目录
[一、LLM 有大脑,但没有手脚](#一、LLM 有大脑,但没有手脚)
[二、为什么需要 Tool Calling?](#二、为什么需要 Tool Calling?)
[(一)连接「会思考的 LLM」和「能执行的工具」](#(一)连接「会思考的 LLM」和「能执行的工具」)
[(一)@tool 装饰器:把函数变成工具](#(一)@tool 装饰器:把函数变成工具)
[(二)LangGraph 中的执行循环](#(二)LangGraph 中的执行循环)
[1. last_message.tool_calls](#1. last_message.tool_calls)
[2. tool_maptool_name.invoke(tool_args)](#2. tool_map[tool_name].invoke(tool_args))
[3. ToolMessage(..., tool_call_id=tool_id)](#3. ToolMessage(..., tool_call_id=tool_id))
[五、实战代码:最小 Tool Agent 骨架](#五、实战代码:最小 Tool Agent 骨架)
[1. 消息链长度:4 vs 2](#1. 消息链长度:4 vs 2)
[2. 工具返回值不是 LLM 算出来的](#2. 工具返回值不是 LLM 算出来的)
[(四)真实跑一遍:在线 LLM + 在线天气 API](#(四)真实跑一遍:在线 LLM + 在线天气 API)
[1. 工具改造:调用 Open-Meteo 真实天气接口](#1. 工具改造:调用 Open-Meteo 真实天气接口)
[2. LLM 改造:真实模型自主决策](#2. LLM 改造:真实模型自主决策)
[3. 真实运行效果](#3. 真实运行效果)
[(一)坑 1:工具没有 bind_tools,LLM 永远不会调用工具](#(一)坑 1:工具没有 bind_tools,LLM 永远不会调用工具)
[(二)坑 2:docstring 太敷衍,LLM 选错工具或不选工具](#(二)坑 2:docstring 太敷衍,LLM 选错工具或不选工具)
[(三)坑 3:ToolMessage 缺少 tool_call_id](#(三)坑 3:ToolMessage 缺少 tool_call_id)
[1. 工具描述质量决定调用准确率](#1. 工具描述质量决定调用准确率)
[2. 参数类型要保持 JSON 兼容](#2. 参数类型要保持 JSON 兼容)
[3. 工具执行一定可能失败](#3. 工具执行一定可能失败)
[4. 有副作用的工具必须加安全控制](#4. 有副作用的工具必须加安全控制)
[1. 可观测性](#1. 可观测性)
[2. 参数白名单](#2. 参数白名单)
[3. 工具版本与灰度](#3. 工具版本与灰度)
干货分享,感谢您的阅读!
这是「LangGraph Agent Engineering Mastery」系列 Stage 2 的第一篇。
读完本文,你将搞懂:一个普通 Python 函数是如何变成 LLM 可以调用的「工具」的,以及 LLM 决策 → 工具执行 → 结果回传 这条链路在 LangGraph 中是如何转起来的。
一、LLM 有大脑,但没有手脚
你大概率遇到过这样的场景:
用户问:
北京今天天气怎么样?
LLM 一本正经地回答:
抱歉,我的训练数据截止到 2023 年......
那一刻你会意识到:纯 LLM 本质上是一个有知识但没手脚的大脑。它能聊天、能写文章、能推理,但它不能直接:
- 查实时天气
- 下订单
- 发邮件
- 查数据库
- 操作业务系统
Tool Calling,就是给这个"大脑"装上手脚的过程。
本文会用一个能做加法、乘法、查天气的最小 Agent,把 Tool Calling 从里到外讲清楚:不依赖框架黑盒,而是手写完整的 LLM → Tool → LLM 调用循环。
二、为什么需要 Tool Calling?
(一)连接「会思考的 LLM」和「能执行的工具」
当 AI Agent 只能依赖训练数据回答问题时,它本质上只是一个「高级聊天机器人」。而 Tool Calling 让 Agent 能够调用外部函数,从而获取实时数据、执行动作、与真实系统交互。这也是 Agent 从「聊天机器人」进化为「智能助手」的关键分水岭。
用后端工程师更熟悉的话来说:
LLM 像一个只会写 SQL、但连不上数据库的人。
它知道该查什么,但真正执行查询、拿到结果的,是你的运行时框架。
Tool Calling 要做的,就是把「会思考的 LLM」和「能执行的工具」连接起来。
(二)它解决了什么问题?
传统 LLM 应用面临一个根本矛盾:
LLM 的知识是静态的,但用户的需求是动态的。
| 用户诉求 | 纯 LLM | 接入 Tool Calling 后 |
|---|---|---|
| 今天天气如何 | 无法可靠回答,因为训练数据有截止日期 | 调用 search_weather 获取实时天气 |
| 帮我算 3 + 5 | 可能算错,尤其是复杂计算 | 调用 add 工具精确计算 |
| 帮我发邮件 | 只能生成邮件文本 | 调用 send_email 真正发送 |
| 查我的订单 | 没有业务系统权限 | 调用 query_order 查询业务库 |
Tool Calling 的核心价值是:LLM 负责判断"要做什么",工具负责真正"去执行"。
三、核心原理:完整链路分四步
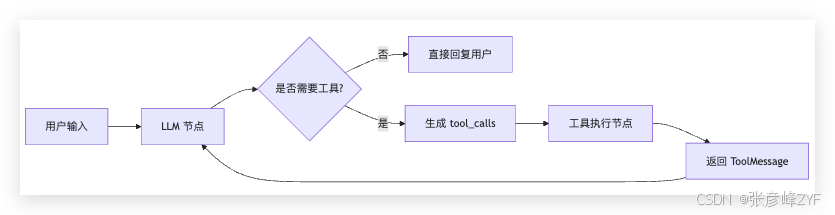
Tool Calling 的完整链路可以拆成四步:
1. 注册工具 → LLM 知道有哪些工具可用
2. LLM 决策 → 判断是否需要工具,并生成工具名与参数
3. 工具执行 → 框架执行对应函数,拿到返回值
4. 结果整合 → LLM 将工具结果整理成自然语言回复注意一个关键点:
工具执行完之后,并不是直接把结果返回给用户,而是把结果塞回消息链,再交给 LLM。
由 LLM 决定:继续调用工具,还是生成最终回答。
(一)@tool 装饰器:把函数变成工具
LangChain 的 @tool 装饰器,是连接 Python 函数与 LLM 的桥梁。例如:
python
from langchain_core.tools import tool
@tool
def search_weather(city: str) -> str:
"""查询指定城市的实时天气。当用户询问天气时使用。"""
return weather_api.query(city)一个普通函数被 @tool 包装之后,会被转换成 LLM 能理解的工具描述。它主要提取三类信息:
|-----------|---------------------------|
| 来源 | 作用 |
| 函数名 | 工具标识符,例如 search_weather |
| docstring | 工具描述,用来帮助 LLM 判断何时使用 |
| 类型注解 | 参数 Schema,用来约束 LLM 生成参数 |
也就是说,下面这些代码信息:
python
def search_weather(city: str) -> str:
"""查询指定城市的实时天气。当用户询问天气时使用。"""会被转换成类似这样的工具结构:
python
工具名: search_weather
工具描述: 查询指定城市的实时天气。当用户询问天气时使用。
参数:
city: string这也是为什么工具的 docstring 非常重要。它不是写给人看的注释,而是写给 LLM 看的「工具使用说明书」。
(二)LangGraph 中的执行循环
在 LangGraph 里,Tool Calling 通常形成一个带条件分支的循环:
START
↓
LLM 节点
↓
是否存在 tool_calls?
├─ 是 → 工具节点 → 工具结果回传 → LLM 节点
└─ 否 → END对应成图就是:
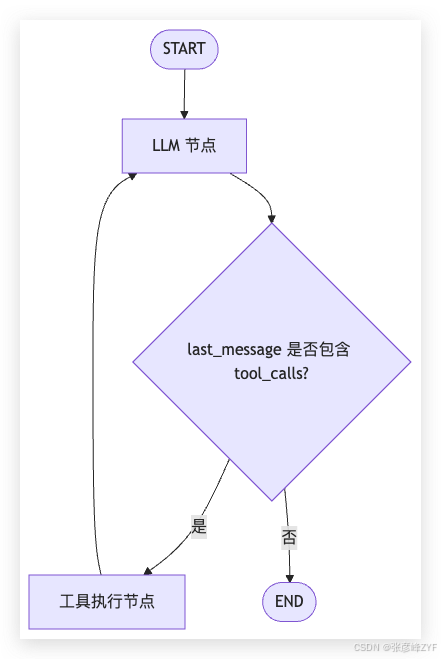
这里最关键的是这个循环:
LLM → Tool → LLM第一次进入 LLM,是让它判断是否需要工具。工具执行完成后再次回到 LLM,是让它基于工具结果生成最终回答。
四、源码分析:手写工具执行节点
(一)关键代码说明
@tool 装饰器的核心实现位于:
langchain_core/tools/convert.py它主要做了三件事:
- 使用
inspect.signature()提取函数参数名和类型注解 - 将类型注解转换为 Pydantic
BaseModel,也就是args_schema - 创建
StructuredTool实例,包含name、description、func、args_schema
为了看清 Tool Calling 的每一步,我们的 Demo 没有直接使用框架自带的 ToolNode,而是手写了一个工具执行节点。核心代码如下:
python
def tool_node(state: ToolDemoState) -> dict:
"""工具执行节点 --- 解析 tool_calls 并执行对应工具。"""
messages = state["messages"]
last_message = messages[-1]
tool_messages = []
if hasattr(last_message, "tool_calls") and last_message.tool_calls:
for tc in last_message.tool_calls:
tool_name = tc["name"]
tool_args = tc["args"]
tool_id = tc["id"]
log_step(
logger,
"工具执行",
f"调用 {tool_name}({tool_args})",
)
if tool_name in tool_map:
result = tool_map[tool_name].invoke(tool_args)
log_success(logger, f"工具 {tool_name} 返回: {result}")
else:
result = f"错误:未找到工具 '{tool_name}'"
tool_messages.append(
ToolMessage(
content=str(result),
tool_call_id=tool_id,
name=tool_name,
)
)
return {"messages": tool_messages}(二)关键点说明
这段代码里有几个关键点。
1. last_message.tool_calls
LLM 并不会直接执行工具。它只会输出一个结构化调用请求,例如:
python
[
{
"id": "call_xxx",
"name": "add",
"args": {"a": 3, "b": 5}
}
]也就是说,LLM 的职责是生成:
请帮我调用
add(a=3, b=5)
而不是自己去执行 Python 函数。
2. tool_map[tool_name].invoke(tool_args)
真正执行工具的是框架或运行时。
python
result = tool_map[tool_name].invoke(tool_args)这里会根据工具名找到对应的 Tool 对象,并把 LLM 生成的参数传进去执行。
比如:
add.invoke({"a": 3, "b": 5})最终得到:
8这个 8 是 Python 函数计算出来的,不是 LLM 自己算出来的。
3. ToolMessage(..., tool_call_id=tool_id)
工具结果需要包装成 ToolMessage 放回消息链。
python
ToolMessage(
content=str(result),
tool_call_id=tool_id,
name=tool_name,
)其中最重要的是:
tool_call_id=tool_id它用于把「工具执行结果」和「LLM 发起的那次工具调用」一一对应起来。这在一次调用多个工具时尤其重要。
(三)路由函数:决定循环是否继续
工具节点之外,还需要一个路由函数来判断是否进入工具执行分支。
python
def should_call_tool(state: ToolDemoState) -> str:
"""路由函数:判断最后一条消息是否包含 tool_calls。"""
messages = state["messages"]
last_message = messages[-1]
if hasattr(last_message, "tool_calls") and last_message.tool_calls:
return "tools"
return "end"逻辑非常简单:
如果最后一条 AIMessage 里有 tool_calls → 进入 tools 节点
否则 → 结束流程这就是 LangGraph 中 Tool Calling 循环的控制开关。
五、实战代码:最小 Tool Agent 骨架
(一)整体设计代码
下面是一段自包含的最小骨架,用来理解 LangGraph 中 Tool Calling 的整体结构。完整可运行版本见 main.py。
python
"""Demo 01: Tool Basics --- @tool 装饰器与 Tool Binding。
演示 Tool Calling 的三大核心要素:
1. @tool 装饰器:将 Python 函数转化为 LLM 可调用的工具
2. Tool Binding:将工具注册给 LLM
3. ToolNode:在 StateGraph 中执行工具调用
运行方式:
python stages/stage2_tool_calling/01_tool_basics/main.py
"""
from __future__ import annotations
import sys
from pathlib import Path
from typing import Annotated, TypedDict
from langchain_core.messages import (
AIMessage,
BaseMessage,
HumanMessage,
ToolMessage,
)
from langchain_core.tools import tool
from langgraph.graph import END, START, StateGraph
from langgraph.graph.message import add_messages
sys.path.insert(0, str(Path(__file__).resolve().parent.parent.parent.parent))
from shared import get_logger, log_step, log_success
logger = get_logger("demo.01_tool_basics")
# ============================================================
# 第一步:使用 @tool 装饰器定义工具
# @tool 会从函数名、docstring、类型注解自动生成工具描述
# ============================================================
@tool
def add(a: int, b: int) -> int:
"""将两个整数相加并返回结果。当用户要求计算加法时使用此工具。"""
return a + b
@tool
def multiply(a: int, b: int) -> int:
"""将两个整数相乘并返回结果。当用户要求计算乘法时使用此工具。"""
return a * b
@tool
def search_weather(city: str) -> str:
"""查询指定城市的实时天气信息。当用户询问天气时使用此工具。
Args:
city: 城市名称,如"北京"、"上海"
"""
weather_data = {
"北京": "晴,25°C,湿度 40%",
"上海": "多云,28°C,湿度 65%",
"广州": "阵雨,30°C,湿度 80%",
}
return weather_data.get(city, f"{city}:暂无天气数据")
# ============================================================
# 第二步:定义 State
# 使用 MessagesState 风格,messages 字段自动累加
# ============================================================
class ToolDemoState(TypedDict):
messages: Annotated[list[BaseMessage], add_messages]
# ============================================================
# 第三步:构建 Tool Calling Graph
# ============================================================
def build_tool_basics_graph(tools: list | None = None):
"""构建演示 Tool Binding 的基础图。
这个图演示手动处理 tool_calls 的完整流程:
1. LLM 节点决定是否调用工具
2. 工具节点执行工具并返回结果
3. 结果回传给 LLM 节点生成最终回复
"""
if tools is None:
tools = [add, multiply, search_weather]
tool_map = {t.name: t for t in tools}
def llm_node(state: ToolDemoState) -> dict:
"""模拟 LLM 决策节点。
分析最后一条消息,决定是否需要调用工具。
在 Mock 模式下,通过关键词匹配模拟 LLM 的工具调用决策。
"""
messages = state["messages"]
last_message = messages[-1]
if isinstance(last_message, ToolMessage):
log_step(logger, "LLM 节点", "收到工具结果,生成最终回复")
tool_result = last_message.content
return {
"messages": [AIMessage(content=f"根据工具调用结果:{tool_result}")]
}
content = str(last_message.content).lower()
log_step(logger, "LLM 节点", f"分析用户输入: '{last_message.content}'")
if "加" in content or "+" in content:
log_step(logger, "LLM 决策", "需要调用 add 工具")
return {
"messages": [
AIMessage(
content="",
tool_calls=[
{
"id": "call_add_001",
"name": "add",
"args": {"a": 3, "b": 5},
}
],
)
]
}
elif "乘" in content or "×" in content or "*" in content:
log_step(logger, "LLM 决策", "需要调用 multiply 工具")
return {
"messages": [
AIMessage(
content="",
tool_calls=[
{
"id": "call_mul_001",
"name": "multiply",
"args": {"a": 4, "b": 7},
}
],
)
]
}
elif "天气" in content:
city = "北京"
for c in ["北京", "上海", "广州"]:
if c in content:
city = c
break
log_step(logger, "LLM 决策", f"需要调用 search_weather 工具,城市: {city}")
return {
"messages": [
AIMessage(
content="",
tool_calls=[
{
"id": "call_weather_001",
"name": "search_weather",
"args": {"city": city},
}
],
)
]
}
else:
log_step(logger, "LLM 决策", "不需要工具,直接回复")
return {
"messages": [
AIMessage(content="你好!我可以帮你做数学计算或查询天气。")
]
}
def tool_node(state: ToolDemoState) -> dict:
"""工具执行节点 --- 解析 tool_calls 并执行对应工具。"""
messages = state["messages"]
last_message = messages[-1]
tool_messages = []
if hasattr(last_message, "tool_calls") and last_message.tool_calls:
for tc in last_message.tool_calls:
tool_name = tc["name"]
tool_args = tc["args"]
tool_id = tc["id"]
log_step(
logger,
"工具执行",
f"调用 {tool_name}({tool_args})",
)
if tool_name in tool_map:
result = tool_map[tool_name].invoke(tool_args)
log_success(logger, f"工具 {tool_name} 返回: {result}")
else:
result = f"错误:未找到工具 '{tool_name}'"
tool_messages.append(
ToolMessage(
content=str(result),
tool_call_id=tool_id,
name=tool_name,
)
)
return {"messages": tool_messages}
def should_call_tool(state: ToolDemoState) -> str:
"""路由函数:判断最后一条消息是否包含 tool_calls。"""
messages = state["messages"]
last_message = messages[-1]
if hasattr(last_message, "tool_calls") and last_message.tool_calls:
return "tools"
return "end"
graph = StateGraph(ToolDemoState)
graph.add_node("llm", llm_node)
graph.add_node("tools", tool_node)
graph.add_edge(START, "llm")
graph.add_conditional_edges("llm", should_call_tool, {
"tools": "tools",
"end": END,
})
graph.add_edge("tools", "llm")
return graph
# ============================================================
# 第四步:运行演示
# ============================================================
def demo_tool_definition():
"""演示 1:@tool 装饰器和工具属性。"""
print("\n--- 演示 1: @tool 装饰器 ---\n")
tools = [add, multiply, search_weather]
for t in tools:
print(f" 工具名: {t.name}")
print(f" 描述 : {t.description}")
print(f" 参数 : {t.args_schema.model_json_schema() if t.args_schema else 'N/A'}")
print()
return tools
def demo_tool_binding():
"""演示 2:Tool Binding --- 将工具绑定到 LLM。"""
print("\n--- 演示 2: Tool Binding ---\n")
from shared import MockChatModel
llm = MockChatModel()
tools = [add, multiply, search_weather]
log_step(logger, "Tool Binding", f"将 {len(tools)} 个工具绑定到 LLM")
try:
llm_with_tools = llm.bind_tools(tools)
print(f" 绑定后对象: {type(llm_with_tools).__name__}")
except NotImplementedError:
llm_with_tools = llm
print(" (MockChatModel 不支持 bind_tools,生产中使用真实 LLM 即可)")
print(f" 绑定的工具: {[t.name for t in tools]}")
print(f" LLM 类型 : {llm._llm_type}")
print()
print(" 说明: bind_tools() 将工具的 JSON Schema 注入到 LLM 请求参数中,")
print(" 让 LLM 在每次调用时都能看到可用工具列表。")
print(" Mock 模式下我们通过手动逻辑模拟工具选择行为。")
return llm_with_tools
def demo_tool_graph():
"""演示 3:完整的 Tool Calling Graph 执行。"""
print("\n--- 演示 3: Tool Calling Graph ---\n")
graph = build_tool_basics_graph()
app = graph.compile()
test_cases = [
"帮我计算 3 加 5",
"4 乘以 7 等于多少?",
"北京今天天气怎么样?",
"你好",
]
results = []
for question in test_cases:
print(f"\n 用户: {question}")
print(f" {'─' * 40}")
result = app.invoke({"messages": [HumanMessage(content=question)]})
final_msg = result["messages"][-1]
print(f" 助手: {final_msg.content}")
print(f" 消息链长度: {len(result['messages'])}")
results.append(result)
return results
def run_demo() -> dict:
"""运行 Tool Basics 全部演示。"""
print("=" * 60)
print(" Demo 01: Tool Basics --- @tool 装饰器与 Tool Binding")
print("=" * 60)
tools = demo_tool_definition()
llm_with_tools = demo_tool_binding()
results = demo_tool_graph()
print()
print("=" * 60)
print(" 关键概念回顾")
print("=" * 60)
print(" 1. @tool : 将 Python 函数转化为 LLM 可调用的工具对象")
print(" 2. Binding : 将工具列表注册给 LLM,LLM 获知可用工具")
print(" 3. tool_calls: LLM 输出的结构化工具调用请求")
print(" 4. ToolMessage: 工具执行结果的标准消息格式")
print(" 5. ToolNode : StateGraph 中负责执行工具的节点")
print(" 6. 路由函数 : 判断 LLM 输出是否包含 tool_calls")
print(" 7. 循环结构 : tools → llm → (判断) → tools/end")
print()
return {
"tools": tools,
"llm_with_tools": llm_with_tools,
"results": results,
}
if __name__ == "__main__":
run_demo()运行方式:
python
source .venv/bin/activate
python stages/stage2_tool_calling/01_tool_basics/main.py这段代码的结构可以理解为:
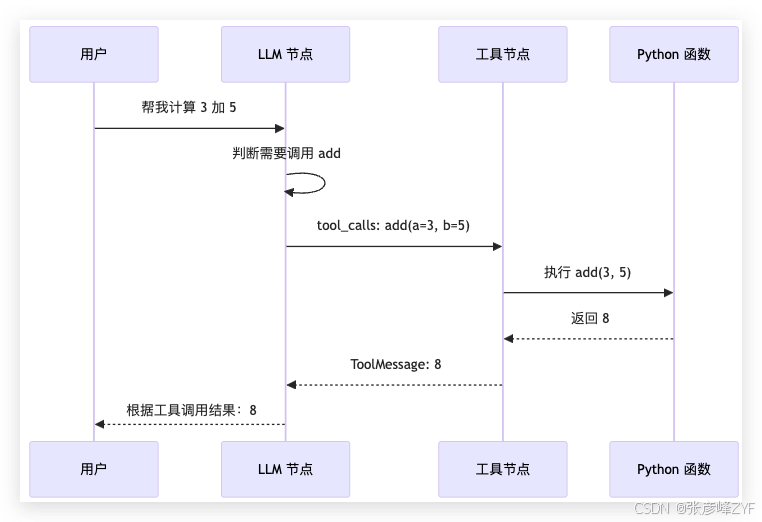
(二)运行效果
下面是实际执行 main.py 的输出截取。这里使用的是 Mock 模式,工具选择由本地逻辑模拟;如果换成真实 LLM,只需要替换 MockChatModel 即可。
Connected to server 127.0.0.1:56450
============================================================
Demo 01: Tool Basics --- @tool 装饰器与 Tool Binding
============================================================
--- 演示 1: @tool 装饰器 ---
工具名: add
描述 : 将两个整数相加并返回结果。当用户要求计算加法时使用此工具。
参数 : {'description': '将两个整数相加并返回结果。当用户要求计算加法时使用此工具。', 'properties': {'a': {'title': 'A', 'type': 'integer'}, 'b': {'title': 'B', 'type': 'integer'}}, 'required': 'a', 'b', 'title': 'add', 'type': 'object'}
工具名: multiply
描述 : 将两个整数相乘并返回结果。当用户要求计算乘法时使用此工具。
参数 : {'description': '将两个整数相乘并返回结果。当用户要求计算乘法时使用此工具。', 'properties': {'a': {'title': 'A', 'type': 'integer'}, 'b': {'title': 'B', 'type': 'integer'}}, 'required': 'a', 'b', 'title': 'multiply', 'type': 'object'}
工具名: search_weather
描述 : 查询指定城市的实时天气信息。当用户询问天气时使用此工具。
Args:
city: 城市名称,如"北京"、"上海"
参数 : {'description': '查询指定城市的实时天气信息。当用户询问天气时使用此工具。\n\nArgs:\n city: 城市名称,如"北京"、"上海"', 'properties': {'city': {'title': 'City', 'type': 'string'}}, 'required': 'city', 'title': 'search_weather', 'type': 'object'}
--- 演示 2: Tool Binding ---
(MockChatModel 不支持 bind_tools,生产中使用真实 LLM 即可)
绑定的工具: 'add', 'multiply', 'search_weather'
LLM 类型 : mock
说明: bind_tools() 将工具的 JSON Schema 注入到 LLM 请求参数中,
让 LLM 在每次调用时都能看到可用工具列表。
Mock 模式下我们通过手动逻辑模拟工具选择行为。
--- 演示 3: Tool Calling Graph ---
用户: 帮我计算 3 加 5
────────────────────────────────────────
助手: 根据工具调用结果:8
消息链长度: 4
用户: 4 乘以 7 等于多少?
────────────────────────────────────────
助手: 根据工具调用结果:28
消息链长度: 4
用户: 北京今天天气怎么样?
────────────────────────────────────────
2026-06-08 19:24:40 INFO demo.01_tool_basics | 📌 Tool Binding 将 3
个工具绑定到 LLM
INFO demo.01_tool_basics | 📌 LLM 节点 分析用户输入:
'帮我计算 3 加 5'
INFO demo.01_tool_basics | 📌 LLM 决策 需要调用 add
工具
INFO demo.01_tool_basics | 📌 工具执行 调用 add({'a':
3, 'b': 5})
INFO demo.01_tool_basics | ✅ 工具 add 返回: 8
INFO demo.01_tool_basics | 📌 LLM 节点
收到工具结果,生成最终回复
INFO demo.01_tool_basics | 📌 LLM 节点 分析用户输入:
'4 乘以 7 等于多少?'
INFO demo.01_tool_basics | 📌 LLM 决策 需要调用
multiply 工具
INFO demo.01_tool_basics | 📌 工具执行 调用
multiply({'a': 4, 'b': 7})
INFO demo.01_tool_basics | ✅ 工具 multiply 返回: 28
INFO demo.01_tool_basics | 📌 LLM 节点
收到工具结果,生成最终回复
INFO demo.01_tool_basics | 📌 LLM 节点 分析用户输入:
'北京今天天气怎么样?'
INFO demo.01_tool_basics | 📌 LLM 决策 需要调用
search_weather 工具,城市: 北京
INFO demo.01_tool_basics | 📌 工具执行 调用
search_weather({'city': '北京'})
INFO demo.01_tool_basics | ✅ 工具 search_weather 返回:
晴,25°C,湿度 40%
INFO demo.01_tool_basics | 📌 LLM 节点
收到工具结果,生成最终回复
INFO demo.01_tool_basics | 📌 LLM 节点 分析用户输入:
'你好'
INFO demo.01_tool_basics | 📌 LLM 决策
不需要工具,直接回复
助手: 根据工具调用结果:晴,25°C,湿度 40%
消息链长度: 4
用户: 你好
────────────────────────────────────────
助手: 你好!我可以帮你做数学计算或查询天气。
消息链长度: 2
--- 演示 4: 真实 LLM + 真实在线工具 ---
2026-06-08 19:24:41 INFO shared.llm_factory | 已创建 deepseek LLM 实例
2026-06-08 19:24:41 INFO demo.01_tool_basics | ✅ 已获取真实在线
LLM:deepseek
INFO demo.01_tool_basics | 📌 真实 LLM
调用在线模型进行决策......
用户: 上海现在天气怎么样?
──────────────────────────────────────────────────
2026-06-08 19:24:43 INFO demo.01_tool_basics | 📌 LLM 决策 自主选择工具
get_weather_online,参数 {'city': '上海'}
INFO demo.01_tool_basics | 📌 工具执行 调用
get_weather_online({'city': '上海'})
2026-06-08 19:24:45 INFO demo.01_tool_basics | ✅ 工具 get_weather_online
返回: 中国上海 实时天气:局部多云,气温
21.5°C,湿度 60%,风速 8.1 km/h
INFO demo.01_tool_basics | 📌 真实 LLM
调用在线模型进行决策......
2026-06-08 19:24:47 INFO demo.01_tool_basics | 📌 LLM 决策
无需工具,直接回复:
上海现在的天气是局部多云,气温为21.5°C,湿度60%,风
速8.1 km/h。
INFO demo.01_tool_basics | 📌 真实 LLM
调用在线模型进行决策......
助手: 上海现在的天气是局部多云,气温为21.5°C,湿度60%,风速8.1 km/h。
消息链长度: 4
用户: 帮我算一下 128 加 256 等于多少
──────────────────────────────────────────────────
2026-06-08 19:24:48 INFO demo.01_tool_basics | 📌 LLM 决策 自主选择工具
add,参数 {'a': 128, 'b': 256}
INFO demo.01_tool_basics | 📌 工具执行 调用 add({'a':
128, 'b': 256})
INFO demo.01_tool_basics | ✅ 工具 add 返回: 384
INFO demo.01_tool_basics | 📌 真实 LLM
调用在线模型进行决策......
2026-06-08 19:24:49 INFO demo.01_tool_basics | 📌 LLM 决策
无需工具,直接回复: 128 加 256 等于 384。
INFO demo.01_tool_basics | 📌 真实 LLM
调用在线模型进行决策......
助手: 128 加 256 等于 384。
消息链长度: 4
用户: 东京和北京现在分别多少度?
──────────────────────────────────────────────────
2026-06-08 19:24:51 INFO demo.01_tool_basics | 📌 LLM 决策 自主选择工具
get_weather_online,参数 {'city': '东京'}
INFO demo.01_tool_basics | 📌 LLM 决策 自主选择工具
get_weather_online,参数 {'city': '北京'}
INFO demo.01_tool_basics | 📌 工具执行 调用
get_weather_online({'city': '东京'})
2026-06-08 19:24:53 INFO demo.01_tool_basics | ✅ 工具 get_weather_online
返回: 中国东京 实时天气:阴,气温 22.6°C,湿度
62%,风速 7.1 km/h
INFO demo.01_tool_basics | 📌 工具执行 调用
get_weather_online({'city': '北京'})
2026-06-08 19:24:55 INFO demo.01_tool_basics | ✅ 工具 get_weather_online
返回: 中国北京 实时天气:局部多云,气温
23.2°C,湿度 52%,风速 4.9 km/h
INFO demo.01_tool_basics | 📌 真实 LLM
调用在线模型进行决策......
2026-06-08 19:24:57 INFO demo.01_tool_basics | 📌 LLM 决策
无需工具,直接回复:
东京现在的天气是阴天,气温为22.6°C,湿度62%,风速7.
1 km/h。
北京现在的天气是局部
助手: 东京现在的天气是阴天,气温为22.6°C,湿度62%,风速7.1 km/h。
北京现在的天气是局部多云,气温为23.2°C,湿度52%,风速4.9 km/h。
消息链长度: 5
============================================================
关键概念回顾
============================================================
@tool : 将 Python 函数转化为 LLM 可调用的工具对象
Binding : 将工具列表注册给 LLM,LLM 获知可用工具
tool_calls: LLM 输出的结构化工具调用请求
ToolMessage: 工具执行结果的标准消息格式
ToolNode : StateGraph 中负责执行工具的节点
路由函数 : 判断 LLM 输出是否包含 tool_calls
循环结构 : tools → llm → (判断) → tools/end
Process finished with exit code 0
伴随日志可以清晰看到整个循环:
📌 [LLM 节点] 分析用户输入: '帮我计算 3 加 5'
📌 [LLM 决策] 需要调用 add 工具
📌 [工具执行] 调用 add({'a': 3, 'b': 5})
✅ 工具 add 返回: 8
📌 [LLM 节点] 收到工具结果,生成最终回复(三)如何解读这个输出?
这里有两个非常重要的细节。
1. 消息链长度:4 vs 2
需要调用工具时,消息链是:
HumanMessage
AIMessage(tool_calls)
ToolMessage
AIMessage(final)所以一共有 4 条。
不需要调用工具时,比如用户只是说「你好」,消息链只有:
HumanMessage
AIMessage所以只有 2 条。这说明:LLM 会自己判断要不要进入工具调用循环。
2. 工具返回值不是 LLM 算出来的
以「帮我计算 3 加 5」为例。LLM 只生成了调用意图:
请调用 add(a=3, b=5)真正的计算发生在 Python 工具函数里:
def add(a: int, b: int) -> int:
return a + b然后工具返回:
8最后 LLM 再把这个结果包装成自然语言:
根据工具调用结果:8这就是 Tool Calling 的核心分工:
LLM 负责想,工具负责做。
(四)真实跑一遍:在线 LLM + 在线天气 API
Mock 模式适合理解结构,但「关键词匹配 + 写死的天气字典」毕竟是演示。要确认这条链路真的能跑通,必须让两端都变成真实的:
- -LLM 端:用真实的在线大模型(DeepSeek / OpenAI / Claude / Gemini),由它自己决定调哪个工具、生成什么参数;
- -工具端:工具内部去打真实的在线 API,而不是返回写死的字典。
1. 工具改造:调用 Open-Meteo 真实天气接口
我们新增了一个 `get_weather_online` 工具,它通过两次真实 HTTP 请求拿到实时天气(Open-Meteo 是免费公开 API,无需 API Key):
python
92:112:stages/stage2_tool_calling/01_tool_basics/main.py
@tool
def get_weather_online(city: str) -> str:
"""查询指定城市的实时天气,调用 Open-Meteo 在线公开 API(无需 API Key)。
当用户询问某个城市当前的天气、气温、湿度、风力时使用此工具。
Args:
city: 城市名称,支持中英文,如 "北京"、"上海"、"Tokyo"、"London"
"""
import httpx
try:
# 第一步:地理编码,把城市名解析为经纬度
geo_resp = httpx.get(
"https://geocoding-api.open-meteo.com/v1/search",
params={"name": city, "count": 1, "language": "zh", "format": "json"},
timeout=10,
)
geo_resp.raise_for_status()
results = geo_resp.json().get("results")
if not results:
return f"未找到城市 '{city}' 的地理位置信息,请换一个更明确的城市名。"注意工具的设计要点:自带容*。在线 API 会超时、会返回空、会 4xx/5xx,工具内部用 `try/except` 兜住所有异常并返回可读的字符串------因为这个返回值最终会变成 `ToolMessage` 喂回给 LLM,让它能基于「失败信息」继续决策,而不是让整条链路崩溃。
2. LLM 改造:真实模型自主决策
关键变化是 `llm_node` 不再做关键词匹配,而是把整段消息历史交给真实 LLM,让模型自己产出 `tool_calls`:
python
353:371:stages/stage2_tool_calling/01_tool_basics/main.py
llm_with_tools = llm.bind_tools(tools)
tool_map = {t.name: t for t in tools}
def llm_node(state: ToolDemoState) -> dict:
"""真实 LLM 决策节点 --- 把整段消息历史交给在线 LLM。"""
messages = state["messages"]
log_step(logger, "真实 LLM", "调用在线模型进行决策......")
response = llm_with_tools.invoke(messages)
if getattr(response, "tool_calls", None):
for tc in response.tool_calls:
log_step(
logger,
"LLM 决策",
f"自主选择工具 {tc['name']},参数 {tc['args']}",
)这里的 `llm` 由 `_get_online_llm()` 提供:它会优先读 `LLM_PROVIDER`,再根据 `.env` 里已配置的 API Key 自动挑选一个可用的在线 Provider,并用 `fallback_to_mock=False` 确保拿到的不是Mock。没有任何在线 Key 时,演示会优雅跳过并提示如何配置。
3. 真实运行效果
下面是接入真实 DeepSeek + 真实 Open-Meteo 后的实际输出(数字每次跑都不一样,因为是实时数据):
--- 演示 4: 真实 LLM + 真实在线工具 ---
用户: 上海现在天气怎么样?
──────────────────────────────────────────────────
助手: 上海现在的天气是阴天,气温为21.3°C,湿度为67%,风速为13.8 km/h。
消息链长度: 4
用户: 帮我算一下 128 加 256 等于多少
──────────────────────────────────────────────────
助手: 128 加 256 等于 384。
消息链长度: 4
用户: 东京和北京现在分别多少度?
──────────────────────────────────────────────────
助手: 东京现在的气温是22.4°C,天气为阴天,湿度62%,风速6.3 km/h。
北京现在的气温是24.4°C,天气为局部多云,湿度46%,风速2.2 km/h。
消息链长度: 5
三个细节值得品味:
- 第一句的天气是真的。`21.3°C / 阴天 / 湿度 67%` 不是字典里写死的,而是 Open-Meteo 当下返回的真实观测------换个时间跑,数字就变了。
- LLM 自己分清了算术和天气。「128 加 256」它选了 `add` 工具而不是瞎算,「天气」它选了 `get_weather_online`,完全没有我们写的 `if "天气" in content` 这类规则。
- 「消息链长度 5」暴露了并行工具调用。问「东京和北京分别多少度」时,LLM 在一条 `AIMessage` 里同时发起了两个 `tool_calls`(东京 + 北京),工具节点一次执行两次、回填两条 `ToolMessage`,最后 LLM 汇总成一段话。这正是手写工具节点时用 `for tc in tool_calls` 循环、并用 `tool_call_id` 一一对应的意义所在。
> 想自己跑:在 `.env` 里填好任一在线 Provider 的 Key(如 `DEEPSEEK_API_KEY`),然后 `python stages/stage2_tool_calling/01_tool_basics/main.py` 即可。天气 API 无需任何 Key。
六、常见坑与排查
(一)坑 1:工具没有 bind_tools,LLM 永远不会调用工具
现象: 你定义了一堆 @tool,但 LLM 死活不调用,永远走「直接回复」分支。
原因: 定义工具不等于让 LLM 知道工具。@tool 只是把函数包装成 Tool 对象。
你还必须通过 llm.bind_tools([...]) 把工具的 JSON Schema 注入到每次 LLM 请求中。
如果没有 bind,LLM 的请求体里根本没有工具列表,自然无从调用。
解决方式:
python
llm_with_tools = llm.bind_tools([add, multiply, search_weather])
# 后续使用 llm_with_tools,而不是原始 llm
llm_with_tools.invoke(messages)(二)坑 2:docstring 太敷衍,LLM 选错工具或不选工具
**现象:**用户问天气,LLM 却调用了计算器。或者明明应该调用工具,LLM 却直接开始编答案。
**原因:**docstring 是 LLM 判断「这个工具该不该用、什么时候用」的重要依据。
如果你写成这样:
"""查询。"""LLM 很难判断这个工具到底适用于什么场景。
解决方式:
docstring 要写清楚:
- 工具做什么
- 什么时候使用
- 必要时说明什么时候不使用
例如:
python
@tool
def db_query(table: str) -> str:
"""查询业务数据库。适用于查找用户信息、订单记录、商品库存等结构化数据。
不适用于:互联网公开信息、实时新闻(那些请用 web_search)。"""一个好的 docstring,本质上就是写给 LLM 看的 API 文档。
(三)坑 3:ToolMessage 缺少 tool_call_id
**现象:**手写工具节点时,回填结果后报错:
tool_call_id 不匹配或者真实 LLM Provider 直接返回 400。
原因: OpenAI 等模型供应商通常要求每条 ToolMessage 必须带上对应的 tool_call_id。
否则模型无法知道:这个工具结果对应的是哪一次工具调用?
解决方式:
构造 ToolMessage 时,务必把原始 tool call 里的 id 透传进去:
python
ToolMessage(
content=str(result),
tool_call_id=tc["id"],
name=tool_name,
)不要自己随便生成 id。
七、工程化问题与生产级方案建议
(一)工程化问题
Tool Calling 跑通 Demo 不难,但要上生产,还需要考虑很多工程问题。
1. 工具描述质量决定调用准确率
docstring 是「给 LLM 看的 API 文档」。它需要像对外接口文档一样认真写,不能只写一句简单注释。
2. 参数类型要保持 JSON 兼容
LLM 生成的参数本质上是 JSON。因此参数类型最好控制在:
str / int / float / bool / list / dict如果你需要传递复杂对象,就要提前序列化。
3. 工具执行一定可能失败
工具调用会遇到各种失败场景:
- 超时
- 网络错误
- 权限不足
- 参数非法
- 第三方 API 不稳定
所以生产环境里,工具节点必须处理异常,并把错误信息以可控方式返回给 LLM。
4. 有副作用的工具必须加安全控制
例如:
- 写数据库
- 发邮件
- 创建订单
- 转账
- 删除数据
这些工具都属于有副作用操作,必须加入:
- 权限校验
- 参数校验
- 二次确认
- 审计日志
不能让 LLM 在没有保护的情况下直接执行高风险操作。
(二)生产级方案建议
如果要把 Tool Calling 用在真实 Agent 项目中,建议至少考虑以下三点。
1. 可观测性
给每次工具调用打点,记录:
tool_name- 入参
- 返回值摘要
- 耗时
- 成功 / 失败
- 错误类型
Tool Calling 是 Agent 最容易出问题的环节。没有埋点,就等于盲飞。
2. 参数白名单
如果你实现了类似 calculator 的工具,千万不要直接使用不受控的 eval。生产环境里应该:
- 使用安全表达式解析库
- 做字符白名单
- 限制可调用函数
- 限制表达式长度
否则很容易变成远程代码执行漏洞。
3. 工具版本与灰度
工具的 docstring、Schema、参数类型一旦变化,LLM 的行为就可能发生漂移。因此工具定义也应该纳入版本管理。
推荐做法是:
- 工具定义版本化
- 新工具先灰度
- 记录不同版本下的调用命中率和失败率
- 观察稳定后再全量放开
八、总结
Tool Calling 是 LangGraph Agent 的核心能力之一。这一篇我们从底层视角手写了完整链路:
@tool 定义工具
↓
bind_tools 注册工具
↓
LLM 生成 tool_calls
↓
工具节点执行函数
↓
ToolMessage 回传结果
↓
LLM 整合最终回复最终形成一个完整闭环:
LLM 决策 → 工具执行 → 结果回传 → LLM 总结理解了这个循环,你就理解了大多数 Agent 框架背后的基本运行方式。
下一篇预告
你可能已经发现:
agent ↔ tools这个循环结构,几乎是所有 Agent 的标配。
如果每次都手写,会比较啰嗦。下一篇《构建你的第一个 Tool Agent:从零理解 ReAct 循环》,我们会把这个循环升级为标准的 ReAct 模式,并看看 create_react_agent 一行代码背后到底封装了什么。