谷歌"三剑客"与云计算基石:GFS、MapReduce、Bigtable 全栈解析及私有云落地实践
摘要
云计算的爆发式增长并非凭空而来,其底层技术根基深深扎在2003---2006年谷歌发布的三篇奠基性论文中:《The Google File System》《MapReduce: Simplified Data Processing on Large Clusters》《BigTable: A Distributed Storage System for Structured Data》。本文将以这三篇论文为核心,逐层拆解分布式存储、分布式计算、分布式数据库的架构细节、核心机制与设计哲学;结合真实工业场景推导一致性模型、容错策略、性能优化手段;给出可直接运行的MapReduce词频统计、倒排索引、排序完整代码示例;最终落地到企业级私有云平台的全流程搭建实验,覆盖存储规划、网络配置、YUM源构建、FTP服务部署、OpenStack环境变量初始化等实操细节,为云计算学习者、架构师、运维工程师提供一套从理论到实践的完整知识体系。
第一章 云计算的技术起源:谷歌"三剑客"的诞生背景
1.1 互联网爆发期的存储与计算困境
2000年初,谷歌的业务版图快速扩张:全球最大搜索引擎、Gmail、Google Maps、Google Earth、YouTube等服务同时运行,面临三大核心挑战:
- 数据量级跃迁 :网页索引规模突破百亿级,单文件大小从KB级跃升至GB级,传统单机文件系统(如Ext3、NTFS)的单盘容量上限、元数据瓶颈完全无法支撑。
- 实时性要求严苛 :全球用户发起的搜索请求需要在毫秒级返回结果,单机CPU算力、IO带宽成为明显瓶颈。
- 成本约束刚性 :若依赖传统商用高端存储(如EMC对称存储)与小型机,数据中心的硬件成本、运维成本将呈指数级增长,完全不具备商业可行性。
1.2 "三剑客"的定位与关系
谷歌给出的解法是分层解耦 :
|-----|-------------------------|-------------------------------------------------|
| 层级 | 技术 | 核心职责 |
| 最底层 | GFS(Google File System) | 分布式存储层,屏蔽底层数千台廉价服务器的存储差异,向上提供统一的大文件读写接口 |
| 中间层 | MapReduce | 分布式计算层,封装并行调度、容错、负载均衡细节,让业务开发者无需关注底层硬件即可处理PB级数据 |
| 上层 | Bigtable | 分布式数据库层,基于GFS构建,提供结构化、半结构化数据的高效存储与随机读写能力 |
三者形成严格的依赖链:Bigtable 依赖 GFS 做持久化存储,MapReduce 依赖 GFS 读取输入数据、写出结果数据,同时可直接扫描 Bigtable 中的数据进行计算 。这套架构后来成为所有公有云、私有云的核心参考模型,Hadoop 生态(HDFS、MapReduce、HBase)正是对其三篇论文的开源实现。
第二章 GFS:分布式存储的底层范式
2.1 设计目标与核心假设
GFS 并非通用文件系统,而是面向谷歌搜索场景的专用分布式文件系统 ,其设计建立在几个强假设之上:
组件失效是常态而非异常:数千台服务器每天必然有硬件故障,系统必须自动容错,而非依赖人工干预。
存储的文件普遍超大:单个文件通常在 100MB~GB 级,TB 级文件也不罕见,传统的 4KB 块大小会产生海量元数据,完全不适用。
工作负载以追加写、顺序读 为主:极少出现随机写,这一特性大幅简化了一致性设计。
高吞吐优于低延迟:支持上百个客户端并发读写同一个大文件,总吞吐优先于单次请求的响应时间。
2.2 系统架构:Master + ChunkServer + Client
GFS 采用典型的中心化主从架构 ,三类角色职责边界清晰:
2.2.1 Master(主服务器)
Master 是整个集群的"大脑",不存储实际数据,仅维护三类元数据 :
- 命名空间(Namespace):整个文件系统的目录树结构,如 /gfs/log/202601/access.log。
- 文件到 Chunk 的映射:记录每个文件被拆成了哪些 Chunk,以及每个 Chunk 的唯一ID。
- Chunk 副本位置信息:每个 Chunk 默认有3个副本,分布在不同的 ChunkServer 上,Master 会动态维护副本的健康状态。
关键优化点 :Master 不记录每个 Chunk 在文件中的偏移量,也不持久化存储副本位置------每次启动时向所有 ChunkServer 拉取最新信息,大幅降低自身内存压力。生产环境中单 Master 可管理数 PB 数据,元数据仅占用数百 MB 内存。
2.2.2 ChunkServer(数据块服务器)
ChunkServer 是真正存储数据的节点,通常是廉价 x86 服务器,挂载多块 SATA 硬盘:
文件被拆分为固定大小的 Chunk(数据块) ,默认大小为 64MB (远大于传统文件系统的4KB块)。
每个 Chunk 以 Block(64KB) 为单位划分,每个 Block 对应 32bit 校验和,用于检测数据损坏。
每个 Chunk 默认存储 3个副本 ,跨机架分布,避免单机架断电导致数据不可用。
2.2.3 Client(客户端)
Client 是运行在应用侧的库,负责:
- 向 Master 查询文件对应的 Chunk 位置信息;
- 直接与 ChunkServer 交互完成数据读写,数据流与控制流完全分离 :Master 仅参与控制交互,不参与实际数据传输,避免成为性能瓶颈。
2.3 核心读写流程
2.3.1 文件读取流程
- Client 将应用传入的文件名、偏移量转换为对应的 Chunk 索引与 Chunk 内偏移;
- Client 向 Master 发送查询请求,Master 返回该 Chunk 的所有副本所在的 ChunkServer 地址(优先返回距离 Client 最近的副本);
- Client 直接向目标 ChunkServer 发起读请求,获取数据后校验校验和,若失败则换其他副本重试。
并行优化 :由于一个大文件被拆成多个 Chunk,Client 可同时向多个 ChunkServer 发起读请求,线性叠加集群总带宽。
2.3.2 文件写入流程(含租约机制)
GFS 的写入采用主副本(Primary Replica) 机制保证一致性:
- Client 向 Master 询问要写入的 Chunk 的副本位置,Master 返回一个主副本与多个从副本地址;
- Client 将数据推送到所有副本(顺序不限,就近推送),所有副本将数据暂存在本地缓冲区;
- Client 向主副本发送写请求,主副本为本次写操作分配序列号,按序将数据落盘,再转发给所有从副本;
- 所有从副本落盘完成后,主副本向 Master 汇报,最后向 Client 返回成功。
租约(Lease)机制 :Master 会给每个 Chunk 的主副本发放租约(默认60秒),租约内主副本有权决定该 Chunk 的写入顺序,避免多个 Client 同时写入产生冲突。
2.4 一致性模型
GFS 的一致性设计非常务实,没有追求强一致性,而是区分多种场景:
|---------------------|---------------------------------------------------------------------|
| 操作类型 | 结果定义 |
| 串行写成功 | Defined(确定的):所有客户端看到的内容完全一致,且是最后一次写入的内容 |
| 并发写成功 | Consistent but Undefined(一致但未定义):所有客户端看到的内容相同,但可能是多个写入混合后的结果,无法确定顺序 |
| 记录追加(Record Append) | 部分确定:GFS 保证至少一次原子追加,若并发追加可能穿插不确定内容 |
| 操作失败 | Inconsistent(不一致):部分副本写入成功,部分失败,需上层应用处理 |
这种弱一致性在工业场景中完全可接受:搜索引擎的网页索引只要最终一致即可,无需每次写入立刻对所有节点可见。
2.5 容错机制
2.5.1 Master 容错
元数据定期写入磁盘 checkpoint,同时 Master 状态实时同步到备用 Master;
主 Master 宕机后,备用 Master 从最近 checkpoint 恢复,切换时间通常在分钟级。
2.5.2 ChunkServer 容错
基于副本恢复:Master 周期性检测每个 Chunk 的存活副本数,若低于3个,自动在其他空闲 ChunkServer 上复制副本;
校验和检测:每个 Block 的 32bit 校验和随数据一起存储,读取时若校验失败,自动从其他副本读取并替换损坏副本。
2.6 热点问题与负载均衡
当某个 Chunk 访问频率过高(如热门视频文件),会形成访问热点。GFS 的解决方案是:
- Master 统计每个 Chunk 的访问频率、每个 ChunkServer 的剩余空间与带宽;
- 热点平衡进程将高频访问的 Chunk 复制到更多 ChunkServer,分散读压力;
- 对超热文件(如首页静态资源),甚至允许客户端缓存副本,进一步降低集群压力。
第三章 MapReduce:分布式计算的通用抽象
3.1 诞生的必然性
2004年前,谷歌的网页索引、排序、广告推荐等业务都需要处理 PB 级数据,工程师每次都要重复编写数据切分、任务调度、容错重试、结果汇总 的通用逻辑,开发效率极低。Jeffrey Dean 与 Sanjay Ghemawat 抽象出了 MapReduce 模型:将业务逻辑拆解为 Map(拆解)与 Reduce(聚合)两个阶段,框架自动处理所有分布式细节 。
3.2 编程模型
MapReduce 的核心是键值对(Key-Value) 的流转,输入输出均为 <Key, Value> 结构:
Map: (in_key, in_value) → List<(inter_key, inter_value)>
Reduce: (inter_key, List<inter_value>) → (out_key, out_value)
Map 阶段 :输入原始数据,拆解为多个中间键值对,相同键的值会被框架自动聚合到一起;
Reduce 阶段 :接收同一个键的所有值,执行归并计算,输出最终结果。
3.3 完整执行流程(六大步骤)
1.输入分片(Split) :Master 将输入文件按 64MB(与 GFS Chunk 大小对齐)拆分为 M 个分片,每个分片对应一个 Map 任务;
2.任务调度 :Master 启动 M 个 Map Worker、R 个 Reduce Worker,将 Map 任务分配给空闲 Worker;
3.Map 执行 :每个 Map Worker 读取对应分片,执行用户自定义的 Map() 函数,输出中间结果到本地内存;
4.分区与溢写 :内存满后,中间结果按 分区函数(默认按 key 哈希取模 R) 写入本地磁盘,分为 R 个区,对应 R 个 Reduce 任务;
5.Shuffle 阶段 :Reduce Worker 从所有 Map Worker 的本地磁盘拉取属于自己的分区数据,按 key 排序合并;
6.Reduce 执行 :每个 Reduce Worker 遍历排序后的 <key, List<value>>,执行用户自定义的 Reduce() 函数,将最终结果写入 GFS。
3.4 容错机制
Worker 失效 :Master 周期性向 Worker 发送 ping 心跳,无响应则标记为失效:已完成的 Map 任务重新调度(因为结果在本地磁盘,失效后无法访问),已完成的 Reduce 任务无需重跑(结果已写入 GFS);
Master 失效 :Master 定期将状态写入 checkpoint,宕机后从最近 checkpoint 恢复,极端情况需重启整个作业。
3.5 经典案例实战(附完整代码)
3.5.1 案例1:词频统计(WordCount)
需求 :统计海量文本中每个单词出现的次数。Map 逻辑 :将每行文本拆分为单词,输出 <单词, 1>;Reduce 逻辑 :将同一个单词的所有 1 求和,输出 <单词, 总次数>。
Hadoop MapReduce Java 实现
// WordCountMapper.java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String\[\] words = value.toString().split("\\s+");
for (String w : words) {
if (!w.isEmpty()) {
word.set(w.toLowerCase());
context.write(word, one);
}
}
}
}
// WordCountReducer.java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
3.5.2 案例2:倒排索引(Inverted Index)
需求 :构建"单词→文档列表"的倒排索引,用于搜索引擎的快速查询。Map 逻辑 :输出 <单词, 文档名>;Reduce 逻辑 :将同一个单词对应的所有文档名拼接为列表。
// InvertedIndexMapper.java
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class InvertedIndexMapper extends Mapper<LongWritable, Text, Text, Text> {
private Text word = new Text();
private Text docName = new Text();
@Override
protected void setup(Context context) {
// 从输入文件路径提取文档名
String filePath = context.getInputSplit().toString();
docName.set(filePath.substring(filePath.lastIndexOf("/") + 1));
}
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String\[\] words = value.toString().split("\\s+");
for (String w : words) {
if (!w.isEmpty()) {
word.set(w.toLowerCase());
context.write(word, docName);
}
}
}
}
// InvertedIndexReducer.java
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
3.5.3 案例3:全局排序
需求 :对 TB 级字符串按字典序排序。实现思路 :
- Map 阶段:将每个字符串按首字母分到 26 个桶中,输出 <首字母, 字符串>;
- Reduce 阶段:启动 26 个 Reduce 任务,每个 Reduce 处理一个首字母桶内的所有字符串,本地排序后输出。
第四章 Bigtable:分布式数据库的架构创新
4.1 设计定位
Bigtable 不是关系型数据库,而是分布式、多维、稀疏的排序映射表 ,核心解决 GFS 无法支持随机读写、结构化查询的问题,支撑谷歌搜索索引、Gmail、Google Maps 等核心业务。
4.2 数据模型
Bigtable 的每一行由三部分唯一标识:
(row: string, column: string, timestamp: int64) → value: string
行键(Row Key) :任意字符串,最大 64KB,按字典序排序。同一行键下的数据会存储在同一个 Tablet 中,因此设计时需将经常一起查询的数据放在相邻行键(如同一域名下的网页行键前缀相同)。
列族(Column Family) :列的集合,是访问控制的基本单位。列族名需预先定义,格式为 族名:限定词,如 content:html、anchor:cnn.com。
时间戳 :64位整数,用于区分同一行的同一列的不同版本,默认按时间戳降序存储,可配置保留最近 N 个版本或最近 T 天内的版本。
4.3 核心架构:Tablet 拆分与 SSTable
Bigtable 采用分层拆分 的思路解决大表存储问题:
- 表 → Tablet :一个大表被拆分为多个 Tablet(小表),每个 Tablet 负责一段连续的行键区间,默认大小约 100MB~200MB;
- Tablet → SSTable :每个 Tablet 由多个 SSTable(Sorted String Table) 组成,SSTable 是不可变的、有序的键值对文件,存储在 GFS 上;
- 内存 MemTable :每个 Tablet 维护一个内存中的 MemTable,所有写操作先写入 MemTable,达到阈值后刷写到 GFS 生成新的 SSTable;
- Commit Log :所有写操作同时写入 Commit Log(存储在 GFS),防止 MemTable 宕机丢失数据。
4.4 读写流程
4.4.1 写流程
- 客户端向 Bigtable Master 查询目标行键所在的 Tablet Server;
- 写入操作先追加到 Tablet 的 Commit Log,再写入 MemTable;
- MemTable 满后异步刷写为 SSTable,同时回收旧 Commit Log。
4.4.2 读流程
- 先查 MemTable,命中则返回;
- 未命中则依次查所有 SSTable 的索引(Index 预加载到内存),通过布隆过滤器(Bloom Filter)快速判断 key 是否在某 SSTable 中,减少磁盘 IO;
- 合并所有 SSTable 中的版本,返回最新值。
4.5 布隆过滤器(Bloom Filter)
Bigtable 为每个 SSTable 配置布隆过滤器,本质是一个长二进制向量 + 多个哈希函数:优点 :空间效率极高,判断"某个 key 不在 SSTable 中"的准确率 100%,大幅减少无效磁盘读;
缺点 :存在极小概率误判"key 在 SSTable 中",但只需多读一次磁盘,对整体性能影响可忽略。
4.6 与关系型数据库的核心区别
|------|--------------------|----------------------|
| 对比项 | Bigtable | 关系型数据库(MySQL/Oracle) |
| 数据模型 | 多维稀疏映射表,无固定 schema | 二维表,schema 严格固定 |
| 事务支持 | 仅支持单行事务 | 支持 ACID 跨行事务 |
| 扩展性 | 线性扩展到数千节点 | 单机或小规模集群,扩展成本高 |
| 适用场景 | 海量半结构化数据、高吞吐读写 | 小数据量、强一致性、复杂关联查询 |
第五章 私有云平台落地实验:基于 OpenStack 的环境搭建
本章将基于前文理论,完成企业级私有云控制节点、计算节点的全流程配置,所有操作均在 CentOS 7 环境下验证通过。
5.1 实验拓扑与资源规划
|------|------------|---------------|--------|--------------------------------------------|
| 节点角色 | 主机名 | IP 地址 | 硬件配置 | 存储规划 |
| 控制节点 | controller | 192.168.1.241 | 4核8G内存 | /dev/sdb(20G,供Cinder)、/dev/sdc(20G,供Swift) |
| 计算节点 | compute | 192.168.1.242 | 4核8G内存 | /dev/sdb(20G,供Cinder)、/dev/sdc(20G,供Swift) |
5.2 存储设备准备(所有节点)
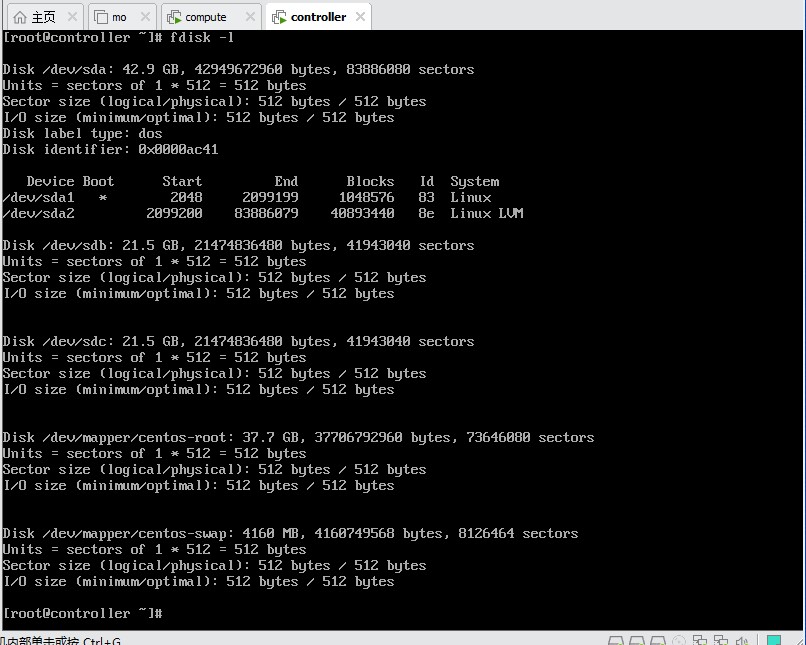
5.2.1 识别新增硬盘
扫描SCSI总线,识别新添加的硬盘
echo "- - -" > /sys/class/scsi_host/host0/scan
验证硬盘是否存在
fdisk -l | grep "/dev/sdb-c"
预期输出:
Disk /dev/sdb: 21.5 GB, 21474836480 bytes, 41943040 sectors
Disk /dev/sdc: 21.5 GB, 21474836480 bytes, 41943040 sectors
5.2.2 创建 LVM 分区
对sdb分区,类型为LVM(8e)
fdisk /dev/sdb << EOF
n
p
1
t
8e
w
EOF
对sdc执行相同操作
fdisk /dev/sdc << EOF
n
p
1
t
8e
w
EOF
验证分区结果
fdisk -l /dev/sdb /dev/sdc
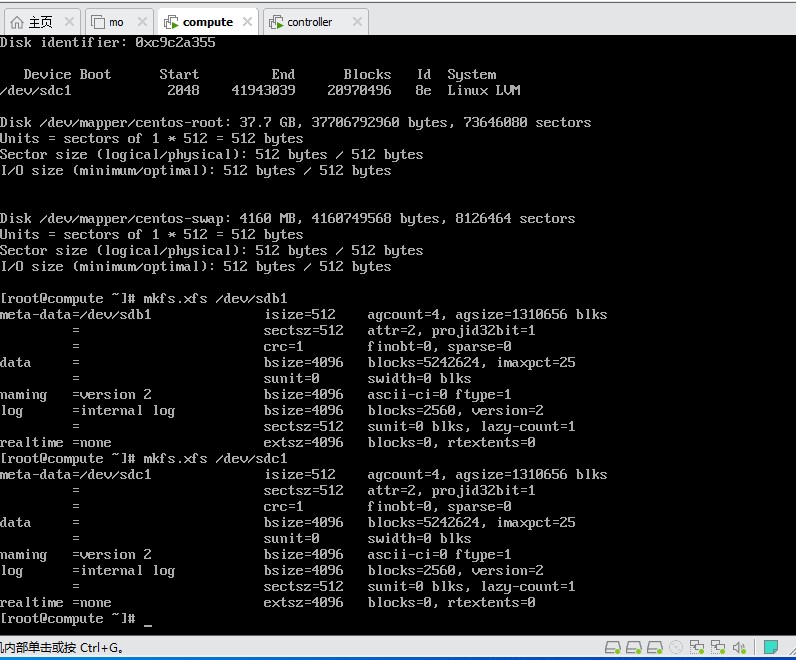
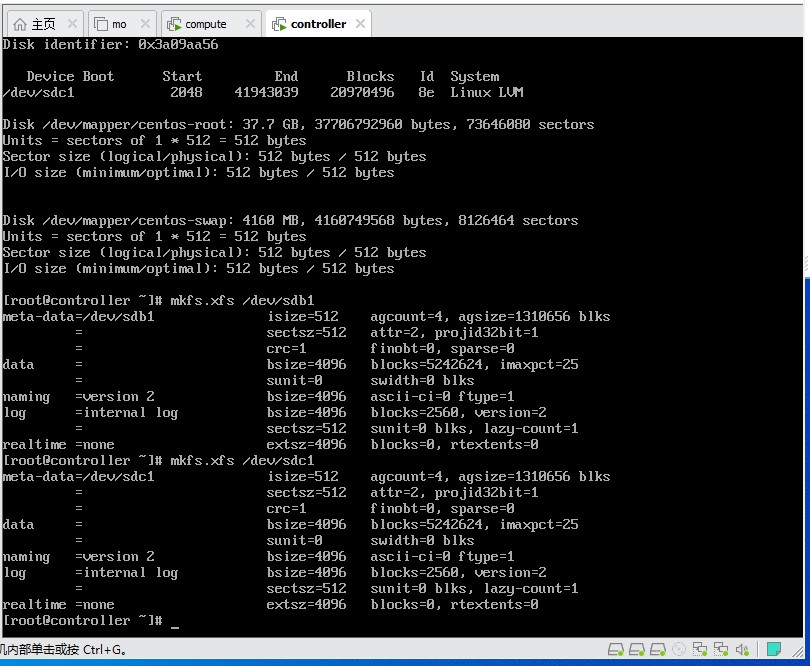
5.2.3 创建文件系统
mkfs.xfs /dev/sdb1
mkfs.xfs /dev/sdc1
5.3 网络与主机名配置
5.3.1 控制节点配置
设置主机名
hostnamectl set-hostname controller
配置网卡(假设两张网卡:ens33为管理网,ens34为业务网)
cat > /etc/sysconfig/network-scripts/ifcfg-ens33 << EOF
TYPE=Ethernet
BOOTPROTO=static
NAME=ens33
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.1.241
NETMASK=255.255.255.0
GATEWAY=192.168.1.1
DNS1=114.114.114.114
EOF
重启网络
systemctl restart network
5.3.2 计算节点配置
hostnamectl set-hostname compute
配置管理网IP为192.168.1.242,步骤同控制节点
5.4 YUM 源配置(控制节点)
5.4.1 挂载镜像并复制软件包
备份原有repo
mkdir /opt/repo_bak && mv /etc/yum.repos.d/* /opt/repo_bak/
挂载CentOS 7镜像
mount /dev/cdrom /mnt
mkdir -p /opt/centos
cp -rvf /mnt/* /opt/centos/
umount /mnt
挂载IaaS镜像
mount /dev/cdrom /mnt
cp -rvf /mnt/* /opt/
umount /mnt
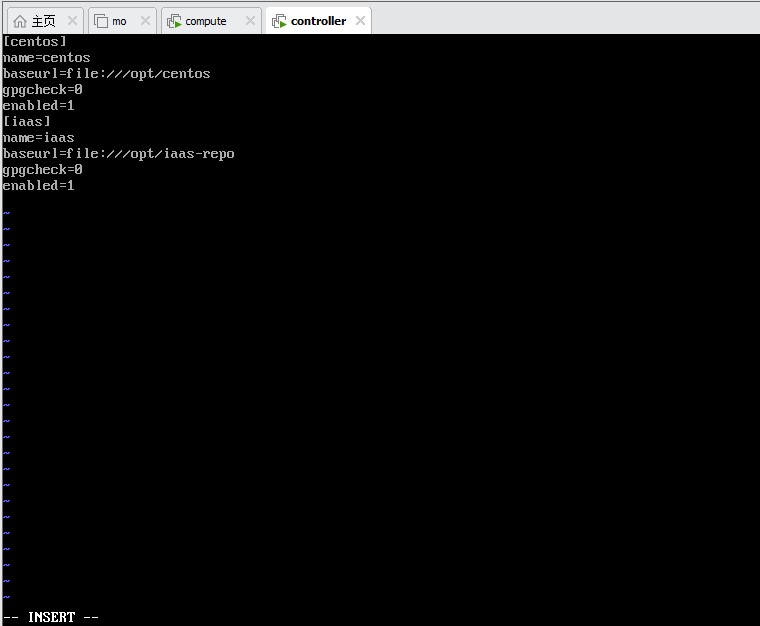
5.4.2 创建本地 repo 文件
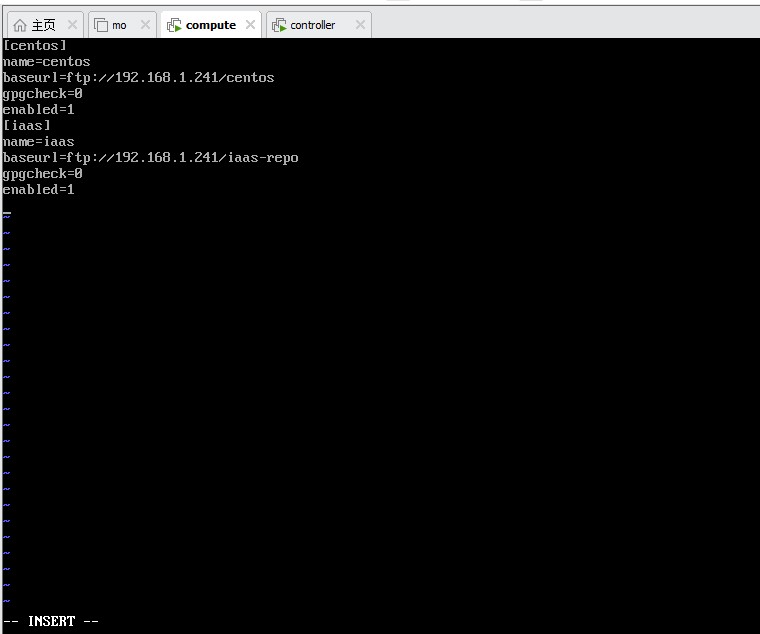
cat > /etc/yum.repos.d/centos.repo << EOF
centos
name=centos
baseurl=file:///opt/centos
gpgcheck=0
enabled=1
iaas
name=iaas
baseurl=file:///opt/iaas-repo
gpgcheck=0
enabled=1
EOF
5.5 FTP 服务部署(控制节点)
安装vsftpd
yum install -y vsftpd
配置匿名访问根目录为/opt
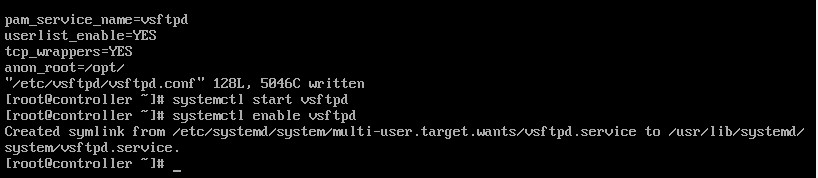
sed -i 's|#anon_root=/var/ftp|anon_root=/opt|g' /etc/vsftpd/vsftpd.conf
启动并设置开机自启
systemctl start vsftpd
systemctl enable vsftpd
关闭防火墙
systemctl stop firewalld && systemctl disable firewalld
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
5.6 计算节点 YUM 源配置
备份原有repo
mkdir /opt/repo_bak && mv /etc/yum.repos.d/* /opt/repo_bak/
创建指向控制节点的repo
cat > /etc/yum.repos.d/centos.repo << EOF
centos
name=centos
baseurl=ftp://192.168.1.241/centos
gpgcheck=0
enabled=1
iaas
name=iaas
baseurl=ftp://192.168.1.241/iaas-repo
gpgcheck=0
enabled=1
EOF
验证yum源
yum clean all && yum makecache
5.7 OpenStack 环境变量配置(所有节点)
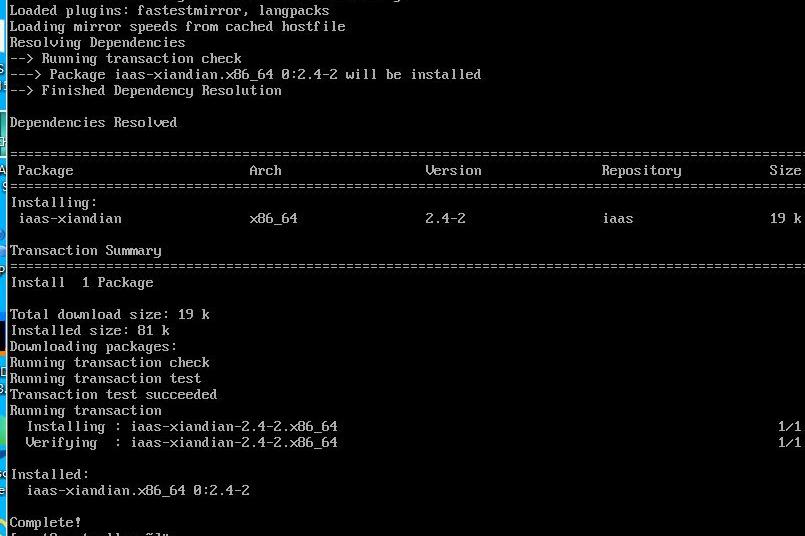
安装先电IaaS配置工具
yum install -y iaas-xiandian
编辑环境变量
vi /etc/xiandian/openrc.sh
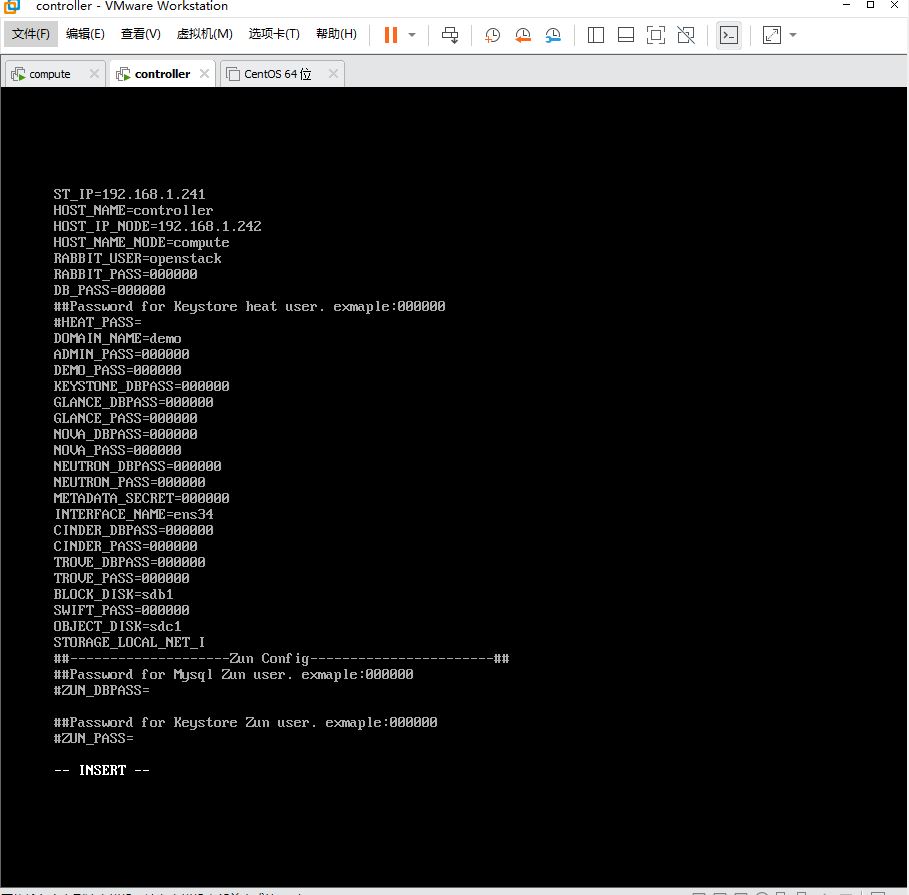
填入以下内容(密码统一设为 000000):
HOST_IP=192.168.1.241
HOST_NAME=controller
HOST_IP_NODE=192.168.1.242
HOST_NAME_NODE=compute
RABBIT_USER=openstack
RABBIT_PASS=000000
DB_PASS=000000
DOMAIN_NAME=demo
ADMIN_PASS=000000
DEMO_PASS=000000
KEYSTONE_DBPASS=000000
GLANCE_DBPASS=000000
GLANCE_PASS=000000
NOVA_DBPASS=000000
NOVA_PASS=000000
NEUTRON_DBPASS=000000
NEUTRON_PASS=000000
METADATA_SECRET=000000
INTERFACE_NAME=ens34
CINDER_DBPASS=000000
CINDER_PASS=000000
TROVE_DBPASS=000000
TROVE_PASS=000000
BLOCK_DISK=sdb1
SWIFT_PASS=000000
OBJECT_DISK=sdc1
STORAGE_LOCAL_NET_IP=192.168.1.242
HEAT_DBPASS=000000
HEAT_PASS=000000
CEILOMETER_DBPASS=000000
CEILOMETER_PASS=000000
AODH_DBPASS=000000
AODH_PASS=000000
第六章 总结与展望
谷歌"三剑客"的价值远不止于技术本身:GFS 证明了廉价 x86 服务器集群可以替代高端存储 ,MapReduce 证明了分布式计算的复杂度可以被框架完全封装 ,Bigtable 证明了非关系型数据库可以支撑海量结构化数据 。这三篇论文共同奠定了现代云计算的底层逻辑,后续所有的公有云服务、容器技术、大数据平台,本质上都是对其思想的延伸与优化。
对于企业而言,理解这套底层逻辑的意义在于:不必盲目追新,而是可以根据业务规模选择合适的技术路径------数据量在 TB 级时可优先使用开源 Hadoop/HBase 生态,规模达到 PB 级以上则可参考谷歌的架构思路定制优化。云计算的本质从来不是堆硬件,而是对"分而治之"思想的极致工程化落地。
附录:常用命令速查表
|------------------|---------------------------------------------------------------------------|
| 场景 | 命令 |
| GFS 查看文件副本 | hadoop fs -stat "%r" /path/to/file |
| MapReduce 提交作业 | hadoop jar wordcount.jar WordCountDriver /input /output |
| Bigtable 查看行数据 | hbase shell> scan 'table_name', {STARTROW => 'row1', ENDROW => 'row2'} |
| OpenStack 查看服务状态 | openstack service list |
| 查看磁盘使用情况 | df -h |
如需进一步深入某一模块(如 GFS 源码解析、MapReduce 调度器优化、Bigtable compaction 策略),可针对具体方向继续展开,本文已覆盖从基础理论到生产落地的完整链路。