💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通
💪🏻 2. AI编程变现手册,从学会AI编程到实现变现都可以
😁 3. 毕业设计专栏,毕业季咱们不慌忙,几千款毕业设计等你选。
❤️ 4. DeepSeek+RPA提效从入门到变现实战
❤️5. 欢迎访问我的免费工具站
❤️ 6. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
文章目录
上线第一周,用户反馈就来了:
"我明明传了文档进去,问它怎么什么都不知道?"
我去排查,知识库里有内容,向量索引也建了,ES服务也正常跑着。但用户一问,系统要么答非所问,要么直接说"暂无相关内容"。
召回率只有60%。
作为一个写了10年Java的人,我当时的第一反应是:这不就是数据库查不到记录的问题嘛------要么数据没入库,要么查询条件写错了。
结果排查下来,两个都有问题。
问题一:内容切得太碎,语义断了
我们当时的切分策略很简单------控制chunk大小,防止向量维度超限。结果一篇2000字的文档被切成了七八个片段,每片就两三百字。
问题来了:一个完整的知识点,被切成了三片。
用Java来类比就是:你把一个完整的业务对象UserInfo拆成了三张表,然后忘了写JOIN------查出来的每条记录都是残的,根本用不了。
用户问"如何申请退款",知识库里有完整的退款流程,但被切成了"退款条件"、"退款步骤"、"退款到账时间"三片。向量检索命中了"退款步骤"那片,但上下文不完整,LLM拿到之后生成的答案逻辑混乱。
解决方案:切分字段拆成两个。
originContent:保留完整语义,最大2000字
embeddingContent:压缩到450字以内,只保留核心语义向量化用embeddingContent(小),返回给LLM用originContent(大)。
检索用小的,回答用大的。
改完之后效果立竿见影------召回到的内容片段语义完整了,LLM"看懂了",答案质量直接上去了。

问题二:只靠向量检索,精确匹配全挂
向量检索的优势是语义相似,但它有个天然缺陷:对精确词汇不友好。
还是用Java类比:向量检索就像MyBatis里的模糊查询LIKE '%keyword%',找近似的很强,但你要精确匹配一个字段值,它就未必靠得住。
用户问专有名词时,向量检索可能给你召回一堆语义相似但不精确的内容。
解决方案:加入BM25全文检索,两路融合。
向量检索负责语义模糊匹配,BM25负责关键词精确匹配,用RRF算法融合打分:
向量分数权重:0.7
全文检索权重:0.3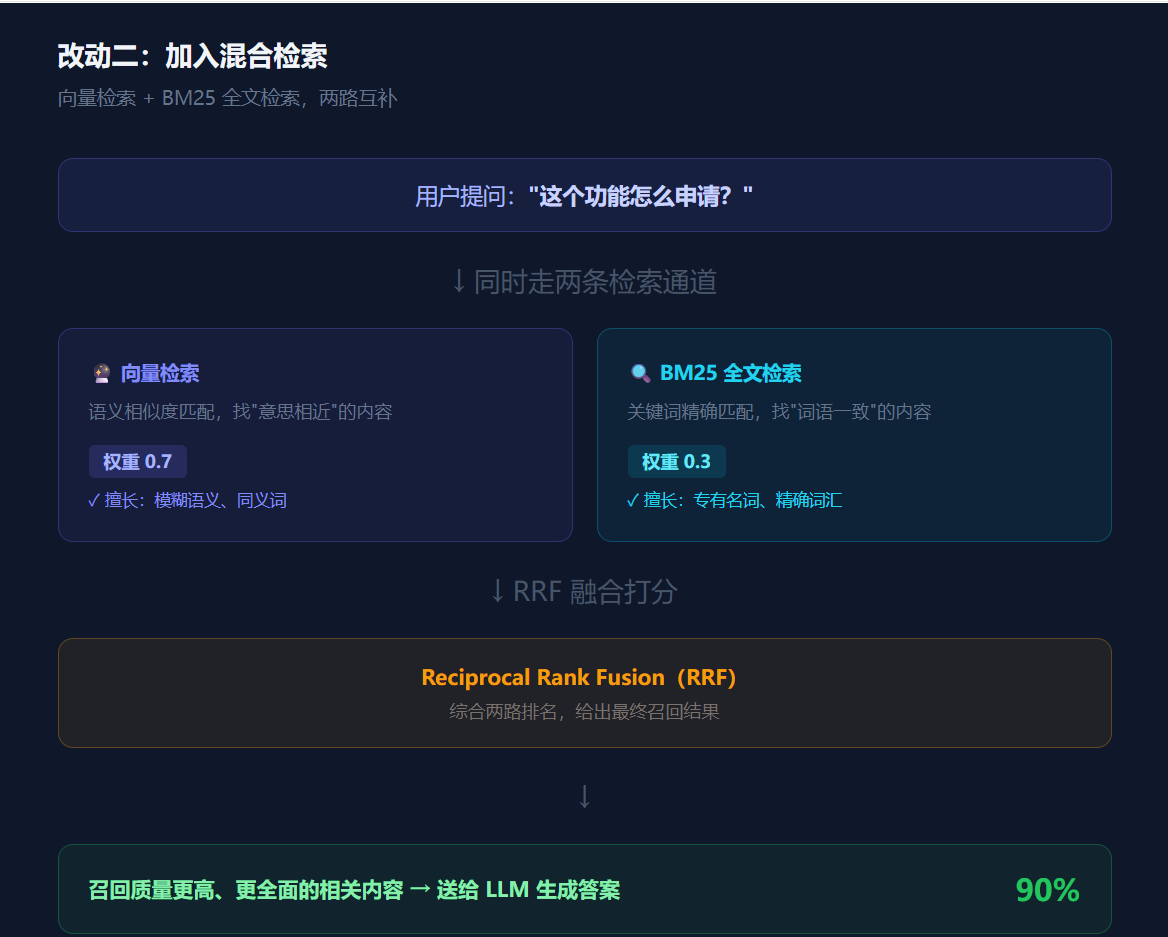
两个通道互补,语义相似和精确匹配都能覆盖到。
就像MySQL里既建了普通索引又建了全文索引,根据查询条件自动选择最优路径。
最终结果
两个改动加起来,召回率从60%提到了90%。
其中切分策略的改动效果最明显,贡献了大部分提升。混合检索是锦上添花,但对专有名词场景来说是刚需。
可以直接用的结论
如果你的RAG召回率上不去,先查这两个地方:
1. 切分粒度 :chunk不是越小越好。切分之前先想清楚:你的知识点最小完整单元是多大?用这个大小做originContent,再压缩一版做embeddingContent。
2. 检索方式:纯向量检索只适合语义模糊场景。有专有名词、精确匹配需求的,混合检索几乎是标配。成本低,效果好,直接上。
这两个问题是我在实际项目中遇到的,不是理论,是真实踩过的坑。
你的RAG系统有没有类似的问题?欢迎来星球聊聊,我们一起看。