从 Tensor 到逻辑回归:云原生开发的 PyTorch 深度学习入门笔记(小白版)
-
- 为什么AI侧云原生开发者也要懂深度学习?
- 什么是深度学习?
- 如何学习深度学习?
- [PyTorch 是什么?为什么代码里写 import torch?](#PyTorch 是什么?为什么代码里写 import torch?)
- Tensor:深度学习里的数字容器
-
- [shape、dtype、device 是排错三件套](#shape、dtype、device 是排错三件套)
- [unsqueeze 和 squeeze 到底在干什么?](#unsqueeze 和 squeeze 到底在干什么?)
- 广播机制是自动补形状
- 计算图与自动求梯度:知道原理,不追底层
- [用 PyTorch 实现线性回归](#用 PyTorch 实现线性回归)
- [什么是优美的 loss 曲线?](#什么是优美的 loss 曲线?)
- Normalization:为什么归一化会影响训练?
- 逻辑回归:名字叫回归,本质做分类
- 逻辑回归的损失函数:二分类交叉熵
- 数据集划分、欠拟合与过拟合
- 二分类模型怎么评价?
- 梯度下降算法有哪些改进?
- [Dataset 和 DataLoader:训练数据怎么喂给模型?](#Dataset 和 DataLoader:训练数据怎么喂给模型?)
- [用 PyTorch 定义逻辑回归](#用 PyTorch 定义逻辑回归)
- 最后总结:你应该掌握到什么程度?
- 我曾经的疑惑
-
- 云原生工程师要学到会训练模型吗?
- 线性回归和逻辑回归哪个更适合先学?
- [loss 降了就说明模型能上线吗?](#loss 降了就说明模型能上线吗?)
最近正在做云原生相关的项目,为了更好的跟AI推理打交道,所以便自学了深度学习。
本篇文章是基于我的学习深度学习时,对一些相关问题的思考,整理而来的。
所以本博客不追求 手推反向传播,也不追求从零造框架,也不会 真让你一行行手搓偏导、矩阵、loss、梯度下降等计算。
而是为了让你,在吃透本篇博客后,
不仅能 更好服务你的工作,
如:看懂模型的训练日志,理解推理服务为什么吃 GPU,知道 Tensor 的 shape、dtype、device 出错时该往哪里查;
也能让你和算法同事把接口、模型输入、loss 曲线和评估指标说清楚;
本篇之后会重点说的:
- PyTorch 官方文档把
torch.Tensor定义为单一数据类型元素组成的多维矩阵,俗称张量,这是理解模型输入、权重、梯度和 GPU 迁移的起点。- 深度学习训练可以先记成六步:数据进入模型,模型输出预测,loss 衡量差距,
backward()求梯度,optimizer 更新参数,再重复很多轮。- 云原生工程师不用手推优化器,但要能看懂 Tensor、Autograd、DataLoader、loss 曲线、二分类指标,以及推理阶段为什么要用
torch.no_grad()。
面试复习用法本片文章只是用来回顾细节的,适合第一次看。
如果已经看本篇,只是想要复习的话,可以看另一篇。
为什么AI侧云原生开发者也要懂深度学习?
云原生工程师学深度学习,目标不是和算法工程师抢模型结构设计,而是补齐 AI 工程链路里的共同语言。
PyTorch 官方文档把 torch 包描述为包含多维 Tensor 数据结构和这些 Tensor 上数学运算的包,并提供 CUDA 对应能力来运行 NVIDIA GPU 计算。
从工程角度看,你会遇到这些问题:
- 模型服务启动后,为什么输入必须是
[batch, feature],不能只传[feature]? - 为什么同样的代码,训练时显存爆了,推理时加上
torch.no_grad()就能降下来? - 为什么 DataLoader 要管
batch_size和shuffle? - 为什么训练集 loss 很低,验证集 loss 很高,反而说明模型不能直接上线?
这些问题不要求你会发明神经网络,但要求你知道训练和推理在做什么。你越懂这个边界,越容易排查 AI 服务里的真实故障。
注
深度学习不是云原生岗位的主战场,但 Tensor、设备迁移、batch、loss、评估指标和推理模式,是 AI Infra / MLOps 工程师必须能沟通的基础。
什么是深度学习?
深度学习 是一种用多层神经网络从数据里学习规律的机器学习方法。《Deep Learning》把它描述为让计算机从经验中学习,并通过概念层级理解世界。
这句话听起来抽象,拆开就好懂了:
- 从经验中学习:经验就是训练数据。
- 概念层级:浅层学简单特征,深层组合成复杂特征。
- 多层结构:神经网络一层接一层,所以叫"深"。
- 参数调整:模型通过 loss 和梯度,不断调整权重。
传统机器学习 常常需要人先设计特征,比如手工提取用户年龄、点击次数、地区、活跃天数。
而深度学习更强调让网络自己从数据中学表示。图片模型可以从边缘学到纹理,再学到局部形状,最后识别物体。文本模型可以从 token 表示学到句法、语义和上下文关系。
那大模型微调算不算深度学习?算,但它不是"从零开始学世界"。微调通常是在预训练模型已有能力上,用更小的数据和更低的学习率改变模型行为,例如输出格式、任务风格或领域回答方式。梯度依然是发动机,但起点和目标都不同。
常见误区
"学深度学习"不等于 "立刻学大模型训练"。
对工程入门来说,先把 Tensor、loss、梯度、线性回归、逻辑回归和 DataLoader 等基础知识串起来,比一上来读 Transformer 更稳。
并且,深度学习 可以理解成用多层神经网络从数据里学习表示。它不是 靠人手工写死规则,而是通过 loss 衡量预测和真实答案的差距,再用梯度不断调整参数。
如何学习深度学习?
对于开发者来说,最顺的路线不是从复杂模型开始,而是从 PyTorch 最小闭环开始。
因为 PyTorch 的入门资料和 API 文档都围绕 Tensor、Autograd、nn.Module、loss、optimizer、Dataset/DataLoader 这些组件展开。
所以本项目的顺序如下:
- Tensor :先会看
shape、dtype、device。 - 线性回归 :理解模型参数
w、b如何被训练出来。 - loss 和梯度:知道 loss 是误差标尺,梯度是参数调整方向。
- Autograd:知道 PyTorch 如何自动记录计算图并求梯度。
- 逻辑回归:从回归过渡到二分类。
- Dataset/DataLoader:理解训练数据如何批量喂给模型。
- 过拟合和指标 :知道模型是否真的能泛化。
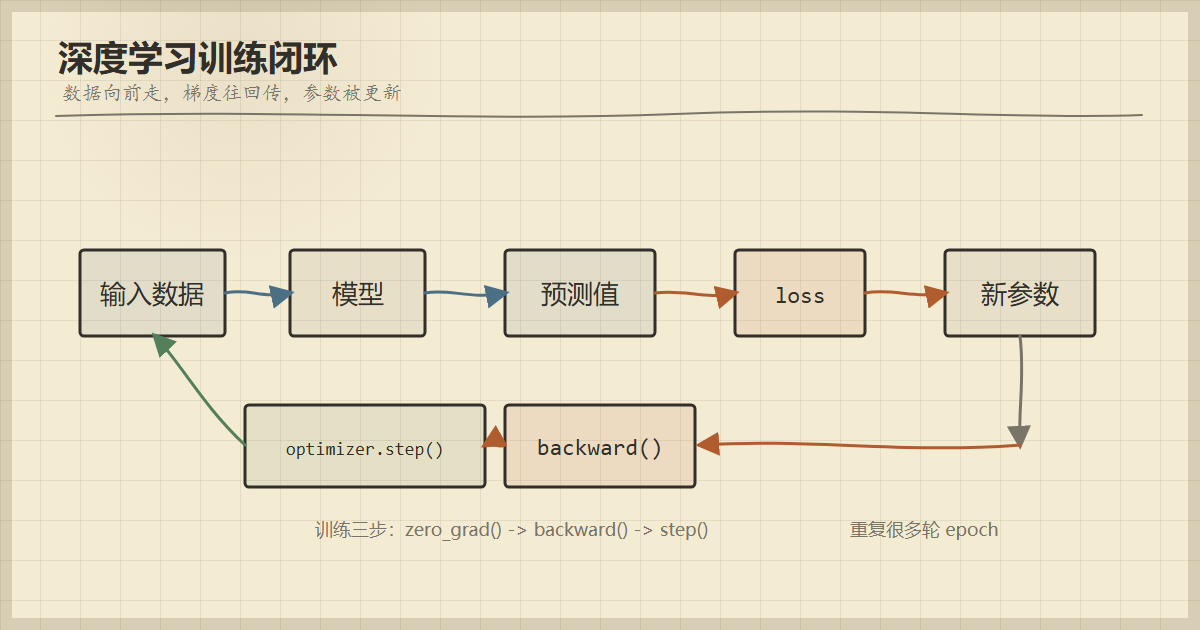
图 1
深度学习训练闭环:数据前向流动,loss 产生误差信号,
backward()计算梯度,optimizer.step()更新参数/修改权重。
PyTorch 是什么?为什么代码里写 import torch?
PyTorch 是一个深度学习框架,代码中 import torch 导入的是它的核心 Python 包。
PyTorch 官方文档说,torch 包包含多维 Tensor 的数据结构,并定义了这些 Tensor 上的数学运算。
可以这样记:
- PyTorch:框架名字。
- torch:代码里导入的核心包。
- Tensor :PyTorch 里的核心数据容器,有多种用途,比如可以用来存放输入、标签、权重、梯度和模型输出。
- Autograd:自动求梯度系统。
- torch.nn:神经网络层、损失函数等模块。
- torch.optim:SGD、Adam 等优化器。
PyTorch 之所以对工程师友好,是因为它把训练中的几件麻烦事封装好了:
如:
python
import torch
from torch import nn
# 创建输入数据 Tensor,形状是 [3, 1],表示 3 条样本,每条 1 个特征
x = torch.tensor([[1.0], [2.0], [3.0]])
# 定义一个线性层:输入 1 个特征,输出 1 个预测值,本质是 y = wx + b
model = nn.Linear(1, 1)
y_pred = model(x) # 把输入 x 喂给模型,得到预测结果 y_pred这几行代码背后已经包含 Tensor 创建、线性层参数、前向计算和输出 Tensor。
你不用手动管理每个权重矩阵的乘法,也不用自己写求导器。
一句话总结
PyTorch 是深度学习框架,
torch是代码里的核心包。它给我三个最重要的能力:Tensor 表示数据,Autograd 自动求梯度,nn和optim帮我定义模型和更新参数。
Tensor:深度学习里的数字容器
Tensor 是 PyTorch 里的核心数字容器。
PyTorch 官方文档把 torch.Tensor 定义为"包含单一数据类型元素的多维矩阵 "。
这句话很关键:Tensor 既有维度,也有数据类型,还可能在 CPU 或 GPU 上。
所以可把 Tensor 想成"带设备属性的多维数组"。普通 Python list 只是数据,Tensor 除了保存数据,还知道:
python
import torch
t = torch.tensor([[1.0, 2.0, 3.0]])
print(t.shape) # torch.Size([1, 3])
print(t.dtype) # torch.float32
print(t.device) # 使用的设施:cpushape、dtype、device 是排错三件套
模型报错时,先看这三个属性:
- shape :形状,比如
[1, 3]表示 1 条样本、3 个特征。 - dtype :数据类型,比如
float32、int64。 - device :数据在哪,比如
cpu、cuda:0。
云原生推理服务里,经常是 Go 网关传 JSON 数组,Python 服务转 Tensor,再送进模型。
只要 shape、dtype、device 有一个不匹配,就可能出错。
unsqueeze 和 squeeze 到底在干什么?
unsqueeze(dim) 是在指定位置加一个长度为 1 的维度。squeeze(dim) 是删除指定位置长度为 1 的维度。
python
import torch
x = torch.tensor([1.0, 2.0, 3.0])
print(x.shape) # torch.Size([3])
batch_x = x.unsqueeze(0)
print(batch_x.shape) # torch.Size([1, 3])
back = batch_x.squeeze(0)
print(back.shape) # torch.Size([3])为什么要加这个维度?因为模型通常按 batch 处理输入。单条样本 [3] 只是 3 个特征,加上 batch 维度后才是 [1, 3],意思是"1 条样本,每条 3 个特征"。
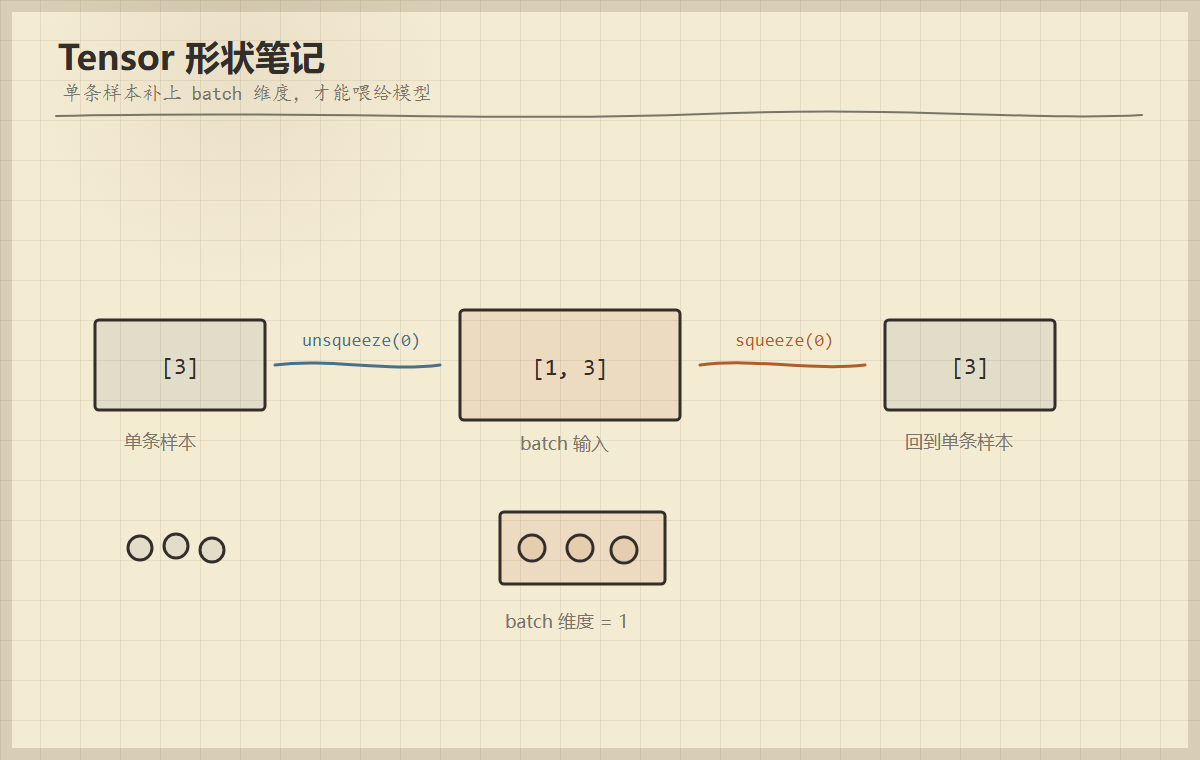
图 2
unsqueeze(0)给单条样本补 batch 维度,squeeze(0)再把这个长度为 1 的维度去掉。
广播机制是自动补形状
PyTorch 的广播规则来自 NumPy 风格语义。
官方广播说明中,两个 Tensor 如果从尾部维度开始比较时,每个维度相等、其中一个为 1,或其中一个维度不存在,就可以广播。
例子:
python
grades = torch.tensor([
[80.0, 90.0, 70.0],
[60.0, 75.0, 85.0],
])
weights = torch.tensor([0.3, 0.4, 0.3])
weighted = grades * weights
print(weighted.shape) # torch.Size([2, 3])grades 是 [2, 3],weights 是 [3]。PyTorch 会把 [3] 逻辑上看成 [1, 3],再扩展成 [2, 3] 参与逐元素计算。
常见误区
squeeze()不写维度会删除所有长度为 1 的维度。推理服务里要谨慎用,因为你可能不小心把 batch 维度也删掉。
细节Tensor 不只是数组,它还带着 shape、dtype 和 device。线上排查模型输入问题时,我会先看这三个属性,因为很多错误本质是维度、类型或 CPU/GPU 设备不一致。
计算图与自动求梯度:知道原理,不追底层
PyTorch 的 Autograd 是反向自动微分系统。
官方文档说明,前向计算时 Autograd 会同时执行运算并构建一张表示梯度函数的图;
沿着这张图从输出回到输入,就能用链式法则自动计算梯度。
不用被"计算图"吓到。你可以这样理解:
python
import torch
w = torch.tensor([2.0], requires_grad=True)
loss = w ** 2
loss.backward()
print(w.grad) # tensor([4.])这里的过程是:
w开启requires_grad=True,PyTorch 开始追踪它。loss = w ** 2产生计算关系。loss.backward()从 loss 往回算梯度。w.grad得到d(loss)/dw,也就是 4。
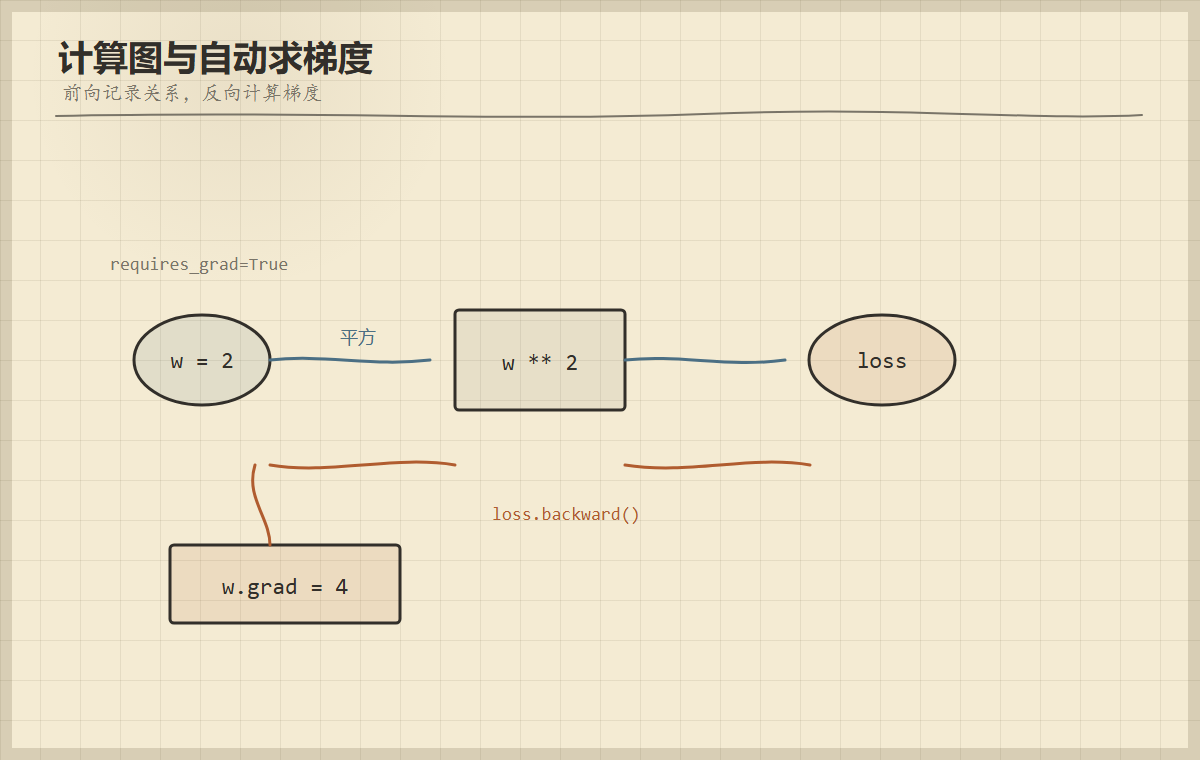
我的经验是,很多推理服务显存问题不是模型真的太大,而是代码还在按训练模式保存梯度。
训练阶段需要梯度,所以会保留计算图。推理阶段只做预测,不需要求导,所以应该用:
python
with torch.no_grad():
y_pred = model(x)这能减少不必要的梯度记录,也能降低显存占用。对模型服务来说,这是很实用的工程习惯。
记忆点
Autograd 不是"魔法求导"。它是在前向计算时记录操作关系,形成计算图;
backward()再沿图反向应用链式法则,得到每个参数的梯度。
所以说我会把 Autograd 解释成"自动记录账本"。前向计算时 PyTorch 记住每一步怎么算出来,到了
loss.backward(),它就沿着这条记录反向算每个参数该承担多少误差。
用 PyTorch 实现线性回归
PyTorch 的 nn.Linear 会对输入做仿射线性变换,官方文档写成 y = xA^T + b。
线性回归正好可以用它做最小例子:输入 x,学习一条直线,让预测接近 y = 2x + 3。
下面代码可以直接保存成 linear_regression_demo.py 运行:
python
import torch
from torch import nn
# 1. 造一组简单数据:真实规律 y = 2x + 3
x = torch.tensor([[1.0], [2.0], [3.0], [4.0], [5.0]])
y = torch.tensor([[5.0], [7.0], [9.0], [11.0], [13.0]])
# 2. 定义模型:输入1个特征,输出1个数
model = nn.Linear(in_features=1, out_features=1)
# 3. 定义损失函数和优化器
loss_fn = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
loss_history = []
# 4. 训练
for epoch in range(1000):
y_pred = model(x)
loss = loss_fn(y_pred, y)
# 以下是核心三步:
optimizer.zero_grad() # 先清掉旧的
loss.backward()
# 根据这个错误,反过来计算每个参数该怎么改。
# 它不负责真正修改参数。
# 它只是把"修改提示"算出来,放到参数的 .grad 里面。
optimizer.step()
# 它会读取刚才 backward() 算出来的 .grad,然后更新模型里的权重。
loss_history.append(loss.item())
if epoch % 100 == 0:
print(f"epoch={epoch}, loss={loss.item():.6f}")
# 5. 查看学到的参数
w = model.weight.item()
b = model.bias.item()
print(f"learned: y = {w:.3f}x + {b:.3f}")
# 6. 推理
with torch.no_grad():
x_new = torch.tensor([[6.0]])
print("x=6 prediction:", model(x_new).item())MSELoss 是均方误差,PyTorch 官方文档说它衡量输入和目标之间的 squared L2 norm。
这里的输入是预测值,目标是标签。
训练循环里最重要的是三行:
python
optimizer.zero_grad() # 清空上一轮梯度
loss.backward() # 自动求导
optimizer.step() # 更新参数为什么先清梯度?因为 PyTorch 默认会累加梯度。如果不清空,上一轮的梯度会混进下一轮,训练方向就乱了。
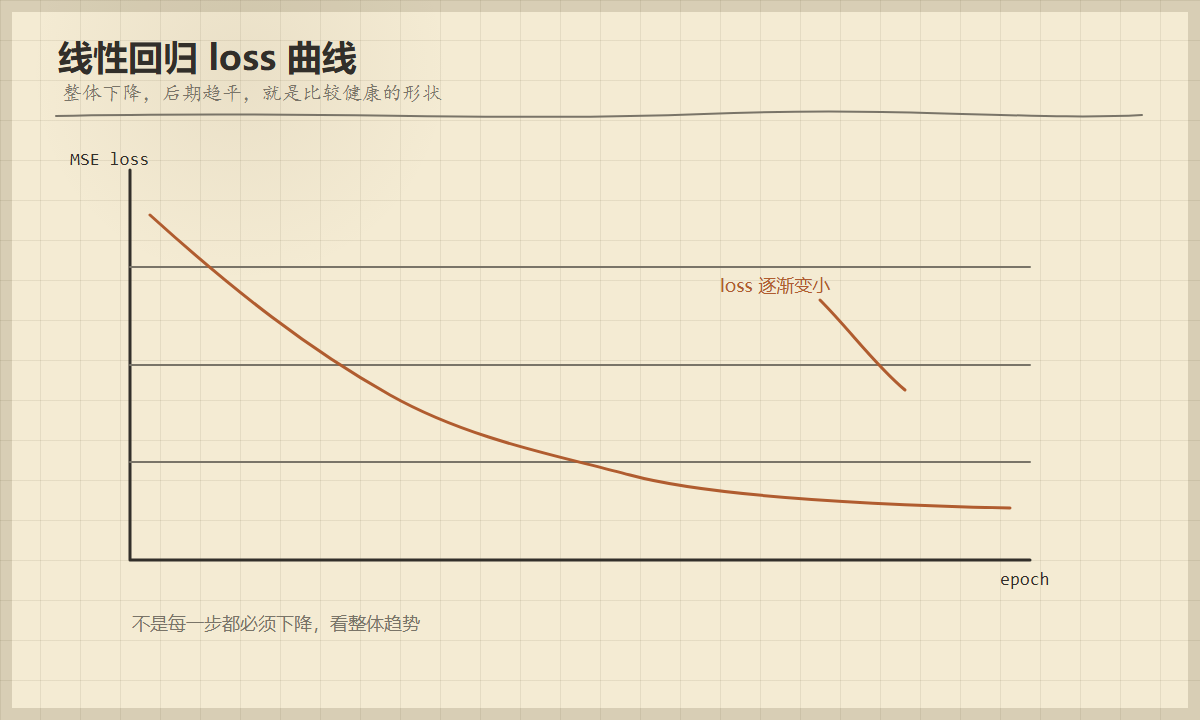
图 3
线性回归的健康 loss 曲线通常是整体下降,后期逐渐变平。中间有轻微波动不一定是坏事。
什么是优美的 loss 曲线?
一条好的 loss 曲线不需要每一步都严格下降,但整体趋势应该下降,并在后期趋于平稳。
PyTorch 官方优化器文档中的典型训练模板也是:
清梯度、前向计算、算 loss、backward()、optimizer.step(),然后重复。
你可以把 loss 曲线当成模型训练的心电图:
| 曲线形态 | 可能含义 | 工程处理 |
|---|---|---|
| 稳定下降后趋平 | 正常学习 | 继续观察验证集 |
| 大幅上下震荡 | 学习率可能太大,batch 太小,数据噪声大 | 降学习率,增大 batch,检查数据 |
| 一直不下降 | 模型没学到,特征或代码可能有问题 | 检查标签、loss、输入 shape |
| 训练 loss 降,验证 loss 升 | 过拟合 | 加正则、早停、更多数据、简化模型 |
loss 变成 nan |
数值爆炸或非法计算 | 降学习率,检查除零、归一化、梯度裁剪 |
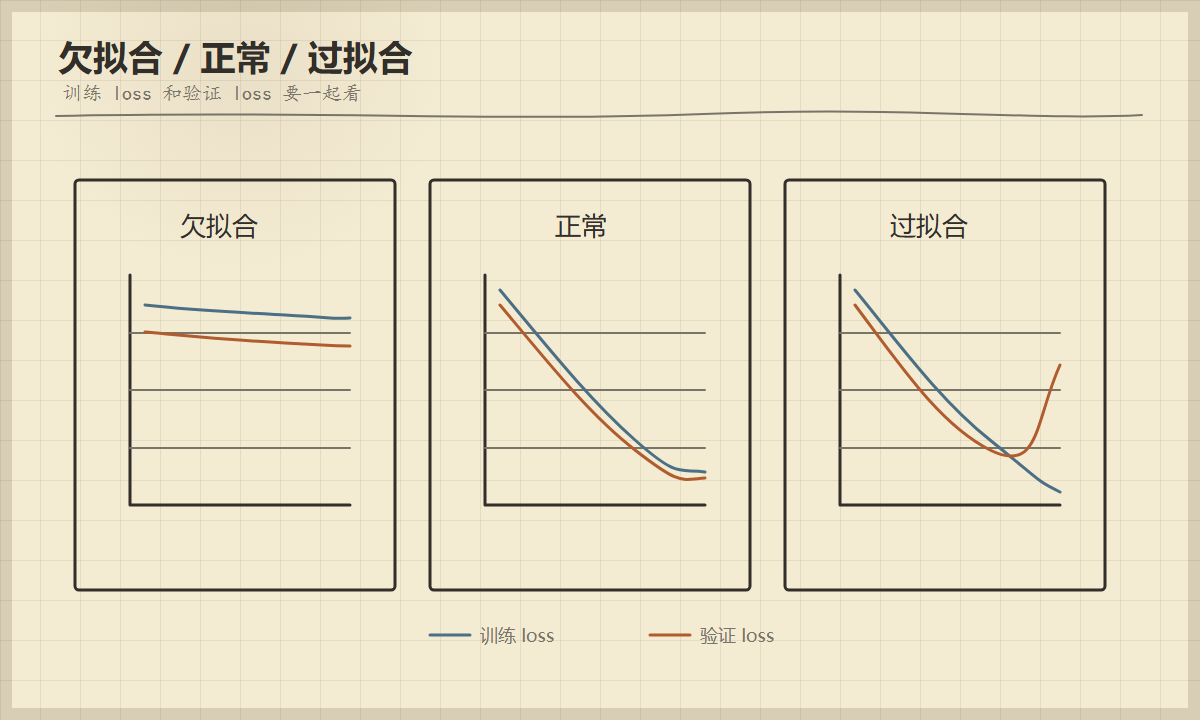
图 4
欠拟合时训练和验证 loss 都降不下来;正常时两者一起下降;过拟合时训练 loss 继续下降,但验证 loss 开始回升。
"优美"不是为了好看,而是为了判断训练是否健康。曲线能告诉你模型有没有学、学得稳不稳、是否开始背训练集。
记忆点
只看训练 loss 不够。训练 loss 低只能说明模型记住训练数据,验证 loss 才能反映泛化能力。
Normalization:为什么归一化会影响训练?
Normalization 是把不同尺度的数据拉到相近范围。
它不是装饰步骤,而是会改变梯度下降的难度。因为深度学习训练依赖数值稳定的优化过程,而输入尺度会影响优化过程的形状。
举个直观例子。一个样本有两个特征:
- 年龄:20 到 60。
- 年收入:50,000 到 500,000。
如果不处理,收入这个特征的数字大很多,模型更新时很容易被它支配。梯度下降看到的 loss 地形会变得像狭长山谷:一个方向很陡,一个方向很平。学习率稍大就震荡,学习率太小又走得很慢。
常见归一化方法有两种:
| 方法 | 公式 | 结果 | 适合直觉 |
|---|---|---|---|
| Min-Max | (x - min) / (max - min) |
压到 [0, 1] |
把不同分值转成百分比位置 |
| Z-score | (x - mean) / std |
均值约 0,标准差约 1 | 看一个值离平均水平多远 |
深度学习里还会遇到 Batch Normalization。它不是对原始输入做归一化,而是在网络中间层对一批数据的激活值做规范化。你入门阶段知道它用于稳定训练即可,不需要先追底层推导。
重点!如何说
归一化的核心是让不同特征处在相近尺度。这样梯度下降不会在某个尺度特别大的方向上来回震荡,训练会更稳定。线上推理时必须复用训练阶段的归一化参数。
逻辑回归:名字叫回归,本质做分类
逻辑回归 虽然叫 regression,但主要用于分类,尤其是二分类。
它先做线性计算,再用 Sigmoid 把原始分数压到 0 到 1 之间,解释成"属于正类的概率"。
这和 PyTorch 的二分类 loss 设计直接相关。
线性回归和逻辑回归的区别可以这样记:
| 模型 | 输出 | 任务 |
|---|---|---|
| 线性回归 | 任意连续数值 | 预测房价、温度、分数 |
| 逻辑回归 | 0 到 1 的概率 | 判断是否恶意、是否流失、是否异常 |
一元逻辑回归只有一个输入特征:
text
score = w * x + b
probability = sigmoid(score)多元逻辑回归有多个输入特征:
text
score = w1*x1 + w2*x2 + ... + wn*xn + b
probability = sigmoid(score)如果概率大于阈值,比如 0.5,就判为正类;否则判为负类。阈值不是天生固定的,业务里会根据误报和漏报成本调整。
重点!怎么说
逻辑回归可以看成最简单的二分类模型。它先用线性层算一个原始分数,再通过 Sigmoid 转成概率,最后根据阈值判断正类或负类。
逻辑回归的损失函数:二分类交叉熵
二分类交叉熵用来衡量预测概率和真实标签之间的差距。
PyTorch 官方文档说明,BCEWithLogitsLoss 把 Sigmoid 层和 BCELoss 合在一个类里,并利用 log-sum-exp 技巧获得更好的数值稳定性。
二分类交叉熵公式是:
text
Loss = - [ y * log(p) + (1 - y) * log(1 - p) ]这里:
y是真实标签,只能是 0 或 1。p是模型预测正类的概率。Loss越小,说明预测越接近真实标签。
如果真实标签是 1,而模型预测 p=0.9,loss 会比较小。
模型猜得对,而且很有信心。
如果真实标签是 1,而模型预测 p=0.1,loss 会很大。
模型不但错了,还错得很自信。
实际写 PyTorch 代码时,推荐这样做:
python
loss_fn = nn.BCEWithLogitsLoss()
logits = model(x) # 原始分数,不手动 sigmoid
loss = loss_fn(logits, y) # loss 内部处理 sigmoid + BCE推理时再把 logits 转成概率:
python
prob = torch.sigmoid(logits)
pred = (prob >= 0.5).float()面试时怎么说
二分类训练里我更倾向用
BCEWithLogitsLoss,因为它把 Sigmoid 和二分类交叉熵合在一起,数值上更稳定。训练时喂 logits,推理时再手动
sigmoid得到概率。
数据集划分、欠拟合与过拟合
训练模型不能只看训练集效果。
常见做法是把数据拆成训练集、验证集和测试集。
训练集用于更新参数,验证集用于调模型和观察过拟合,测试集用于最后评估。
并且这三份数据通常写成 train / validation / test。train 负责学习参数,validation 负责调参和早停,test 负责最后报告一次相对客观的效果。
你可以这样理解三份数据:
| 数据集 | 作用 | 类比 |
|---|---|---|
| train | 让模型学习 | 平时刷题 |
| validation | 调参数和早停 | 模拟考试 |
| test | 最终评估 | 正式考试 |
欠拟合是模型太弱,训练集都学不好。
表现是训练 loss 和验证 loss 都高。解决方向是换更合适的模型、加特征、训练更久,或降低过强的正则。
过拟合是模型把训练集背熟了,但没学到通用规律。
表现是训练 loss 很低,验证 loss 明显更高。解决方向是更多数据、数据增强、正则化、Dropout、早停、简化模型。
面试时怎么说
train是给模型学习的,validation是给我调参和判断过拟合的,test是最后评估用的。不能边看测试集边调参,否则测试集就不再客观。
二分类模型怎么评价?
二分类模型不能只看 accuracy。
scikit-learn 的指标文档列出 accuracy、precision、recall、F1、ROC AUC 等分类指标;
其中一些指标特别适合二分类任务。
先看四个基本计数:
| 名称 | 含义 | 恶意账号例子 |
|---|---|---|
| TP | 预测恶意,实际恶意 | 抓对坏账号 |
| FP | 预测恶意,实际正常 | 误伤正常用户 |
| TN | 预测正常,实际正常 | 放过正常用户 |
| FN | 预测正常,实际恶意 | 漏掉坏账号 |
再看指标:
| 指标 | 公式直觉 | 适合看什么 |
|---|---|---|
| Accuracy | 全部预测里有多少对 | 类别比较均衡时的整体表现 |
| Precision | 判成正类的样本里有多少真是正类 | 控制误报 |
| Recall | 真实正类里有多少被抓到 | 控制漏报 |
| F1 | Precision 和 Recall 的折中 | 误报漏报都重要 |
| ROC-AUC | 不同阈值下的整体区分能力 | 比较模型排序能力 |
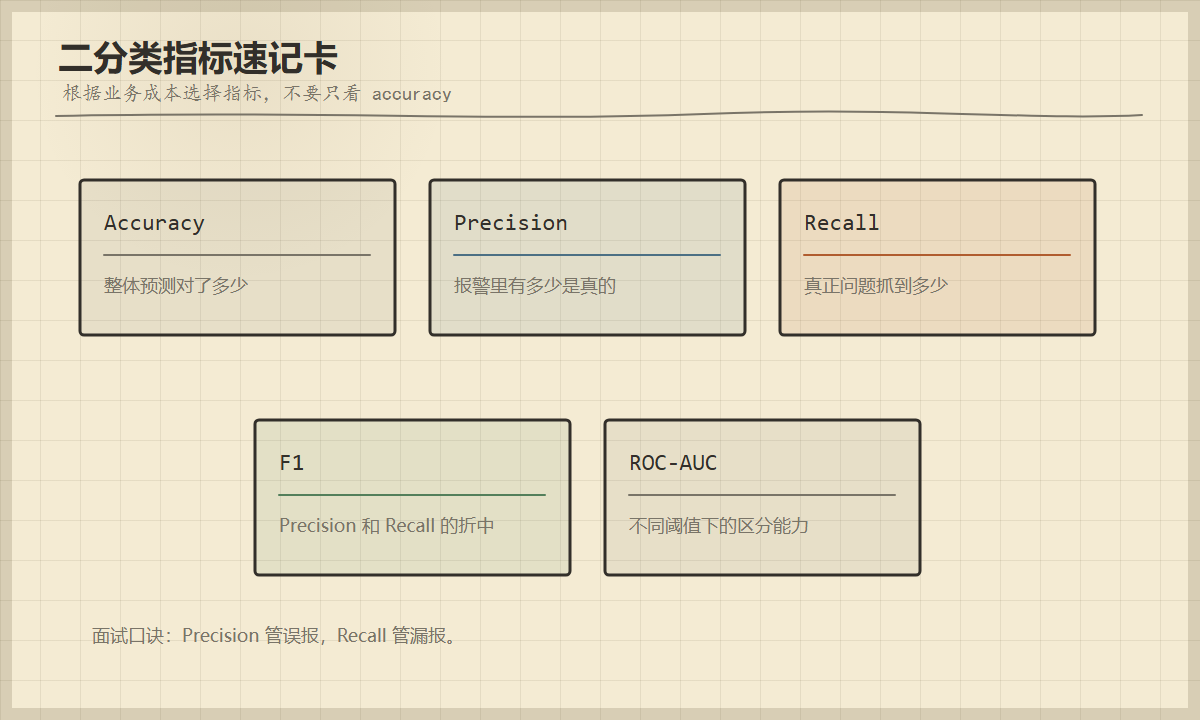
图 5
跟别人说起时,要优先把 Precision 和 Recall 讲清楚:Precision 控制误报,Recall 控制漏报。
为什么 accuracy 容易误导?
假设异常日志只有很少一部分,一个模型永远预测"正常",accuracy 可能看起来不低,但它没有抓到任何异常。
工程上要结合业务成本看指标。
风控 更怕漏掉欺诈时,Recall 更重要;
内容审核更怕误伤正常内容时,Precision 更重要。
记忆点
Precision 回答"我报警的里面有多少是真的";Recall 回答"真正的问题里我抓到了多少"。
重点!怎么说如果业务怕误伤,我会更关注 Precision;如果业务怕漏掉问题,我会更关注 Recall。比如风控漏掉欺诈很危险,所以 Recall 往往更关键;内容审核误伤用户也很敏感,所以 Precision 也要看。
梯度下降算法有哪些改进?
PyTorch 的 torch.optim 包提供多种优化算法。
官方文档说,构造 optimizer 时要传入待优化参数,并指定学习率、权重衰减等选项。
最基础的是梯度下降:沿着梯度的反方向更新参数,让 loss 下降。
text
new_param = old_param - learning_rate * gradient常见变体:
| 方法 | 每次看多少数据 | 特点 |
|---|---|---|
| Batch Gradient Descent | 全部训练集 | 方向稳定,但大数据时很慢 |
| SGD | 1 条样本 | 更新快,但方向抖动大 |
| Mini-batch GD | 一小批样本 | 深度学习最常见折中 |
PyTorch 的 SGD 实现支持 momentum 参数。
Adam 是另一个常用优化器,PyTorch 文档说明它实现 Adam 算法,并维护一阶矩和二阶矩估计。
入门阶段可以把 Adam 理解成"会自适应调整不同参数步长"的优化器。
重点!怎么说
SGD 是按梯度方向更新参数,Mini-batch 是工程上最常见的折中。Momentum 给更新加惯性,减少抖动;Adam 会自适应调整不同参数的步长,通常更容易上手。
Dataset 和 DataLoader:训练数据怎么喂给模型?
PyTorch 教程明确说,Dataset 保存样本和对应标签,DataLoader 在 Dataset 外面包一层可迭代对象,方便访问样本。
教程还说明,训练时通常希望用 minibatch、每个 epoch 重新打乱数据,并用多进程加速数据获取。
先记住分工:
- Dataset:定义"怎么拿到第 i 条数据"。
- DataLoader:定义"怎么批量拿数据、是否打乱、是否并行加载"。
最小自定义 Dataset:
python
import torch
from torch.utils.data import Dataset, DataLoader
class SimpleDataset(Dataset):
def __init__(self):
self.x = torch.tensor([[1.0], [2.0], [3.0], [4.0]])
self.y = torch.tensor([[0.0], [0.0], [1.0], [1.0]])
def __len__(self):
return len(self.x)
def __getitem__(self, idx):
return self.x[idx], self.y[idx]
dataset = SimpleDataset()
loader = DataLoader(dataset, batch_size=2, shuffle=True)
for batch_x, batch_y in loader:
print(batch_x.shape, batch_y.shape)这段代码会每次返回一批样本。真实训练时,训练循环里遍历的就是 DataLoader。
代码关键行
__len__告诉 PyTorch 数据集有多长;__getitem__告诉 PyTorch 如何取一条样本;DataLoader(..., batch_size=..., shuffle=True)决定如何组成 batch。
重点!怎么说Dataset 关心"怎么取一条数据",DataLoader 关心"怎么把数据批量喂给模型"。工程上 DataLoader 还会影响吞吐,因为它控制 batch、shuffle 和并行加载。
用 PyTorch 定义逻辑回归
逻辑回归可以用一个 nn.Linear 表示。二分类训练时,用 BCEWithLogitsLoss 接收模型输出的 logits 和真实标签;推理时再用 torch.sigmoid 把 logits 转成概率。PyTorch, BCEWithLogitsLoss
下面是一份可运行的最小逻辑回归代码,不依赖 scikit-learn:
python
import torch
from torch import nn
from torch.utils.data import TensorDataset, DataLoader
torch.manual_seed(42)
# 1. 构造模拟二分类数据
# 规则:x1 + x2 > 0 视为正类
n = 200
x = torch.randn(n, 2)
y = ((x[:, 0] + x[:, 1]) > 0).float().unsqueeze(1)
# 2. 划分训练集和测试集
train_size = int(0.8 * n)
x_train, x_test = x[:train_size], x[train_size:]
y_train, y_test = y[:train_size], y[train_size:]
train_ds = TensorDataset(x_train, y_train)
train_loader = DataLoader(train_ds, batch_size=16, shuffle=True)
# 3. 定义逻辑回归模型:本质是一层线性层
model = nn.Linear(in_features=2, out_features=1)
loss_fn = nn.BCEWithLogitsLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
# 4. 训练
for epoch in range(100):
for batch_x, batch_y in train_loader:
logits = model(batch_x)
loss = loss_fn(logits, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 20 == 0:
print(f"epoch={epoch}, loss={loss.item():.4f}")
# 5. 评估
with torch.no_grad():
logits = model(x_test)
prob = torch.sigmoid(logits)
pred = (prob >= 0.5).float()
tp = ((pred == 1) & (y_test == 1)).sum().item()
fp = ((pred == 1) & (y_test == 0)).sum().item()
tn = ((pred == 0) & (y_test == 0)).sum().item()
fn = ((pred == 0) & (y_test == 1)).sum().item()
accuracy = (tp + tn) / (tp + fp + tn + fn)
precision = tp / (tp + fp + 1e-8)
recall = tp / (tp + fn + 1e-8)
f1 = 2 * precision * recall / (precision + recall + 1e-8)
print(f"TP={tp}, FP={fp}, TN={tn}, FN={fn}")
print(f"accuracy={accuracy:.3f}")
print(f"precision={precision:.3f}")
print(f"recall={recall:.3f}")
print(f"f1={f1:.3f}")这份代码包含完整链路:
- Tensor 构造数据。
- 划分训练集和测试集。
- 用
TensorDataset和DataLoader批量取数据。 - 用
nn.Linear定义模型。 - 用
BCEWithLogitsLoss训练二分类。 - 用 Accuracy、Precision、Recall、F1 做评估。
从云原生视角看,这段逻辑回归代码比模型准确率本身更有价值。它把线上推理最容易出错的几件事都暴露出来:输入必须是二维 Tensor,标签 shape 要和 logits 对齐,训练时要保留梯度,推理时要关梯度,最终输出要从 Tensor 转成普通数值或 JSON。
重点卡片
逻辑回归训练链路:输入特征 Tensor ->
nn.Linear输出 logits ->BCEWithLogitsLoss算 loss ->backward()求梯度 -> optimizer 更新参数 -> 推理时sigmoid(logits)得到概率 -> 阈值转分类。
最后总结:你应该掌握到什么程度?
如果你的方向是云原生、AI Infra 或 MLOps,因为不需要成为算法专家。
所以更应该掌握模型工程中高频出现的基础对象:Tensor、shape、device、batch、loss、梯度、DataLoader、评估指标和推理模式。
最小学习清单如下:
| 必须掌握 | 为什么 |
|---|---|
Tensor 的 shape/dtype/device |
线上模型输入错误最常见 |
unsqueeze/squeeze/permute/cat/stack |
处理 batch 和维度 |
requires_grad/backward/no_grad |
区分训练和推理 |
zero_grad/backward/step |
看懂训练循环 |
| loss 曲线 | 判断训练是否健康 |
| train/validation/test | 判断泛化能力 |
| Precision/Recall/F1 | 看懂二分类模型是否可用 |
| Dataset/DataLoader | 理解数据如何进入模型 |
暂时不用深挖:
- 手推反向传播公式。
- 从零实现优化器。
- 自研神经网络框架。
- 分布式 Tensor 并行细节。
我曾经的疑惑
云原生工程师要学到会训练模型吗?
不一定。你至少要会读懂训练代码、loss 曲线、Tensor shape 和推理输入输出。真正的模型结构设计可以交给算法工程师,但模型部署、服务稳定性、GPU 利用率、batch 策略和排障链路,往往需要工程师理解这些基础。
线性回归和逻辑回归哪个更适合先学?
先学线性回归。线性回归能帮你理解参数、loss、梯度和 optimizer。再学逻辑回归时,你只是在这条线性计算后面加上分类概率和交叉熵损失,概念迁移更顺。
loss 降了就说明模型能上线吗?
不能。训练 loss 下降只说明模型在训练集上拟合得更好。上线前还要看验证集、测试集、二分类指标、业务阈值和失败样本。训练 loss 很低但验证 loss 很高,通常是过拟合信号。