Data-Juicer是阿里巴巴通义实验室开源的大模型数据处理框架,其定位并不是传统意义上的 ETL 工具,也不是模型训练框架,而是一个专门面向大模型时代的数据操作系统(Data Operating System)。在大模型研发过程中,数据质量往往直接决定模型能力的上限,因此 Data-Juicer 的核心目标是建立一套标准化、自动化、可扩展的数据治理体系,将来自互联网、知识库、数据库、多模态资源等不同来源的原始数据,经过分析、清洗、过滤、去重、增强、评分、合成等多个阶段的处理后,最终生成适用于预训练、监督微调(SFT)、偏好对齐(DPO)、强化学习(RLHF)以及 RAG 检索增强生成等场景的高质量数据集。整个系统采用分层架构设计,从用户接口层到数据存储层形成了一条完整的数据加工流水线,使得数据处理过程具备可配置、可复现、可监控和可扩展的特点。
Data-Juicer (DJ) 是面向大模型时代的数据操作系统(当前版本 v1.5.2),由阿里巴巴通义实验室 SysML 团队维护。核心目标:把原始多模态数据通过可组合的 YAML Recipe 流水线,清洗、合成、分析并导出为 AI-ready 数据集。支持单机多进程到 Ray 千节点集群。
1. 项目总体结构
data-juicer-main/
├── data_juicer/ # 核心 Python 包
│ ├── config/ # 配置解析与 YAML 模板
│ ├── core/ # 执行引擎、数据集、导出、追踪
│ ├── ops/ # 200+ 算子(Operator)
│ ├── format/ # 数据格式加载/导出
│ ├── analysis/ # 数据分析模块
│ ├── utils/ # 工具库
│ ├── download/ # 数据下载(ArXiv、Wikipedia 等)
│ └── tools/ # CLI 工具、HPO、质量分类器、MCP
├── tools/ # 顶层 CLI 入口脚本
├── demos/ # 示例 Recipe 与教程
├── tests/ # 单元测试
├── docs/ # 文档
├── app.py # Streamlit Web UI
└── pyproject.toml # 包定义与可选依赖
CLI 入口(pyproject.toml):
|------------|-----------------------|
| 命令 | 作用 |
| dj-process | 执行数据处理流水线 |
| dj-analyze | 数据集统计分析 |
| dj-install | 按需安装 OP 依赖 |
| dj-mcp | MCP 服务(与 AI Agent 集成) |
2. 核心架构与数据流
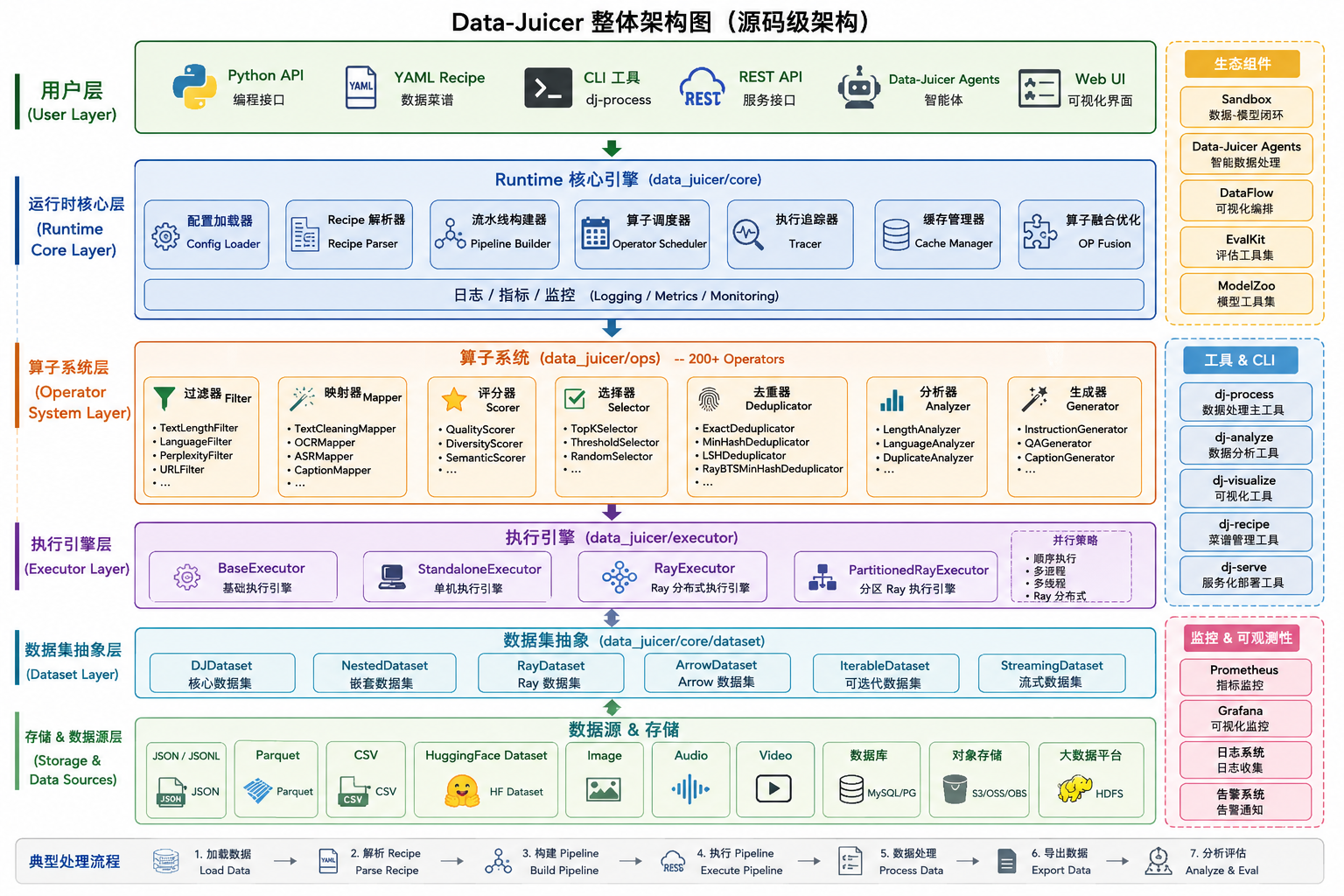
用户层(User Layer)
用户层是整个 Data-Juicer 架构最上层的交互入口,负责接收用户定义的数据处理需求,并将这些需求转换为系统能够执行的 Pipeline。在实际使用过程中,用户既可以通过 Python API 编写代码直接构建数据处理流程,也可以通过 YAML Recipe 文件定义完整的数据处理规则。Recipe 是 Data-Juicer 中最重要的概念之一,它类似于 Dockerfile 或 Jenkins Pipeline 文件,通过声明式配置描述数据处理的全过程。例如,用户可以在 Recipe 中定义数据输入位置、需要执行的过滤器、评分器、去重器以及输出格式,而无需编写复杂代码。
除了 Python API 和 Recipe 配置之外,Data-Juicer 还提供了一套完整的命令行工具,包括 dj-process、dj-analyze、dj-visualize 等,用于执行数据处理、分析统计和结果可视化。同时,为了适应企业级平台集成需求,系统还提供 REST API 接口,使 Data-Juicer 可以嵌入到企业 AI 平台、MLOps 平台或数据治理平台中。随着 Data-Juicer 2.x 的发布,官方进一步引入了 Data-Juicer Agents,通过大模型实现自然语言驱动的数据处理。例如用户只需输入"帮我清洗一个中文知识库",系统即可自动生成对应的 Recipe 配置和 Pipeline 流程,从而显著降低使用门槛。
运行时核心层(Runtime Core Layer)
运行时核心层位于整个系统的中心位置,可以理解为 Data-Juicer 的控制中心和调度中心。该部分主要对应源码中的 data_juicer/core 模块,负责从配置加载到任务执行的全过程管理。当用户提交一个 Recipe 后,首先由 Config Loader 模块负责读取 YAML 配置文件并完成参数校验,然后交给 Recipe Parser 进行解析。Recipe Parser 会将配置中的每一个 Operator 转换为内部执行节点,并建立节点之间的依赖关系。
随后 Pipeline Builder 会根据解析结果构建完整的执行图(Pipeline DAG),这一过程类似于 Airflow 的 DAG 构建或者 Spark 的执行计划生成。Pipeline 构建完成后,Operator Scheduler 会根据算子之间的依赖关系和资源需求决定执行顺序以及并行策略。在执行过程中,Tracer 模块负责记录运行状态,包括任务耗时、资源利用率、吞吐量以及异常信息,为后续性能分析和故障排查提供依据。为了避免重复计算,Cache Manager 会缓存模型加载结果、中间计算结果以及 Embedding 等高成本资源。此外,Data-Juicer 还实现了 OP Fusion 机制,可以将多个连续执行的算子融合为一个执行单元,从而减少数据遍历次数和磁盘 I/O 开销,大幅提高整体处理效率。
算子系统层(Operator System Layer)
算子系统是 Data-Juicer 的核心能力层,也是整个框架最具特色的部分。官方已经提供了超过 200 个 Operator,覆盖文本、图像、音频、视频以及多模态数据处理场景。所有数据处理逻辑最终都被封装为标准化的 Operator,用户只需通过配置方式将这些算子组合起来即可构建复杂的数据处理流水线。
在算子体系中,Filter(过滤器)主要负责删除低质量数据,例如长度过短的文本、乱码数据、广告数据、重复内容以及不符合语言要求的数据。Mapper(映射器)则负责对数据进行转换和增强,例如文本清洗、HTML 去标签、OCR 文本提取、ASR 语音转文本以及图像 Caption 生成等操作。Scorer(评分器)用于对数据质量进行量化评估,通过质量模型、语言模型或语义模型为每条数据生成质量分数。Selector(选择器)则根据评分结果筛选高质量样本,例如保留得分最高的前 10% 数据。
Deduplicator(去重器)是 Data-Juicer 的重点模块之一。互联网数据中存在大量重复内容,如果不进行去重,会严重影响模型训练效果。为此 Data-Juicer 提供了 Exact Dedup、MinHash Dedup、LSH Dedup 和 Embedding Dedup 等多种去重算法,既能够处理完全重复数据,也能够识别语义近似数据。此外,Analyzer(分析器)负责生成数据质量分析报告,包括长度分布、语言分布、重复率统计和 Token 分布等指标,而 Generator(生成器)则通过大模型实现数据增强和数据合成,例如生成 QA 数据、指令数据和图像描述数据等。
执行引擎层(Executor Layer)
执行引擎层决定了 Pipeline 如何真正运行。Data-Juicer 将执行逻辑与数据处理逻辑完全解耦,因此同一个 Pipeline 可以在不同执行环境中运行。所有执行器都继承自 BaseExecutor 抽象基类,并实现统一的执行接口。
StandaloneExecutor 是默认的单机执行器,适用于开发测试和中小规模数据集处理场景。在这种模式下,所有数据处理都在单台机器上完成,部署简单且调试方便。对于大规模数据处理任务,Data-Juicer 提供了基于 Ray 的 RayExecutor。该执行器利用 Ray 的分布式计算能力,将数据自动划分为多个分区并分发到不同计算节点上执行,从而实现水平扩展。当数据规模进一步扩大到 TB 级甚至 PB 级时,可以使用 PartitionedRayExecutor。该执行器支持大规模分布式去重、分布式评分和分布式数据增强任务,在官方测试中已经能够处理数十亿级别的数据样本。
数据集抽象层(Dataset Layer)
数据集抽象层是 Data-Juicer 实现统一数据处理的关键。由于大模型训练数据来源非常复杂,既包括 JSON、CSV、Parquet 等结构化数据,也包括图片、音频、视频等多模态数据,因此 Data-Juicer 引入了统一的数据集抽象机制。无论数据来源是什么格式,在进入系统后都会被转换为统一的 Dataset 对象。
DJDataset 是整个系统的核心数据集对象,所有 Operator 都以 DJDataset 为输入和输出,从而实现统一的数据处理接口。对于多模态场景,系统提供 NestedDataset 来支持嵌套结构数据,例如同时包含图片、文本描述和对话内容的数据样本。RayDataset 则是专门为分布式计算设计的数据集实现,可以与 RayExecutor 无缝集成,实现自动切片和分布式调度。ArrowDataset 基于 Apache Arrow 构建,采用列式存储和零拷贝机制,在大规模数据处理场景下具有更高的性能。对于超大规模数据集,StreamingDataset 则支持流式加载和处理,避免一次性加载全部数据导致内存溢出问题。
数据源与存储层(Storage Layer)
数据源与存储层位于整个架构最底层,是 Data-Juicer 与外部世界连接的桥梁。系统支持多种数据来源,包括 JSON、JSONL、CSV、Parquet 等结构化文件格式,也支持直接读取 HuggingFace Dataset 数据集。对于多模态场景,系统能够处理 JPEG、PNG 等图像格式,MP3、WAV 等音频格式,以及 MP4、AVI 等视频格式。
在企业环境中,训练数据往往存储在数据库或云存储系统中,因此 Data-Juicer 还支持从 MySQL、PostgreSQL 等数据库读取数据,以及从 Amazon S3、阿里云 OSS、华为云 OBS 等对象存储系统获取数据。此外,系统还兼容 Hadoop 生态,可以直接访问 HDFS 等大数据存储平台。通过统一的数据访问接口,Data-Juicer 屏蔽了底层存储差异,使上层 Pipeline 能够专注于数据处理逻辑本身。
数据处理全流程
从整体运行过程来看,Data-Juicer 的工作流程可以概括为:首先从文件系统、对象存储、数据库或 HuggingFace 数据集加载原始数据;随后读取用户定义的 Recipe 配置,并解析生成对应的 Pipeline;Pipeline Builder 根据配置构建执行图,Scheduler 负责调度执行顺序;Executor 选择合适的执行模式(单机或分布式)并开始执行各类 Operator;在执行过程中,数据会依次经过过滤、清洗、去重、评分、增强等处理环节;最终生成高质量的数据集,并通过 Analyzer 输出详细的数据质量报告。
经过这一系列处理后,原始数据将被转化为适用于预训练(Pretrain)、监督微调(SFT)、偏好优化(DPO)、强化学习(RLHF)、检索增强生成(RAG)以及多模态模型训练的数据资产。正因如此,Data-Juicer 在整个大模型研发体系中的定位并不是单纯的数据清洗工具,而是连接原始数据与大模型训练之间的数据生产平台,是大模型时代数据治理的重要基础设施。
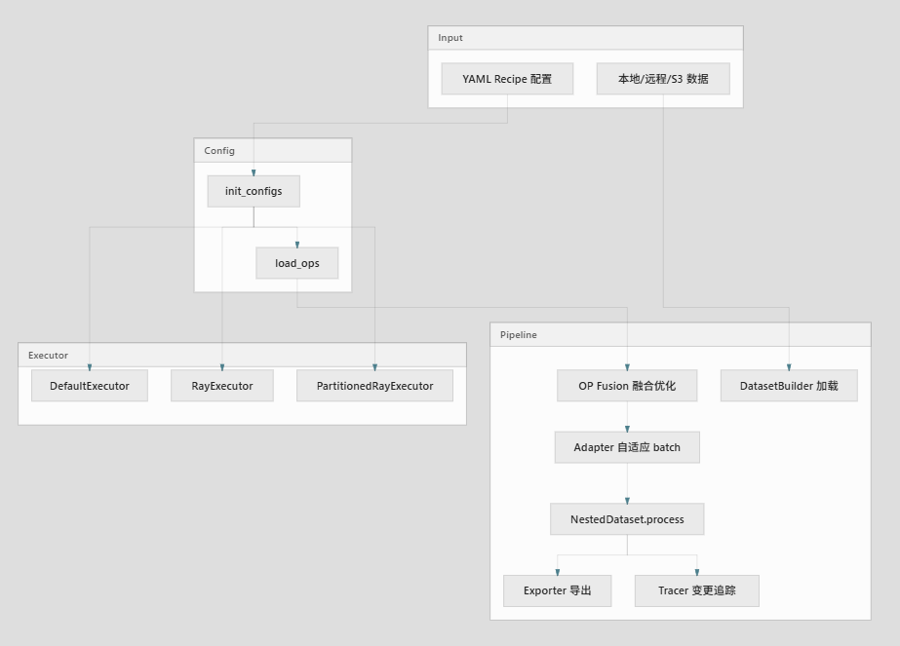
典型执行路径(tools/process_data.py):
- init_configs() 解析 YAML/CLI 参数
- 按 executor_type 选择执行器(default / ray / ray_partitioned)
- executor.run() 完成加载 → 算子链处理 → 导出
3. 配置系统 (`data_juicer/config/`)
配置基于 jsonargparse,支持 YAML 文件 + 命令行覆盖。
最小示例(demos/process_simple/process.yaml):
project_name: 'demo-process'
dataset_path: './demos/data/demo-dataset.jsonl'
np: 4
export_path: './outputs/demo-process/demo-processed.jsonl'
process:
- language_id_score_filter:
lang: 'zh'
min_score: 0.8
关键配置项:
|--------|-------------------------------------------------|
| 类别 | 典型字段 |
| 数据 | dataset_path, dataset, generated_dataset_config |
| 执行 | np, executor_type, use_cache, use_checkpoint |
| 优化 | op_fusion, fusion_strategy, adaptive_batch_size |
| 导出 | export_path, export_type, S3 凭证 |
| 可观测 | open_tracer, open_insight_mining |
| 扩展 | custom_operator_paths 动态加载自定义 OP |
config.py 还负责:OP 参数校验、Ray 环境变量、日志初始化、自定义 OP 动态 import。
4. 执行引擎 (`data_juicer/core/`)
4.1 Executor 层次
ExecutorBase (抽象基类)
├── DefaultExecutor # 单机/多进程,功能最全
├── RayExecutor # Ray 分布式
└── PartitionedRayExecutor # 分区 Ray 执行(v1.5.0+)
DefaultExecutor.run() 主流程:
加载数据:DatasetBuilder / checkpoint 恢复
加载算子:load_ops(cfg.process)
DAG 初始化:DAGExecutionMixin 构建流水线 DAG
OP Fusion:合并连续 Filter,减少重复计算(2--10x 加速)
自适应 batch:Adapter.adapt_workloads() 按资源探测调整 batch_size
处理:dataset.process(ops, exporter, checkpointer, tracer)
导出:Exporter 写 JSONL/Parquet/TSV 等
4.2 数据集抽象 (`core/data/`)
|-----------------------|------------------------------------|
| 类 | 职责 |
| DJDataset | 抽象基类,定义 process(), schema(), get() |
| NestedDataset | 基于 HuggingFace datasets 的主实现 |
| RayDataset | Ray 模式数据集 |
| DatasetBuilder | 从配置构建数据集(本地/远程/HF/S3) |
| Schema | 列名与类型 |
| DataValidatorRegistry | 数据校验插件 |
数据集处理依赖 HuggingFace datasets 的 map / filter,并封装了缓存压缩、checkpoint、多进程上下文(fork/spawn)。
4.3 辅助核心模块
|------------------------|---------------------------|
| 模块 | 作用 |
| Adapter | 小批量探测 OP 速度与资源,做负载均衡 |
| Exporter / RayExporter | 多格式导出,支持 S3、分片、加密 |
| Tracer / RayTracer | 记录样本级变更,便于调试与 bad-case 分析 |
| Monitor | CPU/GPU/内存监控 |
| CheckpointManager | 断点续跑 |
| Analyzer | 分析模式:只跑 Filter 统计 + 可视化 |
4.4 DAG 执行 (`core/executor/`)
- pipeline_dag.py:将 process 列表解析为 DAG
- dag_execution_mixin.py:DAG 监控与并行组调度
- dag_execution_strategies.py:不同执行策略
- event_logging_mixin.py:作业级事件日志
5. 算子系统 (`data_juicer/ops/`) --- 项目核心
5.1 算子类型继承体系
OP (基类)
├── Mapper # 变换/增强:1→1 或 1→N
├── Filter # 过滤:compute_stats → filter
├── Deduplicator # 去重:文档/图像/视频/行级
├── Selector # 采样/TopK/频率选择
├── Grouper # 分组
├── Aggregator # 聚合(跨样本)
└── Pipeline # 复合流水线(如 Ray+vLLM 推理)
所有算子通过 `@OPERATORS.register_module(name='xxx')` 注册到全局 Registry,YAML 中直接用 xxx 作为 key。
规模概览(约):
|--------------|--------|-------------------------|
| 类型 | 数量 | 示例子目录 |
| Mapper | ~120 | 文本清洗、LLM、视频、Agent、图像 |
| Filter | ~55 | 长度、语言、美学、LLM 质量 |
| Deduplicator | ~15 | MinHash、SimHash、Ray 分布式 |
| Selector | 5 | TopK、随机、频率 |
| Grouper | 3 | 键值分组 |
| Aggregator | 4 | 实体/标签聚合 |
| Pipeline | 4 | vLLM、Ray 重分区 |
5.2 OP 基类关键能力 (`base_op.py`)
- 多模态字段键:text_key, image_key, audio_key, video_key, query_key, response_key 等
- 并行:num_proc, auto_op_parallelism, runtime_np()
- 批处理:_batched_op, batch_size, batch_mode
- GPU:accelerator='cuda', Ray num_gpus
- Ray 隔离环境:runtime_env, OPEnvSpec, op_env.py
- 容错:skip_op_error, catch_map_batches_exception
- 缓存指纹:_fingerprint_bytes() 排除 work_dir 等无关字段
5.3 OP Fusion (`op_fusion.py`)
连续 Filter 可融合为 FusedFilter:
- 共享中间变量(INTER_LINES, INTER_WORDS, LOADED_IMAGES 等)
- 策略:greedy(默认)或 probe(按探测速度重排)
- 避免重复分词、加载图像等,显著提速
5.4 Mixins (`mixins.py`)
- EventDrivenMixin:事件注册、轮询、超时等待
- NotificationMixin:Email / Slack / DingTalk 通知(长任务完成告警)
5.5 特殊 Registry
OPERATORS # 全部算子
UNFORKABLE # 不能用 fork 的 OP(需 spawn)
NON_STATS_FILTERS # 不产生 stats 的 Filter
TAGGING_OPS # 产生 meta 标签的 OP
ATTRIBUTION_FILTERS
FUSION_STRATEGIES
FORMATTERS # 格式加载器
5.6 内置字段约定 (`utils/constant.py`)
|---------------------|---------------------|
| 字段 | 含义 |
| dj__stats | Filter 产生的统计量 |
| dj__meta | Mapper 产生的元数据/标签 |
| dj__source_file | 样本来源文件 |
| MetaKeys.* | 情感、意图、主题等结构化 meta 键 |
6. 数据格式层 (`data_juicer/format/`)
load_formatter() 按文件后缀自动选择 Formatter:
|------------------|-------------------------|
| Formatter | 支持后缀 |
| JsonFormatter | .json, .jsonl, .json.gz |
| CsvFormatter | .csv |
| TsvFormatter | .tsv |
| ParquetFormatter | .parquet |
| TextFormatter | 纯文本 |
| EmptyFormatter | 空/占位 |
支持目录批量加载、S3、压缩格式。
7. 数据分析 (`data_juicer/analysis/`)
Analyzer 流程:
加载数据集
对所有 Filter OP 计算 stats
运行分析器:
-
OverallAnalysis:整体分布
-
ColumnWiseAnalysis:列级统计
-
CorrelationAnalysis:相关性
-
DiversityAnalysis:多样性
导出统计表与图表到 work_dir/analysis/
8. 工具层 (`data_juicer/utils/`)
按职责划分的主要工具:
|--------------------------------|----------------|
| 模块 | 功能 |
| registry.py | 插件注册机制 |
| cache_utils.py / ckpt_utils.py | 缓存与 checkpoint |
| process_utils.py | 多进程、并行度计算 |
| ray_utils.py | Ray 初始化与模式检测 |
| model_utils.py | 模型加载/释放 |
| lazy_loader.py | 延迟 import 重依赖 |
| llm_semantic_ops.py | LLM 语义算子公共逻辑 |
| s3_utils.py | S3 读写 |
| file_utils.py | 路径、后缀查找 |
| job/ | 作业监控、快照、停止 |
可选依赖分组(pyproject.toml):generic, vision, nlp, audio, distributed 等,默认安装精简,按需 dj-install 或 uv pip install py-data-juicervision,nlp。
9. 扩展工具与生态 (`data_juicer/tools/`)
|---------------------|---------------------------|
| 工具 | 说明 |
| quality_classifier/ | 数据质量分类器训练/预测 |
| hpo/ | 超参优化(WandB、3-sigma) |
| mcp_server.py | Model Context Protocol 服务 |
| op_search.py | 算子搜索 |
| DJ_mcp_* | MCP Recipe 与细粒度 OP 集成 |
Demos 覆盖:简单处理、Agent bad-case、质量分类、LLM 语义 OP 等场景。
10. 三种使用方式
方式 A:YAML + CLI(生产常用)
dj-process --config demos/process_simple/process.yaml
方式 B:Python API(灵活集成)
from data_juicer.core.data import NestedDataset
from data_juicer.ops.filter import TextLengthFilter
from data_juicer.ops.mapper import WhitespaceNormalizationMapper
ds = NestedDataset.from_dict({"text": "Short", "This passes.", "Text with spaces"})
res = ds.process(TextLengthFilter(min_len=10), WhitespaceNormalizationMapper())
方式 C:Ray 分布式(超大规模)
executor_type: ray # 或 ray_partitioned
Ray 模式支持 OP 级 runtime_env 隔离依赖、GPU Actor、vLLM Pipeline。
11. 设计模式总结
|---------------------|-------------------------------------------|
| 模式 | 体现 |
| Registry 插件 | OP/Formatter/Validator 均可注册扩展 |
| Recipe-first | YAML 描述可版本化的数据处理流水线 |
| Strategy | Executor、Fusion、DAG 执行策略可切换 |
| Mixin | DAG、EventLog、Notification 横切关注点 |
| Builder | DatasetBuilder 统一多种数据源 |
| Template Method | OP.run() → 子类 process() / compute_stats() |
| Adapter | 资源探测与 batch 自适应 |
| Lazy Loading | 重依赖(Ray、torch)按需加载 |
12. 代码阅读建议路径
若你想深入某个方向,可按此顺序阅读:
- 入门:tools/process_data.py → config/config.py → demos/process_simple/process.yaml
- 执行链路:core/executor/default_executor.py → core/data/dj_dataset.py
- 算子开发:ops/base_op.py → 任选一个简单 OP(如 whitespace_normalization_mapper.py)
- 性能优化:ops/op_fusion.py → core/adapter.py
- 分布式:core/executor/ray_executor.py → ops/op_env.py
- 数据分析:core/analyzer.py → analysis/overall_analysis.py
13. 版本与能力边界(v1.5.2 亮点)
- 语义 LLM OP:llm_extract_mapper, llm_condition_filter, llm_structured_ops
- Agent 数据质量:trace 连贯性、bad-case 信号、工具相关性等
- 跨文档行级去重:DocumentLineDeduplicator
- Partitioned Ray Executor:分区执行 + OP 级环境隔离
- Embodied AI:视频标定、去畸变、手部重建、全身姿态等
- S3 I/O、压缩 JSONL、加密导出、Ray Tracer
14. 相关文档
- Quick Start(中文)(tutorial/QuickStart_ZH.md)
- 开发者指南(中文)(DeveloperGuide_ZH.md)
- 算子列表(Operators.md)
- 分布式处理(Distributed_ZH.md)
- 缓存机制(Cache_ZH.md)
- 导出说明(Export_ZH.md)
- 追踪与调试(Tracing_ZH.md)
- 中文文档(文档 --- Data Juicer Agents)
- github(GitHub - datajuicer/data-juicer: Data processing for and with foundation models! 🍎 🍋 🌽 ➡️ ➡️🍸 🍹 🍷 · GitHub)