JiuwenSwarm 的管理面板提供了多项目管理、多模型调度、模型别名等配置能力。本文从配置管理的角度,解析多项目隔离逻辑、is_default 标识的调度含义,以及模型别名对开发流程的优化空间。
一、为什么需要关注配置管理
用 JiuwenSwarm 跑一个小任务,随便配一个模型就行。但当使用场景变复杂之后,配置管理的短板就会暴露得比较明显。
一个典型的场景是多项目并行。假设你同时在做两个项目------一个是面向 C 端用户的电商客服系统,一个是内部技术调研平台。两个项目的 Agent 角色不同、技能不同、甚至需要连接不同的模型服务。如果把它们塞进同一个配置里,每次切换都得改一遍 config.yaml,不光麻烦,还容易出错。更棘手的是,两个项目可能需要同时在线------客服系统 7×24 响应,调研平台随时发起深度搜索。单实例模式下,两套团队配置挤在同一个 team 段里,Leader 人设、Teammate 角色定义、技能列表混在一起,改一个项目的配置可能影响另一个项目的运行。
另一个常见问题是模型切换。当模型列表里堆了五六个不同模型(qwen-plus、deepseek-chat、glm-4.7、gpt-4o...),每次想切模型都要记住完整的 model_name。如果同名的模型还有不同的 API 配置(比如同一个模型走不同渠道),光靠 model_name 根本区分不了。在实际开发中,模型切换是高频操作------调试 Agent 输出质量时要反复对比不同模型的效果,评估成本时要测试轻量模型能否胜任某个角色。如果每次切换都得到 config.yaml 里翻找完整的模型 ID,效率很低。
还有一个容易被忽略的问题:模型调度的歧义。当你配了两个同名的模型(比如两个 qwen-plus,一个走直连,一个走第三方代理),系统在解析请求时怎么知道该用哪一个?如果没有明确的调度规则,可能会出现"你以为用的是直连,实际上走的代理"这种隐蔽问题。
说到底,配置管理的核心诉求是三件事:项目之间互不干扰、模型调度有明确规则、切换操作足够简单。
JiuwenSwarm 的做法是提供一套完整的配置管理体系:通过实例管理(Instance Manager)实现多项目隔离,通过 is_default 标识解决同名模型的调度歧义,通过模型别名(alias)机制降低切换成本。这套机制与管理面板(ConfigPanel)的 UI 是打通的,不是靠手动改 YAML 文件。
运行环境
|--------|---------------------------------------|
| 项目 | 配置值 |
| 操作系统 | Windows 10 / macOS / Linux |
| Python | 3.11 / 3.12 / 3.13 |
| 模型服务 | 华为云 MaaS / OpenAI 兼容接口 / ModelScope 等 |
| 配置入口 | Web 管理面板 / config.yaml / 环境变量 |
核心概念速览
在深入实现细节之前,先理清三个核心概念之间的关系:
|-----------------|---------|---------------------------|
| 概念 | 解决什么问题 | 本质 |
| 实例管理(Instance) | 多项目隔离 | 独立的进程 + 独立的配置目录 + 独立的端口 |
| is_default 标识 | 模型调度优先级 | 在同名模型组中标记"默认使用哪一个" |
| 模型别名(alias) | 快速切换模型 | 给模型条目起一个短名,用于 UI 和 CLI 切换 |
三者不是孤立存在的。实例管理决定了"哪个项目",is_default 决定了"默认用哪个模型",别名决定了"怎么快速切换"。一条完整的模型路由链路是:先定位到正确的实例配置,再通过 is_default 找到默认模型,用户需要切换时通过别名快速定位目标。
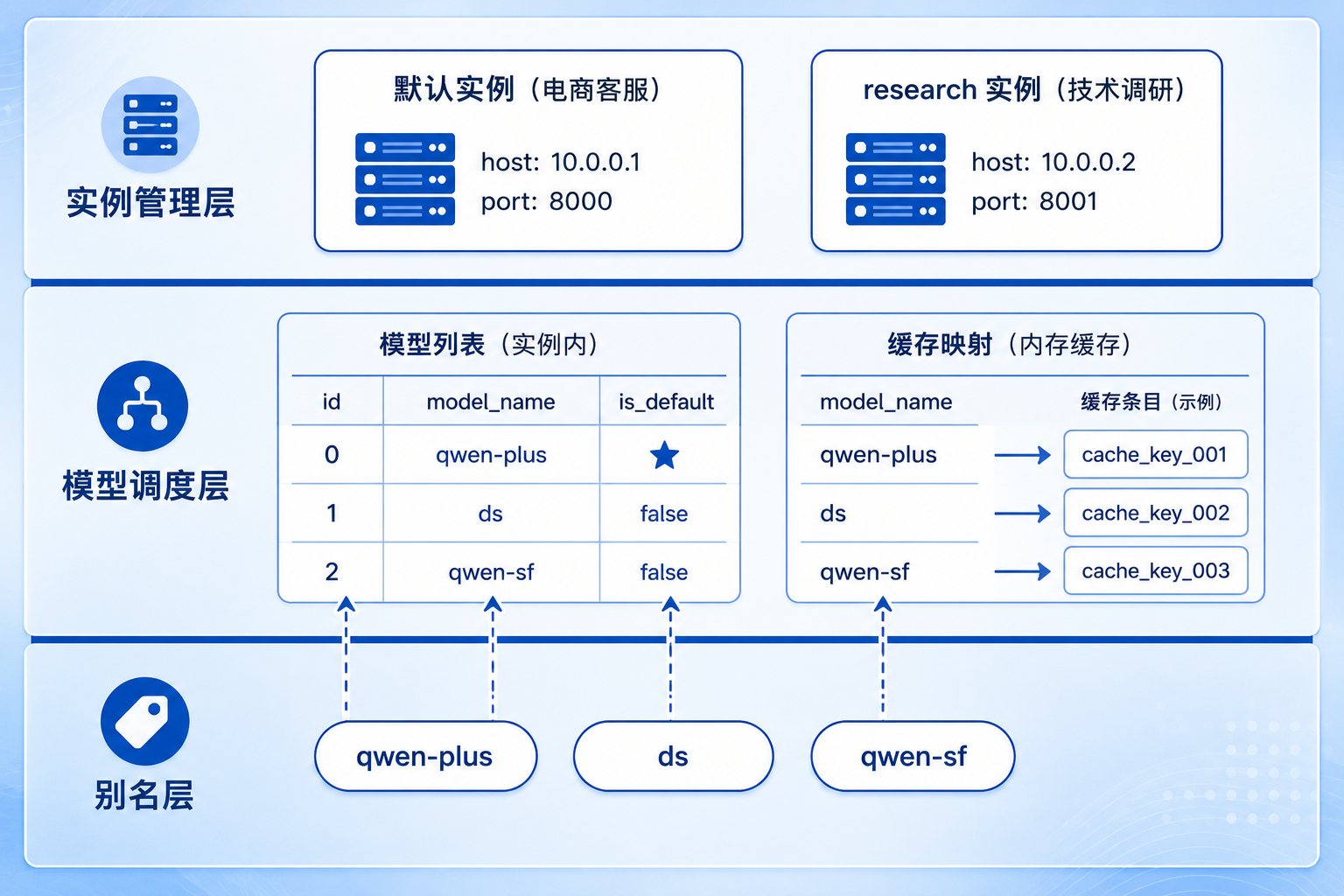
用一个实际的例子串起来:你有一个电商项目(实例 ecommerce)和一个调研项目(实例 research)。电商实例的默认模型是 qwen-plus(走阿里云直连),但你同时配了一个走硅基流动转发的 qwen-plus 作为备用,通过 is_default 标记了直连是默认。调研实例的默认模型是 deepseek-chat,别名叫 ds。当你在调研实例的 CLI 里输入 /model ds,系统通过别名找到 deepseek-chat,再通过 is_default 确定走的是哪个 API 配置。整个过程不需要关心其他实例的配置。
二、多项目隔离逻辑
2.1 实例管理器(Instance Manager)
JiuwenSwarm 通过实例管理器实现多项目隔离。每个实例是一个独立运行的 JiuwenSwarm 服务单元,拥有独立的配置、工作空间和端口。
核心数据结构:
@dataclass
class InstanceConfig:
name: str # 实例名称(唯一标识)
workspace: Path # 实例工作空间目录
ports: Dict[str, int] = field(default_factory=dict) # 端口分配实例的命名有严格规则:只能包含字母、数字、下划线和连字符,长度 1-64 个字符。一些名称被系统保留,不能使用:default、config、tmp、jiuwenswarm、all。
端口分配采用自动计算策略:base_port + index * 1000。默认实例(index=0)使用基础端口,具名实例从 index=1 开始依次递增:
|--------------|---------------|---------------|---------------|
| 服务类型 | 默认实例(index=0) | 实例 1(index=1) | 实例 2(index=2) |
| agent_server | 18092 | 19092 | 20092 |
| web | 19000 | 20000 | 21000 |
| gateway | 19001 | 20001 | 21001 |
| frontend | 5173 | 6173 | 7173 |
这样设计的直接好处是:多个实例可以同时运行,互不干扰。电商客服系统跑在默认实例上,技术调研平台跑在实例 1 上,两者的模型配置、技能、工作空间完全隔离。
端口间隔 1000 的设计并非随意。每个实例需要 4 个端口(agent_server、web、gateway、frontend),端口间隔足够大,即使同时运行十几个实例也不会冲突。同时,端口计算是确定性的------给定实例名称的 index,就能算出对应的端口,不需要运行时动态协商。
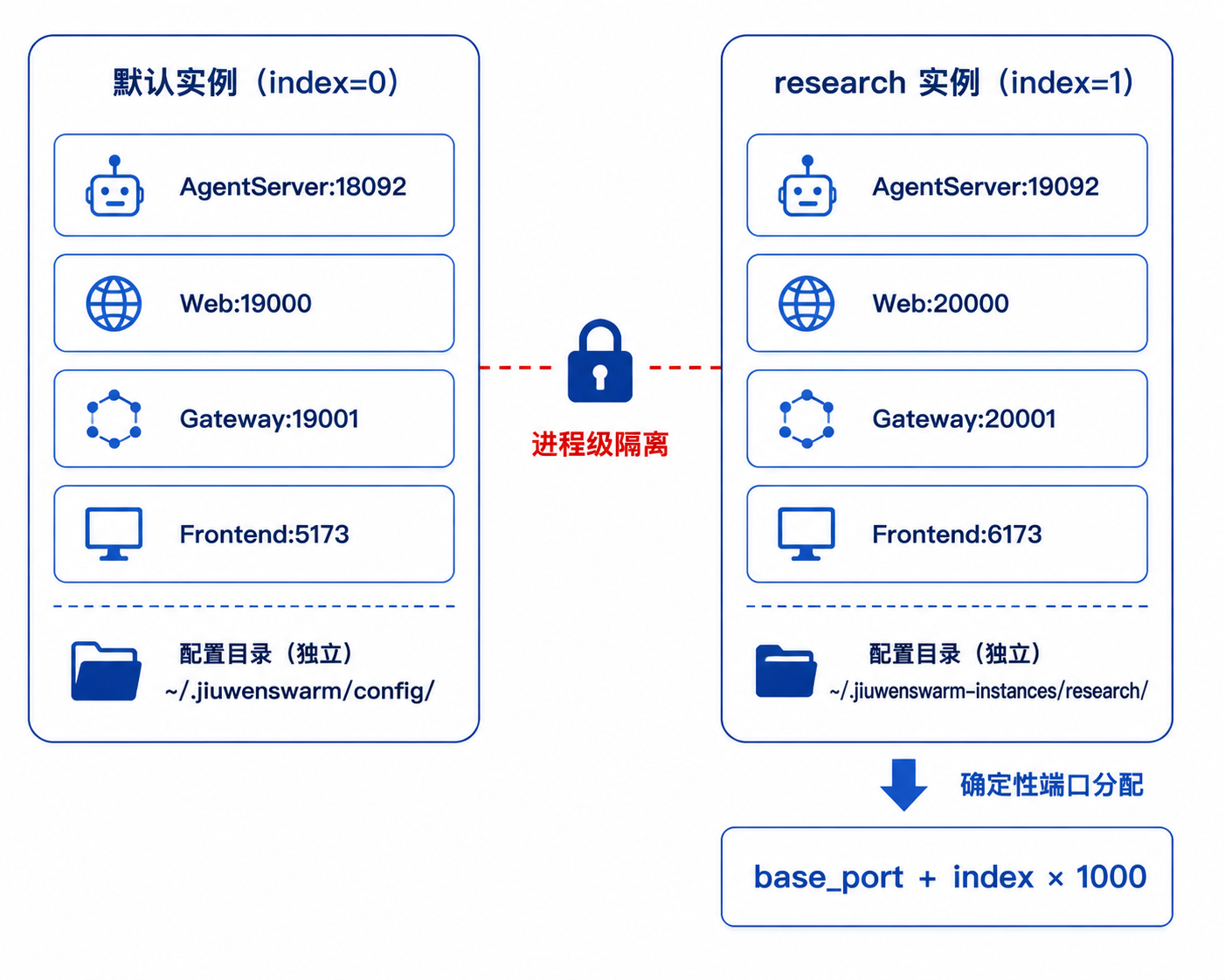
2.2 配置目录隔离
每个实例的配置通过环境变量 JIUWENSWARM_DATA_DIR 隔离。系统在解析配置目录时,get_user_workspace_dir() 函数按优先级查找路径:
- 已缓存的值(通过
set_user_workspace_dir设置或之前调用缓存)
JIUWENSWARM_DATA_DIR环境变量(用于多实例隔离)
- 默认路径
~/.jiuwenswarm
get_config_dir() 在此基础上拼接 config/ 子目录作为配置目录。实例启动时,bootstrap 模块为每个实例创建独立的 .env 文件,写入 JIUWENSWARM_DATA_DIR 指向该实例的工作空间。进程启动后读取自己的 .env,自然就绑定到了对应的配置目录。
实例启动时,bootstrap 模块会为每个实例创建独立的 .env 文件,包含该实例的 JIUWENSWARM_DATA_DIR、实例名称和端口分配。进程启动后读取自己的 .env,自然就绑定到了对应的配置目录。
2.3 实例配置文件
多实例的声明在 ~/.jiuwenswarm/instances.yaml 中管理:
instances:
ecommerce:
workspace: ~/.jiuwenswarm-instances/ecommerce
# ports 自动分配,也可手动指定
research:
workspace: ~/.jiuwenswarm-instances/research
ports:
agent_server: 19092
web: 20000
gateway: 20001
frontend: 6173每个具名实例的工作空间默认在 ~/.jiuwenswarm-instances/<name>/ 下,包含独立的技能目录、记忆文件、会话数据。不同实例的 Agent 完全看不到彼此的数据。
2.4 实例管理的实际效果
用一个具体场景说明。假设你有两个项目:
项目 A:电商客服团队,需要 qwen-plus 模型、客服相关技能、飞书 Channel 接入。
项目 B:技术调研团队,需要 deepseek-chat 模型、DeepSearch 技能、Web 前端使用。
如果把它们塞进同一个实例里,你得在同一份 config.yaml 里维护两套模型、两套团队配置、两套技能。切换时改来改去,稍有不慎就把客服团队的模型改成了调研用的。
实例隔离之后,情况变得简单:项目 A 跑在默认实例上,项目 B 跑在 research 实例上。各管各的配置,各占各的端口,互不影响。需要同时运行时,两个进程并行启动即可。
值得注意的是,实例隔离不只是在配置文件层面做了区分------每个实例是真正独立的进程。bootstrap 模块为每个实例生成独立的 .env 文件,进程启动时加载自己的环境变量,绑定到自己的端口,读取自己的配置目录。这意味着不同实例之间的故障也不会互相传染:如果一个实例的 Agent 因为模型 API 超时而崩溃,另一个实例完全不受影响。
三、is_default 标识的调度含义
3.1 什么是 is_default
models.defaults 是一个模型条目列表,可以包含多个模型。当列表中有多个同名模型(相同的 model_name,但不同的 api_base 或 api_key)时,系统需要知道"默认使用哪一个"。这就是 is_default 标识的作用。
一个典型的场景:你同时配了两个 qwen-plus,一个走阿里云直连,一个走硅基流动(SiliconFlow)的转发。两者的 model_name 都是 qwen-plus,但 api_base 和 api_key 不同。is_default 标记了默认走哪个渠道。
3.2 自动推断规则
is_default 不需要手动配置。系统通过 _infer_is_default() 函数自动推断:
def _infer_is_default(entries):
"""为模型条目列表推断 is_default 字段。
规则:
- 同 model_name 组内仅一个条目 → is_default = True
- 同 model_name 组内多个条目 → 第一个为 True,其余为 False
- 已有 is_default 字段且为 True 的条目保留,同组内其余置 False
"""推断规则很直观:
|---------------------------------|-------------------------------|
| 场景 | 结果 |
| 同名组只有 1 个条目 | 自动标记为 is_default = True |
| 同名组有多个条目,无显式标记 | 列表中第一个为 True,其余为 False |
| 同名组有多个条目,有显式 is_default: True | 显式标记的条目为 True,同组其余为 False |
3.3 调度链路
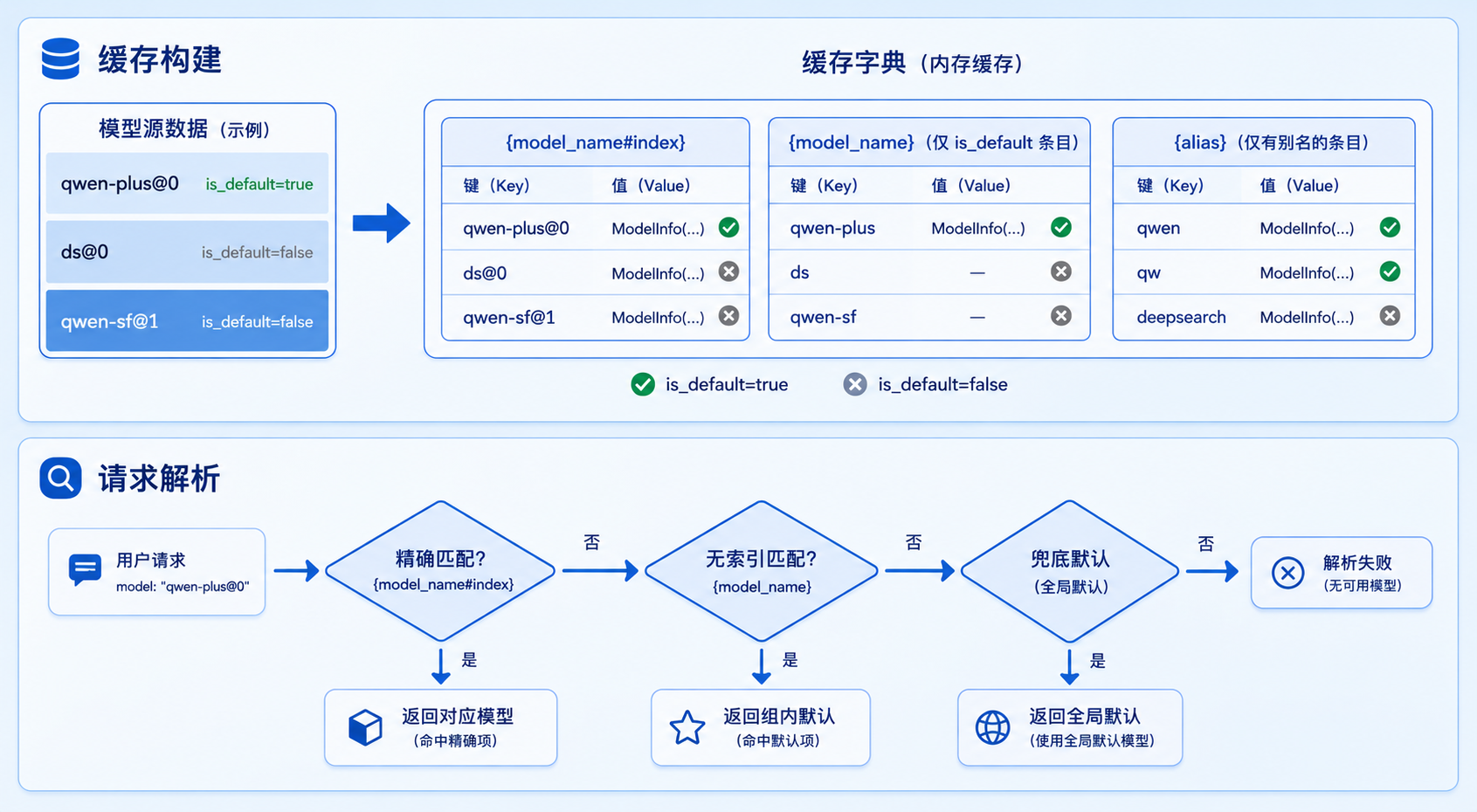
is_default 在模型调度中扮演关键角色。系统启动时会构建模型缓存(model cache),缓存的 key 有三种:
# 缓存 key 的生成逻辑
def _build_model_cache_from_defaults(self):
for i, entry in enumerate(defaults):
model_name = entry.model_client_config.model_name
key_indexed = f"{model_name}#{i}" # 精确索引 key
cache[key_indexed] = model
if entry.is_default:
key_plain = model_name # 无索引 key(默认指向)
cache[key_plain] = model
if entry.alias and entry.alias != model_name:
cache[entry.alias] = model # 别名 key当请求到来时,模型解析按以下优先级匹配:
1. 精确匹配(model_name#index 或 alias) → 命中则返回
2. 无索引匹配(model_name) → 命中 is_default 条目则返回
3. 兜底 → 返回全局默认模型这个设计的精巧之处在于:同一个 model_name的请求,不需要知道列表里有几个条目、排在第几个,直接用 model_name就能路由到默认的那个 。需要指定特定条目时,用 model_name#index 精确定位。
举个完整的例子。假设 models.defaults 列表如下:
|----|---------------|---------|------------|
| 索引 | model_name | alias | is_default |
| 0 | qwen-plus | (空) | true |
| 1 | deepseek-chat | ds | true |
| 2 | qwen-plus | qwen-sf | false |
模型缓存构建后的 key 映射:
"qwen-plus#0" → 条目 0
"qwen-plus" → 条目 0(is_default=true 的 qwen-plus 条目)
"deepseek-chat#1" → 条目 1
"deepseek-chat" → 条目 1(is_default=true 的 deepseek-chat 条目)
"ds" → 条目 1(别名 key)
"qwen-plus#2" → 条目 2
"qwen-sf" → 条目 2(别名 key)注意,条目 2(qwen-sf)虽然有 model_name=qwen-plus,但因为 is_default=false,所以没有 qwen-plus 这个无索引 key。当请求 model_name=qwen-plus 时,系统只会命中条目 0,不会歧义。
在团队协作场景中,这个调度链路尤其重要。JiuwenSwarm 支持成员对不同模型的路由------可以针对不同角色提供合适能力的模型。比如给 Leader 分配一个轻量模型负责调度,给负责深度分析的 Teammate 分配一个推理能力更强的模型。Leader 在创建 Teammate 时,可以通过 model_name#index 指定具体走哪个模型条目,确保不同角色各得其所。
3.4 列表首位 = 全局默认
models.defaults 列表的第一个条目有一个隐含的调度含义:它是全局默认模型。当没有指定任何 model_name 时,系统使用列表首位。
管理面板中的"设为默认"操作,本质上就是把目标条目移到列表首位:
const handleSetActive = (idx: number) => {
// 将目标条目移到列表首位,作为主对话默认模型
const copy = [...models];
const [target] = copy.splice(idx, 1);
// 主对话默认一定是组内默认
target.is_default = true;
for (const m of copy) {
if (m.model_name === targetName) {
m.is_default = false;
}
}
copy.unshift(target);
onModelsChange(copy);
};两级默认的关系:
|------|---------------------------|---------------------|
| 级别 | 含义 | 标识方式 |
| 全局默认 | 列表首位,无任何 model_name 指定时使用 | 列表位置 |
| 组内默认 | 同名模型组中的默认条目 | is_default = True |
如果全局默认恰好是某个同名组中的唯一成员,那它同时是全局默认和组内默认,两套规则自然对齐。如果组内有多个条目,is_default 决定组内路由,列表首位决定全局兜底。
四、模型别名机制
4.1 为什么需要别名
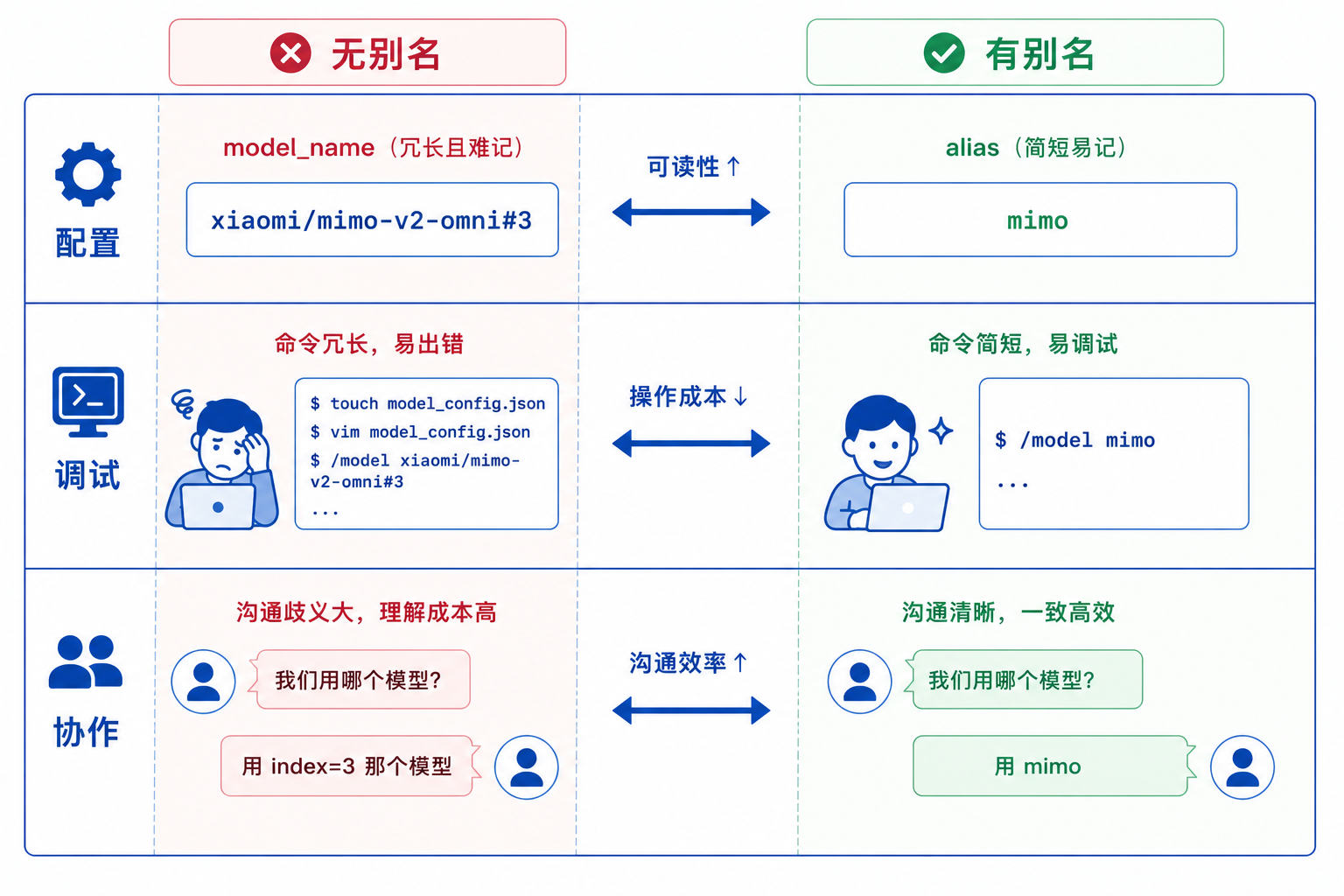
模型别名(alias)解决的是一个看似简单但实际上很烦人的问题:模型名称太长、太难记。
举个例子。你想从 qwen-plus 切换到 xiaomi/mimo-v2-omni。在 CLI 里,你得输入 /model xiaomi/mimo-v2-omni。在 Web UI 的下拉框里,你得在一堆长名字里找到它。
如果给 xiaomi/mimo-v2-omni 设个别名叫 mimo,切换就变成了 /model mimo。短、好记、不容易打错。
4.2 别名规则
别名有以下规则:
|-----|---------------------------------------------------|
| 规则 | 说明 |
| 唯一性 | 别名在所有模型中必须全局唯一,不能与任何模型的 alias 或 model_name 重复 |
| 可选性 | 不设置时,系统自动以 model_name 作为显示名和切换标识 |
| 持久性 | 保存到 config.yaml 后,后续启动自动加载 |
唯一性校验覆盖两个维度:别名之间不能重复,别名也不能与任何模型的 model_name 相同。这是为了防止歧义------如果别名 deepseek-chat 与另一个模型的 model_name 相同,系统无法判断你要切换到哪一个。
前端在编辑时会实时校验别名冲突:
if (field === "alias") {
const alias = value.trim();
if (alias) {
const conflict = models.find((m, i) =>
i !== idx && ((m.alias || "") === alias || m.model_name === alias)
);
if (conflict) {
setLocalError(`Alias '${alias}' is already used by model '${conflict.model_name}'`);
}
}
}4.3 别名在调度链路中的位置
回到模型缓存的构建逻辑,别名的处理很简洁------如果 alias 存在且与 model_name 不同,就在缓存中额外添加一个别名 key:
if entry.alias and entry.alias != model_name:
cache[entry.alias] = model # 别名 key这意味着别名与 model_name、model_name#index 在缓存中是平级的。请求的 model_name 字段无论是填别名、填完整模型名、还是填索引格式,都能被正确解析。
在 CLI 中的切换效果:
# 以下三种方式等价(假设 alias=mimo,model_name=xiaomi/mimo-v2-omni,index=2)
/model mimo # 通过别名切换
/model xiaomi/mimo-v2-omni # 通过模型名切换(命中 is_default 条目)
/model xiaomi/mimo-v2-omni#2 # 通过精确索引切换4.4 别名对开发流程的优化
别名带来的效率提升体现在三个环节:
配置阶段。给模型起好别名后,配置其他组件时可以直接用别名引用。比如在 Team 配置中,给不同的 Agent 角色指定不同模型时,用别名比用完整 model_name 清晰得多:
agents:
leader:
model:
model: mimo # 调度用轻量模型
teammate:
model:
model: deepseek-r1 # 执行用推理模型调试阶段。CLI 中快速切换模型进行 A/B 对比,不用记住完整的模型 ID。特别是在调试 Agent 的输出质量时,频繁切换不同模型是常见操作,别名把每次切换的操作成本降到最低。
团队协作阶段。团队配置中可以给不同角色分配不同能力的模型。JiuwenSwarm 支持成员对不同模型的路由------针对不同角色提供合适能力的模型,因材施教,提升整体效果。别名让这种"因材施教"的配置过程变得直观。
综合来看,别名在整个模型生命周期中扮演的角色:
|----------|--------------------------------|---------------|
| 阶段 | 没有别名 | 有别名 |
| 配置团队模型 | model: xiaomi/mimo-v2-omni#3 | model: mimo |
| CLI 切换测试 | /model xiaomi/mimo-v2-omni | /model mimo |
| 阅读团队配置 | 需要查 index 才知道是哪个模型 | 一眼识别 |
| 向同事解释配置 | "用 index=3 那个模型" | "用 mimo" |
别名的本质是在 model_name 之上加了一层语义映射。model_name 是 API 层的标识,面向机器;别名是面向人的标识,方便开发者理解和操作。两者通过缓存机制统一在同一个调度链路中,不需要额外的解析层。
五、管理面板的配置操作
JiuwenSwarm 的管理面板(ConfigPanel)是上述机制在前端的可视化入口。左侧导航栏打开"配置信息"即可进入。
5.1 面板结构
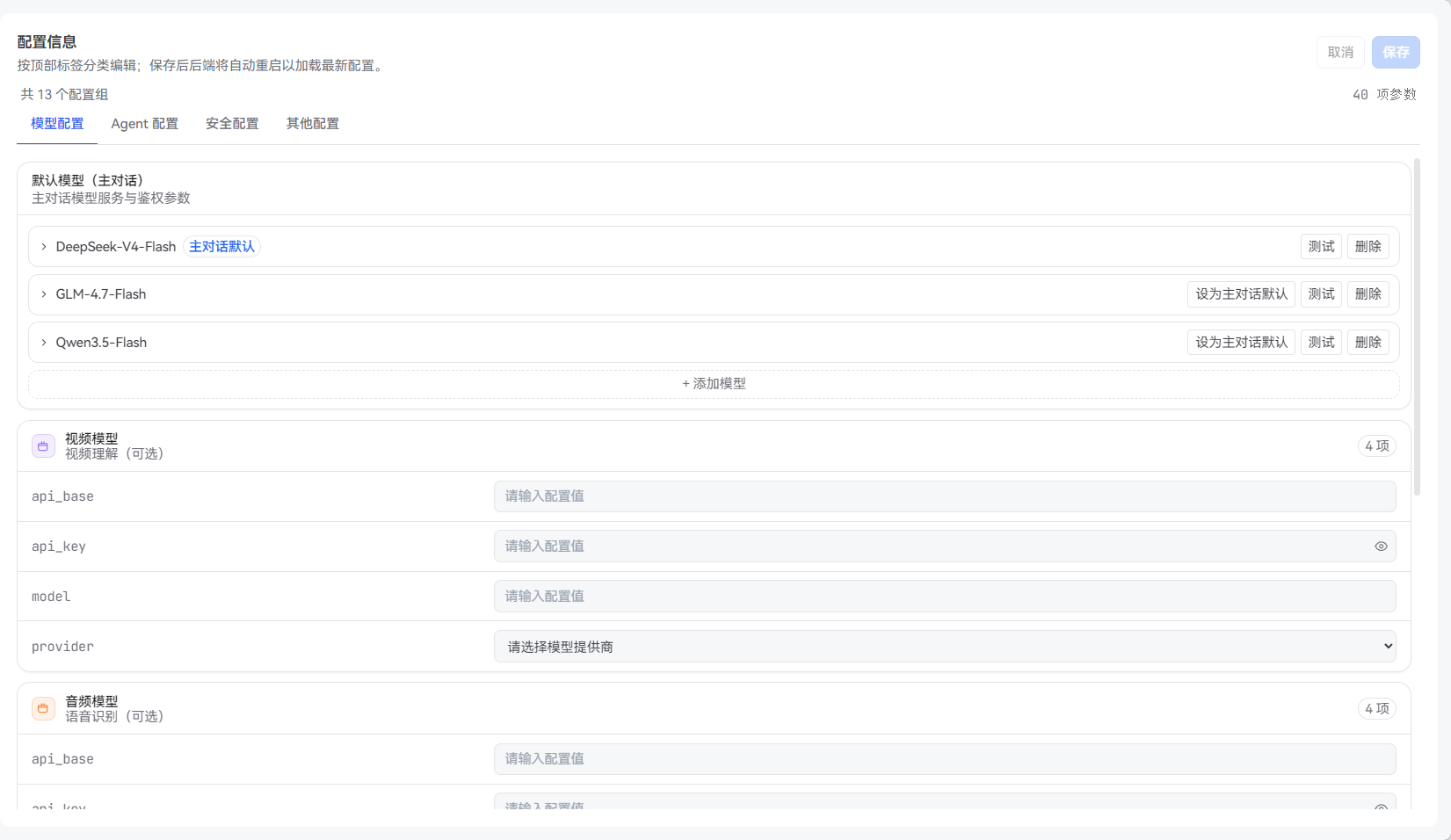
面板分为多个标签页:
|-------|------------------------|
| 标签页 | 配置内容 |
| 模型 | 默认对话模型、视频/音频/视觉/图片生成模型 |
| Agent | Agent 配置、团队(Team)配置 |
| 安全 | 工具权限、安全护栏 |
| 其他 | Embed、第三方服务、自演进、上下文压缩等 |
5.2 模型列表管理
模型配置区域(MultiModelSection)是管理面板的核心组件,支持:
|-------|----------------------------------------|
| 操作 | 说明 |
| 添加模型 | 填写 api_base、api_key、model_name、alias 等 |
| 删除模型 | 删除前检查是否有 Agent 引用该模型 |
| 设为默认 | 将目标条目移到列表首位,自动更新 is_default |
| 拖拽排序 | 调整模型在列表中的顺序 |
| 测试连通性 | 发送测试请求验证 API 配置是否正确 |
| 编辑别名 | 实时校验别名唯一性 |
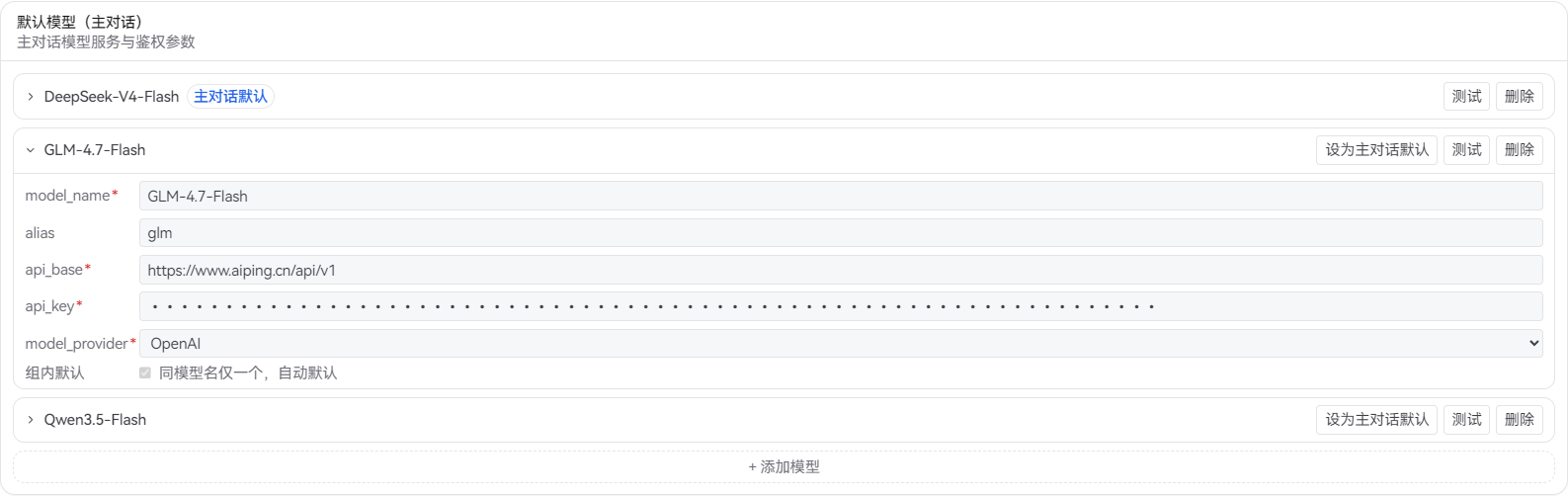
每个模型条目包含以下字段:
|------------------|----|-----------------|
| 字段 | 必填 | 说明 |
| model_name | 是 | 模型在 API 层的名称 |
| alias | 否 | 显示名称 / 切换标识符 |
| api_base | 是 | API 地址 |
| api_key | 是 | API 密钥(面板中脱敏显示) |
| model_provider | 是 | 提供商类型 |
| temperature | 否 | 采样温度,默认 0.95 |
面板中 API Key 等敏感字段做了脱敏处理,不会明文展示。保存时,系统会保留 config.yaml 中的环境变量占位符(如 ${API_KEY}),只更新实际变更的字段。
"设为默认"操作背后的逻辑比表面看起来复杂。当点击某个模型的"设为默认"按钮时,前端做了三件事:把目标条目移到列表首位(全局默认),将目标的 is_default 设为 true(组内默认),同时把同组内其他条目的 is_default 设为 false。这三个操作必须原子完成,否则可能出现"两个同名模型都认为自己是默认"的不一致状态。
删除模型时,系统会检查是否有 Agent 或团队配置引用了该模型。如果检测到引用,会提示用户哪些 Agent 正在使用这个模型,避免删掉正在使用的模型导致运行时错误。这是一种防御性设计------虽然系统在模型找不到时会兜底到全局默认,但提前告警比运行时降级更好。
5.3 团队配置与模型路由
在 Agent 标签页中,可以为团队中的每个角色单独配置模型。配置面板支持多团队管理,每个团队可以定义自己的 Leader 和 Teammate 模型。
模型路由的解析支持 model_name#index 格式,精确定位到 models.defaults 列表中的某个条目:
def _transform_front_team_model_config(model_raw):
model_value = model_raw.get("model")
if model_value and "#" in model_value:
model_name_part = model_value[:sep]
index_part = model_value[sep + 1:]
# 从 defaults 列表中按 index 查找完整配置
defaults_list = get_config_raw().get("models", {}).get("defaults")
entry = defaults_list[target_index]这意味着在团队配置中,可以给 Leader 分配列表中的第一个模型,给数据分析 Teammate 分配第二个模型,给写作 Teammate 分配第三个模型------只要指定对应的 index 即可。
5.4 面板操作的保存与校验
面板上的配置变更通过 WebSocket 实时发送到后端。后端在保存前会做一系列校验:
模型列表校验 :_models_replace_all 处理器在校验别名唯一性时,会同时检查两个维度------别名之间的唯一性,以及别名与所有条目的 model_name 之间的唯一性。校验不通过时返回具体的冲突信息,前端展示为行内错误提示。
环境变量保留 :保存模型配置时,_merge_models_for_replace_all() 会比对原始值和新值。如果原始值中包含 ${VAR_NAME} 格式的环境变量占位符,且前端没有修改这个字段,保留原始占位符不覆盖。这样避免了"面板保存后把 ${API_KEY} 替换成实际密钥明文"的问题。
团队配置校验 :保存团队配置时,系统校验 team_name 必填且全局唯一,member_name 必填,引用的 Agent key 必须在 agents 段中存在。校验失败时,后端返回结构化错误信息,前端定位到具体的配置项。
六、配置文件详解
6.1 多模型配置
在 config.yaml 的 models 段配置多模型列表:
models:
defaults:
- model_client_config:
model_name: "qwen-plus"
api_base: "https://dashscope.aliyuncs.com/compatible-mode/v1"
api_key: "${QWEN_API_KEY}"
client_provider: "OpenAI"
model_config_obj:
temperature: 0.7
is_default: true
- model_client_config:
model_name: "deepseek-chat"
api_base: "https://api.deepseek.com/v1"
api_key: "${DEEPSEEK_API_KEY}"
client_provider: "OpenAI"
model_config_obj:
temperature: 0.95
alias: "ds"
- model_client_config:
model_name: "qwen-plus"
api_base: "https://api.siliconflow.cn/v1"
api_key: "${SILICON_API_KEY}"
client_provider: "SiliconFlow"
model_config_obj:
temperature: 0.7
alias: "qwen-sf"这个配置中有三个条目:
|----|---------------|---------|------------|-------------------------|
| 条目 | model_name | alias | is_default | 含义 |
| 1 | qwen-plus | (空) | true | 全局默认 + qwen-plus 组内默认 |
| 2 | deepseek-chat | ds | true | deepseek-chat 组内唯一,也是默认 |
| 3 | qwen-plus | qwen-sf | false | qwen-plus 组内非默认(走硅基流动) |
切换示例:
- 不指定模型 → 走条目 1(全局默认)
/model ds→ 走条目 2(别名命中)
/model qwen-plus→ 走条目 1(组内默认)
/model qwen-plus#2→ 走条目 3(精确索引)
从这个例子可以看出 is_default 和别名在调度中的分工:is_default 解决的是"同名模型的默认选择"问题,别名解决的是"跨名模型的快速定位"问题。两者覆盖的场景不同但互补------当你在同名模型组内做精细路由时,is_default 是关键;当你需要在不同模型之间频繁切换时,别名是关键。
在 CLI 中的模型切换命令(/model <name>)的实现也值得说明。切换并不是简单地修改一个变量------它实际上会重新排列 models.defaults 列表,将目标模型移到首位,然后调用 update_default_models_in_config() 写入 config.yaml。这意味着模型切换是持久化的,下次启动服务时仍然使用上次切换后的默认模型。
6.2 多团队配置
modes.team 段支持定义多个命名团队,每个团队可以独立配置角色和模型:
modes:
team:
research_team:
team_name: research_team
lifecycle: persistent
teammate_mode: build_mode
spawn_mode: inprocess
leader:
member_name: research_leader
display_name: "调研组长"
persona: "技术调研项目管理专家"
agents:
leader:
skills: ["openJiuwen-DeepSearch"]
max_iterations: 200
completion_timeout: 600.0
teammate:
skills: ["openJiuwen-DeepSearch"]
max_iterations: 200
completion_timeout: 600.0
predefined_members:
- member_name: "topic_researcher"
display_name: "方向调研员"
persona: "擅长深度搜索和分析"
- member_name: "report_writer"
display_name: "报告撰写员"
persona: "擅长整理结构清晰的技术报告"
ecommerce_team:
team_name: ecommerce_team
lifecycle: persistent
teammate_mode: build_mode
spawn_mode: inprocess
leader:
member_name: service_leader
display_name: "客服组长"
persona: "电商客服管理专家"
agents:
leader:
skills: ["openJiuwen-DeepSearch"]
max_iterations: 200
completion_timeout: 300.0不同团队之间完全独立------团队名称、角色定义、技能列表、超时配置都是隔离的。Web 前端切换团队时,直接选择对应的团队名称即可。
6.3 环境变量与配置文件的关系
配置项支持环境变量占位符(${VAR_NAME} 格式),实际值在运行时从 .env 文件或系统环境变量中解析:
model_client_config:
api_base: ${MODEL_API_BASE:-https://open.bigmodel.cn/api/paas/v4}
api_key: ${MODEL_API_KEY}:- 语法提供默认值。如果环境变量不存在,使用 :- 后面的值。这种设计让敏感信息(API Key)不必硬编码在 config.yaml 中,同时保持了配置文件的可读性。
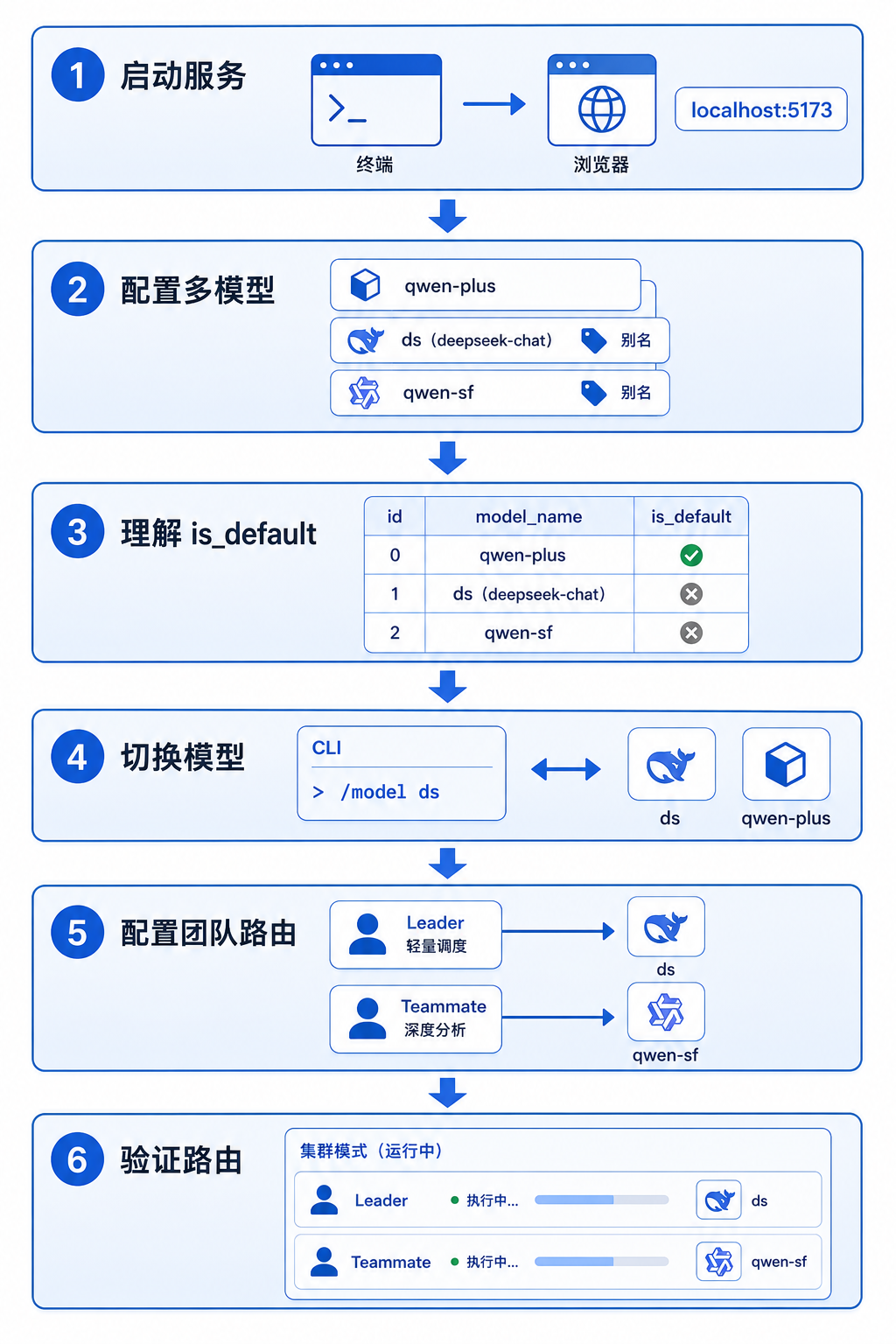
七、实操演示:多模型配置与团队模型路由
用一个完整的实操场景走一遍:从零配置多模型列表、设置别名、理解 is_default 的调度行为,再到为团队中的不同角色指定不同模型。这个场景覆盖了本文三个核心主题的全部实操要点。
7.1 场景说明
假设你正在搭建一个技术调研团队,需求如下:
- 团队中有一个 Leader(调研组长)负责拆解任务和调度,需要响应速度快、成本低的模型
- 团队中有两个 Teammate(方向调研员、报告撰写员)负责深度分析和写作,需要推理能力更强的模型
- 你还希望保留一个轻量模型做日常对话的兜底
- 三个模型走同一个 API 网关(aiping.cn),通过别名区分不同模型的定位
当前项目的三个模型均通过 https://www.aiping.cn/api/v1 接入,分别对应不同的能力定位:DeepSeek-V4-Flash 作为通用默认模型,GLM-4.7-Flash 擅长中文理解和推理,Qwen3.5-Flash 响应快速适合轻量任务。
7.2 步骤一:启动服务并进入配置面板
pip install jiuwenswarm
jiuwenswarm-init # 首次初始化
jiuwenswarm-start # 启动服务服务启动后,浏览器打开 http://localhost:5173,在左侧导航栏点击"配置信息"进入管理面板。
在面板中,确认当前处于"模型"标签页。如果已有模型配置,可以先清空,从零开始。
7.3 步骤二:配置多模型列表与别名
在模型列表区域,点击"添加模型",依次添加三个模型条目:
条目 1:DeepSeek-V4-Flash(默认模型)
|----------------|--------------------------------|
| 字段 | 值 |
| model_name | DeepSeek-V4-Flash |
| alias | 留空(自动取 model_name) |
| api_base | https://www.aiping.cn/api/v1 |
| api_key | 你的 API Key |
| model_provider | OpenAI |
| temperature | 0.95 |
条目 2:GLM-4.7-Flash
|----------------|--------------------------------|
| 字段 | 值 |
| model_name | GLM-4.7-Flash |
| alias | glm |
| api_base | https://www.aiping.cn/api/v1 |
| api_key | 你的 API Key |
| model_provider | OpenAI |
| temperature | 0.95 |
注意这里设置了别名 glm。保存后,在 CLI 中可以直接用 /model glm 切换到这个模型。
条目 3:Qwen3.5-Flash
|----------------|--------------------------------|
| 字段 | 值 |
| model_name | Qwen3.5-Flash |
| alias | qwen |
| api_base | https://www.aiping.cn/api/v1 |
| api_key | 你的 API Key |
| model_provider | OpenAI |
| temperature | 0.95 |
三个条目添加完成后,点击"保存"。三个模型走同一个 API 网关,通过不同的 model_name 调用不同的底层模型,通过别名实现快速切换。
7.4 步骤三:理解 is_default 的调度行为
保存后,观察模型列表的状态:
|------------|-------------------|-------|------------|
| 位置 | model_name | alias | is_default |
| 列表首位(全局默认) | DeepSeek-V4-Flash | (空) | true |
| 第二位 | GLM-4.7-Flash | glm | true |
| 第三位 | Qwen3.5-Flash | qwen | true |
这里有几个关键观察点:
第一,列表首位的 DeepSeek-V4-Flash 是全局默认模型。 当没有指定任何 model_name 时,系统使用这个条目。由于三个模型名称各不相同,每个都是各自组内的唯一成员,因此每个条目的 is_default 都自动为 true。
第二,别名让跨模型切换变得直观。 GLM-4.7-Flash 的别名是 glm,Qwen3.5-Flash 的别名是 qwen。在 CLI 中可以直接用 /model glm 或 /model qwen 快速切换,不需要输入完整的模型名称。
第三,精确索引仍然可用。 虽然三个模型名称不同,DeepSeek-V4-Flash#0、GLM-4.7-Flash#1、Qwen3.5-Flash#2 的索引格式依然有效,适用于需要在团队配置中精确指定模型条目的场景。
你可以做一个快速验证:在 Web 前端的聊天界面的模型下拉框中,选择不同的模型发送消息,观察实际使用的模型是否与预期一致。
7.5 步骤四:切换模型并验证持久化
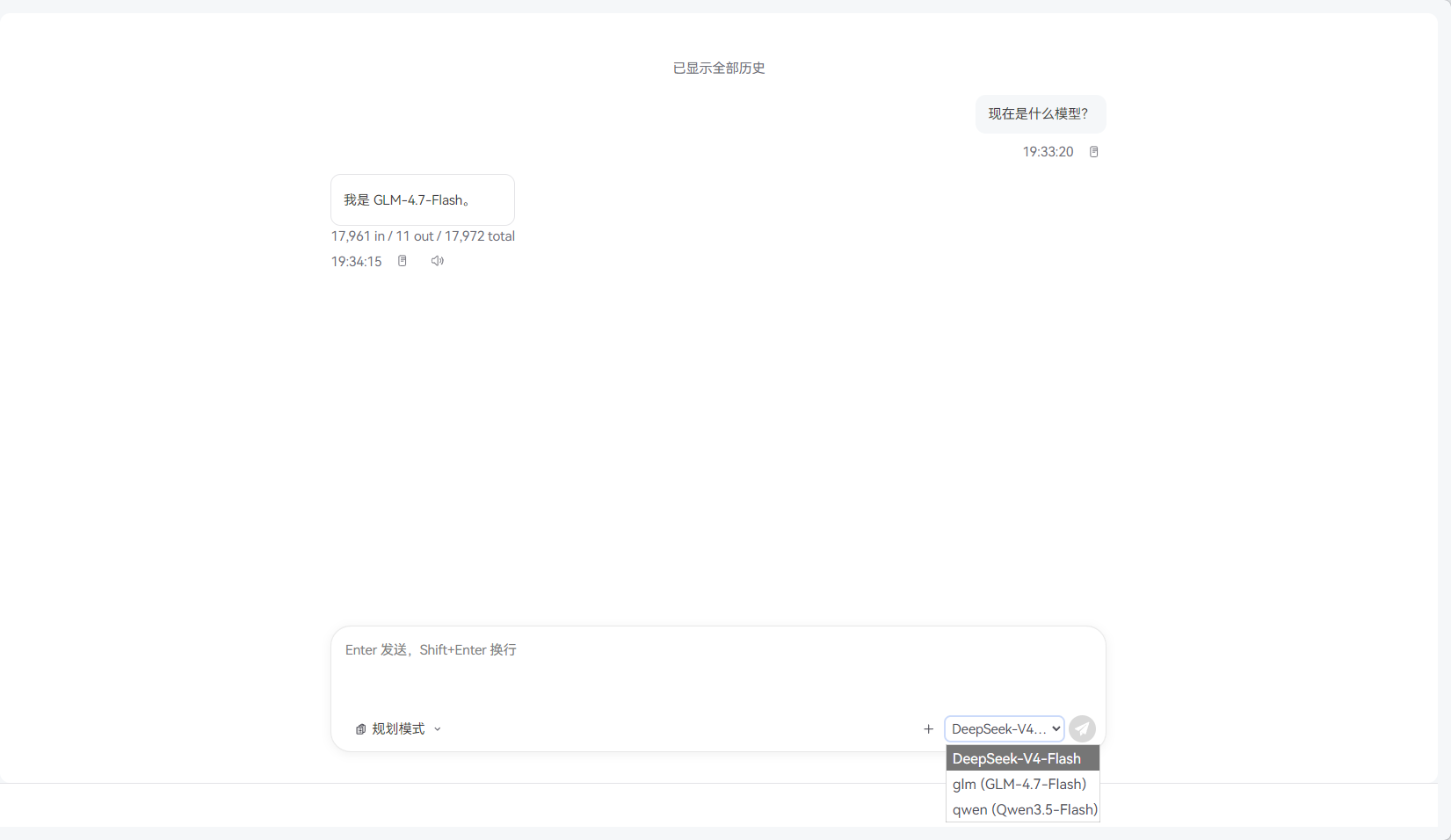
在对话中可以直接切换模型,切换后,发送一条消息验证当前使用的是 GLM-4.7-Flash。
发送消息验证。你会注意到不同模型的响应风格和速度有所差异------GLM-4.7-Flash 在中文理解和推理方面表现出色,Qwen3.5-Flash 响应速度快适合轻量任务,DeepSeek-V4-Flash 则是通用能力均衡的默认选择。
关键点:每次切换都会重排 config.yaml 中的 models.defaults 列表,目标模型被移到首位。重启服务后,默认模型仍然是上次切换后的模型。
7.6 步骤五:配置团队模型路由
回到管理面板,切换到"Agent"标签页。配置调研团队,给 Leader 和 Teammate 指定不同的模型:
Leader(调研组长)配置:
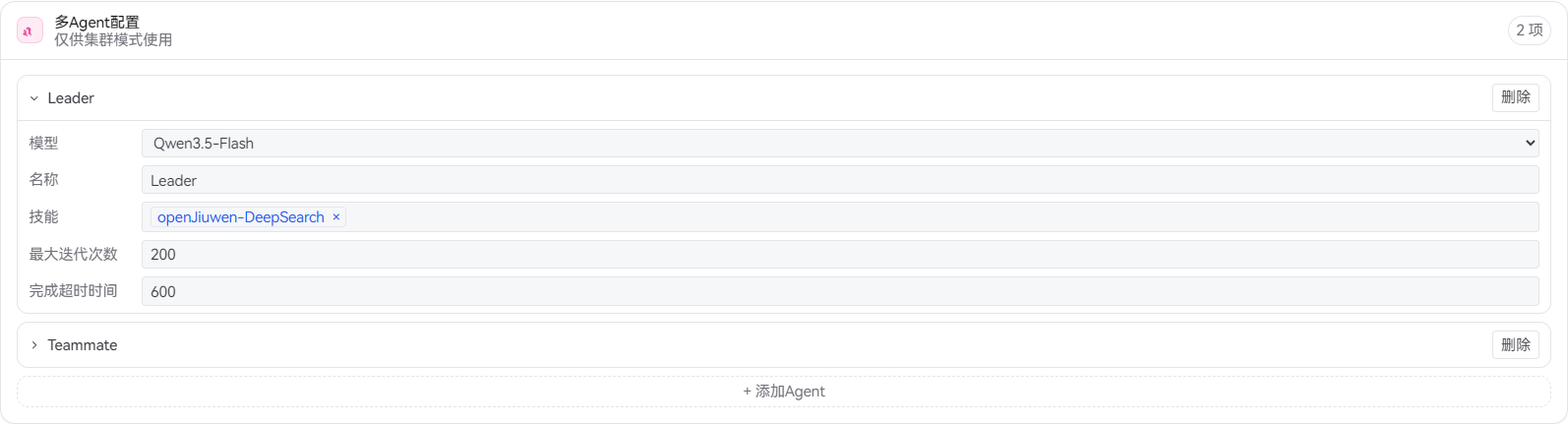
- 模型选择:
Qwen3.5-Flash(响应快速,适合任务调度和分配) - 技能:
openJiuwen-DeepSearch - max_iterations:200
- completion_timeout:600
Teammate(方向调研员)配置:
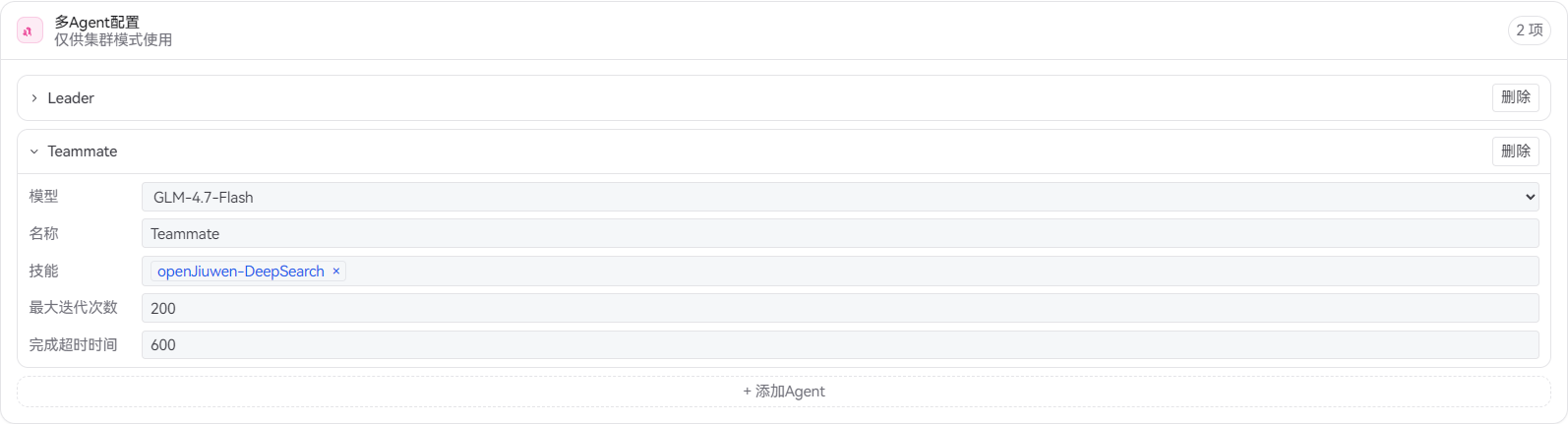
- 模型选择:
GLM-4.7-Flash(通过别名glm指定,中文理解和推理能力强,适合深度分析) - 技能:
openJiuwen-DeepSearch - max_iterations:200
- completion_timeout:600
预定义成员:
|-------|------------------|---------------------|
| 角色 | member_name | persona |
| 方向调研员 | topic_researcher | 擅长针对特定技术方向进行深度搜索和分析 |
| 报告撰写员 | report_writer | 擅长整理结构清晰、逻辑连贯的技术报告 |
保存团队配置。此时配置文件中的实际写入效果:
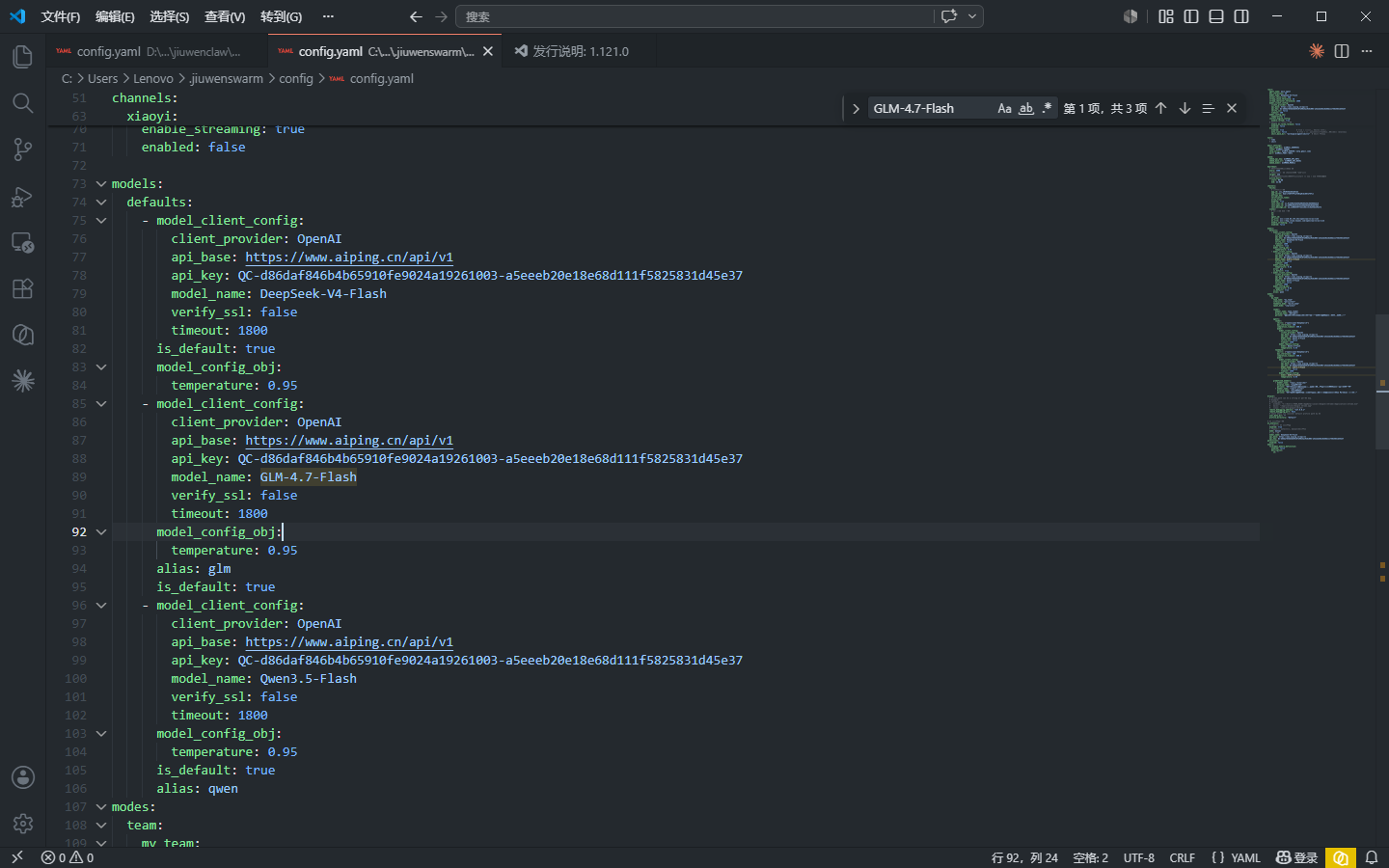
7.7 步骤六:验证团队模型路由
切换到 Web 前端的"集群模式"(点击输入框底部工具栏最右侧的集群按钮),发送一个调研任务:
帮我调研一下 JiuwenSwarm 的多项目配置机制和模型别名系统,生成一份技术分析报告。
观察团队面板中的成员运行情况:
- Leader(调研组长)使用 Qwen3.5-Flash 进行任务拆解和调度
- 方向调研员使用 GLM-4.7-Flash 进行深度搜索和分析
- 报告撰写员继承 Teammate 配置,同样使用 GLM-4.7-Flash
验证要点:观察 Leader 的响应速度和 Teammate 的分析深度。Leader 只做任务分配,不需要深度推理,Qwen3.5-Flash 响应快且成本低。Teammate 需要分析大量搜索结果、提炼观点、组织报告,GLM-4.7-Flash 的推理能力更适合。
调研完成后,检查输出结果的质量和完整性。

7.8 效果对比
|-------------|-----------------------------------|---------------------------|
| 维度 | 单模型配置 | 多模型 + 别名 + is_default |
| Leader 模型 | 与 Teammate 相同,资源浪费 | Qwen3.5-Flash 快速调度,成本低 |
| Teammate 模型 | 受限于单一选择 | GLM-4.7-Flash 推理能力强,能力匹配 |
| 多模型区分 | 只能使用一个模型 | 通过 alias 快速切换(glm / qwen) |
| 模型切换 | 记住完整 model_name | 用别名一键切换 |
| 团队配置可读性 | model: GLM-4.7-Flash#1 需查 index | model: glm 一眼识别 |
通过这个实操,三个核心概念的作用已经清晰体现:实例管理 保障了项目的独立性,is_default 消除了同名模型的调度歧义,别名让配置和切换操作变得直观高效。
八、写在最后
回顾 JiuwenSwarm 的配置管理体系,几个设计决策值得一提。
实例管理用"端口 + 工作空间"双重隔离,比简单的配置文件切换更彻底------不同实例是真的跑在不同进程里,不是同一个进程加载不同配置。进程级隔离的好处是故障隔离------一个实例的 Agent 因为模型 API 超时而崩溃,不会影响其他实例的运行。同时,端口计算采用确定性公式(base + index * 1000),不需要运行时动态协商,多实例的启动顺序没有依赖关系。
is_default 的自动推断消除了手动标记的负担,同时保留了显式覆盖的能力。自动推断的规则很直觉------同名组内唯一条目自动为默认,多个条目时第一个为默认,显式标记优先于位置推断。这套规则让 90% 的场景不需要关心 is_default 字段的存在,只在需要覆盖默认行为时才介入。
别名校验在"与其他别名"和"与 model_name"两个维度做冲突检测,杜绝了调度歧义。这个双维度校验看似严格,但实际上是必要的------如果别名 deepseek-chat 恰好与另一个模型的 model_name 相同,系统在解析 /model deepseek-chat 时就无法确定用户是要切换到别名的模型还是要切换到同名的模型。严格的唯一性约束换取的是调度结果的确定性。
从开发流程的角度看,这套配置体系的优化空间在于"降低配置切换的认知成本"。实例管理让开发者不用关心"现在改的是哪个项目的配置";is_default 让调度规则有明确语义,不用猜"系统会选哪个";别名让模型切换变成一个短命令而不是长字符串。三者配合之下,配置操作的心智负担被压到了很低的水平。
与 JiuwenSwarm 的核心协同能力(技能自演进、记忆系统、HOTS/HITS 人机协作)相比,配置管理属于"基础设施层"------它不直接产生智能体能力的提升,但决定了这些能力能不能在不同项目、不同模型之间顺畅运转。如果配置管理做不好,再强的协同能力也会被"切错模型""改错配置"这类低级问题拖累。
目前还有一些可以探索的方向。实例管理层面,当前的多实例需要手动配置 instances.yaml,如果能提供实例创建/销毁的 CLI 命令(类似 jiuwenswarm instance create ecommerce),上手门槛会更低。别名层面,当前别名只在模型切换时使用,如果能在团队配置、技能配置等更多场景中引用别名,配置的可读性会进一步提升。面板层面,配置变更后需要重启服务才生效,如果支持热加载,开发体验会更好。is_default 层面,当前只在同名组内做默认推断,如果能在不同模型之间也支持"场景化默认"(比如代码任务默认用模型 A,写作任务默认用模型 B),调度的灵活性会更高。
总的来说,这是一套以"消除配置歧义"为核心的配置管理方案------重心放在确保每个配置操作都有明确的语义和可预测的结果,而不是追求配置选项的堆砌。对于在多项目、多模型场景下使用 JiuwenSwarm 的开发者来说,理解这套机制有助于避免"配置看起来对但行为不对"的困惑,也能更好地利用管理面板的 UI 能力来提升日常开发效率。
参考资料: