基座模型是什么?怎么理解?------从原理到实战,一篇讲透
作者 :Weisian
发布时间:2026年4月

直击痛点:
"面试官:'大模型的基座模型是什么?'你:'就是预训练好的模型......'面试官:'那基座模型和微调后的模型有什么区别?为什么不能直接用基座模型做对话?'你:'呃......这个......'------这就是基座模型理解不深的'死亡问答':看似基础的概念,却能暴露你对大模型完整生命周期的认知盲区。"
在大模型应用落地中,**基座模型(Base Model)**是一切的起点,却也是最容易被误解的核心概念:
- 开发者:以为LLaMA、Qwen下载下来就能直接当"助手"用,结果问一句"你好"得到一篇论文续写;
- 算法工程师:分不清"预训练"和"微调"的边界,不知道什么时候该从零训练、什么时候该用基座模型;
- 产品经理:听到"行业大模型"以为是从零训练的,结果发现只是基座模型+微调;
- 面试者:背了"基座模型是大模型的基础"的定义,却说不清为什么ChatGPT比GPT-3"好用"。
解决方案:深入理解基座模型的本质、训练过程和实际应用,掌握一套逻辑严密、生动易懂的解释框架。
📌 核心一句话 :
基座模型是大模型的"毛坯房",是只经过大规模无监督预训练、未做任何人类对齐的原始模型,掌握通用语言规律与世界知识,但不会听话、不会对话,只会"续写文本"。
📌 面试金句先记牢:
- 基座模型定义:仅通过海量文本无监督预训练得到的原始大模型,无人类对齐,核心能力是文本续写,是所有垂类/对话模型的基础。
- 核心能力 :学习语言规律、世界知识、逻辑推理、代码能力,不会对话,只会补全。
- 为什么不能直接用:没有对齐人类意图,答非所问、输出混乱、无安全性约束。
- 与对话模型区别:基座=毛坯房,对话模型=精装修房,SFT/DPO=装修过程。
- 与垂类模型区别:基座是通用底座,垂直模型是基座+领域数据微调后的"定制款"。
- 预训练 vs 微调:预训练是"通识教育"(学语法、常识、推理),微调是"专业培养"(学对话、合规、特定任务);
- ChatGPT的秘密:GPT-3是基座模型,ChatGPT是基座模型 + 指令微调 + RLHF对齐的产物;
- 行业误解:所谓的"行业大模型"绝大多数是基座模型 + 领域微调,而非从零训练;
- 规模定律:基座模型的性能随参数量、数据量、计算量的增加而可预测地提升;
- 基座选型关键:参数量、上下文窗口、预训练数据、语言适配度、推理性能。
- 工程价值:统一底座、降低训练成本、快速迭代垂类模型、保障能力下限。
- 从通用到专用:基座模型 → 指令微调 → RLHF对齐 → 可用的AI助手;
- 本地部署要点:基座模型需配合提示工程、微调或对齐才能落地,Ollama可直接加载运行。
一、基座模型到底是什么?
1.1 一句话概括
基座模型(Foundation Model) = AI世界的"基础教育"
基座模型(Base Model / Pre-trained Model) ,是大模型在仅完成预训练阶段 后的原始形态,它学习了海量文本中的语言规则、知识、逻辑,但没有接受过任何人类指令学习,本质是一个"文本续写机器"。

1.2 类比:毛坯房 vs 精装修房
把大模型落地比作装修房子:
- 基座模型 = 毛坯房
结构牢固、空间完整、水电通了,但没有墙面、没有家具、不能直接住人,只能作为后续改造的基础。 - SFT有监督微调 = 基础装修
刷墙、铺地、装门窗,让房子能满足基本居住需求。 - DPO/RLHF对齐 = 精细化软装
摆家具、调风格、适配居住习惯,住起来舒服、贴心。 - 垂类模型 = 主题精装房
比如改成"医疗诊所""法律办公室""客服门店",专门服务某一场景。
关键结论 :
基座模型不能直接上线服务用户,就像毛坯房不能直接拎包入住,必须经过后续"装修"(对齐/微调)才能用。

1.3 基座模型的完整诞生流程
海量开源文本(书籍、网页、论文、代码)
↓
无监督预训练(Next Token Prediction,预测下一个Token)
↓
基座模型(Base Model)------【本文核心】
↓
SFT有监督微调(指令数据学习对话)
↓
DPO/RLHF人类对齐(符合人类偏好、安全规范)
↓
对话模型/Chat模型(如Qwen Chat、Llama Chat、GPT-3.5/4)
↓
垂类微调(行业数据+场景数据)
↓
行业垂类模型(医疗大模型、法律大模型、客服大模型)
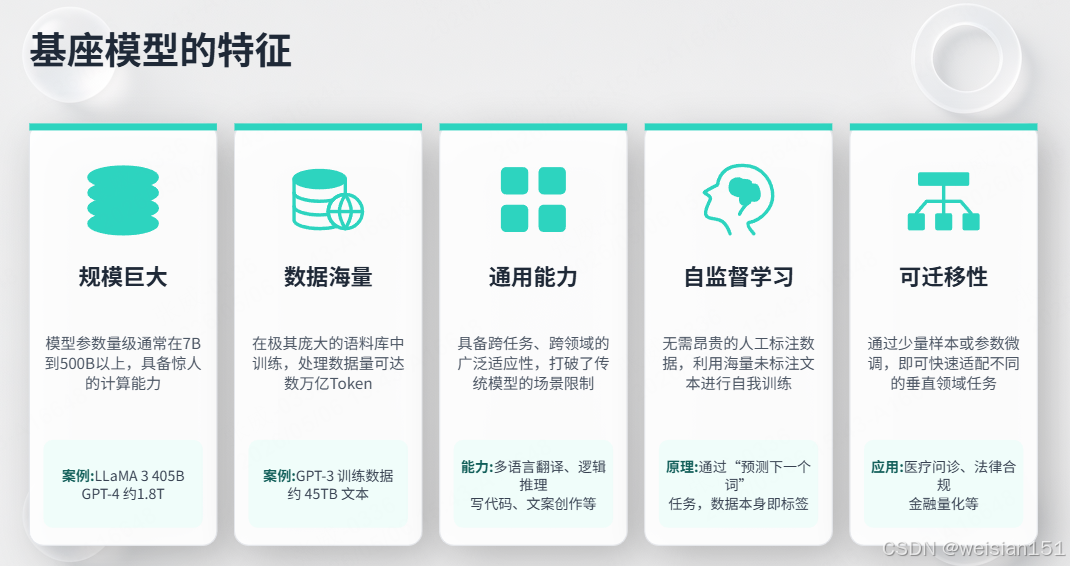
1.4 基座模型的特征
| 特征 | 说明 | 举例 |
|---|---|---|
| 规模巨大 | 参数量通常在7B-500B+ | LLaMA 3 405B、GPT-4 约1.8T |
| 数据海量 | 训练数据达数万亿Token | GPT-3用了45TB文本 |
| 通用能力 | 跨任务、跨领域 | 能写诗、编程、翻译、总结 |
| 自监督学习 | 不需要人工标注 | 预测下一个词,数据本身是标签 |
| 可迁移性 | 可通过微调适配各种任务 | 医疗、法律、金融垂直领域 |
1.5 基座模型的核心行为:只续写,不对话
这是基座模型最容易被误解的点:
- 你问它问题 :它不会直接回答,而是顺着你的话继续写;
- 它没有对话意识:不知道你在提问,只知道"下一个Token应该是什么";
- 典型表现:答非所问、无限续写、输出杂乱无逻辑。
生活类比 :
基座模型就像一个只会接话的小说续写机器人 。
你说:"今天天气真好",它不会回答"是啊",而是续写:"今天天气真好,阳光洒在街道上,行人纷纷脱下外套,鸟儿在枝头歌唱......"

1.6 "基座模型"这个名字的由来
这个术语由斯坦福大学HAI研究中心在2021年正式提出。为什么叫"Foundation Model"而不是"Large Model"?
| 候选名称 | 问题 | 为什么不准确 |
|---|---|---|
| 大模型 | 只强调规模,忽略了本质 | 参数量大是结果,不是定义 |
| 预训练模型 | 暗示"后面才是正事" | 预训练本身就是核心 |
| 语言模型 | 太窄,无法涵盖多模态 | 现在的基座模型能看、能听、能说 |
"Foundation"的含义:
基座模型是AI系统的"基础"------它不是一个产品,而是构建产品的"底座"。就像建造摩天大楼需要先打地基,开发AI应用需要先有基座模型。
面试加分回答:
"基座模型的核心是'通用能力'。它不是在某个特定任务上训练出来的专家,而是在海量数据上学习到的'通才'。这种通用性使其能够通过微调适配无数下游任务,这是它与传统任务专用模型的本质区别。"

1.7 基座 vs 对话模型 vs 垂类模型:一张表看懂
| 模型类型 | 训练阶段 | 核心能力 | 行为特点 | 能否直接上线 | 类比 |
|---|---|---|---|---|---|
| 基座模型 | 仅预训练 | 文本续写、通用知识 | 只会补全,不会对话 | ❌ 不能 | 毛坯房 |
| 对话模型 | 预训练+SFT+DPO | 指令理解、多轮对话 | 听话、回答问题、有逻辑 | ✅ 能 | 精装修房 |
| 垂类模型 | 基座+领域微调 | 专业场景能力 | 垂直领域精准输出 | ✅ 能 | 主题定制房 |

二、基座模型是怎么训练出来的?------从零到一的全流程
2.1 一张图看懂基座模型训练
【基座模型训练全过程】
┌─────────────────────────────────────────┐
│ Stage 1: 数据收集 │
│ 互联网爬取、书籍、论文、代码、多语言 │
│ 数据量:数万亿Token(PB级别) │
└─────────────────┬───────────────────────┘
▼
┌─────────────────────────────────────────┐
│ Stage 2: 数据清洗 │
│ 去重、过滤低质量、隐私脱敏、安全审查 │
│ 数据量:清洗后保留10%-30% │
└─────────────────┬───────────────────────┘
▼
┌─────────────────────────────────────────┐
│ Stage 3: Tokenization │
│ 用BPE等算法将文本切分成Token │
│ 词汇表大小:50K-150K │
└─────────────────┬───────────────────────┘
▼
┌─────────────────────────────────────────┐
│ Stage 4: 预训练 │
│ 自监督学习:预测下一个Token │
│ 算力:数千到数万张GPU,训练数月 │
│ 损失函数:交叉熵损失 │
└─────────────────┬───────────────────────┘
▼
┌─────────────────────────────────────────┐
│ Stage 5: 基座模型 │
│ 具备通用能力,但不会"对话" │
│ 可直接用于续写、特征提取、作为微调起点 │
└─────────────────────────────────────────┘
2.2 预训练的"魔法":自监督学习
基座模型的核心训练方法是自监督学习------不需要人工标注,数据本身就是标签。
核心任务:预测下一个Token
给定前文"今天天气真",让模型预测下一个Token应该是"好"还是"坏"。
如果训练数据中"今天天气真好"出现了1000次,"今天天气真坏"出现了10次,模型就会学会:在"今天天气真"后面,更大概率是"好"。
生活类比:
这就像你给一个孩子看大量英文句子,他不需要你告诉他"语法规则",看着看着就自己学会了"主谓宾"的顺序。这就是"从数据中涌现的规律"。

2.3 预训练的三要素:规模定律(Scaling Law)
OpenAI的研究发现,基座模型的性能与三个因素呈幂律关系:
| 要素 | 说明 | 规律 |
|---|---|---|
| 参数量 | 模型的大小 | 参数量翻倍,性能提升约10% |
| 数据量 | 训练Token数量 | 数据量翻倍,性能提升约10% |
| 算力量 | GPU计算量(FLOPs) | 三者中影响最大 |
规模定律公式(简化版):
模型性能 ≈ (参数量)^α × (数据量)^β × (算力量)^γ生活类比:
就像盖楼。你想盖100层(性能),需要:
- 足够深的地基(参数量)
- 足够多的钢筋水泥(数据量)
- 足够大的施工队(算力量)
三者缺一不可。光有地基没有材料,盖不起来;光有材料没人施工,也盖不起来。
重要发现:
当模型规模超过某个阈值(约10B参数)时,会"涌现"出小模型没有的能力------比如推理、代码生成、多步骤思考。这就是为什么大厂拼命卷模型规模。

2.4 唯一目标:Next Token Prediction(预测下一个Token)
基座模型的预训练没有任何人类标注,只有一个简单到极致的目标:
根据前面的所有Token,预测下一个最可能出现的Token
这就是基座模型所有能力的来源:语言逻辑、世界知识、推理能力,全是靠"猜下一个字"学出来的。
生活类比 :
就像你做完形填空 ,一篇文章挖掉后面的字,让你猜下一个字是什么。
做了10亿道完形填空后,你自然懂语法、懂常识、懂逻辑,这就是基座模型的学习方式。

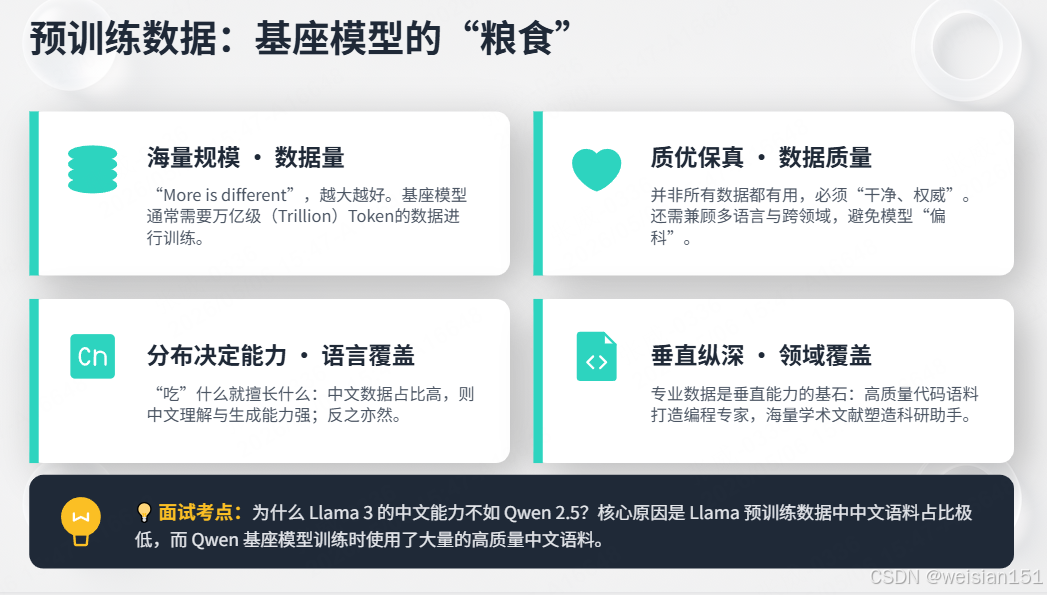
2.5 预训练数据:基座模型的"粮食"
基座模型的能力上限,完全由预训练数据决定:
- 数据量:越大越好,通常万亿级Token;
- 数据质量:干净、权威、多语言、多领域(书籍、论文、代码、百科);
- 语言覆盖:中文数据多→中文能力强,英文数据多→英文能力强;
- 领域覆盖:代码数据多→代码能力强,专业文献多→学术能力强。
面试考点 :
为什么Llama 3中文不如Qwen 2.5?
因为Llama预训练中文数据占比极低,而Qwen基座用了大量高质量中文语料。
2.6 预训练过程:海量算力+超长迭代
基座模型训练是大模型领域成本最高、难度最大的环节:
- 算力:千张A100/H100显卡连续运行数月;
- 参数:7B、14B、34B、72B、110B......参数量越大能力越强;
- 优化目标:最小化预测下一个Token的损失函数;
- 结果 :模型掌握通用语言模式与世界知识,形成通用智能底座。
生活类比 :
基座模型训练就像一个人从小读遍全世界所有书籍,不接受任何老师教导,只自己看书、理解文字规律,最后变成一个知识渊博但不会与人交流的"书呆子"。
三、基座模型 vs 微调模型:核心区别
这是面试最高频的考点:基座模型和微调后的模型有什么区别?
3.1 一张表看懂区别
| 维度 | 基座模型 | 微调模型 |
|---|---|---|
| 训练数据 | 海量、多样化(PB级) | 少量、任务特定(GB级) |
| 训练目标 | 预测下一个Token | 执行特定任务 |
| 能力特征 | 通才,跨领域 | 专才,任务特化 |
| 是否可用 | 直接可用但不"好用" | 开箱即用 |
| 典型输出 | "文本续写" | "回答问题" |
| 训练成本 | 极高(数百万美元) | 可控(数百到数千美元) |
| 谁来做 | 大厂/研究机构 | 中小团队/企业 |
| 典型例子 | GPT-3、LLaMA、Qwen-Base | ChatGPT、CodeLlama、医疗模型 |

3.2 生活类比:大学教育
基座模型 = 高中毕业生
- 学了语文、数学、英语、物理、化学、历史......
- 知识全面,但没有"专业"
- 不能直接上岗工作
微调模型 = 大学毕业生
- 在高中基础上选择了专业(计算机/医学/法律)
- 知识专精,能胜任特定岗位
- 可以"开箱即用"
RLHF对齐模型 = 有工作经验的职场人
- 不仅懂专业知识,还懂"沟通技巧"、"职场礼仪"
- 知道什么话该说、怎么说更好

3.3 基座模型有什么能力?
- 语言建模能力
精通语法、句式、文风,能流畅续写文本。 - 世界知识储备
记住海量常识、历史、科学、文化知识。 - 逻辑与推理能力
具备数学推理、因果推断、模式识别能力。 - 代码能力
能理解代码语法、编写简单程序、排查bug。 - 泛化能力
能处理从未见过的文本,具备零样本基础能力。

3.4 基座模型绝对没有的能力(致命边界)
- 不会理解指令
你说"帮我写总结",它不会执行,只会续写。 - 没有对话意图
分不清提问、陈述、命令,只会机械补全。 - 无安全性约束
可能输出有害、偏见、错误内容。 - 无人类偏好对齐
输出冗长、混乱、不符合用户预期。 - 无垂直领域专精能力
通用但不专业,医疗、法律等领域精度低。

3.5 为什么基座模型不能直接当助手用?
核心原因:基座模型学的是"文本概率分布",不是"指令遵循"。
# 基座模型的"思维"方式
输入:"法国的首都是"
模型思考:"根据训练数据,'法国的首都是'后面最常见的词是'巴黎'"
输出:"巴黎"
# 但如果你问
输入:"法国的首都是什么?"
模型思考:"'法国的首都是什么?'这个问句在训练数据中出现较少,但'法国的首都是'出现很多"
输出:"巴黎" # 还是会输出正确结果,因为问号不影响
# 真正的问题来了
输入:"你好"
模型思考:"'你好'在训练数据中最常见的续写是',世界'、',欢迎'等"
输出:"你好,世界!今天天气真好。" # 而不是 "你好!有什么可以帮你的?"
# 更糟糕的情况
输入:"请告诉我法国的首都"
模型思考:"'请告诉我法国的首都'这个句式模型没见过"
输出:可能乱七八糟的续写,或者重复问题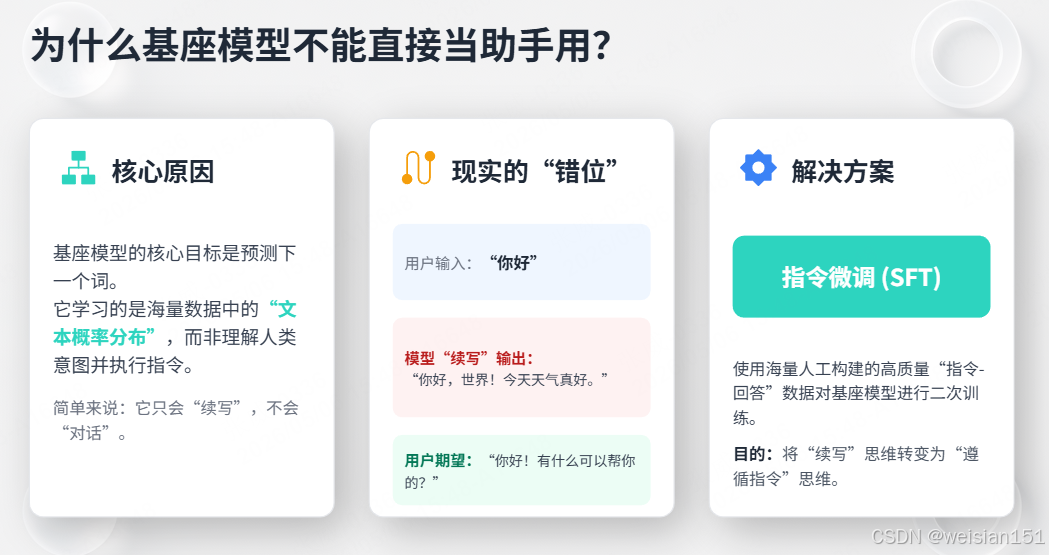
解决方案 :指令微调(Instruction Tuning)
用大量"指令-回答"对数据微调基座模型,教会它"当用户问问题时,应该回答问题,而不是续写文本"。
python
# 指令微调数据示例
instruction_data = [
{
"instruction": "法国的首都是什么?",
"response": "法国的首都是巴黎。"
},
{
"instruction": "你好",
"response": "你好!有什么我可以帮你的吗?"
},
{
"instruction": "请告诉我2+2等于多少",
"response": "2+2等于4。"
}
]
# 微调后,模型学会:看到"指令"格式 → 输出"回答"格式3.6 从基座模型到ChatGPT的完整路径
这是大模型训练的完整流程:
Stage 1: 预训练(Pre-training)
↓
基座模型(如GPT-3)
能力:文本续写、知识储备
问题:不会对话、可能输出有害内容
↓
Stage 2: 监督微调(Supervised Fine-Tuning, SFT)
↓
SFT模型
能力:遵循指令、问答格式
数据:人工标注的"指令-回答"对(约10K-100K条)
问题:可能"讨好"用户、缺乏安全性
↓
Stage 3: 奖励模型训练(Reward Modeling, RM)
↓
奖励模型
能力:判断哪个回答"更好"
数据:人工标注的"回答偏好对"(A比B好)
↓
Stage 4: 强化学习(RLHF/PPO/DPO)
↓
ChatGPT / GPT-4
能力:有用、诚实、无害
特点:会拒绝不安全请求、回答风格自然关键洞察:
ChatGPT不是从零训练的,而是在GPT-3.5(基座模型)的基础上,经过指令微调和RLHF对齐得到的。这也是为什么OpenAI不开放GPT-3基座模型------它"能力很强但方向不对",容易被滥用。

四、为什么一定要用基座模型?(工程价值)
4.1 降低研发成本:不用从零训练
训练一个基座模型需要数亿资金+顶级算力 ,99%企业/团队承担不起。
基座模型相当于"开源通用底座",拿来微调即可,成本降低99%。
生活类比 :
买毛坯房自己装修,比从头盖房子便宜10倍,速度快100倍。

4.2 统一能力底座,保障效果下限
所有垂类模型都基于同一基座,能力稳定、可复用、易维护。
避免每个场景单独训练,导致效果参差不齐。
4.3 快速迭代垂类模型
基于基座做行业微调,只需要少量领域数据+短时间训练,即可上线可用的垂类模型。

4.4 灵活适配不同部署场景
基座模型可量化为INT4/INT8,适配本地CPU、GPU、边缘设备,Ollama可一键部署。
五、基座模型后续进化路径(SFT/DPO/垂类微调)
基座模型必须经过"进化"才能落地,完整路径如下:
5.1 第一步:SFT有监督微调(基础装修)
- 目标 :让模型学会理解指令、执行任务;
- 数据:人工构造的<指令, 回答>对;
- 效果:模型能听懂问题、简单对话、完成基础任务。

5.2 第二步:DPO/RLHF人类对齐(精细化软装)
- 目标 :让模型输出符合人类偏好、安全、有用、简洁;
- 方法:DPO(直接偏好优化)/RLHF(基于人类反馈强化学习);
- 效果:对话自然、逻辑清晰、拒绝有害请求、体验接近商用模型。
5.3 第三步:垂类微调(主题定制)
- 目标 :强化垂直领域专业能力;
- 数据:医疗/法律/客服/金融等行业专属数据;
- 效果:专业精度高、场景适配强,可直接商用。

类比总结:
基座模型(毛坯)
↓ SFT(刷墙铺地)
对话基础模型(简装)
↓ DPO(软装适配)
通用对话模型(精装)
↓ 垂类微调(主题定制)
行业垂类模型(专属空间)六、基座模型的行业应用与误解
6.1 自动驾驶领域的基座模型
基座模型的概念不仅限于NLP,也正在向物理世界扩展。
小鹏汽车的基座模型战略:
小鹏提出用海量真实驾驶数据训练一个"视觉基座模型",然后通过蒸馏、剪枝、量化等技术,将大模型压缩后部署到车端硬件上。
核心思路:
云端:超大基座模型(数百亿参数)← 用海量数据训练
↓ 蒸馏/剪枝/量化
车端:轻量模型(数亿参数)← 部署在车载芯片上元戎启行的VLA基座模型:
以400亿参数的VLA(视觉-语言-动作)基座模型为核心,将场景理解、驾驶决策和安全评估统一到同一套模型架构中。
生活类比:
这就像一位赛车教练(云端大模型)把所有经验教给学生(车端小模型)。教练开过数百万公里,知道所有路况的处理方法;学生虽然开得少,但继承了教练的"经验精髓"。

6.2 行业大模型的常见误解
这是面试中的进阶考点:什么是真正的"行业大模型"?
| 误解 | 真相 |
|---|---|
| "我们从头训练了一个医疗大模型" | 99%的情况是在LLaMA/Qwen上微调的 |
| "行业大模型比通用模型更懂行业" | 微调只能注入"知识",不能改变"推理框架" |
| "基座模型越大越好" | 越大越难部署,需要权衡 |
面试金句:
"所谓的'行业大模型',绝大多数是基座模型 + 领域微调。真正从零训练一个行业基座模型,需要千亿级的高质量行业数据,这是绝大多数企业不具备的。理解这一点,才能避免被'大模型'的概念炒作误导。"

6.3 FunctionGemma:轻量级基座模型的例子
Google发布了FunctionGemma,一个270M参数的轻量级基座模型,专门为函数调用设计。
python
# FunctionGemma 使用示例
import json
from ollama import chat
# FunctionGemma 是一个基座模型,需要微调后才能达到最佳效果
# 但它已经具备了函数调用的基本能力
def get_weather(city: str) -> str:
"""获取天气信息的函数"""
return json.dumps({
'city': city,
'temperature': 22,
'unit': 'celsius',
'condition': 'sunny'
})
messages = [{'role': 'user', 'content': 'What is the weather in Paris?'}]
response = chat('functiongemma', messages=messages, tools=[get_weather])
if response.message.tool_calls:
tool = response.message.tool_calls[0]
print(f"Calling: {tool.function.name}({tool.function.arguments})")
result = get_weather(**tool.function.arguments)
print(f"Result: {result}")
messages.append(response.message)
messages.append({'role': 'tool', 'content': result})
final = chat('functiongemma', messages=messages)
print('Response:', final.message.content)关键特点:
- 极小体积(270M),可运行在笔记本电脑上
- 专为函数调用设计,是"基座模型"的典型例子
- 官方建议:进一步微调以获得最佳效果
七、基座模型选型:怎么选才对?(实战指南)
7.1 选型核心维度
-
语言适配
中文场景优先选:Qwen系列、DeepSeek系列、Baichuan系列
英文场景优先选:Llama 3、Mistral、Gemma
-
参数量大小
- 7B:本地部署、轻量场景、速度快;
- 14B/34B:平衡性能与效果,主流选择;
- 72B+:高精度需求、复杂推理、专业场景。
-
上下文窗口
长文本场景(RAG、文档总结)选128K+基座(Qwen2.5、Llama 3)。
-
量化支持
本地部署优先选支持INT4/INT8/GGUF量化的基座。
-
开源协议
商用选宽松协议(Apache、MIT),避免合规风险。

7.2 主流开源基座模型对比
| 基座模型 | 语言能力 | 参数量 | 上下文窗口 | 开源协议 | 适配场景 |
|---|---|---|---|---|---|
| Qwen2.5-Base | 中文极强 | 7B/14B/72B | 128K | Apache 2.0 | 中文全场景 |
| DeepSeek-Base | 中文优秀 | 7B/67B | 128K | 商用友好 | 代码+中文 |
| Llama 3-Base | 英文极强 | 8B/70B | 128K | 商用宽松 | 英文场景 |
| Mistral-Base | 英文优秀 | 7B/8x7B | 32K | Apache 2.0 | 轻量推理 |
| Gemma-Base | 英文均衡 | 2B/7B | 8K | Apache 2.0 | 轻量部署 |

八、基座模型常见误区(面试避坑)

误区1:基座模型可以直接当ChatGPT用
❌ 错误
✅ 真相:基座只会续写,不会对话,必须SFT+DPO对齐。
误区2:参数量越大,基座一定越好
❌ 错误
✅ 真相:数据质量>训练框架>参数量,小基座+高质量数据>大基座+垃圾数据。
误区3:基座模型没有任何实用价值
❌ 错误
✅ 真相:基座可用于文本续写、小说生成、代码补全、数据合成等非对话场景。
误区4:所有基座模型都能直接微调
❌ 错误
✅ 真相:部分闭源基座不开放权重,只有开源基座(Qwen/Llama)可微调。
误区5:基座模型的知识是最新的
❌ 错误
✅ 真相:基座知识截止到预训练数据截止日期,无实时知识,需RAG补充。
九、基座模型的未来趋势
9.1 从文本到多模态
早期的基座模型只处理文本,现在的基座模型正在向多模态演进:
| 模态 | 模型示例 | 能力 |
|---|---|---|
| 文本 | GPT-3, LLaMA, Qwen | 语言理解、生成 |
| 图像 | DALL-E, Stable Diffusion | 图像生成 |
| 视觉-语言 | Flamingo, GPT-4V | 看图说话、视觉问答 |
| 物理世界 | VLA模型(元戎启行) | 自动驾驶、机器人控制 |

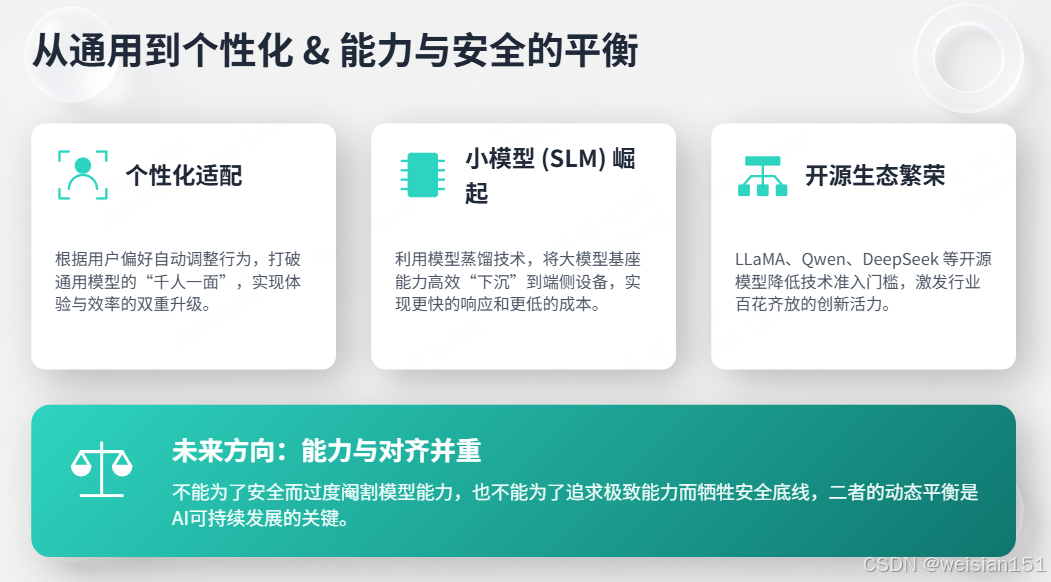
9.2 从通用到个性化
未来的基座模型可能不再是"一个模型服务所有人",而是:
- 个性化适配:根据用户偏好自动调整行为
- 小模型崛起:SLM(小语言模型)+ 蒸馏技术,让基座能力下沉到端侧
- 开源生态:LLaMA、Qwen、DeepSeek等开源模型降低准入门槛
9.3 能力与安全的平衡
基座模型的能力越强,潜在风险越大。未来的方向是"能力与对齐并重"------不能为了安全阉割能力,也不能为了能力牺牲安全。
十、面试高频题详解
Q1:什么是基座模型?它和传统AI模型有什么区别?
参考答案 :
基座模型是在海量数据上预训练的大规模模型,具备跨任务、跨领域的通用能力。
与传统模型的核心区别:
- 传统模型:一个模型做一个任务(如情感分类、翻译),任务专用
- 基座模型:一个模型做所有任务,通过微调适配不同场景
类比:传统模型像瑞士军刀上的单个工具(只能开瓶),基座模型像整个工具箱(什么都能干)。

Q2:为什么基座模型不能直接用于对话?
参考答案 :
基座模型的训练目标是"预测下一个Token",本质是"文本补全器",不是"问答助手"。
举例:
- 用户问"你好" → 基座模型会续写",世界!"(因为训练数据中常见)
- 用户想要的回答是"你好!有什么可以帮你的?"
解决方案:用指令微调(SFT)和RLHF对齐,教会模型"指令-回答"的格式。

Q3:基座模型和微调模型有什么区别?
参考答案:
| 维度 | 基座模型 | 微调模型 |
|---|---|---|
| 训练数据 | 海量、通用(PB级) | 少量、任务特定(GB级) |
| 训练成本 | 数百万美元 | 数百到数千美元 |
| 能力特征 | 通才 | 专才 |
| 是否可用 | 需要二次开发 | 开箱即用 |
关键洞察:基座模型是"半成品",微调模型是"成品"。就像面粉和面包的关系。

Q4:什么是规模定律(Scaling Law)?
参考答案 :
规模定律指出,基座模型的性能随参数量、数据量、计算量的增加而可预测地提升,三者满足幂律关系。
实际意义:
- 模型越大,性能越好(但边际效益递减)
- 数据越多,性能越好(但需要高质量数据)
- 这是大厂"卷"模型规模的理论依据

Q5:什么是"涌现能力"?为什么大模型会有?
参考答案 :
"涌现"指当模型规模超过某个阈值(约10B参数)时,突然出现小模型没有的能力------如推理、代码生成、多步骤思考。
原因:大模型有更多的"参数容量"来存储和组合知识,当规模足够大时,简单的"下一个Token预测"任务会迫使模型学会更高层次的抽象。
类比:就像水加热到100°C突然沸腾------小模型是温水,大模型是开水,量变引起质变。

Q6:所谓的"行业大模型"真的是从零训练的吗?
参考答案 :
绝大多数不是。真正的"行业大模型"需要在海量行业数据上预训练,这需要:
- 千亿级的高质量行业Token
- 数千张GPU
- 数百万美元成本
现实:99%的"行业大模型"是在LLaMA、Qwen等开源基座模型上微调得到的。
面试加分:理解这一点,能避免被概念炒作误导。

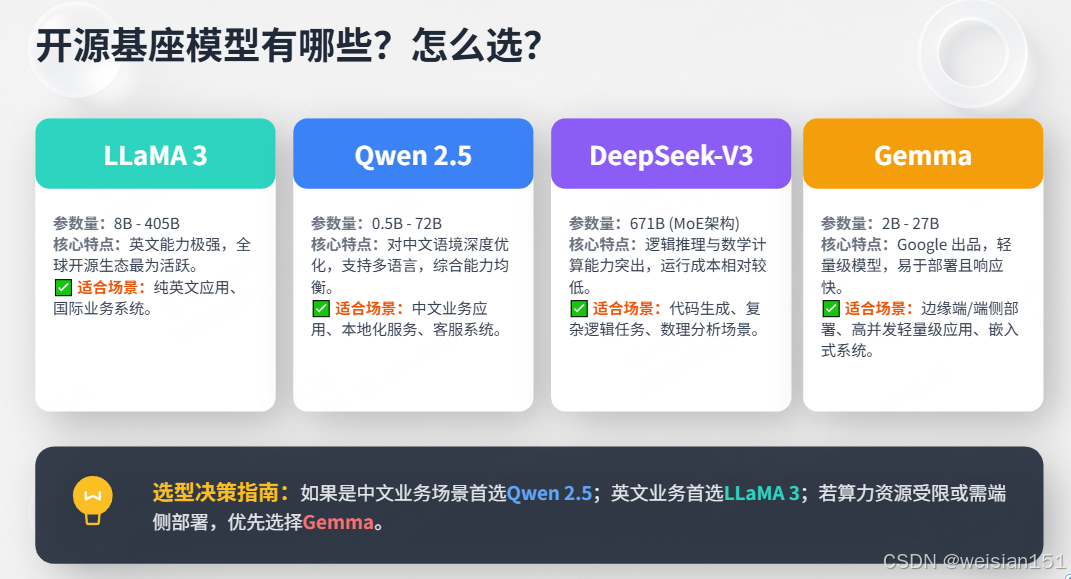
Q7:开源基座模型有哪些?怎么选?
参考答案:
| 模型 | 参数量 | 特点 | 适合场景 |
|---|---|---|---|
| LLaMA 3 | 8B-405B | 英文能力强,开源生态好 | 英文应用 |
| Qwen2.5 | 0.5B-72B | 中文优化好,多语言 | 中文应用 |
| DeepSeek-V3 | 671B | 推理能力强,成本低 | 高难度任务 |
| Gemma | 2B-27B | Google出品,轻量 | 端侧部署 |
选型建议:
- 中文场景首选Qwen
- 英文场景首选LLaMA 3
- 资源受限选Gemma 2B/7B
总结
核心知识点速记
基座模型是底座,通识教育打基础。
海量数据预训练,学会语法和常识。
规模定律定上限,参数数据算力足。
预测下一个Token,本质是文本补全器。
不能直接当助手,需要微调和对齐。
SFT教它遵指令,RLHF教它懂人心。
行业模型多微调,从零训练门槛高。
开源模型百花放,QwenLLaMA是首选。
话术速查表
| 问题类型 | 回答时间 | 核心要点 |
|---|---|---|
| 什么是基座模型 | 10秒 | 海量数据预训练的通才模型,是AI应用的"底座" |
| 和传统模型区别 | 20秒 | 传统模型一个任务一个模型,基座模型一个模型所有任务 |
| 为什么不能直接对话 | 20秒 | 学的是"续写文本",不是"回答问题" |
| 预训练 vs 微调 | 20秒 | 预训练是"通识教育",微调是"专业培养" |
| ChatGPT的秘密 | 20秒 | 基座模型 + 指令微调 + RLHF对齐 |
| 规模定律 | 15秒 | 性能随参数、数据、算力增加可预测提升 |
| 行业大模型真相 | 20秒 | 99%是基座模型+微调,不是从零训练 |
| 开源模型怎么选 | 20秒 | 中文Qwen,英文LLaMA,轻量Gemma |
写在最后
基座模型看似只是一个"预训练模型"的新叫法,但它的本质是AI开发范式的革命------从"任务专用"到"通用底座+微调适配":
- 以前,做情感分析要专门训练一个模型,做翻译要专门训练另一个模型;
- 现在,一个基座模型 + 少量微调数据,就能适配无数任务。
面试官问基座模型,不是在考"定义",而是在考察你对大模型完整生命周期、训练成本、工程落地的综合理解。能讲清楚基座模型的人,模型选型、微调策略、成本估算都不会差。
如果觉得有帮助,欢迎点赞、收藏、转发!有问题欢迎在评论区留言交流。