的结构化数据进行诊断分析,不要凭猜测回答。
""")
@UserMessage("""
请对设备 {{deviceId}} 进行全面的故障诊断分析:
1. 查询设备告警信息
2. 查询设备历史遥测数据
3. 基于以上数据生成诊断报告
""")
DiagnosticResponse diagnose(@V("deviceId") String deviceId);
}@UserMessage 里的 {{deviceId}} 是模板占位符,@V("deviceId") 把方法参数名绑定到占位符。框架在构建请求时,会把模板中的 {{deviceId}} 替换成实际参数值。
@SystemMessage vs @UserMessage 的区别:
| @SystemMessage | @UserMessage | |
|---|---|---|
| 位置 | 固定在对话最开头 | 作为当前轮次的用户输入 |
| 作用 | 人设和全局规则 | 具体任务的指令 |
| 变化 | 不变 | 可以随方法参数变化 |
能力 3:ChatMemory --- Agent 的「记忆」
ChatMemory 是 Agent 记住多轮对话的机制。LangChain4j 提供了两种主要策略:
java
// 策略 1:保留最近 N 条消息(我项目的默认配置)
ChatMemory msgWindow = MessageWindowChatMemory.withMaxMessages(20);
// 策略 2:保留最近 N 个 token
ChatMemory tokenWindow = TokenWindowChatMemory.withMaxTokens(2000, new OpenAiTokenizer());三种策略的表现差异
我做了一个对比实验:同样的三段对话(自我介绍 → 查询设备 → 追问身份),分别用三种记忆策略跑:
java
// MemoryComparisonService 的核心逻辑
Map<String, List<String>> results = new LinkedHashMap<>();
// 20 条消息窗口
ChatMemory msg20 = MessageWindowChatMemory.withMaxMessages(20);
results.put("messageWindow(20)", runConversation(msg20, conversation));
// 4 条消息窗口 --- 模拟「短记忆」
ChatMemory msg4 = MessageWindowChatMemory.withMaxMessages(4);
results.put("messageWindow(4)", runConversation(msg4, conversation));
// 2000 token 窗口
ChatMemory token2k = TokenWindowChatMemory.withMaxTokens(2000, new OpenAiTokenizer());
results.put("tokenWindow(2000t)", runConversation(token2k, conversation));典型结果:
| 策略 | 第三轮追问「我之前说我是谁?」 | 表现 |
|---|---|---|
| messageWindow(20) | 「你是张三,CNC-001 的运维工程师」 | ✅ 正确 |
| messageWindow(4) | 「不好意思,我没有你的身份信息」 | ❌ 失忆 |
| tokenWindow(2000t) | 「你是张三,负责 CNC-001」 | ✅ 正确 |
怎么选?
| 场景 | 推荐策略 | 原因 |
|---|---|---|
| 一般对话 Agent | MessageWindowChatMemory(20) |
简单可控,消息数确定 |
| Token 预算严格 | TokenWindowChatMemory(N) |
精确控制 token 消耗,适合成本敏感场景 |
| 多轮深度诊断 | MessageWindowChatMemory(40+) |
需要更长上下文才能追溯根因 |
经验规则:消息窗口适合「对话轮次可控」的场景,token 窗口适合「单轮消息长度不可控」的场景(比如 RAG 返回大段文档)。
ChatMemory 的当前局限
MessageWindowChatMemory 存在 JVM 内存中,服务重启即丢失。LangChain4j 预留了 ChatMemoryStore 接口,可以接入 Redis 或数据库做持久化:
java
// 持久化 ChatMemory(示意,LangChain4j 0.35.0 需自行实现)
ChatMemory persistentMemory = MessageWindowChatMemory.builder()
.maxMessages(20)
.chatMemoryStore(new RedisChatMemoryStore(redisTemplate))
.build();持久化 Memory 的意义不仅仅是「重启不丢消息」------在多实例部署时,共享 Memory 可以做到用户级别的会话保持。
能力 4:TokenStream --- SSE 流式响应
默认 String chat(String message) 是同步的------LLM 生成完全部内容后才返回。在 UI 上,用户看到一个「正在思考...」的 loading 直到结果出来。
TokenStream 解决了这个问题------每生成一个 token 就推到前端,实现逐字输出效果。
接口定义
java
interface IndustrialAssistant {
String chat(String message);
// 流式方法,返回 TokenStream
TokenStream chatStream(String message);
}同一个接口里可以同时声明同步和流式方法------框架会为每个方法生成对应的调用逻辑。
SSE 端点实现
java
@PostMapping(value = "/chat/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public SseEmitter chatStream(@RequestBody Map<String, String> request) {
String message = request.getOrDefault("message", "");
SseEmitter emitter = new SseEmitter(120_000L); // 2 分钟超时
TokenStream tokenStream = deviceAgent.chatStream(message);
tokenStream
.onNext(token -> {
emitter.send(SseEmitter.event().name("token").data(token));
})
.onComplete(response -> {
log.info("[SSE] Stream completed, tokens: {}", response.tokenUsage());
emitter.complete();
})
.onError(error -> {
log.error("[SSE] Stream error: {}", error.getMessage());
emitter.completeWithError(error);
})
.start();
return emitter;
}三个回调:
onNext:每生成一个 token 调用一次,直接 push 到 SSE 连接onComplete:完整回复生成完毕后调用,tokenUsage()告诉你这次消耗了多少 tokenonError:调用出错时触发,把异常传给 SSE 连接让前端感知
什么时候用流式?
| 场景 | 推荐 |
|---|---|
| Web UI 对话 | 流式 --- 用户体验好,逐字显示 |
| API 对 API 调用 | 同步 --- 调用方不消费 SSE |
| 批量诊断 | 同步 --- 跑完一批再统一处理结果 |
能力 5:POJO 结构化输出
工具返回 JSON 字符串是第一步。更进一步------让 Agent 的方法直接返回 Java POJO。
定义输出模型
java
@Data
public class DiagnosticResponse {
@Description("设备ID")
private String deviceId;
@Description("设备当前状态:normal/warning/critical")
private String status;
@Description("诊断分析结论")
private String analysis;
@Description("可能的故障原因,按可能性从高到低排列")
private List<String> possibleCauses;
@Description("建议的维修或处理措施")
private List<String> suggestedActions;
@Description("优先级:HIGH/MEDIUM/LOW")
private String priority;
@Description("是否需要立即处理")
private Boolean requiresImmediateAction;
@Description("诊断置信度,0.0-1.0")
private Double confidence;
}@Description 注解是关键------它告诉 LLM 每个字段的含义和取值范围。LLM 会在推理时决定每个字段填什么。
接口方法
java
interface DiagnosticAssistant {
@SystemMessage("""
你是一个工业设备故障诊断专家。你必须使用提供的工具查询设备数据,
然后基于工具返回的结构化数据进行诊断分析,不要凭猜测回答。
""")
@UserMessage("""
请对设备 {{deviceId}} 进行全面的故障诊断分析:
1. 查询设备告警信息
2. 查询设备历史遥测数据
3. 基于以上数据生成诊断报告
""")
DiagnosticResponse diagnose(@V("deviceId") String deviceId);
}返回类型从 String 变成 DiagnosticResponse。框架会把工具调用结果和 LLM 推理内容,自动映射到 POJO 的各个字段。
String vs POJO
| 方式 | 优点 | 缺点 |
|---|---|---|
String 返回 |
灵活,LLM 自由发挥 | 解析靠正则,前端耦合 |
DiagnosticResponse 返回 |
类型安全,前端直接反序列化 | 字段定义要提前设计 |
实践建议:核心业务场景(诊断、工单生成、报表)用 POJO;调试/探索性对话保留 String 接口。
五个能力的关系
less
@SystemMessage → 定义 Agent 的人设和边界(全局)
@UserMessage → 定义当前任务的具体指令(方法级)
ChatMemory → 管理对话上下文(状态)
TokenStream → 控制输出的传输方式(SSE 流式 vs 同步)
POJO / String → 控制输出的格式(结构化 vs 自然语言)它们不是互相替代的,而是各管一段------AiServices 的 builder 把它们统一编织到代理对象的 invoke() 引擎里。
一个值得注意的设计选择
在 DeviceAgent 的实现中,我选择每次 chat() 都重新 build:
java
public String chat(String userMessage) {
return AiServices.builder(IndustrialAssistant.class)
.chatLanguageModel(chatModel)
.chatMemory(chatMemory)
.tools(alarmTool, dataTool, diagnosisTool)
.build()
.chat(userMessage);
}为什么? 因为 chatMemory 是单例 Bean------同一个实例被所有请求共享。每次 rebuild 只是创建一个新的代理对象,但底层指向同一个 Memory 实例,所以对话历史不会丢。代理创建的 overhead 很小(JDK 动态代理,没有网络调用)。
什么时候该缓存代理? 如果你在代理上注册了 ChatMemoryProvider(为每个用户创建独立 Memory),就应该缓存代理实例。但对于大多数单用户场景,每次 build 是最简单的方式。
总结
LangChain4j AiServices 的核心设计是:
- 接口 = 意图,代理 = 引擎------你写接口,框架生成实现
- @SystemMessage 定义人设和知识边界,@Tool 描述定义工具触发条件
- ChatMemory 管理对话上下文,消息窗口和 token 窗口各有适用场景
- TokenStream 让 Agent 支持 SSE 流式输出,提升前端体验
- POJO 输出让 Agent 返回类型安全的 Java 对象,告别 String 解析
理解了这五个能力,你就理解了 AiServices 的「魔法」------它本质上是把 Agent 调用链中的模板代码抽取到代理引擎里,让你专注定义「Agent 能做什么」,而不是「Agent 怎么做」。
代码仓库:github.com/LaoLiang-ag...
本文由 LaoLiang 原创,首发于掘金/知乎/微信公众号。转载请联系作者。