大模型的安全问题不是某一个漏洞,而是一条攻击面持续扩大的演化线------从输入层(Prompt Injection / Jailbreak)→ 训练层(数据投毒 / 模型窃取)→ 执行层(Agent安全)→ 评估与治理层(红队方法论 / 安全左移)。每一层的攻击都让上一层的防御变得不够用。
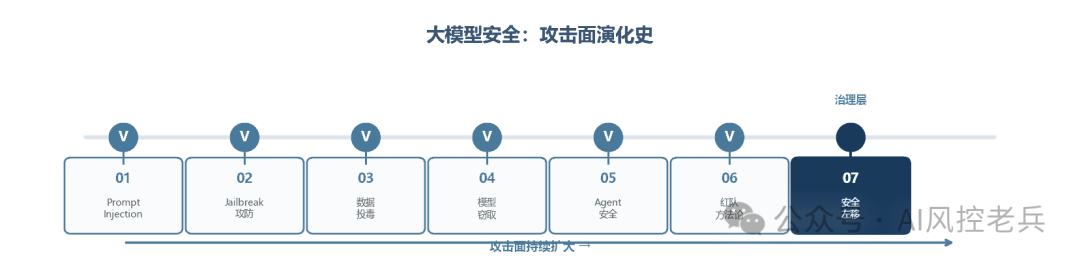
本篇是系列的最终篇 ,进入治理层 。前六篇讲了攻击面的每一层,这一篇回答一个终极问题:怎么让安全不再是一个事后补丁,而是从一开始就嵌在系统里?
2023年,一个安全团队发现公司新上线的AI聊天机器人会泄露系统Prompt。追溯原因:开发团队在两周内就完成了从HuggingFace下载模型到上线部署的全流程------没人做过安全评估,没人审计过模型来源,没人给API加过速率限制。
这不是个例。2024年GitLab的DevSecOps调查显示,78%的专业人士认为AI正在改变安全测试方式,但只有不到30%的团队在AI开发生命周期中嵌入了安全检查。到了2026年,Agent可以执行文件操作、调用API、管理数据------每次部署事故的代价是真实世界损失,不只是"模型说了不该说的话"。
传统安全花了二十年才从"最后检查"走到"安全左移"。AI安全不能等二十年,因为攻击面的演化速度比传统软件快得多。
一、AI时代的安全左移:不只是DevSecOps
传统"安全左移"的核心是把安全检查从生产环境前移到开发和构建阶段:SAST、DAST、IAST、依赖扫描、容器镜像扫描。这套模式在软件供应链安全领域已经验证有效。
但在AI/ML场景下,"左移"的含义需要扩展:
不仅仅是从"部署后"移到"部署前",而是从"模型部署阶段"移到"整个ML生命周期"------包括数据准备、模型训练、模型评估、模型部署、持续监控。
| 传统SDLC阶段 | 传统安全左移措施 | AI/ML等效措施 |
|---|---|---|
| 需求/设计 | 威胁建模 | AI threat modeling(数据流、模型行为、工具权限) |
| 编码 | SAST | Prompt security review、tool description审计 |
| 构建 | SCA、镜像扫描 | 模型签名验证、ML-SBOM、container runtime audit |
| 测试 | DAST、IAST | Prompt injection测试、red teaming pipeline |
| 部署 | WAF、RASP | 推理防护、输入输出过滤、沙箱验证 |
| 运维 | SIEM、SOAR | Agent行为基线、LLM-aware SIEM、异常检测 |
关键区别:传统安全左移的"向左"指的是在SDLC时间轴上向左移动。AI安全左移不仅向左,还要"向下"------深入到ML训练/微调/评估的技术栈内部。
二、合规对表:EU AI Act与法规对齐
2.1 EU AI Act:高风险AI系统的安全要求
2024年通过的EU AI Act是全球首部全面的AI监管法律。对于部署LLM/Agent应用的企业,有几个条款直接关系安全左移实践:
| EU AI Act条款 | 要求 | 安全左移的对应措施 |
|---|---|---|
| Art. 15 | 高风险AI系统应具备适当的准确性和安全性 | 自动化red teaming + ASR阈值阻断 |
| Art. 9 | 建立风险管理系统 | AI threat modeling + 持续弱点管理 |
| Art. 12 | 记录事件日志 | Agent工具调用审计 + LLM-aware SIEM |
| Art. 14 | 人类监督 | HITL(人在回路)+ 分级授权 |
| Art. 10 | 数据治理 | 数据供应链审计 + 毒性检测 |
| Art. 29 | 部署者的义务 | ML-SBOM + 模型来源验证 |
核心洞察:EU AI Act的要求跟安全左移的六道关卡几乎一一对应。这不是巧合------监管要求和技术最佳实践在AI安全领域正在趋同。做合规的人需要懂技术(不然写不出可审计的流程),做技术的人需要懂合规(不然扛不住监管审查)。
2.2 中国生成式AI监管
中国在2023-2025年间出台了一系列生成式AI管理规定。核心要求包括:
- 训练数据合规:数据来源合法、不含违法内容、保护个人信息
- 内容安全:生成内容不违反社会主义核心价值观、不传播虚假信息
- 算法备案:提供具有舆论属性或社会动员能力的生成式AI服务需备案
- 安全评估:上线前需通过安全评估
这些要求对安全左移的直接影响:
-
数据供应链审计(第二篇的要求)直接对应训练数据合规
-
内容安全检测(第一篇的要求)直接对应生成内容审核
-
安全评估报告(第六篇的要求)直接对应用于备案的红队测试报告
一句话总结:合规不是为了应付检查,而是为了建立可审计的安全流程。ML-SBOM、red teaming pipeline、审计日志------这些技术措施同时也是合规证据。
三、模型供应链安全:从"信则灵"到"可验证"
前几篇反复提到一个共同问题:你不知道你的模型里有什么。
-
第03篇:数据投毒------100条毒样本就能污染一个模型
-
第04篇:模型窃取------通过API查询就能偷走模型能力
-
第04篇也提到:LoRA适配器可以被投毒
-
第05篇:工具投毒------tool description可以被篡改
这些攻击有个共同根源:ML模型的供应链缺乏完整性验证机制。
3.1 ML-SBOM:ML版"软件物料清单"
传统软件有SBOM(Software Bill of Materials),列出所有依赖组件的版本和来源。ML场景需要ML-SBOM(或AI-BOM):
-
基座模型的来源、版本、哈希值
-
训练数据的数据集来源和许可证
-
微调过程的完整记录(基座版本、LoRA权重、超参数)
-
评估结果和安全测试记录
2025年,Sigstore社区发布了Model Transparency项目,把软件签名验证的思路迁移到ML模型。核心做法:模型签名 + 可验证的provenance attestation,让模型消费者能验证模型的来源和完整性。这与Cosign签名容器镜像的逻辑完全同构。
3.2 模型注册与版本管理
不要在CI/CD里直接从HuggingFace拉:latest的模型。这跟你从Docker Hub拉:latest的镜像是一个道理------你不知道今天的":latest"跟昨天的":latest"有什么区别。
最佳实践:
- Pin模型哈希:就像Docker image pin digest
- 签名验证:部署前验证模型签名(Sigstore Model Signing)
- 来源白名单:只允许从经过审核的模型仓库部署
3.3 数据供应链审计
训练数据、RAG数据、微调数据的来源必须可追溯。关键控制点:
-
数据来源记录:每个数据集的来源、收集时间、处理流程
-
数据污染检测:对训练数据做毒性检测和异常检测
-
RAG数据隔离:不同来源的RAG数据在向量数据库中的权限隔离
四、Pipeline安全:把安全检查变成自动化关卡
Agent AI的应用开发比传统应用开发更快------一个Agent应用可能在一周内就完成从"想法"到"部署"。这意味着安全检查必须自动化,不能依赖人工review。
4.1 CI/CD中的安全关卡
开发 → Lint + Prompt Review → Build → SAST + 依赖扫描 → Test → Red Teaming Pipeline → 部署 → 持续监控
↓
阻断失败部署每一道关卡都应该有明确的通过/失败标准和阻断能力:
- Prompt Review Gate:系统Prompt和tool description的安全审计,检测是否存在指令注入漏洞
- Model Verification Gate:验证模型签名、版本、来源白名单
- Red Teaming Pipeline Gate :自动化运行四层红队评估(单轮/多轮/工具调用/多Agent),ASR超过阈值则阻断部署
- Dependency Scan Gate :检测依赖包、容器镜像、LoRA适配器的已知漏洞
4.2 Agent权限的声明式管理
比"运行时审计"更好的做法是"声明式权限"------在Agent定义阶段就声明Agent需要哪些资源,而不是运行后再去审计它做了什么。
类似于Kubernetes的RBAC声明,Agent的权限声明应该包含:
- 工具白名单:Agent可以调用哪些工具
- 资源访问范围:可以读写的文件路径、API端点
- 网络访问限制:可以访问的外部域名
- 执行环境:沙箱/容器配置
- 最大操作次数/时间:防止无限循环和资源耗尽
4.3 持续安全验证
红队不是"做一次"就够了。Agent系统的每一次更新------模型升级、tool变更、权限调整------都可能引入新的安全风险。最有效的方式是把red teaming嵌入CI/CD,每次部署前自动运行。
这与传统安全中"从年度渗透测试到持续弱点管理"的演化路径完全一致。做AI安全的一个核心原则是:不要发明新方法论,把传统安全已验证过的模式迁移过来。
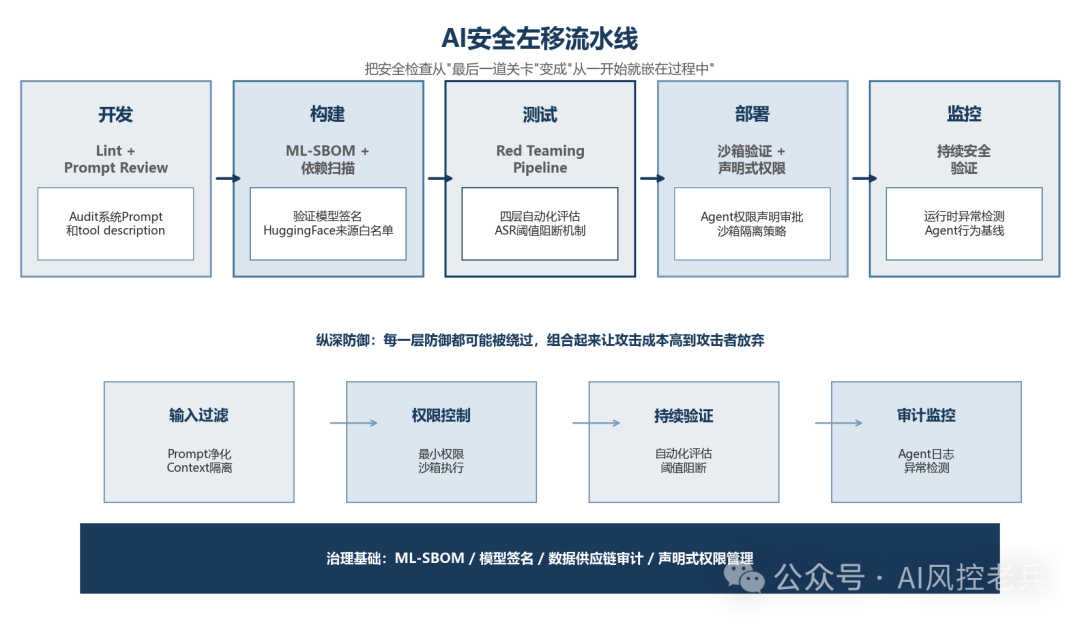
五、从"独立防御"到"纵深防御"
前六篇每一篇讲了一种攻击,也提到了一些针对性的防御。但单点防御是不够的------你需要纵深防御(Defense in Depth)。
把七篇的防御串起来:
| 攻击层 | 防御层 | 关键措施 |
|---|---|---|
| 输入层:Prompt Injection / Jailbreak | 输入过滤 + Prompt加固 | 输入净化、系统Prompt隔离、Context分区 |
| 训练层:数据投毒 | 数据验证 | 数据来源审计、毒性检测、异常检测 |
| 训练层:模型窃取 | API防护 | 速率限制、异常查询检测、水印 |
| 执行层:Agent安全 | 权限控制 | 最小权限、沙箱、HITL、工具验证 |
| 评估层:红队测试 | 持续验证 | 自动化red teaming、ASR阈值阻断 |
| 治理层:安全左移 | Pipeline关卡 | ML-SBOM、模型签名、声明式权限 |
每一层防御都可能被绕过,但组合起来能让攻击成本高到攻击者放弃。这就是传统安全做了三十年的纵深防御------在AI安全里,同样适用。
4.4 CI/CD安全管线的YAML实现示例
以GitHub Actions为例,实现AI Agent部署的安全管线:
# .github/workflows/ai-deploy-pipeline.yml
name: AI Agent Security Pipeline
on: [push, pull_request]
jobs:
security-gates:
runs-on: ubuntu-latest
steps:
- name: Gate 1 - Prompt Review
run: |
# 检查系统prompt中是否有已知的注入模式
# 检查tool description是否有权限越界
python scripts/audit_system_prompt.py --manifest agent_manifest.yaml
- name: Gate 2 - Model Verification
run: |
# 验证模型来自白名单仓库
# 验证模型签名和哈希
cosign verify ${{ env.MODEL_REGISTRY }}/${{ env.MODEL_NAME }}@${{ env.MODEL_DIGEST }}
- name: Gate 3 - Dependency Scan
run: |
# 扫描Python依赖 + LoRA适配器 + 容器镜像
trivy scan --severity HIGH,CRITICAL requirements.txt lora_weights/ container/
- name: Gate 4 - Red Teaming Pipeline
run: |
# 运行四层自动化红队评估
npx promptfoo@latest eval --config .promptfooconfig.yaml
python scripts/check_asr_threshold.py --threshold 0.1
- name: Gate 5 - Permission Declaration
run: |
# 验证权限声明文件格式和合规性
# 对比权限声明 vs 工具定义的实际权限
python scripts/audit_permissions.py --manifest agent_manifest.yaml --threshold l3
- name: ALL GATES PASSED
if: success()
run: echo "Deployment approved"这个pipeline的设计原则:每个gate都独立可运行、有明确的通过标准、有可审计的日志输出。任何gate失败都会阻断部署------就像单元测试失败阻断合并一样。
六、AI安全治理角色与团队组织
安全左移不只是一个技术问题,还是一个组织问题。你需要回答:谁来做安全?
本文把AI安全治理划分为四个角色:
| 角色 | 职责 | 需要什么能力 | 来自哪里 |
|---|---|---|---|
| AI安全工程师 | 搭建和维护安全pipeline(red teaming、模型验证、权限审计) | 安全工程 + ML基础 | 传统安全团队转型 |
| AI红队成员 | 做深度red teaming评估、发现自动化工具覆盖不到的攻击路径 | 安全测试 + prompt engineering | 渗透测试团队 |
| 合规审计员 | 确保流程满足EU AI Act、国内法规等要求 | 合规 + 技术理解 | GRC团队 |
| ML工程师(安全意识) | 写安全的Agent代码、遵循安全规范 | ML开发 + 安全意识 | 开发团队 |
关键组织原则:
- 安全团队不能一个人做完所有事。安全pipeline可以安全团队搭建,但执行应该自动化、嵌入CI/CD,不需要安全团队的日常参与
- ML工程师需要安全培训。就像传统开发需要安全编码培训一样,Agent开发者需要安全Agent开发培训。核心知识点:什么是指令注入、什么是Agentic Gap、什么是最小权限
- 合规不能跟技术脱节。写合规文档的人必须理解技术实现,否则写出来的流程无法执行
七、AI安全成熟度模型
作为系列的最终篇,我把整条攻击面演化线对应到一个5级成熟度模型上:
| 级别 | 名称 | 特征 | 覆盖的攻击层 |
|---|---|---|---|
| L0 混沌 | 无任何安全措施,模型直接从HF拉latest上线 | 所有 | |
| L1 基础 | 有基本的输入过滤 + 拒绝敏感请求 | 输入层:001/002 | |
| L2 系统 | 数据供应链审计 + 模型版本管理 + API防护 | 训练层:003/004 | |
| L3 主动 | Agent最小权限 + HITL + 工具签名 + 审计日志 | 执行层:005 | |
| L4 持续 | 自动化red teaming嵌入CI/CD + 持续安全验证 | 评估层:006 | |
| L5 治理 | ML-SBOM + 声明式权限 + 合规对齐 + 完整治理体系 | 治理层:007 |
这个模型的价值:它把七篇文章的每一层映射到一个可度量的成熟度级别。你可以拿这个表去跟你的团队、你的领导、你的客户对表------"我们现在在L1,目标是下季度到L3"。
一个现实的 roadmap:
-
第1-2周:从L1到L2(做输入过滤 + 模型溯源)
-
第3-8周:从L2到L3(Agent安全加固,最耗时)
-
第9-12周:从L3到L4(搭建自动化red teaming pipeline)
-
第13-16周:从L4到L5(完善治理体系 + 合规对齐)
八、三条Takeaway
8.1 AI安全左移不等于传统DevSecOps
除了将安全检查前移到CI/CD早期阶段,还需要"向下"深入到ML训练/微调/评估的技术栈内部------模型签名、ML-SBOM、数据供应链审计是AI特有的新维度。
8.2 纵深防御串起整条攻击面演化线
从输入层到治理层,每一篇的防御措施都不是独立的------输入净化保护Agent、数据验证保护模型、权限控制缓解注入后果。把七篇的防御组合起来,才能形成真正的安全体系。
8.3 自动化持续验证是AI安全的底线
Agent系统迭代速度远超传统应用,手工评估跟不上。把red teaming嵌入CI/CD,ASR超过阈值即阻断部署------这跟"CI/CD中测试失败阻断发布"是同一个逻辑。
行动建议:
如果你刚开始搭建AI安全体系 :先跑一次审计------你的模型从哪来、有没有签名、上线经过了哪些检查。把结果写在wiki上,这就是你的安全基线。不需要完美,只需要有记录。建立模型来源白名单 + ML-SBOM,就像做一次依赖审计一样,半天就能搞定。
- 如果你在运营Agent生产系统 :把自动化red teaming嵌入CI/CD pipeline。从Promptfoo开始,跑第一/二层评估,ASR阈值设为10%,超过即阻断。记住:第一次跑不是为了阻断,而是为了建立基线。
- 如果你在设计Agent权限体系 :实施Agent权限声明式管理。每个Agent部署前必须附带权限声明文件,审批通过后才能上线。这跟Kubernetes的PodSecurityPolicy是同一个模式 ------权限在部署时声明,不在运行时猜测。
系列结语:
七篇文章,从输入层走到治理层。每一层都在回答同一个问题:当AI从"文本生成器"变成"真实世界执行者",安全体系怎么跟上?
001 Prompt Injection------数据也能变指令
002 Jailbreak------让"不"变成"好"
003 数据投毒------训练供应链的"慢性毒药"
004 模型窃取------你的模型不是你的
005 Agent安全------从只读账户到root shell
006 红队方法论------怎么系统性地找到漏洞
007 安全左移------把安全嵌进流水线
最终答案不是某个单一技术,而是一整套迁移过来的安全方法论:纵深防御 + 最小权限 + 持续验证 + 安全左移。这些概念在传统安全领域已经被验证了二十年,现在轮到它们在AI领域证明自己了。
写这个系列的初衷很简单:AI安全不需要发明新理论,需要的是把老经验迁移到新场景。 作为安全老兵,我看到太多AI项目在重复传统安全十年前犯过的错------上线前不做安全评估给root权限还不审计。不是技术问题,是意识问题。
这个系列没有讲什么惊天动地的新攻击------每一个攻击类型在传统安全里都有原型。Prompt Injection跟SQL注入是同一种思维模式,Agent横向移动跟域渗透是同一种攻击链,供应链投毒跟Log4j是同一个深层问题。
差别在于意识到位的早晚。传统安全花了二十年才把这些概念推向主流,AI安全没有二十年的时间。LLM的攻击面从"说错话"到"做错事"只用了两年,Agent的数量正在指数级增长。
如果你是安全工程师:请带着你的老经验进入AI领域。你会的每一样东西------最小权限、纵深防御、威胁建模、审计日志------在AI场景里都有用。
如果你是ML工程师:请重视安全不是"别人的事"。你的Agent今天没有出问题,不是因为它安全,而是因为还没人专门攻击它。
做AI安全不需要发明新理论,需要的是把老经验迁移到新场景。
参考资料:
-
GitLab (2024). "DevSecOps Survey." 78% of professionals cite AI changing security testing
-
Sigstore / OpenSSF. "Model Transparency: Supply Chain Security for ML." github.com/sigstore/model-transparency
-
OWASP (2025). "Top 10 for LLM Applications 2025."
-
OWASP (2026). "Top 10 for Agentic Applications 2026."
-
ReversingLabs (2025). "Secure Your AI Supply Chain with the ML-BOM."
-
Google Cloud. "Shifting Left on Security: Securing Software Supply Chains."
-
Rapid7. "Shift Left Security: Benefits, Tools & Best Practices."
-
NIST (2024-2025). "AI RMF (Risk Management Framework)."
-
SLSA (Supply-chain Levels for Software Artifacts). "Provenance Attestation for ML Models."
-
Splunk (2025). "Shift Left Security: Adoption Trends."
-
European Commission (2024). "EU AI Act." Regulation (EU) 2024/1689
-
中国国家网信办 (2023-2025). "生成式人工智能服务管理暂行办法."
参考文献: