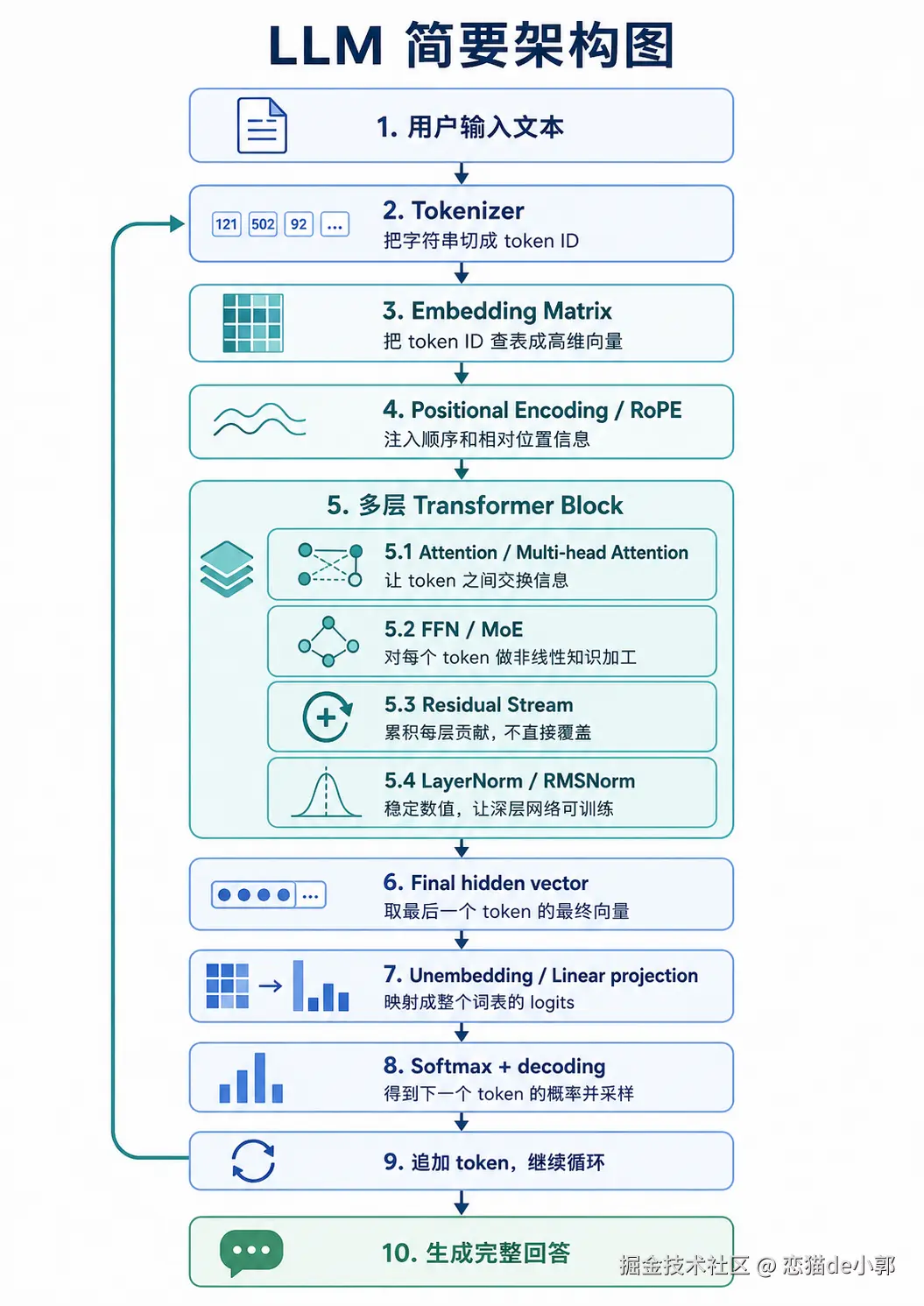
今天刚好看到一篇 《How LLMs Actually Work》 的内容,可以很形象地解释 LLM 究竟是怎么工作的,特别是作者抛开了各种复杂的数学原理,还能直观让你理解 LLM 是怎么工作的。
简单来说, LLM 大多是把 Transformer block 一层层堆起来,所以只要理解 token、embedding、位置编码、attention、FFN、残差流、归一化、next-token prediction,基本就能看懂很多论文和模型在讲什么,而且可以换个角度理解。
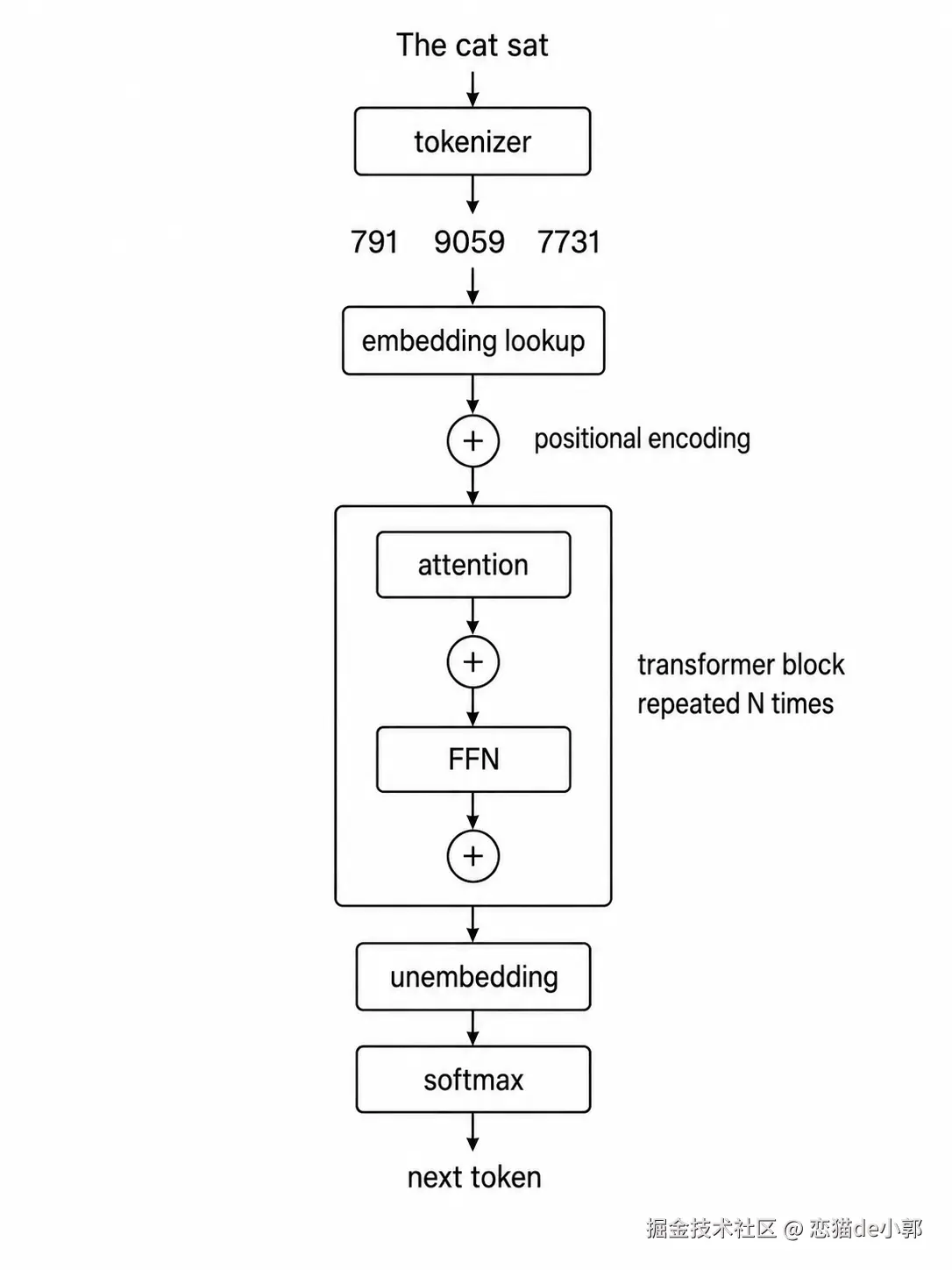
这个图说的就是, LLM 要理解一句话并给出回答,正常来说它需要:
- 先把文本切成 token ID
- 再变成高维向量
- 加入位置信息
- 通过多层 Transformer 让 token 互相交换信息
- 做局部和全局变换
- 把最后一个 token 的向量映射成下一个 token 的概率分布,然后一个 token 一个 token 地采样生成完整回答
看不懂?没事,后面看完就理解了,简单来说就是:
LLM 的一次生成,是每一步都在问:基于目前所有上下文,下一个最合理的 token 是什么?
1. Tokenization:模型不读文字,只读整数
这个其实很重要,LLM 不直接处理自然语言字符串,而是先通过 tokenizer 把文本变成一串整数 ID,每个整数对应词表里的一个 token。
所以 token 不一定是单词,也不一定是字符,更多时候是 subword ,比如:
css
tokenization -> ["token", "ization"]
running -> ["run", "ning"]因为如果用整个单独作表,词表会太大,而且遇到新词泛化会变差,如果字符级别词表太小,就会导致序列太长,所以:
subword 是折中方案,常见片段作为单独 token,罕见词或新词通过更小片段拼出来。
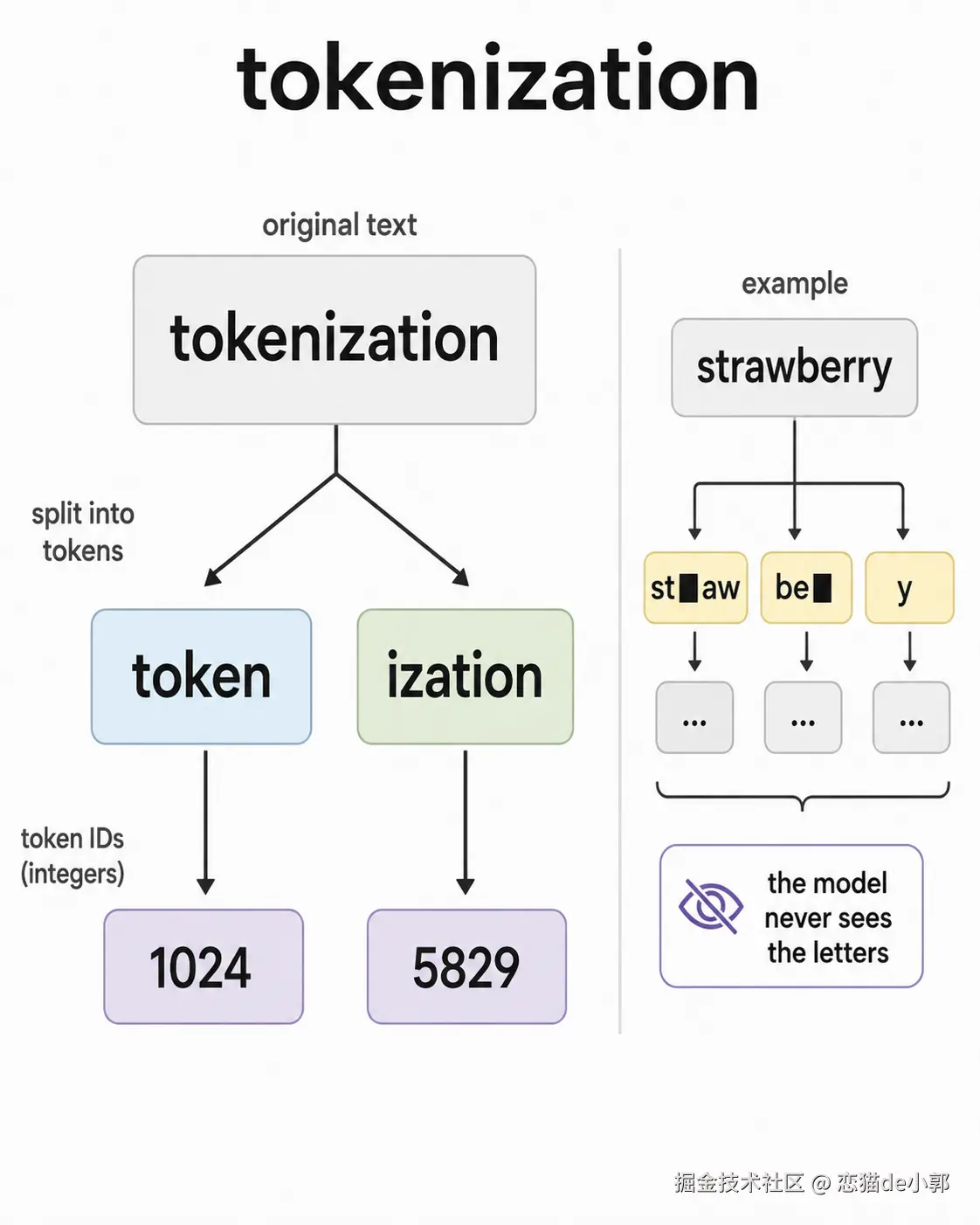
这就可以解释了 LLM 里一个经典现象:
LLM 有时数不清 "strawberry" 里有几个 r,不是因为模型完全不会数数,而是因为它不是天然按字母处理文本,而是按 token ID 处理。
另外,不同模型家族 tokenizer 不同,一半来说,GPT 系列常用 BPE 变体,LLaMA 风格模型常见 SentencePiece ,所以简单来说,tokenizer 类似 LLM 世界里的"输入法 + 压缩器 + 词表协议" 。
同一句话,在不同 tokenizer 下可能变成不同 token 数,这会直接影响上下文长度、价格、速度和模型对某些语言/符号的处理能力。
2. Embeddings:整数本身没意义,要变成向量
前面说的 token ID 只是一个索引,比如 1024 本身不代表任何语义,模型真正处理的是 embedding,也就是从 embedding matrix 里查出来的一行高维向量。
比如 7B 级别模型的 hidden size 可能是 4096,也就是每个 token 会被映射成一个 4096 维向量,更大的模型通常会有更宽的向量。
是不是看着又开始懵了 ?简单来说,可以把 hidden size = 4096 理解成:
模型不是用一个词来理解一个 token,而是给每个 token 做了一张「4096 项特征表」。
比如 token 是 苹果 ,人看到"苹果" 可能会想到:
水果
甜的
红色/绿色
公司 Apple
手机
乔布斯
中文词
名词
可以吃
科技品牌
......但模型不会用中文标签写这些特征,它会把苹果 变成一串数字,大概像:
csharp
[0.12, -0.48, 0.03, 1.27, ...] 共 4096 个数字这 4096 个数字不是随机的,而是模型训练出来的"含义坐标",你可以粗暴理解成:
每个 token 都被放进一个 4096 维的语义空间里,4096 个维度一起描述它的意思、语法、上下文潜力和各种隐含特征。
比如只用一个数字描述 苹果 ,大概可能是:
苹果 = 8
香蕉 = 7
手机 = 3如果是二维就是:
甜度、科技感苹果水果可能是:
甜度 9,科技感 1Apple 公司可能是:
甜度 0,科技感 10而 4096 维就是超级复杂的「含义雷达图」,它不是只看甜度、科技感,而是同时看几千个隐含方向:
是不是名词
是不是品牌
是不是食物
是不是中文
和水果相关程度
和手机相关程度
和公司相关程度
和颜色相关程度
和代码上下文相关程度
和句子主语相关程度
......当然真实维度不是这么人工命名的,但是大概理解就是这样,所以:
hidden size 4096 = 模型用 4096 个数字来表示每个 token 当前的"状态"。
而且需要注意的是,不只是 token 原始含义,随着 Transformer 一层层处理,这个 4096 维向量也会不断变化,所以关键点是:
embedding 不是人工写死的语义表,而是在训练中学出来的,语义相近的 token 会在向量空间中靠得更近,比如 "king" 和 "queen","Paris" 和 "France"。
经典的 embedding 例子就是:king - man + woman ≈ queen
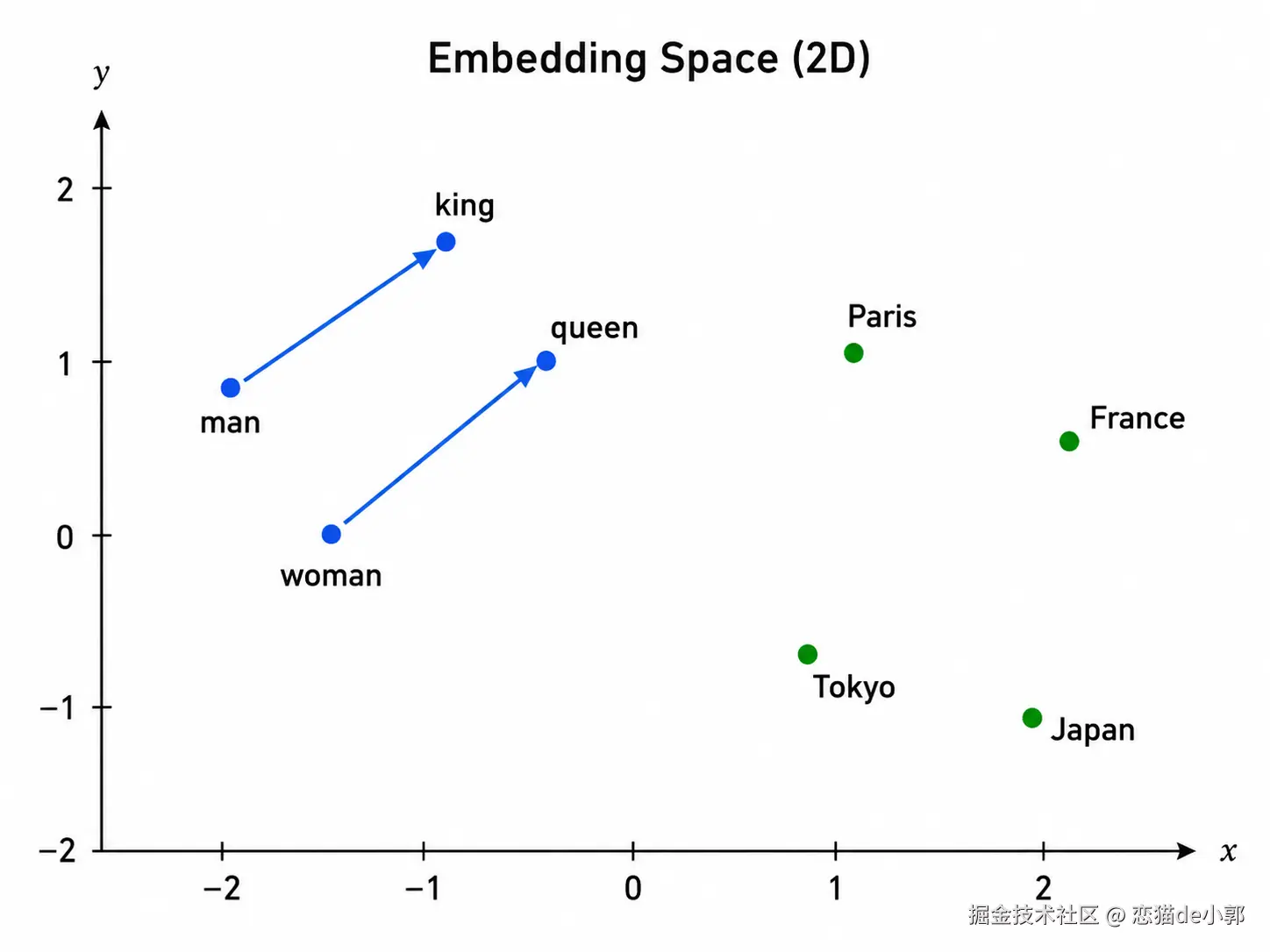
不过 embedding 页有一个问题:它只表示 token 的语义,不表示位置,也就是说 "dog" 出现在句首还是句尾,查出来的基础 embedding 是一样的,所以才会有后续的「位置编码」。
到这里就可以理解:tokenization 把文字变成编号,embedding 把编号变成模型能计算的"语义坐标"。
3. Positional Encoding:模型怎么知道顺序?
纯 self-attention 本身不天然知道词序,如果不给它位置信息,它就无法直接区分 "dog bites man" 和 "man bites dog" ,所以模型必须把 token 的「位置」注入进去。
原始 Transformer 使用正弦/余弦位置编码,把位置信息加到 token embedding 上,这样 "dog at position 1" 和 "dog at position 5" 会变成不同向量。
不需要理解太高深,就是粗暴认为有一组代表顺序的数字就行,不过早期这种 additive positional encoding 有两个问题:
- 语义和位置被塞进同一组数字里,容量有限
- 绝对位置 embedding 对长上下文泛化不好,如果模型训练时只见过 2048 token 长度,那么位置 5000 可能没有被同样充分学习
现在 LLM 大多使用 RoPE,也就是 Rotary Position Embeddings ,它不是把位置向量加到 embedding 上,而是在 attention 里旋转 Query 和 Key 向量,旋转角度取决于 token 的位置。
两个 token 做 attention 比较时,Query 和 Key 的相对旋转差异就编码了它们之间的相对距离。
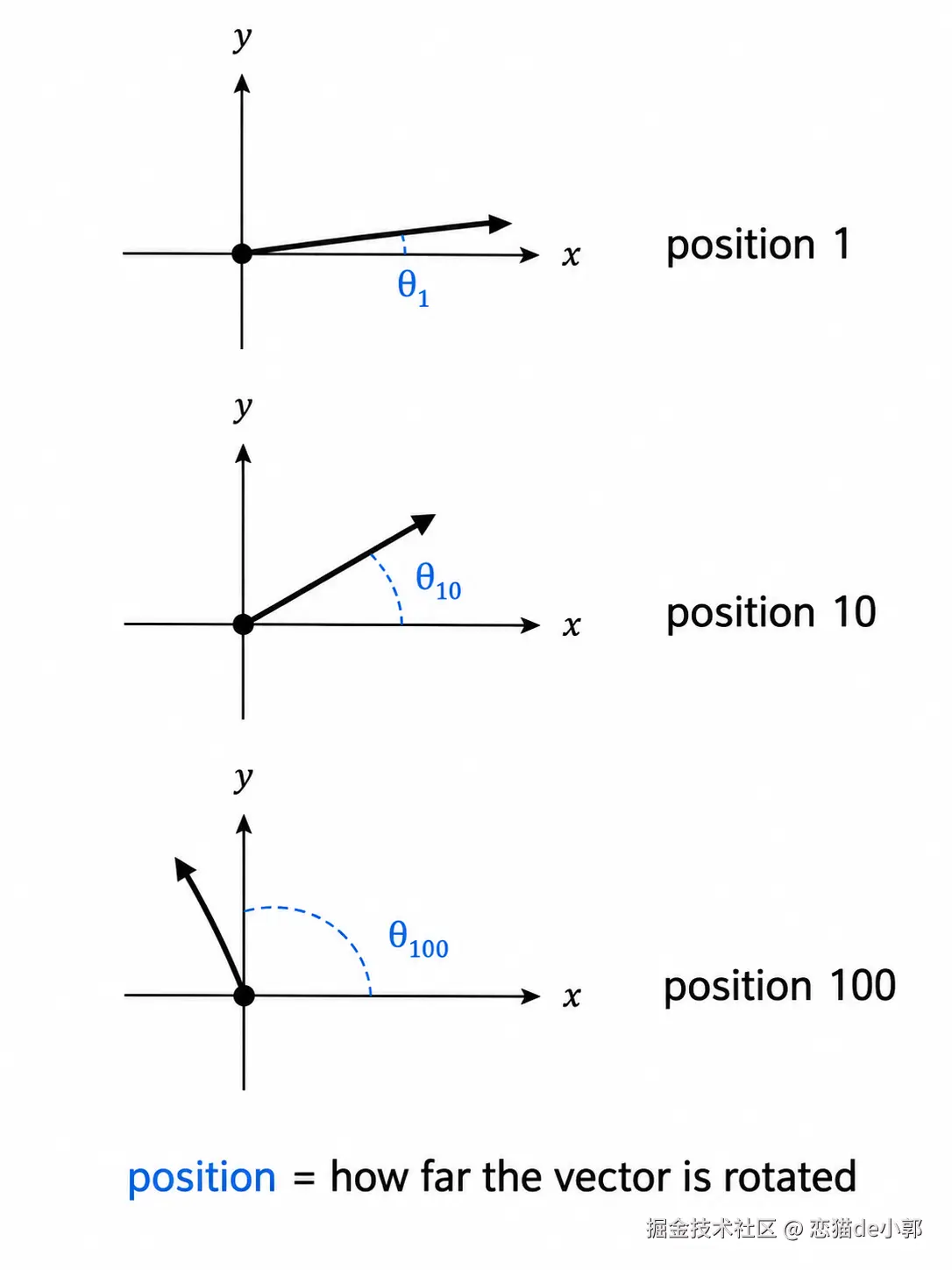
RoPE 的好处就是天然表达相对位置,更适合 attention 的需求,而且长上下文泛化更好,不增加额外参数。
不过就算使用了好的位置编码,LLM 还是会有 "lost in the middle" 问题,也就是长 prompt 中开头和结尾的信息更容易被利用,中间信息经常被忽略,所以:
"把重要信息放前面,或者在结尾重复关键约束",这种 prompt 技巧是说法的~~
所以,长上下文不是等于模型平均理解所有上下文,能塞进去,不代表能同等权重地用好。
4. Attention:token 之间怎么交换信息?
一半来说,每个 token 会被投影成三种向量:
- Query:我在找什么?
- Key:我能被什么匹配?
- Value:如果我被匹配上,我传递什么信息?
Query 和 Key 做点积,得到匹配分数,再通过 softmax 变成权重,最后用这些权重对 Value 做加权平均,高权重 token 的 Value 会更强地影响当前 token 的新表示。
说人话就是:每个 token 都会去上下文里"找相关信息",先判断谁和我最相关,再按相关程度把它们的信息混合进自己。
或者说:Query 负责提问,Key 负责被匹配,Value 负责提供内容,匹配越高,内容影响越大。
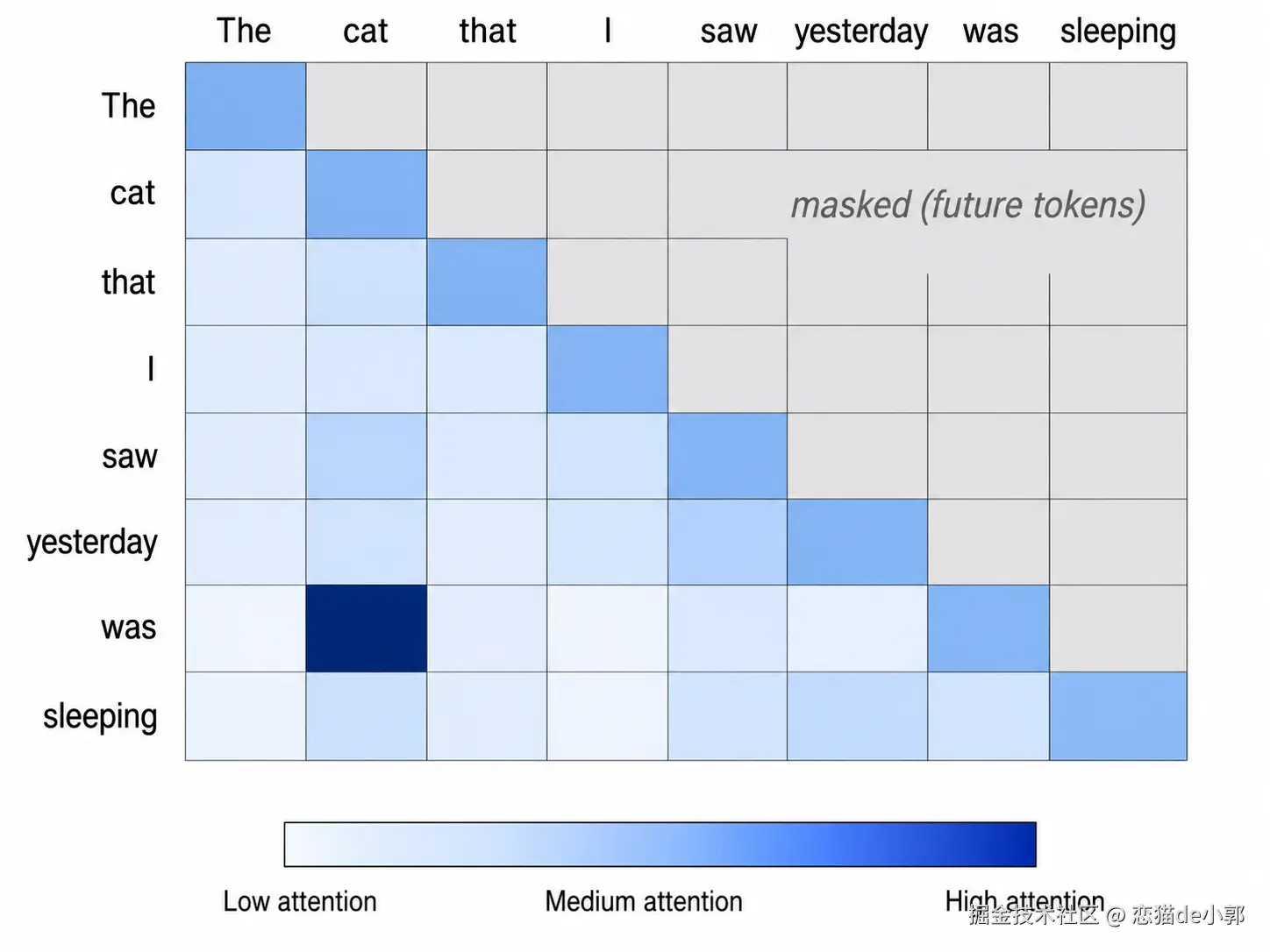
比如 The cat that I saw yesterday was sleeping. :
- 当模型处理 "was" 时,它需要知道谁 "was sleeping"
- "was" 的 Query 会和前面 token 的 Key 做比较
- 和 "cat" 的匹配较高,和 "yesterday" 的匹配较低
- softmax 后,"cat" 得到更高权重,于是 "cat" 的 Value 对 "was" 的新表示影响更大
- 这样模型就能把几个位置之前的主语关联过来
对于 GPT-style decoder-only 模型还有一个限制:生成是从左到右的,所以当前位置不能看未来 token,这叫 causal masking,实现上就是把未来 token 的注意力分数设得极低,softmax 后权重几乎为 0。
作者还还提到 Anthropic 2022 年发现的 induction heads,这类 attention head 会识别类似
A B ... A的模式,然后当第二次看到 A 时,回头找第一次 A 后面跟着什么 B,从而预测 B,这是目前解释in-context learning的一个机制。
另外 attention 的代价很高,full attention 里每个 token 要和所有可见 token 比较,所以 prompt 长度会翻倍,计算量大致会变成四倍,这就是长上下文贵、慢、占资源的底层原因之一,也是 FlashAttention、sparse attention、linear attention 等研究方向存在的原因。
说人话就是:
Attention 是每个 token 都在问:上下文里哪些 token 的信息最该被我吸收?
5. Multi-head Attention
单个 attention head 只能学一种关系,但语言里同时存在很多关系:主谓一致、代词指代、局部短语、长距离引用、位置模式 等,所以 Transformer 会并行运行多个 attention head。
当然,每个 head 不是简单拿原始 token 向量的一小段切片,比如:
hidden size 是 4096,有 32 个 head,每个 head 可能工作在 128 维空间,但这 128 维是从完整 4096 维学出来的投影,不是原向量的固定切块。
每个 attention head 不是把 4096 维向量切一块拿走,而是用自己的一套"滤镜",从完整的 4096 维里提取它关心的 128 维信息。
所以多头注意力不是"把脑子切成 32 块",其实是"32 个不同视角同时看同一个 token" 。
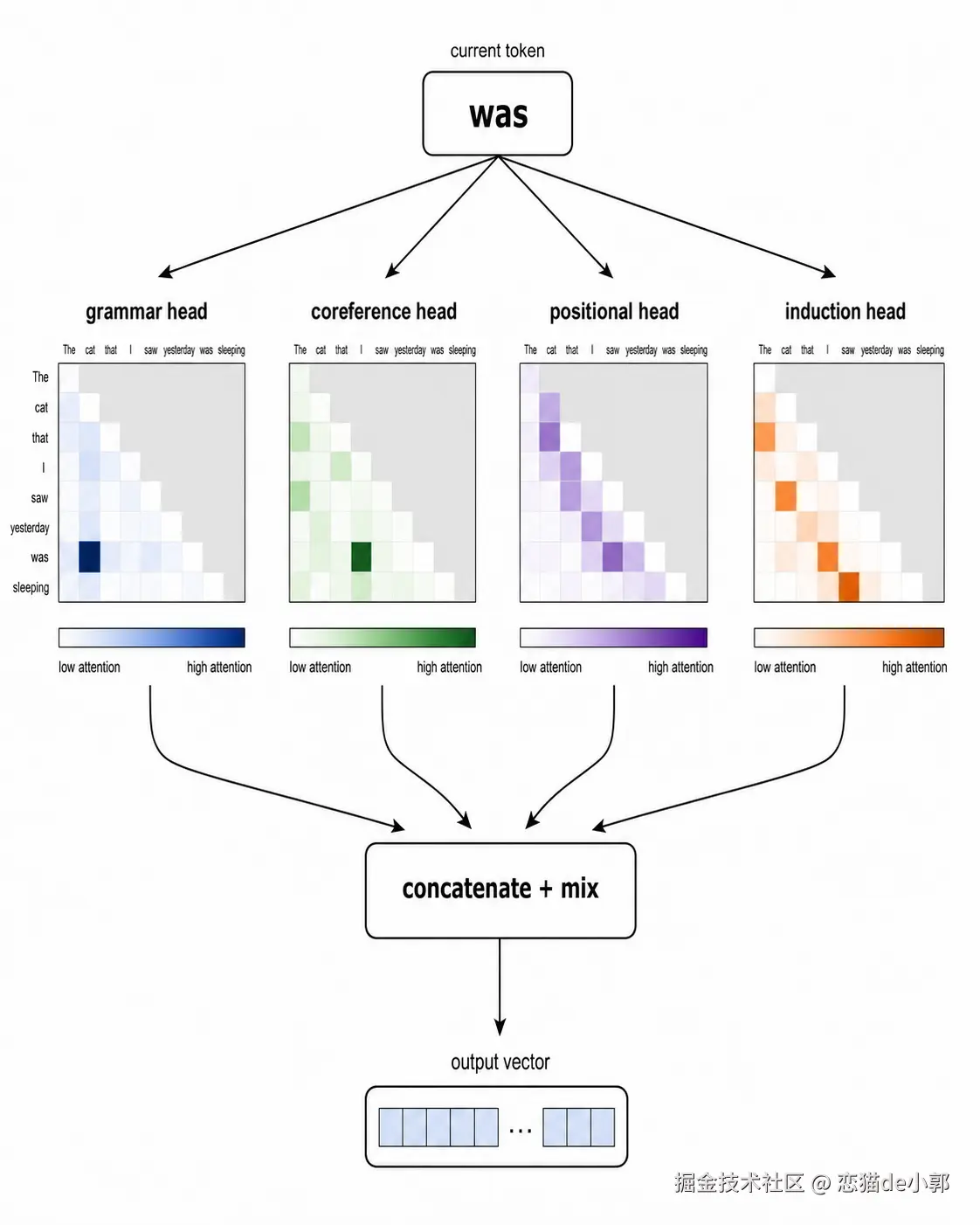
每个 head 独立做 attention,输出再拼接起来,经过一个最终线性层混合回完整向量。
不同 head 会自然分工,有的关注语法,有的关注代词,有的关注位置模式,有的形成 induction head,模型没有被人工规定哪个 head 做什么,这些都是在训练中涌现出来的。
特别是 KV cache 生成时,模型不希望每生成一个 token 就重算整个 prefix,所以会缓存过去 token 的 Key 和 Value,这样新 token 到来时,可以直接复用旧 K/V,但 KV cache 是长上下文推理的主要内存成本之一。
因此现代 decoder-only LLM 常用 GQA,也就是 Grouped-Query Attentio,多个 query head 共享较少数量的 key/value head,从而减少 KV cache 内存压力,说人话就是:
GQA 负责"提问"的头很多,但负责"存档和回答"的头少一点,多个提问头共用同一套 Key/Value,从而省内存。
正常多头注意力可以理解成:
diff
32 个 head
= 32 套 Query
+ 32 套 Key
+ 32 套 Value问题是生成时要缓存历史 token 的 Key/Value,也就是 KV cache,上下文越长,层数越多,Key/Value 头越多,占用内存越大,所以 GQA 改成:
bash
32 个 Query head
但只有 8 个 Key/Value head也就是说每 4 个 Query head 共用 1 组 Key/Value ,这就像公司里:
32 个员工都可以提问题,但不用配 32 个资料库,只需要 8 个共享资料库
所以保留多个 Query head 的不同观察角度,同时大幅减少要缓存的 Key/Value 数量,这样长上下文推理更省显存,也更快, 比如:
- LLaMA-2 70B 有 64 个 query heads,但只有 8 个 key/value heads
- Mistral 7B 有 32 个 query heads 和 8 个 key/value heads
所以长上下文不只是输入 token 多,还意味着每一层、每个生成步骤都要维护大量历史 K/V 状态,KV cache 是推理内存成本的核心之一。
6. Feed-Forward Network
Feed-Forward Network 是模型"记知识"的大仓库之一,Attention 负责 token 之间的信息交换,但每个 Transformer layer 还有一个很重要的模块:Feed-Forward Network,也就是 FFN。
attention 是 token 之间"互相看",而 FFN 是每个 token 独立做进一步加工,不混合其他 token,它通常有三步:
扩展向量维度 -> 经过非线性函数 -> 压回原始维度,说人话就是:先把 token 的信息摊开看得更细,再做一次复杂判断,最后浓缩回原来的大小。
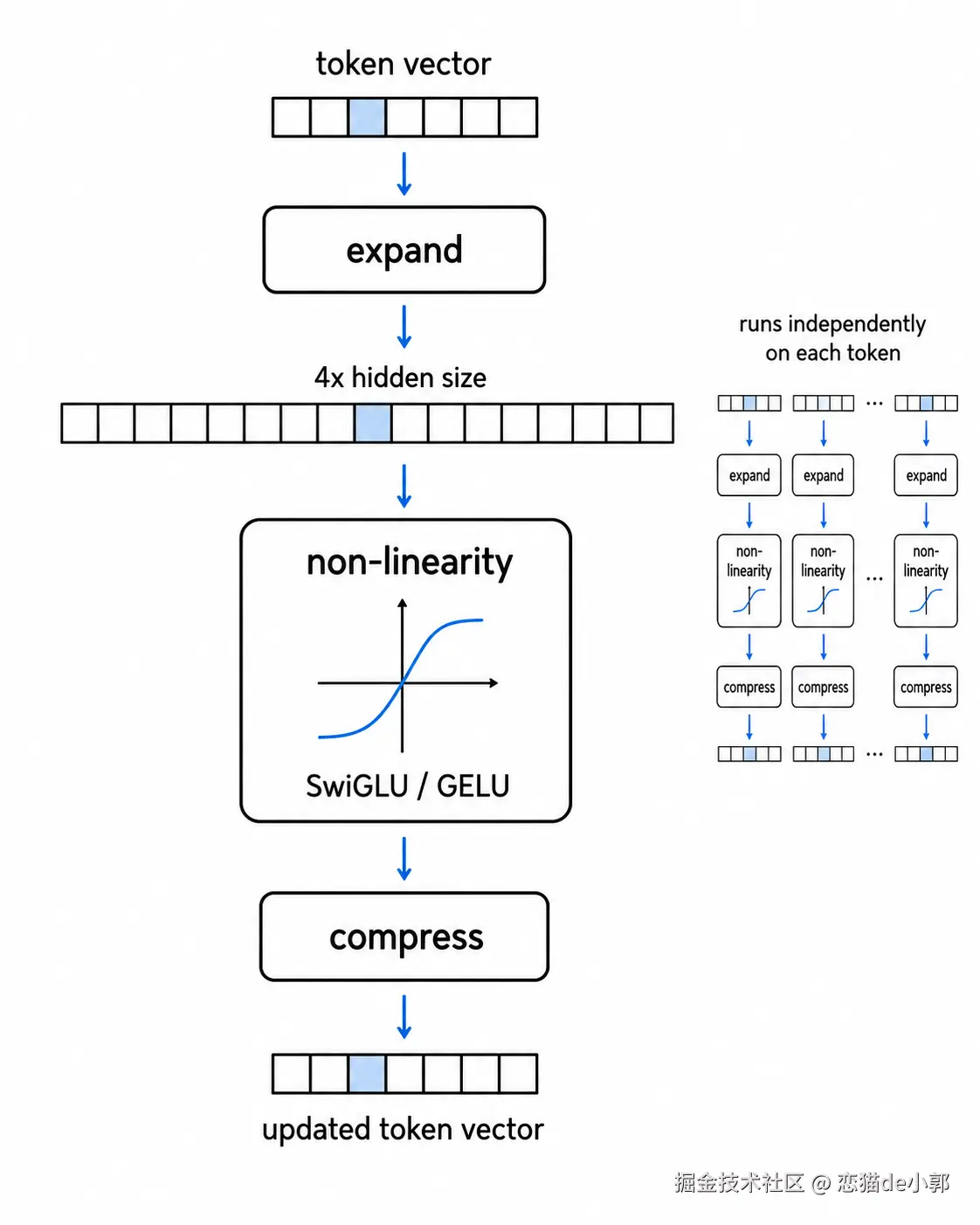
简单说就是,Attention 负责"从上下文里找信息",FFN 负责"把找到的信息在自己脑子里再加工一遍" ,粗暴点理解:
-
Attention:
- 这个 token 去看别的 token
- "我该参考谁?"
- "前面哪个词和我有关?"
- "这个代词指的是谁?"
FFN:
-
这个 token 不再看别人,而是在自己内部加工:
- "结合刚才拿到的信息,我现在应该更像什么?"
- "我是水果苹果,还是 Apple 公司?"
- "我是变量名,还是普通英文单词?"
再简单点理解就是:
- Attention : 信息搬运 / 上下文关联
- FFN :信息加工 / 知识变换
原始 Transformer 用 ReLU,GPT/BERT 常用 GELU,现代 LLaMA、Mistral、PaLM 等模型常用 SwiGLU,核心结构还是 expand-transform-compress,变化主要在非线性函数。
所以 Attention 让 token 从上下文里拿信息,而 FFN 就是让每个 token 在自己的向量空间里做深加工,FFN 先把向量扩展到更大的空间,让隐藏特征充分展开,再通过 ReLU/GELU/SwiGLU 这类非线性函数做选择和变换,最后压回原来的 hidden size。
非线性很关键,因为没有它,多层线性网络本质上仍然只是一个大矩阵,模型就很难表达复杂语义和知识。
而且,dense transformer 里大量参数其实在 FFN,而不是 attention,因为 FFN 里存着很多模型的事实和语义结构,一些 neuron 会对特定概念强激活,比如 Eiffel Tower、编程语言、过去时动词等。
模型知道「巴黎是法国首都」这类事实,这并不是存在一个显式数据库里,而是分布在 FFN 权重和激活中。
而 MoE 不是每层只有一个 FFN,而是有多个 expert FFN,再由 router 为每个 token 选择少数几个 expert,比如:
Mixtral 8x7B 每层有 8 个 expert,每个 token 只激活 2 个,这样总参数量可以变大,但每个 token 的实际计算量增长没那么快,Mixtral 8x7B 总参数 46.7B,但每个 token 大约只用 12.9B 参数。
7. Residual Stream 和 LayerNorm
而 Transformer 里不是每层都把旧表示完全替换掉,而是把 attention 或 FFN 的输出加回原向量,也就是:
arduino
new vector = old vector + block output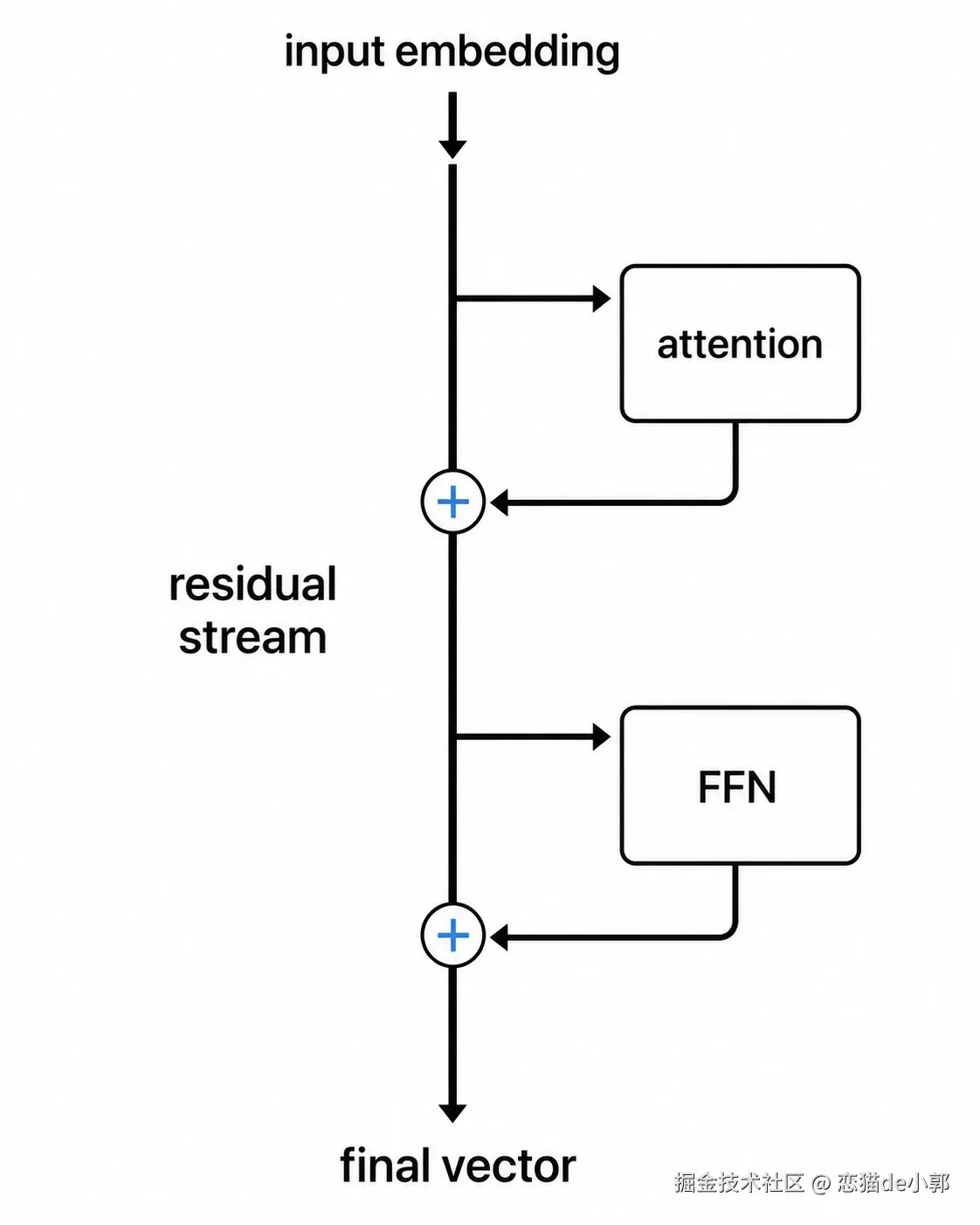
这叫残差连接( residual connection),多层堆叠后,每层贡献都会累积在一个持续流动的表示里,这个运行中的总和就是残差流 (residual stream)。
说人话就是,Transformer 每一层不是把前一层的理解推翻重写,而是在原来的理解上"补一笔" 。
比如一个 token 一开始只是 苹果 ,经过 attention 之后,它可能从上下文里拿到信息:
前面说"发布了新芯片" 。
那这一层不会把「苹果」原来的表示整个删掉,而是把新信息加进去:
苹果 + 发布新芯片相关信息。
所以它越来越像 Apple 公司 ,再经过下一层 FFN,它又补上一些更深的知识:
Apple 公司 + 科技公司 + 芯片 + 发布会 + 产品信息 。
所以残差连接可以理解成:
每一层都在给 token 的表示做增量更新,而不是全量重写。
作者在这里主要强调了残差连接让深层网络可以训练,这个技巧来自 ResNet,最早是为了解决深层图像网络训练困难的问题:
梯度在很多层中传播时会变弱或变强,导致训练失败,shortcut path 让训练信号更容易从输出传回输入,Transformer 继承了这个技巧。
残差连接解决的是「深层网络怎么把信息和训练信号一路传下去」,然后 LayerNorm/RMSNorm 解决的是「传下去的时候,数值不会出问题」。
简单来说就是:
- 残差连接让 Transformer 每层只做"增量修改",旧信息可以沿着 residual stream 一路传下去,所以深层网络更容易训练
- 残差流就像模型内部的公共黑板,attention、FFN 和最终输出层都在上面读
- LayerNorm/RMSNorm 则是数值稳定器,防止这块黑板上的向量经过几十层相加后爆炸或塌缩
简单来说就是:
残差连接让信息和梯度有高速路,LayerNorm/RMSNorm 让这条高速路上的数值别失控,没有它们堆几十层、上百层 Transformer 会困难很多。
8. Next-token Prediction
那最后到底输出了什么?所有 Transformer 层处理完后,模型会得到每个 token 的最终向量。
生成下一个 token 时,模型通常只取最后一个 token 的最终向量,把它映射成词表大小的一组分数,比如词表有 100,000 个 token,就得到 100,000 个 raw scores,这些叫 logits。
这里 logits 还不是概率,经过 softmax 后,才变成"下一个 token 是每个候选 token 的概率分布",而模型通常不会永远选概率最高的 token,temperature、top-k、top-p 等 decoding 参数会影响采样行为:
- 低 temperature 更保守、更确定
- 高 temperature 更随机、更发散
- top-k/top-p 会限制候选 token 集合,只从比较合理的范围里采样
一旦选出一个 token,它就被追加到输入后面。模型再基于更长的序列预测下一个 token,这个循环一直持续,直到生成 EOS token 或达到长度限制,整段回答就是这个循环反复运行的结果。
说人话其实就是:
Transformer 最后不是直接输出一句话,而是输出一张"下一个 token 候选榜"。
比如当前输入是 苹果发布了新 ,那么模型处理完所有 Transformer 层后,会拿最后一个 token,也就是"新"的最终向量,去预测后面最可能接什么,这这时候它不会直接说 芯片 ,而是先给整个词表里的所有 token 打分:
芯片:12.8
手机:10.4
产品:9.7
系统:8.9
电影:-3.2
香蕉:-6.5
......这些原始分数就是 logits ,然后 softmax 把这些分数变成概率:
erlang
芯片:45%
手机:18%
产品:12%
系统:8%
......这时模型才开始"选下一个 token",然后 temperature、top-k、top-p 可以理解成"选词风格控制器":
- temperature 控制模型敢不敢冒险
- top-k 是只看前 k 个候选
- top-p 是只看累计概率达到 p 的候选集合,
所以 top-k 是固定人数入围,top-p 是按概率动态入围。
而基础 LLM 的核心训练目标就是 next-token prediction, 基础并不是直接以"事实正确""会聊天""会推理""会写代码"为目标训练的,而是在海量文本上学习预测下一个 token。
之后的 instruction tuning、preference tuning、safety tuning 这些 post-training,才让它更会遵循指令、对齐偏好和适应对话。
另外小模型会先快速草拟多个 token,大模型并行验证,如果草拟 token 在大模型概率下可接受,就直接采用,否则回退到大模型生成,做得好的时候,输出分布可以等价于单独运行大模型,但速度更快。
9. Architecture vs Weights
最后作者还分析了 GPT、Claude、Gemini、LLaMA 到底差在哪里?
他认为 GPT、Claude、Gemini、LLaMA 等模型的公开细节不同,闭源模型也不会公布所有结构选择,但在这篇文章讨论的层面,它们大多都处于 Transformer-family 设计空间中。
现代 Transformer LLM 的共同骨架通常包括前面我们所说的这些东西:
- tokenization
- embedding
- positional encoding
- stacked transformer layers
- multi-head attention
- feed-forward network
- residual stream
- normalization
- next-token prediction
而真正让模型不同的主要是三类东西:
- 第一,训练出来的 weights,也就是不同数据、规模、训练流程学出来的参数
- 第二,配置差异,比如层数、词表大小、head 数、参数量、dense 还是 MoE
- 第三,post-training,比如指令微调、人类偏好学习、安全控制、对话行为塑造
所以现在不同 LLM 的差距,不只是"架构谁更神秘",更多来自训练数据、规模、训练 recipe、后训练、推理系统、工具链和产品化策略。
最后
最后简单总结一下:
- 第一,token 是一切的入口, 模型不是按人类自然理解的字、词、句直接思考,而是处理 tokenizer 给出的 ID 序列,所以 tokenization 会影响成本、长上下文、多语言表现、字符级任务表现
- 第二,embedding 是语义空间, token ID 通过 embedding matrix 变成向量,语义关系是训练中学出来的几何结构
- 第三,RoPE 不是简单"告诉模型第几个词",而是在 attention 的 Q/K 比较中编码相对位置, 这也是为什么它比早期绝对位置 embedding 更适合现代长上下文模型
- 第四,attention 是信息路由,不是知识本体, 它决定当前 token 应该从哪些上下文 token 吸收信息,但 dense 模型中大量参数和事实结构其实在 FFN 里
- 第五,KV cache 是推理成本的核心之一, 很多人只知道"上下文越长越贵",但原因不只是输入 token 变多,还包括每层要保存历史 K/V,生成时持续复用
- 第六,FFN 很可能是"模型知识仓库"的重要部分, ,事实、概念、语义结构大量分布在 FFN 权重和激活中,MoE 本质上也是围绕 FFN 容量和计算成本做稀疏扩展
- 第七,残差流是现代 interpretability 的核心对象, 每个模块都在 residual stream 上读写,模型不是一层层覆盖旧信息,而是在不断累积和修改表示
- 第八,base model 的训练目标不是"正确回答",而是 next-token prediction, 后训练让模型变得像助手,但底层生成机制仍然是基于概率分布逐 token 采样