1 概念
在并发编程领域,Go语言以其优雅的goroutine和channel设计脱颖而出。但你是否曾好奇,为什么Go能轻松创建百万级goroutine而不会导致系统崩溃?这背后的秘密正是GMP调度模型------Go语言并发能力的核心引擎。
本文基于对Go runtime源码的深入分析,为你系统解析GMP的工作原理、设计哲学和实际应用。
1.1 线程
在深入GMP之前,先思考一个根本问题:传统的线程模型为何在高并发下力不从心
- 线程之重:操作系统线程是内核调度的基本单位,其创建、销毁、切换都涉及内核态与用户态的频繁切换(上下文切换),每次切换都需要保存/恢复大量寄存器状态,成本高昂。更重要的是,每个线程需要预留较大的栈空间(通常MB级别),当线程数量增多时,内存消耗成为瓶颈。
- 阻塞之痛:考虑一个简单的网络服务场景 ------ 使用线程池处理请求。当某个线程因等待I/O(如数据库查询、远程调用)而阻塞时,这个线程占用的系统资源(内存、内核数据结构)被白白闲置。而CPU却可能因活跃线程数不足而无法充分利用
cpp
// 传统多线程模型的伪代码示意
void handle_request(request req) {
data = query_database(req); // 阻塞点!线程在此挂起
process(data);
send_response();
}此时,操作系统调度器会切换到其他就绪线程,但线程本身的资源并未释放。当阻塞的请求过多,线程池被耗尽,新请求只能排队等待。
1.2 协程(Coroutine)
因此,协程作为用户态的轻量级解决方案应运而生。**协程(Coroutine)**的核心理念是将调度权从内核收回用户态。协程是更轻量的执行单元,由程序自身而非操作系统内核负责调度。
关键改进:
- 栈空间小:初始仅KB级别,且可动态增长
- 切换成本低:只需保存少量用户态寄存器,不涉及内核态切换
- 调度灵活:应用程序可根据自身逻辑优化调度策略
然而,原生协程库(如C++的libco、Python的gevent)通常面临一个挑战:调度与运行时系统的整合。程序员需要手动管理协程的调度点(yield),且协程与语言的其他组件(如内存分配器、I/O库)往往存在适配隔阂。
如果你想尝试着使用 c++ 效仿 gmp 实现一套协程调度体系,虽然还原出了其中大部分功能,但在使用上还是存在一个很大的缺陷c++ 标准库中的并发工具(如 lock、semaphore 等)对应的阻塞粒度都是 thread 级别的,这就导致一个协程(coroutine)的阻塞会上升到线程(thread)级别,并导致其他 coroutine 也丧失被执行的机会.
1.3 goroutine
Go语言没有选择暴露原始的"协程"概念,而是创造了goroutine 这一更高层次的抽象,并将其与一套完整的运行时系统深度集成。goroutine不是孤立的,它是GMP体系的有机组成部分。
Gorutine核心优势(相较于传统协程):
- 自动栈管理:栈空间可动态扩展。开始时很小,根据需要自动扩容,无需用户干预
- 深度集成调度:创建、阻塞、唤醒、销毁全由运行时管理,用户只需go func()
- 统一并发语义:Go中所有的并发操作(channel、锁、定时器、网络I/O)最终都转换为goroutine调度事件,实现了并发模型统一
1.4 goroutine调度器

线程与协程N:1或者是1:1的关系都无法体现协程的更大的优越性。
- 线程与协程1:1的关系,其实就等同于多线程的模型,切换协程与切换线程无异,代价昂贵
- 线程与协程1:N的关系,则无法利用到多个CPU,从属同一个内核级线程,无法并行;一个协程阻塞会导致从属同一线程的所有协程无法执行。
GMP模型的精髓也在于此,使用线程与协程M:N的对应关系。可利用多个线程,实现并行,通过调度器的斡旋,实现和线程间的动态绑定和灵活调度。
实际上,"灵活调度" 一词概括得实在过于简要,Golang 在调度 goroutine 时,针对"如何减少加锁行为","如何避免资源不均"等问题都给出了精彩的解决方案,这一切都得益于经典的 "gmp" 模型,而这些,我们接下来进行一一的介绍
2 GMP三大核心组件
GMP不是三个独立概念的拼接,而是一个相互依存、协同工作的有机整体。
2.1 G(Goroutine)
- g即是goroutine,是golang中对协程的抽象
- g有自己的运行栈、状态、以及执行的函数任务(用户通过go func指定)
- g需要绑定p才能执行,在g视角中,p就是它的cpu
我们通过源码来一探究竟:
Go
// 一个 goroutine 的具象类
type g struct{
// g 的执行栈空间
stack stack
/*
栈空间保护区边界,用于探测是否执行栈扩容
在 g 超时抢占过程中,用于传递抢占标识
*/
stackguard0 uintptr
// ...
// 记录 g 执行过程中遇到的异常
_panic *_panic
// g 中挂载的 defer 函数,是一个 LIFO 的链表结构
_defer *_defer
// g 从属的 m
m *m
// ...
atomicstatus uint32
// ...
// 进入全局队列 grq 时指向相邻 g 的 next 指针
schedlink guintptr
// ...
}主要包括以下字段:
- stack:g的栈空间
- stackguard0:栈空间保护区边界,同时也承担了传递抢占标识的作用
- panic:g运行函数中发送的panic
- defer:g运行函数中创建的defer操作(以LIFO次序组织)
- m:正在执行g的m(若g部位running状态,则此字段为空)
- atomicstatus:g的生命周期状态
- _Gidle = iota:刚被分配未初始化
- _Grunnable:就绪态,可以被调度
- _Grunning:正在被调度运行过程
- _Gsyscall:正在执行系统调用
- _Gwaiting:g处于阻塞态,需要等待其他外部条件成立后,才重新恢复成就绪态
- _Gdead:生死本是一个轮回. 当 g 调度结束生命终结,或者刚被初始化准备迎接新生前,都会处于此状态
2.2 M(Machine)
- m即machine,是golang中对线程的抽象
- m不直接执行g,而是先和p绑定,由其实现代理
- 借由p的存在,m无需和g绑死,也无需记录g的状态,因此g在全生命周期可以跨m执行。这也是gmp精髓所在
Go
type m struct{
// 用于调度普通 g 的特殊 g,与每个 m 一一对应
g0 *g
// ...
// m 的唯一 id
procid uint64
// 用于处理信号的特殊 g,与每个 m 一一对应
gsignal *g
// ...
// m 上正在运行的 g
curg *g
// m 关联的 p
p puintptr
// ...
// 进入 schedt midle 链表时指向相邻 m 的 next 指针
schedlink muintptr
// ...
}核心成员主要包括:
- g0:执行调度流程的特殊的g(不由用户创建,是与m一对一伴生的特殊的g,为m寻找合适的普通的g用于执行)
- gsignal:执行信号处理的特殊g(不由用户创建,是与m一对一伴生的特殊的g,处理分配给m的signal)
- curg:m上正在执行的普通g(由用户通过go func()(...)操作创建)
- p:当前与m结合的p
我们先不考虑gsignal,可以将m的运行模板分为g0和g,两者是时钟交替进行的:g0不断的调度g到响应的m进行执行任务,g执行完任务又把执行权交给g0,循环往复。
2.3 P(Processor)
- p即processor,是golang的调度器
- p是gmp的中枢,借由p承上启下,实现g和m之间的动态有机结合
- 对于g而已,p是其cpu,g只有被p调度才得以执行
- 对于m而言,p是其执行代理,为其提供必要信息的同时(可执行的g、内存分配情况等),并隐藏了繁杂的调度细节
- p的数量决定了g最大并行数量,可由用户通过GOMAXPROCS进行设定(超过CPU核数时无意义)
Go
type p struct{
id int32
/*
p 的状态
// p 因缺少 g 而进入空闲模式,此时会被添加到全局的 idle p 队列中
_Pidle = iota // 0
// p 正在运行中,被 m 所持有,可能在运行普通 g,也可能在运行 g0
_Prunning // 1
// p 所关联的 m 正在执行系统调用. 此时 p 可能被窃取并与其他 m 关联
_Psyscall // 2
// p 已被终止
_Pdead // 4
*/
status uint32// one of pidle/prunning/...
// 进入 schedt pidle 链表时指向相邻 p 的 next 指针
link puintptr
// ...
// p 所关联的 m. 若 p 为 idle 状态,可能为 nil
m muintptr // back-link to associated m (nil if idle)
// lrq 的队首
runqhead uint32
// lrq 的队尾
runqtail uint32
// q 的本地 g 队列------lrq
runq [256]guintptr
// 下一个调度的 g. 可以理解为 lrq 中的特等席
runnext guintptr
// ...
}- status:p生命周期状态
- m:当前于p结合的m
- runq:p私有的g队列 ------ local run queue,简称lrq
- runqhead:lrq中队首节点索引
- runqtail:lrq中队尾节点索引
- runnext:lrq中的特定席,指向下一个即将指向的g
2.4 schedt
schedt 是全局共享的资源模块,在访问前需要加全局锁:
Go
// 全局调度模块
type schedt struct{
// ...
// 互斥锁
lock mutex
// 空闲 m 队列
midle muintptr // idle m's waiting for work
// ...
// 空闲 p 队列
pidle puintptr // idle p's
// ...
// 全局 g 队列------grq
runq gQueue
// grq 中存量 g 的个数
runqsize int32
// ...
}- lock:全局维度的互斥锁
- midle:空闲m队列
- pidle:空闲p队列
- runq:全局g队列------global run queue,简称grq
- runqsize:grq中存在的g个数
之所以存在 midle 和 pidle 的设计,就是为了避免 p 和 m 因缺少 g 而导致 cpu 空转. 对于空闲的 p 和 m,会被集成到空闲队列中,并且会暂停 m 的运行
3 调度原理
3.1 goroutine的诞生
1)main
M0是启动程序后的编号为0的主线程,这个M对应的实例会在全局变量runtime.m0中,不需要在heap上分配,M0负责执行初始化操作和启动第一个G, 在之后M0就和其他的M一样了。
main 函数作为整个 go 程序的入口是比较特殊的存在,它是由 go 程序全局唯一的 m0(main thread)执行的,对应源码位于 runtime.proc.go:
Go
//go:linkname main_main main.main
func main_main()
// The main goroutine.
func main(){
// ...
// 获取用户声明的 main 函数
fn := main_main
// 执行用户声明的 main 函数
fn()
// ...
}2)普通的g
除了main这个函数之外,当用户执行go func(){...}时,都会以 g 的形式进入到 gmp 架构当中,runtime会:
Go
func newproc(fn *funcval) {
gp := getg() // 获取当前g
systemstack(func() {
newg := newproc1(fn, gp, pc) // 创建新goroutine
_p_ := getg().m.p.ptr()
// 优先放入当前P的LRQ
if runqput(_p_, newg, true) {
return
}
// LRQ满了则放入GRQ
runqputslow(_p_, newg)
})
}创建策略遵循"就近原则":优先放入当前P的LRQ,满了再放入GRQ。
3.2 调度循环:g0的使命
G0是每次启动一个M都会第一个创建的gourtine ,G0仅用于负责调度的G,G0不指向任何可执行的函数, 每个M都会有一个自己的G0。在调度或系统调用时会使用G0的栈空间, 全局变量的G0是M0的G0。
每个M都在g0和普通g之间不断切换:
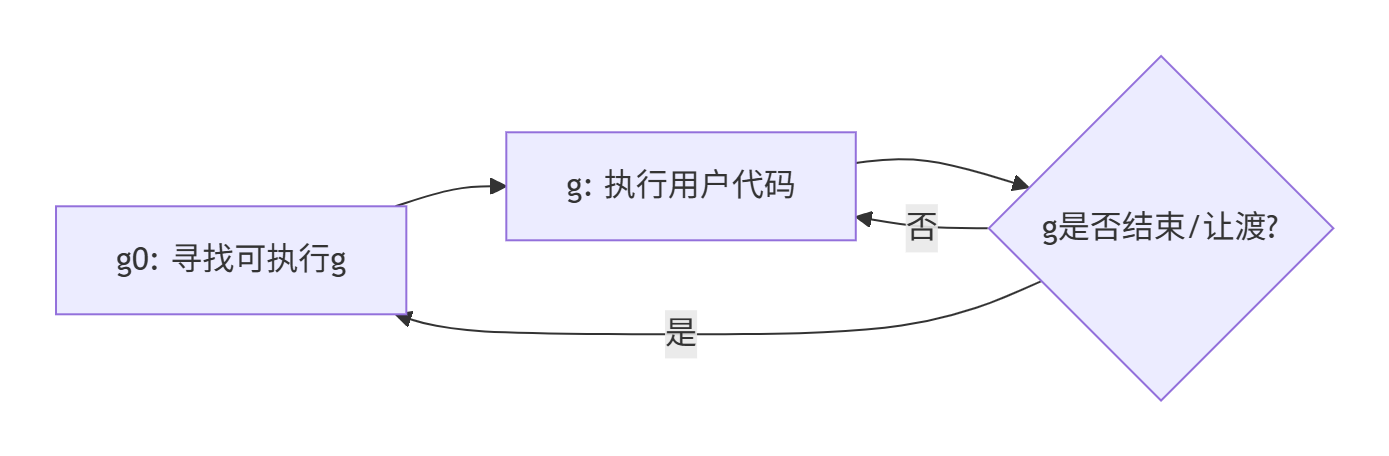
g0->g 的调度逻辑在schedule()函数中:
Go
// 执行方为 g0
func schedule(){
// 获取当前 g0
_g_ := getg()
// ...
top:
// 获取当前 p
pp := _g_.m.p.ptr()
// ...
/*
核心方法:获取需要调度的 g
- 按照优先级,依次取本地队列 lrq、取全局队列 grq、执行 netpoll、窃取其他 p lrq
- 若没有合适 g,则将 p 和 m block 住并添加到空闲队列中
*/
gp, inheritTime, tryWakeP := findRunnable()// blocks until work is available
// ...
// 执行 g,该方法中会将执行权由 g0 -> g
execute(gp, inheritTime)
}
// 执行给定的 g. 当前执行方还是 g0,但会通过 gogo 方法切换至 gp
func execute(gp *g, inheritTime bool){
// 获取 g0
_g_ := getg()
// ...
/*
建立 m 和 gp 的关系
1)将 m 中的 curg 字段指向 gp
2)将 gp 的 m 字段指向当前 m
*/
_g_.m.curg = gp
gp.m = _g_.m
// 更新 gp 状态 runnable -> running
casgstatus(gp,_Grunnable,_Grunning)
// ...
// 设置 gp 的栈空间保护区边界
gp.stackguard0 = gp.stack.lo +_StackGuard
// ...
// 执行 gogo 方法,m 执行权会切换至 gp
gogo(&gp.sched)
}- schedule:调用 findRunnable 方法,获取到可执行的 g
- execute:更新 g 的上下文信息,调用 gogo 方法,将 m 的执行权由 g0 切换到 g
g -> g0:mcall、systemstack
Go
// 从 g 切换至 g0 执行. 只允许在 g 中调用
func mcall(fn func(*g))
// 在普通 g 中调用时,会切换至 g0 压栈执行 fn,执行完成后切回到 g
func systemstack(fn func())3.3 四级调度策略
在调度流程中,最核心的步骤就在,findRunnable 方法中如何按照指定的策略获取到可执行的 g.
Go
// 获取可用于执行的 g. 如果该方法返回了,则一定已经找到了目标 g.
func findRunnable()(gp *g, inheritTime, tryWakeP bool){
// 获取当前执行 p 下的 g0
_g_ := getg()
// ...
top:
// 获取 p
_p_ := _g_.m.p.ptr()
// ...
// 每 61 次调度,需要尝试处理一次全局队列 (防止饥饿)
if _p_.schedtick%61==0&& sched.runqsize >0{
lock(&sched.lock)
gp = globrunqget(_p_,1)
unlock(&sched.lock)
if gp !=nil{
return gp,false,false
}
}
// ...
// 尝试从本地队列 lrq 中获取 g
if gp, inheritTime := runqget(_p_); gp !=nil{
return gp, inheritTime,false
}
// 尝试从全局队列 grq 中获取 g
if sched.runqsize !=0{
lock(&sched.lock)
gp := globrunqget(_p_,0)
unlock(&sched.lock)
if gp !=nil{
return gp,false,false
}
}
// 执行 netpoll 流程,尝试批量唤醒 io 就绪的 g 并获取首个用以调度
if netpollinited()&& atomic.Load(&netpollWaiters)>0&& atomic.Load64(&sched.lastpoll)!=0{
if list := netpoll(0);!list.empty(){// non-blocking
gp := list.pop()
injectglist(&list)
casgstatus(gp,_Gwaiting,_Grunnable)
// ...
return gp,false,false
}
}
// ...
// 从其他 p 的 lrq 中窃取 g
gp, inheritTime, tnow, w, newWork := stealWork(now)
if gp !=nil{
return gp, inheritTime,false
}
// 若存在 gc 并发标记任务,则以 idle 模式参与协作,好过直接回收 p
// ...
// 加全局锁,并 double check 全局队列是否有 g
lock(&sched.lock)
// ...
if sched.runqsize !=0{
gp := globrunqget(_p_,0)
unlock(&sched.lock)
return gp,false,false
}
// ...
// 确认当前 p 无事可做,则将 p 和 m 解绑,并将其添加到全局调度模块 schedt 中的空闲 p 队列 pidle 中
// 解除 m 和 p 的关系
releasep()
// 将 p 添加到 schedt.pidle 中
now = pidleput(_p_, now)
unlock(&sched.lock)
// ...
// 在 block 当前 m 之前,保证全局存在一个 m 留守下来,以阻塞模式执行 netpoll,保证有 io 就绪事件发生时,能被第一时间处理
if netpollinited()&&(atomic.Load(&netpollWaiters)>0|| pollUntil !=0)&& atomic.Xchg64(&sched.lastpoll,0)!=0{
atomic.Store64(&sched.pollUntil,uint64(pollUntil))
// ...
// 以阻塞模式执行 netpoll 流程
delay :=int64(-1)
// ...
list := netpoll(delay)// block until new work is available
// 恢复 lastpoll 标识
atomic.Store64(&sched.lastpoll,uint64(now))
// ...
lock(&sched.lock)
// 从 schedt 的空闲 p 队列 pidle 中获取一个空闲 p
_p_, _ = pidleget(now)
unlock(&sched.lock)
// 若没有获取到 p,则将就绪的 g 都添加到全局队列 grq 中
if _p_ ==nil{
injectglist(&list)
}else{
// m 与 p 结合
acquirep(_p_)
// 将首个 g 直接用于调度,其余的添加到全局队列 grq
if!list.empty(){
gp := list.pop()
injectglist(&list)
casgstatus(gp,_Gwaiting,_Grunnable)
// ...
return gp,false,false
}
// ...
goto top
}
}
// ...
// 走到此处仍然未找到合适的 g 用于调度,则需要将 m block 住,添加到 schedt 的 midle 中
stopm()
goto top
}- 每经历61次调度后,需要先处理一次全局队列grp(globrunqget------加锁),避免产生饥饿
- 尝试从本地队列lrq获取g(runqget ------ CAS无锁)
- 尝试从全局队列获取g(globrunqget ------ 加锁)
- 尝试获取io就绪的g(netpoll------非阻塞模式)
- 尝试从其他p的lrq窃取(stealwork)
- 一次窃取目标P本地队列的一半任务,平衡负载
- double check 一次 grq(globrunqget------加锁)
- 若没找到g,将p置为idle状态,添加到schedt pidle队列(动态缩容)
- 确保留守一个m,监听处理io就绪的g(netpoll ------ 阻塞模式)
- 若m仍无事可做,增将其添加到schedt midle队列(动态缩容)
- 暂停m(回收资源)
4 让渡设计
在GMP调度模型中,"让渡"指的是goroutine主动交出执行权 ,从运行状态(_Grunning)切换回调度状态的过程。这是协作式调度的重要体现,与"抢占"(外部强制中断)形成对比。
4.1 正常结束
当goroutine执行完用户函数后,会触发正常的结束让渡流程:

Go
// 此时执行方是普通g
func goexit1() {
// 通过mcall,将执行方转为g0,调用goexit0方法
mcall(goexit0)
}
// 此时执行方为g0,入参gp为已经运行结束的g
func goexit0(gp *g) {
_g_ := getg() // 获取g0
_p_ := _g_.m.p.ptr() // 获取对应的p
// 将gp的状态由running更新为dead
casgstatus(gp, _Grunning, _Gdead)
// 清空gp的数据
gp.m = nil
gp._defer = nil
gp._panic = nil
// 将g和m解除关系
dropg()
// 将g添加到p的gfree队列中(复用池)
gfput(_p_, gp)
// 发起新一轮调度
schedule()
}首先,g 在运行结束时会调用 goexit1 方法中,并通过 mcall 指令切换至 g0,由 g0 调用 goexit0 方法,并由 g0 执行下述步骤:
- 将g状态由running更新为dead
- 清空g中的数据
- 解除g与m的关系
- 将g添加到p的gfree队列以供复用
- 调用schedule方法发起新一轮的调度
4.2 主动让渡
用户可以通过调用runtime.Gosched()主动让出CPU:

Go
// 主动让渡出执行权,此时执行方还是普通g
func Gosched() {
// 通过mcall,将执行方转为g0,调用gosched_m方法
mcall(gosched_m)
}
// 此时执行方为g0
func gosched_m(gp *g) {
goschedImpl(gp)
}
func goschedImpl(gp *g) {
// 将g状态由running改为runnable就绪态
casgstatus(gp, _Grunning, _Grunnable)
// 解除g和m的关系
dropg()
// 将g添加到全局队列grq
lock(&sched.lock)
globrunqput(gp)
unlock(&sched.lock)
// 发起新一轮调度
schedule()
}- 将g由running改为runable状态
- 解除g和m的关系
- 将g直接添加到全局队列grq中
- 调用schedule方法发起新一轮调度
4.3 阻塞让渡
当goroutine需要等待某个条件(如channel通信、锁、定时器)时,会触发阻塞让渡:
Go
// 此时执行方为普通g
func gopark(unlockf func(*g, unsafe.Pointer) bool,
lock unsafe.Pointer, reason waitReason) {
gp := mp.curg // 获取要阻塞让渡的g
// 通过mcall,将执行方由普通g -> g0
mcall(park_m)
}
// 此时执行方为g0,入参gp为需要执行park的普通g
func park_m(gp *g) {
_g_ := getg() // 获取g0
// 将gp状态由running变更为waiting
casgstatus(gp, _Grunning, _Gwaiting)
// 解绑g与m的关系
dropg()
// g0发起新一轮调度流程
schedule()
}与 gopark 相对的,是用于唤醒 g 的 goready 方法,其中会通过 systemstack 压栈切换至 g0 执行 ready 方法------将目标 g 状态由 waiting 改为 runnable,然后添加到就绪队列中.
Go
// 此时执行方为普通g,入参gp为需要唤醒的另一个普通g
func goready(gp *g, traceskip int) {
// 切换到g0执行ready方法
systemstack(func() {
ready(gp, traceskip, true)
})
}
// 此时执行方为g0,入参gp为拟唤醒的普通g
func ready(gp *g, traceskip int, next bool) {
_g_ := getg() // 获取g0
// 将目标g状态由waiting更新为runnable
casgstatus(gp, _Gwaiting, _Grunnable)
// 将g放入就绪队列
runqput(_g_.m.p.ptr(), gp, next)
// 如果有空闲的m或p,将其唤醒
wakep()
}此处需要注意 ,在阻塞让渡后,g 不会进入到 lrq 或 grq 中,因为 lrq/grq 属于就绪队列. 在执行 gopark 时,使用方有义务自行维护 g的引用,并在外部条件就绪时,通过 goready 操作将其更新为 runnable 状态并重新添加到就绪队列中.
操作系统阻塞与goroutine阻塞的区别:
| 特性 | 操作系统线程阻塞 | Goroutine阻塞 |
|---|---|---|
| 阻塞粒度 | 线程级别 | Goroutine级别 |
| 调度器感知 | 不感知,由OS调度 | 完全感知,立即重新调度 |
| 开销 | 上下文切换开销大 | 用户态切换,开销小 |
| 并发数 | 受限于线程数 | 可支持数十万并发 |
5 抢占设计
如果G从不主动让渡(如死循环),如何保证其他G有机会执行?这就需要抢占 ------由系统强制G交出CPU。
最后是关于"抢占"的流程介绍,抢占和让渡有相同之处,都表示由 g->g0 的流转过程,但区别在于,让渡是由 g 主动发起的(第一人称),而抢占则是由外力干预(sysmon thread)发起的(第三人称).
5.1 监控线程
Go
// The main goroutine.
func main() {
systemstack(func() {
newm(sysmon, nil, -1) // 创建监控线程
})
// ...
}
func sysmon() {
for {
// 根据闲忙情况调整轮询间隔,在空闲情况下 10 ms 轮询一次
usleep(delay)
// 执行 netpoll,处理网络I/O
if netpollinited() && lastpoll != 0 {
list := netpoll(0) // 非阻塞检查
// 唤醒I/O就绪的goroutine
}
// 执行抢占工作
retake(now)
// 定时检查是否需要发起GC
if t := (gcTrigger{kind: gcTriggerTime}); t.test() {
// 触发GC
}
}
}在 go 程序运行时,会启动一个全局唯一的监控线程------sysmon thread,其负责定时执行监控工作,主要包括:
- 执行netpoll操作,唤醒io就绪的g
- 执行retake操作,对运行时间过长的g执行抢占操作
- 执行gcTrigger操作,探测是否需要发起新的gc
5.2 系统调用抢占
如果一个goroutine执行了长时间阻塞的系统调用,它所在的M(线程)会被操作系统挂起。如果这个M还绑定着P,那么这个P也无法被其他M使用,造成CPU资源浪费。所以此时的抢占处理思路是,将发起 syscall 的g 和 m 绑定,但是解除 p 与 m 的绑定关系,使得此期间 p 存在和其他 m 结合的机会.
1)进入系统调用时的处理
具体实现方法:
Go
func reentersyscall(pc, sp uintptr) {
// 获取 g
_g_ := getg()
// ...
// 保存寄存器信息
save(pc, sp)
// ...
// 将 g 状态更新为 syscall
casgstatus(_g_,_Grunning,_Gsyscall)
// ...
// 解除 p 与 m 绑定关系
pp := _g_.m.p.ptr()
pp.m =0
// 将 p 设置为 m 的 oldp
_g_.m.oldp.set(pp)
_g_.m.p =0
// 将 p 状态更新为 syscall
atomic.Store(&pp.status,_Psyscall)
// ...
}- 将g和p状态更新为syscall
- 解除p和m的绑定
- 将p设置为m.oldp,保留p与m的弱联系(使得m_syscall后还有一次尝试复用p的机会)
2)系统调用返回时的处理
系统调用完成后,goroutine需要重新进入用户态调度:
Go
func exitsyscall() {
_g_ := getg() // 刚从系统调用返回的goroutine
// 尝试快速路径:直接复用原来的P
oldp := _g_.m.oldp.ptr()
_g_.m.oldp = 0
if exitsyscallfast(oldp) {
// 成功复用P,恢复执行
casgstatus(_g_, _Gsyscall, _Grunning)
return
}
// 慢速路径:寻找新的P
mcall(exitsyscall0)
}
func exitsyscall0(gp *g) {
// 1. 状态更新:_Gsyscall → _Grunnable
casgstatus(gp, _Gsyscall, _Grunnable)
// 2. 解除g与m的关系
dropg()
lock(&sched.lock)
// 3. 尝试寻找空闲的P
var _p_ *p
_p_, _ = pidleget(0)
// 4. 如果找不到P,将g放入全局队列
if _p_ == nil {
globrunqput(gp)
}
unlock(&sched.lock)
// 5. 找到P则继续执行,否则停止M
if _p_ != nil {
acquirep(_p_) // M与P结合
execute(gp, false) // 继续执行goroutine
} else {
stopm() // 停止M,进入空闲队列
schedule() // 如果M被重新启用,重新调度
}
}- 快速路径优化:首先尝试重新绑定原来的P。如果这个P还在并且空闲,可以立即恢复执行,利用CPU缓存局部性。
- 优雅降级:如果原来的P已被占用,则寻找其他空闲P;如果都没有,则将goroutine放入全局队列,M进入空闲状态。这保证了资源的高效利用。
- 状态一致性 :无论快速路径还是慢速路径,都确保goroutine状态正确地从
_Gsyscall转换到可执行状态。
我们再将视角转换到监控线程sysmon定期检查所有P的状态,对执行系统调用的P实施抢占:
Go
func retake(now int64) uint32 {
n := 0
lock(&allpLock)
// 遍历所有P
for i := 0; i < len(allp); i++ {
_p_ := allp[i]
s := _p_.status
// 对于正在执行系统调用的P
if s == _Psyscall {
// 检查条件:
// 1. P的本地队列是否为空?
// 2. 系统调用是否已执行超过10ms?
// 3. 是否有空闲的M可以接管?
if runqempty(_p_) &&
atomic.Load(&sched.nmspinning) + atomic.Load(&sched.npidle) > 0 &&
pd.syscallwhen + 10 * 1000 * 1000 > now {
continue // 条件不满足,不抢占
}
unlock(&allpLock)
// 执行抢占:将P状态从_Psyscall更新为_Pidle
if atomic.Cas(&_p_.status, s, _Pidle) {
// 让P拥有和其他M结合的机会
handoffp(_p_)
}
lock(&allpLock)
}
}
unlock(&allpLock)
return uint32(n)
}- 本地队列有任务:如果P的本地队列不为空,说明有goroutine在等待执行,应立即抢占。
- 系统调用超时:默认阈值是10毫秒。如果系统调用执行时间超过10ms,认为它"太长",应该释放P给其他goroutine使用。
- 有可用执行资源 :只有存在空闲的M(
sched.nmspinning)或空闲的P(sched.npidle)时,抢占才有意义。 - 原子状态转换 :使用
atomic.Cas确保状态变更的原子性,防止并发问题。
当决定抢占一个系统调用中的P时,执行handoffp:
Go
func handoffp(_p_ *p) {
// 情况1:P的本地队列或全局队列还有任务
if !runqempty(_p_) || sched.runqsize != 0 {
// 分配一个新M与这个P结合
startm(_p_, false)
return
}
// 情况2:系统完全空闲,没有任务需要调度
pidleput(_p_, 0) // 将P放回空闲队列
}5.3 运行超时抢占
运行超时抢占是针对长时间执行用户代码的goroutine 的强制干预机制。与系统调用抢占(处理阻塞在内核的goroutine)不同,运行超时抢占处理的是一直在用户态运行、不主动让出CPU的goroutine。
如果一个goroutine执行一个无限循环或计算密集型任务,且从不调用任何可能触发让渡的函数(如channel操作、time.Sleep等),它可能会长时间独占CPU,导致其他goroutine"饿死"。
- 在Go1.13及之前:主要依赖协作式抢占,在函数调用序言插入检查点
- 在Go1.14及之后:引入基于信号的异步抢占,实现真正的强制抢占
5.3.1 触发机制:sysmon的监控与决策
监控线程sysmon每10ms(空闲时)左右执行一次retake()函数,检查所有P的状态:
Go
func retake(now int64) uint32 {
for i := 0; i < len(allp); i++ {
_p_ := allp[i]
if s == _Prunning { // P正在运行用户代码
// 如果某个P下存在运行超过10ms的g,需要进行抢占
if pd.schedwhen + forcePreemptNS <= now {
preemptone(_p_) // 执行抢占
}
}
}
}代码实现:
Go
func preemptone(_p_ *p) bool {
mp := _p_.m.ptr() // 获取P对应的M
gp := mp.curg // 获取当前运行的G
// 设置抢占标志
gp.preempt = true
// stackPreempt是一个特殊的常量值0xfffffffffffffade
gp.stackguard0 = stackPreempt
return true
}- 会对目标g设置抢占标识(将stackguard0标识为stackPreempt),这样当g运行到检查点时,就会配合抢占意图,自觉完成让渡操作
- 会对目标g所在的m发送抢占信号sigPreempt,通过改写g程序计数器(pc)的方式将g逼停
5.3.2 协作式抢占:基于栈检查的有限抢占
在Go 1.13及之前,运行超时抢占主要依赖协作式抢占,其核心思想是:在函数调用时检查是否被标记为需要抢占。

Go
// 编译器在函数序言插入的代码
func functionPro() {
// 编译器插入的检查
if stackguard0 == stackPreempt {
// 发现抢占标志,切换到g0执行让渡
morestack_noctxt() -> newstack() -> gopreempt_m()
}
// 函数正常逻辑...
}局限性:
- 紧密循环问题:
Go
// 这个循环永远不会触发抢占检查
func tightLoop() {
for {
i++ // 无函数调用,无抢占检查点
}
}- 检查点依赖:必须在函数调用时才能检查抢占标志
- 响应延迟:即使被标记抢占,也要等到下一次函数调用才响应
例如,一下代码在Go1.13版本的协作式抢占下可能卡死:
Go
func main() {
go func() {
for { // 无限循环,无函数调用
// 计算密集型任务
}
}()
// 其他goroutine可能永远得不到执行
go fmt.Println("I may never run")
select{} // 阻塞主goroutine
}5.3.3 异步抢占:基于信号的真正抢占
为了解决协作式抢占的局限,Go 1.14引入了基于信号的异步抢占。

信号发送与处理:
Go
func preemptone(_p_ *p) bool {
mp := _p_.m.ptr()
gp := mp.curg
// 1. 设置协作式抢占标志(向后兼容)
gp.preempt = true
gp.stackguard0 = stackPreempt
// 2. 基于信号机制实现非协作式抢占
if preemptMSupported && debug.asyncpreemptoff == 0 {
_p_.preempt = true
preemptM(mp) // 发送SIGURG信号
}
return true
}
func preemptM(mp *m) {
// 向指定的M发送抢占信号
// const sigPreempt untyped int = 16
signalM(mp, sigPreempt)
}- Go 的异步信号抢占,不依赖函数调用边界,可抢占长时间运行的循环或系统调用。
preemptone()在设置gp.preempt = true的同时,通过tgkill向 M 发送SIGURG。- 信号处理器
sighandler会调用doSigPreempt,修改 G 的寄存器上下文(PC、SP 等),使得信号返回后直接跳转到asyncPreempt2执行。 asyncPreempt2通过mcall(gopreempt_m)切换到 g0 栈完成抢占,最终让出 CPU 并进入调度循环。
5.3.4 两种抢占对比
| 维度 | 协作式抢占 | 异步抢占 |
|---|---|---|
| 触发时机 | 函数调用时 | 任意时刻(信号触发) |
| 实现方式 | 栈检查标志 | 信号+上下文修改 |
| 响应速度 | 延迟(等待函数调用) | 即时(10ms后立即响应) |
| 覆盖率 | 不覆盖无函数调用代码 | 覆盖所有代码 |
| Go版本 | 1.2-1.13 | 1.14+ |
| 开销 | 极小(一个比较指令) | 较大(信号处理、上下文保存) |
6 总结
GMP的精髓:
- 分而治之:将调度职责分解为G、M、P,各司其职,降低复杂度
- 局部性优先:通过P的本地队列、本地缓存,使大部分操作在局部完成,减少共享数据竞争
- 工作窃取负载均衡:静态分区(固定P)与动态窃取结合,即保持了局部优越性,又实现了全局负载均衡
- 协作与强制平衡:以协作为主(让渡)、强制为辅(抢占),在保证公平的同时减少不必要的上下文切换
- 深度集成:调度器与内存管理、垃圾回收、网络I/O等运行时组件深度集成,形成统一的并发生态系统。(关于这一点我会单独写一篇文章讨论)
GMP模型是Go语言简洁并发编程体验背后的复杂工程杰作。它将操作系统的进程/线程调度思想引入用户态,针对Go语言的特点进行了量身定制,最终成就了Go在高并发领域的独特优势。理解GMP,不仅是理解一个调度算法,更是理解Go语言"通过通信共享内存"哲学背后的工程实现智慧。